- 출처
- 핸즈온 머신러닝2
- 핸즈온 머신러닝2 github
- 핸즈온 머신러닝2 8장 pdf
- 핸즈온 머신러닝2 8장 강의
- 되도록이면 책의 내용과 코드를 그대로 옮기기 보다는 요약과 보충설명!
읽기전에
개념 정리
외삽이란?
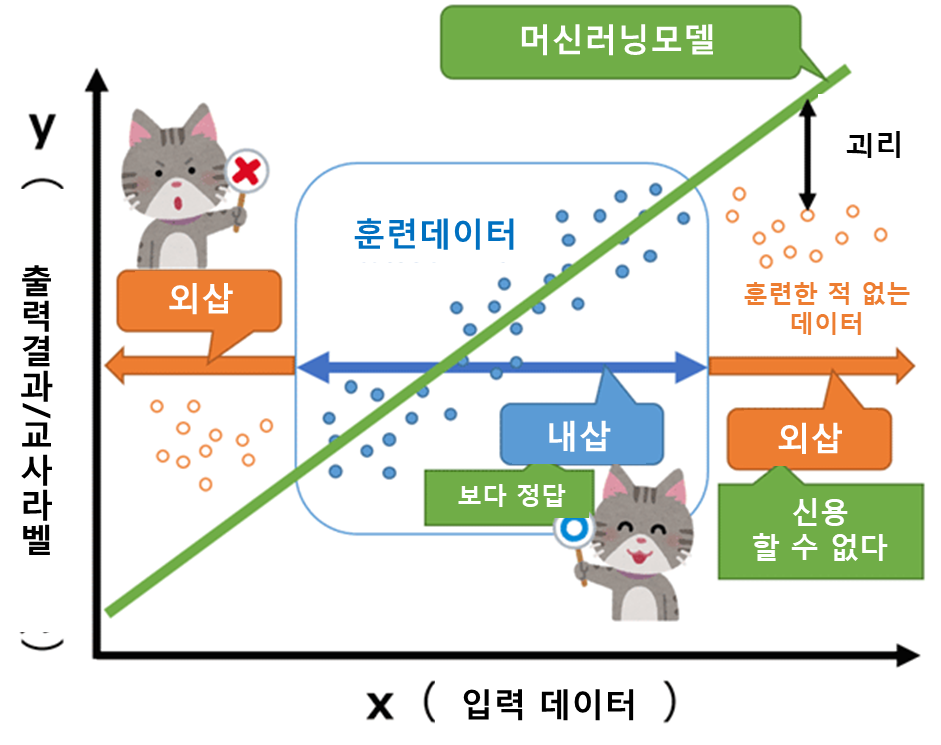
- 내삽(interpolation)
- 주위에 데이터가 많을 때, 결과값을 예측하는 것
- 어떤 데이터를 사용하여 훈련한 기계 학습 모델의 출력 결과가 그 훈련 데이터(입력 데이터 및 교사 라벨)의 수치 범위 내에 있는 것.
- 외삽(extrapolation)
- 대부분의 데이터와 동떨어진 점에서 결과값을 예측하는 것
- 훈련 데이터 범위 밖의 수치.
python 정리
8장 차원 축소
차원의 저주와 차원 축소
- 어마무시한 개수의 특성을 가진 훈련 샘플들로 인해서 훈련의 속도가 느려지고, 문제를 해결하기 어렵게 만든다.
- 이를 차원 축소로 훈련 속도를 높이거나, 데이터 시각화를 유용하게 할 수 있다.
고차원?
- 차원이 어마무시하게 많으면, 훈련 데이터가 서로 멀리 떨어져 있게 되고, 더 많은 외삽을 해야하며(더보기), 이는 곧 과대적합의 가능성을 커지게 한다.
차원 축소 접근 방법
1. 투영(projection)
- 예: 3차원 데이터에서, 사실 데이터들이 2차원 평면에 몰려있다면? 2차원으로 차원을 축소할 수 있다.
2. 매니폴드 학습(manifold learning)
- manifold
- 원본의 training DB의 데이터를 잘 표현하는 원본 공간에서의 subspace
- 고차원의 데이터를 공간상에 표현하면 각 데이터들은 점의 형태로 찍혀지는데, 이러한 점들을 잘 아우르는 subspace
- 출처: https://junstar92.tistory.com/157
- 예: 스위스 롤. 3차원 데이터가 마치 돌돌 말린 롤케이크 같다면, 이를 2차원에 축소 하면 데이터가 서로 겹치게 된다. 이를 쭉 펴주어야 한다.
- 다시 말하면, d차원 매니폴드는 국부적으로 d차원 초평면으로 보일 수 있는 n차원 공간의 일부이다.4
- 이때 스위스 롤은 d=2, n=3. 국부적으로는 2차원 평면으로 보이지만, 사실은 3차원으로 말려있기 때문이다.
- 매니폴드 가정: 고차원 데이터셋이 더 낮은 저차원 매니폴드에 가깝게 놓여 있다.
- 매니폴드 학습
- 많은 차원 축소 알고리즘이 훈련샘플이 놓여 있는 매니폴드를 모델링하는 식으로 작동
- 매니폴더를 잘 찾는 것
- 잘 찾은 매니폴드에서 projection시키면 데이터의 차원이 축소될 수 있다.
- 매니폴드 학습을 하면 훈련 속도는 더 빨라지지만, 항상 더 낫거나 간단한 솔루션이 되는건 아니다.
차원 축소 알고리즘
- 투영 기법 알고리즘
- PCA(주성분분석)
- 커널 PCA (비선형 사영)
- 매니폴드 학습 기법 알고리즘
- LLE(지역 선형 임베딩)
1. PCA(주성분 분석)
- 1) 축 선택
- 원본 데이터셋과 투영된 것 사이의 평균 제곱 거리를 최소화하는 축
- 다시 말하면, 분산이 최대로 보존되는 축을 선택
- 2) 주성분 추출
- 분산이 최대인 축을 찾고, 그 다음 남은 분산을 최대한으로 보존하는 축을 찾고, 그 다음...
- 이때, i번째 축을 i번째 주성분(PC)라고 부름
- 특잇값 분해(SVD)로 찾을 수 있음:
np.linalg.svd()함수
- 3) d차원으로 투영
- d번째 까지의 주성분을 이용하여 데이터셋을 d차원으로 투영하는 일은 행렬의 곱셈으로 바로 해결됨.
- 수직을 긋고, 수직을 긋고...
python 코드
- 사이킷런
pca() - 설명된 분산의 비율:
explained_variancd_ratio_ - 적절한 차원 수 선택
압축을 위한 PCA
- svm 과 같은 분류 알고리즘의 속도를 높일 것이다
- 압축한 pca 데이터셋을 다시 원래의 차원으로 되돌릴 수 있다
- 재구성 오차: 원본 데이터와 재구성된 데이터(압축 후 원복한 것) 사이의 평균 제곱 거리
inverse_transform()
랜덤 PCA
- 처음 d개의 주성분에 대한 근삿값을 빠르게 찾음
svd_solver = "randomized"
점진적 PCA
- SVD 알고리즘을 실행하기 위해 전체 훈련 세트를 메모리에 올려놓아야 하는 PCA 구현의 문제를 해결
- 미니배치로 나누어서 한번에 하나씩.
- 넘파이
array_split()
2. 커널 PCA (어렵다 이해해보자..)
- 5장의 커널 트릭에서, 고차원 공간으로 매핑해서 svm의 비선형 분류와 회귀를 가능케 한 것을 pca에 적용한 것.
- 즉 복잡한 비선영 투영이 가능
- 커널 PCA = 특성맵(으로 훈련 세트를 무한 차원의 특성 공간에 매핑) + PCA
- 비지도 학습
- 방식 1: 전처리 용도로 사용 후 예측기와 연동하는 그리드탐색 등을 활용하여 성능 측정 가능
- 방식 2: 가장 낮은 재구성 오차를 만드는 커널과 하이퍼파라미터 선택 가능
- 재구성 원상
- 우리는 차원 축소를 할건데, 이렇게 축소된 걸 다시 역전 시키면 원본 공간으로 갈까? 놉.. 특성 공간에 놓이게 됨. 즉 무한 차원에.
- 그럼, 원본 공간의 포인트를 찾을 수 없나..? 가능함. 재구성 원상!
- 어떻게? 지도 학습 회귀모델로! train: 투영된 샘플, target: 원본 샘플
fit_inverse_transform=True
3. LLE(지역 선형 임베딩)
- 비선형 차원 축소(NLDR) 기술의 하나
- 1) 가장 가까운 이웃에 얼마나 선형적으로 연관되어 있는지 측정
- 몇개의 이웃을 찾을지 정함:
k - 샘플을 고정하고 최적의 가중치를 찾음
- 몇개의 이웃을 찾을지 정함:
- 2) 국부적인 관계가 가장 잘 보존되는 훈련 세트의 저차원 표현 찾음.
- 1단계에서 가중치 행렬이 구해짐.
- 가중치를 고정하고 저차원 공간에서 샘플의 최적의 위치를 찾음
- 간단히 말하면.. 가장 가까운 샘플간의 거리가 잘 보존되는 저차원 공간을 찾는것.
- 2단계에서 계산 복잡도가 높아서, 데이터 수가 많으면 적용하기 어려움
기타 차원 축소 기법
랜덤 투영
다차원 스케일링(MDS)
lsomap
t-SNE
선형 판별 분석(LDA)
질문
- 왜 훈련 세트의 차원이 클수록 과대적합 위험이 커지나?
- 훈련 세트의 차원이 크면, 훈련 데이터들간의 거리가 멀다.
- 그러면 더 많은 외삽을 해야함.
- 따라서 과대적합 가능성이 커짐
- 투영과 매니폴드 학습의 차이점?
- 투영: 선형대수에서 등장하는 개념..! 한 벡터를 다른 벡터 위에 투영하면, 새로 생긴 벡터는 원래 벡터와 가장 가까운 벡터가 된다.
- 매니폴드 학습은 매니폴드를 찾고 여기서 투영 시키는 것.
- 이때 매니폴드란 원본 데이터 셋을 잘 설명하는 원본 공간에서의 부분 공간
- 랜덤 포레스트 vs pca
- 랜덤 포레스트는 다중공선성 문제를 해결 못하는데, pca는 다중공선성에 영향을 받지 않음. 그래서 pca를 하고 랜덤 포레스트로 변수 중요도를 보면 될듯?
- 293p. 그림 8-12. 왜 이런 모양이 나타났을까?
- 수학적인..식에..의해..ㅎ..

내 인생의 주연