- 출처: HackerRank: Advanced Select
- MYSQL 사용
Easy
1. ⭐ Type of Triangle (Easy)
Write a query identifying the type of each record in the TRIANGLES table using its three side lengths. Output one of the following statements for each record in the table:
- Equilateral: It's a triangle with sides of equal length.
- Isosceles: It's a triangle with sides of equal length.
- Scalene: It's a triangle with sides of differing lengths.
- Not A Triangle: The given values of A, B, and C don't form a triangle.
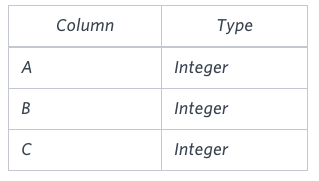
TRIANGLES table
Sample Input
Sample Output
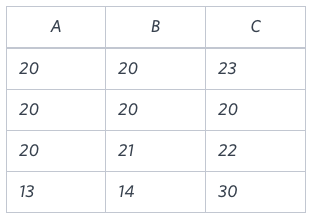
Isosceles
Equilateral
Scalene
Not A TriangleExplanation
(20, 20, 23): Isosceles triangle, A≡B.
(20, 20, 20): Equilateral triangle, A≡B≡C.
(20, 21, 22): Scalene triangle, A≠B≠C.
(13, 14, 30): cannot triangle, A and B is not larger than that of side C.
풀이
- CASE 식을 써야겠다
- 검색 CASE 식
CASE
WHEN 조건식1THEN 식1
[WHEN 조건식2 THEN 식2...]
[ELSE 식3]
END또는
- 단순 CASE 식: CASE 뒤에는 대상을 적고, WHEN 뒤에는 값만 적는다.
CASE 식1
WHEN 식2 THEN 식3
[WHEN 식4 THEN 식5...]
[ELSE 식6]
END1. 실패
SELECT
CASE WHEN A + B > C AND A + C > B AND B + C > A THEN CASE
WHEN A = B AND B = C THEN 'Equilateral'
WHEN A = B OR A = C OR B = C THEN 'Isosceles'
ELSE 'Scalene'
ELSE 'Not A Triangle'
FROM TRIANGLES;- 이중 CASE문을 작성하려니 헷갈린다..
2. 성공
SELECT
CASE
WHEN A + B > C AND B + C > A AND C + A > B THEN
CASE
WHEN A = B AND B = C THEN 'Equilateral'
WHEN A = B OR A = C OR B = C THEN 'Isosceles'
ELSE 'Scalene'
END
ELSE 'Not A Triangle'
END
FROM TRIANGLES;다시풀기
- 문제풀이 시간: 15분
- 주석에 조건문을 파이썬으로 작성하다가 에러가 뜨고, 여기서 한 5분은 버렸다..
- Your submission contains non ASCII characters, we dont accept submissions with non ASCII characters for this challenge.
1. CASE 3개..
- 처음에는
CASE-WHEN함수를 파이썬의if-else문으로 먼저 작성해본 뒤 쿼리문을 작성했다.
if a + b > c and a + c > b and b + c > a: # 삼각형이라면,
if a == b == c: # 세 변의 길이가 같다면,
result = "Equilateral"
else:
if a == b or a == c or b == c: # 두 변의 길이가 같다면,
result = "Isosceles"
else: # 모든 변의 길이가 같지 않다면,
result = "Scalene"
else: # 삼각형이 아니라면,
result = "Not A Triangle"SELECT
CASE
WHEN A + B > C AND A + C > B AND B + C > A THEN
CASE
WHEN A = B AND B = C THEN 'Equilateral'
ELSE
CASE
WHEN A = B OR A = C OR B = C THEN 'Isosceles'
ELSE 'Scalene'
END
END
ELSE 'Not A Triangle'
END
FROM TRIANGLES;2. CASE 2개..
- 그런데 쿼리문이 너무 이쁘지 않아서 다시 곰곰히 생각해보니.. 조건절을 두 부분으로만 나눠도 되는걸 깨달았다. 즉
- 삼각형이냐?
- 삼각형이면: 변의 길이가 몇개나 같냐?
- sql에서는
CASE-WHEN에서 elif는 없지만 그냥 이어서WHEN을 쓰면 되는건데, 그걸 간과하고 바로ELSE로 넘겨서 다른 조건절을 만든것이었다.
즉 이걸 파이썬으로 작성한다면,
# 1. 삼각형이냐?
if a + b > c and a + c > b and b + c > a: # 삼각형이라면,
# 2. 변의 길이가 몇개나 같냐?
if a == b == c: # 세 변의 길이가 같다면,
result = "Equilateral"
elif a == b or a == c or b == c: # 두 변의 길이가 같다면,
result = "Isosceles"
else: # 모든 변의 길이가 같지 않다면,
result = "Scalene"
else: # 삼각형이 아니라면,
result = "Not A Triangle"- 그래서 다시 이를 SQL로
CASE안의CASE로, 즉 총 두개의CASE로 줄였다.
SELECT
CASE
WHEN A + B > C AND A + C > B AND B + C > A THEN
CASE
WHEN A = B AND B = C THEN 'Equilateral'
WHEN A = B OR A = C OR B = C THEN 'Isosceles'
ELSE 'Scalene'
END
ELSE 'Not A Triangle'
END
FROM TRIANGLES;3. 최종적으로 단 하나의 CASE로 작성
- 그리고 또 곰곰히 생각해보니, 처음부터 삼각형이 아닌지를 따지면 더 간단해지는거였다. 즉, 삼각형이 아니라면 거기서 조건절이 끝나고, 삼각형이라면 그 다음 else if로 넘기면 되는 거였다. 이를 다시 파이썬으로 표현해본다면,
if a + b <= c or a + c <= b or b + c > a: # 삼각형이 아니냐?
result = "Not A Triangle"
elif a == b == c: # 세 변의 길이가 같냐?
result = "Equilateral"
elif a == b or a == c or b == c: # 두 변의 길이가 같냐?
result = "Isosceles"
else: # 모두다 아닌, 즉 모든 변의 길이가 같지 않다면,
result = "Scalene"SELECT
CASE
WHEN A + B <= C OR A + C <= B OR B + C <= A THEN 'Not A Triangle'
WHEN A = B AND B = C THEN 'Equilateral'
WHEN A = B OR A = C OR B = C THEN 'Isosceles'
ELSE 'Scalene'
END
FROM TRIANGLES;- 훨씬 쿼리문이 깔끔하고 짧아졌다.
- 이렇게 시행착오를 겪은 이유는, sql의
CASE-WHEN을 else if가 없다고 착각했기 때문이다. 순서대로 조건을 탐색하니까, 바로 이어서WHEN을 작성하면 되는데.. - 이렇게 조건문을 간소화하는 작업은 언뜻 파이썬 코테를 생각나게 했다. 백준이라면 실버밖에 안될 문제를 헤매다니. 아직도 SQL에 완전히 익숙해지지 않았나보다.
Medium
1. ⭐ The PADS (Medium)
Generate the following two result sets:
1. Query an alphabetically ordered list of all names in OCCUPATIONS, immediately followed by the first letter of each profession as a parenthetical (i.e.: enclosed in parentheses).
For example:AnActorName(A), ADoctorName(D), AProfessorName(P), and ASingerName(S).
2. Query the number of ocurrences of each occupation in OCCUPATIONS. Sort the occurrences in ascending order, and output them in the following format:There are a total of [occupation_count] [occupation]s.
where[occupation_count]is the number of occurrences of an occupation in OCCUPATIONS and[occupation]is the lowercase occupation name. If more than one Occupation has the same[occupation_count], they should be ordered alphabetically.
Note: There will be at least two entries in the table for each type of occupation.
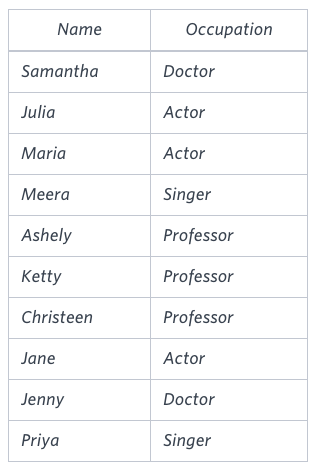
OCCUPATIONS table

Occupation will only contain one of the following values: Doctor, Professor, Singer or Actor.
Sample Input
Sample Output
Ashely(P)
Christeen(P)
Jane(A)
Jenny(D)
Julia(A)
Ketty(P)
Maria(A)
Meera(S)
Priya(S)
Samantha(D)
There are a total of 2 doctors.
There are a total of 2 singers.
There are a total of 3 actors.
There are a total of 3 professors.Explanation
first query: formatted to the problem description's specifications.
second query: ascendingly ordered first by number of names corresponding to each profession (2≤2≤3≤3), and then alphabetically by profession (doctor≤singer, and actor≤professor).
풀이
- 이름을 알파벳 순으로 하고, 바로 뒤에 직업의 첫글자를 괄호로
- 각 직업의 등장 횟수를 적기: 횟수로, 알파벳순으로 정렬
LEFT(string-expression, integer)- 문자열 결합:
- MySQL:
CONCAT - Oracle, DB2, PostgreSQL:
|| - SQL Server:
+
- MySQL:
LOWER('문자열'): 대문자를 소문자로 바꿈
1. 실패
SELECT CONCAT(Name, '(', LEFT(Occupation, 1), ')')
FROM OCCUPATIONS
ORDER BY Name;
SELECT CONCAT('There are a total of ', COUNT(Occupation), ' ', LOWER(Occupation), 's')
FROM OCCUPATIONS
ORDER BY COUNT(Occupation), Occupation;ERROR 1140 (42000) at line 4: In aggregated query without GROUP BY, expression #1 of SELECT list contains nonaggregated column 'OCCUPATIONS.Occupation'; this is incompatible with sql_mode=only_full_group_by
GROUP BY를 잊지 말자!
2. 성공
SELECT CONCAT(Name, '(', LEFT(Occupation, 1), ')')
FROM OCCUPATIONS
ORDER BY Name;
SELECT CONCAT('There are a total of ', COUNT(Occupation), ' ', LOWER(Occupation), 's.')
FROM OCCUPATIONS
GROUP BY Occupation
ORDER BY COUNT(Occupation), Occupation;다시 풀기
- 문제를 잘 읽자..!!!!
- 특히 정렬이 어떤 컬럼을 기준으로 하는지..!
- CONCAT이 아닌
+를 써서 문자열을 연결한다면,COUNT(Occupation)는 숫자이므로 오류가 발생한다!
2. ⭐ Occupations
Pivot the Occupation column in OCCUPATIONS so that each Name is sorted alphabetically and displayed underneath its corresponding Occupation. The output column headers should be Doctor, Professor, Singer, and Actor, respectively.
Note: Print NULL when there are no more names corresponding to an occupation.
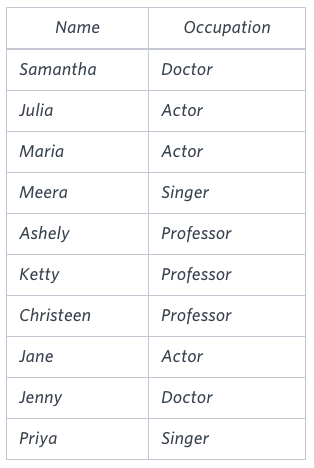
OCCUPATIONS table

Occupation will only contain one of the following values: Doctor, Professor, Singer or Actor.
Sample Input
Sample Output
Jenny Ashley Meera Jane
Samantha Christeen Priya Julia
NULL Ketty NULL MariaExplanation
The first column is an alphabetically ordered list of Doctor names.
The second column is an alphabetically ordered list of Professor names.
The third column is an alphabetically ordered list of Singer names.
The fourth column is an alphabetically ordered list of Actor names.
The empty cell data for columns with less than the maximum number of names per occupation (in this case, the Professor and Actor columns) are filled with NULL values.
풀이
- 데이터리안 SQL 문제풀이 고급 해설강의를 보고 순서대로 풀어보았다.
- 윈도우 함수를 제대로가 아닌 얼렁뚱땅 배워서인지, 이번 문제는..너무 어려웠다. 나중에 다시 풀어보자.
1. 윈도우 함수
ROW_NUMBER() OVER (PARTITION BY Occupation ORDER BY Name)
: 직업(Occupation) 별로 이름(Name) 순서에 따라 고유한 순위를 부여한다.
- ROW_NUMBER: 동일한 값에도 고유한 순위를 부여한다.
- PARTITION BY 절: 전체 집합을 소그룹으로 나눌 기준
- ORDER BY 절: 순위를 지정할 기준
SELECT Occupation
, Name
, ROW_NUMBER() OVER (PARTITION BY Occupation ORDER BY Name) AS rn
FROM OCCUPATIONS;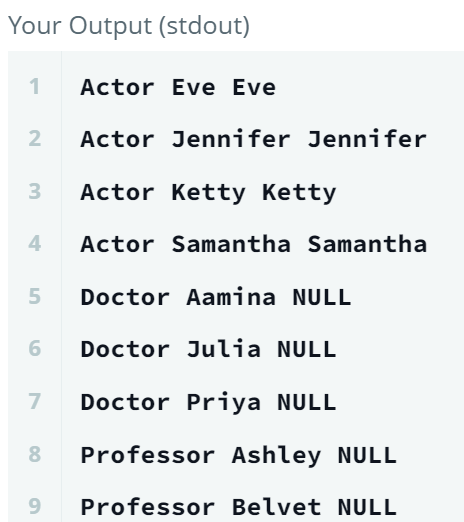 - 각 직업 안에서 순위를 매겨서, 다른 직업에서는 다시 1부터 시작.
- 각 직업 안에서 순위를 매겨서, 다른 직업에서는 다시 1부터 시작.
2. 해당 직업일 때 이름 표시하기
CASE WHEN사용해서 해당 직업일 때 이름 표시하고, 아니라면 결측치(null)로 표시
SELECT rn
, Occupation
, Name
, (CASE WHEN Occupation = 'Doctor' THEN Name ELSE NULL END) AS doctor
FROM (
SELECT Occupation
, Name
, ROW_NUMBER() OVER (PARTITION BY Occupation ORDER BY Name) AS rn
FROM OCCUPATIONS
) AS rn_table
WHERE rn = 1;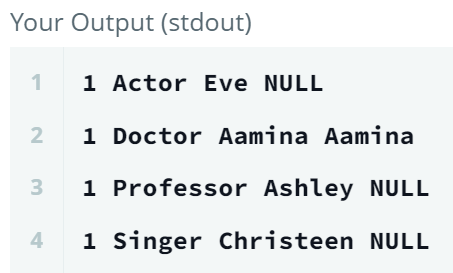 - rn=1일때, 즉 각 직업에서 첫번째 이름만 뽑고, Doctor일 때만 이름 표시했더니, 다른 직업은 다 null로 나옴.
- rn=1일때, 즉 각 직업에서 첫번째 이름만 뽑고, Doctor일 때만 이름 표시했더니, 다른 직업은 다 null로 나옴.
3. GROUP BY로 묶고, 집계함수로 NULL 제거
- 우리가 원하는건 각 컬럼에 직업별로 이름이 나오는 것!
- 그러려면, 해당 직업이 아닌 경우에 결측치로 표시되는걸 output에서 제외해야한다. -> 집계함수를 아무거나 사용하면, 결측치는 집계에서 제외된다!
SELECT rn
, MIN(CASE WHEN Occupation = 'Doctor' THEN Name ELSE NULL END) AS doctor
, MIN(CASE WHEN Occupation = 'Professor' THEN Name ELSE NULL END) AS professor
, MIN(CASE WHEN Occupation = 'Singer' THEN Name ELSE NULL END) AS singer
, MIN(CASE WHEN Occupation = 'Actor' THEN Name ELSE NULL END) AS actor
FROM (
SELECT Occupation
, Name
, ROW_NUMBER() OVER (PARTITION BY Occupation ORDER BY Name) AS rn
FROM OCCUPATIONS
) AS rn_table
WHERE rn = 1
GROUP BY rn;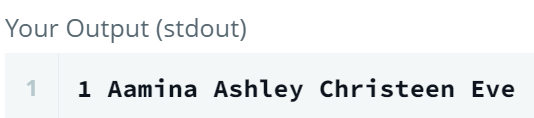 - 각 직업에서 첫번째 이름이 각 컬럼으로 출력되었다.
- 각 직업에서 첫번째 이름이 각 컬럼으로 출력되었다.
4. 모든 직업을 출력하자
- 이제 문제에서 요구하는대로 다듬자.
- 앞에서 첫번째 순위만 봤지만, 정답은 모든 순위를 출력해야한다.
- 알파벳 순서대로 정렬해야한다. 즉 우리가 윈도우 함수로 정의한 rn을 기준으로 정렬해서 출력해야한다.
- 그러나 rn(순위) 자체는 출력할 필요 없다.
SELECT MIN(CASE WHEN Occupation = 'Doctor' THEN Name ELSE NULL END) AS doctor
, MIN(CASE WHEN Occupation = 'Professor' THEN Name ELSE NULL END) AS professor
, MIN(CASE WHEN Occupation = 'Singer' THEN Name ELSE NULL END) AS singer
, MIN(CASE WHEN Occupation = 'Actor' THEN Name ELSE NULL END) AS actor
FROM (
SELECT Occupation
, Name
, ROW_NUMBER() OVER (PARTITION BY Occupation ORDER BY Name) AS rn
FROM OCCUPATIONS
) AS rn_table
GROUP BY rn
ORDER BY rn;
- Doctor, Professor, Singer, Actor의 직업이 컬럼 순서대로 잘 출력되었다.
- 순위(rn)로 그룹화했지만, 순위를 출력하지는 않았다.
3. Binary Tree Nodes
You are given a table, BST, containing two columns: N and P, where N represents the value of a node in Binary Tree, and P is the parent of N.
BST
Write a query to find the node type of Binary Tree ordered by the value of the node. Output one of the following for each node:
- Root: If node is root node.
- Leaf: If node is leaf node.
- Inner: If node is neither root nor leaf node.
Sample Input
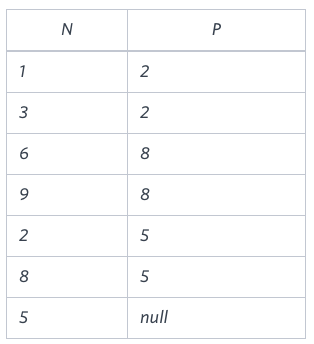
Sample Output
1 Leaf
2 Inner
3 Leaf
5 Root
6 Leaf
8 Inner
9 LeafExplanation
The Binary Tree below illustrates the sample:
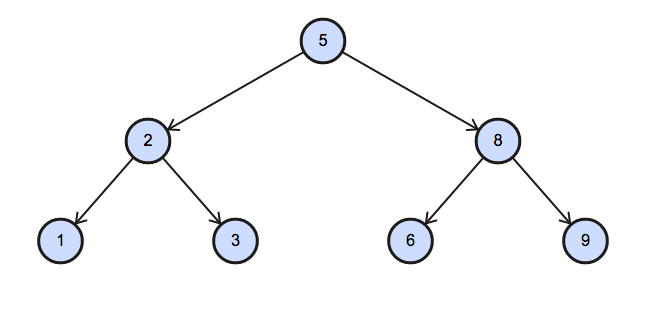
풀이
- 이진분류가 왜 여기서..와이..? 그냥 머신러닝 돌리게 해주세요
다시풀기1: JOIN 사용
- 문제풀이 시간: 10분
- 이진트리 모델에서는 부모-자식 관계가 존재한다.
- a - b - c 라면,
- a는 b의 부모 노드
- b는 a의 자식 노드이고, c의 부모 노드
- c는 b의 자식 노드
- 부모 노드가 없다면 루트 노드이고, 자식 노드가 없다면 리프 노드이다.
- 그런데 지금 테이블에서는 현재 노드의 상태만 나와있어서, 이들간의 관계를 보기 위해서 테이블을 join 해줬다. 즉, 원래 테이블의 N이 부모 노드가 되도록 붙이면, 원래 테이블 N의 자식 노드를 알 수 있다.
- 원래 테이블 BST: N, P, JOIN한 테이블 child: N2, P2
- 만약 JOIN 후 P2가 비어있다면, 원래 테이블 N의 자식노드(N2)가 없어서 P2도 결측치인 것!!
SELECT DISTINCT BST.N,
CASE
WHEN BST.P is null THEN 'Root'
WHEN child.P is null THEN 'Leaf'
ELSE 'Inner'
END
FROM BST
LEFT JOIN BST AS child ON BST.N = child.P
ORDER BY BST.N;아래 데이터리안의 JOIN 사용한 풀이와 같은 내용이지만, 아래 설명이 훨씬 쉽다!
다시풀기2: JOIN 사용
데이터리안 해설 보기 전 풀이
: 보다 비효율적인 조건 찾기(즉, Root 부터 찾는게 편한데 Inner 부터 찾는다면)..
-- N P N2 P2 => P -> N -> N2 순서
-- 자식(N2) & 부모(P) 둘다 있으면: Inner
-- 자식(N2)은 있는데 부모(P)는 없으면: Root
-- 자식(N2)은 없고 부모(P)만 있으면: Leaf
SELECT DISTINCT a.N
, CASE
WHEN b.N IS NOT NULL AND a.P IS NOT NULL THEN "Inner"
WHEN b.N IS NOT NULL THEN "Root"
ELSE "Leaf"
END AS node
FROM BST a
LEFT JOIN BST b ON a.N = b.P
ORDER BY a.N;데이터리안 풀이
JOIN 사용
- 먼저, 스스로와 JOIN: N P N2 P2 => P -> N -> N2 순서
이때, '부모가 없는 경우'는 Root 한개뿐이므로, Root 부터 찾는다!! - 부모(P)가 없으면: Root
- 부모(P)는 있는데 자식(N2)은 없음:Leat
- 그 외(부모(P)도 있고 & 자식(N2)도 있음): Inner
SELECT DISTINCT a.N
, CASE
WHEN a.P IS NULL THEN "Root"
WHEN b.N IS NULL THEN "Leaf"
ELSE "Inner"
END AS node
FROM BST a
LEFT JOIN BST b ON a.N = b.P
ORDER BY a.N;서브쿼리 사용
- 부모(P)가 없으면: Root
- 부모(P)가 있고 & 내가(N) 누군가의 부모(P)인 경우, 즉 자식이 있으면: Inner
- 그 외(부모(P)는 있는데 자식은 없음): Leat
SELECT N
, CASE
WHEN P IS NULL THEN "Root"
WHEN N IN (SELECT DISTINCT P FROM BST) THEN "Inner"
ELSE "Leaf"
END
FROM BST
ORDER BY N;JOIN 사용과 서브쿼리 사용시 조건 탐색의 순서가 다르다.
- '내가 누군가의 부모 노드인 경우'를 JOIN으로 찾느냐, 아니면 바로 IN 서브쿼리로 심플하게 작성하느냐의 차이.
- 서브쿼리가 훨씬 심플하다!
4. ⭐ New Companies
Amber's conglomerate corporation just acquired some new companies. Each of the companies follows this hierarchy:
Given the table schemas below, write a query to print the company_code, founder name, total number of lead managers, total number of senior managers, total number of managers, and total number of employees. Order your output by ascending company_code.

Note:
- The tables may contain duplicate records.
- The company_code is string, so the sorting should not be numeric. For example, if the company_codes are C_1, C_2, and C_10, then the ascending company_codes will be C_1, C_10, and C_2.
Input Format
The following tables contain company data:
- Company
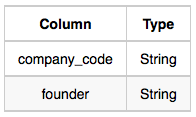
- Lead_Manager

- Senior_Manager
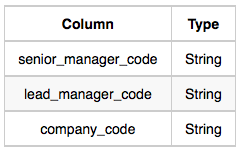
- Manager
- Employee
Sample Input
Company Table:

Lead_Manager Table:

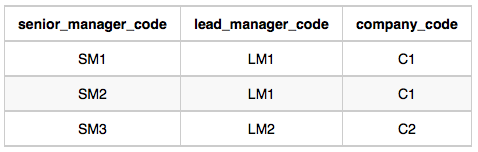
Senior_Manager Table:
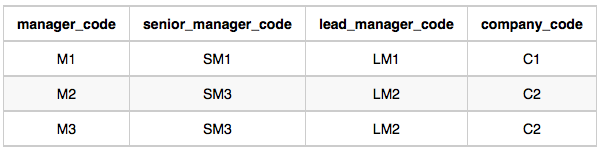
Manager Table:
Employee Table:

Sample Output
C1 Monika 1 2 1 2
C2 Samantha 1 1 2 2Explanation
In company C1, the only lead manager is LM1. There are two senior managers, SM1 and SM2, under LM1. There is one manager, M1, under senior manager SM1. There are two employees, E1 and E2, under manager M1.
In company C2, the only lead manager is LM2. There is one senior manager, SM3, under LM2. There are two managers, M2 and M3, under senior manager SM3. There is one employee, E3, under manager M2, and another employee, E4, under manager, M3.
풀이
1. 다시풀기: JOIN 사용
처음 SQL 스터디에서 풀지 못했던 문제를 이번에 다시 풀면서 성공!
- 문제풀이 시간: 30분
- 테이블을 조인해서 집계함수로 푸는 문제인데, 의외로 실수하기 좋은 문제였다. 실수로 구글링을 하면, 잘못된 정답을 적어놓은 블로그가 꽤 많다.
- 문제를 풀고나서 데이터리안 해설 영상을 보니, 고려해야할 점이 참 많은 문제였다!
야하는건 알겠는데, key를 무슨 컬럼으로 하느냐가 고민이었다.
우선 정답:
SELECT C.company_code
, C.founder
, COUNT(DISTINCT(L.lead_manager_code))
, COUNT(DISTINCT(S.senior_manager_code))
, COUNT(DISTINCT(M.manager_code))
, COUNT(DISTINCT(E.employee_code))
FROM Company AS C
LEFT JOIN Lead_Manager AS L ON C.company_code = L.company_code
LEFT JOIN Senior_Manager AS S ON L.company_code = S.company_code
LEFT JOIN Manager AS M ON S.company_code = M.company_code
LEFT JOIN Employee AS E ON M.company_code = E.company_code
GROUP BY C.company_code, C.founder
ORDER BY C.company_code;1. 어느 테이블을 join하지?
"어? Employee 에 다 나와있네? 그럼 Company와 Employee 테이블만 join하면 되는거 아냐?"라는 생각에 많이들 실수하는데, 이러면 예외 케이스가 누락된다!!!
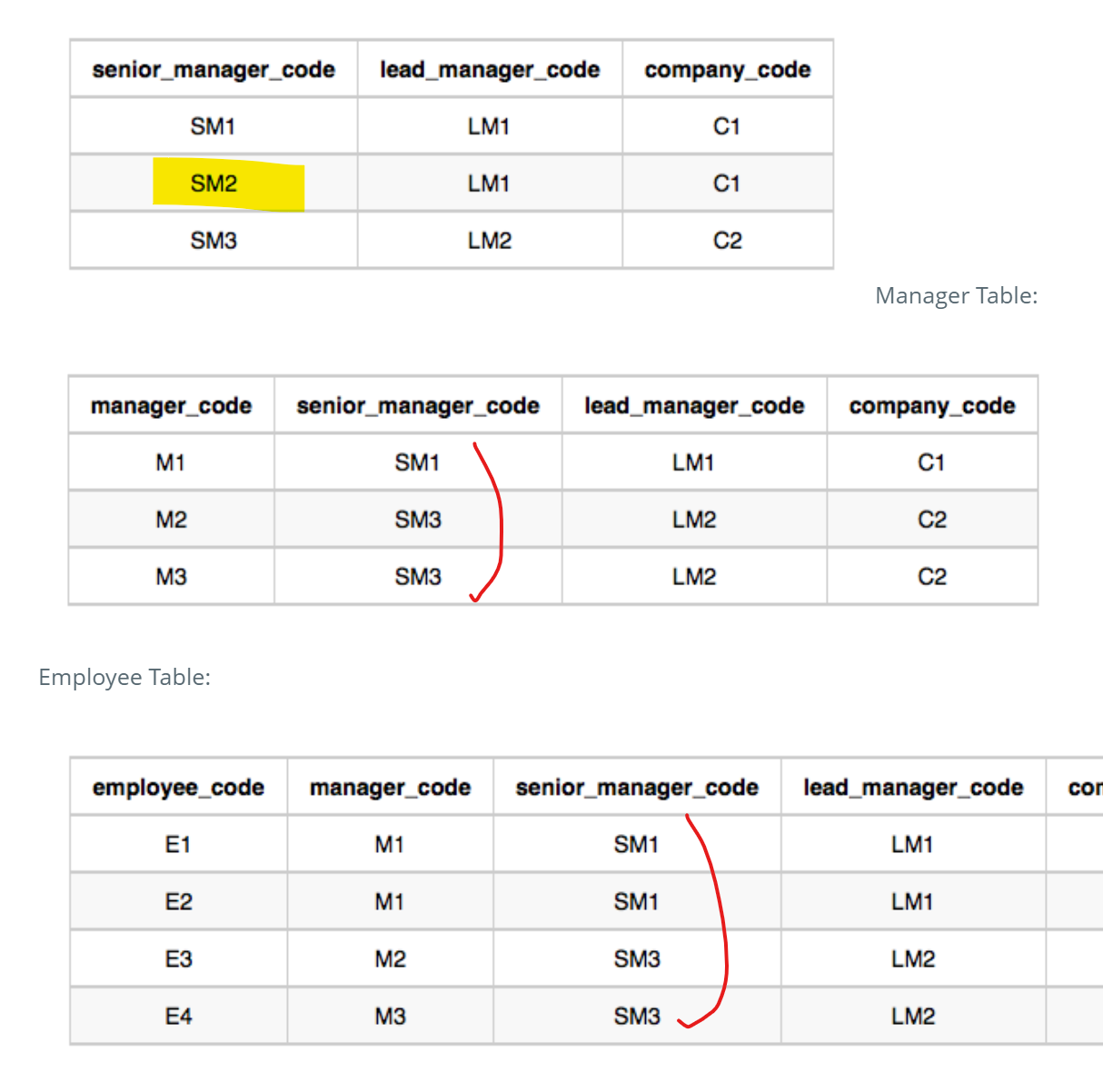
- 샘플을 보면, SM2 시니어 매니저에 속한 매니저와 직원이 없다. 그래서 SM2는 그 다음 직책의 테이블에서 등장하지 않는다.
- 따라서 모든 테이블을 다 join 해줘야한다.
2. 왜 LEFT JOIN을 해야할까?
SM2 사례처럼, 상위 직책이 존재해도 하위 직책이 부여된다는 보장이 없다. 설령 리드 매니저 아래 직책이 없다고 해도, 리드 매니저는 output에 표시되어야 한다.
- 만약 INNER JOIN을 하게 되면, 특정 테이블에만 있는 데이터는 output에 포함되지 않게 된다.
- 그러나 LEFT JOIN을 하게 되면, LEFT 테이블에 있는데 RIGHT 테이블에 존재하지 않는 경우는 결측값(null)로서 output에 나타난다.
3. 왜 KEY값을 상위 직책으로 해야할까?
직책은 계층구조로 구성되어 있다. 회사-창업자-리드 매니저-시니어 매니저-매니저-직원
4. 왜 SELECT에서 어느 테이블의 컬럼인지 명시해야할까?
어느 테이블의 컬럼을 의미하는지 정확히 명시하자!(예: L.lead_manager_code)
5. 왜 GROUP BY에서 C.founder도 정의한걸까?
- SELECT 절에는 GROUP BY 기준이 되는 컬럼과 집계 함수로 선택된 컬럼만 포함되어야 한다.
- GROUP BY 기준이 되는 컬럼은 SELECT 절에 그대로 사용할 수 있다.
- GROUP BY에 정의하지 않은 컬럼은 반드시 집계 함수를 사용한 컬럼의 집계값만 SELECT에서 사용할 수 있다
- 즉, 반드시 GROUP BY 절과 집계 컬럼을 제외한 SELECT절의 열이 일치해야한다.
6. 기타: 콤마는 앞에 찍자!
사실 그동안 습관적으로 컬럼명 다음에 바로 콤마를 찍었는데.. 데이터리안 해설 강의를 보면서 매우 잘못된 습관이란걸 깨달았다!
- 콤마를 뒤에 찍게 되면, 복붙을 하다가 실수로 콤마인 상태로 SELECT 문이 종료되어 에러가 날 수 있다.
- 복붙과 실수를 방지하기 위해 콤마를 앞에 찍자!
- 참고: https://23log.tistory.com/109
2. 다시풀기: JOIN 없이 SELECT SUBQUERY로 풀기
- 데이터리안 sql 문제풀이 고급 참조
SELECT C.company_code
, C.founder
, (SELECT COUNT(DISTINCT lead_manager_code)
FROM Lead_Manager
WHERE company_code = C.company_code)
, (SELECT COUNT(DISTINCT senior_manager_code)
FROM Senior_Manager
WHERE company_code = C.company_code)
, (SELECT COUNT(DISTINCT manager_code)
FROM Manager
WHERE company_code = C.company_code)
, (SELECT COUNT(DISTINCT employee_code)
FROM Employee
WHERE company_code = C.company_code)
FROM Company AS C
-- GROUP BY C.company_code, C.founder
ORDER BY company_code;- 각 직책의 수만 구한다면, 그냥 해당 테이블에서 select로 뽑아내면 된다. 그것을 select subquery로 넣는데, 이때 회사별로 찾아야하므로
WHERE로 Company 테이블의 company_code와 맞도록 조건을 건다. - 이때, GROUP BY를 할 필요가 없다. company_code와 founder는 각각 1대 1 매칭되고, 나머지 직책 수는 각 서브쿼리로 구해서 SELECT 하기 때문이다.
