# Set a batch size and epoch before training.
batch_size, epochs = 32, 10
# load train and test dataset from CIFAR-10
train_dataset = datasets.CIFAR10(root='../data/CIFAR10',
train=True, download=True, transform = transforms.ToTensor())
test_dataset = datasets.CIFAR10(root="../data/CIFAR10", train=False, transform=transforms.ToTensor())- dataset 다운로드
# divide by a batch size
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
# show first mini batch from train data
for (X_train, y_train) in train_loader:
print('X_train: ', X_train.size(), 'type: ', X_train.type())
print('y_train: ', y_train.size(), 'type: ', y_train.type())
break
# We can see sizes of samples
# channel: 3(R, G, B) / image: 32x32- x_train: torch.Size([32, 3, 32, 32]) -> [batch_size, channel, height, width]
- y_train: torch.Size([32]) -> [bathc_size]
- image: 32 * 32 / channel: 3 (R, G, B)
MLP
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# (width * height * channel) = 32*32*3
self.fc1 = nn.Linear(32*32*3, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 10)
def forward(self, x):
# reduce a dimension
# each image has a 32x32 size, We need to flatten each image.
x = x.view(-1, 32*32*3)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
x = self.fc3(x)
x = F.log_softmax(x, dim=1)
return x- batch_size는 이미지의 개수, nn.Linear에서 처음 input dim은 32 32 3임
- forward에서 처음에, 각 image size가 32 32인데 이를 flatten 시켜줘야함 -> x.view(-1, 32 32 * 3)
model = Net().to(DEVICE) # assign to a defined device
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
print(model)- model의 features

def train(model, train_loader, optimizer, log_interval):
model.train()
for batch_idx, (image, label) in enumerate(train_loader):
# assign to a defined device
image = image.to(DEVICE)
label = label.to(DEVICE)
# initialize a gradient
optimizer.zero_grad()
output = model(image)
loss = criterion(output, label)
loss.backward()
optimizer.step()
# print logs
if batch_idx % log_interval == 0:
print("Train Epoch {} [{}/{}({:.0f}%)]\tTrain Loss: {:.6f}".format(epoch, batch_idx*len(image), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item()))- train function 정의
def evaluate(model, test_loader):
model.eval()
test_loss, correct = 0, 0
with torch.no_grad(): # stop updating a gradient during testing
for image, label in test_loader:
# assign to a defined device
image = image.to(DEVICE)
label = label.to(DEVICE)
output = model(image)
test_loss += criterion(output, label).item()
# predict with the label with the largest value out of 10 results
prediction = output.max(1, keepdim=True)[1]
# cumulate the number of correct answers
correct += prediction.eq(label.view_as(prediction)).sum().item()
test_loss /= len(test_loader.dataset)
test_accuracy = 100. * correct / len(test_loader.dataset)
return test_loss, test_accuracy- evaluate function 정의
for epoch in range(1, epochs+1):
train(model, train_loader, optimizer, log_interval=200)
test_loss, test_accuracy = evaluate(model, test_loader)
print("\n[Epoch: {}], \tTest Loss: {:.4f}, \tTest Accuracy: {:.2f} % \n".format(epoch, test_loss, test_accuracy))- 학습 진행 (+ 평가도 동시에 진행)
CNN
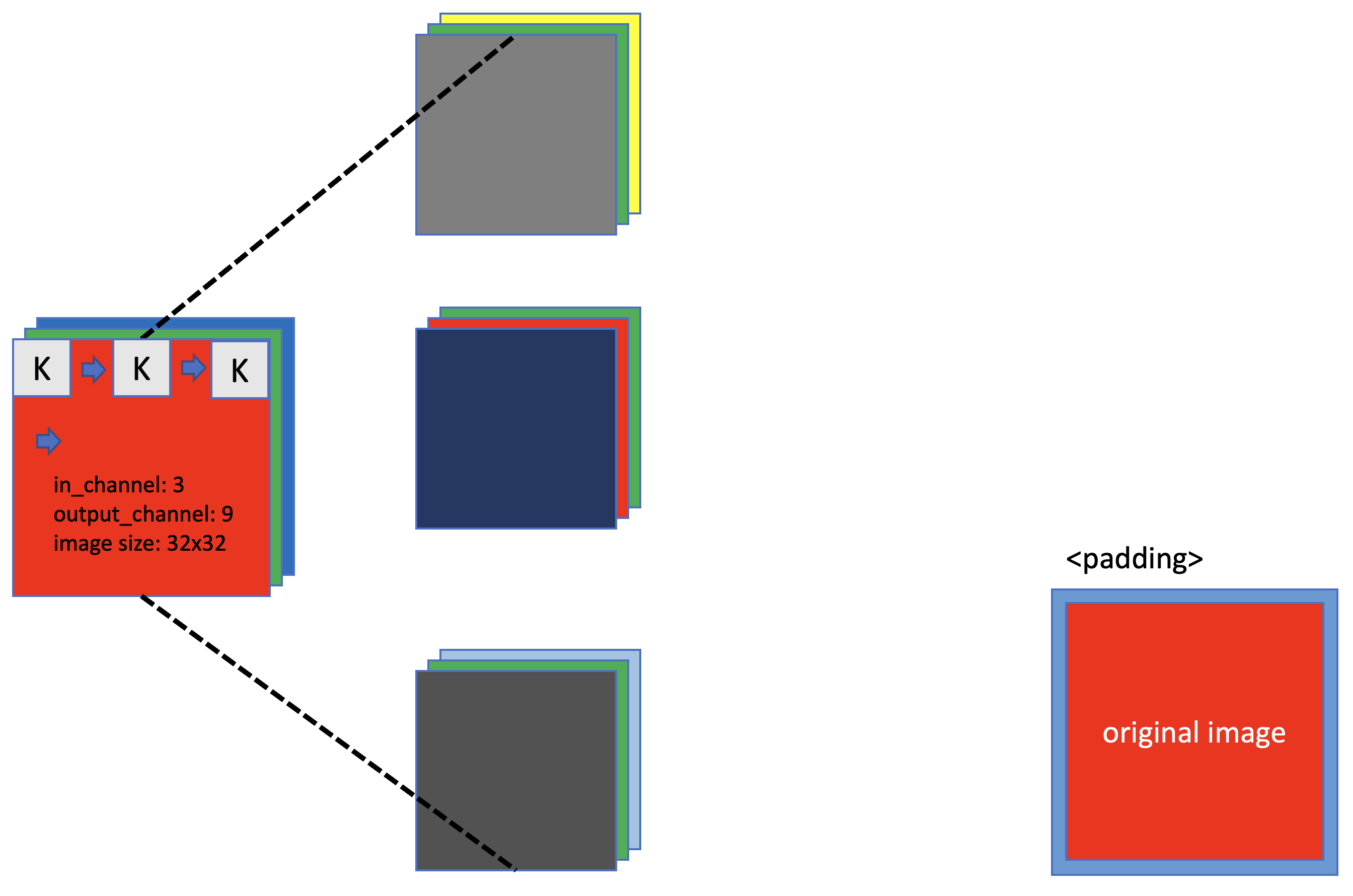
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# in_channel: R, G, B
# kernel_size: 3x3
# padding: the number of zero padding
self.conv1 = nn.Conv2d(in_channels=3, out_channels=9, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(in_channels=9, out_channels=18, kernel_size=3, padding=1)
# kernel_size= 2x2, maximum value will be replaced as a representative value of 4 pixels.
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
# Fully Connected Layers
self.fc1 = nn.Linear(8*8*18, 64)
self.fc2 = nn.Linear(64, 32)
self.fc3 = nn.Linear(32, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.pool(x)
x = self.conv2(x)
x = F.relu(x)
x = self.pool(x)
x = x.view(-1, 8*8*18)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
x = self.fc3(x)
x = F.log_softmax(x)
return x
- input image의 크기는 32 * 32 & 3개의 channel, kernel의 크기는 3 * 3
- conv1 -> pooing -> conv2 -> pooling -> flatten -> fully connected layer 1, 2, 3 -> log_softmax
- convolution layer를 지나면 input dim이 8 * 8 * 18이 됨. (image size: 8 * 8, channel: 18)
# show a model's architecture
model = CNN().to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
print(model)- model의 구조


💼 Software Engineer @ LG Electronics | 🎓 SungKyunKwan Univ. CSE