Attention is All You Need (2017, Google)
RNN이나 CNN 같은 기존의 순차적(sequence-based) 구조를 사용하지 않고, 오직 Attention 메커니즘만을 활용하여 자연어 처리(NLP) 모델을 설계한 최초의 연구이다. 이 모델이 바로 Transformer이며, 이후 BERT, GPT 등의 최신 AI 모델의 기반이 되었다.
기존의 Seq2Seq 모델에서 인코더는 입력 시퀀스를 하나의 벡터 표현으로 압축하는데, 이 과정에서 입력 시퀀스의 정보가 일부 손실된다는 단점이 있다.
✅ 1. Seq2Seq 모델이란?
자연어 처리(NLP)에서 입력 시퀀스를 출력 시퀀스로 변환하는 모델이다.
기계 번역(예: 영어 → 한국어), 문서 요약, 질의응답(QA) 등에서 많이 사용된다.
기본적으로 Seq2Seq 모델은 두 개의 RNN 계층(인코더와 디코더)로 구성된다.
💡 예제: "I love you" → "나는 너를 사랑해" 번역
- 입력 시퀀스(Input Sequence): "I love you"
- 출력 시퀀스(Output Sequence): "나는 너를 사랑해"
Seq2Seq 모델은 이런 식으로 입력된 단어 시퀀스를 출력 시퀀스로 변환한다.
✅ 2. Seq2Seq의 주요 구성 요소
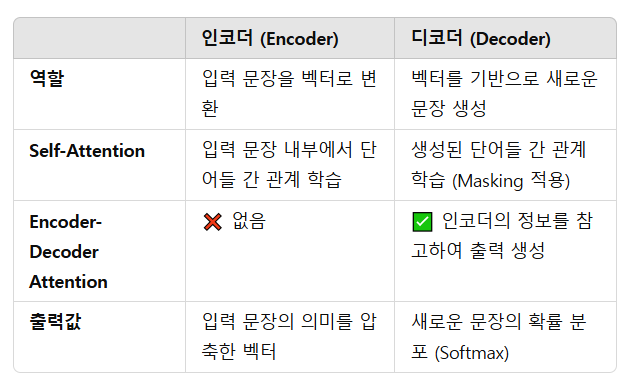
① 인코더(Encoder)
입력 문장을 받아서 **하나의 벡터(고정된 크기의 숫자 표현)**로 변환하는 역할.
단순히 단어를 숫자로 변환하는 게 아니라, 단어의 의미를 유지하면서 고정된 크기의 벡터로 압축하는 것이 핵심이다.
"문장을 컴퓨터가 이해할 수 있는 숫자로 변환하는 과정"
우리가 흔히 사용하는 원-핫 인코딩(One-Hot Encoding) 또는 임베딩 벡터(Word Embedding) 등을 사용할 수 있다.
📌 숫자는 아무렇게나 지정되는 게 아니다!
- 단순히 숫자를 랜덤하게 지정하는 것이 아니라, 의미를 가지도록 변환하는 것이 중요하다.
- 컴퓨터는 글자를 이해하지 못하기 때문에, 단어를 수학적으로 표현할 방법이 필요하다.
- 이를 해결하는 방법이 원-핫 인코딩(One-Hot Encoding)과 임베딩 벡터(Word Embedding)이다. 🧠
✅ 1. 원-핫 인코딩 (One-Hot Encoding)
각 단어를 고유한 벡터로 변환하는 가장 기본적인 방법
🔹 개념
단어를 0과 1로만 이루어진 벡터로 표현하는 방식.
단어 개수만큼의 차원을 가지며, 해당 단어 위치만 1이고 나머지는 모두 0.
🔹 예제
단어 집합 (Vocabulary):
| 단어 | 원-핫 벡터 |
|---|---|
| "I" | [1, 0, 0, 0, 0] |
| "love" | [0, 1, 0, 0, 0] |
| "you" | [0, 0, 1, 0, 0] |
| "hello" | [0, 0, 0, 1, 0] |
| "world" | [0, 0, 0, 0, 1] |
이제 컴퓨터는 "I"를 [1, 0, 0, 0, 0]로, "love"를 [0, 1, 0, 0, 0]으로 인식할 수 있어.
🔹 문제점 🚨
❌ 차원이 너무 커짐!
- 단어가 많아질수록 벡터 크기가 커져서 비효율적임.
- 예를 들어, 10만 개의 단어가 있다면 벡터 크기가 (100,000,)이 됨.
❌ 단어 간의 관계를 표현할 수 없음!
- 예를 들어 "love"와 "like"는 의미가 비슷하지만, 원-핫 인코딩에서는 관련이 없는 벡터로 표현됨.
- 따라서, 단어 간의 유사성을 반영하는 방법이 필요함.
- → 그래서 나온 게 "임베딩 벡터"!
✅ 2. 임베딩 벡터 (Word Embedding)
단어를 의미를 반영한 숫자 벡터로 변환하는 방법
🔹 개념
원-핫 인코딩과 다르게, 각 단어를 작은 차원의 벡터로 변환하면서 의미를 반영.
비슷한 단어들은 가까운 벡터 값을 가지도록 학습됨.
🔹 작은 차원이 필요한 이유
원-핫 인코딩에서는 단어가 많아질수록 벡터 크기가 커지잖아?
예시:
- 단어 집합이 10만 개(100,000 words)인 경우
- 원-핫 인코딩:
[0, 0, 0, ..., 1, ..., 0](벡터 크기: 100,000) - 임베딩 벡터:
[0.2, -0.5, 0.1, ..., 0.8](벡터 크기: 100~300)
- 원-핫 인코딩:
💡 즉, 차원을 줄여서 더 효율적으로 단어를 표현하는 것이 목표!
| 비교 | 차원 크기 | 단어 간 의미 반영 |
|---|---|---|
| 원-핫 인코딩 | 크기가 너무 큼 (100,000) | ❌ 없음 |
| 임베딩 벡터 | 작음 (100~300) | ✅ 있음 |
원-핫 인코딩은 차원이 너무 크고 단어 간 관계를 표현할 수 없음
임베딩 벡터는 차원을 줄이면서도 의미를 반영할 수 있음!
📌 숫자는 어떤 기준으로 정해지는 걸까?
이 숫자는 그냥 랜덤한 값이 아니라, 단어의 의미를 학습하면서 최적의 숫자가 정해지는 거야!
즉, 임베딩 벡터 값들은 학습 과정에서 자동으로 결정됨.
🔹 예제
우리가 "I love you"를 임베딩 벡터로 변환한다고 가정하면, 원-핫 벡터와 달리 다음과 같이 표현될 수 있음.
| 단어 | 임베딩 벡터 |
|---|---|
| "I" | [0.1, 0.3, 0.5] |
| "love" | [0.4, 0.6, 0.2] |
| "you" | [0.7, 0.2, 0.8] |
💡 여기서 중요한 점은?
비슷한 의미의 단어들이 더 비슷한 벡터 값을 가지도록 학습된다는 점이야! 🔥
예를 들어, "love"와 "like"는 비슷한 단어니까 다음과 같이 유사한 벡터 값을 가질 수 있음.
"love" = [0.4, 0.6, 0.2]
"like" = [0.42, 0.58, 0.21]🔹 임베딩 벡터를 만드는 방법 (숫자가 결정되는 과정)
🎯 처음에는 벡터 값을 랜덤하게 초기화
1️⃣ Word2Vec (CBOW, Skip-gram)
Word2Vec은 비슷한 문맥에서 자주 등장하는 단어들은 비슷한 벡터를 가져야 한다는 아이디어를 기반으로 학습해. 🧠
💡 CBOW (Continuous Bag of Words)
- 주변 단어(Context)를 보고 중심 단어(Target Word)를 예측하는 방식
- 예제: "I love ___" → 모델이 "you"를 예측해야 함
💡 Skip-gram
- 중심 단어를 보고 주변 단어를 예측하는 방식
- 예제: "love" → "I", "you" 예측
🎯 학습 과정
1️⃣ 처음에는 모든 단어의 임베딩 벡터를 랜덤한 숫자로 초기화
2️⃣ CBOW나 Skip-gram을 이용해 예측하면서 손실 함수(loss function)를 최소화하는 방향으로 벡터를 업데이트 🔄
3️⃣ 여러 번 학습을 반복하면 비슷한 의미의 단어들이 비슷한 벡터 값으로 변환됨! 🚀
🔹 손실 함수(loss function)를 최소화하면서 벡터를 업데이트하는 과정
임베딩 벡터를 학습할 때, 손실 함수(loss function)를 최소화하는 방향으로 벡터 값을 조정하면서 최적의 벡터를 찾는 과정이 진행돼.
이 과정은 신경망을 학습할 때와 비슷하게 **경사 하강법(Gradient Descent)**과 **역전파(Backpropagation)**를 사용해 진행됨.
✅ 1. 기본적인 학습 흐름
🔹 초기 벡터는 랜덤 값
처음에는 단어 임베딩 벡터를 랜덤한 숫자로 초기화.
예: "love" = [0.3, -0.7, 0.2]
🔹 모델이 예측을 수행
예를 들어, **Word2Vec (Skip-gram)**이라면 중심 단어 **"love"**를 보고 주변 단어 **"I", "you"**를 예측하는 과정을 수행.
즉, "love" 벡터를 입력으로 넣어 "I"와 "you"를 예측해야 함.
🔹 손실(loss) 계산
- 모델이 예측한 값과 실제 정답(정답 단어 "I", "you") 사이의 차이를 계산
- 이 차이를 **손실 함수(loss function)**라고 함.
- 손실 함수가 높으면 벡터가 잘못된 방향으로 설정된 것, 낮으면 올바르게 학습된 것!
🔹 경사 하강법(Gradient Descent)으로 손실을 줄이도록 벡터 업데이트
1️⃣ 손실 함수를 미분하여 어떤 방향으로 벡터 값을 조정해야 손실이 줄어드는지 계산.
2️⃣ 벡터를 조금씩 조정하면서 손실을 줄여 나감 → 이를 역전파(Backpropagation) 과정이라고 함.
3️⃣ 업데이트 후 "love"의 벡터 값이 조정됨. 예: "love" = [0.35, -0.65, 0.22]
🔹 반복 학습 (수천~수백만 번 반복)
같은 과정을 여러 번 반복하면서 벡터가 점점 최적화됨.
결국 "love"와 "like" 같은 단어는 유사한 벡터 값을 갖게 됨!
즉, 모델이 예측한 주변 단어 확률이 실제 단어와 다르면 손실이 커지고, 정확할수록 손실이 작아짐.
이 손실을 줄이도록 벡터를 업데이트하는 과정이 학습 과정!
🎯 손실을 줄이는 과정
1️⃣ 손실을 줄이기 위해 벡터를 업데이트하는 방향을 계산
- 손실 함수를 벡터에 대해 미분
- 즉, 어떤 방향으로 벡터를 움직여야 손실이 줄어드는지 계산
2️⃣ 경사 하강법(Gradient Descent) 적용
- 벡터를 손실이 줄어드는 방향으로 조금씩 이동시키며 업데이트
3️⃣ 벡터 업데이트 후 다시 예측 → 손실 감소
- 벡터를 조정한 후 다시 예측을 수행하고, 손실이 줄었는지 확인
- 이 과정을 수천만 번 반복하면서 벡터가 최적의 값으로 수렴함 🚀
✅ 4. 예제: Word2Vec Skip-gram 학습 과정
예를 들어, "I love you" 문장을 Skip-gram 모델에서 학습한다고 해보자.
1️⃣ 초기 벡터 설정 (랜덤)
초기 단어 벡터를 랜덤하게 설정
| 단어 | 초기 벡터 |
|---|---|
| "I" | [0.3, -0.7, 0.2] |
| "love" | [0.1, 0.4, -0.6] |
| "you" | [-0.5, 0.2, 0.8] |
2️⃣ 중심 단어를 보고 주변 단어를 예측
중심 단어 "love"를 보고, 주변 단어 "I"와 "you"를 예측해야 함.
- 모델이 "love"를 입력하면 "I"가 나올 확률, "you"가 나올 확률을 계산.
3️⃣ 손실 함수 계산
모델이 "love" → "I"를 예측했는데 확률이 0.2라면?
- 실제 정답(1.0)과 차이가 크므로 손실이 큼.
- 따라서 "love" 벡터를 업데이트해서 "I"를 예측할 확률을 높이도록 조정해야 함.
4️⃣ 벡터 업데이트 (경사 하강법)
손실 함수를 줄이는 방향으로 벡터를 업데이트
| 단어 | 업데이트된 벡터 |
|---|---|
| "love" | [0.15, 0.35, -0.55] |
✅ 업데이트됨! 🎯
5️⃣ 반복 학습 🔄
이 과정을 수백만 개의 문장에 대해 반복하면, "love"와 "like" 같은 비슷한 단어들이 비슷한 벡터 값을 가지도록 학습됨! 🚀
📌 예제
| 단어 | 학습 전 벡터 | 학습 후 벡터 |
|---|---|---|
| "love" | 랜덤값 [0.3, -0.7, 0.2] | [0.4, 0.6, 0.2] |
| "like" | 랜덤값 | [0.42, 0.58, 0.21] |
결과: "love"와 의미가 비슷한 "like"가 비슷한 벡터를 가짐!
2. GloVe (Global Vectors for Word Representation)
GloVe(Global Vectors for Word Representation)는 단어들이 함께 등장하는 확률을 이용해서 단어 벡터를 학습하는 방법이야.
즉, 특정 단어가 문서에서 얼마나 자주 함께 등장하는지를 분석해서 의미를 반영하는 방식이야. 📊
1️⃣ "단어가 함께 등장한다"는 게 무슨 의미일까?
우리가 말을 할 때, 특정 단어들은 자주 함께 등장해.
📌 예제:
"A woman became a queen."
"A man became a king."위 문장들을 보면 "king"과 "man", "queen"과 "woman"이 비슷한 문맥에서 자주 등장해.
즉,
- "king"이라는 단어가 나오면 "man"도 자주 등장하고,
- "queen"이라는 단어가 나오면 "woman"도 자주 등장하는 패턴이 있는 거야.
GloVe는 이런 동시 등장 패턴을 분석해서 단어 벡터를 학습해! ✨
즉, 단어 간의 관계를 통계적으로 표현하는 것이야.
2️⃣ GloVe 학습 과정
🔹 1단계: "단어들이 문장에서 얼마나 자주 함께 등장하는지"를 계산
예를 들어,
- "king"이라는 단어가 나오면 "man"이 얼마나 자주 등장하는지?
- "queen"이라는 단어가 나오면 "woman"이 얼마나 자주 등장하는지?
🔹 2단계: 동시 등장 확률을 기반으로 행렬(matrix) 생성
- 각 단어가 다른 단어들과 함께 등장하는 확률을 기반으로 행렬(matrix)을 생성 🔢
- 즉, 각 단어의 "동시 등장 확률"을 이용해서 벡터를 만들게 돼.
🔹 3단계: 행렬을 줄이면서 비슷한 문맥에서 등장하는 단어들을 최적화
- 행렬을 축소하면서 비슷한 의미를 가진 단어들이 비슷한 벡터를 가지도록 조정 🔄
- 이 과정에서 벡터 간 의미적인 연산이 가능해짐!
🎯 GloVe는 어떻게 학습할까?
✅ GloVe는 단어가 같은 문장이나 주변 문맥에서 얼마나 자주 등장하는지(동시 등장 확률)를 분석해서 벡터를 학습해. 🔥
📌 즉, 단순히 단어 순서나 위치만 보는 것이 아니라, 전체적인 동시 등장 확률을 고려하여 단어 간 관계를 더 풍부하게 학습하는 것! 🚀
📌 예제: "king - man + woman = queen"
이걸 제대로 이해하려면, 먼저 단어 벡터에서 의미가 어떻게 반영되는지를 봐야 해. 🧠
1️⃣ "king"과 "man", "woman"의 관계
✅ "king"은 "man"과 관련 있음
✅ "queen"은 "woman"과 관련 있음
GloVe는 이런 연관성을 벡터에 반영할 수 있도록 학습해. 🔥
즉,
- "king"에서 "man"을 빼면 남는 의미가 "왕족"이라는 개념이고,
- 여기에 "woman"을 더하면 "queen"이라는 단어가 나온다는 것! 👑
2️⃣ 벡터 연산 예제
우리가 학습한 벡터들을 다음과 같이 설정한다고 가정하자.
| 단어 | 벡터 값 |
|---|---|
| king | [0.8, 0.6, 0.7] |
| man | [0.5, 0.2, 0.6] |
| woman | [0.4, 0.1, 0.5] |
벡터 연산을 수행하면:
queen = king - man + woman
= [0.8, 0.6, 0.7] - [0.5, 0.2, 0.6] + [0.4, 0.1, 0.5]
= [0.7, 0.5, 0.6] (≈ queen 벡터)✅ 결과적으로 "queen" 벡터와 거의 비슷한 값이 나옴! 🎉
이런 방식으로 단어 간 의미적인 관계를 벡터 연산으로 표현할 수 있는 것이 GloVe의 핵심이야! 🚀
3️⃣ "king - man + woman = queen"이 왜 성립하는 걸까?
이제 핵심을 설명해볼게! 🔎
- 우리가 "king"과 "man"을 자주 함께 봤다면, 그 벡터는 왕과 남성의 의미를 포함해야 해.
- 마찬가지로 "queen"과 "woman"도 함께 등장했으므로, 벡터는 왕과 여성의 의미를 포함해야 해.
- 따라서 "king" 벡터에서 "man"의 영향을 빼고, "woman"의 영향을 더하면 "queen"이 되는 것! 👑✨
📌 예제: 벡터 연산 (더 큰 값으로 계산)
가정:
| 단어 | 벡터 값 |
|---|---|
| king | [8.0, 6.3, 7.1] |
| man | [4.5, 3.0, 6.0] |
| woman | [4.0, 3.3, 4.8] |
계산하면:
queen = king - man + woman
= [8.0, 6.3, 7.1] - [4.5, 3.0, 6.0] + [4.0, 3.3, 4.8]
= [7.5, 6.6, 5.9] (≈ queen 벡터)✅ 실제 "queen" 벡터와 유사한 값이 나옴! 🎯
이런 벡터 연산이 가능한 이유는 GloVe가 단어들 간의 관계를 확률적으로 학습했기 때문이야! 📊
🔹 GloVe의 특징 🏆
✅ 단어 간 동시 등장 확률을 이용해 벡터를 학습함
✅ 단어 의미를 벡터 연산으로 표현할 수 있음 (ex: king - man + woman = queen)
✅ 문맥이 아니라 전체 코퍼스(데이터셋)에서 통계적으로 학습하는 방식
✅ 비슷한 단어는 비슷한 벡터를 가지게 됨
✅ "king"과 "queen"의 의미적 관계를 벡터 연산으로 표현 가능
📌 결론: 실제 벡터 값은 학습을 통해 손실 함수를 줄여가면서 최적의 벡터를 찾는 과정에서 결정됨! 🚀
3. FastText 🚀
FastText는 기존 Word2Vec의 단점을 보완한 모델이야.
즉, 단어를 그대로 벡터로 바꾸는 게 아니라, 단어를 여러 개의 작은 단위(Subword)로 쪼개서 벡터를 학습하는 방식! 🔥
🔹 왜 FastText가 필요할까?
Word2Vec이나 GloVe는 단어 단위로 벡터를 학습하기 때문에 새로운 단어를 잘 처리하지 못함.
📌 예제: Word2Vec의 한계
- Word2Vec에서 "unhappiness"를 학습한 적이 없다면? → ❌ "unhappiness"라는 단어를 이해할 수 없음 😢
- 하지만 "happy", "happiness", "unhappy" 같은 단어는 알고 있음.
- 그런데도 "unhappiness"는 전혀 새로운 단어처럼 취급되기 때문에 유사한 의미를 찾지 못함.
🔥 FastText는 이런 문제를 해결하기 위해 단어를 Subword(부분 단어) 단위로 학습함! 🔥
🔹 FastText는 어떻게 작동할까?
✅ 단어를 여러 개의 작은 조각(서브워드, n-gram)으로 나눔
✅ 각 서브워드도 벡터를 학습하여 전체 단어의 벡터를 생성
✅ 새로운 단어라도 그 단어의 일부 조각들을 사용해서 의미를 유추할 수 있음
📌 예제: "unhappiness"를 학습할 때
FastText는 "unhappiness"를 학습할 때 부분 단어(subword)로 쪼갬.
| 원래 단어 | 3-gram 기준 서브워드 |
|---|---|
| "unhappiness" | ["unh", "hap", "ppi", "ine", "ess"] |
✅ 각 부분(서브워드)도 학습되므로,
✅ "happiness"와 "unhappiness"는 비슷한 벡터를 가질 수 있음! 🔄
✅ "happiness"를 학습한 적이 있다면 "unhappiness"도 비슷한 벡터로 변환 가능! 🎉
🔹 FastText의 특징 🏆
✅ 단어를 부분 단어(Subword, n-gram)로 쪼개서 벡터를 학습
✅ 처음 보는 단어(신조어, 복합어)도 이해할 수 있음
✅ 한국어 같은 어절 변화가 많은 언어(예: "먹다" → "먹었습니다", "먹고" 등)에서도 효과적
✅ 비슷한 단어가 비슷한 벡터를 가질 가능성이 높음
📌 결론: FastText는 기존 Word2Vec의 한계를 보완하여 새로운 단어도 이해할 수 있도록 학습하는 강력한 방법! 🚀
4. Transformer 기반 임베딩 (BERT, GPT) 🚀
문맥(Context)에 따라 단어의 의미가 변하는 방식.
📌 예: "bank" (은행 vs 강둑) → 문맥에 따라 다른 벡터로 변환!
최근에는 BERT, GPT 같은 Transformer 모델에서 임베딩 벡터를 학습하는 방법이 더 많이 사용돼. 🔥
📌 기존 Word2Vec, GloVe의 문제점
❌ 단어 벡터가 고정됨 → 문맥에 따라 다른 의미를 표현하지 못함
📌 예제:
- "The bank is near the river" 🏞
- "I deposited money in the bank" 🏦
여기서 "bank"는 다른 의미인데, Word2Vec에서는 같은 벡터를 사용함 😢
🔥 해결책: BERT, GPT
Transformer 모델은 단어 벡터를 문맥(Context)에 따라 다르게 학습해.
즉, "bank"라는 단어가 어떤 문장에서 쓰이는지에 따라 벡터 값이 변함.
📌 예제:
| 문장 | "bank" 벡터 |
|------|-------------|
| "The bank is near the river" | 강둑 의미로 변환 → [0.5, -0.2, 0.8] |
| "I deposited money in the bank" | 은행 의미로 변환 → [0.9, -0.1, 0.3] |
✅ 즉, Transformer 기반 모델은 "bank"가 문장에서 어떤 의미로 쓰였는지를 주변 단어를 통해 학습하고, 그에 따라 벡터를 다르게 설정하는 거야!
✅ 3. 문맥(Context)을 반영하는 원리
Transformer 기반 모델에서는 🔥 Self-Attention(자기-어텐션) 메커니즘을 사용해서 문장에서 각 단어가 어떤 의미로 쓰였는지를 학습해.
즉, 단어의 주변 단어(문맥)를 보고 의미를 다르게 해석할 수 있음!
📌 예제: "bank"가 포함된 두 문장
1️⃣ "The bank is near the river."
✅ "bank"의 주변 단어: "river"(강), "near"(가까운)
✅ 모델이 "bank"의 의미를 "강둑"으로 해석하도록 벡터를 조정 🔄
➡ "bank" 벡터 → [0.5, -0.2, 0.8] (강둑 의미)
2️⃣ "I deposited money in the bank."
✅ "bank"의 주변 단어: "money"(돈), "deposited"(입금하다)
✅ 모델이 "bank"의 의미를 "은행"으로 해석하도록 벡터를 조정 🔄
➡ "bank" 벡터 → [0.9, -0.1, 0.3] (은행 의미)
🔥 즉, Transformer 기반 모델은 "bank"가 문장에서 어떤 의미로 쓰였는지를 주변 단어를 통해 학습하고, 그에 따라 벡터를 다르게 설정하는 거야! 🚀
✅ 4. Transformer 모델이 동적인 벡터를 생성하는 과정
💡 이걸 가능하게 하는 핵심 기술 = Self-Attention (자기-어텐션)
Transformer 모델은 단어 하나하나를 독립적으로 해석하는 게 아니라, 문장 전체를 보고 단어의 관계를 학습해.
즉, 각 단어가 다른 단어들과 얼마나 관련이 있는지를 계산하는 과정이 들어가! 📊
📌 Self-Attention이 문맥을 반영하는 방법
✅ 1️⃣ "bank"라는 단어를 처리할 때 그 주변 단어들을 확인
- "river"가 가까우면 → "강둑" 의미 강화
- "money"가 가까우면 → "은행" 의미 강화
✅ 2️⃣ 각 단어의 의미를 조정하기 위해 가중치(Attention Score)를 다르게 부여
- "bank" → "river" (강둑 의미로 연결)
- "bank" → "money" (은행 의미로 연결)
✅ 3️⃣ 이 과정을 통해 "bank"의 벡터가 문맥에 따라 동적으로 변경됨! 🔄
🔥 즉, Transformer 모델은 같은 단어라도 문맥에 따라 다르게 벡터를 생성할 수 있는 거야! 🚀
기존 RNN 기반 Seq2Seq 모델과 Transformer 모델의 차이점 🔍
기존 RNN 기반 Seq2Seq 모델과 Transformer 모델의 가장 큰 차이점은 어떻게 문장을 학습하고 디코딩하는지의 방식이야.
📌 기존 RNN 계열 모델(RNN, LSTM, GRU) → 문장의 마지막에 도달한 후 컨텍스트 벡터(Context Vector)를 통해 문장을 생성
📌 Transformer 모델 → 단어들의 의미를 학습하고 한 번에 모든 단어를 고려하면서 문장을 생성
🔹 RNN 계열 모델: 순환 신경망 기반 학습 방식
✅ RNN, LSTM, GRU 등 순환 신경망(RNN 계열 모델)이 단어를 한 번에 하나씩 처리
✅ 단어를 순서대로 처리하면서, 이전 단어 정보를 현재 단어와 함께 사용하여 숨겨진 상태(hidden state)를 업데이트
✅ 문장을 한 단어씩 처리하면서 마지막 시점의 숨겨진 상태(hidden state)를 컨텍스트 벡터(Context Vector)로 만든다
✅ 마지막 단어까지 처리되면, 최종적으로 컨텍스트 벡터(Context Vector)가 만들어짐
✅ 이 컨텍스트 벡터는 문장의 전체 의미를 함축한 고정된 크기의 벡터
✅ 디코더는 이 벡터를 사용해 새로운 문장을 생성할 수 있음
📝 예시: 입력 → "I love you"
| 입력 단어 | Hidden State |
|---|---|
| "I" | hidden state 1 |
| "love" | hidden state 2 |
| "you" | hidden state 3 (최종 컨텍스트 벡터) |
✅ 컨텍스트 벡터: h3 (고정된 크기의 벡터)
✅ 마지막 hidden state h3는 전체 문장의 의미를 담고 있는 벡터가 됨.
✅ 이 벡터 h3는 디코더에게 전달됨.
3️⃣ 디코더(Decoder): 컨텍스트 벡터를 받아 문장을 생성
✅ 인코더의 마지막 hidden state(h3)가 됨됨
✅ 컨텍스트 벡터(h3)를 받아서 디코더가 문장을 생성하는 방식
✅ 한 번에 한 단어씩 생성하며, 이전에 생성한 단어를 입력으로 받아 다음 단어를 예측.
입력: 컨텍스트 벡터 (h3)
출력: "나는" → "너를" → "사랑해"
1️⃣ h3를 받아서, 디코더가 처음 단어 "나는"을 생성.
2️⃣ 그 후 "나는"을 다시 입력하여 "너를"을 생성.
3️⃣ "너를"을 다시 입력하여 "사랑해"를 생성.
📌 문제점: 긴 문장의 경우 정보 손실이 발생할 수 있음.
✅ 2. 예제: "I love you" 변환 과정
🔹 ① 단어를 숫자로 변환
우리가 "I love you"라는 문장을 숫자로 변환한다고 가정하자.
(실제로는 Word2Vec, FastText 같은 단어 임베딩 기법을 사용하지만, 이해를 돕기 위해 단순한 숫자로 표현!)
| 단어 | 임베딩 벡터 |
|---|---|
| "I" | [0.1, 0.3, 0.5] |
| "love" | [0.4, 0.6, 0.2] |
| "you" | [0.7, 0.2, 0.8] |
✅ 이제 이 단어들을 RNN 인코더에 넣어보자!
🔹 ② 인코더가 순차적으로 단어를 처리 (RNN 동작)
📌 RNN(또는 LSTM, GRU)은 숨겨진 상태(hidden state, h)를 계속 업데이트하면서 단어를 처리한다.
1️⃣ 첫 번째 단어: "I"
- 처음에는 아무 정보도 없으므로, 초기 hidden state
h0 = [0, 0, 0] - "I"를 입력하면 새로운
h1이 생성됨. h1 = tanh(W1 * "I" + b1)→ 예:h1 = [0.2, 0.5, 0.7]
2️⃣ 두 번째 단어: "love"
- 이전 hidden state(
h1)와 현재 단어(love)를 조합하여 새로운h2를 만듦. h2 = tanh(W2 * "love" + U2 * h1 + b2)→ 예:h2 = [0.6, 0.4, 0.9]
3️⃣ 세 번째 단어: "you"
- 마찬가지로,
h2와 "you"를 입력하여h3을 만듦. h3 = tanh(W3 * "you" + U3 * h2 + b3)→ 예:h3 = [0.9, 0.1, 0.4]
✅ 마지막 hidden state = 컨텍스트 벡터(Context Vector)
📌 이제 h3 = [0.9, 0.1, 0.4]가 컨텍스트 벡터가 됨!
📌 이 벡터는 "I love you" 문장의 전체 의미를 포함한 고정된 크기의 벡터 표현!
✅ 3. 왜 컨텍스트 벡터를 사용하는 걸까?
🔹 입력 문장의 길이가 다르더라도 같은 크기의 벡터로 표현할 수 있음
🔹 예: "Hello"(1단어)와 "I really love programming"(4단어)도 모두 고정된 크기 벡터로 변환 가능
🔹 이렇게 변환하면 문장을 비교하거나 디코더에서 새로운 문장을 생성할 때 편리!
🔹 디코더가 문장 생성 시 참조할 핵심 정보 제공
✅ 디코더는 이 컨텍스트 벡터를 받아서 새로운 문장을 생성함 (예: 번역 결과).
✅ 4. 한 문장으로 요약 ✨
📌 "인코더는 입력 문장을 고정된 크기의 벡터(Context Vector)로 변환하는 역할을 한다."
✅ 단어들을 순차적으로 처리하면서 hidden state를 업데이트
✅ 마지막 hidden state가 문장의 전체 의미를 담은 컨텍스트 벡터가 됨
📌 이제 Transformer는 이 컨텍스트 벡터 없이, 모든 단어의 관계를 직접 학습하는 방식으로 더 효율적인 NLP 모델을 만든 거야! 🚀
✅ 3. Seq2Seq 모델의 문제점 🚨
🔹 컨텍스트 벡터의 정보 손실
✅ 긴 문장을 하나의 벡터(h3)로 압축하면 중요한 정보가 손실될 수 있음.
✅ 예를 들어, 100개의 단어가 있는 문장을 1개의 벡터로 변환하면 앞부분의 정보가 소실될 수 있음.
🔹 병렬 처리 불가능
✅ RNN 계열 모델은 단어를 순차적으로 처리해야 하므로 속도가 느림.
✅ GPU 병렬 처리가 어려움.
🔹 장기 의존성 문제(Long-Term Dependency)
✅ 문장이 길어질수록 앞부분 단어의 영향을 뒷부분에서 받기 어려움.
✅ 예제:
The cat that lived in the house near the river was very happy.➡ "happy"가 "cat"을 가리킨다는 걸 RNN이 기억하기 어려울 수 있음.
🔥 그래서 등장한 것이 Transformer!
✅ 이를 보완하기 위해 어텐션만으로 인코더와 디코더를 구성하는 모델을 제안 🚀
✅ Transformer는 컨텍스트 벡터 없이 모든 단어 간의 관계를 Self-Attention으로 학습함.
✅ Multi-head self-attention을 이용한 병렬 처리가 특징!
1️⃣ 입력된 모든 단어를 동시에 학습
✅ Transformer는 단어를 한 번에 입력받고, 단어들 간의 관계를 분석함.
✅ 이를 위해 Self-Attention 메커니즘을 사용해서 각 단어가 문장에서 어떤 단어와 관련이 있는지 학습함.
2️⃣ 각 단어가 다른 단어들과 얼마나 연관이 있는지를 계산 (Self-Attention)
✅ "I"는 "love", "you"와 어떤 관계인지 학습.
✅ "love"는 "I", "you"와 어떤 관계인지 학습.
✅ "you"는 "I", "love"와 어떤 관계인지 학습.
📌 즉, Transformer는 단어별로 서로 얼마나 영향을 주고받는지를 계산해서 학습하는 거야!
3️⃣ 각 단어를 독립적으로 디코딩 (병렬 처리 가능)
✅ Transformer는 디코더에서 단어를 하나씩 순차적으로 출력하는 것이 아니라, 한 번에 여러 단어를 예측할 수 있음.
✅ 즉, "나는", "너를", "사랑해"를 동시에 예측할 수 있음.
🔹 Transformer의 핵심 아이디어: 어텐션만으로 시퀀스 모델링
✅ Transformer는 위 문제를 해결하기 위해 어텐션 메커니즘만을 이용한 모델을 제안했다.
✅ 즉, RNN 없이도 문장 내 단어 간의 관계를 효과적으로 학습할 수 있는 구조를 설계했다.
🔥 핵심 구성 요소:
✅ Self-Attention (자기-어텐션)
📌 각 단어가 문장 내 다른 단어들과 얼마나 관련이 있는지를 계산하는 기법.
📌 예제:
The animal didn't cross the street because it was too tired.➡ 여기서 "it"이 무엇을 가리키는지(= animal) 파악하기 위해 어텐션이 사용될 수 있다.
✅ Multi-Head Attention
📌 Self-Attention을 여러 개 병렬로 수행하는 방식.
📌 문장에서 서로 다른 의미를 강조하는 여러 개의 "관점"을 동시에 학습할 수 있음.
📌 예제: "bank"라는 단어가 문맥에 따라 "은행"인지 "강둑"인지 구별해야 할 때, 다른 헤드들이 각각 다른 문맥을 학습할 수 있음.
✅ 포지셔널 인코딩 (Positional Encoding)
📌 RNN은 입력 순서를 자연스럽게 반영하지만, Transformer는 병렬 연산을 위해 순서를 무시한다.
📌 이를 보완하기 위해, 입력 단어의 위치 정보를 추가적으로 학습하도록 함.
✅ 훈련(train) 과정 vs 추론(inference) 과정
📌 인코더(Encoder)에 문장을 넣어 학습하는 과정(Train)과, 디코더(Decoder)를 통해 문장을 생성하는 과정(Inference)은 별개로 진행돼!
하지만 Seq2Seq 모델을 설명할 때는 훈련 과정과 추론 과정이 연결되어 있기 때문에 한 번에 설명한 것이야.
✅ 1. 인코더-디코더 구조는 학습과 추론이 따로 이루어짐
🔹 Step 1: 훈련 과정 (Training) → 모델 학습
1️⃣ 인코더(Encoder)가 문장을 입력받아 hidden state(Context Vector)를 생성
2️⃣ 디코더(Decoder)가 정답 문장을 입력받아 학습하면서, 다음 단어를 예측하도록 손실 함수를 줄임
3️⃣ 모델이 학습되면서 점점 더 정확하게 예측할 수 있도록 가중치 업데이트
📌 즉, 훈련(train) 과정에서는 모델이 학습하는 단계이므로 "정답 문장"을 함께 사용함!
🔹 Step 2: 추론 과정 (Inference) → 실제 문장 생성
1️⃣ 학습된 인코더 모델이 입력 문장을 받아 hidden state를 생성
2️⃣ 학습된 디코더 모델이 하나씩 단어를 예측하며 문장을 생성
3️⃣ 디코더가 멈출 때까지 단어를 반복해서 생성
📌 즉, 추론 과정에서는 정답 문장이 없고, 모델이 스스로 문장을 만들어내는 과정!
✅ 2. RNN 기반 Seq2Seq 모델에서 학습(train)과 추론(inference) 과정
📌 1) 훈련(Train) 과정
💡 예제: "I love you" → "나는 너를 사랑해" 번역 모델 학습
훈련 과정에서는 디코더가 정답을 알고 있는 상태에서 학습함.
🔹 과정
1️⃣ 인코더에 입력 문장을 넣음 ("I love you")
| 입력 단어 | Hidden State |
|---|---|
| "I" | hidden state h1 |
| "love" | hidden state h2 |
| "you" | hidden state h3 (컨텍스트 벡터) |
2️⃣ 컨텍스트 벡터(h3)를 디코더에 전달
3️⃣ 디코더에 정답 문장을 입력하여 다음 단어 예측을 학습
| 입력 | 예측 |
|---|---|
| START | "나는" |
| "나는" | "너를" |
| "너를" | "사랑해" |
4️⃣ 예측 결과와 실제 정답을 비교하여 손실(loss) 계산
5️⃣ 손실을 최소화하도록 가중치 업데이트 → 모델이 점점 똑똑해짐!
📌 2) 추론(Inference) 과정
💡 학습된 모델을 이용해서 새로운 문장을 번역하는 과정!
훈련 때는 정답 문장을 제공했지만, 추론 과정에서는 디코더가 하나씩 예측하면서 문장을 생성해야 함.
🔹 과정
1️⃣ 인코더에 입력 문장을 넣음 ("I love you")
2️⃣ 컨텍스트 벡터 h3를 디코더에 전달
3️⃣ 디코더가 하나씩 단어를 예측하며 문장을 생성
| Hidden State | 예측된 단어 |
|---|---|
| h3 | "나는" |
| "나는" | "너를" |
| "너를" | "사랑해" |
4️⃣ 디코더가 END 토큰을 예측하면 문장 생성을 멈춤 🚀
✅ 3. Transformer에서도 훈련과 추론이 분리됨
📌 1) Transformer 훈련(Train) 과정
✅ Transformer에서도 훈련 과정에서는 정답 문장을 이용하여 디코더를 학습함.
1️⃣ 입력 문장을 인코더에 넣음
"I love you"→ Self-Attention 학습
2️⃣ 출력 문장의 일부를 디코더에 넣어 학습
| 입력 | 예측 |
|---|---|
| START | "나는" |
| "나는" | "너를" |
| "너를" | "사랑해" |
3️⃣ 예측 결과와 실제 정답을 비교하여 손실을 줄이도록 학습
📌 2) Transformer 추론(Inference) 과정
✅ 학습된 모델을 이용하여 새로운 문장을 생성하는 과정
1️⃣ 인코더에 입력 문장을 넣어 문맥을 이해함
2️⃣ 디코더가 START를 입력받아 첫 번째 단어 예측
3️⃣ 이전까지 생성된 단어들을 기반으로 다음 단어 예측을 반복
4️⃣ 예측된 문장이 끝날 때까지 반복해서 단어를 생성
📌 즉, Transformer도 훈련(train)과 추론(inference)이 분리되어 있음!
✔ 훈련(train)과 추론(inference)은 분리된 과정이 맞음!
✔ 훈련 과정에서는 정답 문장을 제공하여 학습, 추론 과정에서는 모델이 스스로 단어를 생성함.
✔ Seq2Seq 모델(RNN)과 Transformer 모두 이 원리를 따름.
✔ 하지만 Transformer는 전체 문맥을 동시에 학습할 수 있어서 더 효율적! 🚀
🔹 Transformer의 장점 🚀
✅ 병렬 연산 가능 (속도 향상)
- RNN은 데이터를 한 단계씩 처리해야 하지만, Transformer는 병렬 연산이 가능하다.
- GPU에서 빠르게 연산할 수 있어 학습 속도가 훨씬 빠름.
✅ 장기 의존성 문제 해결
- 어텐션 메커니즘을 통해 모든 단어가 서로 직접 연결될 수 있어, 먼 거리의 단어들끼리도 쉽게 관계를 배울 수 있음.
✅ 더 좋은 성능
- 번역, 질의응답(QA), 문서 요약 등 다양한 NLP 작업에서 기존 RNN 기반 모델보다 성능이 뛰어남.
🔹 Transformer 구조 요약 ✨
✅ 입력 단어를 벡터로 변환한 후, Self-Attention과 Multi-Head Attention을 이용해 관계를 학습.
✅ 포지셔널 인코딩을 추가하여 단어 순서 정보를 보존.
✅ 인코더-디코더 구조를 사용하여 입력 시퀀스를 이해하고 출력 시퀀스를 생성.
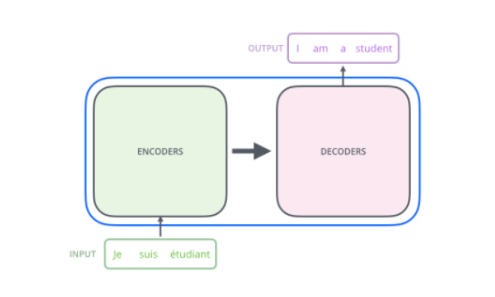
Transformer 개요
✅ Encoder와 Decoder 구조
✅ Encoding은 여러 개의 Encoder를 쌓아 올려 만든 것, 논문에서는 6개를 쌓아올림.
✅ Decoding은 Encoding과 동일한 개수만큼의 Decoder를 쌓은 것.
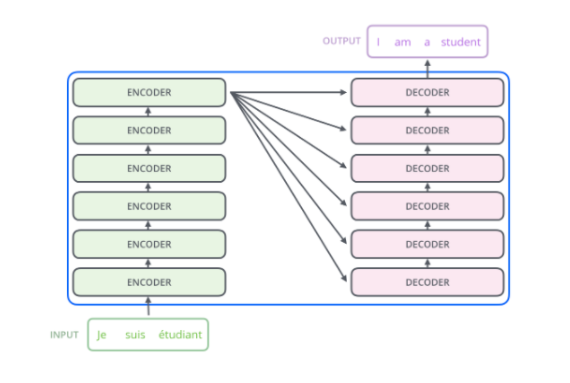
✅ Transformer에서 인코더와 디코더 개수가 동일해야 하는 이유
📌 꼭 인코더 개수만큼 디코더를 써야 하는 건 아니지만, 논문에서는 6개씩 사용한 이유가 있어!
✅ Transformer 구조에서 인코더 개수(Encoder Layers)와 디코더 개수(Decoder Layers)는 반드시 동일할 필요는 없지만, 일반적으로 같게 설정하는 것이 성능적으로 좋기 때문이야.
🔹 1. 정보 손실을 방지하기 위해
✅ 인코더는 입력 문장을 점점 더 고차원적인 특징으로 변환하면서 정보를 압축해.
✅ 디코더는 그 정보를 다시 풀어서(디코딩) 문장을 생성해야 함.
✅ 만약 인코더가 6개인데, 디코더가 2개만 있다면?
- 인코더에서 너무 고차원적인 정보를 압축해버려서, 디코더가 충분히 해석할 수 없을 가능성이 큼.
- 결과적으로 번역 성능이나 문장 생성 품질이 떨어질 수 있음.
✅ 반대로, 디코더가 너무 많으면? - 디코더가 필요 이상의 복잡한 연산을 수행하게 되어 연산량이 증가하고 과적합(Overfitting) 위험이 커질 수 있음.
➡ 그래서 일반적으로 인코더 개수와 디코더 개수를 동일하게 설정하면 가장 균형이 맞음!
✅ 하지만 꼭 같을 필요는 없다! (실제로 다르게 쓰는 경우)
📌 Transformer 모델을 적용하는 작업에 따라, 인코더 개수와 디코더 개수를 다르게 설정할 수도 있어!
💡 실제 사례들
✅ BERT (Bidirectional Encoder Representations from Transformers) → 인코더만 사용 (디코더 없음)
✅ GPT (Generative Pre-trained Transformer) → 디코더만 사용 (인코더 없음)
✅ T5 (Text-To-Text Transfer Transformer) → 인코더와 디코더 사용 (개수 동일)
✅ Whisper (OpenAI의 음성 모델) → 인코더와 디코더 개수 다르게 설정
📌 예를 들어,
- 인코더 개수를 늘리고, 디코더 개수를 줄이면?
- 더 많은 정보를 압축해서 효율적인 문장 이해 가능 (하지만 생성 능력은 제한될 수 있음).
- 디코더 개수를 늘리고, 인코더 개수를 줄이면?
- 인코딩을 간단히 하고 더 창의적인 문장을 생성할 수 있음 (예: 이미지 캡셔닝 같은 작업).
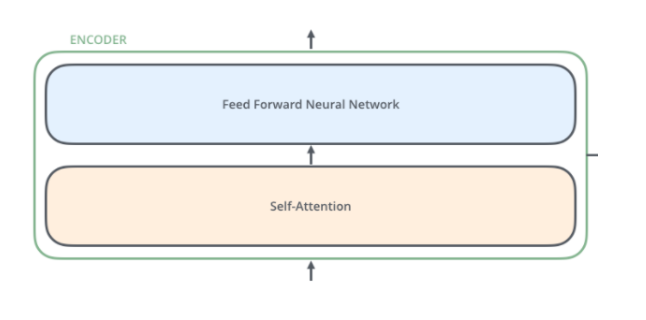
✅ Transformer의 Encoder 구조
✅ Encoder들은 모두 같은 구조를 가지나 동일한 Weight을 공유하지 않음.
✅ 2개의 Sub-layer를 가짐:
- Self-Attention Layer
- Feed Forward Neural Network Layer
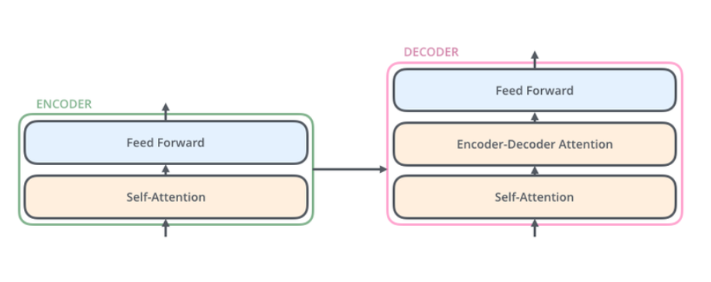
✅ Transformer의 Decoder 구조
✅ Decoder는 3개의 Sub-layer를 가짐:
- Self-Attention Layer
- Encoder-Decoder Attention Layer
- Feed Forward Layer
🔹 1. Encoder 구조: 2개의 Sub-layer
Transformer의 인코더는 입력 문장을 벡터로 변환하는 역할을 해.
각 인코더 블록(Encoder Layer)은 2개의 Sub-layer로 구성됨.
📌 인코더의 구조
🔹 (1) Self-Attention Layer
🔹 (2) Feed Forward Neural Network (FFN) Layer
✅ (1) Self-Attention Layer (자기-어텐션 레이어)
📌 역할:
- 문장에서 각 단어가 다른 단어들과 얼마나 관련이 있는지를 계산하는 역할.
- 모든 단어가 서로를 참고할 수 있도록 함!
- 예를 들어, "I love NLP" 문장에서 "I"가 "love"와 관련이 있는지를 학습하는 과정.
📌 어떻게 동작할까?
1️⃣ 각 단어를 Query(Q), Key(K), Value(V) 세 가지 벡터로 변환
2️⃣ Query와 Key의 내적(dot product)을 계산하여 각 단어가 다른 단어들과 얼마나 관련이 있는지 점수(Attention Score)를 매김
3️⃣ 이 점수를 확률로 변환하여(Value) 각 단어의 정보를 가중 평균
4️⃣ 최종적으로 각 단어의 새로운 벡터 표현을 생성
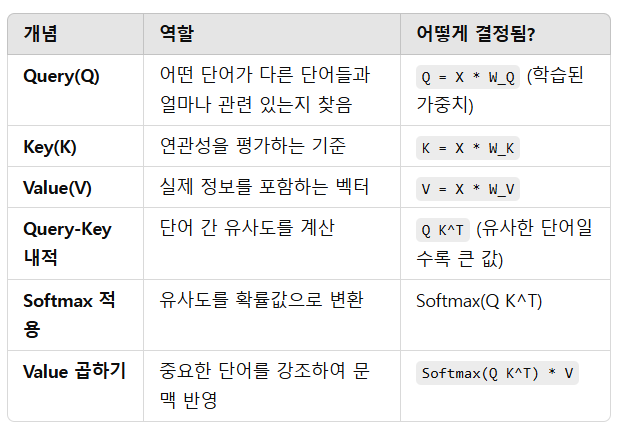
✅ Query(Q)와 Key(K)는 어떻게 설정할까?
Transformer에서 Query(Q), Key(K), Value(V)는 Self-Attention과 Encoder-Decoder Attention에서 핵심적인 역할을 해!
즉, 각 단어가 다른 단어들과 얼마나 관련이 있는지(어텐션 스코어)를 계산하기 위해 사용되는 벡터들이야.
🔹 1. Query(Q), Key(K), Value(V)의 개념
📌 Self-Attention에서 Query(Q), Key(K), Value(V) 역할
- Query(Q): "나는 누구와 관련이 있을까?"를 찾는 벡터
- Key(K): "나와 얼마나 관련이 있는지?"를 평가하는 벡터
- Value(V): "관련 있는 정보를 담은 벡터"
📌 예제:
"I love NLP."Self-Attention을 적용할 때,
- "love"가 "I"와 "NLP"와 얼마나 관련이 있는지 계산하려면?
- "love"는 Query(Q), "I"와 "NLP"는 각각 Key(K)
- 즉, "love"의 Query(Q)와 "I"의 Key(K)를 내적(dot product)하여 "love"가 "I"와 얼마나 관련 있는지를 확인하는 거야.
📌 이제 Query(Q)와 Key(K)를 어떻게 설정하는지 수식으로 알아보자! 🔥
🔹 2. Query(Q), Key(K), Value(V) 벡터 설정 과정
Transformer에서 Query(Q), Key(K), Value(V)는 학습된 가중치 행렬을 곱해서 생성됨.
📌 1) 입력 벡터 설정
먼저 각 단어를 벡터(Word Embedding)로 변환한다고 가정하자.
📌 예제 문장: "I love NLP."
| 단어 | 벡터 값 |
|---|---|
| "I" | [0.1, 0.3, 0.5] |
| "love" | [0.4, 0.6, 0.2] |
| "NLP" | [0.7, 0.2, 0.8] |
✅ 이제 각 단어 벡터(입력 벡터)를 Query, Key, Value로 변환해야 해!
📌 2) Query(Q), Key(K), Value(V) 만들기
각 입력 벡터(단어 벡터)에 학습 가능한 가중치 행렬
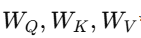
을 곱해서 Query, Key, Value를 생성해.
🔹 3. 가중치 행렬
💡 가중치 행렬은 학습(train) 과정에서 자동으로 최적의 값이 결정됨!
✅ 즉, 우리가 직접 정하는 게 아니라 모델이 학습하면서 자동으로 최적의 값으로 업데이트됨!
📌 2) 가중치 행렬의 초기 값은 어떻게 정할까?
💡 초기에는 랜덤 값으로 설정하고, 학습하면서 최적의 값으로 조정함.
✅ 훈련이 시작될 때는 가중치 행렬은 작은 랜덤 값으로 초기화됨.
✅ 이후, 모델이 데이터를 학습하면서 손실 함수(loss function)를 최소화하는 방향으로 가중치가 조정됨.
📌 학습 과정
1️⃣ 처음에는 랜덤한 값으로 설정
2️⃣ Query(Q), Key(K), Value(V)를 생성하여 Self-Attention 연산 수행
3️⃣ 예측 결과와 정답을 비교하여 손실(loss)을 계산
4️⃣ 역전파(Backpropagation) + 경사 하강법(Gradient Descent)으로 가중치를 업데이트
5️⃣ 반복해서 학습하면서 점점 더 좋은 값을 가지게 됨
📌 3) 왜 가중치 행렬이 필요할까?
💡 각 단어의 의미를 다른 관점에서 해석할 수 있도록 하기 위해!
📌 예제: "I love NLP"라는 문장에서,
✅ Query("love")는 "I"와 "NLP" 중 어느 쪽과 더 관련이 있는지를 결정해야 함.
✅ Key("I", "NLP")는 자신과 Query가 얼마나 관련 있는지를 평가해야 함.
✅ Value("I", "NLP")는 관련 있는 정보를 넘겨줘야 함.
➡ 가중치 행렬을 학습하면서, 모델이 각 단어가 다른 단어들과의 관계를 더 잘 파악할 수 있게 됨!
🔥 즉, 가중치 행렬은 모델이 문맥을 학습할 수 있도록 돕는 역할을 함! 🚀
📌 Query, Key, Value 수식 정리:
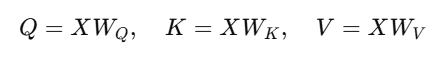
X = 단어 임베딩 벡터 (예: "I", "love", "NLP")
Query(Q) = 입력 벡터 * W_Q
Key(K) = 입력 벡터 * W_K
Value(V) = 입력 벡터 * W_V✅ 즉, Query, Key, Value는 입력 벡터에 학습된 가중치 행렬을 곱해서 생성하는 것! 🚀
📌 Query(Q)와 Key(K)로 어텐션 스코어 계산하기

📌 즉, Self-Attention의 핵심 과정:
1️⃣ Query 벡터와 Key 벡터를 내적(dot product) 해서 유사도를 계산
2️⃣ Softmax 함수를 적용하여 확률값으로 변환
3️⃣ Value 벡터와 곱해서 최종적인 문맥 정보를 얻음 🚀
🔹 1. Query와 Key를 내적(dot product)하는 게 왜 유사도를 계산하는 걸까?
💡 내적(Dot Product)은 벡터의 방향이 얼마나 비슷한지를 측정하는 연산이야!
즉, 두 벡터를 내적하면 서로 얼마나 비슷한지를 수치로 나타낼 수 있음.
📌 (1) 벡터 내적이란?
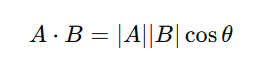
✅ 벡터의 방향이 같을수록(각도가 0도에 가까울수록) 내적 값이 커지고, 방향이 다르면(각도가 90도 이상이면) 내적 값이 작아짐.
✅ 즉, 내적이 크다는 건 두 벡터가 비슷한 방향을 가진다는 의미야!
➡ Self-Attention에서 내적을 사용하면, 두 단어가 얼마나 유사한지를 측정할 수 있음!
📌 (2) Self-Attention에서 Query와 Key 내적하기
Self-Attention에서는 Query(Q)와 Key(K)를 내적하여 두 단어가 얼마나 관련이 있는지를 측정함.
예제 문장:
"The cat sat on the mat."여기서, "cat"과 "sat"의 관계를 분석한다고 가정하자.
1️⃣ 각 단어 벡터를 Query(Q)와 Key(K)로 변환
Query("cat") = [0.5, 0.2, 0.1]
Key("sat") = [0.4, 0.3, 0.2]2️⃣ 내적(dot product) 계산
Attention Score = Q("cat") · K("sat")
= (0.5 * 0.4) + (0.2 * 0.3) + (0.1 * 0.2)
= 0.2 + 0.06 + 0.02
= 0.28👉 0.28이라는 값이 나왔는데, 이 값이 클수록 "cat"과 "sat"이 더 관련 있다는 의미!
💡 즉, Query와 Key의 내적 결과가 높으면 두 단어가 서로 연관성이 높다는 뜻!
📌 Softmax 적용 과정
Self-Attention에서는 Query와 Key의 내적 결과(Attention Score)를 Softmax를 적용해 확률 값으로 변환합니다.
1️⃣ Query와 Key의 내적을 통한 Score 계산
각 단어의 Query와 문장의 모든 단어 Key를 내적하여 Attention Score를 계산합니다.
Attention Score("cat", "cat") = 0.50
Attention Score("cat", "sat") = 0.28
Attention Score("cat", "mat") = 0.102️⃣ Softmax를 적용하여 확률값으로 변환
📌 Softmax 함수 공식
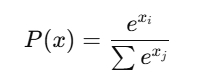

📌 Softmax의 역할
📌 exp(지수 함수)는 Attention Score를 확률값으로 변환하는 Softmax 함수에서 사용됨.
- exp(지수 함수)를 적용하면 큰 값과 작은 값의 차이가 극대화됨.
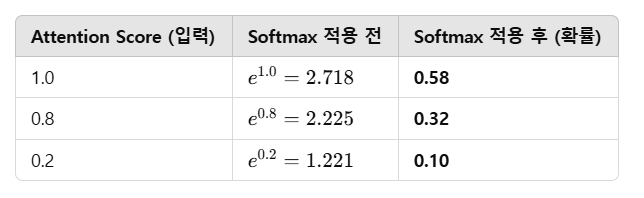
📌 exp()를 사용하지 않으면, 값이 비슷한 경우 확률 차이가 크지 않음.
📌 exp()를 사용하면 큰 값과 작은 값의 차이가 더 커져서, 중요한 단어에 더 많은 가중치를 줄 수 있음!
exp(0.50) = 1.6487
exp(0.28) = 1.3231
exp(0.10) = 1.1052📌 Softmax 결과
| 단어 | 계산식 | 확률값 |
|---|---|---|
| cat | 1.6487 / (1.6487 + 1.3231 + 1.1052) | 0.39 |
| sat | 1.3231 / (1.6487 + 1.3231 + 1.1052) | 0.31 |
| mat | 1.1052 / (1.6487 + 1.3231 + 1.1052) | 0.26 |
💡 Softmax를 적용하면 모든 Attention Score가 0~1 사이의 확률 값이 되고, 확률의 합이 1이 됩니다!
3️⃣ Softmax 없이 사용하면?
Softmax를 사용하지 않고 Attention Score를 그대로 사용하면:
🔹 값이 음수이거나 너무 작은 값이 나올 수 있음.
🔹 확률처럼 해석하기 어려움.
🔹 학습이 안정적으로 이루어지지 않을 가능성이 높음.
🔥 Softmax를 사용하면 Attention Score를 확률 값으로 변환할 수 있어 학습이 더 안정적임! 🚀
4️⃣ Softmax 결과를 Value 벡터와 곱하는 이유
Softmax 결과를 Value(V) 벡터와 곱하면, 문장에서 중요한 단어들만 강조된 벡터를 만들 수 있음! 즉, 문맥(Context)에 맞게 정보가 조정됨!
📌 Value 벡터 설정
Value("cat") = [0.2, 0.4, 0.6]
Value("sat") = [0.3, 0.5, 0.7]
Value("mat") = [0.1, 0.3, 0.2]📌 Softmax 가중치와 곱하기
최종 벡터 = (0.39 * Value("cat")) + (0.31 * Value("sat")) + (0.26 * Value("mat"))
= (0.39 * [0.2, 0.4, 0.6]) + (0.31 * [0.3, 0.5, 0.7]) + (0.26 * [0.1, 0.3, 0.2])
= [0.078, 0.156, 0.234] + [0.093, 0.155, 0.217] + [0.026, 0.078, 0.052]
= [0.197, 0.389, 0.503]💡 "cat"의 최종 벡터는 [0.197, 0.389, 0.503]이 됨!
➡ 즉, "cat"이 문장에서 "sat"과 "mat"과 어떻게 연결되는지를 반영한 벡터가 생성됨.
🔥 이 과정이 바로 "Self-Attention을 통해 문맥(Context)이 반영된 벡터를 만드는 과정"! 🚀
5️⃣ 왜 Query-Value를 곱해야 할까?
💡 Query(Key와 내적하여 얻은 어텐션 확률)와 Value를 곱하는 이유는 "문장에서 중요한 정보를 강조하고, 불필요한 정보를 억제하기 위해서입니다."
📌 Self-Attention의 목표
- 각 단어가 문장 내 다른 단어들과 얼마나 관련 있는지를 학습하는 것.
- Query와 Key를 통해 계산한 "연관성(Attention Score)"을 단순한 수치로만 두면 의미가 없음.
- 이 값을 실제 단어 정보(Value 벡터)와 연결해야 의미가 생김!
📌 Query-Key를 통해 계산한 가중치를 Value 벡터에 반영
Query와 Key를 통해 얻은 어텐션 확률(Softmax 값)을 Value 벡터에 곱하면:
✔ 중요한 단어의 정보를 더 강조하고,
✔ 중요하지 않은 단어의 정보는 덜 반영할 수 있음!
📌 예제 문장: "The cat sat on the mat."
- "cat"의 문맥 정보를 만들려면?
- "cat"과 관련이 높은 단어: "sat" → 높은 어텐션 값 ✅
- "cat"과 관련이 낮은 단어: "on" → 낮은 어텐션 값 ❌
➡ 따라서 "sat"의 Value 벡터를 더 많이 반영하고, "on"의 Value 벡터는 거의 반영하지 않도록 조정함.
🔹 즉, Query-Key를 통해 구한 어텐션 확률을 Value 벡터와 곱하면, "문맥을 반영한 단어 표현"이 생성됨!
6️⃣ Self-Attention의 최종 계산 공식
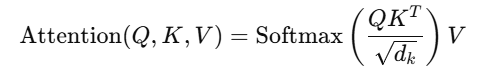
📌 각 항목의 의미
1️⃣ Query와 Key의 내적 → "단어 간의 연관성(어텐션 점수)"을 계산.
2️⃣ Softmax 적용 → 연관성을 확률 값(0~1)으로 변환하여 중요한 단어에 높은 가중치를 부여.
3️⃣ Value 벡터와 곱하기 → "문맥을 반영한 최종 단어 벡터" 생성.
🔥 즉, Self-Attention의 최종 목표는 각 단어의 의미를 문맥(Context) 기반으로 변환하는 것! 🚀
📌 Value 벡터 생성 과정
Value 벡터도 Query, Key와 마찬가지로, 입력 단어 벡터(Word Embedding)에 가중치 행렬을 곱해서 생성됨!
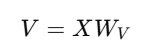
📌 각 항목의 의미

즉, 처음에는 랜덤한 값을 가지지만, 학습이 진행되면서 점점 더 문맥을 반영할 수 있도록 조정됨! 🎯
📌 2) 왜 Value 벡터도 변환해야 할까?
Value 벡터를 그냥 단어 벡터로 사용하지 않고, 학습 가능한 가중치 행렬을 곱해서 변환하는 이유는?
✅ Value 벡터를 조정하면 모델이 더 유연하게 단어 관계를 학습할 수 있기 때문!
예를 들어,
- "cat"의 Value 벡터가 항상
[0.1, 0.2, 0.3]이면, "cat"이 어떤 문장에서든 같은 정보만 유지됨. - 하지만, Self-Attention을 거쳐 조정된 Value 벡터는 문맥에 따라 달라질 수 있음!
📌 "The cat sat"에서는 "sat"과 더 연관된 벡터로 조정됨.
📌 "The cat chased the mouse"에서는 "chased"와 더 연관된 벡터로 조정됨.
🔥 즉, Value 벡터는 문맥에 맞게 조정될 수 있도록 학습 가능해야 하고, 그래서 학습 가능한 가중치를 곱해서 생성하는 것! 🚀
📌 Self-Attention과 Value 벡터의 역할
✔ Query-Key로 계산한 유사도를 Softmax를 통해 확률값으로 변환한 후, 이를 Value 벡터에 곱하면 문맥이 반영된 최종 벡터가 생성됨!
✔ Value 벡터는 학습 가능한 가중치 행렬을 곱해서 생성되며, 처음에는 랜덤 값이지만 학습을 통해 최적화됨!
🔥 즉, Query-Key는 "어떤 단어가 중요한가"를 찾는 과정이고, Value는 "그 중요한 정보를 반영하는 과정"이야! 🚀
💡 결과
✅ Self-Attention을 통해 문장 내에서 중요한 단어들을 학습하고 연결함.
✅ 기존 RNN처럼 한 방향으로 순서대로 학습하는 것이 아니라, 모든 단어들이 동시에 서로의 관계를 학습할 수 있음!
💡 이 과정이 Transformer의 핵심이며, 이를 통해 문맥을 효과적으로 반영할 수 있음!
🧠 Feed Forward Neural Network (FFN) Layer
📌 역할
각 단어의 표현을 더 복잡한 형태로 변환하는 비선형 변환 역할을 합니다. 즉, Self-Attention을 거친 단어 벡터를 더 의미 있게 조정하는 과정입니다.
📌 어떻게 동작할까? 🤔
1️⃣ 각 단어 벡터를 하나의 신경망에 넣고 변환
- 첫 번째 선형 변환 (Linear Transformation) → ReLU 활성화 함수 적용
- 두 번째 선형 변환 (Linear Transformation) → 최종 출력
💡 Self-Attention을 거친 벡터를 바로 사용하지 않는 이유?
➡ 더 복잡한 관계를 학습할 수 있도록 비선형 변환을 적용하기 위해서! 🚀
🔹 1. Self-Attention 결과 벡터는 선형 변환만 적용된 상태
Self-Attention을 거친 벡터는 단어 간의 관계를 반영한 값이지만, 연산 과정이 선형적인 연산(내적, Softmax, Value 곱하기)만 포함되어 있습니다.
벡터를 만들긴 했지만, 이 벡터가 충분히 복잡한 패턴을 학습하지 못할 수도 있습니다.
그러므로, 추가적인 비선형 변환을 적용하여 더 풍부한 의미를 학습할 필요가 있습니다! 이를 위해 두 번의 선형 변환과 ReLU 활성화 함수를 사용합니다. 🔥
📌 (1) 첫 번째 선형 변환
X' = W_1 X + b_1📌 X: Self-Attention 결과 벡터
📌 W, b: 학습 가능한 가중치 행렬과 편향(Bias)
✅ 이 과정에서 벡터 차원이 증가합니다. (보통 d→4d)
✅ 차원을 확장함으로써 더 많은 정보를 저장할 수 있도록 합니다.
📌 (2) ReLU 활성화 함수 적용 (비선형 변환)
X'' = ReLU(X')✅ ReLU(Rectified Linear Unit)라는 비선형성을 추가하는 활성화 함수 적용 ✅ 음수 값은 0으로 만들고, 양수 값은 그대로 유지
✅ 이를 통해 비선형적인 특징을 학습할 수 있게 됨!
📌 ReLU 적용 이유 💡 (왜 비선형 변환이 필요할까?)
- 선형 변환만 사용하면 모든 연산이 단순한 행렬 곱셈이므로 복잡한 패턴을 학습할 수 없음 ❌
- ReLU를 적용하면 단어의 다의성, 긴 거리의 문맥 관계 등 복잡한 패턴을 학습할 수 있음! ✅
📌 (3) 두 번째 선형 변환 (최종 출력)
Y = W_2 X'' + b_2✅ ReLU를 적용한 벡터를 다시 원래 차원으로 축소하는 과정입니다. 즉, 4d→d로 차원을 다시 축소 ✅ 차원을 다시 줄이면서 비선형 변환이 적용된 문맥 정보가 최종 벡터로 반환됩니다.
🔹 3. 전체 과정 정리 ✅
Self-Attention을 거친 후, 더 깊은 의미를 학습하기 위해 다음 단계를 추가합니다!
1️⃣ Self-Attention 수행
2️⃣ 첫 번째 선형 변환: 벡터 차원을 확장하여 더 많은 정보 저장
3️⃣ ReLU 활성화 함수 적용: 비선형성을 추가하여 더 복잡한 관계 학습
4️⃣ 두 번째 선형 변환: 벡터 차원을 다시 원래 크기로 줄이면서 최종 벡터 출력
💡 결과 🏆
- 각 단어가 더 복잡한 의미를 가질 수 있도록 벡터를 변환합니다.
- Self-Attention이 문맥(Context)을 학습하는 역할이라면, FFN은 그 문맥을 더 풍부한 벡터로 변환하는 역할을 합니다!
✅ 인코더와 디코더의 차이점: 왜 디코더가 따로 필요할까?
💡 인코더에서 이미 단어들의 관계와 의미를 벡터로 학습했는데, 왜 디코더에서 다시 Self-Attention을 적용해야 할까?
➡ 인코더는 입력 문장을 이해하는 역할을 하고, 디코더는 새 문장을 생성하는 역할을 하기 때문!
즉, Transformer에서 인코더와 디코더는 서로 다른 목적을 가지고 있음. 🚀
이제 인코더와 디코더의 차이점을 자세히 알아보자!
🔹 1. 인코더(Encoder)의 역할
📌 인코더는 입력 문장을 하나의 의미 있는 벡터 표현으로 변환하는 역할!
📌 (1) 인코더의 동작 과정
인코더는 다음과 같은 과정으로 입력 문장을 처리합니다.
1️⃣ 입력 문장을 벡터로 변환 (Word Embedding + Positional Encoding 적용)
2️⃣ Self-Attention을 통해 단어들 간의 관계를 학습
3️⃣ Feed Forward Network를 적용하여 비선형 변환 수행
4️⃣ N개(논문에서는 6개)의 인코더 블록을 통과하면서 정보를 점점 더 압축
5️⃣ 최종적으로, 문장 전체를 표현하는 벡터(고차원 의미 벡터)를 생성하여 디코더로 전달
💡 즉, 인코더의 목표는 "입력 문장의 의미를 벡터로 변환하는 것"!
➡ 하지만, 이 벡터를 바로 디코더에서 사용할 수 없는 이유가 있음!
📌 (2) 왜 인코더 벡터를 그대로 쓰면 안 될까?
💡 인코더가 만든 벡터는 "입력 문장의 의미"를 담고 있지만, "출력 문장을 생성"하는 과정과는 다름!
즉, 디코더는 새로운 문장을 만들어야 하기 때문에, "입력 문장을 이해한 벡터"를 "출력 문장을 만드는 벡터"로 변환하는 과정이 필요합니다!
➡ 디코더는 "출력 문장이 자연스럽게 생성될 수 있도록" 인코더 벡터를 변환해야 함.
🔹 2. 디코더(Decoder)의 역할
📌 디코더는 인코더가 만든 의미 벡터를 받아, 올바른 출력을 생성하는 역할!
📌 (1) 디코더의 동작 과정
디코더는 인코더의 출력 벡터를 받아서 새로운 문장을 생성하는 과정을 수행합니다.
1️⃣ 디코더의 Self-Attention을 통해, 현재까지 생성된 단어들 사이의 관계를 학습
2️⃣ Encoder-Decoder Attention을 통해, 입력 문장과 생성 중인 문장을 연결
3️⃣ Feed Forward Network를 적용하여 최종적인 벡터를 생성
4️⃣ Softmax를 사용하여 최종적으로 확률 분포를 계산 → 다음 단어를 생성
5️⃣ 이 과정을 반복하여 최종적으로 문장을 완성
💡 즉, 디코더는 "입력 문장"을 기반으로 "출력 문장"을 한 단어씩 생성하는 과정!
📌 (2) 왜 디코더도 Self-Attention을 해야 할까?
💡 디코더는 이전에 생성된 단어들과의 관계를 학습해야 하기 때문!
➡ 출력 문장을 생성할 때, 앞에서 나온 단어들을 참고해서 자연스럽게 문장을 만들어야 함.
📌 예제: 영어 → 한국어 번역
- 입력: "I love you"
- 출력: "나는 너를 사랑해"
- "나는"이 생성된 후, "너를"을 생성할 때 "나는"을 참고해야 함.
- "사랑해"를 생성할 때, "나는 너를"을 참고해야 함.
❗ 만약 디코더가 Self-Attention을 사용하지 않으면, 각 단어를 독립적으로 생성해서 문맥이 깨질 수 있음!
🔥 즉, 디코더의 Self-Attention은 "출력 문장 내부에서 단어들의 관계를 학습하는 과정"! 🚀
📌 (3) Encoder-Decoder Attention이 필요한 이유
💡 Encoder-Decoder Attention은 인코더에서 만든 의미 벡터를 활용하여, 출력 문장을 더 자연스럽게 만들기 위해 필요함!
즉, 입력 문장과 출력 문장을 연결하는 과정!
📌 Encoder-Decoder Attention의 역할
- 입력 문장의 정보를 활용하여, 현재까지 생성된 출력 문장이 올바른 방향으로 가도록 유도
- 예를 들어, "I love you"를 번역할 때 "love"와 "사랑해"가 올바르게 연결되도록 도와줌
- ❗ 만약 이 Attention이 없으면, 출력 문장이 엉뚱하게 생성될 가능성이 높아짐!
🔥 즉, Encoder-Decoder Attention은 입력과 출력을 연결하는 핵심적인 과정!
✅ 4. 최종 정리
✔ 인코더는 입력 문장을 이해하는 역할 → 문장 전체를 벡터로 압축하여 의미를 학습
✔ 디코더는 입력 문장을 기반으로 새로운 문장을 생성하는 역할 → 인코더 벡터를 활용하여 단어를 하나씩 생성
✔ 인코더의 정보를 그대로 사용하면 "출력 문장 생성"에 필요한 문맥이 부족할 수 있어서, 디코더에서 추가적인 변환 과정이 필요함
✔ 디코더가 Self-Attention을 하는 이유 → 이전에 생성된 단어들과의 관계를 학습하기 위해!
✔ 디코더의 Encoder-Decoder Attention이 중요한 이유 → 인코더가 이해한 내용을 활용하여 올바른 출력을 만들기 위해!
🔥 즉, Transformer의 디코더는 단순히 인코더 벡터를 그대로 쓰는 게 아니라, "출력 문장을 만들 수 있도록" 추가적인 변환을 수행하는 거야! 🚀
🔹 2. Decoder 구조: 3개의 Sub-layer
Transformer의 디코더는 인코더에서 받은 정보를 바탕으로 문장을 생성하는 역할을 합니다.
각 디코더 블록(Decoder Layer)은 3개의 Sub-layer로 구성됩니다.
📌 디코더의 구조
🔹 (1) Self-Attention Layer
🔹 (2) Encoder-Decoder Attention Layer
🔹 (3) Feed Forward Neural Network (FFN) Layer
(1) Self-Attention Layer (자기-어텐션 레이어)
📌 역할
- 디코더가 생성하는 문장에서 각 단어 간의 관계를 학습하는 역할
- 이전까지 생성된 단어들만 참고하도록 마스킹(Masking)을 적용함
- 예를 들어, "나는"을 생성한 후 "너를"을 생성할 때 "사랑해"를 미리 보면 안 되므로 마스킹이 필요함
📌 어떻게 동작할까? 🤔
1️⃣ 인코더의 Self-Attention과 동일한 방식으로 각 단어의 관계를 학습
2️⃣ 하지만 미래 단어를 참고하지 않도록 Masking을 적용
3️⃣ 생성된 단어들끼리의 관계를 반영하여 새로운 벡터를 생성
🔹 1. 디코더에서 마스킹이 필요한 이유
📌 디코더의 목표
- 인코더에서 전달받은 문장 정보를 바탕으로 출력 문장을 생성해야 함
- 하지만, 출력 문장은 한꺼번에 나오지 않고 하나씩 생성되면서 예측해야 함
📌 (1) 학습할 때: 정답 문장이 주어지는 경우
🔥 디코더의 학습 과정에서는 정답 문장(출력 문장)이 주어짐
📌 예제: 영어 → 한국어 번역
- 입력: "I love you"
- 출력(정답): "나는 너를 사랑해"
📌 문제점 🤯
만약 디코더가 "나는 너를 사랑해" 전체를 한 번에 본다면?
- "나는"을 예측할 때 "너를 사랑해"도 알고 있음 → 쉽게 예측 가능 😱
- "너를"을 예측할 때 "사랑해"도 알고 있음 → 쉽게 예측 가능 😱
즉, 학습이 제대로 되지 않고 단어를 보고 그대로 따라 쓰는 방식으로 학습될 위험이 있음! ❌
➡ 디코더가 "현재 단어까지"의 정보만 사용해서 다음 단어를 예측하도록 제한해야 함!
📌 (2) 마스킹(Masking)의 역할
💡 마스킹은 디코더가 미래 단어를 보지 못하도록 가리는 역할을 함
➡ 현재까지 생성된 단어만 참고하여 예측할 수 있도록 제한함!
📌 마스킹이 적용된 학습 예제
| 디코더 입력 (Self-Attention) | 마스킹 적용 후 보이는 단어 |
|---|---|
| START 나는 너를 사랑해 | START |
| START 나는 너를 사랑해 | START 나는 |
| START 나는 너를 사랑해 | START 나는 너를 |
| START 나는 너를 사랑해 | START 나는 너를 사랑해 |
✅ 즉, "나는"을 예측할 때 "너를 사랑해"를 미리 보면 안 되고,
✅ "너를"을 예측할 때 "사랑해"를 미리 보면 안 됨!
➡ 그래서 마스킹을 적용해서 디코더가 미래 단어를 볼 수 없도록 함! 🚀
✅ 디코더(Self-Attention & Masking)의 동작 방식: 학습(train)과 추론(inference) 비교
💡 디코더에서 Self-Attention을 적용할 때, 학습할 때와 추론할 때 방식이 같은지?
➡ 기본적인 구조는 같지만, 실행 방식은 다름! 🚀
➡ 특히 Masking(미래 단어 가리기) 방식이 학습과 추론에서 차이가 있음.
🔹 학습(Train)과 추론(Inference)에서 디코더의 동작 차이
🔹 1. 학습할 때(Train) vs 추론할 때(Inference)의 차이점
📌 (1) 학습할 때 (Train Mode)
- 정답 문장이 주어지므로, 디코더가 전체 문장을 한 번에 볼 수 있음.
- 하지만 미래 단어를 미리 보면 안 되므로 Masking을 적용.
- 즉, 마스크된 미래 단어는 볼 수 없도록 설정하고, 현재까지의 단어만 사용해서 예측.
🔹 학습 과정
1️⃣ 입력 문장 → 인코더에 전달 → 인코더의 출력 생성
2️⃣ 디코더의 Self-Attention 수행 (미래 단어 Masking 적용)
3️⃣ Encoder-Decoder Attention 수행 (인코더 출력과 결합)
4️⃣ Feed Forward Network 적용 → 최종 출력 단어 예측
5️⃣ 예측된 단어와 정답 비교 → 손실(loss) 계산 → 가중치 업데이트
📌 (2) 추론할 때 (Inference Mode)
- 추론할 때는 정답 문장이 주어지지 않음!
- 따라서, 디코더가 단어를 하나씩 생성하면서 예측을 진행해야 함.
- Masking은 동일하게 적용되지만, 한 번에 전체 문장을 입력하는 것이 아니라, 단어를 점진적으로 생성함.
🔹 추론 과정
1️⃣ 입력 문장 → 인코더에 전달 → 인코더의 출력 생성
2️⃣ 디코더의 입력으로 START 토큰을 제공 → 첫 번째 단어 예측
3️⃣ 예측된 첫 번째 단어를 다시 디코더 입력으로 사용 → 두 번째 단어 예측
4️⃣ 이 과정을 반복하면서 문장을 생성
5️⃣ END 토큰이 나올 때까지 반복
💡 즉, 학습할 때는 정답 문장이 있어 한 번에 연산하지만, 추론할 때는 한 단어씩 예측하면서 진행해야 함!
💡 Masking을 적용해서 현재 단어까지의 정보만 보고 학습하도록 만듦!
💡 결과:
디코더가 단어를 하나씩 순차적으로 생성하도록 학습함.
이전 단어들만 참고하여 문장을 만들어 나갈 수 있도록 함.
🔹 2. Transformer의 추론 과정
추론(Inference)할 때는 인코더가 입력 문장을 벡터로 변환하고, 디코더가 그 벡터를 이용해 학습된 내용을 바탕으로 단어를 하나씩 생성하는 방식이야.
하지만, 그동안 학습한 문장을 단순히 "찾아"서 출력하는 게 아니라, 학습된 확률 모델을 기반으로 "새로운 문장을 생성"하는 방식이야! 🚀
📌 Transformer의 동작 흐름
1️⃣ 사용자가 입력 문장을 인코더에 넣음
2️⃣ 인코더가 입력 문장을 벡터로 변환 (Self-Attention 수행)
3️⃣ 디코더가 하나씩 단어를 생성 (처음에는 START 토큰 입력)
4️⃣ 생성된 단어를 다시 디코더에 넣고 다음 단어를 예측 (반복)
5️⃣ END 토큰이 나오면 문장 생성을 멈춤
🔥 즉, Transformer는 학습 데이터에서 가장 적절한 문장을 찾아 출력하는 게 아니라, "확률적으로 가장 적절한 단어들을 하나씩 생성"하는 방식! 🚀
🔹 3. Transformer는 문장을 "찾는 것"이 아니라, "생성하는 것"
💡 Transformer는 학습할 때 단어들의 관계를 확률 모델로 학습함!
즉, 이전에 본 문장을 그대로 출력하는 게 아니라, 확률적으로 가장 적절한 단어를 하나씩 생성하는 것!
📌 (1) 왜 학습한 문장을 단순히 "찾는 것"이 아닐까?
📌 기계 번역(예: 영어 → 한국어 번역) 예제
- 입력: "I love you"
- 출력할 문장(한국어 번역): "나는 너를 사랑해"
이 문장을 학습 데이터에서 본 적이 있을 수도 있지만,
Transformer는 단순히 "I love you"라는 문장이 등장했던 기존 문장을 찾아서 복사(copy)하는 게 아님!
➡ "I love you"라는 입력이 주어졌을 때, 확률적으로 가장 적절한 단어를 생성하는 것!
즉, 학습할 때 "love" 다음에 "you"가 나올 확률이 높다는 걸 배운 것처럼,
추론할 때 "나는" 다음에는 "너를"이 나올 확률이 높다고 판단하여 확률적으로 가장 적절한 단어를 생성하는 것!
💡 즉, Transformer는 학습한 문장을 "찾는 것"이 아니라, 학습된 확률 모델을 기반으로 "새로운 문장을 생성"하는 것! 🚀
📌 (2) Transformer는 확률적으로 가장 적절한 단어를 선택함
🔥 Transformer가 단어를 하나씩 생성할 때, 각 단어가 올 확률을 계산하고 가장 확률이 높은 단어를 선택!
📌 예제: "나는 너를 사랑해" 예측 과정
➡ 즉, 가장 확률이 높은 단어를 하나씩 예측하면서 문장을 생성하는 것!
🔹 4. Transformer 추론 과정 예제
📌 (1) 사용자가 문장을 입력
input_sentence = "I love you"📌 (2) 인코더가 입력 문장을 벡터로 변환
1️⃣ "I love you"를 Word Embedding과 Positional Encoding을 거쳐 벡터로 변환
2️⃣ Self-Attention을 통해 단어 간 관계를 학습
3️⃣ 최종적으로 인코더는 입력 문장의 의미를 담은 벡터를 생성하여 디코더에 전달
📌 (3) 디코더가 한 단어씩 생성
1️⃣ 첫 번째 입력으로 START를 디코더에 넣음
2️⃣ 디코더가 START 다음 단어를 예측 → "나는"을 생성
3️⃣ "나는"을 다시 디코더에 입력하여 다음 단어 예측 → "너를"을 생성
4️⃣ "나는 너를"을 입력하여 다음 단어 예측 → "사랑해"를 생성
5️⃣ END 토큰이 나오면 종료
✅ Transformer가 START 토큰에서 어떻게 첫 번째 단어(예: "나는")를 뽑아내는지?
💡 디코더는 처음에는 START 토큰 하나만 입력으로 받는데, 어떻게 "나는"을 뽑아낼까?
➡ "나는"을 뽑아내는 과정도 확률 기반으로 이루어짐!
즉, 디코더는 학습 과정에서 배운 확률 분포를 바탕으로 첫 번째 단어를 생성하는 것! 🚀
🔹 Transformer 디코더가 첫 단어를 생성하는 과정
📌 Transformer의 디코더는 어떻게 첫 단어를 생성할까?
🔥 디코더는 단순히 START 라는 단어를 기억해서 "나는"을 내뱉는 게 아니라, 확률적으로 가장 적절한 단어를 선택하는 방식으로 동작!
📌 (1) 첫 번째 단어 생성 과정 (START 토큰 → "나는")
🔥 추론(Inference)할 때, 디코더가 단어를 예측하는 첫 번째 단계
1️⃣ 디코더는 첫 입력으로 START 토큰을 받음
- 디코더는 이 START를 보고 학습한 내용을 기반으로 가장 적절한 첫 번째 단어를 예측해야 함.
2️⃣ 디코더 내부에서 Self-Attention과 Encoder-Decoder Attention을 수행
- Self-Attention: START 토큰 자체를 참고 (다른 단어가 없으므로 의미 없음)
- Encoder-Decoder Attention: 인코더에서 넘어온 입력 문장 벡터를 기반으로 가장 적절한 단어를 찾음
3️⃣ 디코더는 Softmax를 사용하여 첫 번째 단어의 확률 분포를 계산
- "나는" / "저는" / "그는" 등 다양한 단어가 나올 가능성이 있음.
- Transformer는 학습된 확률 모델을 기반으로, 가장 확률이 높은 단어를 선택!
📌 (2) Softmax를 이용한 첫 번째 단어 예측
디코더는 START를 입력받아 다음 단어로 나올 확률이 높은 단어들을 계산함.
(예: "나는", "저는", "그는" 등)
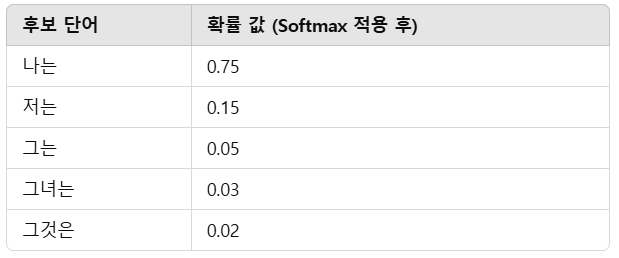
📌 확률이 가장 높은 "나는"(0.75)이 선택됨!
➡ 즉, 디코더는 "나는"을 선택해서 첫 번째 단어로 출력하는 것! 🚀
📌 (3) 첫 번째 단어 예측 후, 두 번째 단어 예측 과정
1️⃣ "나는"이 첫 번째 단어로 선택되면,
2️⃣ 이제 디코더의 입력이 START → "나는"이 됨.
3️⃣ 디코더는 "나는"을 입력으로 받아 다음 단어 "너를"을 예측.
4️⃣ 이 과정을 반복해서 "나는 너를 사랑해"가 완성됨!
🔥 즉, Transformer는 학습된 확률 모델을 기반으로 가장 적절한 단어를 예측하면서 문장을 생성하는 방식! 🚀
🔹 Encoder-Decoder Attention Layer
📌 역할
- 인코더가 만든 정보를 참고하여 디코더가 올바른 문장을 생성하도록 함.
- 즉, 입력 문장과 생성할 문장을 연결하는 역할!
- 예를 들어, "I love you"를 "나는 너를 사랑해"로 번역할 때,
- "I"는 "나는"과 연결
- "love"는 "사랑해"와 연결
- "you"는 "너를"과 연결
📌 어떻게 동작할까? 🤔
1️⃣ 인코더에서 나온 hidden state를 Key(K), Value(V)로 사용
2️⃣ 디코더에서 Query(Q)를 만들고, 인코더의 Key와 Attention Score를 계산
3️⃣ 인코더에서 나온 정보를 활용하여 디코더가 다음 단어를 예측할 수 있도록 도와줌
🔥 Encoder-Decoder Attention는 디코더가 인코더의 정보를 활용하여 올바른 문장을 생성할 수 있도록 도와주는 역할을 해!
즉, 입력 문장(영어)과 출력 문장(한국어)의 관계를 연결해주는 과정이야! 🚀
🔹 1. Encoder-Decoder Attention이 필요한 이유
- Transformer의 디코더는 문장을 생성해야 하지만,
- 출력 문장("나는 너를 사랑해")을 입력 문장("I love you")과 올바르게 연결해야 함!
- 만약 Encoder-Decoder Attention이 없으면?
- "나는", "너를", "사랑해"를 랜덤으로 생성할 수도 있음! 😱
🔥 Encoder-Decoder Attention은 입력 문장의 의미를 참고하여, 디코더가 올바른 문장을 생성하도록 도와주는 역할! 🚀
🔹 2. Encoder-Decoder Attention의 동작 과정
Encoder-Decoder Attention의 핵심 개념은 "입력 문장과 출력 문장을 연결하는 것"!
➡ 즉, 입력 문장("I love you")의 의미를 잘 반영하여 출력 문장("나는 너를 사랑해")을 만들 수 있도록 도와주는 역할!
📌 (1) Encoder의 출력 벡터를 Key(K)와 Value(V)로 사용
- 인코더는 입력 문장을 Self-Attention을 통해 처리하여 각 단어의 의미를 벡터로 변환
- 즉, 각 단어를 Key(K), Value(V)로 설정!
| 단어 | 인코더의 최종 벡터 (예제 값) |
|---|---|
| "I" | [0.5, 0.2, 0.7] |
| "love" | [0.8, 0.3, 0.5] |
| "you" | [0.6, 0.4, 0.9] |
➡ 이 벡터들은 Encoder-Decoder Attention에서 Key(K)와 Value(V)로 사용됨!
📌 (2) 디코더에서 Query(Q) 생성
- 디코더는 현재까지 생성된 단어들을 보고, 다음 단어를 예측해야 함.
- 따라서, 디코더는 생성된 단어(출력 문장)의 정보를 Query(Q)로 변환하여 Key(K)와 비교함.
| 단어 | 디코더의 Query(Q) 벡터 (예제 값) |
|---|---|
| "나는" | [0.4, 0.1, 0.6] |
➡ 디코더는 "나는"이라는 단어가 입력 문장의 어떤 부분과 관련이 있는지 판단해야 함.
➡ 이를 위해 Query(Q)와 Key(K)의 내적을 계산함.
📌 (3) Query(Q)와 Key(K) 내적하여 Attention Score 계산
- 디코더의 Query(Q)와 인코더의 Key(K)를 내적(dot product)하여, 입력 단어들과의 연관성을 계산함.
Query(Q)와 Key(K) 내적 계산 예제
Attention Score("나는", "I") = (0.4 * 0.5) + (0.1 * 0.2) + (0.6 * 0.7) = 0.64
Attention Score("나는", "love") = (0.4 * 0.8) + (0.1 * 0.3) + (0.6 * 0.5) = 0.65
Attention Score("나는", "you") = (0.4 * 0.6) + (0.1 * 0.4) + (0.6 * 0.9) = 0.82📌 즉, "나는"이라는 단어는 "you"와 가장 연관이 높다고 계산됨!
➡ 하지만 번역을 위해선 "I"와 더 강한 연결을 만들어야 함.
➡ Transformer는 학습을 통해 이러한 관계를 조정함.
📌 (4) Softmax를 적용하여 Attention 확률 계산
- Softmax를 적용하여 Attention Score를 확률값으로 변환
| 단어 | Attention Score | Softmax 확률 |
|---|---|---|
| "I" | 0.64 | 0.30 |
| "love" | 0.65 | 0.31 |
| "you" | 0.82 | 0.39 |
➡ 확률이 가장 높은 단어가 출력 문장에 가장 많이 반영됨.
➡ 이 확률 값을 이용하여 Value 벡터와 곱해서 최종 벡터를 생성!
📌 (5) Value(V) 벡터와 곱하여 최종 Context 벡터 생성
- Attention 확률과 Value 벡터를 곱해서 최종 문맥(Context) 벡터를 생성함.
Context Vector = (0.30 * Value("I")) + (0.31 * Value("love")) + (0.39 * Value("you"))➡ 즉, 입력 문장의 정보를 반영한 최종 벡터가 만들어짐!
➡ 이 벡터를 기반으로 디코더는 "나는" 이후에 올 단어를 예측함. 🚀
🔹 Feed Forward Neural Network (FFN) Layer
📌 역할
- Self-Attention과 Encoder-Decoder Attention을 거친 단어 벡터를 최종적으로 변환하는 역할
- 즉, 디코더에서 생성한 단어 벡터를 더 복잡한 의미로 변환
📌 어떻게 동작할까? 🤔
1️⃣ 선형 변환(Linear Transformation) + 활성화 함수(ReLU) 적용
2️⃣ 다시 선형 변환하여 최종 출력
🔹 1. FFN Layer가 필요한 이유
📌 Self-Attention과 Encoder-Decoder Attention은 "단어 간의 관계"를 학습하는 과정!
📌 하지만, 각 단어의 의미 자체를 더욱 풍부하게 만들기 위해 추가적인 비선형 변환이 필요!
📌 FFN Layer는 "각 단어의 의미를 더욱 정교하게 조정"하는 역할!
📌 (1) Self-Attention과 Encoder-Decoder Attention만 사용하면 안 되는 이유
🔥 Self-Attention과 Encoder-Decoder Attention이 하는 일은 "단어 간의 관계"를 학습하는 것!
➡ 하지만, 각 단어 자체의 표현(의미)을 더욱 풍부하게 만들기 위해 추가적인 변환이 필요!
➡ 즉, 단어 간 관계를 학습하는 과정과, 개별 단어 벡터를 최적화하는 과정은 다름!
➡ 그래서 최종적으로 FFN을 통해 단어 벡터를 비선형 변환하여 의미를 더욱 풍부하게 만드는 것! 🚀
🔹 2. FFN Layer가 없으면 어떻게 될까? 🤯
📌 만약 FFN Layer가 없으면?
❌ Self-Attention과 Encoder-Decoder Attention이 단어 간 관계를 학습하는 것은 가능하지만, 각 단어의 의미를 더 정교하게 조정할 수 없음.
❌ 단어 자체의 표현력을 충분히 강화하지 못하기 때문에, 더 깊고 풍부한 의미를 학습하는 데 한계가 생김!
❌ 모델이 복잡한 의미를 학습하지 못하고, 단순한 번역 패턴만 학습할 가능성이 높음.
🔥 즉, FFN이 없으면 단어 간 관계는 학습할 수 있지만, 단어 자체의 표현력이 부족할 수 있음! 🚀
✅ 4. 최종 정리
✔ 디코더의 FFN은 번역된 한국어 문장에서 "각 단어의 의미를 더 깊게 학습"하는 과정!
✔ Self-Attention과 Encoder-Decoder Attention이 단어 간 관계를 학습하는 과정이라면, FFN은 개별 단어를 최적화하는 과정!
✔ 두 번의 선형 변환(차원 확장 → 차원 축소)과 ReLU를 통해 더 복잡한 의미를 학습할 수 있도록 도와줌!
✔ FFN이 없으면 단어 간 관계는 학습할 수 있지만, 개별 단어의 의미를 세밀하게 조정하지 못할 가능성이 높음.
🔥 즉, 디코더의 FFN은 번역된 문장의 단어를 최적의 표현으로 변환하여 더 자연스럽고 정확한 번역이 나오도록 도와주는 역할을 하는 거야! 🚀
💡 결과
✅ 최종적으로 각 단어가 적절한 형태로 변환되어 출력될 준비가 됨.
✅ 디코더에서 예측한 단어를 다음 예측 과정에 활용함.
🔹 트랜스포머의 입력
📌 트랜스포머는 단어 입력을 순차적으로 받지 않음
- 트랜스포머는 단어 입력을 순차적으로 받지 않기 때문에 단어의 위치 정보를 다른 방식으로 알려줄 필요가 있음
- Positional Encoding(포지셔널 인코딩): 단어의 임베딩 벡터에 위치 정보를 더하여 모델의 입력으로 사용하여 단어의 위치 정보를 전달
- 같은 단어라도 포지셔널 인코딩 값이 달라지고 임베딩 벡터 값이 달라짐
- ➡ 따라서 단어의 순서 정보가 반영됨!
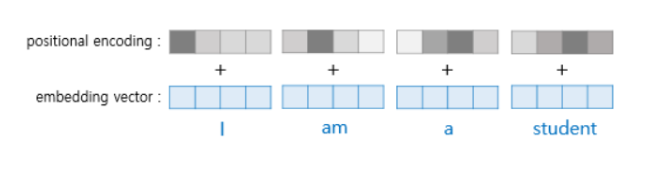
📌 (1) RNN 계열 모델은 단어 순서를 자연스럽게 학습
💡 기존 RNN 구조에서는 단어를 순차적으로 입력받았기 때문에, 단어의 순서를 자연스럽게 학습할 수 있었음!
📌 예제 문장 (RNN 입력)
"I love NLP."➡ RNN은 "I" → "love" → "NLP" 순서대로 입력받음.
➡ 따라서 "I"가 먼저 입력되고, "NLP"가 마지막에 입력된다는 순서를 자연스럽게 인식할 수 있음!
➡ 즉, RNN은 단어의 순서를 자연스럽게 고려할 수 있음!
📌 (2) 트랜스포머는 단어를 한꺼번에 입력받음
💡 트랜스포머는 병렬 처리를 위해 단어를 한꺼번에 입력받기 때문에, 단어의 순서를 직접 알 수 없음.
📌 예제 문장 (트랜스포머 입력)
["I", "love", "NLP"]➡ 트랜스포머는 한 번에 모든 단어를 입력받기 때문에, 어떤 단어가 먼저 등장했는지 직접 알 수 없음!
➡ 따라서, 단어의 위치 정보를 따로 제공해야 함!
🔥 이 문제를 해결하는 것이 "포지셔널 인코딩(Positional Encoding)"! 🚀
🔹 포지셔널 인코딩(Positional Encoding)이란?
📌 포지셔널 인코딩의 역할
- 포지셔널 인코딩은 단어 벡터에 위치 정보를 더해서 모델이 단어의 순서를 이해할 수 있도록 하는 방법!
- 즉, 같은 단어라도 문장에서 위치가 다르면 다른 값을 가지도록 변환하는 것!
📌 Positional Encoding 값 구하기
-
왼쪽 행렬: 각 단어의 임베딩 벡터(Word Embedding)
- 단어 "I", "am", "a", "student"가 행렬 형태로 변환됨.
- 각 단어는 d_model 차원의 벡터로 변환됨. (예: 512차원)
- 이 벡터에는 단어의 의미 정보가 포함됨.
-
오른쪽 행렬: 포지셔널 인코딩(Positional Encoding)
- 단어의 위치 정보를 추가하는 행렬
- 같은 단어라도 문장에서 위치가 다르면 다른 값을 가짐.
-
중앙 화살표 (pos,i)
pos = 문장에서 단어의 위치 (예: "I"는 1번째 단어, "am"은 2번째 단어)
i = 벡터 차원의 특정 인덱스 (예: 512차원 벡터 중 3번째 차원)
->
그림에서는, 2번째 단어인 am 의 총 512개의 임베딩 벡터 중, 3번째 임베딩 벡터가 어떻게 변화할지 가리키는 것
그림에서 화살표가 의미하는 것
📌 화살표가 가리키는 위치는 단순히 "am" 전체를 의미하는 게 아니라, 특정 단어("am")의 특정 차원(예: 3번째 차원) 값이 어떻게 변하는지를 나타내는 것!
➡ 즉, 포지셔널 인코딩을 추가하면 단어의 순서 정보가 반영됨!
🔹 1. 포지셔널 인코딩의 동작 방식
📌 (1) 트랜스포머의 입력 벡터 구성
1️⃣ 각 단어는 벡터(예: 512차원)로 표현됨
| 단어 | 벡터 값 (예제) |
|---|---|
| "I" | [0.2, 0.3, ..., 0.5] |
| "am" | [0.4, 0.7, ..., 0.2] |
| "student" | [0.1, 0.8, ..., 0.3] |
2️⃣ 포지셔널 인코딩도 같은 차원의 벡터(512차원)를 가짐
| 단어 | 위치 정보 벡터 (예제) |
|---|---|
| "I" | [0.9, 0.1, ..., 0.3] |
| "am" | [0.5, 0.6, ..., 0.4] |
3️⃣ 각 단어의 벡터에 포지셔널 인코딩을 더함
최종 입력 벡터 = (단어 의미 벡터) + (위치 벡터)
➡ 즉, 포지셔널 인코딩을 더해주면, 트랜스포머는 단어의 순서를 고려할 수 있게 됨! 🚀
즉, 해당 차원의 값이 단어 위치에 따라 어떻게 조정되는지를 나타냄!
🔹 2. 포지셔널 인코딩 계산 방식
트랜스포머에서는 사인(Sin)과 코사인(Cosine) 함수를 이용해서 포지셔널 인코딩을 생성함.
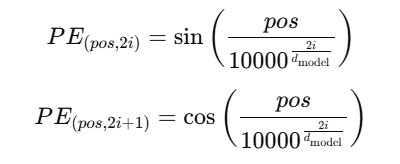
📌 pos (위치) → 문장에서 단어가 몇 번째 위치인지
📌 i (차원 인덱스) → 임베딩 벡터의 특정 차원 인덱스
📌 d_model (임베딩 차원 수) → 트랜스포머의 모든 층의 출력 차원을 의미하는 하이퍼파라미터(논문에서는 512 값을 사용)
➡ 즉, 각 차원의 값이 단어의 위치에 따라 조정됨!
📌 포지셔널 인코딩 적용 방식
1️⃣ 각 단어를 임베딩 벡터로 변환
2️⃣ 각 단어의 위치(Positional Encoding) 값을 계산
3️⃣ 임베딩 벡터와 포지셔널 인코딩 값을 더해서 최종 입력 벡터를 만듦
📌 최종 입력 벡터 계산
입력 벡터=단어 임베딩+포지셔널 인코딩
🔥 즉, 포지셔널 인코딩을 더해주면, 트랜스포머는 단어의 순서를 고려할 수 있게 됨! 🚀
🔹 트랜스포머에서 사용되는 어텐션 이해하기
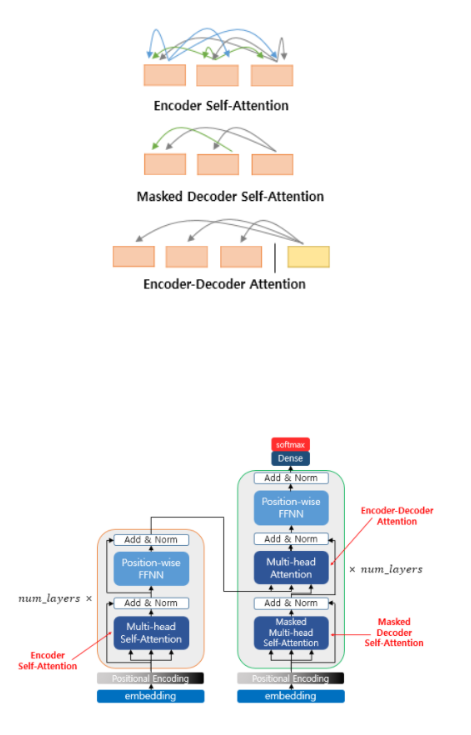
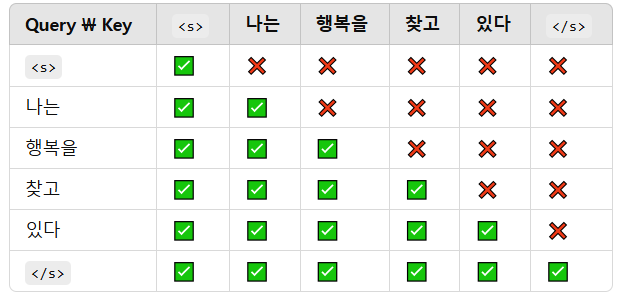
🔹 1. Encoder Self-Attention (인코더 자체 어텐션)
- 인코더에서 입력 문장의 모든 단어가 서로를 참고하여 의미를 학습하는 과정.
- 모든 단어가 다른 단어들과 자유롭게 연결됨 (자유로운 Attention).
- 예: "I love NLP"에서 "I"는 "love", "NLP"와도 관계를 가질 수 있음.
🔹 2. Masked Decoder Self-Attention (마스킹된 디코더 자체 어텐션)
- 디코더에서 문장을 생성할 때, 미래 단어를 보지 못하도록 마스킹이 적용됨.
- 현재까지 생성된 단어까지만 참고하여 다음 단어를 예측.
- 예: "나는"을 생성할 때 "너를 사랑해"를 미리 보면 안 됨.
🔹 3. Encoder-Decoder Attention (인코더-디코더 어텐션)
- 인코더에서 생성된 정보를 기반으로, 디코더가 출력 문장을 생성하는 과정.
- 예: "I"가 "나는"과 연결되고, "love"가 "사랑해"와 연결됨.
- 입력과 출력을 매핑하는 가장 중요한 단계!
📌 (1) 인코더 구조 (왼쪽)
💡 인코더는 입력 문장을 벡터로 변환하는 역할!
1️⃣ Embedding & Positional Encoding (단어 임베딩 + 위치 정보 추가)
단어를 벡터로 변환하고(Positional Encoding 추가), 순서를 반영.
2️⃣ Multi-Head Self-Attention (멀티 헤드 자기 어텐션)
문장의 모든 단어가 서로를 참고하여 의미를 학습.
3️⃣ Add & Norm (잔차 연결 + 정규화)
네트워크의 안정성을 높이기 위해 정규화(Normalization) 적용.
4️⃣ Feed Forward Neural Network (FFN, 피드포워드 네트워크)
단어 벡터를 더 깊이 학습하기 위한 비선형 변환 수행.
➡ 즉, 인코더는 입력 문장의 의미를 벡터로 압축하여 디코더로 전달하는 역할을 함! 🚀
📌 (2) 디코더 구조 (오른쪽)
💡 디코더는 인코더에서 전달받은 정보를 기반으로 새로운 문장을 생성하는 역할!
1️⃣ Embedding & Positional Encoding (단어 임베딩 + 위치 정보 추가)
입력된 문장을 벡터로 변환하고, 위치 정보를 추가.
2️⃣ Masked Multi-Head Self-Attention (마스킹된 자기 어텐션)
미래 단어를 보지 못하도록 마스킹을 적용하여 문장을 순차적으로 생성.
3️⃣ Encoder-Decoder Attention (인코더-디코더 어텐션)
인코더의 정보를 참고하여 가장 적절한 단어를 선택.
4️⃣ Feed Forward Neural Network (FFN, 피드포워드 네트워크)
각 단어 벡터를 더 정교하게 다듬어서 최종적인 의미를 학습.
5️⃣ Softmax & Dense (출력 생성)
최종적으로 확률 분포를 계산하여 단어를 하나씩 생성.
➡ 즉, 디코더는 인코더의 정보를 활용하여 하나씩 단어를 생성하는 역할을 함! 🚀
📌 어텐션 요약
📌 Encoder Self-Attention: 인코더를 구성하며 입력으로 들어간 문장 내 단어들이 서로 유사도를 구함.
📌 Decoder Self-Attention: 디코더를 구성하며 단어를 1개씩 생성하는 과정에서 앞 단어들과의 유사도를 구함.
➡ 즉, 디코더는 앞에서 나온 단어들이 서로 어떻게 관련되는지를 학습해야 함! 🚀
🔹 2. 앞 단어들과 유사도를 구하는 이유
📌 디코더는 앞에서 나온 단어들이 서로 어떻게 관련되는지를 학습해야 함.
- 이 과정이 바로 "Masked Self-Attention"에서 이루어짐!
💡 Masked Self-Attention이란?
Self-Attention을 적용하되, 미래 단어를 보지 못하도록 마스킹을 적용한 것!
즉, 현재 단어까지만 참고하여 다음 단어를 예측하도록 제한함.
📌 디코더의 역할
- 디코더는 앞 단어들과 유사도를 계산하여 다음 단어를 예측해야 함.
- 이전 단어들과의 관계(유사도)를 학습하여, 가장 적절한 다음 단어를 선택함.
예제: "나는 너를 사랑해"를 예측하는 과정
📌 디코더가 앞 단어들과 유사도를 구하는 이유는?
- "너를"을 예측할 때 → "나는"과의 관계를 고려해야 함.
- "사랑해"를 예측할 때 → "나는 너를"과의 관계를 고려해야 함.
따라서, 디코더는 앞에서 생성된 단어들과의 유사도를 계산하여 가장 적절한 다음 단어를 선택하는 방식으로 동작함!
🔥 즉, 디코더는 단어를 하나씩 생성하면서, 앞 단어들과의 관계를 학습하여 다음 단어를 예측하는 것! 🚀
📌 Encoder-Decoder Attention
- 디코더를 구성하며, 디코더가 잘 예측하기 위해서 인코더에 입력된 단어들과 유사도를 구함.
- 어텐션을 위한 세 가지 입력 요소
- 쿼리(Query)
- 키(Key)
- 값(Value)
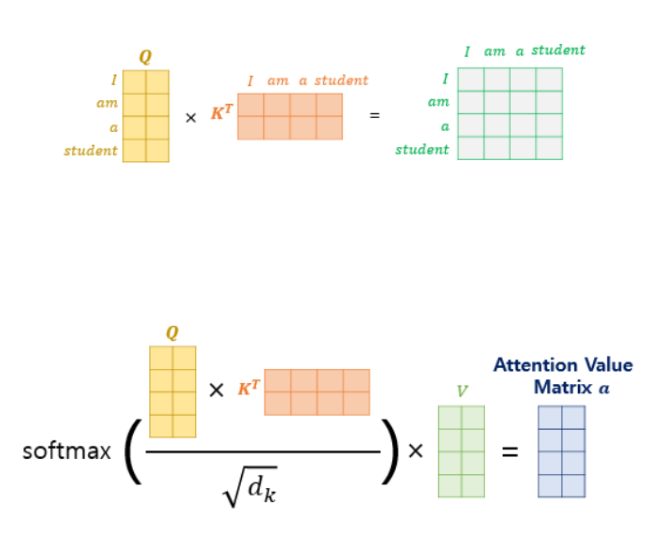
🔹 Self-Attention

📌 "그 동물은 길을 건너지 않았다. 왜냐하면 그것은 너무 피곤했기 때문이다."
- 이 문장에서 "그것"은 길을 말하는 걸까? 동물을 말하는 걸까?
- 사람에게는 간단한 질문이지만, 신경망 모델에게는 그렇지 않음!
그것이 동물 또는 길에 해당하는지는 유사도에 의한 확률 값으로 알 수 있다. - Self-Attention을 통해 문맥적 관계를 고려해야 함.
🔹 Self-Attention 유사도 계산
📌 유사도를 구하는 식
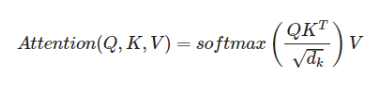
📌 Q (쿼리), K (키), V (값), X (입력 벡터 시퀀스)
- Self-Attention은 쿼리(Query), 키(Key), 밸류(Value) 3가지 요소의 관계를 분석하는 과정
- 쿼리, 키, 밸류를 구하는 식
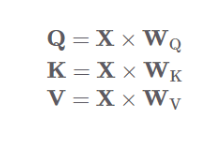
🔹 입력 벡터 시퀀스 예제
📌 입력 벡터 시퀀스 예제

📌 쿼리(Query) 계산
좌변이 입력벡터 시퀀스이고 우변이 W_Q에 대응
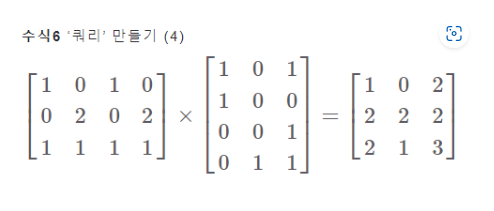
📌 키(Key) 계산
좌변이 입력벡터 시퀀스이고 우변이 W_K에 대응
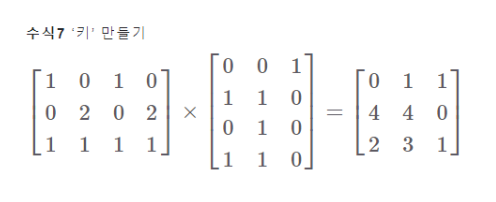
📌 밸류(Value) 계산
좌변이 입력벡터 시퀀스이고 우변이 W_V에 대응
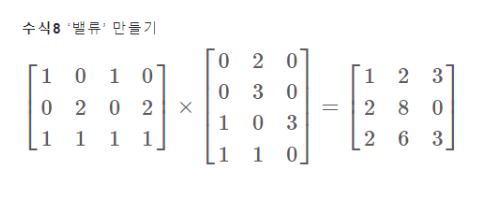
📌 W_Q, W_K, W_V는 학습 과정에서 업데이트됨
🔹 Query × Key 연산 과정
📌 원래 Key 벡터는 세로 행렬(컬럼 벡터)이지만, 전치(transpose) 연산을 적용하여 가로 행렬(로우 벡터)로 변환
- 이전 Query 벡터와 내적(dot product)을 계산하기 위해 변환!
📌 Query(Q) × Key(K_t) 연산 (행렬 곱)
- Query 행렬과 Key 행렬을 곱하면 Self-Attention Score(유사도 행렬) 이 생성됨.
- 각 단어가 다른 단어와 얼마나 관련 있는지 점수를 매기는 과정!
📌 결과 행렬의 의미
- 행렬의 각 위치 (i,j)는 i번째 단어(열, Query)가 j번째 단어(행, Key)와 얼마나 연관이 있는지를 나타내는 값!
🔹 2. Self-Attention Score 행렬의 의미
📌 Self-Attention Score 행렬이란?
Self-Attention Score 행렬(오른쪽, 초록색)은 Query와 Key의 내적으로 계산되며, 단어 간의 유사도를 나타냅니다.
예를 들어:
- "I" → "I" 와의 유사도: 높음 (자기 자신이므로)
- "I" → "student" 와의 유사도: 낮음 (문법적으로 덜 관련됨)
- "am" → "a" 와의 유사도: 중간 정도 (문맥상 연결될 수 있음)
🔥 즉, 이 연산을 통해 트랜스포머는 문장에서 어떤 단어들이 서로 더 관련 있는지를 학습할 수 있습니다! 🚀
🔹 Multi-Head Attention에서의 d_k 값 계산
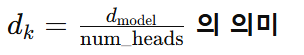
▪d_k 값은 d_model/num_heads라는 식에 따라 구하며 여기에 루트를 씌운 값으로 계산합니다.
📌 Multi-Head Attention 개념
트랜스포머의 멀티헤드 어텐션(Multi-Head Attention)에서는 하나의 큰 벡터(예: 512차원)를 여러 개의 작은 벡터(예: 8개로 나눠서 각 64차원)로 분할하여 어텐션을 수행합니다.
🔹 각 헤드의 차원 크기 = d_k
예를 들어:
- 모델의 차원 d_model = 512
- 헤드 개수 num_heads = 8
- 따라서, 𝑑_k =512/8=64
➡ 즉, 하나의 어텐션 헤드에서 처리하는 벡터 차원이 d_k로 설정됩니다.
🔹 트랜스포머에서 Query(Q)와 Key(K)의 내적을 계산할 때, 왜 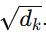 로 나누는가?
로 나누는가?
✅ 이유:
1. 값이 너무 커지거나 작아지는 문제 방지
2. Softmax의 출력이 안정적으로 나오도록 하기 위함 🚀
✅ 추가 개념:
- d_model/num_heads 값은 Q, K, V 벡터의 차원과 동일합니다.
- Query는 타깃 언어 문장의 단어 벡터 시퀀스
- Key는 소스 언어의 문장의 단어 벡터 시퀀스
- Encoder-Decoder Attention에서는 Query(Q)와 Key(K)의 역할이 다릅니다!
➡ 디코더의 Query(Q)는 타깃 언어(출력 문장)의 단어 벡터 시퀀스, Key(K)는 소스 언어(입력 문장)의 단어 벡터 시퀀스에 해당합니다.
🔹 Scaled Dot Product Attention 과정
- Query와 Key를 행렬곱(dot product) 수행
- 결과 행렬을 키 차원수의 제곱근 값(( \sqrt{d_k} ))으로 나눔
- Softmax 함수 적용 → 스코어 행렬 생성
- 스코어 행렬을 Value 벡터와 행렬곱하여 Attention Value 계산
💡 Softmax를 사용하는 이유:
➡ 유사도를 0과 1 사이 값으로 Normalize 하기 위함
📌 위와 같은 방식으로 Q와 K의 유사도를 구했기 때문에 Scaled Dot Product Attention이라 불립니다.
📌 특정 값을 분모로 나누지 않은 어텐션은 Dot Product Attention이라고 합니다.
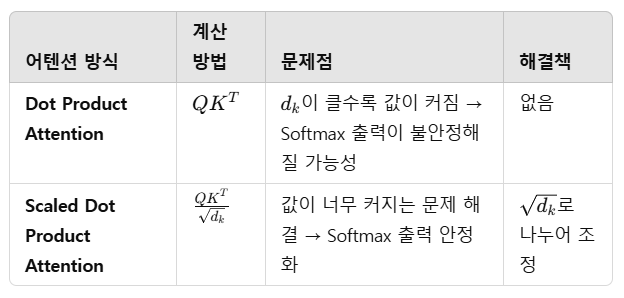
🔥 즉, Scaled Dot Product Attention은 기존 Dot Product Attention의 문제점을 보완하여 Softmax 출력을 더 안정적으로 만드는 개선된 방식입니다! 🚀
The Beast With Many Heads (병렬로 어텐션 수행하기)
📌 Multi-Head Attention의 개념
Self-Attention Layer에 "Multi-Head Attention" 메커니즘을 추가하여 Attention Layer의 성능을 향상시킵니다.
💡 멀티 헤드 어텐션이란?
기존 Self-Attention을 확장하여, 여러 개의 시각에서 문장을 해석할 수 있도록 만든 기법입니다!
➡ 하나의 어텐션이 아닌, 여러 개의 어텐션을 병렬로 수행하여 더 풍부한 정보를 학습하는 방식입니다. 🚀
🔹 1. 멀티 헤드 어텐션을 왜 사용하는가?
기본적인 Self-Attention은 문장 내 단어들 간의 관계를 학습하지만, 한 번의 어텐션으로는 모든 관계를 고려하기 어렵습니다.
📌 그리스 로마 신화에 등장하는 괴물 히드라나 케로베로스는 머리가 여러 개라 상대방을 여러 시점에서 볼 수 있습니다. 멀티 헤드 어텐션도 어텐션을 병렬로 수행해 다양한 시각으로 정보를 수집합니다.
예를 들어,
"그 동물은 길을 건너지 않았다. 왜냐하면 그것은 너무 피곤하였기 때문이다."
➡ 여기서 "it"이 "the animal"을 가리키는지, "the road"를 가리키는지 한 번의 Self-Attention만으로 판단하기 어렵습니다.
🔥 그래서 여러 개의 어텐션(멀티 헤드 어텐션)을 병렬로 수행하여, 문맥을 다양한 시각에서 해석합니다! 🚀
📌 멀티 헤드 어텐션의 핵심
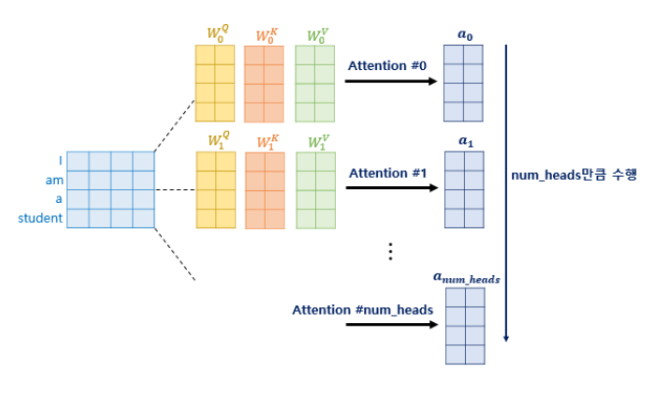
- d_model 차원의 어텐션을 수행하지 않고, d_model을 num_heads로 나누어 차원 축소된 벡터로 여러 번 어텐션을 수행
- 즉, 어텐션을 num_heads 만큼 병렬로 수행 (num_heads는 hyperparameter)
- 각각의 어텐션 값 행렬을 어텐션 헤드라고 부름
- 각 헤드는 서로 다른 W_Q, W_K, W_V 가중치 행렬을 사용
🔹 2. 멀티 헤드 어텐션이 동작하는 방식
멀티 헤드 어텐션은 하나의 큰 어텐션을 수행하는 대신, 여러 개의 작은 어텐션을 독립적으로 수행하고 이를 결합하는 방식입니다.
📌 동작 방식
1️⃣ 입력 벡터를 d_model 차원의 벡터로 임베딩
2️⃣ d_model을 num_heads 개의 작은 차원으로 나눔
3️⃣ 각 부분 벡터에 대해 독립적으로 Self-Attention 수행
4️⃣ 각 어텐션 결과를 결합하여 최종 벡터 생성
📌 (1) 하나의 어텐션만 사용하면?
만약 Self-Attention을 한 번만 수행한다면, 모든 단어들 간의 관계를 단 하나의 시각에서만 학습해야 합니다.
즉, "it"이 "animal"과 관련이 있는지, "road"와 관련이 있는지 구분하는 것이 어려울 수 있습니다.
➡ 단 하나의 시각에서 문장을 해석해야 하므로 문맥 이해가 부족할 수 있습니다.
📌 (2) 멀티 헤드 어텐션을 사용하면?
💡 멀티 헤드 어텐션을 사용하면, 여러 개의 다른 어텐션이 서로 다른 관계를 학습할 수 있습니다!
| 어텐션 헤드 | "it"과 강하게 연결된 단어 |
|---|---|
| 헤드 1 | "animal" (명시적 참조) |
| 헤드 2 | "tired" (의미적 연관) |
| 헤드 3 | "road" (다른 가능성 탐색) |
🔥 즉, 하나의 어텐션이 하나의 해석만 하는 것이 아니라, 여러 개의 어텐션이 서로 다른 시각에서 문장을 분석할 수 있도록 합니다! 🚀
🔹 3. 멀티 헤드 어텐션의 계산 과정
📌 멀티 헤드 어텐션을 구현하는 방식
1️⃣ 입력 벡터(Embedding)를 여러 개의 작은 벡터로 분할
- 예: 모델 차원 512, num_heads = 8 → 각 헤드에서 처리하는 벡터 차원: 512/8=64
2️⃣ 각 헤드에서 독립적인 Query(Q), Key(K), Value(V) 행렬을 생성
- 어텐션 헤드마다 다른 가중치 행렬 사용하여 변환
3️⃣ 각 헤드에서 개별적으로 Self-Attention 수행
- Query와 Key의 내적 → Softmax → Value에 곱하기 → 최종 벡터 생성
4️⃣ 각 어텐션 결과를 결합 (Concat)하여 최종 출력 벡터 생성
- 각 헤드의 출력을 결합하여 원래 차원(예: 512)으로 되돌림
📌 병렬 어텐션을 모두 수행하였다면 모든 어텐션 헤드를 연결(Concatenate) 합니다.
- 최종 어텐션 행렬의 크기: (seq_len, d_model)
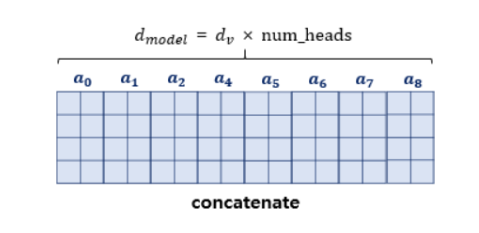
🔹 4. 멀티 헤드 어텐션의 최종 출력 과정
✅ 멀티 헤드 어텐션에서 최종 출력을 어떻게 선택하는가?
💡 각 헤드에서 병렬로 어텐션을 수행한 후, 마지막에 합쳐진 차원에서 가장 확률이 높은 것을 선택하는 방식인가?
💡 최종 선택은 단순히 "가장 확률이 높은 헤드"를 선택하는 방식이 아니라, "모든 헤드의 정보를 결합"하는 방식! 🚀
📌 최종 출력 과정
1️⃣ 각 헤드에서 독립적으로 Self-Attention 수행 → Query(Q), Key(K), Value(V) 생성
2️⃣ 각 헤드에서 Self-Attention 연산 수행하여 결과 벡터 생성
3️⃣ 각 헤드에서 나온 결과를 합쳐(Concatenate) 큰 벡터로 변환
4️⃣ 최종적으로 하나의 벡터로 변환하기 위해 추가적인 가중치 행렬을 곱함
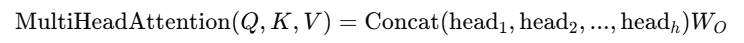
🔥 즉, 각 헤드에서 얻은 정보들을 모두 결합한 후 새로운 가중치를 학습하여 최종 출력을 생성합니다! 🚀
📌 최종 출력 벡터는 무엇을 의미하는가?
- "it"이 "animal"과 강한 연관이 있음
- "it"이 "tired"와 의미적으로 연결됨
- "it"이 "road"와도 연결될 가능성이 있음
➡ 최종 벡터는 단순한 해석이 아니라 문맥적 정보를 풍부하게 포함한 벡터입니다.
🔥 즉, 멀티 헤드 어텐션은 여러 개의 시각에서 정보를 해석하고 이를 종합하여 최적의 문맥 정보를 제공하는 역할을 합니다! 🚀
🔹 2. 각 헤드의 결과를 하나로 합치는 이유
💡 각 헤드를 합치는 이유
각 헤드는 서로 다른 시각에서 정보를 학습하기 때문에, 모든 헤드의 정보를 결합하면 더 풍부한 문맥 정보를 학습할 수 있습니다.
📌 만약 가장 높은 확률을 선택하는 방식이라면?
- 여러 개의 헤드 중 가장 확률이 높은 것만 남기면, 나머지 헤드의 정보가 손실됩니다.
- 이는 멀티 헤드 어텐션의 목적(다양한 시각에서 정보를 학습하는 것)과 맞지 않습니다.
📌 그래서 모든 헤드의 정보를 합친 후, 다시 변환하는 방식을 사용합니다!
- 각 헤드가 학습한 내용을 모두 반영하여 최종적으로 가장 의미 있는 정보를 생성할 수 있도록 합니다.
- 마지막에 가중치 행렬을 적용하는 이유는, 합쳐진 정보들을 다시 원래 모델 차원(예: 512차원)으로 맞춰주는 과정이 필요하기 때문입니다.
🔥 즉, "가장 높은 확률을 선택하는 방식"이 아니라, "모든 헤드의 정보를 결합한 후 변환하는 방식"입니다! 🚀
🔹 최종 벡터는 가장 의미 있는 하나의 정보인가?
📌 아닙니다!
- 최종 벡터는 "가장 의미 있는 하나의 정보"만을 출력하는 것이 아니라, 여러 정보를 조합한 최적의 벡터를 출력하는 것입니다.
📌 최종 출력 벡터는 어떻게 해석할 수 있을까요?
- 이 벡터는 각 헤드가 학습한 정보를 종합적으로 반영한 벡터입니다.
- 모델이 이 벡터를 활용하여 다음 레이어로 전달합니다.
- 즉, 이 벡터는 "하나의 단일 정보"가 아니라, 문맥적 정보를 풍부하게 포함한 벡터입니다.
🔥 최종 벡터는 단순한 정보만 포함하는 것이 아니라, 여러 개의 어텐션 헤드가 학습한 정보를 반영한 최적의 표현 벡터입니다! 🚀
🔹 멀티 헤드 어텐션이 "it"을 여러 개의 시각에서 분석하는 과정
📌 예제 문장
The animal did not cross the road because it was too tired.
(그 동물은 길을 건너지 않았다. 왜냐하면 그것은 너무 피곤했기 때문이다.)
➡ 여기서 "it"이 "animal"을 뜻하는지, "road"를 뜻하는지 헷갈릴 수 있습니다.
🔥 멀티 헤드 어텐션을 적용하면?
| 어텐션 헤드 | "it"과 강하게 연결된 단어 |
|---|---|
| 헤드 1 | "animal" (명시적 참조) |
| 헤드 2 | "tired" (의미적 연관) |
| 헤드 3 | "road" (다른 가능성 탐색) |
📌 이제, 최종 출력 벡터는 어떤 의미를 가지는가?
- 최종 벡터가 직접적으로 "it = animal"이라고 확정하는 것이 아닙니다.
- 대신, "it"이 "animal"과 강한 연관이 있음 + "it"이 "tired"와 의미적으로 연결됨 등의 정보를 포함한 벡터를 생성합니다.
- 이후 다음 레이어(Feed Forward Network, FFN)가 이 벡터를 보고 최종적으로 "it"이 무엇을 가리키는지 판단하게 됩니다.
🔥 즉, 멀티 헤드 어텐션은 "it"의 다양한 해석을 제공하고, 최종적으로 모델이 문맥을 이해할 수 있도록 정보를 풍부하게 전달하는 역할을 합니다! 🚀
🔹 멀티 헤드 어텐션의 최종 출력 벡터의 역할
📌 최종 출력 벡터는 "가능성"을 제공하는 역할!
- 각 어텐션 헤드가 다른 시각에서 분석한 정보를 포함한 벡터를 생성합니다.
- 다음 레이어(FFN, 또는 다른 트랜스포머 블록)가 이 벡터를 바탕으로 최적의 해석을 수행합니다.
- 즉, 멀티 헤드 어텐션이 판단을 직접 내리는 것이 아니라, "이 단어가 가질 수 있는 의미를 종합해서 제공하는 역할"을 합니다.
📌 트랜스포머는 문장을 여러 개의 레이어를 통해 점진적으로 이해해 나갑니다!
- 한 번의 멀티 헤드 어텐션에서 단어의 의미를 100% 확정하는 것이 아닙니다.
- 이후 추가적인 Self-Attention, Feed Forward Network(FFN), 디코더의 Attention 레이어 등을 거치면서 점점 더 정교한 해석을 수행합니다.
🔥 즉, 최종 출력 벡터는 "이중에서 상황에 따라 알맞게 판단하세요"라는 느낌이 맞습니다! 🚀
➡ 모델이 다음 레이어에서 더 깊이 있는 해석을 할 수 있도록 여러 시각에서 분석한 정보를 제공하는 것입니다!
🔹 마스킹(Masking)
📌 마스킹(Masking)이란?
특정 값들을 가려서 실제 연산에 방해가 되지 않도록 하는 기법으로, 트랜스포머에서는 패딩 마스킹(Padding Masking)과 룩 어헤드 마스킹(Look-ahead Masking, 다음 단어 가리기)을 사용합니다.
1️⃣ 패딩 마스킹(Padding Masking)
📌 패딩 마스킹이란?
입력 문장에 padding 이 있을 경우 어텐션에서 제외하기 위한 연산
padding 은 실질적인 의미를 가진 단어가 아니기 때문에 토큰이 존재한다면 이에 대해서는 유사도를 구하지 않도록 마스킹(Masking) 해줌
💡 패딩 마스킹은 의미 없는 패딩(Padding) 토큰이 어텐션 연산에 영향을 주지 않도록 제외하는 과정입니다.
➡ 즉, 트랜스포머가 의미 없는 토큰을 고려하지 않고 실제 단어만을 학습하도록 하기 위한 기술입니다! 🚀
🔹 1. 왜 패딩(Padding)이 필요한가?
💡 문장의 길이가 다를 때, 신경망에서 연산을 수행하기 위해 모든 문장을 같은 길이로 맞춰야 합니다.
➡ 이때 짧은 문장에는 의미 없는 토큰(패딩, [PAD])을 추가하여 길이를 맞춥니다.
📌 예제: 문장 길이 맞추기
| 원본 문장 | 패딩 적용 후 |
|---|---|
| "I love NLP" | "I love NLP [PAD][PAD]" |
| "Transformers are amazing" | "Transformers are amazing" |
➡ 이제 두 문장의 길이가 동일해졌지만, [PAD]는 의미 없는 단어이므로 학습할 필요가 없습니다.
🔥 문제점은?
Self-Attention 연산에서는 모든 토큰을 서로 연관 지으려 하기 때문에, [PAD]까지 학습하려고 합니다. 그러면 의미 없는 [PAD] 토큰까지 고려하게 되어 모델의 성능이 저하될 수 있습니다.
➡ 따라서 패딩 마스킹을 적용하여 [PAD] 토큰을 연산에서 제외합니다! 🚀
🔹 2. 패딩 마스킹 적용 방식
📌 패딩 마스킹은 [PAD] 토큰이 Attention Score에 영향을 미치지 않도록 제거하는 방식입니다.
➡ 즉, 패딩 토큰을 어텐션 연산에서 제외하기 위해 Attention Score를 0 또는 매우 작은 값(음수 무한대)으로 만들어서 무시하는 것!
📌 패딩 마스킹 적용 과정
1️⃣ Self-Attention 수행 전, 마스킹 적용
[PAD]가 있는 위치를 찾아서 마스킹 벡터를 생성합니다.- 예:
[1, 1, 1, 0, 0](1은 유효한 단어, 0은[PAD]위치)
- 예:
2️⃣ 어텐션 연산에서 [PAD] 부분을 제외
- Attention Score를 계산할 때,
[PAD]가 있는 부분을-∞(음의 무한대)로 설정합니다. - Softmax를 적용하면 이 값이
0이 되어, 해당 위치는 학습되지 않습니다.
📌 패딩 마스킹 적용 전후 비교
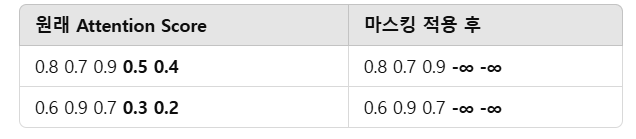
🔥 즉, 패딩 마스킹을 적용하면 [PAD] 토큰이 어텐션 연산에서 제외되어 모델이 불필요한 연산을 수행하지 않도록 합니다! 🚀
2️⃣ 룩 어헤드 마스킹(Look-ahead Masking)
📌 룩 어헤드 마스킹이란?
💡 룩 어헤드 마스킹(Look-ahead Masking)은 트랜스포머 디코더에서 "미래 단어를 보지 못하도록" 제한하는 마스킹 기법입니다!
➡ 즉, 트랜스포머는 한꺼번에 문장을 입력받기 때문에, 훈련 시 미래 단어를 미리 보는 문제를 방지하기 위해 마스킹이 필요합니다! 🚀
🔹 1. 왜 룩 어헤드 마스킹이 필요한가?
💡 기존 RNN 기반 모델과 트랜스포머의 입력 방식이 다르기 때문!
📌 (1) 기존 RNN 구조에서는?
- RNN은 각 단어를 순차적으로 입력받으며, 이전 단어를 참고하여 다음 단어를 예측합니다.
- 즉, 자연스럽게 "미래 단어"를 볼 수 없습니다. (시간적으로 순차적인 입력)
📌 (2) 트랜스포머의 입력 방식은 다릅니다!
- 트랜스포머는 문장을 한꺼번에 행렬(Matrix) 형태로 입력받습니다.
- 즉, 훈련 중에 미래 단어도 함께 주어지기 때문에, 모델이 미래 단어를 미리 보지 않도록 막아야 합니다.
🔥 즉, RNN처럼 순차적인 구조가 아닌 트랜스포머에서는, 디코더가 미래 단어를 보지 못하도록 "룩 어헤드 마스킹"을 적용해야 합니다! 🚀
🔹 2. 룩 어헤드 마스킹 적용 방식
📌 룩 어헤드 마스킹을 적용하면, 트랜스포머 디코더가 아직 예측하지 않은 미래 단어를 참조하지 못하도록 제한할 수 있습니다.
📌 룩 어헤드 마스킹의 동작 방식
1️⃣ 문장을 행렬(Matrix) 형태로 입력받음
2️⃣ 현재까지의 단어까지만 사용하고, 이후 단어는 마스킹 처리 (-∞ 값 할당)
3️⃣ Softmax를 적용하면 마스킹된 단어는 확률이 0이 되어, 모델이 참고할 수 없음
📌 룩 어헤드 마스킹 적용 전

➡ 이 상태에서는 모든 단어를 참고할 수 있음 → 미래 단어를 미리 볼 수 있음!
📌 룩 어헤드 마스킹 적용 후

➡ 이제, 디코더는 아직 생성되지 않은 단어(미래 단어)를 참조하지 못함!
➡ Softmax를 적용하면 -∞ 값은 0이 되어 완전히 무시됨.
🔥 즉, 룩 어헤드 마스킹을 사용하면, 트랜스포머 디코더가 훈련 중에 미래 단어를 미리 참조하지 못하도록 만들 수 있습니다! 🚀
1️⃣ RNN과 트랜스포머의 입력 방식 차이
✔ RNN 입력 구조
RNN은 순차적으로 단어를 입력받고, 이전 단어를 기반으로 다음 단어를 예측하는 방식입니다.
📌 예제: RNN의 입력 과정
| Step | 현재까지의 입력 | 출력 |
|---|---|---|
| 1️⃣ | what | is |
| 2️⃣ | what is | the |
| 3️⃣ | what is the | problem |
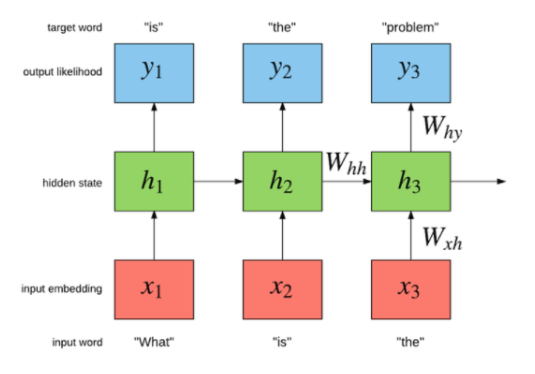
➡ RNN은 한 번에 하나의 단어씩 입력받으며, 자연스럽게 미래 단어를 볼 수 없습니다.
✔ 트랜스포머 입력 구조
트랜스포머는 전체 문장을 한꺼번에 입력받아 병렬 연산을 수행합니다. 하지만, 이렇게 되면 미래 단어를 미리 참조하는 문제가 발생할 수 있습니다.
➡ 이를 방지하기 위해 룩 어헤드 마스킹을 적용합니다.
📌 트랜스포머에서 룩 어헤드 마스킹 적용 방식
- 디코더의 첫 번째 Self-Attention 서브층에서 미래 단어를 참조하지 못하도록 마스킹을 적용합니다.
- Query(Q) 벡터의 뒤쪽 K(미래 단어) 부분을 마스킹 처리하여 미래 정보를 가릴 수 있도록 제한합니다.
- self-attention을 통해 얻는 attention score matrix에서 Q 뒤의 K 단어들에 대해 마스킹함
2️⃣ Query(Q), Key(K), Value(V)의 개념
트랜스포머에서는 문장 속 단어들이 서로 얼마나 관련이 있는지를 계산하기 위해 Query, Key, Value를 사용합니다.
💡 이 개념은 정보 검색 시스템에서 "질문(Query)"과 "데이터베이스(Key-Value)" 관계와 비슷합니다.
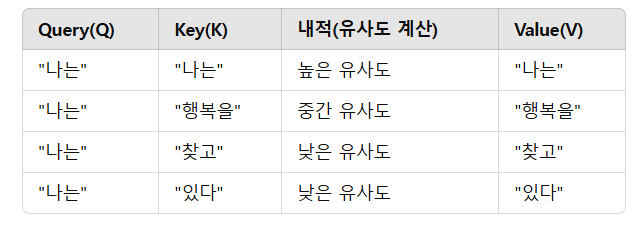
📌 예제: "나는 행복을 찾고 있다." 문장에서 각 단어가 서로 얼마나 연관이 있는지 계산한다고 가정하자.
🔹 Query(Q) - 질문을 던지는 역할
Query(Q)는 특정 단어가 다른 단어들과 얼마나 관련이 있는지 질문하는 벡터입니다.
예를 들어, Query가 "나는"이라면:
"나는"이 문장 속에서 "행복을", "찾고", "있다"와 얼마나 관련이 있는지 알고 싶어!
💡 즉, Query는 "이 단어가 다른 단어들과 얼마나 연관이 있는지 물어보는 벡터"야.
🔹 Key(K) - 질문에 대한 비교 기준
Key(K)는 각 단어의 특성을 담고 있는 벡터입니다.
Query가 특정 단어를 찾을 때, Key를 이용해서 비교함.
예를 들어:
Query가 "나는"이라면,
Key는 "행복을", "찾고", "있다" 등의 단어들을 포함하는 행렬이야.
"나는"과 "행복을"의 관계가 얼마나 가까운지 판단하기 위해 Key를 사용해.
💡 즉, Key는 Query가 찾고자 하는 단어들을 평가할 수 있도록 하는 기준이 되는 벡터야.
🔹 Value(V) - 최종적으로 문맥 정보를 전달하는 역할
Value(V)는 최종적으로 선택된 단어의 문맥 정보를 담고 있는 벡터.
Query와 Key를 비교한 후, 가장 연관이 높은 Key를 선택하고, 그에 해당하는 Value를 가져와 최종 결과로 사용합니다.
예를 들어:
"나는"이라는 Query가 "행복을"과 가장 높은 연관성을 가진다면,
"행복을"이라는 Key에 대응하는 Value가 최종적으로 사용됨.
💡 즉, Value는 Query와 Key의 연관성을 계산한 후, 최종적으로 적용할 문맥 정보를 담고 있어.
3️⃣ Query, Key, Value를 이용한 Attention Score 계산
📌 트랜스포머에서는 Self-Attention을 계산할 때 Query와 Key를 내적(dot product)하여 연관성(유사도)을 계산합니다.
➡ Query와 Key를 비교하여 유사도를 구하고, 그 유사도에 따라 Value를 가중합해서 최종 벡터를 결정하는 방식입니다.
💡 즉, Query와 Key를 비교하여 연관도가 높은 단어를 찾고, 그 단어의 Value 정보를 최종적으로 반영하는 방식이야! 🚀
📌 (1) Query (왼쪽, 입력 문장 열)
현재까지 생성된 단어들을 기준으로, 다음 단어 예측을 위한 질문을 던지는 벡터.
즉, "이 단어가 문장에서 어떤 단어들과 가장 연관이 있는지 알고 싶다!"
💡 Query의 역할:
"나는"이 등장했을 때, "행복을"과 "찾고"와 얼마나 관련이 있는지 알고 싶어!
📌 (2) Key (위쪽, 입력 문장 행)
입력 문장에서 등장한 단어들의 특성을 담고 있는 벡터.
Query와 비교하여 각 단어가 얼마나 관련이 있는지 계산하는 기준.
💡 Key의 역할:
Query("나는")가 Key("행복을")과 비교하여 얼마나 관련이 있는지를 판단하는 기준.
📌 (3) Value (가운데, 입력 문장과 동일한 형태)
Query와 Key를 비교하여 가장 연관성이 높은 단어를 찾은 뒤, 그 단어의 문맥 정보를 반영.
💡 Value의 역할:
Query("나는")가 Key("행복을")과 높은 연관이 있다고 판단되면,
→ Value("행복을")을 최종 결과에 반영!
📌 (2) Query-Key Attention Score 행렬 (왼쪽)
📌 Query와 Key를 내적하여 유사도를 계산하는 과정
그림에서 보이는 왼쪽의 주황색/빨간색 행렬이 바로 Query와 Key를 내적한 "Attention Score 행렬"이야.
각 단어가 다른 단어와 얼마나 관련이 있는지 점수를 계산한 후, Softmax를 적용해서 확률 값으로 변환함.
그런데 여기서 룩 어헤드 마스킹을 적용하여, 미래 단어를 가려버려야 함!
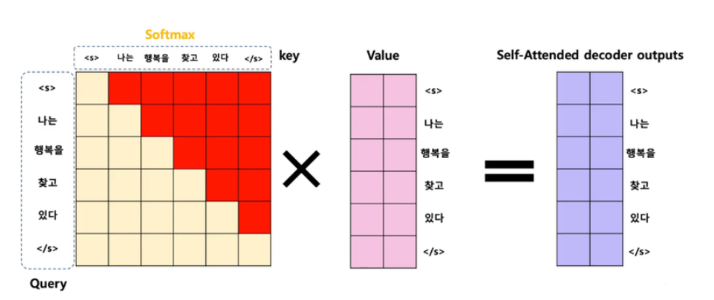
4️⃣ 룩 어헤드 마스킹 적용 방식
룩 어헤드 마스킹은 "현재까지 예측한 단어까지만 참고하도록, 미래 단어를 Softmax에서 제외하는 기법"입니다.
📌 룩 어헤드 마스킹이 적용된 Attention Score 행렬의 모습 (왼쪽 행렬)
빨간색 부분 = 마스킹된 부분 (Softmax 확률이 0이 되어 무시됨)
연한색 부분 = 미래 단어를 볼 수 없는 곳, 현재 단계의 단어 (음수 무한대 값을 넣어 Softmax 적용 후 0이 됨)
분홍색 부분 = 현재까지의 단어들 간의 관계를 학습하는 부분
📌 룩 어헤드 마스킹이 적용된 Attention Score 행렬
📌 룩 어헤드 마스킹의 의미
첫 번째 단어 (s)는 아무 문제 없이 모든 단어와 연관됨.
두 번째 단어 (나는)는 자기 자신까지만 보이고, 이후 단어들은 가려짐.
세 번째 단어 (행복을)는 "나는"과 "행복을"만 보고, "찾고", "있다" 같은 미래 단어는 못 봄.
네 번째 단어 (찾고)는 "나는", "행복을", "찾고"까지만 볼 수 있음.
다섯 번째 단어 (있다)는 "나는", "행복을", "찾고", "있다"까지만 볼 수 있음.
🔥 즉, 룩 어헤드 마스킹이 적용되어, 현재까지의 단어까지만 참고할 수 있도록 제한하는 구조야! 🚀
🔥 즉, 룩 어헤드 마스킹 덕분에 디코더는 훈련 과정에서 미래 단어를 미리 참조하지 않고, 자연스럽게 다음 단어를 예측하는 방식으로 학습할 수 있습니다! 🚀
5️⃣ Softmax 적용 후 Value 행렬과 곱하기
마스킹된 Attention Score 행렬과 Value 행렬을 곱하여 최종적인 Self-Attended Decoder Output을 생성함.
이제 디코더는 현재까지의 단어까지만 참고하면서 다음 단어를 예측할 수 있음.
🔥 즉, 룩 어헤드 마스킹 덕분에 디코더는 훈련 과정에서 미래 단어를 미리 참조하지 않고, 자연스럽게 다음 단어를 예측하는 방식으로 학습할 수 있어! 🚀
🚀 트랜스포머(Transformer) 인코더(Encoder)
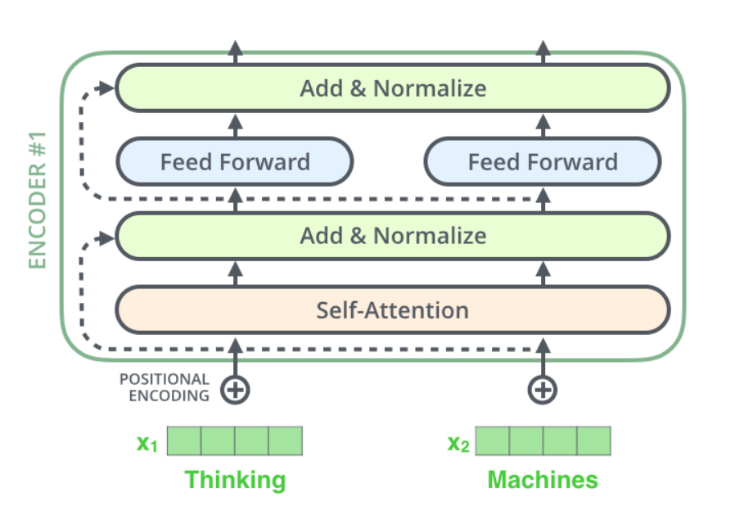
🔹 Self-Attention Layer & Feed Forward Neural Network Layer
트랜스포머의 인코더(Encoder) 내의 각 Sub-layer(층)는 Residual Connection(잔차 연결)을 사용하여 연결되며, 이후 Layer Normalization(층 정규화)을 적용하는 구조입니다.
➡ 즉, 정보 손실을 줄이고 학습을 안정적으로 만들기 위해 이 과정을 거치는 것입니다. 🚀
🔹 1. Residual Connection(잔차 연결)이란?
💡 Residual Connection(잔차 연결)은 입력값을 변형하지 않고 그대로 다음 레이어에 더하는 방식입니다.
➡ 즉, 원래 입력값을 유지하면서도 추가적인 변환을 적용할 수 있도록 합니다! 🚀
📌 Residual Connection의 계산 과정
Output = LayerNorm(Input + Sub-layer(Input))- 현재 입력(Input)을 Sub-layer에 넣어서 변환된 값(예: 어텐션 결과, FFN 결과)을 계산합니다.
- 이 변환된 값과 원래 입력을 더하여 Residual Connection을 적용합니다.
- 이후 Layer Normalization을 적용하여 정규화합니다.
📌 Residual Connection이 필요한 이유?
✅ Gradient Vanishing 문제 완화
- 신경망이 깊어질수록 기울기(Gradient)가 사라지는 문제(Gradient Vanishing)를 방지합니다.
➡ 즉, 네트워크가 깊어질수록 앞쪽(초기 입력층)에 있는 가중치가 업데이트되지 않아서 학습이 느려지거나 멈춰버리는 현상이 발생함. 🚀
✅ 입력값의 원래 정보 유지 - 원래 정보를 유지하면서 새로운 학습된 특징을 추가할 수 있도록 도와줍니다.
✅ 학습 속도 증가 & 안정적인 네트워크 학습 가능 - 신경망이 깊어질수록 학습이 어려워지는데, Residual Connection이 이를 해결합니다.
🔥 즉, Residual Connection을 사용하면 입력 정보를 보존하면서도 새로운 정보를 추가할 수 있습니다! 🚀
🔹 2. Layer Normalization(층 정규화)이란?
💡 Layer Normalization(층 정규화)은 신경망의 각 층에서 출력을 정규화하여 안정적인 학습을 가능하게 하는 기법입니다.
➡ 즉, 모델이 더 빠르게 수렴하고, Gradient Explosion(기울기 폭발)이나 Overfitting(과적합)을 방지하는 역할을 합니다! 🚀
📌 Layer Normalization의 계산 과정
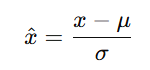
- 각 층의 출력을 평균(𝜇)과 분산(𝜎)을 사용하여 batch에 있는 각 input을 정규화합니다.
- 이후 학습 가능한 가중치와 편향을 적용하여 다시 변환합니다.
📌 Layer Normalization이 필요한 이유?
✅ 모델 학습 안정성 향상
✅ Gradient Vanishing & Gradient Explosion 방지
✅ Batch 크기와 무관하게 동작 (BN과의 차이점!)
🔥 즉, Layer Normalization을 적용하면 신경망의 출력을 안정적으로 유지할 수 있습니다! 🚀
🔹 배치 정규화(Batch Normalization) vs 층 정규화(Layer Normalization)
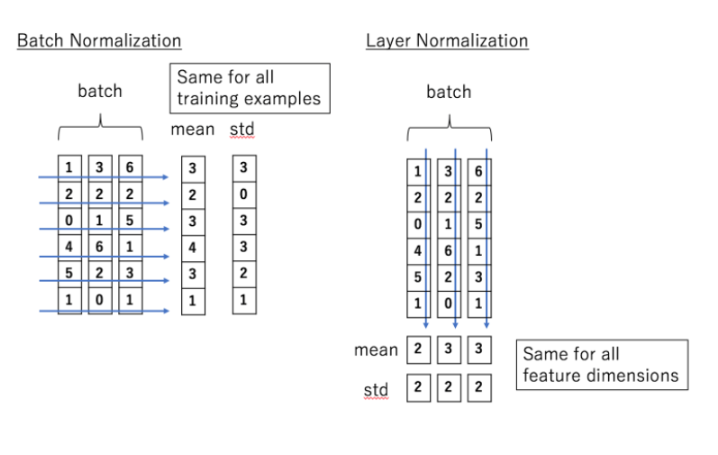
🟦 1. 배치 정규화(Batch Normalization, BN)
배치 정규화(Batch Normalization, BN)는 "미니배치(batch) 단위로 정규화하는 방법"이다.
즉, 배치 내의 모든 샘플을 기준으로 평균(mean)과 표준편차(std)를 계산하고, 이를 사용해 정규화한다.
📌 배치 정규화의 과정
1️⃣ 배치(batch)에서 각 feature(특징)마다 평균(mean)과 표준편차(std)를 계산
2️⃣ 해당 평균과 표준편차를 사용하여 정규화 수행
3️⃣ 각 미니배치마다 다른 정규화 값이 적용됨
📌 그림 해석 (왼쪽)
- 각 특징(feature)별로 평균(mean)과 표준편차(std)를 계산함.
- 즉, 열(column) 기준으로 정규화 진행!
- 같은 특징이라도, 다른 미니배치(batch)에서는 정규화 값이 달라질 수 있음.
💡 즉, 배치 정규화는 같은 특성을 가지는 값들끼리 정규화하며, 배치 단위로 동작하는 기법!
🔥 배치 정규화의 한계
배치 정규화(BN)는 배치 내(feature별) 평균과 표준편차를 계산하여 정규화하는 방식이다. 그러나 트랜스포머와 같은 모델에서는 BN을 사용하기 어렵거나 비효율적일 수 있다!
📌 (1) 배치 크기에 의존적임
- 배치 정규화는 배치 내에서 feature별 평균과 표준편차를 계산함.
- 따라서 배치 크기(Batch Size)가 작으면, 평균과 표준편차의 신뢰성이 낮아지고 학습이 불안정해질 수 있음.
- 하지만 트랜스포머는 종종 작은 배치 크기에서도 학습해야 하므로, 배치 크기에 영향을 받지 않는 정규화 방식이 필요함!
📌 (2) 시퀀스(문장) 모델에는 적합하지 않음
- 배치 정규화는 일반적으로 CNN이나 이미지 모델에서는 잘 동작하지만, 문장을 처리하는 RNN, 트랜스포머 같은 모델에서는 문제가 발생할 수 있음.
- 예를 들어, 문장 길이가 다를 경우 배치 내 패딩(Padding) 처리가 어려움.
- 시퀀스 모델에서 샘플 간 정규화를 하면, 문맥 정보가 왜곡될 가능성이 있음.
🔥 즉, 배치 정규화는 시퀀스 데이터(문장) 처리에는 적절하지 않으며, 트랜스포머 같은 모델에서는 사용하기 어려워! 🚀
🟦 2. 층 정규화(Layer Normalization, LN)
층 정규화(Layer Normalization, LN)는 "각 샘플(데이터 포인트) 단위로 정규화하는 방법"이다.
즉, 각 데이터 포인트(샘플)의 모든 feature 값들을 기준으로 평균(mean)과 표준편차(std)를 계산하여 정규화한다.
📌 층 정규화의 과정
1️⃣ 각 샘플(한 데이터 포인트)에서 평균(mean)과 표준편차(std)를 계산
2️⃣ 해당 평균과 표준편차를 사용하여 정규화 수행
3️⃣ 모든 데이터 포인트에서 동일한 방식으로 정규화됨 (배치와 무관함)
📌 그림 해석 (오른쪽)
- 각 데이터 포인트(샘플) 단위로 평균(mean)과 표준편차(std)를 계산
- 즉, 행(row) 기준으로 정규화 진행!
- 같은 샘플이라면, 어떤 배치에서든 동일한 정규화 값을 가짐.
💡 즉, 층 정규화는 샘플 자체를 기준으로 정규화하며, 배치 크기에 영향을 받지 않는 기법!
🔥 층 정규화를 사용하는 이유
층 정규화(LN)는 배치 크기에 영향을 받지 않고, 문장을 구성하는 각 단어의 표현(Embedding)을 정규화할 수 있다.
따라서 트랜스포머와 같은 자연어 처리(NLP) 모델에서 더 적합함.
📌 (1) 배치 크기(Batch Size)에 영향을 받지 않음
- LN은 각 샘플(단어)에 대해 개별적으로 정규화함.
- 즉, 배치 크기에 영향을 받지 않고 일관된 성능을 유지할 수 있음!
- 트랜스포머는 GPU 메모리 문제로 인해 작은 배치 크기로 학습하는 경우가 많으므로, BN보다 LN이 훨씬 유리함.
📌 (2) 문장의 각 단어를 독립적으로 정규화 가능
- 트랜스포머에서는 문장을 구성하는 단어 각각이 하나의 샘플(Sample)로 처리됨.
- 즉, 층 정규화에서는 "각 단어"에 대해 정규화를 수행한다고 볼 수 있음!
- Self-Attention에서는 모든 단어가 서로 영향을 주기 때문에, 각 단어를 독립적으로 정규화하는 것이 더 효과적임.
🔥 즉, 층 정규화는 배치 크기에 영향을 받지 않으면서, 트랜스포머가 문장 내 단어를 처리하는 방식과 더 잘 맞기 때문에 사용되는 거야! 🚀
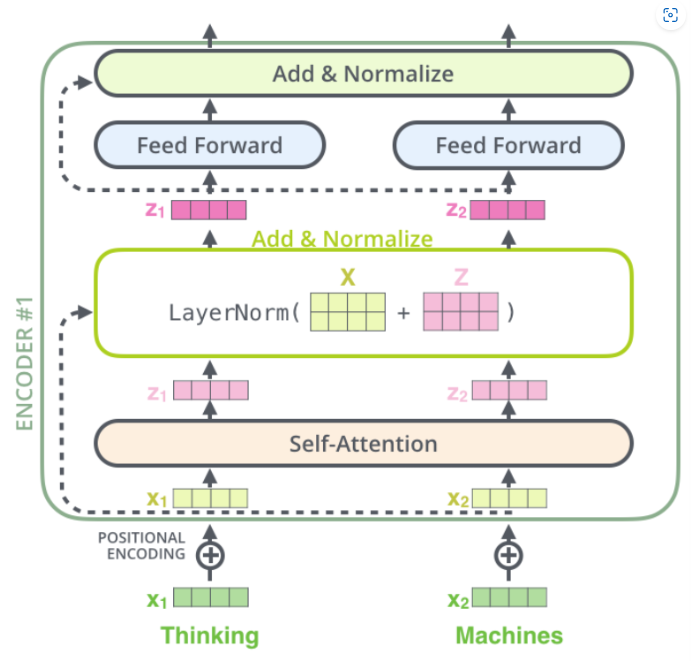
🚀 Transformer 디코더 (Decoder)
📌 디코더의 입력
① 인코더 마지막 블록에서 나온 단어 벡터 시퀀스
인코더(Encoder)는 입력 문장을 벡터로 변환하는 역할을 합니다.
트랜스포머의 인코더는 입력 문장의 모든 단어를 벡터로 변환하고, 단어 간의 관계를 학습하여 최종 벡터 시퀀스를 생성합니다.
마지막 인코더 블록에서 나온 벡터는 입력 문장의 의미를 압축한 표현(고유한 의미 벡터)이라고 볼 수 있습니다.
📌 예제 문장 (영어 → 한국어 번역)
입력 문장:
"I love NLP"인코더의 마지막 블록에서 생성된 벡터 시퀀스:
| 단어 | 벡터 변환 |
|---|---|
| I | → h1 |
| love | → h2 |
| NLP | → h3 |
디코더는 이 벡터 시퀀스를 참조하여 번역할 문장을 생성할 때 활용합니다.
🔥 즉, 인코더가 입력 문장의 의미를 벡터로 변환하고, 디코더는 이 정보를 기반으로 문장을 생성하는 것입니다! 🚀
② 이전 디코더 블록의 수행 결과 (타깃 단어 벡터 시퀀스)
디코더는 문장을 한꺼번에 생성하는 것이 아니라, 단어를 하나씩 예측하면서 문장을 만들어갑니다.
현재까지 생성된 단어들을 바탕으로 다음 단어를 예측해야 하므로, 이전 블록의 출력이 다음 블록의 입력으로 사용됩니다.
이는 RNN의 "시퀀스 기반 학습 방식"과 유사하지만, 트랜스포머는 병렬 연산을 지원하므로 훨씬 빠릅니다.
📌 예제 (한국어 문장 생성 과정)
타깃 문장: "나는 NLP를 사랑해."1️⃣ 디코더가 처음에는 시작 토큰(s)을 입력받음.
2️⃣ 이전 디코더 블록에서 예측된 단어를 다음 블록의 입력으로 사용하여 점점 더 문장을 확장해 나감.
🔥 즉, 디코더는 이전에 예측된 단어들을 입력으로 받아, 점진적으로 문장을 만들어 가는 방식입니다! 🚀
🔹 디코더의 입력 ①과 ②가 함께 사용되는 이유
디코더는 "입력 문장의 의미" + "현재까지 생성된 문장"을 조합하여 다음 단어를 예측해야 합니다.
✔ ① 인코더에서 얻은 정보(입력 문장의 의미)를 참고하여 번역 방향을 설정
✔ ② 이전에 생성된 단어들을 사용하여 문장의 흐름을 유지하면서 다음 단어를 예측
📌 디코딩 예제
1️⃣ 인코더가 "I love NLP"를 벡터로 변환하여 디코더에게 전달
2️⃣ 디코더는 시작 토큰 s을 입력받아 "나는"을 예측
3️⃣ 디코더는 "나는"을 입력받아 "NLP를"을 예측
4️⃣ 디코더는 "나는 NLP를"을 입력받아 "사랑해."을 예측🔥 즉, 디코더는 "입력 문장의 의미"와 "현재까지의 예측 결과"를 함께 참고하여 문장을 만들어 가는 것입니다! 🚀
📌 Decoder Self-Attention
번역하려는 언어(예: 한국어 → 영어 번역 시 영어)의 단어 벡터 시퀀스를 디코더 셀프 어텐션을 통해 계산합니다.
예를 들어, "I went to the cafe there." 문장에서 ‘cafe’ 다음으로 올 단어가 ‘there’임을 맞추는 과정입니다.
| 단어 | 어텐션 값 |
|---|---|
| I | 0.01 |
| went | 0.01 |
| to | 0.02 |
| the | 0.03 |
| cafe | 0.05 |
| there | 0.80 |
📌 Masked Multi-Head Attention
소스 언어 문장(예: "어제 카페 갔었어 거기 사람 많더라")의 단어 벡터 시퀀스를 Key로 삼고, 타깃 언어 문장(예: "I went to the cafe yesterday. There...")의 단어 벡터 시퀀스를 Query로 삼아 셀프 어텐션 계산을 수행합니다.
💡 쿼리는 질문이고, 답을 찾기 위해 참조하는 것이 키(Key)라는 점을 기억하세요!
예를 들어, 쿼리(Query) 안의 'cafe'에 대응하여 Key 요소들은 셀프 어텐션을 통하여 확률값을 갖고 그중 가장 높은 확률을 갖는 '카페'를 맞추는 것입니다.

📌 마스킹(Masking) 기법
학습시 디코더에서 수행되는 셀프 어텐션에는 단어 벡터 시퀀스에 마스킹이 적용됩니다.
✅ 목적:
미래 정보를 참고하는 것을 방지하여, 정답을 포함한 미래 정보를 셀프 어텐션 계산에서 제외하도록 하기 위함입니다.
✅ 방법:
마스킹이 적용된 단어 정보는 확률값이 0이 되게 하여 해당 단어 정보가 무시되도록 합니다.
📌 멀티-헤드 어텐션 (Multi-Head Attention)
Decoder Self-Attention과 Encoder-Decoder Attention 모두 스케일드 닷 프로덕트 어텐션(Scaled Dot-Product Attention)을 멀티-헤드 어텐션(Multi-Head Attention)으로 병렬 수행합니다.
🚀 이를 통해 병렬 연산이 가능해지고, 더욱 강력한 문맥 이해가 가능합니다!
📌 디코딩 과정
1️⃣ 각 스텝마다 출력된 단어가 다음 스텝의 디코더 입력이 됨
2️⃣ 여러 디코더 레이어를 통과하며 문장이 생성됨
3️⃣ 출력할 문장이 완성될 때까지 반복
🔥 즉, 디코더는 "입력 문장의 의미" + "현재까지의 예측 단어"를 바탕으로 번역을 수행하는 것입니다! 🚀
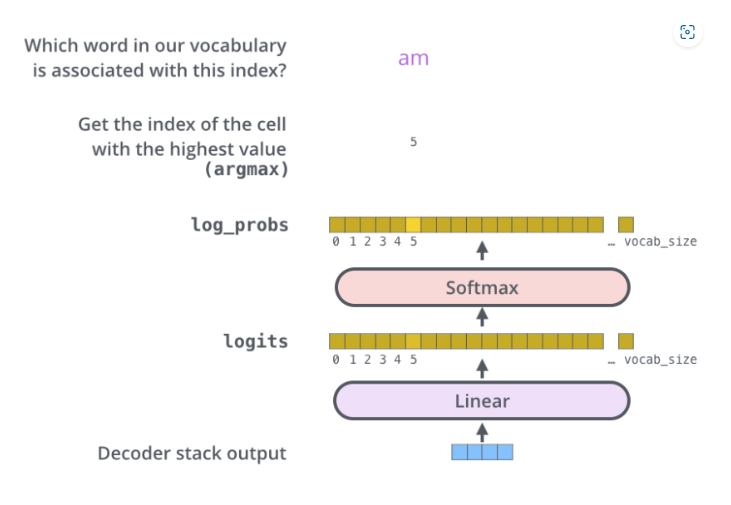
Linear Layer & Softmax Layer
📌 디코더의 최종 결과물인 벡터를 Linear Layer와 Softmax Layer를 통해 예측 단어로 바꿔준다.
💡 트랜스포머(Transformer)의 디코더는 최종적으로 "단어 벡터"를 "단어"로 변환해야 해!
➡ 이를 위해 Linear Layer(선형 변환) 와 Softmax Layer(확률 변환) 를 사용해서 단어를 예측하는 거야! 🚀
📌 Linear Layer: fully-connected 신경망으로 디코더의 출력 벡터를 훨씬 더 큰 사이즈인 logits 벡터로 투영시킴. 예를 들어 10,000개의 영어 단어를 학습하였다고 가정하면 logits vector의 크기는 10,000이 됨. 벡터의 각 요소는 각 단어에 대한 점수
📌 softmax layer: logits vector의 각 셀들의 점수를 확률로 변환해주는 역할. 각 셀값들을 모두 더하면 1이 되고 가장 높은 확률 값을 가지는 셀의 단어가 최종 출력됨.
🔹 1. 디코더가 문장을 생성하는 과정
📌 디코더의 출력은 처음부터 단어가 아니라 "벡터"야!
➡ 따라서 이 벡터를 실제 단어로 변환해야 함!
📌 예제 (한국어 번역을 생성하는 과정)
- 입력 문장:
"I love NLP" - 디코더의 최종 출력 벡터:
[0.3, 1.5, -0.2, 0.8, ...](숫자 벡터) - ➡ 이 벡터를 실제 단어로 변환해야 함!
- 🔥 이제 Linear Layer 와 Softmax Layer 를 사용하여 이 벡터를 단어로 변환하는 과정이 필요해! 🚀
🔹 2. Linear Layer (선형 변환)
📌 디코더의 출력 벡터를 "단어 사전(Vocabulary)" 크기의 벡터로 변환하는 과정이야.
➡ Fully-connected 신경망(FC layer, 선형 변환)을 사용하여, 벡터를 logits 벡터 로 변환함.
📌 어떻게 동작하는가?
- 예를 들어, 우리가 10,000개의 영어 단어 를 학습한 모델을 가지고 있다고 가정해보자.
- 그러면 Linear Layer의 출력 차원은 10,000 이어야 함.
- 즉, 디코더에서 나온 벡터를 10,000차원 벡터(logits)로 투영 시킴.
📌 Linear Layer 계산 과정
logits=W×output_vector+b
- W: (단어 사전 크기 × 디코더 출력 차원) 크기의 가중치 행렬
- output_vector: 디코더의 최종 출력 벡터
- b: 편향(bias)
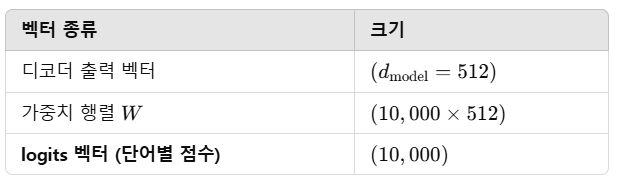
🔥 즉, 디코더의 출력 벡터(512차원)를 곱해서 10,000차원의 logits 벡터로 변환하는 과정이야! 🚀
🔥 즉, Linear Layer는 "디코더의 벡터"를 "단어별 점수 벡터(logits)"로 변환하는 역할을 함! 🚀
🔹 3. Softmax Layer (확률 변환)
📌 Linear Layer에서 나온 logits 벡터는 단순한 "점수"일 뿐이야.
➡ 따라서 Softmax를 적용해서 "확률 분포"로 변환해야 함.
📌 Softmax 계산 공식
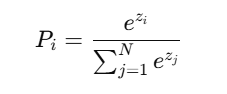
- P_i: i번째 단어가 선택될 확률
- Z_i: logits 벡터 값 (해당 단어의 점수)
- N: 단어 사전(Vocabulary) 크기
🔹 Logits 벡터의 예제
📌 예제: "나는 NLP를" 다음 단어를 예측하는 과정
디코더의 최종 출력 벡터가 아래와 같은 logits 벡터로 변환된다고 가정해 보자:
logits = [ -0.3, 2.5, 0.8, 1.7, -1.1, ... ] (총 10,000개)- logits 벡터의 크기는 단어 사전 크기(10,000)와 동일함.
- 각 값 Z_i 는 특정 단어에 대한 점수를 의미함.
- 점수가 높은 단어일수록 문맥상 더 적절할 가능성이 높음.
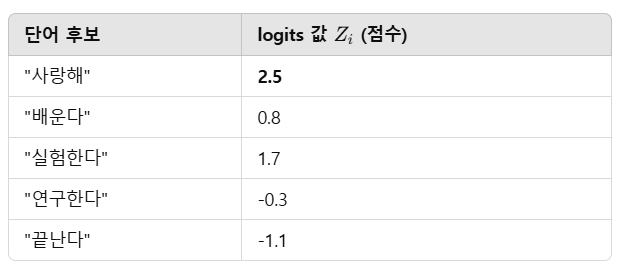
🔥 즉, logits 벡터의 값은 "각 단어가 현재 문장에서 등장할 가능성(적절성)"을 나타내는 점수야! 🚀
📌 Softmax 적용 후 특징
- logits 벡터를 확률 값으로 변환함.
- 모든 단어의 확률을 더하면 1이 됨.
- 가장 확률이 높은 단어를 선택하여 최종 출력 단어로 결정!
📌 예제 (Softmax 적용 과정)
✅ Logits 벡터 (Linear Layer 출력):
[0.2, 2.5, -1.3, 1.7, 0.9, ...] (10,000개)✅ Softmax 적용 후 확률 벡터:
[0.01, 0.60, 0.02, 0.20, 0.05, ...] (10,000개)✅ 확률이 가장 높은 단어 선택!
➡ 2번째 값(0.60)이 가장 크므로, 해당 단어가 최종 출력됨!
🔥 즉, Softmax는 "logits 벡터"를 "확률 분포"로 변환하고, 가장 확률이 높은 단어를 선택하는 역할을 함! 🚀