[R] 데이터분석
1.[R] 패키지, 함수, 파일 불러오기
[1] 패키지 1. 패키지 설치 > 한번만 설치하면 됨 2. 패키지 불러오기 > RStudio 실행 할 때 마다 불러와야 함 3. 패키지 제거하기 > [2] csv 파일 1. csv 파일 불러오기 readr 패키지 안의 read_csv 함수 사용 (안정적임)
2.[R] 여러가지 함수
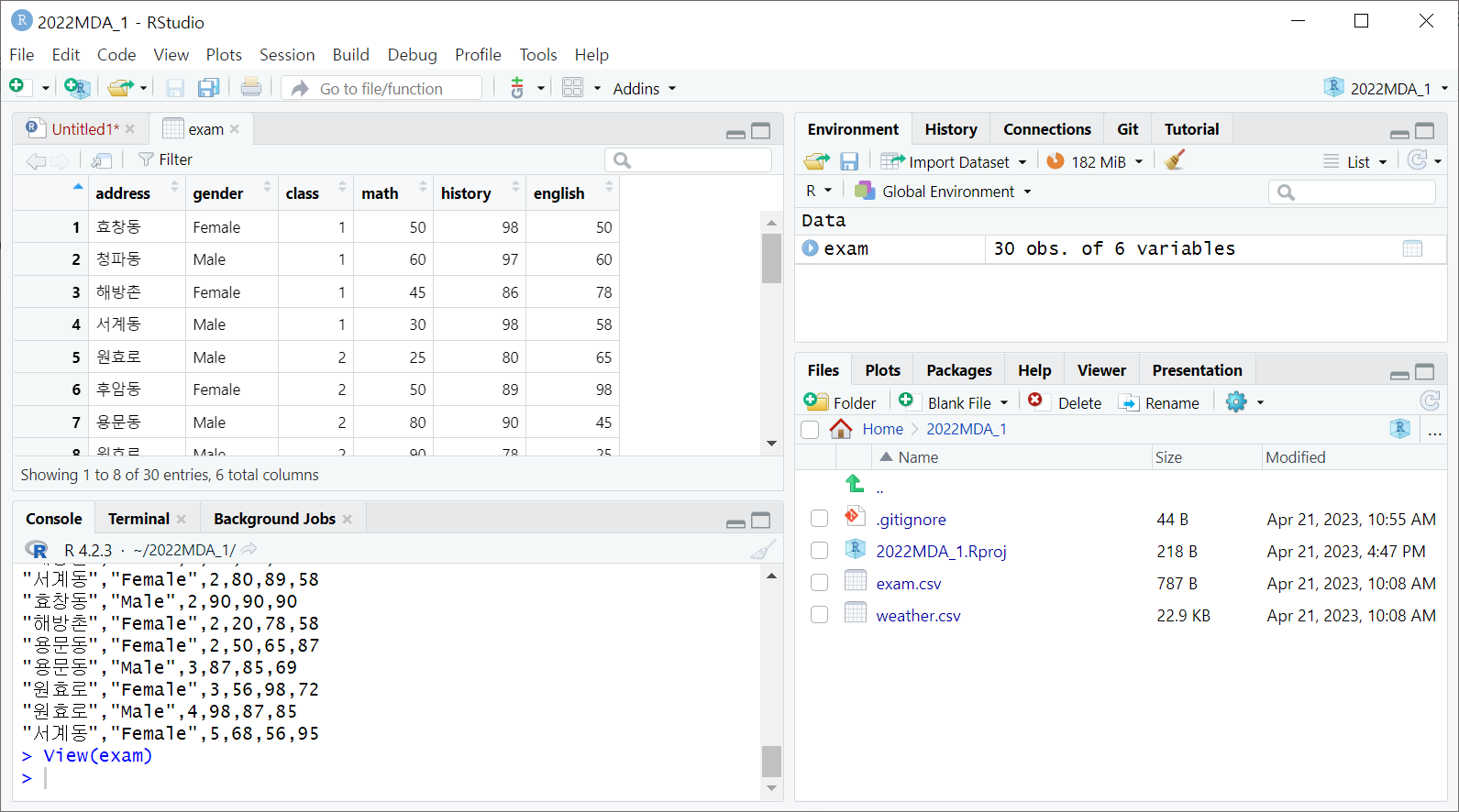
오른쪽 환경 창에서 데이터프레임 클릭 > 왼쪽에 데이터 띄워지며 아래 콘솔창에 View(데이터프레임명) 나타남row, column, 각 변수별 타입과 값들as factor
3.[R] 개별 변수에 대한 빈도
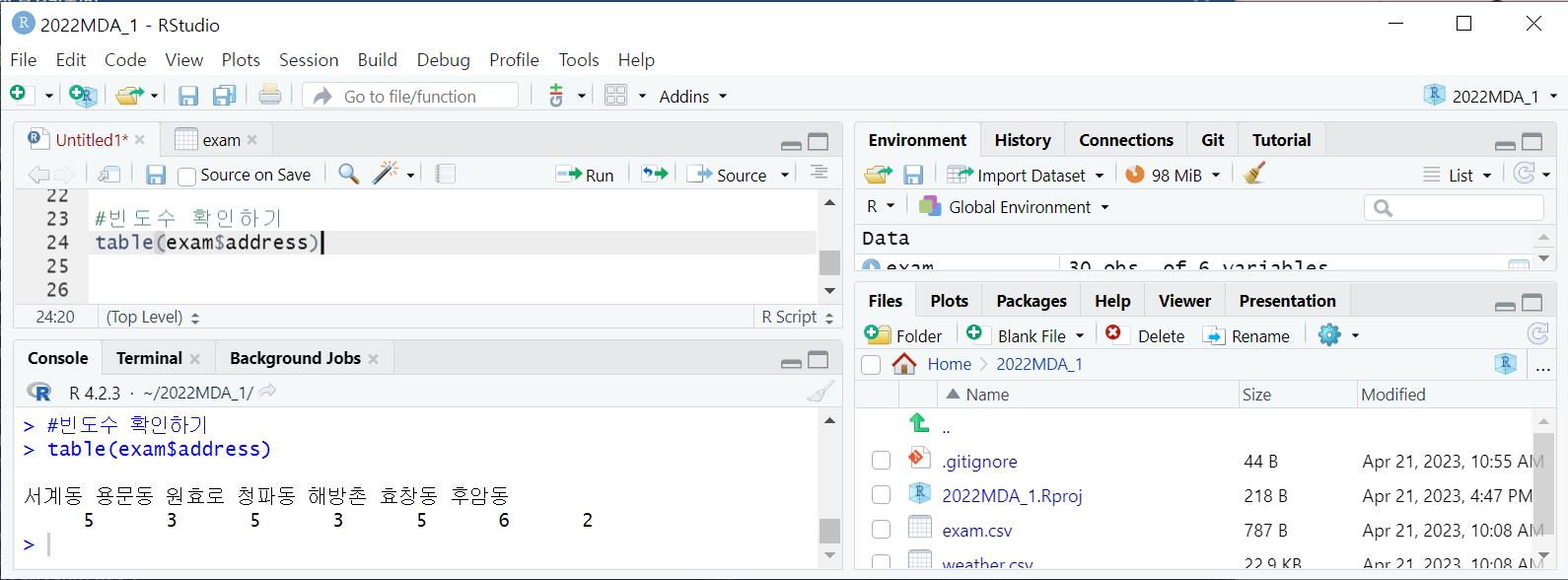
내장함수descr 패키지에 있는 함수시각화
4.[R] 기술통계량

척도가 계량형(numeric, integer)인 변수 대상내장함수인 mean, var, sd 쓸 때 관측값들 중 NA있는지 확인, 제거 후에 계산해야함True : NA 값 존재기술통계량 계산 시, NA 값은 빼고 계산여섯가지 기술 통계량 알 수 있음내장함수내장함수내장함
5.[R] 히스토그램
대상의 척도가 반드시 계량형(integer, numeric) 이어야 함내장함수데이터프레임만 X, 대상이 변수여야 함
6.[R] 비교 연산자, 논리 연산자
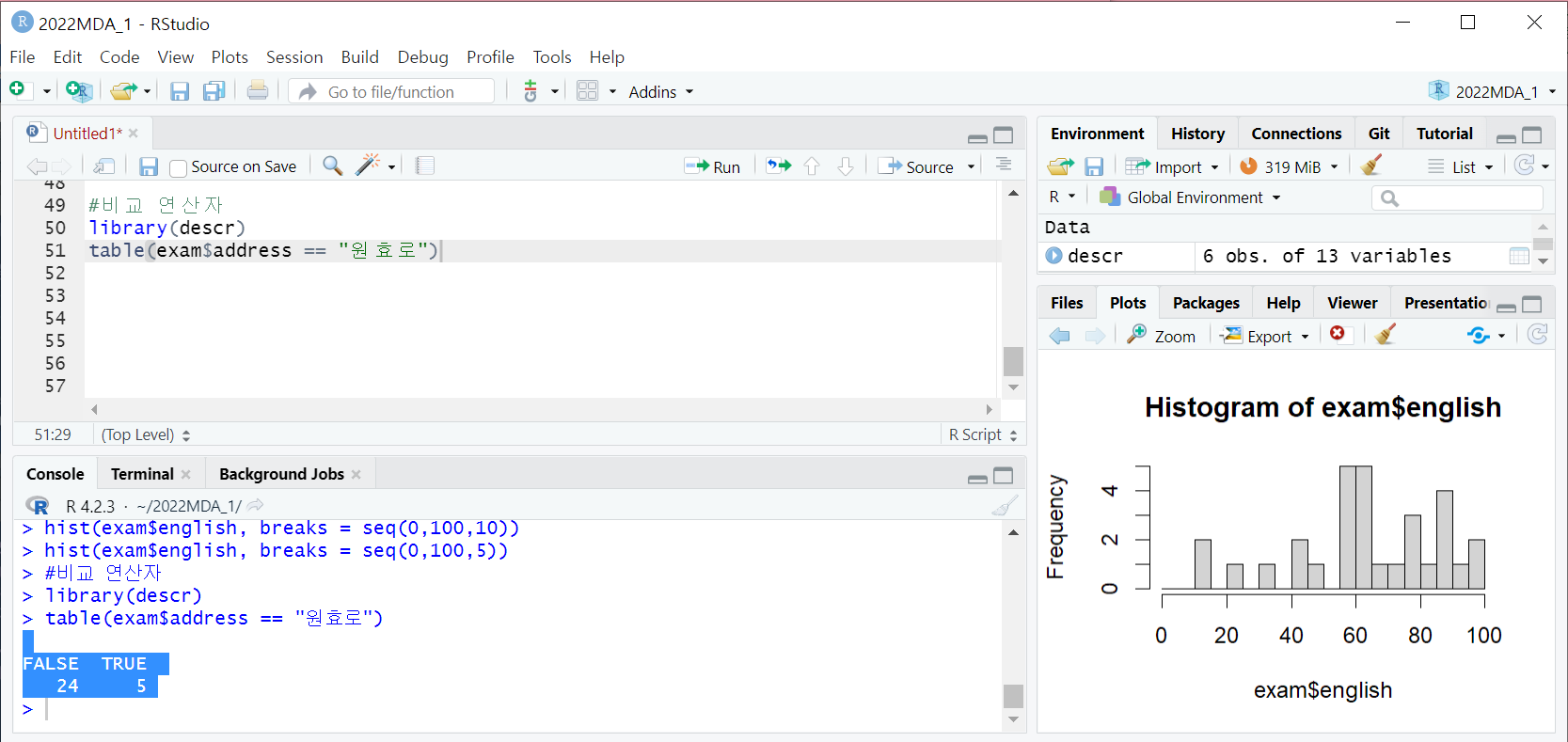
6\. 이하(작거나 같다)
7.[R] 데이터프레임의 변수
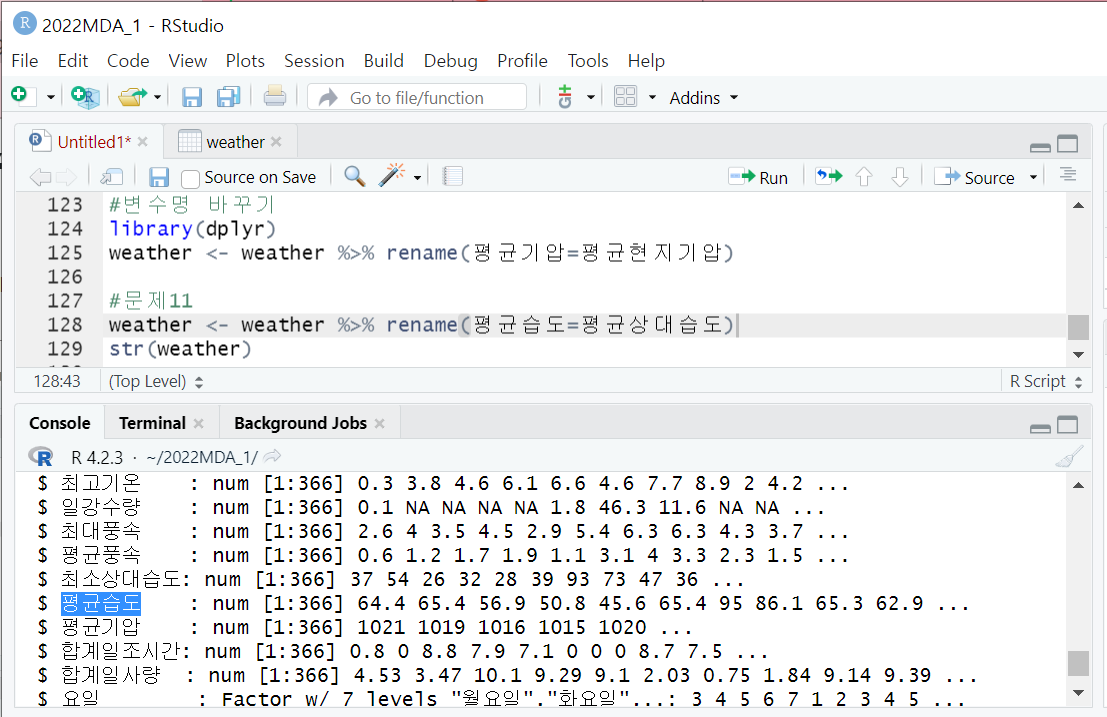
데이터프레임명$변수명 <- NULL5\. 변수 척도 변경
8.[R] 데이터 전처리
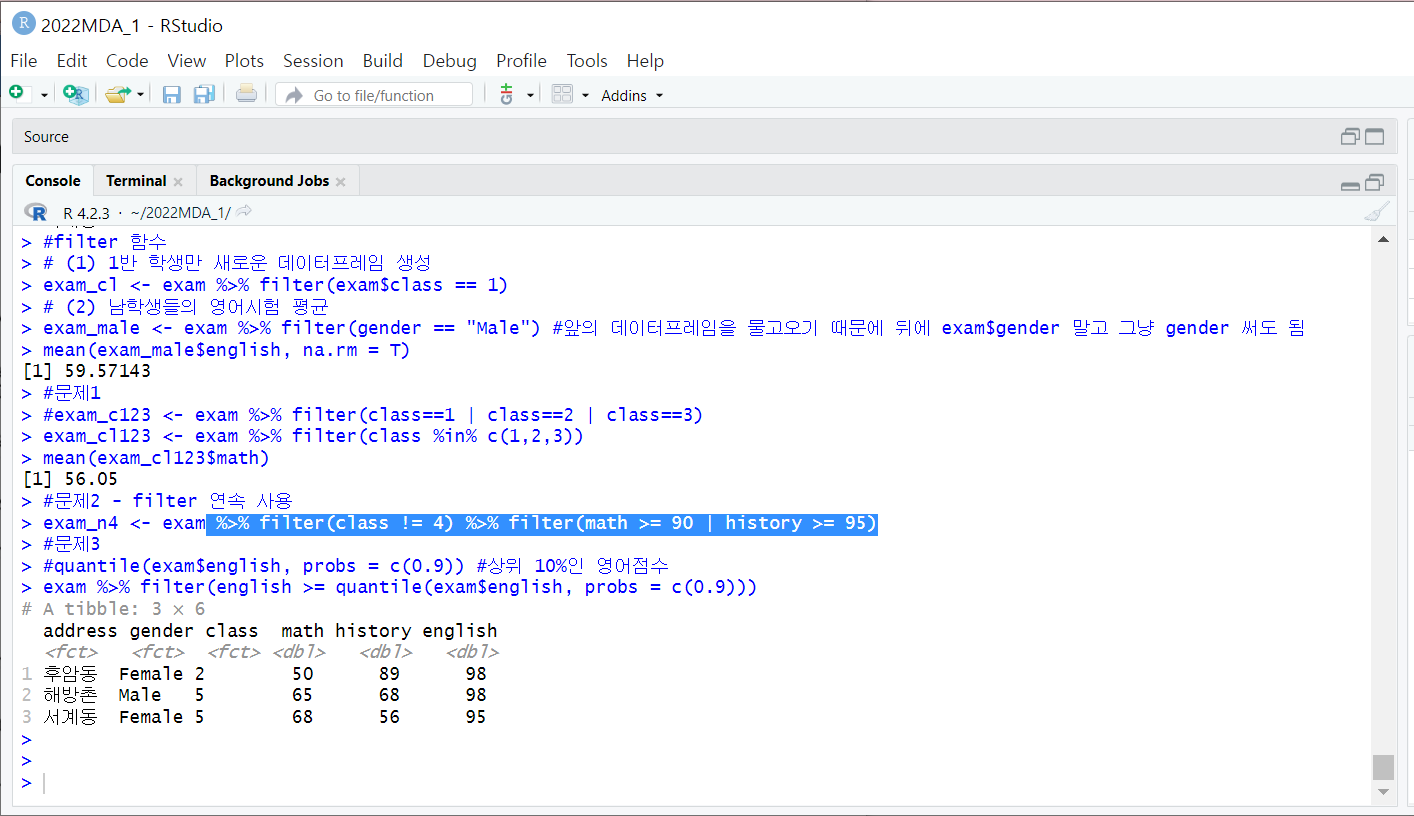
dplyr 패키지의 함수들 주로 사용조건에 부합하는 사례들을 추출할 때 사용파이프 연산자 (%>%) 를 사용해서 filter 함수 연속 사용 가능filter() %>% filter( )
9.[R] 데이터 전처리 - left join

공통 변수 = 기준이 되는 변수 = 변수명이 다르더라도, 내용 상 동일한 변수 를 기준으로 join
10.[R] 데이터 전처리 - bind_rows
변수가 일치할 필요 X => 변수의 관측값이 없는 경우 NA 처리공통변수 : 내용 상 동일한 변수 = 반드시 변수명이 일치해야 함, 변수의 척도 동일해야 함
11.[R] 데이터 전처리 - 이상치
어떤 변수의 측정값이 예상 범주를 벗어났을 대대부분 입력 오류에 기인한 경우가 많음NA로 대체 (또는 나머지 값들의 평균 ...)
12.{실습} 독립표본 t-검정
예제1.
13.{실습} 대응표본 t-검정
ㄹ
14.{실습} one-way ANOVA | 귀무가설 채택
STEP1 가설 수립 [1] 독립변수를 기준으로 나눈 3개 이상의 집단의 종속변수 모평균 비교 독립변수(priority), 종속변수(price) Ho : 뮤High = 뮤Medium = 뮤Low = 뮤NotSpecified Ha : 적어도 한 집단의 모평균은 다른 집
15.{실습} one-way ANOVA | 대립가설 채택
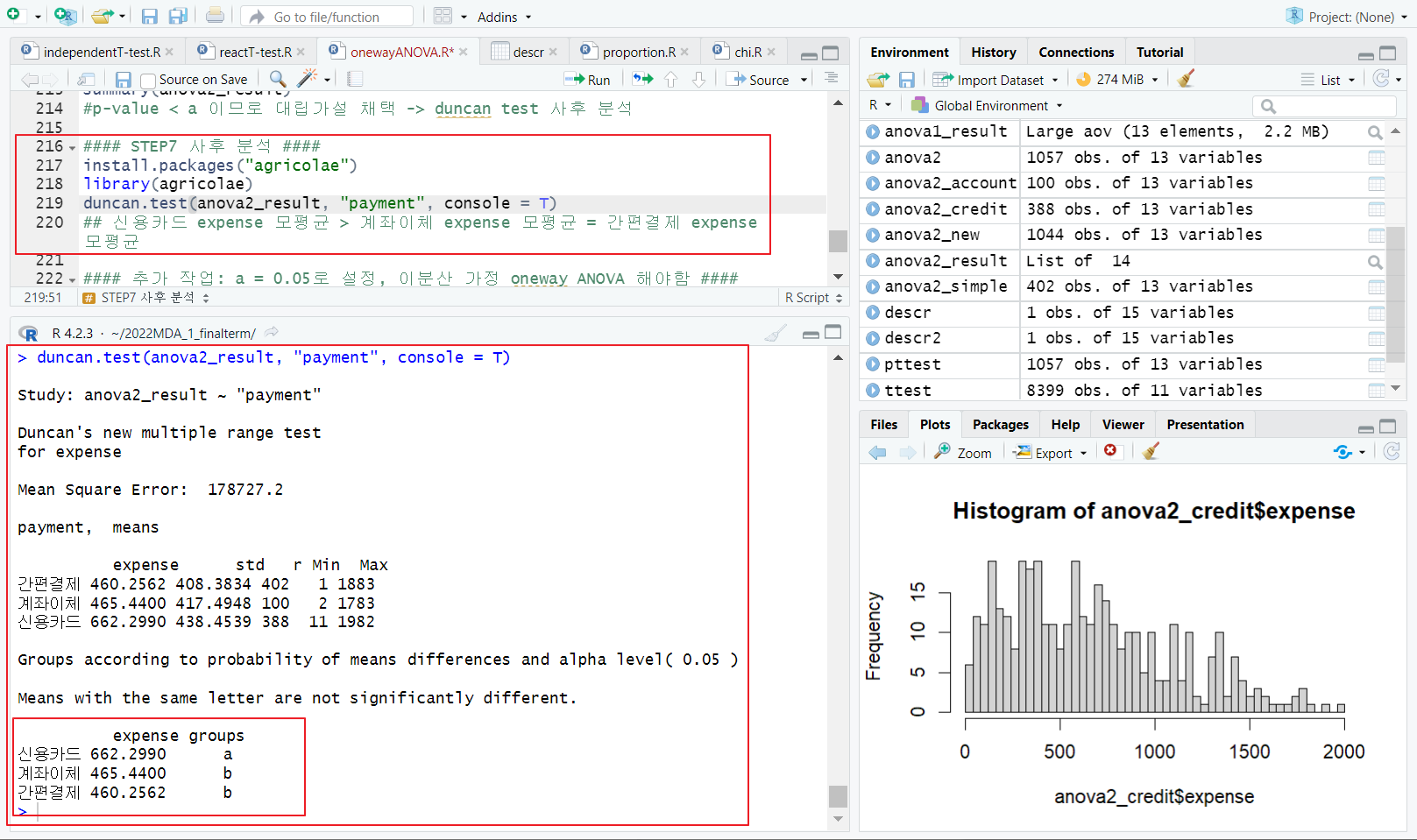
duncan.test 함수(agricolae 패키지); 등분산 가정 one-way ANOVA 검정결과 표시 - 오른쪽으로 갈수록 작아지게이분산 가정 one-way ANOVA oneway.test 함수; 사후 검정 dunn.test 함수 (dunn.test 패키지);
16.{실습} two-way ANOVA
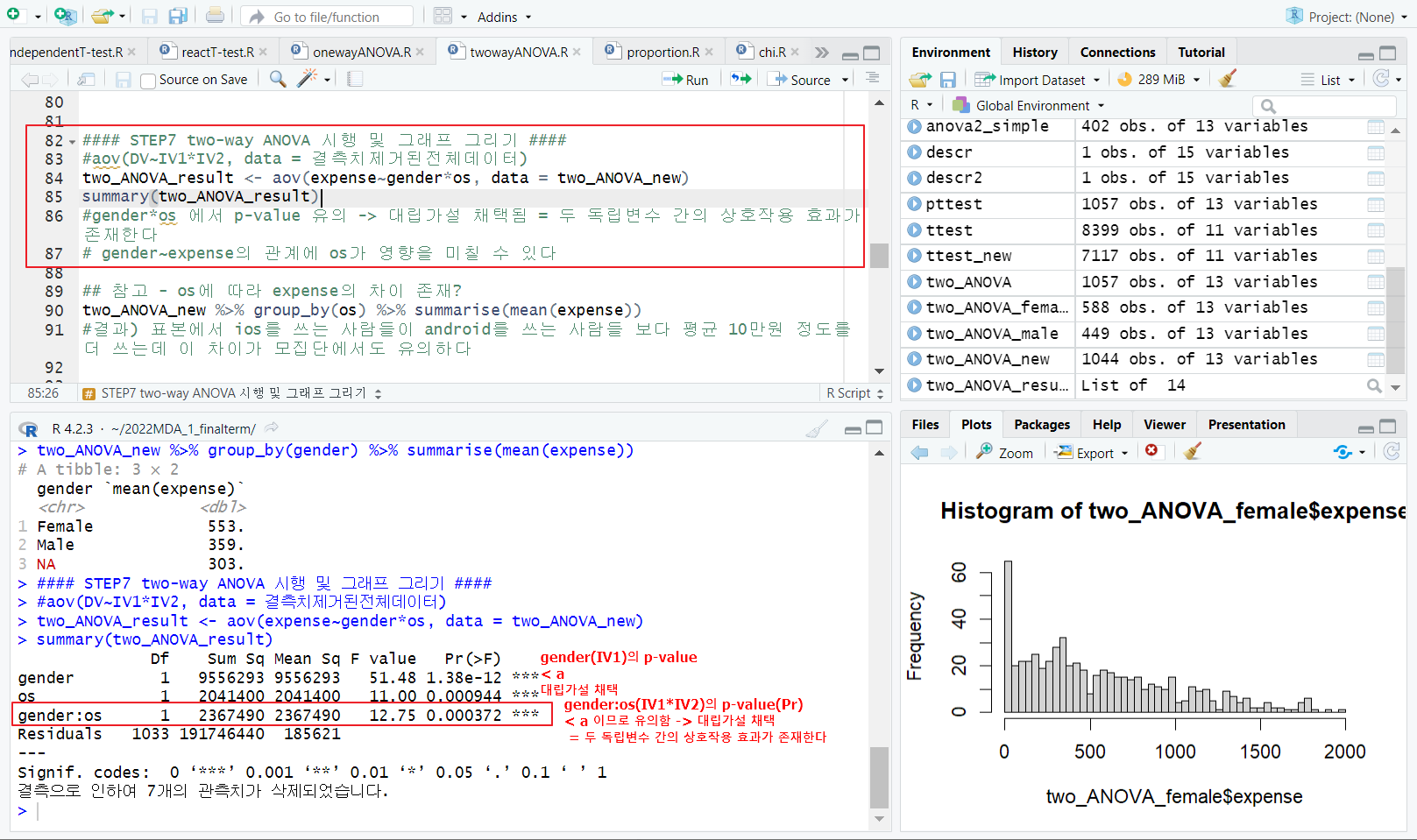
STEP1~5 two-way ANOVA를 하기 위한 기존 독립변수에 대한 one-way ANOVA를 하는 작업 STEP6 사후 분석 할필요 없음 이유1. 우리의 목적은 two-way ANOVA 이므로 이유2. 집단이 두개로 구분되어 집단별로 차이가 있다는 것은
17.{실습} 다항모집단 적합성 검정
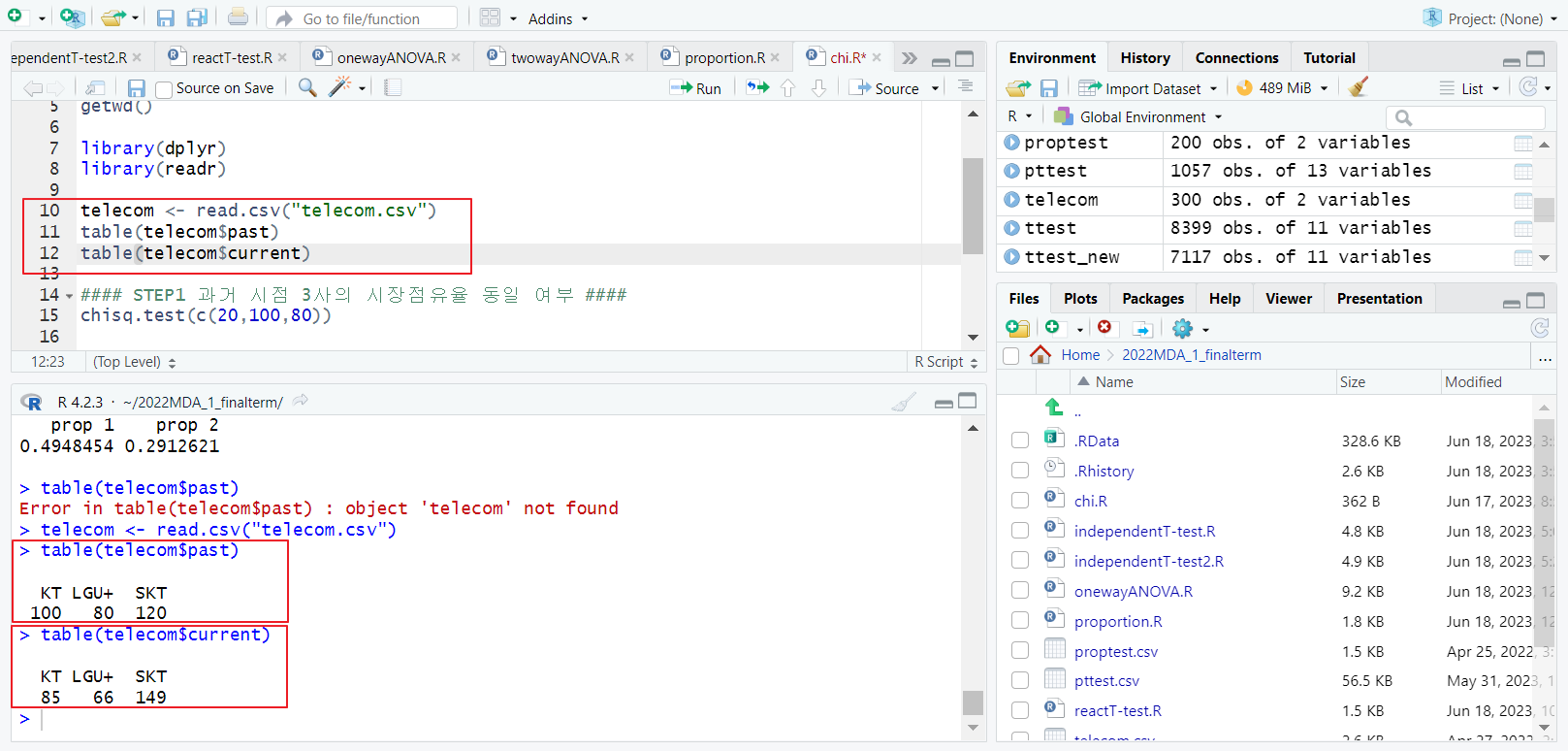
기본 세팅 작업 디렉토리 변경 getwd() : 현재 작업중인 디렉토리 콘솔에 출력 setwd("작업할 디렉토리 주소") : "작업할 디렉토리 주소"로 이동 라이브러리 함수 미리 세팅 readr : dplyr : psych : forcats : car : leven