크롤링
1.Web 기초 정리

: 통합 자원 식별자출처: https://bakcoding.github.io/webpage/webpage001-uri/출처: https://medium.com/@lidiach217/web-기본개념-http-통신-cf5f89906c8e: client는
2.Web Crawling(웹 크롤링) 이란?
: robots.txt 파일에 크롤링 정책 설명User-agent: 어떤 client가 요청하는지(os는 뭐고, 버전은 몇이고, 크롬이고, 등등의 client의 정보)를 request 할때 server에 전달: 아 우리 서비스는 ios는 30프로, android는 10
3.Web Crawling(웹 크롤링)_동적 페이지_네이버 주식 (python)
: 여러 유사한 용어들이 존재crawling: 데이터 수집, 분류하는 작업scraping: 데이터 수집하는 작업spider or web crawler: 컴퓨터가 자동으로 데이터 수집bot: 자동으로 데이터 수집하는 소프트웨어정적페이지: 페이지의 데이터가 변경될 때, U
4.Web Crawling(웹 크롤링)_동적 페이지_네이버 데이터랩_검색어 시각화 (python)
: application programming interface서비스에서 데이터를 제공하는 공식적인 방법으로, api를 이용한다.api 이용 수집이 가능하다면, 이 방법을 사용하는게 더 좋다.네이버 디벨로퍼: https://developers.naver.com
5.Web Crawling(웹 크롤링)_동적 페이지_카카오 지도_주소로 좌표 찾기 (python)
: 절차 생략..ㅎ저어얼대 귀찮아서 아님..ㅎ
6.Web Crawling(웹 크롤링)_동적 페이지_직방 원룸 정보 (python)
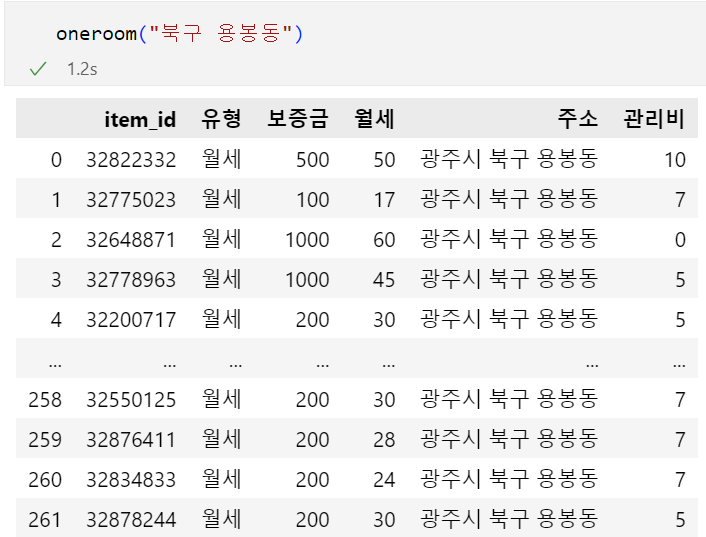
동 이름원룸의 위치원룸 매물 정보: '동 이름'을 넣으면 그 동의 원룸 정보를 추출하고 싶다. 3번의 request가 필요함만약, url이 깨져 보인다면..: 인코딩 되어있는걸 디코딩 해서 보여주는 사이트: https://meyerweb.com/eric/too
7.Web Crawling(웹 크롤링)_정적 페이지가 맞나_네이버 쇼핑 검색어 순위목록 (python)
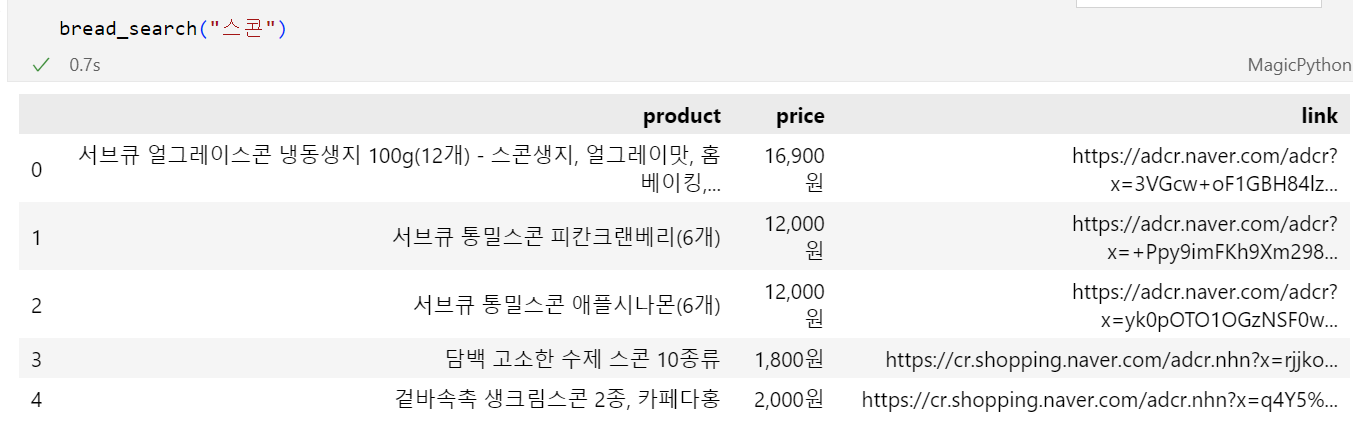
동적 페이지는 JSON형식(str)로 받으며, 이를 list나 dict로 변환하는게 쉬웠음.그러나 정적 페이지는 HTML 형식으로 받으며, 이를 list나 dict로 변환하는건 쉽지 않음.그래서, BeautifulSoup과 CSS Selector을 이용하여 html을
8.Web Crawling(웹 크롤링)_정적 페이지_11번가 베스트셀러 (python)
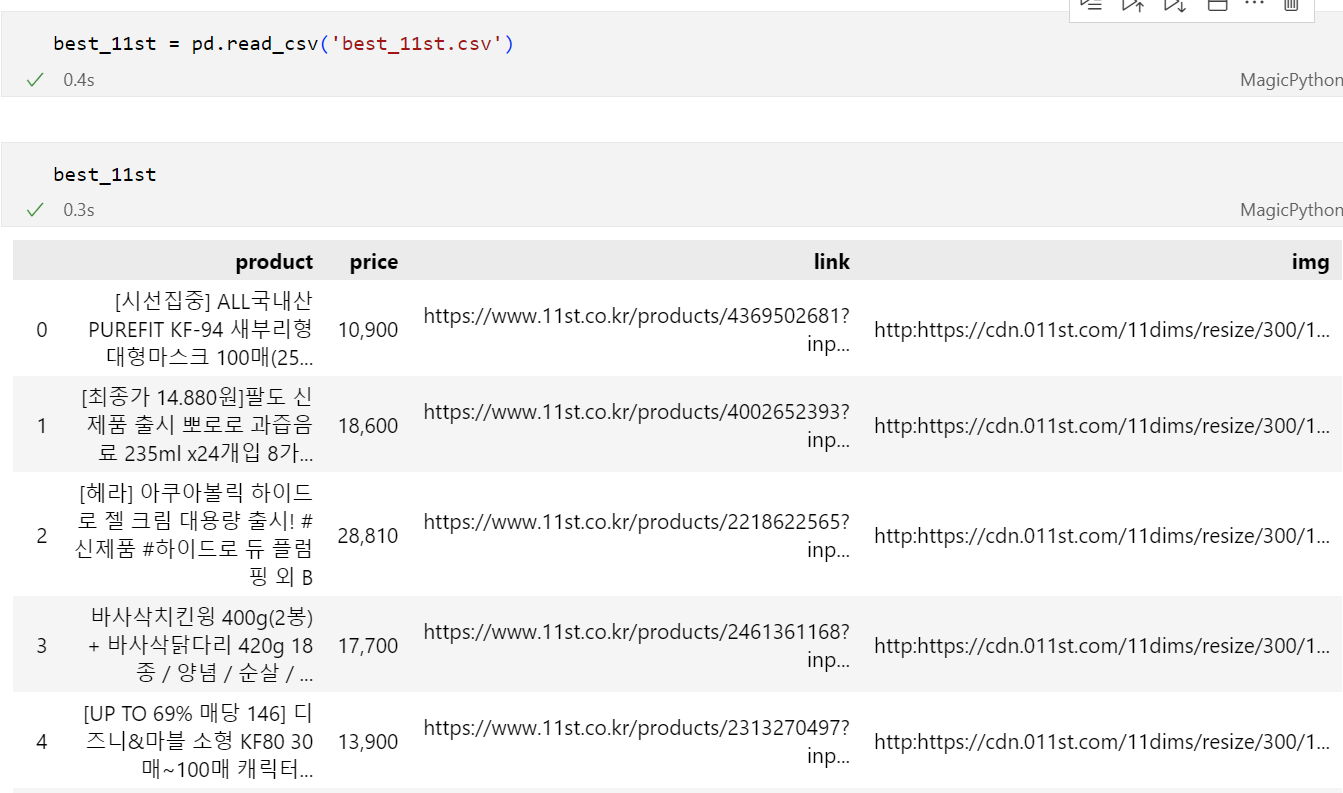
업로드중..
9.Web Crawling(웹 크롤링)_11번가 베스트셀러 이미지 (python)

os: 컴퓨터 파일 시스템을 다루는 패키지: 디렉토리 생성, 파일 삭제/복사/이동 등등디렉터리 존재 유무를 확인하는 코드: 여기에는 이미지 url이 들어있음(image link)서버로 이 이미지 url을 request 하면 이미지 파일을 response 받을 수 있음r
10.Web Crawling(웹 크롤링)_Selenium_인프런 강의목록 (python)
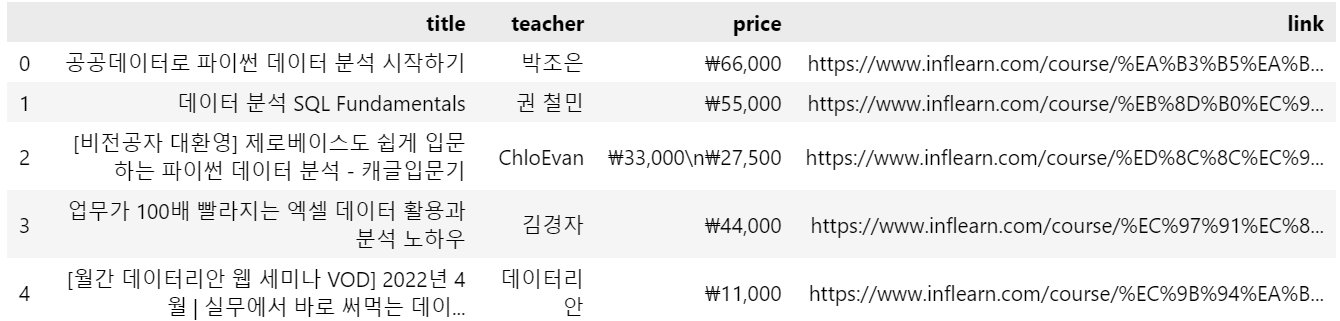
회사에서 어떤 코드를 만들었다면, 이를 바로 서비스할 수 없음.QA 팀을 통해서 테스트가 통과되어야 실제 서비스 되도록 올라갈 수 있음.근데.. 매번 모든 기능을 일일히 사용하기에는 번거로움.그래서! QA팀이 이 기능을 사용하는 것을 자동화 시켜주는게 selenium.
11.Web Crawling(웹 크롤링)_팝콘에듀 베스트 상품 리스트 (python)
os 시스템 명령어를 이용폴더 내부를 살펴보면..: 프레임워크는 빈칸채우기 같음! 출력해보면 틀이 다 있음이 파트는 xpath로 데이터를 가져오는걸 보여주기 위한것. 실제 크롤링에서는 1, 3, 4번만 수행xpath 찾은걸 스크래피 프로젝트에 적용할 것임 xpath를
12.Web Crawling(웹 크롤링)_Selenium_해커랭크 SQL 목록 (python)
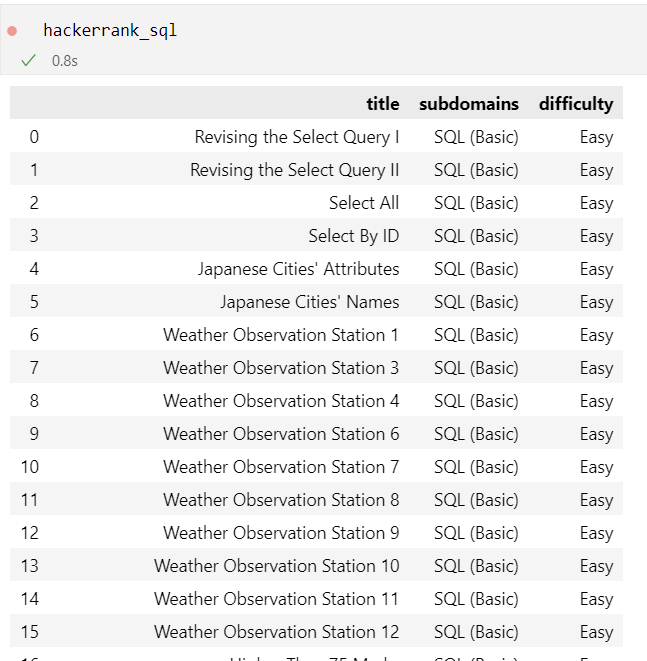
Selenium 절차 설치 실행 데이터프레임 수정 출력
13.Web Crawling(웹 크롤링)_이미지 to pdf: with open~ 사용
이걸 with을 사용하면 이렇게 간단하게!출처: 점프 투 파이썬