정리
CASE식을 쓰자. 이번에는 조건이 복잡하므로 단순 CASE 말고, 검색 CASE를 쓰자- ELSE와 END를 까먹지 말자
LEFT(문자열, 정수): 문자열 자르기CONCAT(어쩌고, 저쩌고, 어찌저찌..): 이게 두개만 받는 경우도 있고, 세개 이상 받을 수 있는 경우도 있다. SQL 마다 다르다!LOWER(문자열): 알파벳 대문자를 소문자로!GROUP BY를 까먹지 말자. 근데 이거 맨날 헷갈림..- SQL에서는
==이 아니라=를 쓴다! REPLACEORTRANSLATE둘다 가능하지만, MYSQL에는TRANSLATE가 없음- 두 테이블을 엮어서 봐야한다면?
JOIN->JOIN종류를 알아놓자 ABS: 절댓값- POWER(숫자, 거듭제곱 횟수) : 거듭제곱, SQRT(숫자) : 제곱근
JOIN의 기본값:INNER JOIN
궁금증
- 30.Top Earners: 궁금증:
SELECT절에서COUNT(*)가 왜 들어가지? - Weather Observation Station 15:
ORDER BY LAT_N DESC LIMIT 1말고WHERE로 다중 조건을 할 순 없을까?
- Weather Observation Station 15:
Easy
1. Revising Aggregations - The Count Function (Easy)
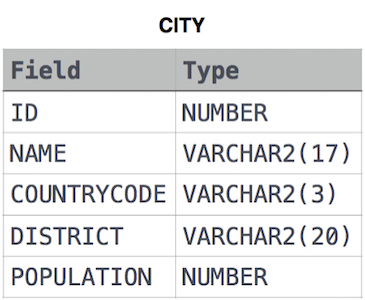
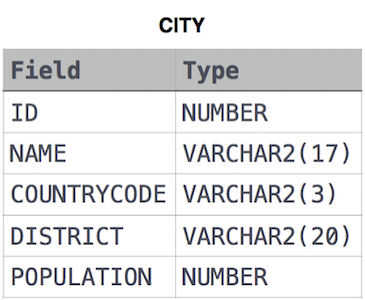
Query a count of the number of cities in CITY having a Population larger than 100,000.
CITY table
풀이
- 인구가 100,000이 넘는 도시의 수를 출력하라
- 도시를 나타내는 NAME이 있으니까, 이것의 수를 출력하면 되겠다.
SELECT COUNT(NAME)
FROM CITY
WHERE POPULATION > 100000;2. Revising Aggregations - The Sum Function (Easy)
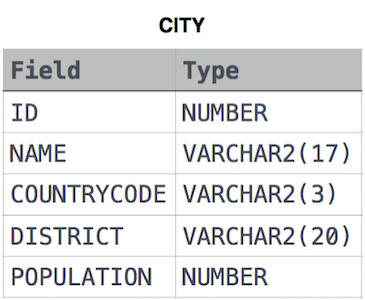
Query the total population of all cities in CITY where District is California.
CITY table
풀이
- 캘리포니아에 위치한 총 인구수 출력
1. 실패
SELECT POPULATION
FROM CITY
WHERE DISTRICT = 'California';
# 출력
124966
121780
92256- 캘리포니아에 위치한 '모든' 도시의 인구 수 '총합'을 내야함!!
2. 성공
SELECT SUM(POPULATION)
FROM CITY
WHERE DISTRICT = 'California';3. Revising Aggregations - Averages
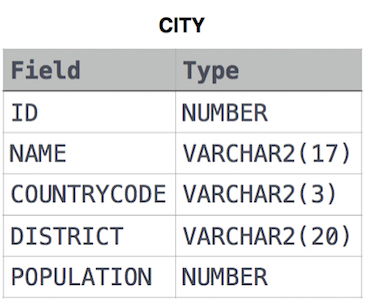
Query the average population of all cities in CITY where District is California.
CITY table
풀이
- 평균:
AVG
SELECT AVG(POPULATION)
FROM CITY
WHERE DISTRICT = 'California';4. Average Population
Query the average population for all cities in CITY, rounded down to the nearest integer.
CITY table
풀이
- 반올림:
ROUND
SELECT ROUND(AVG(POPULATION))
FROM CITY;5. Japan Population
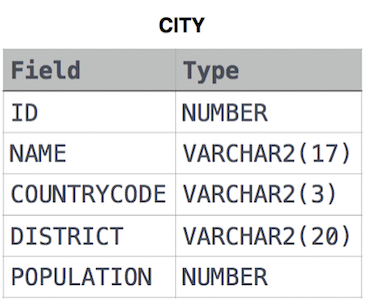
Query the sum of the populations for all Japanese cities in CITY. The COUNTRYCODE for Japan is JPN.
CITY table
풀이
- python과는 다르게, SQL에서는
==이 아니라=를 쓴다! 자꾸 이거 헷갈려서 틀림 ㅠ
SELECT SUM(POPULATION)
FROM CITY
WHERE COUNTRYCODE = 'JPN';6. Population Density Difference
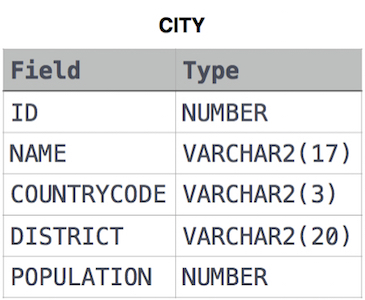
Query the difference between the maximum and minimum populations in CITY.
CITY table
풀이
- difference 라길래 순간 어? 했는데, 다시 보니까 차이를 구하라는듯.
SELECT MAX(POPULATION) - MIN(POPULATION)
FROM CITY;7. ⭐ The Blunder
Samantha was tasked with calculating the average monthly salaries for all employees in the EMPLOYEES table, but did not realize her keyboard's key was broken until after completing the calculation. She wants your help finding the difference between her miscalculation (using salaries with any zeros removed), and the actual average salary.
Write a query calculating the amount of error (i.e.: actual-miscalculated average monthly salaries), and round it up to the next integer.
EMPLOYEES table
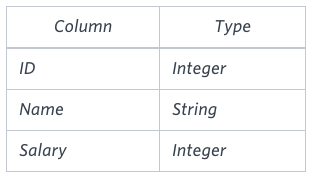
Note: Salary is per month.
Constraints
Sample Input
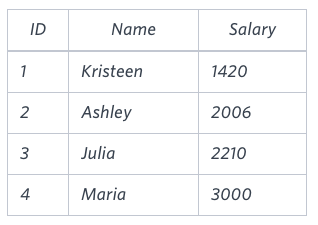
Sample Output
2061Explanation
The table below shows the salaries without zeros as they were entered by Samantha:
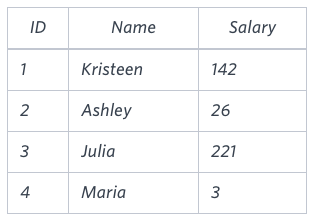
Samantha computes an average salary of 98.00. The actual average salary is 2159.00.
The resulting error between the two calculations is 2159.00-98.00=2061.00. Since it is equal to the integer 2061, it does not get rounded up.
풀이
- 0을 없앨 방법은?
REPLACEORTRANSLATEREPLACE(str, find, repl)- MYSQL에는
TRANSLATE가 없음
- 평균 구하기
- 올림(round it up to the next integer)
ROUND: 반올림,CEILING(또는CEIL): 올림,FLOOR: 내림
SELECT CEILING(AVG(Salary) - AVG(REPLACE(salary, '0', '')))
FROM EMPLOYEES;다시풀기
- 컬럼들 타입 확인하기(mysql 기준)
SHOW COLUMNS FROM EMPLOYEES;
- 순서대로Field, Type, Null, Default
1. Int -> Char
만약 그냥 CHAR(컬럼명)을 하게되면, 아스키문자열로 바뀐다.
SELECT Name
, Salary
, CHAR(Salary)
FROM EMPLOYEES;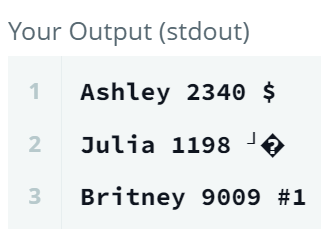
오라클에서는 그냥TO_CHAR면 문자열로 바뀐다.
select TO_CHAR(12345) -- 12345: 공백 제거 없이 그대로 문자열로 바뀜
, TO_CHAR(123.45, 'FM0000.900') -- 0123.450: 1000의 자리 고정, 소수 세번째 자리 고정
, TO_CHAR(0.59, 'FM099.0') -- 000.6: 100의 자리 고정, 소숫점이 형식보다 길어서 반올림
, TO_CHAR(0.59, 'FM999.0') -- .6: 정수 고정 안됨, 소수점이 형식보다 길어서 반올림
, TO_CHAR(123, 'FM0') -- 오류
from EMPLOYEES;- FM: 좌우 공백 제거.
9: 가변적인 값. 숫자가 없거나 0이면 버린다
0: 고정된 값. 즉 숫자의 길이를 맞추고 싶을때 0으로 채운다.
지정한 형식보다 값의 길이가 길면, 정수는 오류가 나고 소숫점은 반올림 한다.
그런데 MYSQL에서는 문자열로 변환 함수가 기억이 안나서 결국 검색해버렸다: CAST(컬럼명 AS 새로운 타입)
SELECT Name
, Salary
, CAST(Salary AS CHAR) -- Int -> Char
FROM EMPLOYEES;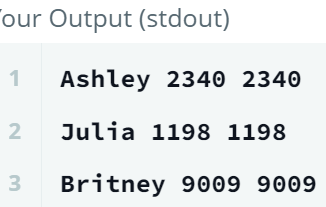
2. 0을 ''으로 대체하기
이것저것 실험해봤는데, REPLACE(컬럼명, 바꿀 문자열, 새로운 문자열)에 어떤 타입의 컬럼을 넣어도, 그 타입과 맞지 않아도 잘 찾아서 문자열로 바꿔줬다!!
SELECT Name
, Salary
, REPLACE(CAST(Salary AS CHAR), '0', '')
, REPLACE(CAST(Salary AS CHAR), 0, '') -- CHAR인데, 숫자 0 -> ''이 되네?
, REPLACE(Salary, 0, '')
, REPLACE(Salary, '0', '') -- INTEGER인데, 문자열 '0' -> ''으로 바뀌네?
FROM EMPLOYEES;
- 아마 자동 형 변환을 사용하여 서로 다른 데이터 유형 간의 연산을 수행해준 것 같다.
3. 최종 쿼리문
자동형변환 해주는걸 고려하면,
1. 0을 찾아서 빈 문자열('')로 바꾼다
2. 평균을 구한다.
3. 잘못된 평균값과 옳게 구한 평균값의 차를 구해 올림하여 출력한다.
SELECT CEILING(AVG(Salary) - AVG(REPLACE(Salary, 0, '')))
FROM EMPLOYEES;자동형변환 해주는걸 고려하지 않고 정석(?)대로 하면..
1. Salary 컬럼을 Int에서 Char 타입으로 바꾼다.
2. 0을 찾아서 빈 문자열('')로 바꾼다
3. 다시 Signed(부호있는 숫자) 타입으로 바꾼다.
4. 평균을 구한다.
5. 잘못된 평균값과 옳게 구한 평균값의 차를 구해 올림하여 출력한다.
SELECT CEILING(AVG(Salary) - AVG(CAST(REPLACE(CAST(Salary AS CHAR), '0', '') AS SIGNED)))
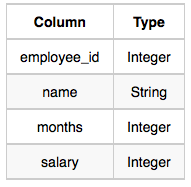
FROM EMPLOYEES;8. ⭐ Top Earners
We define an employee's total earnings to be their monthly salary X months worked, and the maximum total earnings to be the maximum total earnings for any employee in the Employee table. Write a query to find the maximum total earnings for all employees as well as the total number of employees who have maximum total earnings. Then print these values as 2 space-separated integers.
Employee table
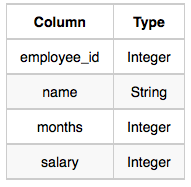
where employee_id is an employee's ID number, name is their name, months is the total number of months they've been working for the company, and salary is the their monthly salary.
Sample Input
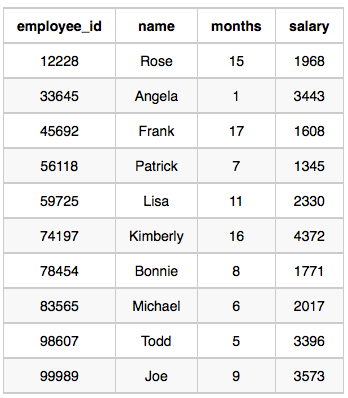
Sample Output
69952 1Explanation
The table and earnings data is depicted in the following diagram:
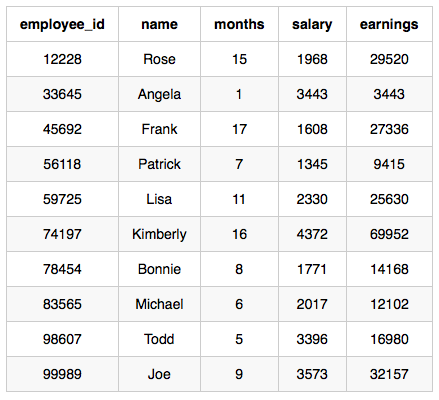
The maximum earnings value is 69952. The only employee with earnings = 69952 is Kimberly, so we print the maximum earnings value (69952) and a count of the number of employees who have earned $69952 (which is 1) as two space-separated values.
풀이
1. 실패
2. 정답 검색
- 순서: WHERE 구 -> GROUP BY 구 -> HAVING 구 -> SELECT 구 -> ORDER BY 구
- ORDER BY 구가 무조건 마지막!
- 다른 방법으로도 풀어보자!
- 궁금증:
SELECT절에서COUNT(*)가 왜 들어가지?
SELECT (months*salary) AS earnings, COUNT(*)
FROM Employee
GROUP BY earnings
HAVING earnings = (SELECT MAX(months*salary) FROM Employee);다시풀기
1. 바로 MAX(months * salary)?
단순히 months * salary로 groupby를 하고, 그 수를 출력하면 최댓값만 출력할 수 없다!
SELECT MAX(months * salary)
, COUNT(*)
FROM Employee
GROUP BY months * salary;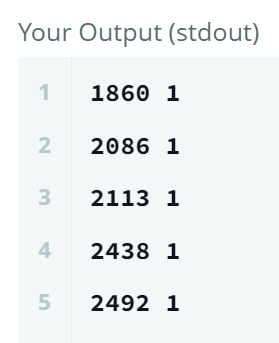
2. 가장 간단한 정답
우선 months * salary을 earnings로 별칭을 짓고, 그룹화 및 정렬 한다. '내림차순 했을 때 첫번째'가 바로 '최댓값'이기 때문이다.
SELECT months * salary AS earnings
, COUNT(*)
FROM Employee
GROUP BY earnings
ORDER BY earnings DESC
LIMIT 1;
groupby에서는 alias를 정의하는건 불가능하지만, select에서 정의한 alias를 groupby에서 사용하는건 가능하다! groupby가 select보다 먼저 실행되지만 알아서 적용된다.(다른 DB는..찾아보기!)
GROUP BY months * salary AS earnings: 불가능!
2. WITH 구문,
아쉽게도 해커랭크 MYSQL의 버전이 5.7이라서, 8.0 버전 이전의 경우 WITH 구문 사용이 불가능하다는걸 알게되었다.
WITH earnings AS (
SELECT MAX(months * salary) AS max_earnings
, COUNT(*) AS count
FROM Employee
GROUP BY months * salary
ORDER BY max_earnings DESC
LIMIT 1
)
SELECT *
FROM earnings;3. 서브쿼리를 사용한다면,
그래서 대신에 서브쿼리를 사용했다.
from 절에 서브쿼리가 들어간다면:
SELECT *
FROM (
SELECT MAX(months * salary) AS max_earnings
, COUNT(*) AS count
FROM Employee
GROUP BY months * salary
ORDER BY max_earnings DESC
LIMIT 1
) AS earnings;WHERE에 서브쿼리가 들어간다면:
다만 매 행마다 저 조건을 탐색해야해서.. 아마 많이 느릴 것 같다.
SELECT MAX(months * salary), COUNT(*)
FROM Employee
WHERE months * salary = (SELECT MAX(months * salary) FROM Employee);HAVING에 서브쿼리가 들어간다면:
마찬가지로 mysql에 한해서 select절의 alias를 where절과 having절에서 사용 가능하다.
단, having의 서브쿼리안에서는 alias가 오류가 났다.
HAVING earnings = (SELECT MAX(earnings) FROM Employee): 오류
SELECT (months*salary) AS earnings, COUNT(*)
FROM Employee
GROUP BY earnings
HAVING earnings = (SELECT MAX(months*salary) FROM Employee);9. Weather Observation Station 2
Query the following two values from the STATION table:
- The sum of all values in LAT_N rounded to a scale of 2 decimal places.
- The sum of all values in LONG_W rounded to a scale of 2 decimal places.
STATION table
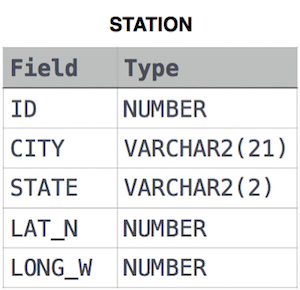
where LAT_N is the northern latitude and LONG_W is the western longitude.
Output Format
Your results must be in the form:
lat lonwhere lat is the sum of all values in LAT_N and lon is the sum of all values in LONG_W. Both results must be rounded to a scale of 2 decimal places.
풀이
SELECT ROUND(SUM(LAT_N), 2), ROUND(SUM(LONG_W), 2)
FROM STATION;10. Weather Observation Station 13
Query the sum of Northern Latitudes (LAT_N) from STATION having values greater than 38.7880 and less than 137.2345. Truncate your answer to decimal places.
STATION table
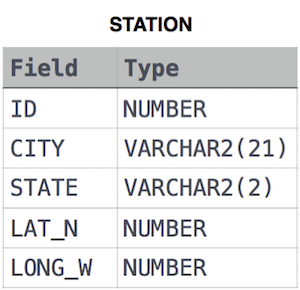
where LAT_N is the northern latitude and LONG_W is the western longitude.
풀이
SELECT TRUNCATE(SUM(LAT_N), 4)
FROM STATION
WHERE LAT_N > 38.7880 AND LAT_N < 137.2345;11. Weather Observation Station 14
Query the greatest value of the Northern Latitudes (LAT_N) from STATION that is less than 137.2345. Truncate your answer to 4 decimal places.
STATION table
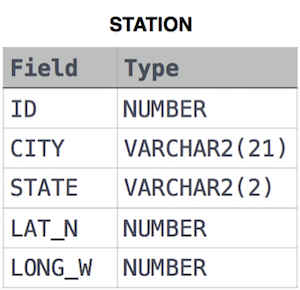
where LAT_N is the northern latitude and LONG_W is the western longitude.
풀이
SELECT TRUNCATE(MAX(LAT_N), 4)
FROM STATION
WHERE LAT_N < 137.2345;12. Weather Observation Station 15
Query the Western Longitude (LONG_W) for the largest Northern Latitude (LAT_N) in STATION that is less than 137.2345. Round your answer to decimal places.
STATION table
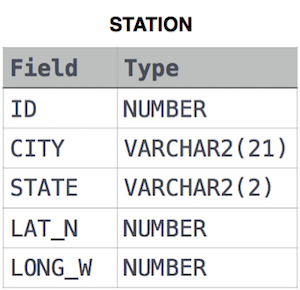
where LAT_N is the northern latitude and LONG_W is the western longitude.
풀이
- 궁금증:
ORDER BY LAT_N DESC LIMIT 1말고WHERE로 다중 조건을 할 순 없을까?
SELECT ROUND(LONG_W, 4)
FROM STATION
WHERE LAT_N < 137.2345
ORDER BY LAT_N DESC LIMIT 1;다른 방법 풀이
SELECT ROUND(LONG_W, 4)
FROM STATION
WHERE LAT_N = (SELECT MAX(LAT_N) FROM station WHERE LAT_N < 137.2345);WHERE안에 서브쿼리를 넣자- 문제에서 요구하는 것 자체가 조건 안의 조건 같은거니까..!
WHERE LAT_N = (SELECT MAX(lat_n) FROM station) AND LAT_N < 137.2345;라고 하면 애초에 충돌을 해버림!!
다시풀기
order by & limit vs. where subquery 뭐가 더 빠를까?
위의 풀이에서 바로 ORDER BY LAT_N DESC LIMIT 1 를 하느냐, 아니면 WHERE절에서 서브쿼리로 MAX(LAT_N)를 찾느냐 중 어느것이 더 빠른지 궁금해졌다.
일반적으로 시간 복잡도를 나타내는 빅오표기법은 이렇다.
- 파이썬에서(다른 언어는 잘 모르겠는데, 아마 비슷할 것 같다) min, max의 시간복잡도는 O(N), 기본 정렬 알고리즘의 시간복잡도는 O(N Log N)이라서 min, max가 훨씬 빠르다.
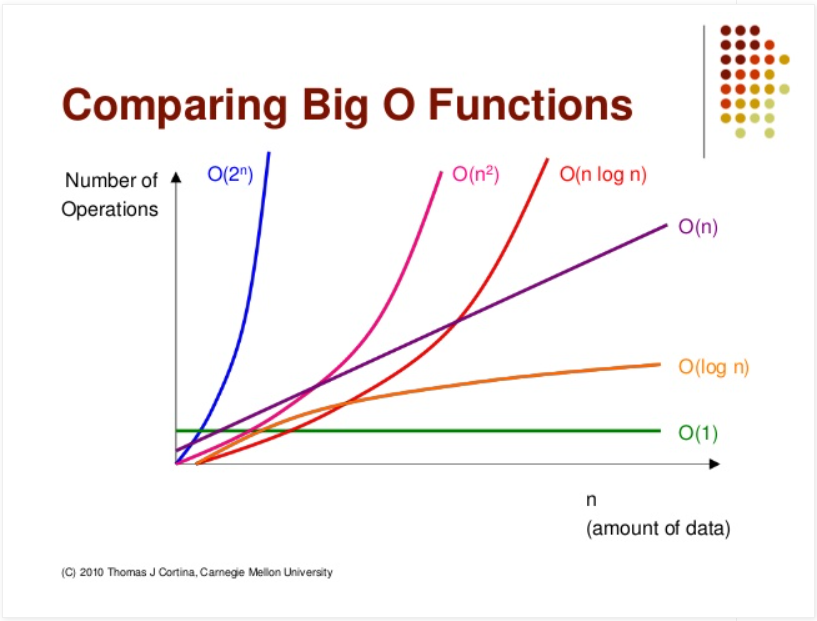
그런데.. SQL에서는 어떨까?
1. min/max는 faster in the worst case
서브쿼리 빼고 단순히 min/max와 order by & limit을 비교해보면, 최악의 상황에서는 min/max가 가장 빠르지만, 바람직한 상황이라면 둘의 차이는 없다고 한다.
2. 그때그때 달라요
찾아보니 인덱스에 따라, DB에 따라 차이가 난다고 한다. 더군다나 위 쿼리문에서는 서브쿼리에 min, max가 들어가므로 또 다른 변수가 생긴 셈이다.
- 출처: https://stackoverflow.com/questions/70472832/efficiency-of-order-by-desc-limit-vs-where-subquery
결론. 정답은 없다
이 고민을 정리하면 정렬기준과 출력 해야하는 컬럼이 다른 경우이고, 두가지 풀이방법이 있다.
- ORDER BY, LIMIT를 엮어서 ORDER BY에서는 정렬 기준을, SELECT에서는 출력해야 하는 컬럼을 써주는 방법
- 서브쿼리를 써서, WHERE로 특정 값(최대값 또는 최소값)만 걸러낸 뒤에 출력해주는 방법
그리고 이 두가지 풀이방법에 정답은 없다! 내 쿼리 계획에 따라 각각 실행해보며 비교하거나, 그때그때 잘 결정하자.
no answer to your question
13. Weather Observation Station 16
Query the smallest Northern Latitude (LAT_N) from STATION that is greater than 38.7780. Round your answer to 4 decimal places.
STATION tabl
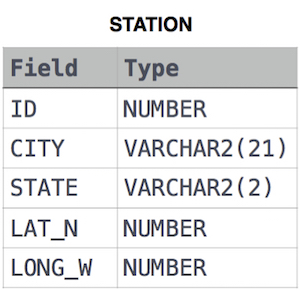
where LAT_N is the northern latitude and LONG_W is the western longitude.
풀이
- LAT_N이 38.7780보다 큰 값 중에서 가장 작은 값을 소수 4째까지 반올림 하여라
- 가장 작은 값? :
ORDER BY로ASC: 오름차순 정렬하기
SELECT ROUND(LAT_N, 4)
FROM STATION
WHERE 38.7780 < LAT_N
ORDER BY LAT_N ASC LIMIT 1;다시풀기
MIN 사용
SELECT ROUND(MIN(LAT_N), 4)
FROM STATION
WHERE LAT_N > 38.7780;14. Weather Observation Station 17
Query the Western Longitude (LONG_W)where the smallest Northern Latitude (LAT_N) in STATION is greater than 38.7780. Round your answer to 4 decimal places.
STATION table
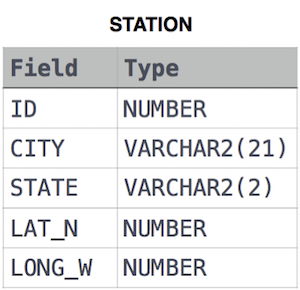
where LAT_N is the northern latitude and LONG_W is the western longitude.
풀이
- 윗 문제와 거의 동일
- LONG_W을 소수 4번째 자리까지 출력하는데, LAT_N이 38.7780 보다 큰 값중에서 가장 작은 값 중에서 출력.
SELECT ROUND(LONG_W, 4)
FROM STATION
WHERE 38.7780 < LAT_N
ORDER BY LAT_N ASC LIMIT 1;다시풀기
WHERE에 서브쿼리로 풀면:
SELECT ROUND(LONG_W, 4)
FROM STATION
WHERE LAT_N = (
SELECT MIN(LAT_N)
FROM STATION
WHERE LAT_N > 38.7780
);Medium
1. Weather Observation Station 18
Query the Manhattan Distance between points and on a 2D plane and round it to a scale of 4 decimal places.
- : minimum value in Northern Latitude (LAT_N in STATION).
- : minimum value in Western Longitude (LONG_W in STATION).
- : maximum value in Northern Latitude (LAT_N in STATION).
- : maximum value in Western Longitude (LONG_W in STATION).
STATION table
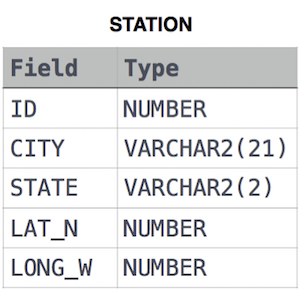
풀이
- 맨해튼 거리: p1 at (x1, y1) and p2 at (x2, y2), it is |x1 - x2| + |y1 - y2|.
ROUND와ABS중 어느것을 먼저하느냐에 따라 두가지 방법 존재
성공1
SELECT ABS(ROUND(MIN(LAT_N), 4) - ROUND(MAX(LAT_N), 4)) + ABS(ROUND(MIN(LONG_W), 4) - ROUND(MAX(LONG_W), 4))
FROM STATION;성공2
SELECT ROUND(ABS(MIN(LAT_N) - MAX(LAT_N)),4) + ROUND(ABS(MIN(LONG_W) - MAX(LONG_W)),4)
FROM STATION;다시풀기
생각해보니, 최종적으로 마지막에만 반올림을 하면 되는거였다.
SELECT ROUND(ABS(MIN(LAT_N)-MAX(LAT_N)) + ABS(MIN(LONG_W)-MAX(LONG_W)), 4)
FROM STATION;2. Weather Observation Station 19
Consider and to be two points on a 2D plane where are the respective minimum and maximum values of Northern Latitude (LAT_N) and are the respective minimum and maximum values of Western Longitude (LONG_W) in STATION.
Query the Euclidean Distance between points and and format your answer to display 4 decimal digits.
STATION table
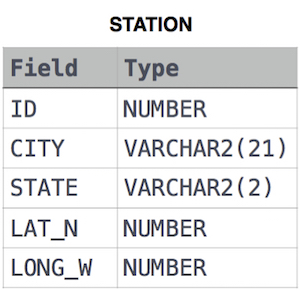
풀이
- Euclidean Distance:
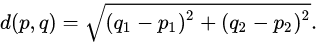
POWER(숫자, 거듭제곱 횟수): 거듭제곱
SQRT(숫자): 제곱근- 소수점 4째자리까지 표시(반올림)
SELECT ROUND(SQRT(POWER(MIN(LAT_N) - MAX(LAT_N), 2) + POWER(MIN(LONG_W) - MAX(LONG_W), 2)), 4)
FROM STATION;4. ⭐ Weather Observation Station 20
A median is defined as a number separating the higher half of a data set from the lower half. Query the median of the Northern Latitudes (LAT_N) from STATION and round your answer to decimal places.
STATION table
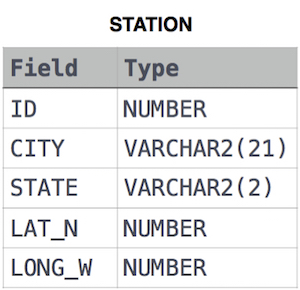
풀이
OVER(세부기준..):GROUP BY나 서브쿼리를 사용하지 않고 간단하게 분석함수(SUM, MAX, COUNT)나 집계함수(GROUP BY, ORDER BY)를 사용할 수 있음
다시풀기
놀랍게도 mysql에는 median 함수가 없어서 직접 중앙값을 구해야한다.
1. PERCENT_RANK()로는 중앙값을 구할 수 없다.
처음 이 문제를 풀었을 때, 많은 블로그들이 percent_rank()로 백분률이 0.5인 행을 찾아 문제를 통과했다. 그러나 이 방법은 큰 반례가 존재한다.
SELECT ROUND(LAT_N, 4)
FROM (
SELECT LAT_N
, PERCENT_RANK() OVER (ORDER BY LAT_N ASC) AS percent
FROM STATION
) AS a
WHERE percent = 0.5;행의 개수가 짝수인 경우, 백분률이 0.5인 경우가 존재하지 않기 때문이다.
1. row_number() 와 count()
중앙값을 직접 구하는 방법을 찾다가 좋은 블로그를 발견했다.
[SQL] MEDIAN 함수 없이 중앙값 구하기 글을 참고해서, row_number() 와 count() 를 이용해서 두가지 방법으로 중앙값을 구해보았다.
자칫하면 오류나기 쉬워서 꽤 헤맸고, 헤매면서 윈도우 함수에 대해 쪼끔 더 익숙해졌다.
1-1. 2*row_num BETWEEN cnt AND cnt+2
중앙값이 위치한 행을 찾아서 그 값들의 평균을 구한다.
SELECT ROUND(AVG(LAT_N), 4)
FROM (
SELECT LAT_N
, COUNT(*) OVER() AS cnt
, ROW_NUMBER() OVER (ORDER BY LAT_N ASC) AS row_num
FROM STATION
) AS a
WHERE 2*row_num BETWEEN cnt AND cnt+2;- 전체 n행이고, 찾고자 하는 중앙값의 행이 row_num이라면,
- 짝수 행인 경우, row_num은 두개: n/2행, (n/2)+1행
- 홀수 행인 경우, row_num은 한개: (n+1)/2행
- 이것을 양변에 2를 곱해서 row_num의 관점에서 전개하면,
- 짝수 행인 경우, 2*row_num은 n행, n+2행
- 홀수 행인 경우, 2*row_num은 n+1행
따라서 2*row_num이 n과 n+2 사이인 행들만 찾아내서 평균을 구하면(짝수인 경우 행이 2개이므로) 중앙값!!
- 예를 들어,
- 전체 6행인 경우: 중앙값은 3행과 4행
- 전체 7행인 경우: 중앙값은 4행
1-2. row_num between floor((cnt+1)/2) and ceil((cnt+1)/2)
1-1과 같은 방법인데, 내림과 올림을 사용했다.
SELECT ROUND(AVG(LAT_N), 4)
FROM (
SELECT LAT_N
, COUNT(*) OVER() AS cnt
, ROW_NUMBER() OVER (ORDER BY LAT_N ASC) AS row_num
FROM STATION
) AS a
WHERE row_num BETWEEN floor((cnt+1)/2) AND ceil((cnt+1)/2);우선 홀수 행인 경우, 전체 행의 개수를 2로 나눈게 곧 중앙값의 행이다.
그런데 짝수 행인 경우, 전체 행의 개수를 2로 나누면 소수점이 발생한다.
- 예: 전체 7행인 경우, 7/2 = 3.5행
중앙값은 3행과 4행을 구해서 이들의 평균을 구해야하는데, 이는 각각 3.5행의 내림값과 올림값과 같다.
1-3. 자칫하면 오류 발생하는 쿼리들
-
FROM의 서브쿼리에서
COUNT(*)시에OVER()을 사용해야만 하지 않으면, groupby가 되어서 다음 오류가 발생한다.- 즉
COUNT(*)는 단일값을 출력하는 함수인데, 이것을 FROM 절에 넣어서 모든 행마다 행의 수를 출력하라면 반드시OVER()을 써줘야 한다.ERROR 1140 (42000) at line 15: In aggregated query without GROUP BY, expression #1 of SELECT list contains nonaggregated column 'STATION.LAT_N'; this is incompatible with sql_mode=only_full_group_by
- 즉
-
1-1에서 만약
(2*row_num - cnt) between 0 and 2을 하게 되면, 다음 오류가 발생한다. 아무래도2*row_num - cnt이 마이너스가 되는 경우, 컬럼 타입의 범위를 벗어나서 생기는 오류로 보인다.- 따라서 tot_cnt을 빼지 말고 탐색할 값에 더해서 between에서 탐색하는게 좋다.
ERROR 1690 (22003) at line 6: BIGINT UNSIGNED value is out of range in '((2 *
a.row_num) -a.cnt)'
- 따라서 tot_cnt을 빼지 말고 탐색할 값에 더해서 between에서 탐색하는게 좋다.
2. row_number()와 case when
ROW_NUMBER()와 COUNT(*)를 사용하는건 같은데, WHERE절에서 CASE WHEN을 사용해서 짝수 행인 경우와 홀수 행인 경우를 나눈다.
MOD(): 나머지 구하기- 출처: 데이터리안
SELECT ROUND(AVG(LAT_N), 4)
FROM (
SELECT LAT_N
, COUNT(*) OVER() AS cnt
, ROW_NUMBER() OVER (ORDER BY LAT_N ASC) AS row_num
FROM STATION
) AS a
WHERE
CASE
WHEN MOD(cnt, 2) = 0 THEN row_num IN (cnt/2, (cnt/2)+1) -- 짝수 행인 경우
ELSE row_num = (cnt+1)/2 -- 홀수 행인 경우
END;윈도우 함수를 얼렁뚱땅(=그때그때 구글링 하면서) 익혔더니, 매번 검색하게 된다. 한번 날잡고 다져봐야지.
