Scrapy란?
동기방식, 비동기 방식
동기 방식
- 순서대로 데이터를 받아옴. 즉 request 1, response1, request 2, response 2,...
비동기 방식
- 네트워크 타임 동안 다른 코드를 수행하기 때문에 네트워크 타임 세이브 가능.
- 대신 순서대로 가져오지 않음.
- request 1, request 2, ....response 10, response 3, request 13,... 이런식 가능.
Scrapy
장점
- 비동기 방식으로 데이터 수집 속도가 빠르다
단점
- 순서가 섞여서 수집된다
절차
1. scrapy project 생성
import scrapy, requests
from scrapy.http import TextResponse- os 시스템 명령어를 이용
!scrapy startproject popconeboardgame- 폴더 내부를 살펴보면..
: 프레임워크는 빈칸채우기 같음! 출력해보면 틀이 다 있음
!tree popconeboardgame /f
2. 수집할 데이터의 xpath를 찾음
- 이 파트는 xpath로 데이터를 가져오는걸 보여주기 위한것. 실제 크롤링에서는 1, 3, 4번만 수행
- xpath 찾은걸 스크래피 프로젝트에 적용할 것임
링크 가져옴
url = 'https://www.popcone.co.kr/goods/goods_list.php?cateCd=038001'
request = requests.get(url)
response = TextResponse(request.url, body=request.text, encoding="utf-8")- xpath를 가져옴:
'//*[@id="contents"]/div[2]/div/div[2]/div[2]/div/div[1]/ul/li[1]/div/div[2]/div[1]/a'- 이를 적절히 수정
aa = response.xpath('//*[@id="contents"]/div[2]/div/div[2]/div[2]/div/div[1]/ul/li/div/div[2]/div[1]/a/@href').extract()
links = []
for i in aa:
links.append('https://www.popcone.co.kr'+i[2:])- for문을 돌린 이유는 앞에 http 이게 안 뜨기 때문에
aa[:2]
# 출력
['../goods/goods_view.php?goodsNo=74187',
'../goods/goods_view.php?goodsNo=86238']- for문을 돌려서 다음과 같은 결과를 얻음
links[:2]
# 출력
['https://www.popcone.co.kr/goods/goods_view.php?goodsNo=74187',
'https://www.popcone.co.kr/goods/goods_view.php?goodsNo=86238']상세페이지 데이터 수집
link = links[0]
request = requests.get(link)
response = TextResponse(request.url, body=request.text, encoding='utf-8')
# 결과데이터가 항상 list로 나옴. 그래서 0번을 가져오도록.
title = response.xpath('//*[@id="frmView"]/div/div/div[1]/h3/text()')[0].extract() # /text() 추가
price = response.xpath('//*[@id="frmView"]/div/div/div[2]/dl[2]/dd/strong/strong/text()')[0].extract() # /text() 추가- 출력
title, price
('[온라인콘특가][팝콘게임즈] 익스플로딩 키튼 (63.5x88 FIT 소프트슬리브 100매 증정) / 얼리버드특가', '19,800')- 만약, [0].extract() 안 쓰면?
response.xpath('//*[@id="frmView"]/div/div/div[1]/h3/text()')
# 출력
[<Selector xpath='//*[@id="frmView"]/div/div/div[1]/h3/text()' data='[온라인콘특가][팝콘게임즈] 익스플로딩 키튼 (63.5x88 FIT...'>]3. item.py: 코드 작성
- model(AI의 모델이 아니라, 데이터의 구조라고 생각하면 좋음)
: 수집할 데이터의 컬럼을 정의
%%writefile popconeboardgame/popconeboardgame/items.py
import scrapy
class PopconeboardgameItem(scrapy.Item): # scrapy.Item을 상속 받음
title = scrapy.Field()
price = scrapy.Field()
link = scrapy.Field() # 이 세개의 컬럼으로 수집할 것임4. spider.py: 코드 작성: 크롤링 절차 정의 (이 단계가 핵심!!)
%%writefile popconeboardgame/popconeboardgame/spiders/spider.py
import scrapy
from popconeboardgame.items import PopconeboardgameItem
class GMSpider(scrapy.Spider):
name = "GMB" # 스크래피 프로젝트 실행시 이름으로 사용됨.
# spider 안에는 여러개의 spider class를 만들수 있는데, 난 그중에서 GMB라는 이름의 spider를 사용하겠다
allow_domain = ["popcone.co.kr/"] # 도메인 지정
start_urls = ["https://www.popcone.co.kr/goods/goods_list.php?cateCd=038001"] # 최초의 request response를 하는 url을 써줌.
# 이렇게 설정하면 request response 하는 코드를 이 스크래피가 알아서 해줌. 프레임워크는 빈칸채우기라는 말이 이것!
def parse(self, response): # request 한 url이 response에 들어감. link 데이터를 수집함.
aa = response.xpath('//*[@id="contents"]/div[2]/div/div[2]/div[2]/div/div[1]/ul/li/div/div[2]/div[1]/a/@href').extract()
links = []
for i in aa:
links.append('https://www.popcone.co.kr'+i[2:])
for link in links[:20]: # 200개 수집된것 중에서 20개만 사용(시간이 너무 걸리니까)
yield scrapy.Request(link, callback=self.parse_content)
# 비동기 방식으로 실행되기 때문에, 실행될때 첫번째 링크로 request 하고, 그다음 두번째.. 즉, 실행될때마다 return 데이터가 달라짐
# 최초에 실행되는 메서드는 꼭 parse라고 써줘야하고. yield에 parse_content라고 쓴거 꼭 아래 함수랑 같은걸로 써줘야함(식별자 맞춰야함)
def parse_content(self, response):
item = PopconeboardgameItem() # 3개의 객체를 가지고 있음
item["title"] = response.xpath('//*[@id="frmView"]/div/div/div[1]/h3/text()')[0].extract()
item["price"] = response.xpath('//*[@id="frmView"]/div/div/div[2]/dl[2]/dd/strong/strong/text()')[0].extract()
item["link"] = response.url
yield item5. scrapy project 실행
- 우리는
scrapy crawl GMB -o items.csv를 실행해야함- -o: output의 약자.
- 이 명령어를 실행하려면 popconeboardgame 디렉토리 안에 들어가서 실행해야함
절차
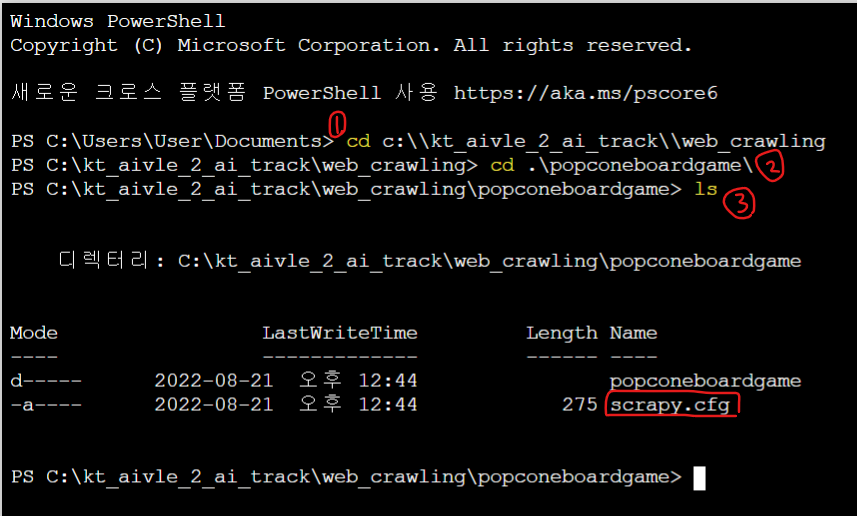
- %pwd로 내 폴더 경로 본 뒤
- 앞에 cd를 붙여서 경로로 체인지.
: cd c:\kt_aivle_2_ai_track\web_crawling - ls 눌러서 현재 폴더 봐보자.
- cd .\popconeboardgame\
: 이때 cd 하고 popcorn 한 다음 tab키 누르면 자동완성 - ls 눌러서 확인 한번 해주고..
- scrapy.cfg에서 실행해야함.
: scrapy crawl GMB -o items.csv 명령어 실행. 그러면 크롤링이 됨
실행
%pwd
# 출력 'c:\\kt_aivle_2_ai_track\\web_crawling'2, 4, 5.
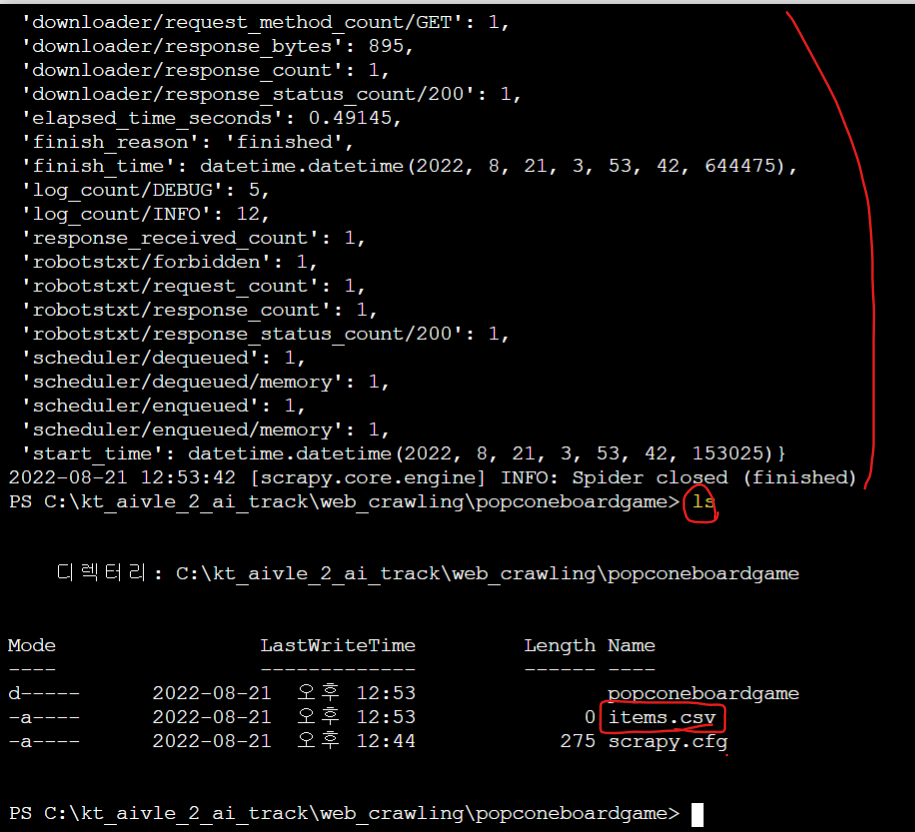
items.csv파일이 만들어진걸 확인할 수 있음
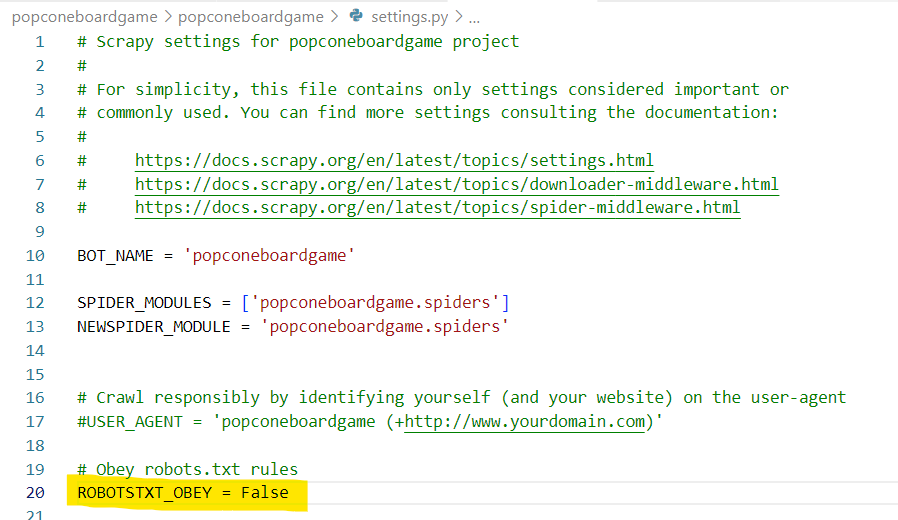
ROBOTSTXT_OBEY 설정
-
그러나,
items.csv이 비어있음. -
왜 아무것도 크롤링 되지 않았나 robots.txt를 살펴보니,

-
settings.py 에서 ROBOTSTXT_OBEY 를 False로 바꾸고 재시도
items.csv 파일이 만들어진걸 확인할 수 있음
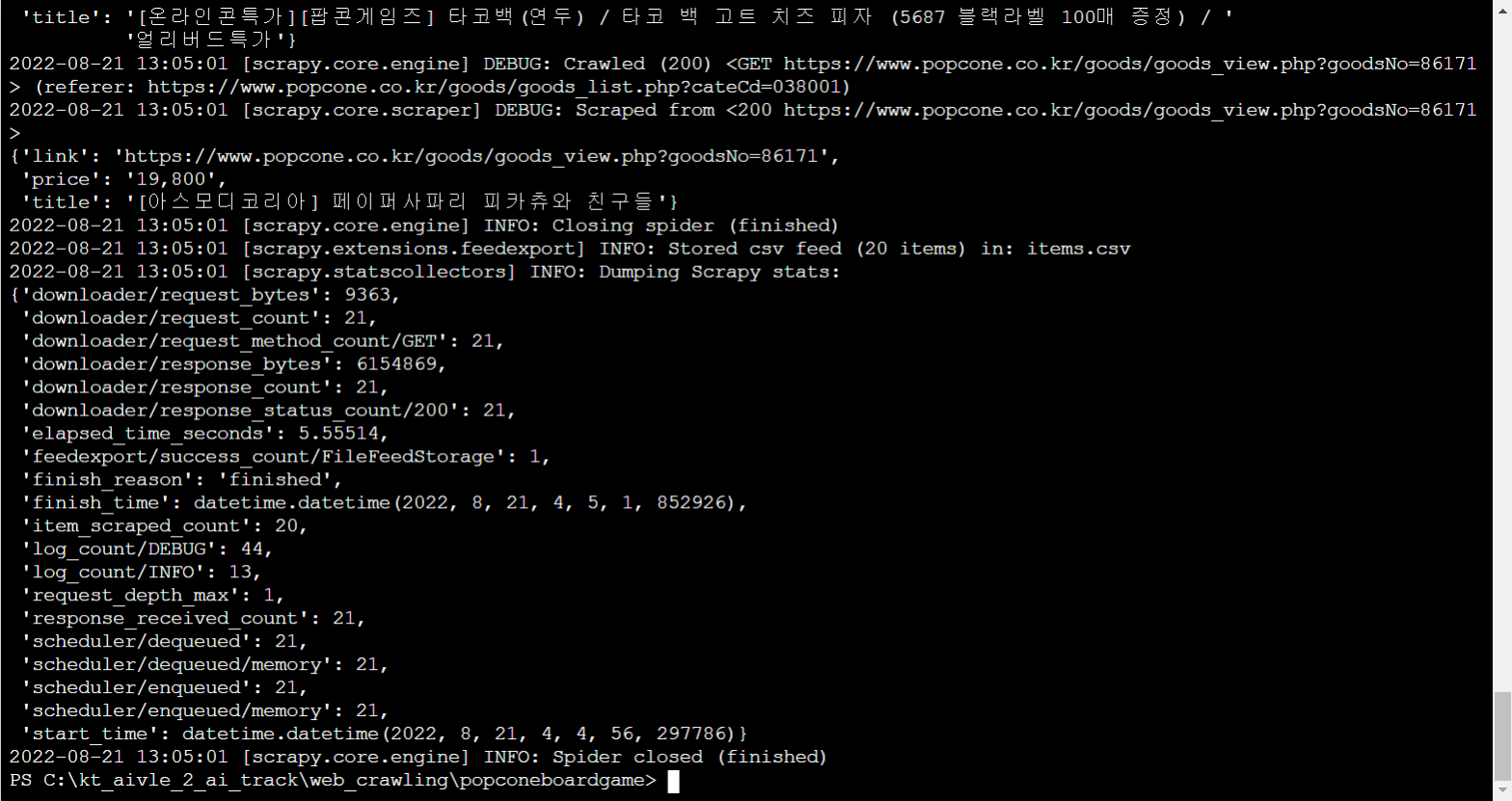
출력


내 인생의 주연