RNN
- RNN은 sequential data (Speech, Text, Image)를 사용하여 Nest step prediction, Classification, Sequence Generation 등을 수행할 수 있음
- RNN process의 4가지 유형
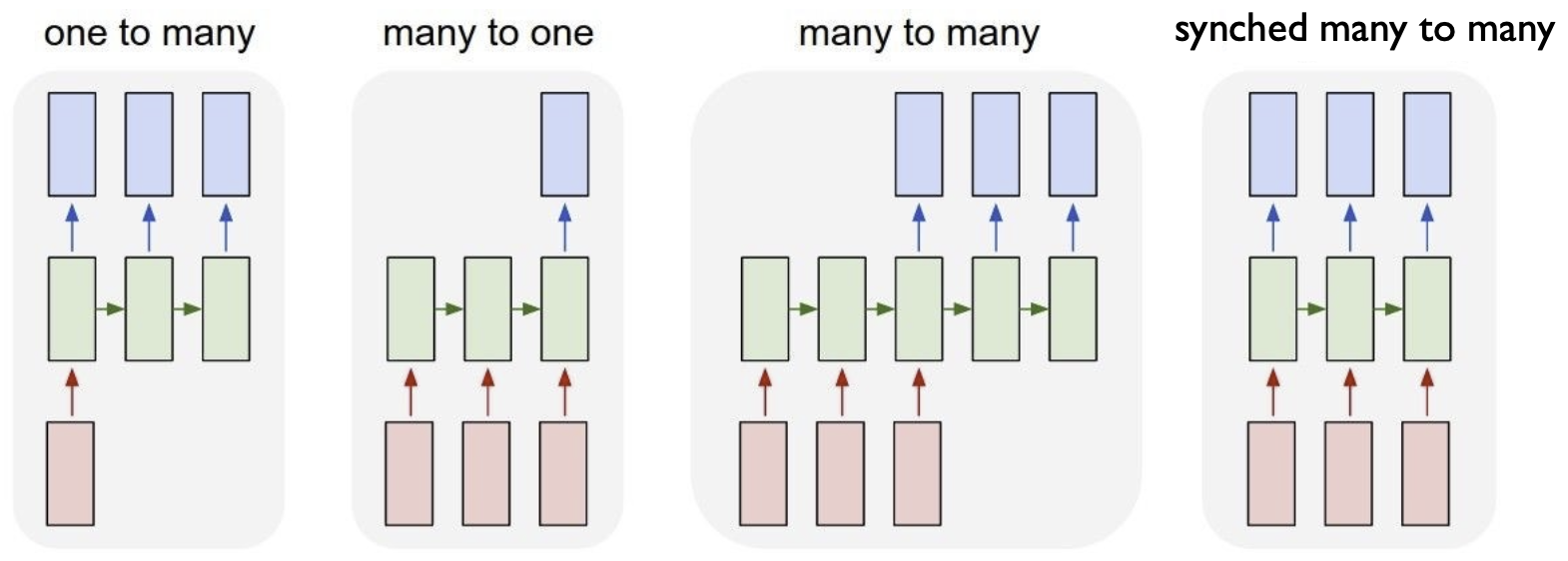
1. Text generation
2. Text classficiation
Text generation
Data preprocessing
sentence = "life is like a box of chocolates you never know what you are going to get".split()
#Make a vokabulary list
vocab = list(set(sentence))
print(vocab)word2index = {tkn: i for i, tkn in enumerate(vocab, 1)}
word2index['<unk>']=0
print(word2index)- word2index (dictionary type)
#T his dict transfroms index to number(number)
index2word = {v: k for k, v in word2index.items()}
print(index2word)- index2word (dictionary type)
# Function to make the input data(X) and the labels(Y)
def build_data(sentence, word2index):
encoded = [word2index[token] for token in sentence] # transforms word to index
input_seq, label_seq = encoded[:-1], encoded[1:] # Split the input sequence and label sequence
input_seq = torch.LongTensor(input_seq).unsqueeze(0)
label_seq = torch.LongTensor(label_seq).unsqueeze(0)
return input_seq, label_seq, encoded
x, y, encoded = build_data(sentence, word2index)- x는 encoded[:-1], y는 encoded[1:] -> RNN 구조에 따라
embedding_function = torch.nn.Embedding(num_embeddings=len(word2index), embedding_dim = 5)
embedding_function(x)- text data의 word를 모두 numeric value로 바꿔줘야함 (embedding dimension as 5)
Many to Many RNN model 구현
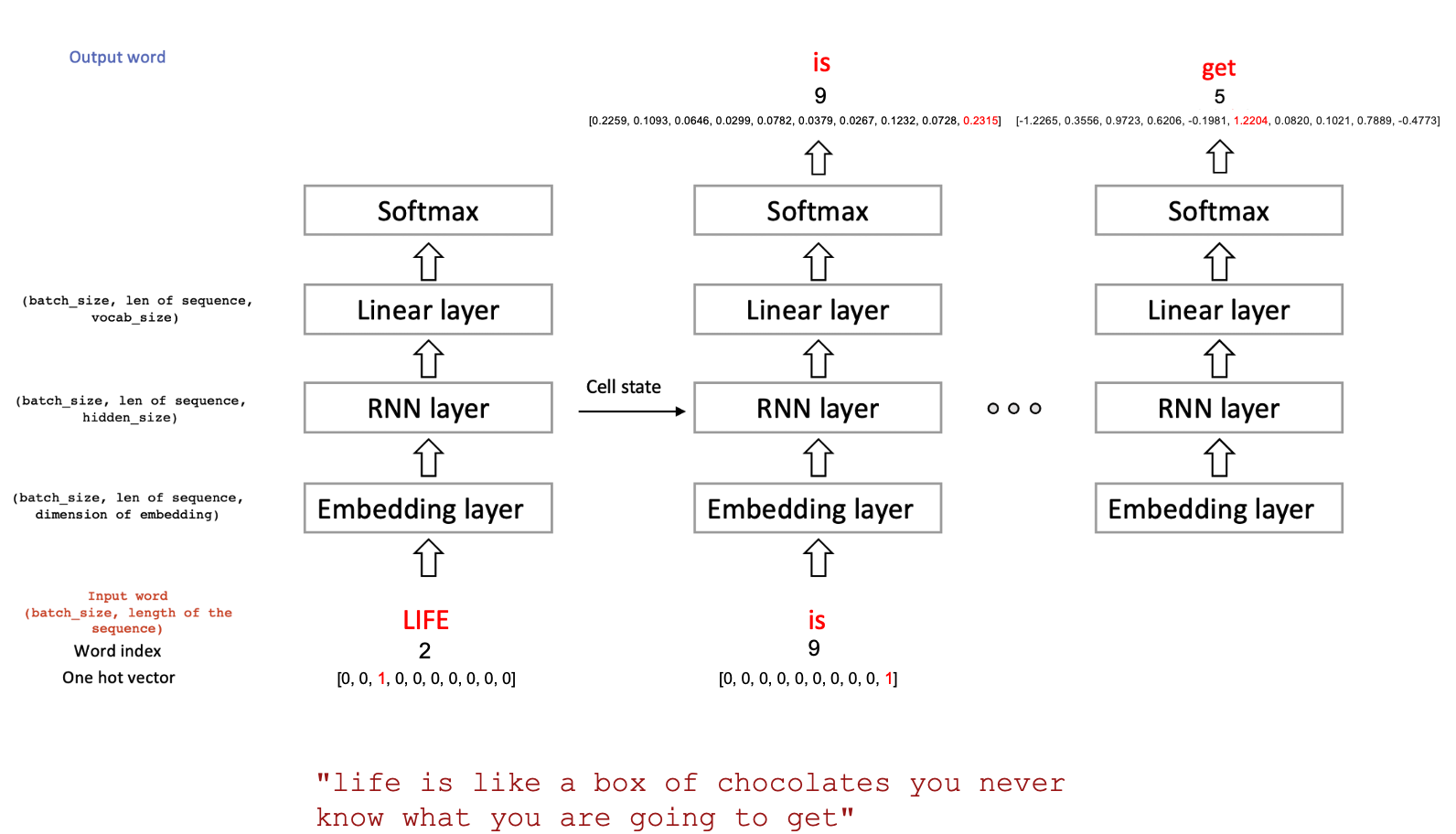
- Many to Many RNN model을 사용할거임 -> multiple inputs & get multiple outputs sequentially
- 처음 단어 'life'가 time t에 input으로 들어가면, time t+1에 "life"와 "is"가 hidden representation으로 생성횜.
- 마지막 단계에서 softmax가 확률을 주고, cross entrophy를 사용해 loss를 생성함
#hyper parameter
vocab_size = len(word2index) # 16
input_size = 5 # embbeding dim
hidden_size = 20 # hidden size of RNN layer
epochs = 200- 임의로 Hyper parameters 설정 (grid search를 하는 게 더 좋긴함)
class RNN_model(torch.nn.Module):
# vocab_size = size of the using word 16 (decided from original text)
# hidden_size = size of the RNN's output 20 (hyper-parameter)
# input size = size of input embedding 5 (decided from previous cell)
def __init__(self, vocab_size, input_size, hidden_size):
super(RNN_model, self).__init__()
# Embedding layer
self.embedding_layer = torch.nn.Embedding(num_embeddings=vocab_size,embedding_dim=input_size) # give embedding for each word
# RNN layer
self.rnn_layer = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=1, batch_first=True) # RNN(5, 20, num_layers=1)
# linear layer
self.linear = torch.nn.Linear(hidden_size, vocab_size) # Linear(in_features=20, out_features=16, bias=True)
def forward(self, x):
#1. Embedding layer
# size of the data: (batch_size, length of the sequence) -> (batch_size, lenth of the sequence, dimension of embedding)
y = self.embedding_layer(x)
# x: tensor([[ 5, 3, 7, 12, 8, 14, 15, 9, 4, 10, 6, 9, 1, 11, 2]]) torch.Size([1, 15])
# y: torch.Size([1, OO, 5])
#2. RNN layer
# size of the data: (batch_size, length of the sequence, embedding dimension) -> y: (batch_size, length of the sequence, hidden_size), hidden: (num_layer, batch_size, hidden_size)
y, hidden = self.rnn_layer(y)
# y: torch.Size([1, 15, 20]) hidden: torch.Size([1, 15, OO])
#3. Linear layer
# size of the data: (batch_size, length of the sequence, hidden_size) -> (batch_size, length of the sequence, vocab_size)
y = self.linear(y)
# y: torch.Size([1, 15, 16])
# Size of the return value: (batch_size*length of the sequence, vocab_size)
return y.view(-1, y.size(2)) # torch.Size([15, 16])- embedding_layer -> (vacab_size, input_size)
- rnn_layer -> (input_size, hidden_size)
- linear -> (hidden_size, vocab_size)
- rnn_layer에서 batch_first를 True로 줘야함
Train the RNN model
model = RNN_model(vocab_size, input_size, hidden_size)
loss_function = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model.parameters())- optimizer는 torch.optim.Adam
- loss_function은 torch.nn.CrossEntropyLoss()
decode = lambda y: [index2word.get(x) for x in y]- model result를 word로 decode 해줌
# Training
print(f'life is like a box of chocolates you never know what you are going to get')
for epoch in range(1, epochs+1):
optimizer.zero_grad()
output = model(x)
loss = loss_function(output, y.view(-1))
loss.backward()
optimizer.step()
# Observe the result
if epoch % 20 == 0:
print(f"Epoch: {epoch}, Loss: {loss}")
pred = output.softmax(-1).argmax(-1).tolist()
print(" ".join(['life']+ decode(pred)))
print()- training 진행
One Hot Encoding
def one_hot_encoding(sentence, word2index):
encoded = torch.zeros(len(word2index), len(word2index))
for idx, word in enumerate(sentence):
word_index = word2index[word]
encoded[idx][word_index] = torch.LongTensor([1])
input_seq, label_seq = encoded[:-1], encoded[1:]
return input_seq.to(torch.long), label_seq.to(torch.long), encoded.to(torch.long)
x, y, encoded = one_hot_encoding(sentence, word2index)
print(x,y,encoded)- One hot encoding function 정의
#hyper parameter
vocab_size = len(word2index) # 16
input_size = 5 # embbeding dim
hidden_size = 20 # hidden size of RNN layer
epochs = 200
class RNN_model(torch.nn.Module):
def __init__(self, vocab_size, input_size, hidden_size):
super(RNN_model, self).__init__()
self.vocab_size = vocab_size
self.input_size = input_size
self.hidden_size = hidden_size
#Embedding layer
self.embedding_layer = torch.nn.Linear(vocab_size, input_size)
#RNN layer
self.rnn_layer = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=1, batch_first=True)
#linear layer
self.linear = torch.nn.Linear(hidden_size, vocab_size)
def forward(self, x):
y = self.embedding_layer(x.to(torch.float)).reshape(1,x.shape[0],self.input_size)
y, hidden = self.rnn_layer(y)
y = self.linear(y)
return y.view(-1, y.size(2)) # torch.Size([15, 16])
model = RNN_model(vocab_size, input_size, hidden_size)
loss_function = torch.nn.MSELoss()
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.01)
print(f'life is like a box of chocolates you never know what you are going to get')
for epoch in range(1, epochs+1):
optimizer.zero_grad()
output = model(x)
loss = loss_function(output, y.float())
loss.backward()
optimizer.step()
# Observe the result
if epoch % 20 == 0:
print(f"Epoch: {epoch}, Loss: {loss}")
pred = output.argmax(-1).tolist()
print(" ".join(['life']+ decode(pred)))- 다시 training 진행
Text Classification (by using LSTM)
- RNN의 문제점: long term dependency problem (gradient vanishing issue 때문) -> LSTM model을 통해 해결
- 사용하고자 하는 Dataset: movie reviews & labels whether reviews are positive or negative
TEXT = torchtext.data.Field(sequential=True, batch_first=True, lower=True)
LABEL = torchtext.data.Field(sequential=False, batch_first=True)
trainset, testset = torchtext.datasets.IMDB.splits(TEXT, LABEL)pos_data = vars(trainset[0]) # vars: returns dictionary of used class' object(사용된 클래스의 객체에 대한 dictionary 를 반환한다. )
neg_data = vars(trainset[20000])- vars(): dictionary를 반환함
TEXT.build_vocab(trainset, min_freq=5)
LABEL.build_vocab(trainset)
vocab_size = len(TEXT.vocab)
trainset, valset = trainset.split(split_ratio=0.8)- train dataset을 train, validation으로 나눔
train_iter, val_iter, test_iter = torchtext.data.BucketIterator.splits(
(trainset, valset, testset), batch_size=64,
shuffle=True, repeat=False
batch = next(iter(train_iter))
print(f'Shape of first batch: {batch.text.shape}')
batch = next(iter(train_iter))
print(f'Shape of second batch: {batch.text.shape}')
# Reset the data loader to learn the observed data as well
train_iter, val_iter, test_iter =torchtext.data.BucketIterator.splits(
(trainset, valset, testset), batch_size=64,
shuffle=True, repeat=False)LSTM model 정의 및 training
def train(model, optimizer, train_iter):
for b, batch in enumerate(train_iter):
x, y = batch.text.to(DEVICE), batch.label.to(DEVICE)
y.data.sub_(1) #transforms the labels into (0, 1)
optimizer.zero_grad()
logit = model(x)
loss = torch.nn.functional.cross_entropy(logit, y)
loss.backward()
optimizer.step()- train 정의
def evaluate(model, val_iter):
corrects, total_loss = 0, 0
for batch in val_iter:
x, y = batch.text.to(DEVICE), batch.label.to(DEVICE)
y.data.sub_(1) #transforms the labels into (0, 1)
logit = model(x)
loss = torch.nn.functional.cross_entropy(logit, y, reduction='sum')
total_loss += loss.item()
corrects += (logit.max(1)[1].view(y.size()).data == y.data).sum()
size = len(val_iter.dataset)
avg_loss = total_loss / size
avg_accuracy = 100.0 * corrects / size
return avg_loss, avg_accuracy- evalute 정의
class LSTM(torch.nn.Module):
def __init__(self, vocab_size, input_size, n_labels, hidden_size, num_layers = 1, batch_first=True):
super(LSTM, self).__init__()
self.vocab_size = vocab_size # 46159
self.input_size = input_size # 128
self.hidden_size = hidden_size # 256
self.num_layers = num_layers # 2
# Embedding layer
self.embedding_layer = torch.nn.Embedding(num_embeddings=self.vocab_size,embedding_dim=self.input_size)
# Embedding(46159, 128)
# LSTM layer
self.lstm_layer = torch.nn.LSTM(input_size=self.input_size, hidden_size=self.hidden_size, num_layers =self.num_layers, batch_first=True)
# LSTM(128, 256, num_layers=2, batch_first=True)
# linear layer
self.linear = torch.nn.Linear( hidden_size, n_labels)
# Linear(in_features=256, out_features=2, bias=True)
def forward(self, x):
#1. Embedding layer
#size of the data: (batch_size, lenth of the sequence) -> (batch_size, lenth of the sequence, dimension of embedding)
y = self.embedding_layer(x) # y torch.Size([64, 727, 128])
#Initial hidden state
h_0 = torch.zeros((self.num_layers, y.shape[0], self.hidden_size)).to(DEVICE)# h_0 torch.Size([2, 64, 256])
#Initial cell state
c_0 = torch.zeros((self.num_layers, y.shape[0], self.hidden_size)).to(DEVICE)# c_0 torch.Size([2, 64, 256])
#2. LSTM layer
# size of the data: (batch_size, lenth of the sequence, dimension of embedding) -> h_n, c_0 = (num_layers, batch size, hidden_size)
hidden_states, (h_n , c_n) = self.lstm_layer(y, (h_0, c_0)) # hidden_states torch.Size([64, 727, 256]) h_n torch.Size([2, 64, 256]) c_n torch.Size([2, 64, 256])
h_t = hidden_states[:,-1,:] # h_t torch.Size([64, 256]). ## Only need last one from sequence! Look at the dimension of h_t
#3. Linear layer
# size of the data: (batch_size, hidden_size) -> (batch_size, n_labels)
result = self.linear(h_t) # result torch.Size([64, 2])
#Size of the return value: (batch_size, n_labels)
return result
model = LSTM(vocab_size=vocab_size, input_size=128,num_layers = 1, n_labels=2, hidden_size=256).to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)- LSTM model 정의
for e in range(1, epochs+1):
train(model, optimizer, train_iter)
val_loss, val_accuracy = evaluate(model, val_iter)
print(f"Epoch: {e}, Loss of validation: {val_loss} Accuracy of validation: {val_accuracy}")- training & evaluating
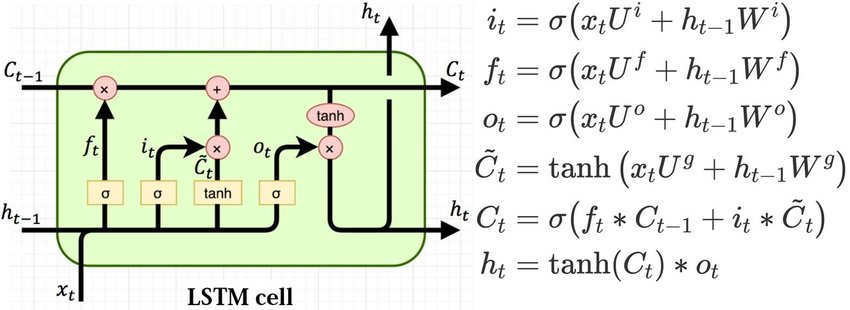
- LSTM에선 tanh를 사용함으로서, 기울기가 0 ~ 1 사이이기 때문에 Vanishing Gradient problem을 막을 수 있음
- LSTM은 tanh 활성화 함수와 gate 메커니즘을 통해 long term dependency, 다양항 활성화 함수, gradient 흐름 관리 등의 장점을 갖고 있어, 단순한 RNN보다 더 나은 성능을 발휘함
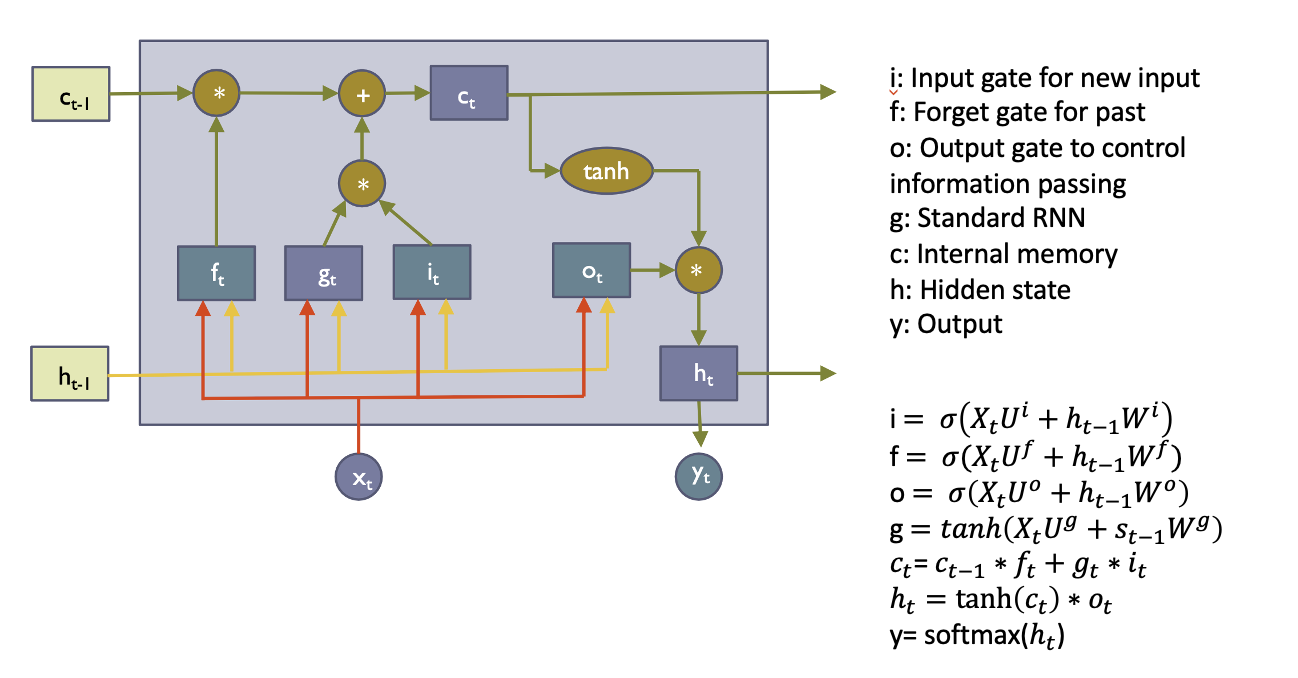
- 아래 코드는 LSTMCell을 직접 구현한 코드임
class LSTMCell(nn.Module):
def __init__(self, input_size, hidden_size, bias=True):
super(LSTMCell, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.bias = bias
self.xh = nn.Linear(input_size, hidden_size * 4, bias=bias)
self.hh = nn.Linear(hidden_size, hidden_size * 4, bias=bias)
self.reset_parameters()
def reset_parameters(self):
std = 1.0 / np.sqrt(self.hidden_size)
for w in self.parameters():
w.data.uniform_(-std, std)
def forward(self, x, hx, cx):
gates = self.xh(input) + self.hh(hx)
input_gate, forget_gate, cell_gate, output_gate = gates.chunk(4, 1)
i_t = torch.sigmoid(input_gate)
f_t = torch.sigmoid(forget_gate)
g_t = torch.tanh(cell_gate)
o_t = torch.sigmoid(output_gate)
ct = cx * f_t + i_t * g_t
ht = o_t * torch.tanh(ct)
return (ht, ct)- LSTMcell이 nn.Linear of hidden_size 4 times 로 초기화되는 이유
-> 빨간 화살표가 4개의 각각 다른 방향으로 감. linear layer의 outputdmf 4 방향으로 나눠줘야함
-> 한번 이렇게 input을 받고 4 gates로 chunk해주면 나머지는 이 공식을 따라서 실행됨
GRU 구현
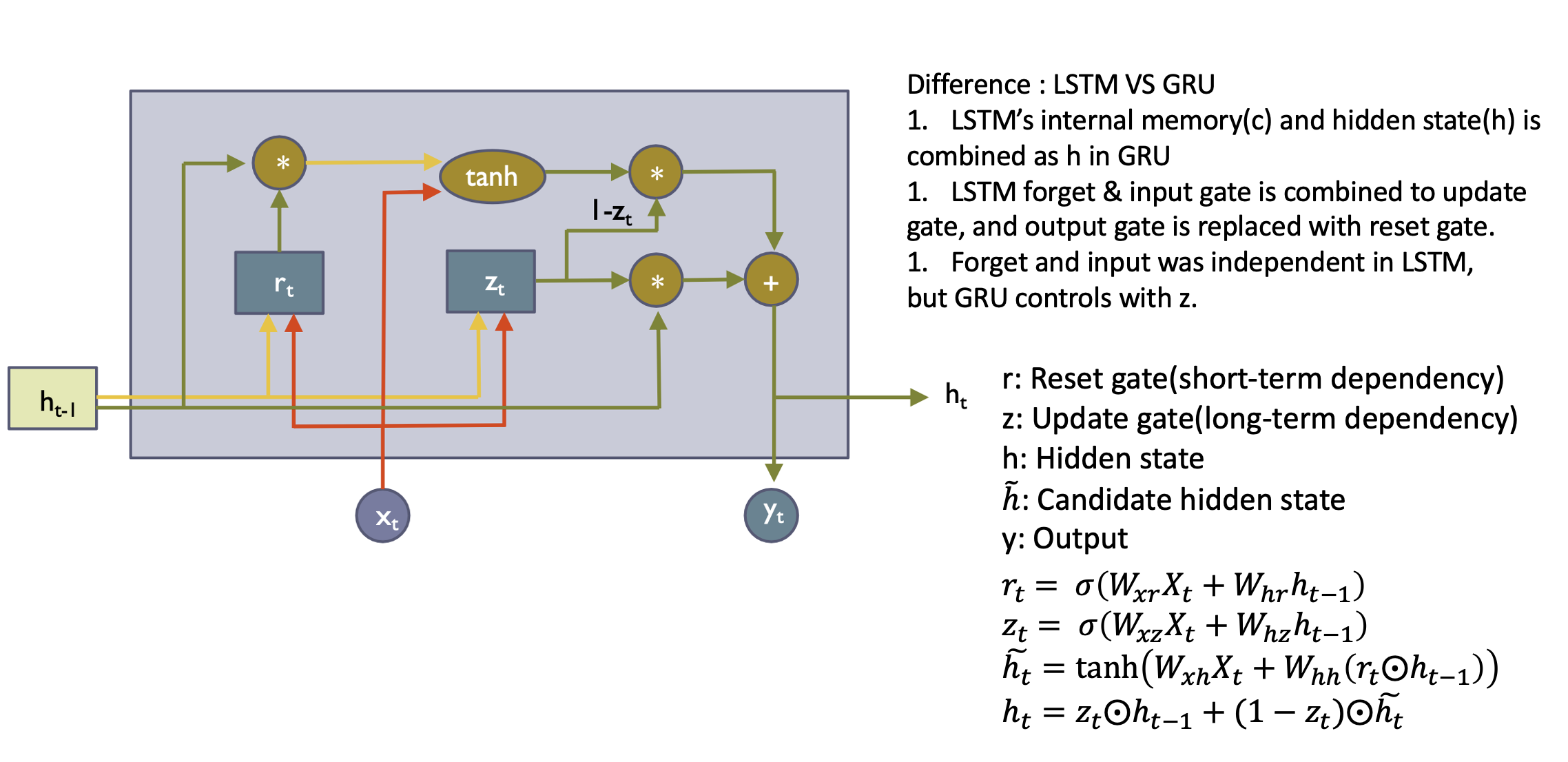
- 아래 코드는 GRUCell을 직접 구현한 코드임
class GRUCell(nn.Module):
def __init__(self, input_size, hidden_size, bias=True):
super(GRUCell, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.bias = bias
self.x2h = nn.Linear(input_size, 3 * hidden_size, bias=bias)
self.h2h = nn.Linear(hidden_size, 3 * hidden_size, bias=bias)
self.reset_parameters()
def reset_parameters(self):
std = 1.0 / np.sqrt(self.hidden_size)
for w in self.parameters():
w.data.uniform_(-std, std)
def forward(self, x, hx):
x_t = self.x2h(x)
h_t = self.h2h(hx)
x_reset, x_upd, x_new = x_t.chunk(3, 1)
h_reset, h_upd, h_new = h_t.chunk(3, 1)
reset_gate = torch.sigmoid(x_reset + h_reset)
update_gate = torch.sigmoid(x_upd + h_upd)
candidate_hidden_state = torch.tanh(x_new + (reset_gate * h_new))
hy = update_gate * hx + (1 - update_gate) * candidate_hidden_state
return hy- Linear layer는 3 parts로 chunk 됨 -> colored arrowrk 3개의 방향으로 쪼개지기 때문

💼 Software Engineer @ LG Electronics | 🎓 SungKyunKwan Univ. CSE