파이썬 문법 조각들..
zip
>>> numbers = [1, 2, 3]
>>> letters = ["A", "B", "C"]
...
>>> for pair in zip(numbers, letters):
... print(pair)
...
(1, 'A')
(2, 'B')
(3, 'C')>>> for number, upper, lower in zip("12345", "ABCDE", "abcde"):
... print(number, upper, lower)
...
1 A a
2 B b
3 C c
4 D d
5 E e#zip을 다시 풀고 싶을때
>>> numbers, letters = zip(*pairs)
...
>>> numbers
(1, 2, 3)
...
>>> letters
('A', 'B', 'C'): 병렬로 묶어준다!
map
>>> def two_times(x):
... return x*2
...
>>> list(map(two_times, [1, 2, 3, 4]))
[2, 4, 6, 8]: map(f, iterable)은 함수(f)와 반복 가능한(iterable) 자료형을 입력으로 받는다. map은 입력받은 자료형의 각 요소를 함수 f가 수행한 결과를 묶어서 돌려주는 함수이다.
>>> list(map(lambda a: a*2, [1, 2, 3, 4]))
[2, 4, 6, 8]: 람다로 표현.
map(int, input().split())
- input(): 입력값을 문자열로 인식
>>> A = a, b = input().split()
aa bb
... print(A)
['aa', 'bb'] #list 형식으로 나옴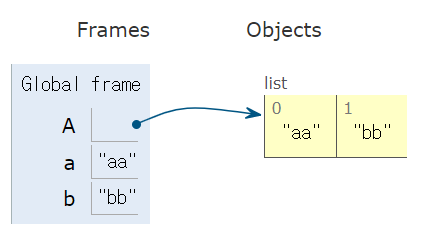
-> int를 이용해서 숫자로 인식해야함
-> 한번에 괄호로 int 하면 어떨까? 그런데..
>>> a, b = int(input().split())
>>> print(a + b)
TypeError: int() argument must be a string, a bytes-like object or a number, not 'list'
#list화 된 것을 int 하면 에러가 발생!-> map 함수를 사용하자!
>>> a, b = map(int, input().split())
1 3
#a, b에 input 입력
>>> print(a + b)
4
#출력index
: 리스트 매소드 중에서 index()는 리스트 중에서 특정한 원소가 몇 번째에 처음으로 등장했는지를 알려준다. 그런데 두 번 이상 원소가 중복되어 존재하는 경우에는 맨 처음 등장한 순간의 인덱스를 출력해준다는 점을 기억하자.
enumerate
: index와 원소를 모두 출력 가능
#in 다음을 enumerate로 감싸면, tuple 형태로 출력됨
>>> for entry in enumerate(['A', 'B', 'C']):
... print(entry)
...
(0, 'A')
(1, 'B')
(2, 'C')#tuple이 싫다? 그러면 index와 원소를 나눠서 for에 넣자
>>> for i, letter in enumerate(['A', 'B', 'C'], start=1):
... print(i, letter)
...
1 A
2 B
3 Cfor문, if문 한줄로 쓰기
list_a = []
for i in range(10):
list_a.append(i)
print(list_a)list_a = [i for i in range(10)]
print(list_a)continue
result = 0
for i in range(1, 10):
if i % 2 == 0:
continue
resulte += i
print(result)25: 1~9까지의 수 중에서 홀수만 더하고 싶을때
-> 짝수일 경우에는 continue로 반복문의 남은 코드를 넘기고, 홀수일 때만 반복문의 남은 코드 실행되도록 하자.
scores = [90, 85, 40, 95, 70]
cheating_list = {2, 4}
for i in range(5):
if i + 1 in cheating_list:
continue
if scores[i] >= 80:
print(i + 1, "번 학생은 합격입니다.")1 번 학생은 합격입니다: if i + 1 in cheating_list를 하는 이유: list의 원소는 0부터 시작하기 때문.
치팅한 학생들만 continue 해서 그 다음 반복문 내용은 넘어가도록 하고, 치팅 안한 학생들만 출력되도록 함.
- 출처: 이것이 취업을 위한 코딩 테스트다
break
i = 1
while True:
print("현재 i의 값:", i)
if i == 5:
break
i += 1현재 i의 값: 1
현재 i의 값: 2
현재 i의 값: 3
현재 i의 값: 4
현재 i의 값: 5: while에 True를 넣어서 항상 실행되도록 함.
print 하고.. 만약 i==5가 되면 반복문을 즉시 탈출하도록 함. i<5일때는 그 아래 i += 1을 실행하고 다시 while 문 반복
- 출처: 이것이 취업을 위한 코딩 테스트다
패킹 언패킹
def operator(a, b):
add = a + b
sub = a - b
mul = a * b
div = round(a / b, 1) #소수점 1번째 자리까지 반올림
return add, sub, mul, div #패킹
a, b, c, d = operator(7, 3) #언패킹
print(a, b, c, d)10 4 21 2.3: return 값에 여러개 가능. 그리고 이걸 다시 함수로 언패킹.
def operator(a, b):
add = a + b
sub = a - b
mul = a * b
div = round(a / b, 1) #소수점 1번째 자리까지 반올림
return print(add, sub, mul, div) #바로 print 씌움
operator(7, 3)10 4 21 2.3: 바로 print 씌워서 operator에 a, b값 넣어서 바로 출력되도록 함
lambda
: 함수를 한줄로! 간단하게!
: 이름 없는 함수 라고도 불림
def add(a, b):
return a + b
print(add(3, 7))
#이걸 lambda로 표현하면?!
print(lambda a, b: a + b)(3, 7))10
10또 다른 예:
array = [('홍길동', 50), ('이순신', 32), ('아무개', 74)]
def my_key(x):
return x[1] #array의 각 원소(튜플)의 두번째 원소를 출력
print(sorted(array, key = my_key))
print(sorted(array, key = lambda x: x[1]))
#sorted 함수에서 정렬 기준으로 key 값 넣기 가능[('이순신', 32), ('홍길동', 50), ('아무개', 74)]
[('이순신', 32), ('홍길동', 50), ('아무개', 74)]또 다른 예: 여러 개의 리스트에 적용
list1 = [1, 2, 3, 4, 5]
list2 = [6, 7, 8, 9, 10]
result = map(lambda a, b: a + b, list1, list2)
print(list(result))[7, 9, 11, 13, 15]- 출처: 이것이 취업을 위한 코딩 테스트다
위 lambda를 def 문으로 다시 작성해보면..
def list_add(a, b):
result = [0] * len(a) #a 길이만큼 list 생성
for i in range(len(a)):
result[i] = a[i] + b[i]
return print(result)
list_add(list1, list2)dictionary 정렬 출력
aaa = {'a': 10, 'b': 5, 'c': 1}
aaa_sorted = sorted(aaa, key = aaa.get)
print(*aaa_sorted)
#출력
c b a: value를 기준으로 정렬하여 key 값만 출력하고자 할 때!
이때 *를 써주면, unpacking 되어 출력된다.
deque
from collections import deque
a = deque()
a.append(1) #맨 오른쪽에 원소 덧붙이기
a.append(2)
a.append(3)
a.appendleft(0) #맨 왼쪽에 원소 덧붙이기
a.pop() #맨 오른쪽 원소 출력
a.popleft() #맨 왼쪽 원소 출력
b = list(a) #deque 상태인 a를 list로 만들기
print(a)
print(b)deque([1, 2])
[1, 2]재귀함수
def a(i):
if i == 5:
return
print(i, '번째 재귀함수에서', i + 1, '번째 재귀함수를 호출합니다.')
a(i + 1)
print(i, '번째 재귀함수를 종료합니다.')
a(1)i == 5가 될때까지
print(i, '번째 재귀함수에서', i + 1, '번째 재귀함수를 호출합니다.')를 출력하고
a(i + 1)을 호출한다.
i == 5가 되면, 종료.
그리고 자기 자신을 호출했던 함수로 돌아간다. 두번째 print 문을 만나서 출력하고, 또 자기 자신을 호출했던 함수로 돌아가서 두번째 print문 출력하고..반복.
그 결과:
1 번째 재귀함수에서 2 번째 재귀함수를 호출합니다.
2 번째 재귀함수에서 3 번째 재귀함수를 호출합니다.
3 번째 재귀함수에서 4 번째 재귀함수를 호출합니다.
4 번째 재귀함수에서 5 번째 재귀함수를 호출합니다.
4 번째 재귀함수를 종료합니다.
3 번째 재귀함수를 종료합니다.
2 번째 재귀함수를 종료합니다.
1 번째 재귀함수를 종료합니다.- 출처: 이것이 취업을 위한 코딩 테스트다
DFS
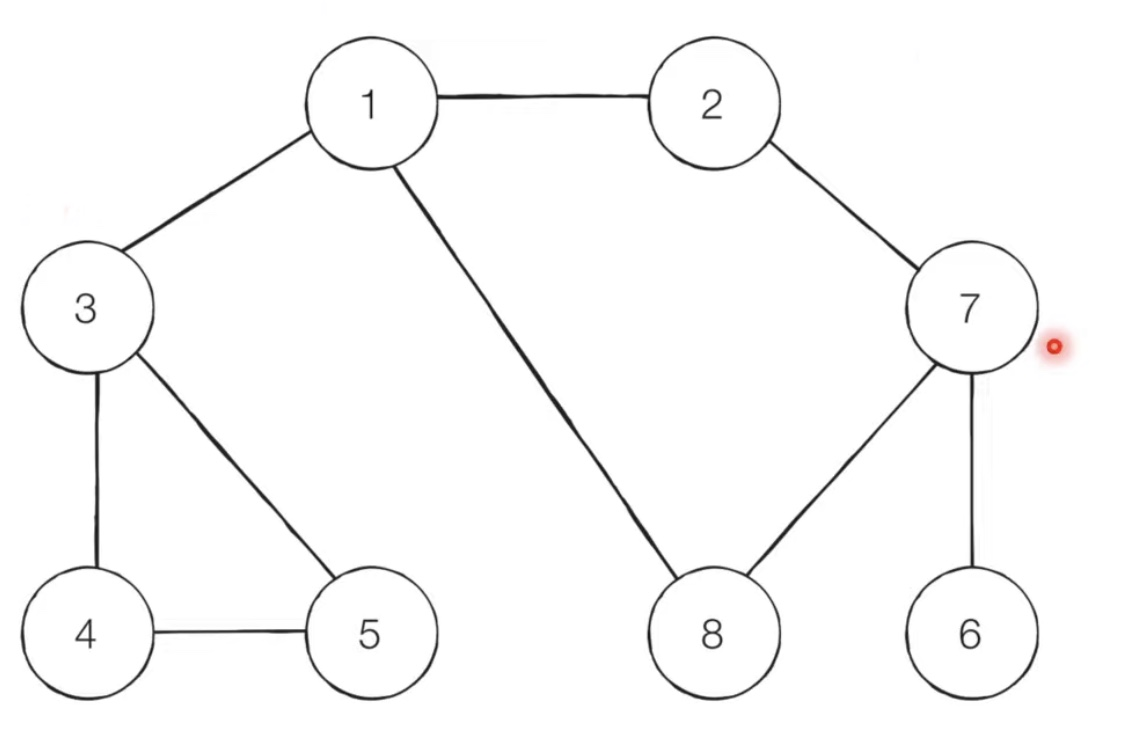
#각 노드가 연결된 정보를 표현 (2차원 리스트)
grapg = [
[],
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]
#각 노드가 방문된 정보를 표현 (1차원 리스트)
visited = [False] * 9
#DFS 메서드 정의
def dfs(graph, v, visited):
#현재 노트를 방문 처리
visited[v] = True
print(v, end=' ')
#현재 노드와 연결된 다른 노드를 재귀적으로 방문
if i in graph[v]:
if not visited[i]:
dfs(graph, i, visited)
#정의된 DFS 함수 호출
dfs(graph, 1, visited)1 2 7 6 8 3 4 5: 6까지 출력한 이후, 더 방문할 곳이 없으니까 6을 호출했던 7로 거슬러 올라감.
8 출력하고, 또 방문할 곳이 없으니까 7로 거슬러 올라감.
7에서 또 방문할 곳이 없으니 7을 호출했던 2로 거슬러 올라감.
반복..
- 출처: 이것이 취업을 위한 코딩 테스트다
datetime
import datetime
print(str(datetime.datetime.now())[:10]): 백준 10699번.
오늘 날짜 출력하기
YYYY-MM-DD로 출력하려면, 총 10자리까지 끊어서 출력해야함. 그래서 [:10] 작성.
abs 절대값
print(abs(3-5))2빠른 입력: sys.stdin.readline()
import sys
n = int(sys.stdin.readline())
for _ in range(n):
a, b = map(int, sys.stdin.readline().split())
print(a + b)- 좀 간단히 하려면..
import sys
input = sys.stdin.readline
n = int(input())
for _ in range(n):
a, b = map(int, input().split())
print(a + b)-
input 대신 sys.stdin.readline을 사용할 수 있다. 단, 이때는 맨 끝의 개행문자까지 같이 입력받기 때문에 문자열을 저장하고 싶을 경우 .rstrip()을 추가로 해 주는 것이 좋다.
-
rstrip을 하라는 건 문자열 자체를 변수에 저장하고 싶을 때 얘기지, 개행문자가 맨 끝에 들어와도 int 변환이나 split()을 그대로 할 수 있습니다. 즉 int(sys.stdin.readline()), sys.stdin.readline().split() 이렇게 해도 아무 문제 없습니다. 참고로 이름이 꽤 길기 때문에 저는 input = sys.stdin.readline을 맨 처음에 함으로써 쓰는 편입니다.
try-except 구문
while True:
try:
a, b = map(int, input().split())
except:
break
print(a + b): try 구문을 실행하는데, 이때 에러가 난다면 except 구문을 실행함.
: 이를 활용하여 try-except-else-finally로 가능.
- else: except 구문을 실행하지 않았을 경우 실행되는 구문
- finally: try 구문에서 예외의 발생 여부에 관계없이 항상 실행되는 절
swapcase
a = input()
print(a.swapcase()): 대문자는 소문자로, 소문자는 대문자로 바꾸기
입력 그대로 출력하기
while True:
try:
print(input())
#End of File(입력이 끝남) 에러
except EOFError:
break: 여러줄이 주어지는 입력일때, 입력한 그대로 출력하고 싶으면?!
asterisk(*)
- 곱하기, 제곱
- 위치 인자, 키워드 인자
- 가변인자?
- 리스트나 튜플 언패킹
위치 인자, 키워드 인자
-> 설명이 조금 헷갈림. 적어놓은것 뒤엎자! 이해되면 다시 작성하자!
-
positional arguments(위치 인자)
: 값이 없는 경우 error 발생
: *가 앞에 붙은 인자
: 인자 중 처음에 나오거나, *붙은것 -
keyword arguments: default 값으로 None 값을 줌
: 함수 호출 때 식별자가 앞에 붙은 인자 또는 **가 앞에 붙은 딕셔너리 전달되는 인자
num = [1, 2, 3, 4]
def fun(*arg):
return arg
print(fun(num))
>> ([1, 2, 3, 4]) #인자 1개
print(fun(*num))
>> (1, 2, 3, 4) #리스트가 언패킹 되어 4개의 숫자로 출력
print(fun(*[1, 2, 3, 4))
>> (1, 2, 3, 4)'구분자'.join(리스트)
: 문자열 합치기
abc = ['a', 'b', '1', '2', '3']
#join 이용
result1 = '_'.join(abc)
print(result1)
# for문 이용
result2 = ''
for i in abc:
result2 += i
print(result2)#출력
a_b_1_2_3
ab123- 만약, 리스트 원소들이 문자열이 아니라면?
num = [1, 2, 3]
print('_'.join(str(_) for _ in num))
#출력
1_2_3str(list)
a = [1, 2, 3, 4, 5]
print(str(a))
print('<' + str(a)[1:-1] + '>')
#출력
[1, 2, 3, 4, 5]
<1, 2, 3, 4, 5>: list를 바로 str 할 수 있다! 그러나 이때는 리스트 기호인 [] 대괄호도 같이 출력되므로, 대괄호는 없애고 싶다면 [1:-1] 해야한다~!
2차원 list를 1차원으로: sum(list, [])
# 입력
arr = [[[1, 2, 3], [4, 5, 6]], [['a', 'b', 'c'], ['d', 'e', 'f'], ['g','h', 'i']]]
result_1 = sum(arr)
result_2 = sum(arr, []))
result_3 = sum(arr[1], [])
print(result_1)
print(result_2, result_3, sep = '\n')
# 출력
# 1.
TypeError: unsupported operand type(s) for +: 'int' and 'list'
# 2. 3중 list가 2중 list가 됨
[[1, 2, 3], [4, 5, 6], ['a', 'b', 'c'], ['d', 'e', 'f'], ['g', 'h', 'i']]
# 3. arr[1]을 1차원 list로 만듦.
['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i']sum(list, []): list의 []를 하나 벗겨냄!
얕은 복사, 깊은 복사
- 깊은 복사:
: 그냥b = a를 해버리면, 얕은 복사가 되어버리고 만다.-
얕은 복사란? 주소값이 동일! 그래서 만약 list를 복사할 경우, 복사본을 수정하면 Mutable한 list의 특성때문에 원본도 수정되어 버린다.
-
깊은 복사란? https://crackerjacks.tistory.com/14
: deepcopy가 가장 느리지만.. 가장 편리한것 같기도 하고? 몇몇 깊은 복사들은 list 내부 사정에 따라 얕은 복사가 되어버리기도 함. 그냥 for문 쓰는게 편한 것 같기도 하고..?
-
슬라이싱을 활용하자
- 1차원 list: [:]
- 2차원 list:
# list일 때
new_list_arr= [x[:] for x in list_arr]
# numpy ndarray일 때
new_np_arr = np.array(list(x[:] for x in np_arr))for i in list(a) 주의사항!
# 입력
alpha_num = ['1', '2', '3', 'a', 'b', 'c']
num = '0123456789'
for i in alpha_num:
if i in num:
print(i, end = ' ')
alpha_num.remove(i)
else:
print(alpha_num)
break
# 출력
1 3 ['2', 'a', 'b', 'c']: 출력에서 보다시피.. 분명 숫자는 1 2 3 인데도 불구하고, 1 다음에 3으로 건너갔다.
그 이유는..
i는 index = 0에서 index = 1로 전진하는데, 1이 remove 됨으로써 2가 index 0이 되고 3이 index 1이 되었기 때문이다!
i = 1 -> alpha_num = ['2', '3', 'a', 'b', 'c'] 남음
2차원 list의 특정 위치 원소들 합 구하기
arr = [[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 1, 1, 15], [16, 17, 1, 1, 20]]
n = 2
# 1. map 사용해서 lambda로 지정된 행의 특정 원소들을 꺼낸 다음,
# 그 원소들을 map 사용해서 각각 sum하고, 이를 list로 만듦
print(list(map(sum, list(map(lambda x: x[n:2 * n], arr[n:2 * n])))))
# 2. map 사용해서 lambda로 지정된 행의 특정 원소들을 꺼낸 다음,
# 그 원소들을 map 사용해서 각각 sum하고, 이를 다시 sum함
print(sum(map(sum, (map(lambda x: x[n:2 * n], arr[n:2 * n])))))
# 3. map 사용해서 lambda로 지정된 행의 특정 원소들을 꺼낸 다음,
# 이를 sum으로 1차원 list로 만들고, 이를 sum함
print(sum(sum(map(lambda x: x[n:2 * n], arr[n:2 * n]), [])))
# 출력
[2, 2]
4
4: 특정 행(같은 위치의 행)만 가능한거 같음.
서로 다른 행의 서로 다른 열의 원소들을 더하는건 아직 잘 모르겠네..?
list slicing
a = [] # 빈 list 일 때
# 1. 그냥 index로는 비교 불가(empty array일 때 indexing error)
if a[-1] == i: # 불가능
# 2. slicing으로는 비교 가능(list를 slicing 하여 가져오니까)
if a[-1:] == [i]: # 가능if문에서 or, and 잘 써보자(특히 여러개일때)
a = [3,4,5]
if (3 and 5) in a:
print(1) # 출력 1
if 1 in a or 2 in a or (3 in a and 5 in a):
print(2) # 출력 2 -> 왜?
if (1 or 2 or (3 and 5)) in a:
print(3) # 출력 안됨
if (1 or 2 or (3 or 5)) in a:
print(4) # 출력 안됨
or는 bool 타입 연산자이지, 비교 연산자가 아니다.
if (month == 1 or 3 or 5)
# month(숫자)가 1(숫자) 또는 3(숫자) 또는 5(숫자)와 같은가?
if (month == 1 or month == 3 or month == 5
# month의 값이 1 또는 3 또는 5인가?