데이터 다루기
1.Feature engineering

: 도메인 지식을 이용해 원자료를 가공하여 특징을 추출하는 작업: 분석을 위해서는 먼저 데이터를 전처리 해야한다.NaN(Not a number) 혹은 NA(Not available)df.isnull().sum() 혹은 df.isna().sum(): 각 열마다 NaN이
2.문법 조각 (python)
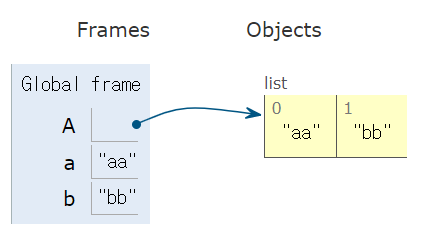
: 병렬로 묶어준다!출처: https://www.daleseo.com/python-zip/
3.for문과 while문 (python)
문자열을 입력하여 첫글자와 마지막 글자를 붙여서 출력하고자 할 때. 단, 각 문자열마다 엔터1) while문2) for문
4.재귀함수 (python)
팩토리얼(1\. 재귀함수 이용1)2)for문 이용while문 이용
5.입력, 문자열/행렬 뒤집기 (python)
: N x M 행렬을 바로 입력하기: 입력이 1 2 3 이런식으로 띄어쓰기가 있을 때: 입력이 123 이런식으로 띄어쓰기 없을 때a_lista:b:c: a부터 b까지 c 간격으로.행렬을 90도 회전하고 싶으면: result_4 = list(map(list, zip(\*
6.시간 복잡도를 줄여보자! (python)
https://towardsdatascience.com/10-techniques-to-speed-up-python-runtime-95e213e925dc
7.클래스, 모듈, 패키지, 라이브러리 (python) (작성중)
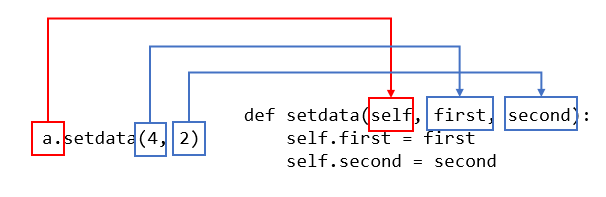
출처: 점프 투 파이썬
8.Numpy 정리
데이터 분석시에는 대용량 데이터를 처리하곤 하는데, 이때 list는 느리다!배열을 효과적으로 관리하고 싶다.so, Numerical Python!불러오자주의할 점: 축은 0부터 시작한다는거~!
9.Pandas 정리
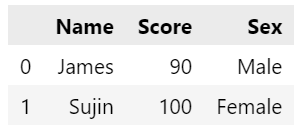
: DataFrame을 사용하기 위해서!: 데이터프레임에서 하나의 열을 떼어낸 형태로, 1차원 구조: 하나의 정보에 대한 데이터들의 집합pd.DataFrame: 데이터프레임 만들기pd.read_csv()df.shape: np.shape과 기능이 같을 뿐, 같은 함수는
10.Matplotlib 정리
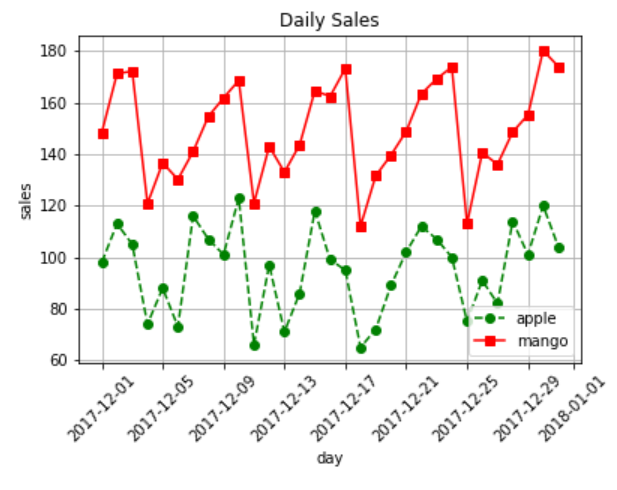
출처: : 파이썬에서 그래프를 그릴때 유용한 시각화 라이브러리plt.plot()plt.plot('date', 'item1', data = my_data): 옵션 이름 = 내 데이터프레임 명. 권장사항plt.plot(my_data'date', my_data'item1')
11.Seaborn 정리
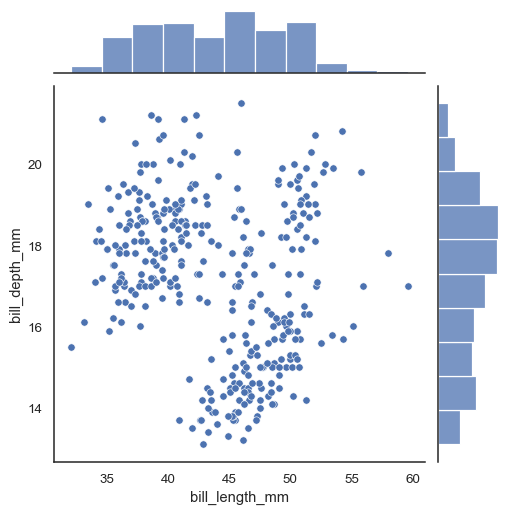
sns.kdeplot(데이터명\['열 이름'])커널 밀도 추정(Kernel Density Estimation) 그래프흐름을 볼 수 있지만, 세밀한 조정이 불가능하다sns.distplot(데이터명\['열 이름'], hist = True, bins = 16): 히스토그램과
12.Scipy 정리
: 고급 수학 함수, 수치적 미적분, 미분 방정식 계산, 최적화, 신호 처리 등에 사용하는 다양한 과학 기술 계산 기능을 제공spst.pearsonr(데이터\['열1 이름'], 데이터\['열2 이름']): (상관계수, p-value) 순서로 출력됨
13.statsmodels 정리
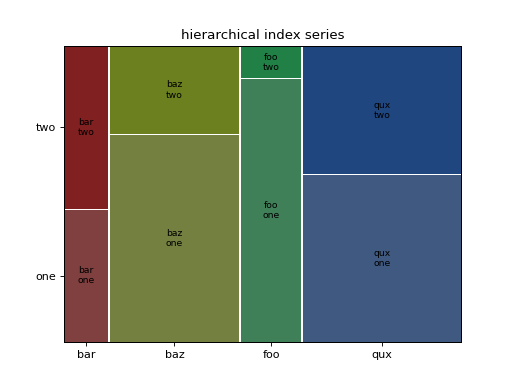
: 기존에 R에서 가능했던 다양한 회귀분석과 시계열분석 방법론을 그대로 파이썬에서 이용할 수 있다. https://www.statsmodels.org/stable/api.htmlmosaic(data명, \['열이름1', '열이름2']: 범주별 양과 비율을 그래
14.Linear Regression 정리
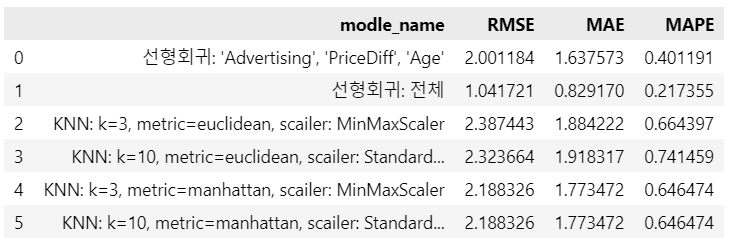
데이터 분할: x, y 나누기데이터 분할: train, validation, test set로 나누기여기서는 이미 test set이 나누어져 있다고 가정함변수 지정예측평가KNN
15.데이터 모델링 전까지, 어떤 순서로 이루어질까?
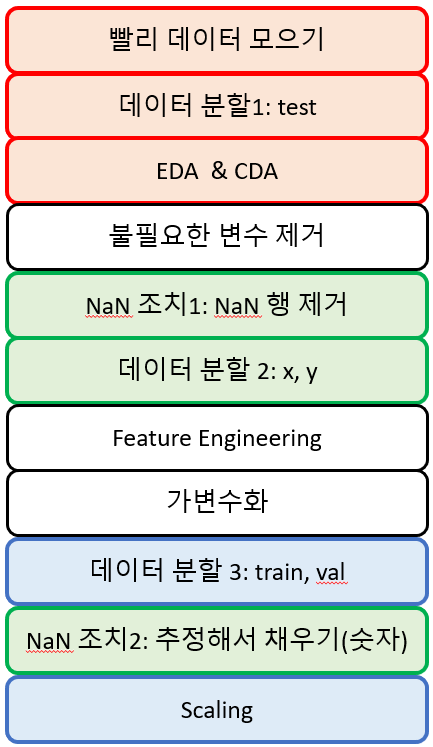
각 색깔별로는 절대로 바뀌어서는 안되는 고정된 순서이다. 그 사이에 다른 것이 끼어들 수는 있지만, 색깔안에서의 순서는 고정!EDA, CDA는 test를 떼어낸 train과 val 세트로 진행한다.불필요한 변수 제거: 만약 feature engineering으로 날짜요
16.KNN(K-Nearest Neighbors) 정리
"가까운 이웃에게 물어봐"회귀로도, 분류로도 사용 가능거리를 계싼하여 가장 가까운 k개 이웃의 y값들의 평균으로 예측흔다결측치 조치, 가변수화, 스케일링하이퍼파라미터에 의해 성능이 달라진다.k값: 클수록 단순(최대치가 되면 평균 모델이 되니까), 작을수록 복잡거리계산법
17.Logistic Regression 정리
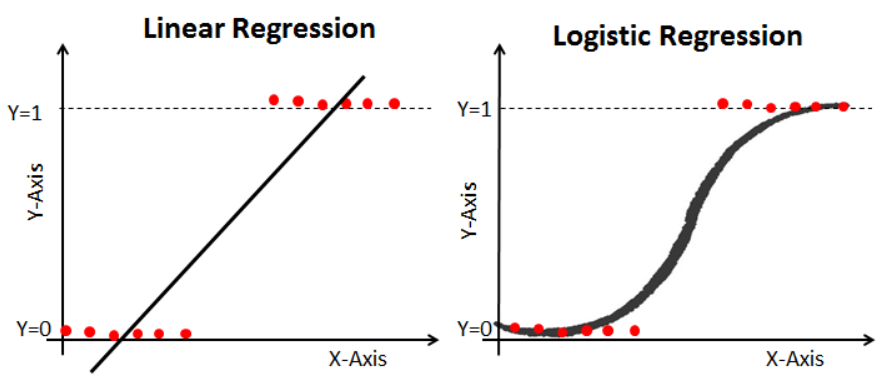
이진분류만 OK데이터 분할: x, y 나누기NaN 조치가변수화데이터 분할: train, validation 나누기Scaling
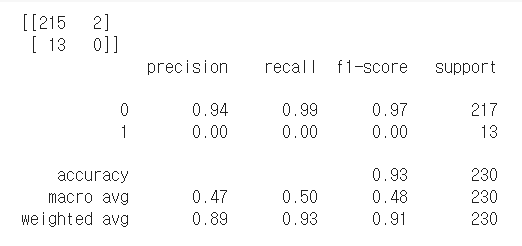
18.Classification(분류) 모델 평가하기
전체 중에서 올바르게 예측한 수실제 True 중에서 True로 예측한 비율True로 예측한 것 중에서 실제 True의 비율따라서, 뭐가 더 중요하고 더 쓸모있는지는 해봐야 안다!한눈에 쫘악특히 살펴볼 것: precision, recall, f1-score, accura
19.회귀 모델의 평가
관습적으로 $RMSE$를 많이 봄. 그러나 다 보자!: 평균 모델의 오차와 회귀 모델의 오차를 비교$R^2 = \\displaystyle \\frac{SSR}{SST} = 1 - \\frac {SSE}{SST}$$R^2$ (결정계수, 모델의 설명력)평균 모델의 오차 대
20.Decision Tree(의사결정나무) 정리
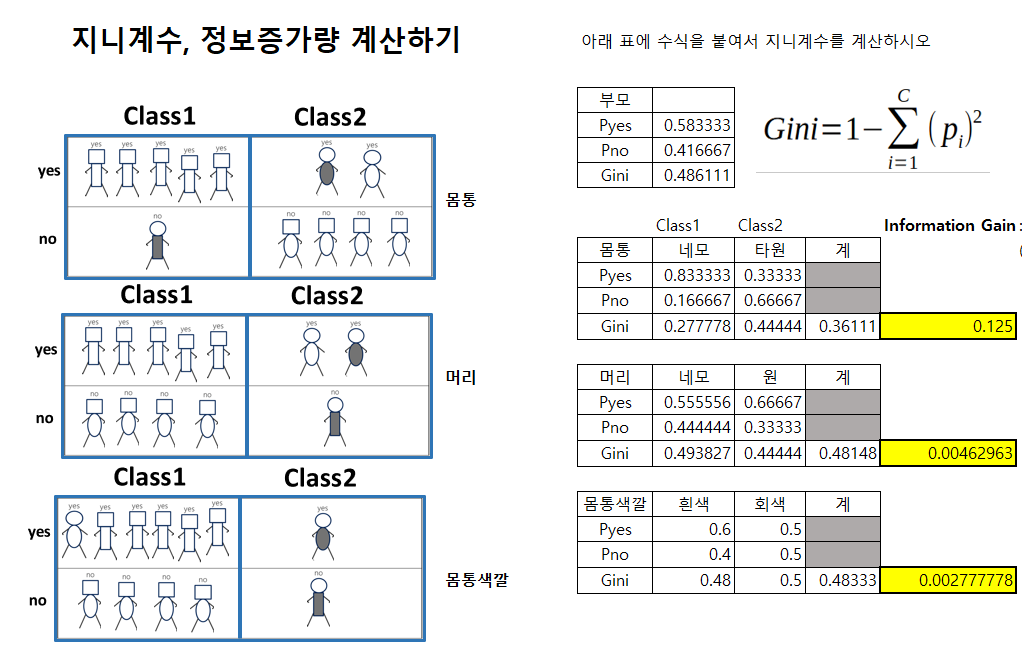
에이블 교육 정리정보 증가량이 가장 큰 변수를 기준으로 split 하기를 반복한다NaN 조치, 가변수화max_depth가 클수록, min_samples_leaf가 작을수록 모델이 복잡하다범위: 0~0.5$Gini = 1- \\displaystyle \\sum\_{i=1
21.SVM(Support Vector Machine) 정리
마진을 가장 넓게하는 결정겅계를 찾자.NaN 조치, 가변수화, 스케일링(거리를 재기 때문에)C가 클수록, gamma가 클수록 모델이 복잡하다.어떻게 하면 두 class 사이에 가장 넓은(즉, 마진이 가장 큰) 도로를 낼 것인가?두 class를 구분하는 경계선두 clas
22.모델의 성능 향상(작성중)
얼마나 정답에서 떨어져 있느냐얼마나 흩어져있느냐우선 train과 test set로 나누고train 데이터를 k등분 한다각각모델의 성능 향상 2. 데이터 늘리기
23.결측치 처리
행 삭제열 삭제평균값, 최빈값, 중앙값, 등앞, 뒤, 앞뒤 평균출처: https://scikit-learn.org/stable/modules/generated/sklearn.impute.KNNImputer.html가변수화가 선행되어야 한다.KNNImputer를
24.XGBoost, LGBM, Catboost
https://jhkim0759.tistory.com/12https://statinknu.tistory.com/33캣부스트 짱
25.AI 모델 해석 및 평가
permutation feature importance1-1. 트리 기반 모델의 변수 중요도는 음수값이 나오지 않지만, pfi를 이용한 변수 중요도는 음수값도 나옵니다. 이에 음수값이 도출된 변수는 제거했을 때 성능이 올라가리라 생각되어, svm에서 변수중요도가 음수값
26.feature_importance vs Permutation importance
디시전트리나 랜덤포레스트에 있는 feature_importance는 안쓰는게 좋습니다. 노이즈에 취약해요Permutation importance 쓰십시오
27.데이터 프레임 다루기
분리하고, column 명 지정하고, concat 하고, 원래 열은 삭제출처: https://doitgrow.com/40
28.[SQLD] 1과목_데이터 모델링의 이해_개념 정리
5) 분산 데이터베이스와 성능
29.원핫인코더
encoder = OneHotEncoder()encoder.fit(train\['type'])onehot = encoder.transform(train\['type'])onehot = onehot.toarray()onehot = pd.DataFrame(onehot)on
30.데이터 읽고 저장하기
출처: pandas.read_csvnrows: n번째 row까지 불러오기(index가 아니라 행 개수로 따졌을 때)index_col: column을 index로 지정. False. default Nonesep: 구분자. default ','header: column으
31.데이터 살펴보기 1: 그래프 없이
라이브러리 불러오기 경고메시지 감추기 공통 index, values 확인 데이터프레임 살펴보기 데이터 부분 읽어들이기 수치형 데이터 범주형 데이터
32.데이터 살펴보기 2: 그래프
matplot과 seaborn의 정리는 별도로 작성할 예정이고, 이 글에서는 간단한 애들만 작성matplot과 seaborn의 정리는 이쪽으로 <- 아직 글 안 씀~ㅠ
33.데이터 전처리
inplace: 원본 대체. default Falseaxis: 0: row, 1: columncolumns: str, 혹은 list 안에 str들을 넣기. 이러면 axis=1 로 한것과 같음. ex. '열1', '열2'먼저 info나 dtype으로 확인하고, head나
34.머신러닝
여기서는 머신러닝 극히 일부만, 간단하게.자세한거는 별도로 글 써야지로지스틱 회귀를 예로 들면
35.딥러닝
여기서는 딥러닝 극히 일부만, 간단하게.자세한거는 별도로 글 써야지