최신 고성능 모델들은 Transformer 아키텍쳐를 기반으로 함
ex) GPT는 Transformer의 Decoder 아키텍쳐 활용
Transformer 부터는 RNN을 사용하지 않고, Attention 기법만 사용
-> 성능이 훨씬 좋아짐
-> 입력 시퀀스 전체에서 정보를 추출하는 방향으로 발전
Seq2Seq 기법의 한계
하나의 context Vector(문맥 벡터)가 소스 문장의 모든 정보를 가지고 있어야 하므로 성능이 저하됨
-> 매번 소스 문장의 출력값 전부를 입력으로 받음으로써 해결(GPU가 많은 메모리와 빠른 병렬 처리를 지원하여 가능)
하나의 고정된 크기의 context Vector에 담지 않고, 소스 문장 출력 전부를 입력으로 받도록
-> 소스 문장의 전체 출력 중 어떤 단어에 집중할 지 Model이 고려하도록 하여 성능을 더욱 높일 수 있음(출력값들을 전부 참고하겠다)
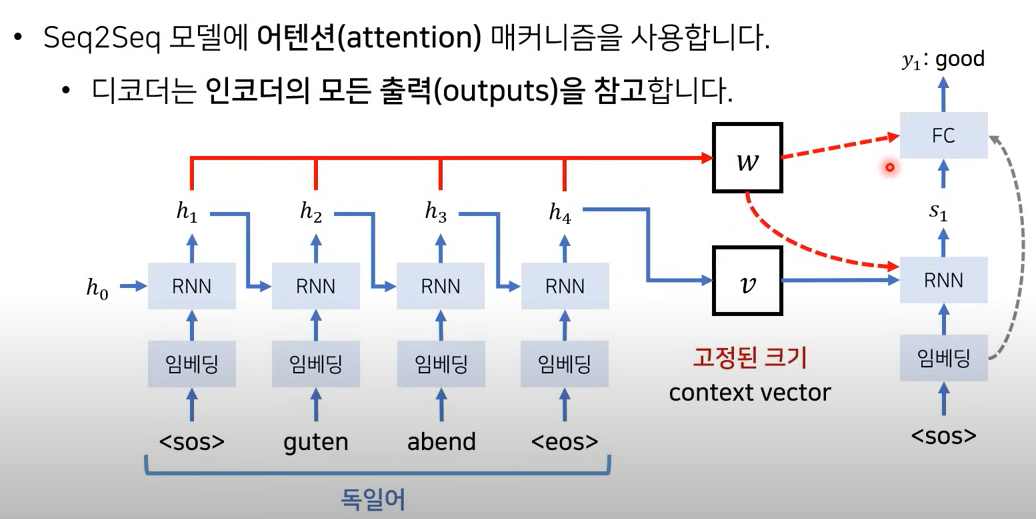
매번 디코더 part에서 각각의 단어를 만들 때(현재 Hidden state)
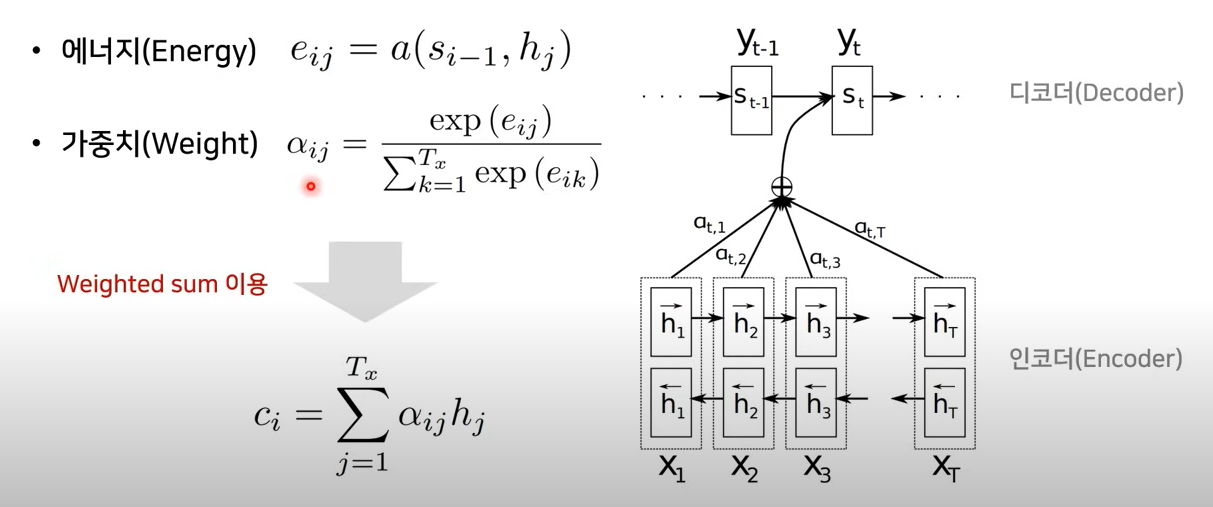
1. 이전 Hidden state 값과, 인코더 part의 모든 각각의 Hidden state 값을 같이 묶어 에너지 값을 구함
2. 해당 에너지 값에 SoftMax를 취해서, 비율값을 구할 수 있음(a값)
-> 어떤 걸 가장 많이 참고하면 되는지에 대한 비율값
3. 최종적으로 이를 참고해서, 다음 Hidden state(St)를 뭘 출력할 지 알 수 있음
Transformer는 RNN, CNN을 전혀 사용 X
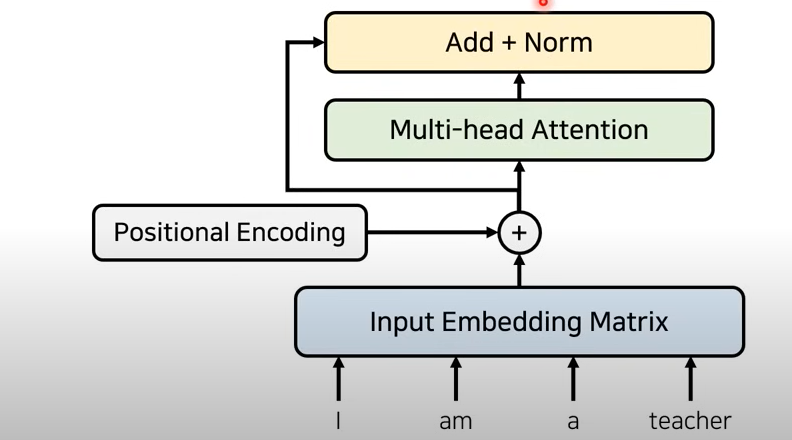
1. But, 문장 안의 단어들의 순서(위치 정보)를 알려주기 위해 Positional Encoding을 사용
2. 그 후, Attention 기법에 적용 시킴
3. 이때, Residual Learning(잔여 학습) 또한 가능하도록 하여 성능 향상을 시킴
-> 특정 레이어를 건너 뛰어 입력을 받아 기존 정보를 입력 받는 것 이외에 추가적으로 잔여된 부분까지 학습하도록 함
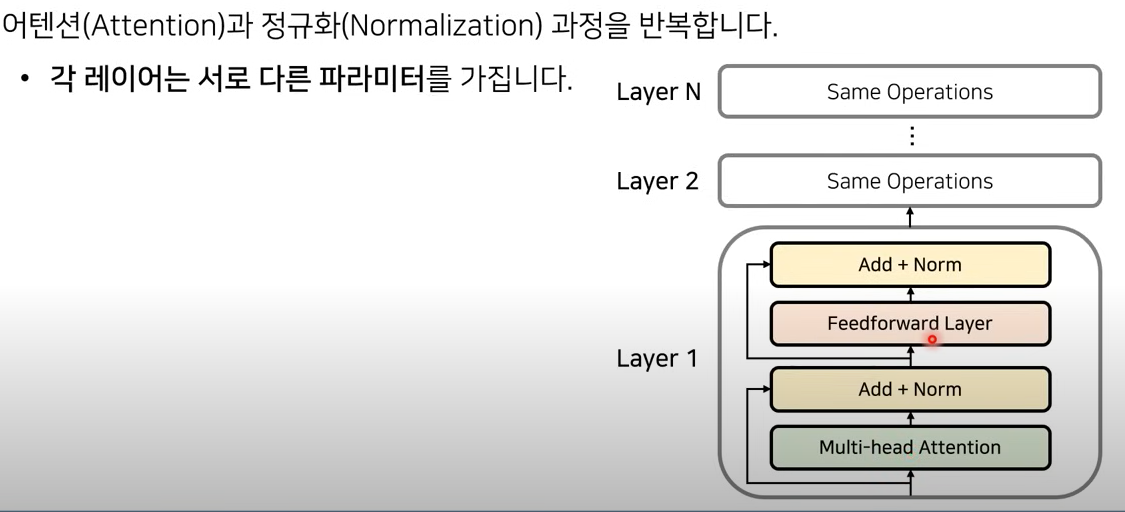
인코더 구조
어텐션과 정규화 과정을 반복하여 인코딩 하고, 여러개의 레이어를 중첩하여 각 레이어에 전달
인코더와 디코더가 연결된 전체 구조
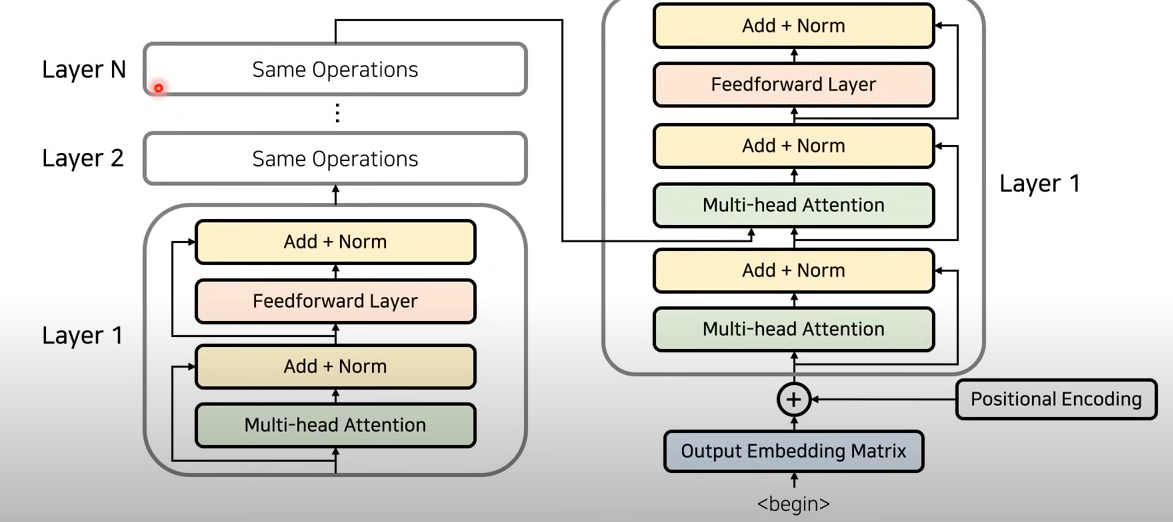
인코딩 한 값을 디코더에 입력하여(비율값을 통해 어떤 단어에 가장 많은 초점을 두어야 할 지), 디코더에서 나온 값이 우리가 최종적으로 출력한 단어
Multi-Head Attention
어떤 단어가 다른 단어와 어떤 연관성이 있는 지 물어보는 것
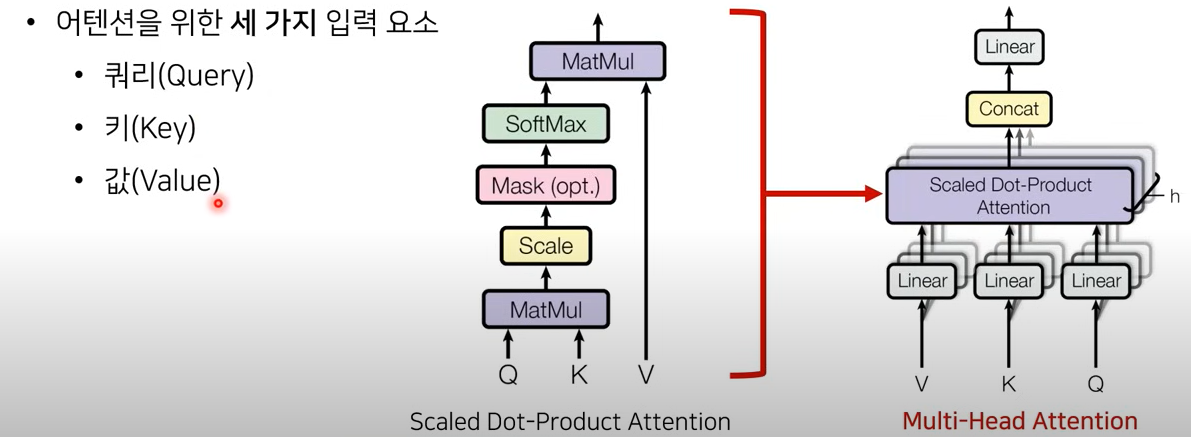
쿼리: 무언가를 물어보는 주체 (문장 속 한 단어)
키: 물어보는 대상(문장에 있는 모든 각각의 단어, 이들 각각과의 연관성을 물어보는 것)
값: Key에서 알아낸 가중치가 높은 값의 가중치와 Value 값을 곱해서 결과적인 Attetion Value 값을 구함
