VGGNet paper
https://arxiv.org/pdf/1409.1556.pdf
1.Introduction
-
VGGNet의 핵심은 네트워크의 깊이를 깊게 만드는 것이 성능에 어떤 영향을 미치는지 확인하고자 한 것이다.
-
VGG연구팀은 깊이의 영향만을 최대한 확인하고자 컨볼루션 필터커널의 사이즈는 가장 작은 3x3으로 고정함.
-
필터커널의 사이즈가 크면 그만큼 이미지의 사이즈가 금방 축소되기 때문에 네트워크를 충분히 깊게 만들 수 없다(계속해서 축소하면 이미지 속 데이터가 손실됨).
-
본 논문에서는 필터커널 사이즈가 작아서 네트워크의 깊이를 비교적 깊게 만들 수 있었음.
2.Architecture

-
Input image size는 224x224로 고정.
-
Conv layer에서는 3x3 conv filter와 1x1 conv filter를 사용.
(conv filter의 stride는 1, 연산시 padding 적용.) -
max pooling은 conv layer 다음에 적용되고 총 5개의 max pooling layer로 구성.
(2x2 size and stride = 2) -
FC(Fully-Connected) layer의 처음 두 FC layer는 총 4096 channel로 이루어짐.
-
모든 hidden layer에는 ReLU activation function이 적용.
-
AlexNet에서 사용된 LRN 기법은 VGGNet 저자가 실헝했을때 성능 향상도 없고, 메모리 소모 및 연산량을 늘려 사용하지 않음.
-
Original 논문에서 총 6개의 구조(A, A-LRN, B, C, D, E)를 만들어 성능을 비교하였다.
-
여러 구조를 만든 이유는 기본적으로 깊이의 변화에 따른 성능 변화를 비교하기 위함이며, D 구조가 VGG-16, E구조가 VGG-19 라고 보면 됨.
3.Conv3's effect
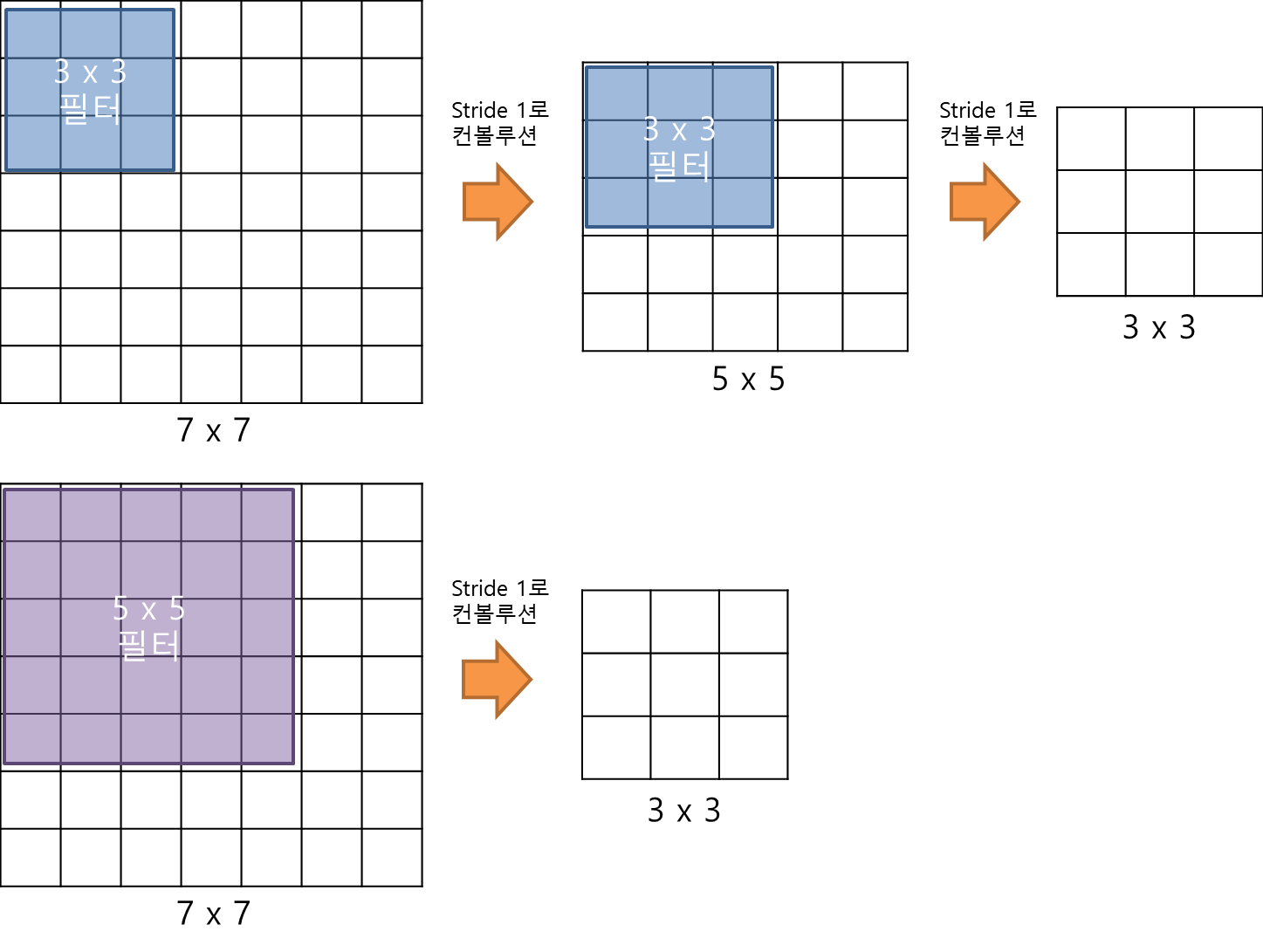
-
3x3 필터로 두 차례 컨볼루션을 하는 것과 5x5 필터로 한 번 컨볼루션을 하는 것이 결과적으로 동일한 사이즈의 Feature map을 산출한다.
-
또, 3x3 필터로 세 차례 컨볼루션 하는 것은 7x7 필터로 한번 컨볼루션 하는 것과 동일하다.
-
이때 3x3 필터로 세 차례 컨볼루션하는 것이 7x7 필터로 한 번 컨볼루션 하는 것 보다 나은 점은 가중치 또는 파라미터 개수의 차이 이다.
3x3 필터가 3개면 총 27개의 가중치를 갖는 반면, 7x7 필터는 49개의 가중치를 갖는다. -
CNN에서 가중치는 모두 훈련이 필요한 것들로, 가중치가 적다는 것은 그만큼 훈련시켜야할 것의 갯수가 작다는 것을 의미하며, 따라서 학습 속도가 빨라진다(학습시켜야하는 파라미터가 적어서).
-
또한, 줄어든 파라미터들은 overfitting을 줄이는데 도움을 준다.
파라미터(가중치)는 어떠한 객체(혹은 이미지)의 판단 기준을 의미하는데, 판단 기준이 많을 수록 같은 물체를 조금만 달라고 다른 물체로 인식할 확률이 높다.(링크 바나나 예제 참고, https://89douner.tistory.com/55)
4.VGG C model
-
VGG C model의 경우, 1x1 conv를 두어 non-linear 성격을 강화 시켰다.
1x1 conv는 링크 참조 https://github.com/JUYEON048/CNN_Study/blob/main/06.%20Deep%20Neural%20Network%20%EA%B2%BD%EB%9F%89%ED%99%94.md
4.1 Training
-
Hyper-parameter
-
Cost function : Multinonial logistic regression objective = Cross Entropy
-
Mini-batch : Batch size 256
-
Optimizer : Momenturn = 0.9
-
Regularization: L2 Regularization = 5.10^-4 & Dropout=0.5
-
Learning rate : 10-^2 --> validation error rate이 높아질수록 1/10씩(10^-1)감소시킴.
-
-
본 논문에서는 AlexNet보다 신경망이 깊고, parameter도 좀 더 많지만, 더 적은 epoch를 기록한 것은 implicit regularisation 과 pre-initialisation 때문이라고 언급.
-
implicit regularisation
- 7x7 한 개보다 3개의 3x3 conv filter에 적용되는 parameter가 적기 때문에 이를 implicit regularisation이라고 언급.
-
pre-initialisation
-
먼저 VGG A모델(16 layer)를 학습하고, 다음 B,C,D,E 모델들을 구성할때 A 모델에 학습된 layer들을 가져다 쓰는 방식으로 진행.
(A모델의 처음 4개 conv layer와 akwlakr 3개 FC layer를 사용) -
해당 방법을 통해, 최적의 초기값을 설정해주어 학습을 좀 더 용이하게 만듦.
-
-
-
Traing image size
-
VGG model을 학습시킬 때 training image를 VGG 모델의 input size에 맞게 바꿔줘야한다.
-
training scale을 S라고 할때, S를 설정하는 방법은 2가지가 있다.
-
Single-scale training
이 방식은 S를 256 or 384로 고정시켜 사용하는 방식으로, 처음에 S=256으로 설정하여 학습시킨 VGG 모델의 가중치값들을 기반으로, S=384로 설정하여 다시 학습 시킨다. S=256에서 이미 많은 학습이 진행된 상태이기 때문에 S = 384로 설정하고 학습할 때에는 learning rate를 줄여 학습시킨다.
-
Multi-scale training
Multi-scale training 방식의 경우, S를 고정시키지 않고 256~512 값들 중에서 random하게 값을 설정해준다. 보통 객체들이 모두 같은 사이즈가 아니라 각각 다를 수 있으므로, 이렇게 random하게 multi-scale로 학습시키게 해주면 학습효과가 더 좋아질 수 있다. 이러한 data augmentation 방식을 scale jittering이라고 하며, multi-scale을 학습시킬 때에는 앞선 single scale training 방식을 진행한 VGG modle(S=256 or 384)로 fine tuning 시킨다.
-
-
4.2 Test

-
Test를 할 때에도 image가 rescaling되는데, Training image를 rescaling 할때 기준이 되는 값을 S라고 했다면, test image를 rescaling 할때 기준이 되는 값은 Q이다. 이때, Q=S일 필요는 없다.
-
VGGNet 모델은 Training 할때와 중간중간 overfitting을 막기위해 Testing(Validation)할때 쓰이는 CNN구조가 약간 다르다.
Test시에는 training에서 사용되던 첫 번째 FC layer를 7x7 conv layer로 바꾸고, 마지막 두 FC layer를 1x1 conv layer로 바꾸어, 전체(uncropped) image에 적용시킬 수 있다고 한다.
(이미지상에서는 FC-connected라고 표현되어있지만, 실제로는 3개의 1x1 conv layer)
5.Classification Experiments
- Dataset은 ILVRC를 사용했고, top-1 결과는 multi-class classification error, top-5 결과는 기존 ILSVRC에서 요구하는 test(evaluation) 기준을 사용.
대부분의 실험에서 validation set을 test set으로 사용하였다고 함.
- Single scale Evaluation
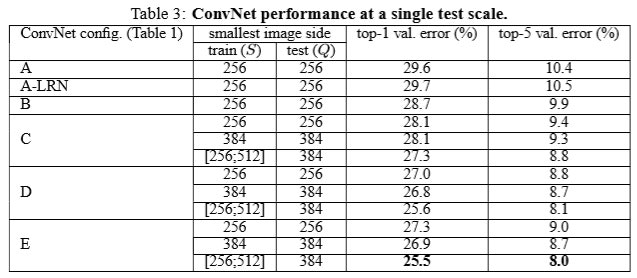
-
Single scale Evaluation이란 test 시 image size가 고정되어 있는 것을 의미.
-
single scaling training 방식을 선택했을 때에는 S=Q size로 test image size가 고정, multi-scaling trailing 방식에서는 0.5(256+512)=384로 고정.
-
A모델에서 LRN(Local Response Normalization) 기법을 사용한 모델과 그렇지 않은 모델간의 성능차이가 거의 없어 B모델부터는 LRN을 사용하지 않았음.
-
1x1 conv filter를 사용한 C 모델보다, 3x3 conv filter를 사용한 D 모델의 성능이 더 좋게 나왔다. 저자는 1x1 conv filter를 사용하면 non linearity를 더 잘 표현할 수 있지만, 3x3 conv filter가 spatial context(공간 or 위치정보)의 특징을 더 잘 추출해주기 때문이라고 언급하며 3x3 conv filter가 더 좋다고 서술.
-
Multi-scale evaluation
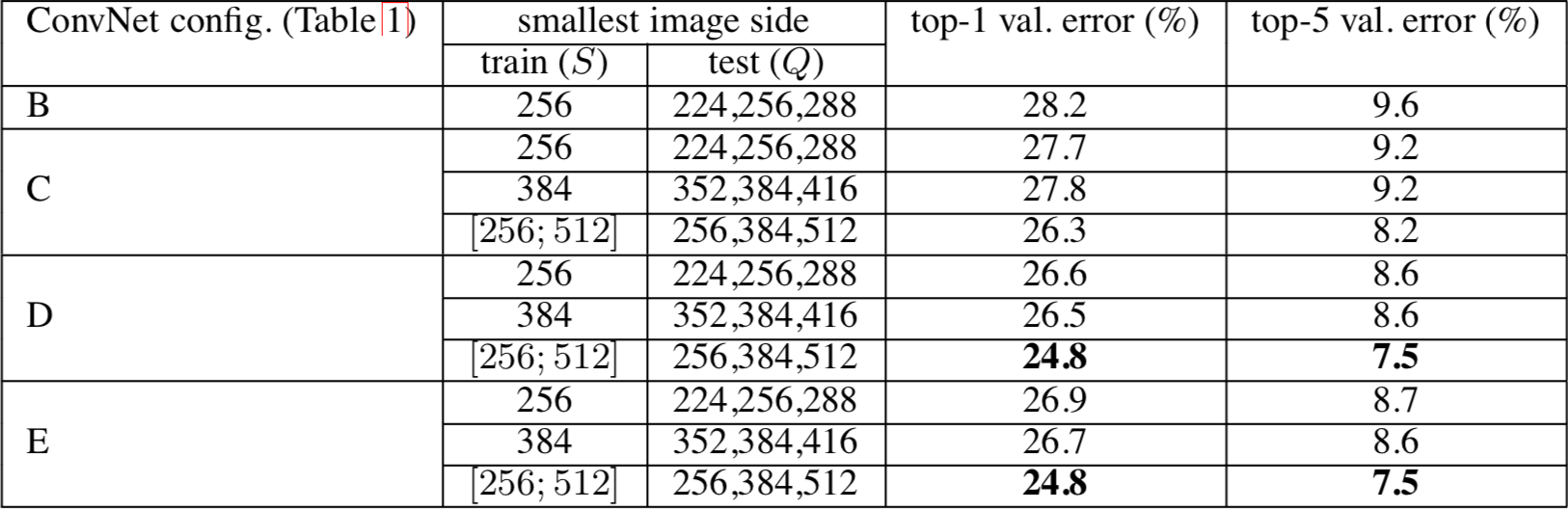
- Multi scale evaluation은 test 이미지를 multi scale로 설정하여 evaluation한 방식을 의미.
(하나의 S사이즈에 대해 여러 test image로 evaluation)
- Multi scale evaluation은 test 이미지를 multi scale로 설정하여 evaluation한 방식을 의미.
-
Comparison with the state of the art

-
저자는 ILSVRC 대회에 모델 성능을 제출할 때 7개 모델의 ensemble 기법을 적용.
-
최종적으로 2014 ILSVRC에 출시된 classification 모델들과 경합한 결과, VGGNet은 이 대회에서 2등을 차지.
-
대회 이후 자체 실험에서는 단 2개의 모델(D,E)만 ensemble한 결과가 더 좋았다고 함.
-
6.Ensemble 기법

-
Ensemble(앙상블)기법은 여러개의 결정 트리(Decision Tree)를 결합하여 하나의 결정 트리보다 더 좋은 성능을 내는 머신러닝 기법.
-
앙상블 학습의 핵심을 여러개의 약 분류기(Weak Classifier)를 결합하여 강 분류기(Strong Classifier)를 만드는 것으로, 그리하여 모델의 정확성이 향상됨.
-
앙상블 학습 방법에는 Bagging과 Boosting 두가지가 있으며, 자세한 내용은 링크 참조.
참고자료
https://89douner.tistory.com/61
https://bskyvision.com/504
https://bskyvision.com/504#recentComments
