✅ Abstract
기존 방법들은 구조적으로 잘 접히는 단백질과 원하는 기능이 좋은 단백질을 동시에 만족시키는 데 어려움이 있음
① 구조 기반 모델
단백질이 안정적으로 접히는 구조(foldability) 를 잘 맞춤
하지만 기능적 성질은 놓칠 수 있음
② 단백질 언어모델(Protein Language Model, PLM)
진화적 신호나 기능 관련 패턴을 잘 포착함
하지만 구조적으로 불안정한 서열을 예측하는 경우가 많음
즉,
구조 모델은 “잘 접히는지”는 강하지만
언어모델은 “기능적으로 그럴듯한지”는 강함
논문은 MAProt라는 프레임워크를 제안
- 구조 기반 방법 (예: ProteinMPNN)
→ 목표 backbone에 잘 맞는 서열 생성 - 단백질 언어모델 기반 방법 (예: ESM, SaProt)
→ 진화적으로 그럴듯하고 기능적으로 유망한 서열을 선호
을 다중 에이전트(multi-agent) 형태로 함께 사용
에이전트들 간 목표 충돌을 해결하기 위해
Pareto 기반 협상 모듈(Pareto-based negotiation module) 을 도입
서로 다른 기준을 내세우는데, 그중 하나만 밀어붙이지 않고
여러 목표를 동시에 최대한 잘 만족하는 균형점을 찾는 방식
✅ Introduction
단백질 설계의 핵심 난제:
구조적 접힘 가능성(foldability) 과 기능적 성능(functional performance) 의 균형
즉,
“기능은 좋아졌는데 구조가 무너짐”
혹은
“구조는 안정적인데 기능이 별로”
같은 상황이 생김.
구조 기반 방법의 장점과 한계
장점:
구조적 무결성(structural integrity)을 잘 보장함
target backbone과 잘 맞는 서열을 찾는 데 강함
한계:
효소 활성
결합 친화도
열안정성(thermostability)
같은 핵심 기능 속성을 충분히 반영하지 못할 수 있음
그래서 구조는 맞는데
원하는 기능이 충분히 나오지 않는 단백질을 만들 수 있음
언어모델의 장점과 한계
대규모 단백질 데이터베이스에서
전역적 서열 패턴(global sequence patterns)
진화적 제약(evolutionary constraints)
을 잘 학습함
그래서 실험 라벨 데이터가 많지 않아도
기능적으로 중요한 신호를 어느 정도 추론할 수 있음
하지만 문제는,
이런 모델들이 생성한 서열은 종종
구조적 안정성
foldability
가 떨어질 수 있다는 점
즉,
언어모델은 “생물학적으로 그럴듯한 말”은 잘하지만,
그게 실제로 안정적으로 접히는 단백질 문장인지는 또 다를 수 있음
서로 다른 모델은
foldability
evolutionary plausibility
functional fitness
같은 서로 다른 목표를 보고 있고,
이 목표들은 종종
서로 양립 불가능하거나
일부 겹치거나
일부 충돌함
즉, 문제는 단순 통합이 아니라
이질적인 모델들의 충돌을 어떻게 조정하고 합의시킬 것인가라는 것임
MAProt라는 multi-agent 기반 프레임워크
구조 기반 에이전트: ProteinMPNN
→ target backbone과의 적합성 보장
서열 기반 에이전트: ESM, SaProt
→ 전역적 서열 특성과 돌연변이 효과를 포착
단백질 설계는 다중 목적 최적화(multi-objective optimization) 문제
즉, 단순히 하나의 점수만 최대화하는 것이 아니라,
여러 목표를 동시에 고려해야 한다는 뜻
✅ Method
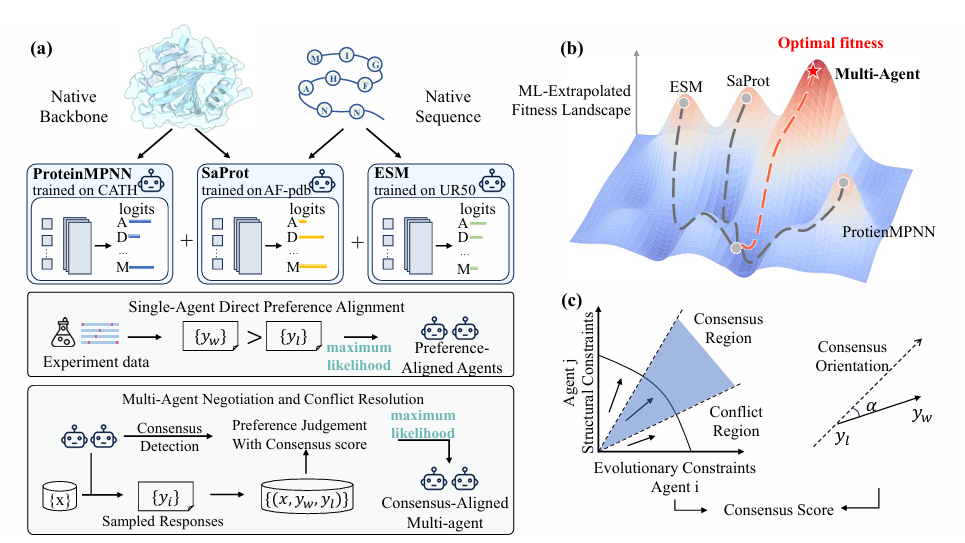
Multi-Agent Negotiation and Consensus 단계
- agent들의 의견이 어디서 일치하는지 찾고
- 충돌하는 부분을 해결하
- 그 결과를 다시 반영해
- 최종적으로 합의된 설계 방향으로 유도하는 구조
ProteinMPNN: “이 구조에 맞는 서열이 뭐냐?”를 잘 맞힘
ESM: “이 서열이 자연스럽고 기능적으로 그럴듯한가?”를 잘 봄
SaProt은 서열 + 구조를 함께 보는 모델: “이 residue가 무슨 아미노산인지”뿐 아니라, “구조적으로 어떤 상태인지”도 같이 보는 모델
Building Preference Data
실험적으로 측정된 protein fitness에 맞추기 위해, sequence preference pair를 구성

즉, 같은 입력에 대해
“이 둘 중 어느 쪽이 더 좋다”는 짝(pair)을 만들어
모델이 그 preference를 배우게 하는 방식
-> 점수 하나만 주는 게 아니라,
“이 서열이 저 서열보다 낫다”는 비교 데이터를 만드는 것
서열 A: 실험 결과 더 좋음
서열 B: 실험 결과 덜 좋음
각 모델을 먼저 실험 데이터로 “좋은 서열을 더 좋아하도록” 다시 맞춰줌
Direct Preference Optimization(DPO)
각 agent는 처음에는 대규모 서열/구조 데이터로 pretraining된 모델
이후 실험 fitness에 맞도록,
고 fitness sequence를 더 선호하도록 policy를 fine-tune 함
핵심은
“입력 𝑥가 주어졌을 때, 좋은 sequence 𝑦𝑤를 나쁜 sequence 𝑦𝑙 보다 더 선호하게 만들자”는 것
“좋은 서열은 더 높은 확률을 주고, 나쁜 서열은 더 낮은 확률을 주도록 모델을 조정하도록 학습”
ProteinMPNN도 “좋은 구조”만 보는 게 아니라 실험적으로 좋은 방향을 더 좋아하게 만들고
ESM도 “자연스러운 서열” 중에서 실제 목표에 더 맞는 걸 선호하게 만들고
SaProt도 구조-서열 관점에서 더 좋은 후보를 선호하게 만듦
그 후, 여러 모델의 의견이 얼마나 비슷한지 본다
“이 후보 서열을 세 모델이 진짜로 같이 좋다고 보고 있나?”
Pareto-based Multi-Agent Preference Agreement
consensus(합의)와 conflict(충돌)를 구분
그 후, 합의를 숫자로 만듦 -> consensus score
consensus score를 만드는 방식
- 방향이 같은가?
좋은 서열이 나쁜 서열보다 더 좋다고
세 모델이 같은 방향으로 평가하는가
- 실제로 agreement 비율이 높은가?
agent pair들 사이에서
consensus label이 많이 붙는가
합의가 높은 데이터에 더 큰 가중치
Multi-Agent Sampling
서열을 한 글자씩 생성할 때
각 모델이 “다음 아미노산은 뭐가 좋을지” 점수를 내고,
그 점수들을 더해서 최종 결정을 내림
✅ Results
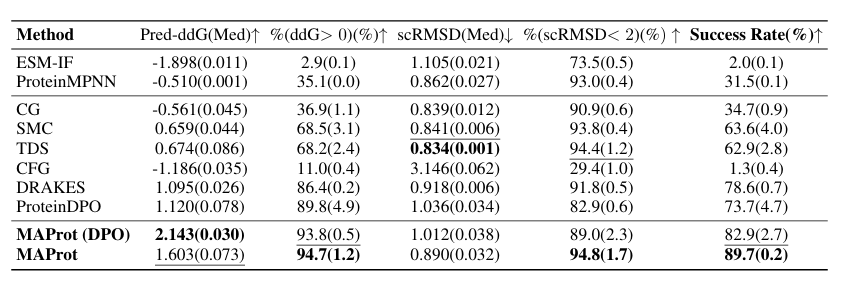
MAProt(DPO) 는 안정성 향상 폭 자체는 제일 큼
최종 MAProt 은 안정성과 구조 보존, 성공률의 전체 균형이 가장 좋음
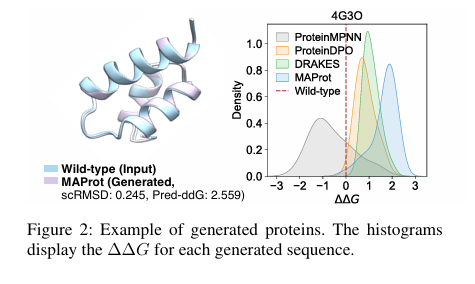
원래 구조와 매우 비슷하게 유지되면서(scRMSD 0.245),
안정성은 크게 좋아짐
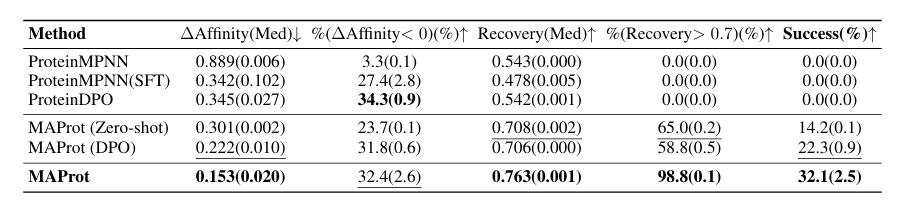
Affinity 도 MAProt 이 가장 success 가 높음
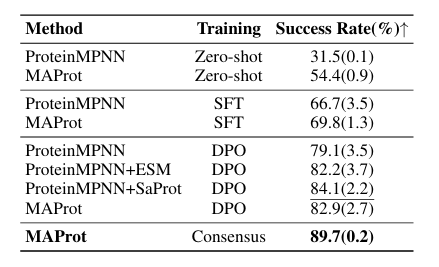
multi-agent framework가 single-agent보다 일관되게 더 좋다고 주장
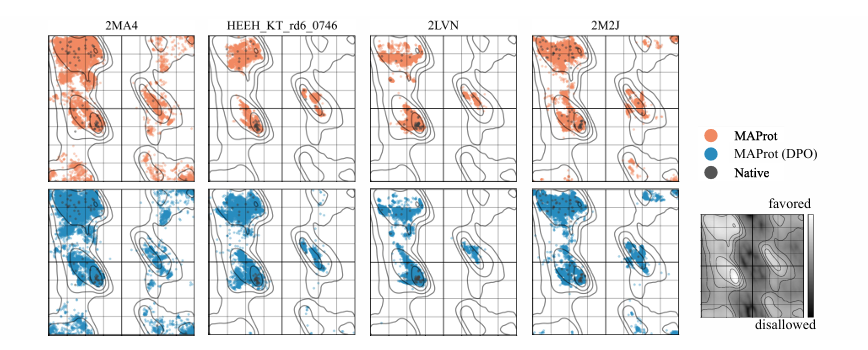
MAProt 과 MAProt(DPO) 의 생성 구조는
대부분 favored region에 집중되어 있고
native protein과 매우 비슷함
이는 생성 구조가 기하학적으로 타당하고, steric clash가 거의 없다는 뜻
MAProt은 disallowed region에 의미 있는 population이 거의 없음
반면 MAProt(DPO) 는 일부 residue가 이런 불리한 영역에 보임
