TSMtech Record
1.AWS DynamoDB in Python (Boto3)

DynamoDB -> Amazon에서 AWS에 최적화된 NoSQL 데이터베이스RDBMS가 아닌 NoSQL 데이터베이스이기 때문에 별도의 SQL Programming을 하지 않고, 일반 프로그래밍 언어 상에서 DB Scheme을 설계하고 관리해야함\-> 지원 언어: Ja
2.AWS Lambda_handler
Lambda function handler is the method in your function code that processes events.\-> 함수가 호출되면 Lambda는 handler method를 실행함 (main 함수 느낌?)\-> When the h
3.AWS Lambda event, context
The contents of the event parameter include all of the data and metadata your Lambda function needs to drive its logic. For example, an event created
4.favorite API (CRD)
favorite_transport_createfavorite_transport_deletefavorite_transport_read
5.Transport_Energy APIs documentation
수송에너지 부분 탄소배출량 데이터 획득에 있어 다음과 같은 문제점 발생차량 mcu의 오픈 데이터셋 (경유, 휘발유 소비량)을 어떻게 얻어야 할지? 해당 지역에 등록된 차량의 mcu 데이터를 얻을 수 있는 방법을 잘 모르겠음.티맵이나 카카오맵의 주행 이력을 확인하여 이
6.Building_Energy DB 구축
MySQL이용/ Python으로 query 및 pandas DataFrame 이용\+2022년도 data append 필요
7.Industry_Energy DB 구축
도단위/연도별 산업에너지 DB 구축RDS 이용
8.Building_Energy DB migration
건물에너지 data는 이미 관계형 DB (RDS)로 구축했는데 data 분석의 다각화를 위해 비정형 데이터 처리가 필요해짐\-> DB migration 작업 진행 (from SQL(RDS) to NoSQL(DynamoDB))AWS DynamoDB console에 par
9.Building_Emissions READ api
event -> type, date, addr 값을 parameter로 입력받음type은 총 6개/ 월단위 Third, Second, First 범위, 연단위 Third, Second, First 범위(주소값 합칠 때 사용)Input은 dictionary list 형태
10.에너지 소비량 (gas, electricity) parsing
pandas.errors.ParserError: Error tokenizing data. C error: out of memory\-> 전기에너지 소비량 데이터 chunksize 줄여야할듯
11.법정동 -> 행정동 mapping
건물에너지 DB 구축 끝난 줄 알았는데 모든 데이터가 법정동 기반이었다는 걸 API 연동 test 하면서 발견함dataset의 법정동코드를 행정동코드로 mapping 해야함법정동코드와 행정동코드가 정확히 1대 1로 매핑이 되지 않음\-> mapping table 2개를
12.best_energy_consumption_by_building
상위 5개 시군구에 대해 -> 행정동코드 & 전체소비량 / 건물 개수 (kWh & g)co2_sum = energy_sum \* 424 (g)
13.법정동 -> 행정동 mapping 코드 (최종)
다 돌아가는데 5일 걸림 ㅠ
14.h_gas, h_electricity truncate
h_gas와 h_electricity 각각 행정동코드 'False'인 경우, 지번주소가 없는 경우 날리기 + row가 중복되는 경우도 날리기
15.gas_trunc, electricity_trunc group by
16.gas_groupby, electricity_groupby join
gas 소비량이 left join할 때 Nan값 때문에 float type으로 처리됨
17.pd.dataframe to dynamodb
gas소비량 NaN값 그냥 0으로 처리
18.Crawling & DB insert
최신 데이터 추가 자동화 알고리즘 (기록용)
19.Delete item in DynamoDB
python boto3 library를 이용함boto3에선 dynamodb의 partition key와 sort key를 모두 이용해야 item을 delete 할 수 있음현재 dynamodb에 삽입된 202205의 행정동 addr를 모두 읽고, 그 addr(sort k
20.Query vs. Batch_get_item
query: partition key를 이용함getitem: primary key를 이용함기존에 qeury를 사용했음 -> table에 5년 \* 12달 = 60번의 query를 보내야 해서 api 요청 시간이 오래 걸림boto3 library의 batchgetitem
21.python으로 daemon scheduler 구현

데이터 자동 추가를 위해 linux crontab을 이용하려 했는데, 실행하고자 하는 crawling.py 파일에 외부 라이브러리가 많아서 그런지 (crontab 파일에 따로 library path를 추가해야 할듯?) crontab이 매달 실행 자체가 안됨\-> pyt
22.EC2에서 Nginx 호스팅
Nginx is Web Server
23.Nginx Domain name 변경 및 Kakaomap API 오류 해결
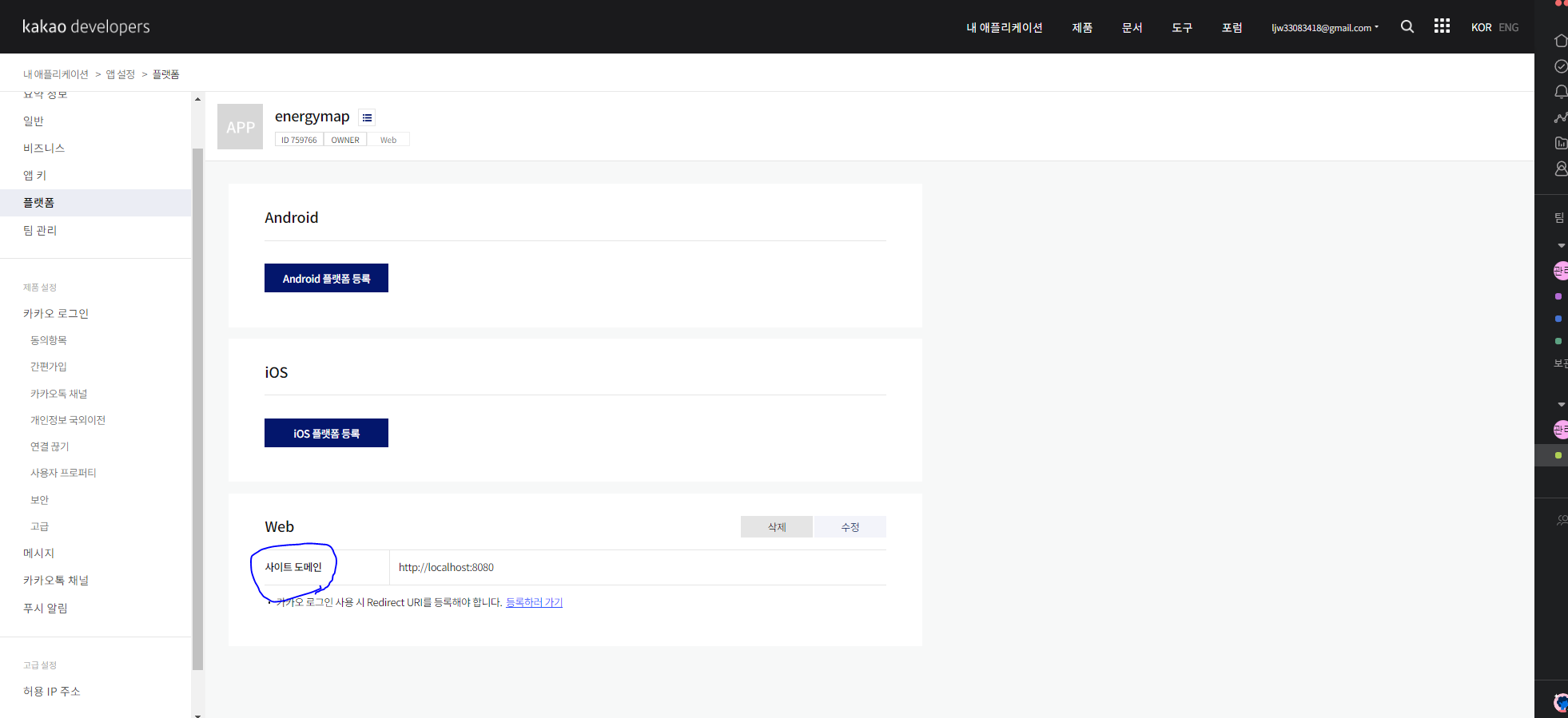
eco-plans.co.kr로 domain name 변경
24.Mapping 되지 않는 법정동코드
위 코드로 추출
25.kaptCode 추출
requests module을 이용하여 API 요청 및 응답을 받을 수 있도록 함수 구현beautifulSoup module을 이용하여 html parsing (xml 형식이긴 한데 tag 형식이면 parsing은 가능)xml parsing은 xml.etree.Elem
26.단지코드 단위 에너지소비량 local Dataset 구축
전국 단지코드 목록 한번에 받기Request parameter: kaptCode, reqDateenergy_parsing()의 input parameter를 통해 해당 함수를 호출하여 helect, hgas, hheat, hwaterCool, hwaterHot의 값들을
27.Lambda로 작업한 API 정리 (메모)
new건물 배출량 읽기lambda: emissions_building_readnew최신 건물 배출량 읽기lambda: emissions_building_read_newnew지번으로 건물하나 배출량 읽기lambda: jibun_readnew빌딩 개수 읽기lambda: b
28.TimeoutError: [WinError 10060] 해결
오류 내용
29.지번 주소 -> latitude, longitude 추출
행정동코드 is False인 경우, 지번 주소를 통해 위도와 경도 추출얻은 위도와 경도를 통해 행정동코드를 얻을 예정googlemaps API를 이용함\-> service key를 발급 받을 때, 카드 등록을 해야하는데 사용 시작 시점으로부터 90일 까지 300$ 크레
30.latitude, longitude -> hjdcode 변환
googlemaps API로 얻은 위도, 경도를 이용하여 kakaomap API를 통해 행정동코드로 변환하는 코드위도, 경도가 추출되지 않는 지번주소의 경우를 제외하고 모두 행정동코드 변환이 가능한듯행정기준코드와 행정동코드 구별법정동코드와 행정동코드의 시도 및 시군구
31.행정동코드를 얻을 수 없는 지번주소 목록
latlng_is_false
32.Local Database 구축 (유실 데이터 해결)
유실되는 지번주소를 최대한 줄여 map2를 새로 생성함googlemaps API 이용하여 위도 경도 받기 -> kakaomap API 이용하여 hjdcode 받기전체 지번 주소: 4,199,281 개유실 되는 지번 주소: 218 개새로 생성한 map2를 이용하여 유실
33.Data processing에서 join 부분 수정
기존에는 count_gas를 drop하고 전기에너지 기준으로 left join을 했었음그 이유는 가스에너지소비량의 건물주소가 전기에너지소비량의 부분집합이라고 생각했기 때문근데 가스에너지소비량의 건물주소가 전기에너지소비량의 건물주소에 포함되지 않는 경우도 존재함을 발견함
34.DynamoDB (Re)Create Table
유실데이터를 최대한 복구하여 DB Table을 재구축읍면동단위 Table명: energy시군구단위 Table명: energy_sigungu시도단위 Table명: energy_sido세 Table 모두 On-Demand로 설정IAM 권한은 Table 마다 설정하는게 아니
35.에너지소비량, 탄소배출량 단위
에너지소비량 단위 -> kWh탄소배출량 단위 -> kgCO2이산화탄소배출량 = 전력사용량(kwh)×424g CO2/kwh※ 전기 1kwh 사용시 424g의 이산화탄소(CO2)가 배출됨
36.단지코드 - 도로명주소 - 지번주소
Algorithms 1) 단지코드당 전기에너지소비량 데이터에서 '단지코드'와 '도로명주소'가 매핑되는 row를 뽑고, ('단지코드'와 '도로명주소'가 매핑되지 않는 경우는 제외) 2) 지번주소당 전기에너지소비량 데이터에서 '지번주소'와 '도로명주소'가 매핑되는 row를
37.한국전력공사_전기에너지 데이터

한국전력공사에서 월별&법정동별 전기에너지소비량 데이터를 제공하고 있음을 확인하여 test를 진행함법정동주소 column에서 '리'까지 표시되어있음 & 시군구 column에서 공백이 존재함/ 법정동코드로 변환하기 위해 '리'를 제거함 & 공백을 제거함세종특별자치시의 경우
38.kaptget.py 수정 사항
try, except 문에서 오류가 발생할 경우 sleep(2)하고 다시 try 하는 방식으로 구현하여 timeout error 해결 (기존에는 except문에서 다시 요청을 보냈고, 보낸 요청에 대해 다시 error가 발생할 경우, 프로세스가 종료되었음)HTTP st
39.File Uploader 구현 (진행중)
여너초밥