서울대
1.서울대 가기 전 공부
큰 주제: 발현 정제, Binding/Non-Binding포항공대와 협업Lama 3.2를 finetuning(LoRA, QLoRa 통해)그 후, ProteinMPNN 을 통해 자체 서열 생성하여, 새로운 단백질 생성\-> De novo + 발현까지 좋도록목표: 단백질
2.[논문 리뷰] Target-conditioned diffusion generates potent TNFR superfamily antagonists and agonists

https://www.science.org/doi/10.1126/science.adp1779기존 단백질 설계는 평탄하고 극성인 표면을 가진 표적(TNFR1 등)에 대해 형상 적합성(shape complementarity)이 낮아서 결합체 설계에 실패해왔음제한된
3.[논문 리뷰] Atomically accurate de novo design of antibodies with RFdiffusion
https://www.biorxiv.org/content/10.1101/2024.03.14.585103v2현재 항체 개발은 주로 동물 면역이나 무작위 라이브러리 스크리닝에 의존이 방식은 시간이 오래 걸리고, 원하는 에피토프에 정확히 결합하는 항체를 찾기 어려움
4.[논문 리뷰] An adaptive autoregressive diffusion approach to design active humanized antibody and nanobody
sdr -> mouse의 cdr3 중 결합하는 잔기만 남기고 나머지 cdr3 잔기는 human 꺼로 대체\-> 아직 할 수 있는 tool 없음
5.[논문 리뷰] BioPhi: A platform for antibody design, humanization, and humanness evaluation based on natural antibody repertoires and deep learning
Sapiens는 언어 모델링을 사용하여 OAS에서 학습된 딥러닝 인간화 방법
6.[논문 리뷰] Computational optimization of antibody humanness and stability by systematic energy-based ranking
1️⃣ 동물 항체의 구조를 기반으로 모든 가능한 인간 V/J 조합의 framework (~20,000개 이상)에 CDR을 graft2️⃣ Rosetta 에너지 함수(ref2015)를 기반으로 에너지 최적화 순위 선정3️⃣ 높은 homology(유전자 유사성)보다 에너지
7.[논문 리뷰] Data-driven analyses of human antibody variable domain germlines: pairings, sequences and structural features
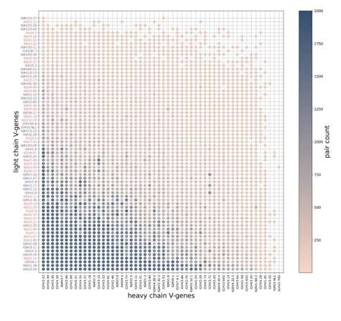
1️⃣ 기존 가설항체의 VH (Heavy)와 VL (Light) 체인은 무작위로 결합한다2️⃣ 문제 제기실제 pairing은 비무작위적(nonrandom)일 가능성이 있으며, 서열, 구조, 전하 등이 영향을 미칠 수 있다3️⃣ 목표:OAS (Observed Antibo
8.[논문 리뷰] Improving Protein Expression, Stability, and Function withProteinMPNN
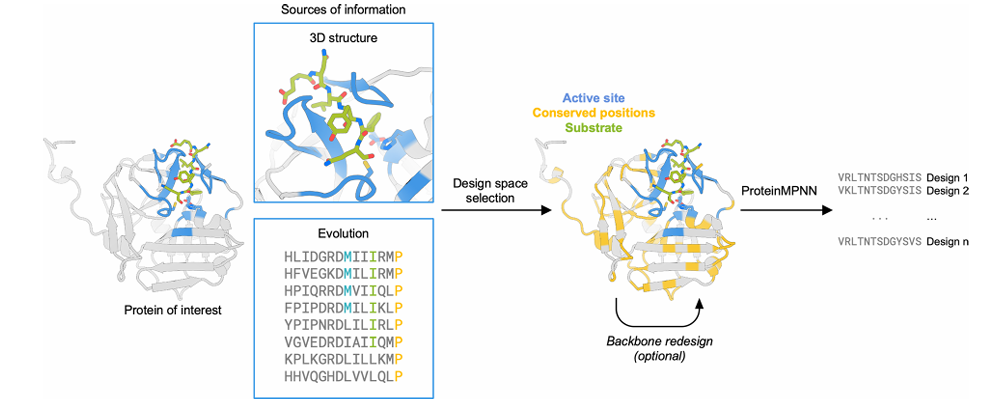
문제점: 자연 단백질은 기능에는 최적화되어 있지만, 대량 생산에는 적합하지 않음\-> 낮은 발현량, 낮은 용해도, 낮은 열안정성 등ProteinMPNN의 장점설계된 단백질 골격(backbone)에 대해 매우 안정적인 서열 생성 가능자연 단백질의 구조(backbone)에
9.[논문 리뷰] A PD-1-targeted, receptor-masked IL-2 immunocytokine that engages IL-2 Ra strengthens T cell-mediated anti-tumor therapies
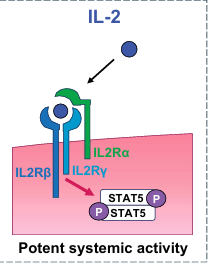
고전적인 IL-2 기반 면역치료의 독성 문제를 해결하면서도 항암 효능을 유지하거나 향상시키기 위해 새롭게 설계된 “PD-1-targeted, receptor-masked IL-2” 치료제를 소개IL-2R 알파를 활성화하는 PD-1 표적 receptor-masked IL
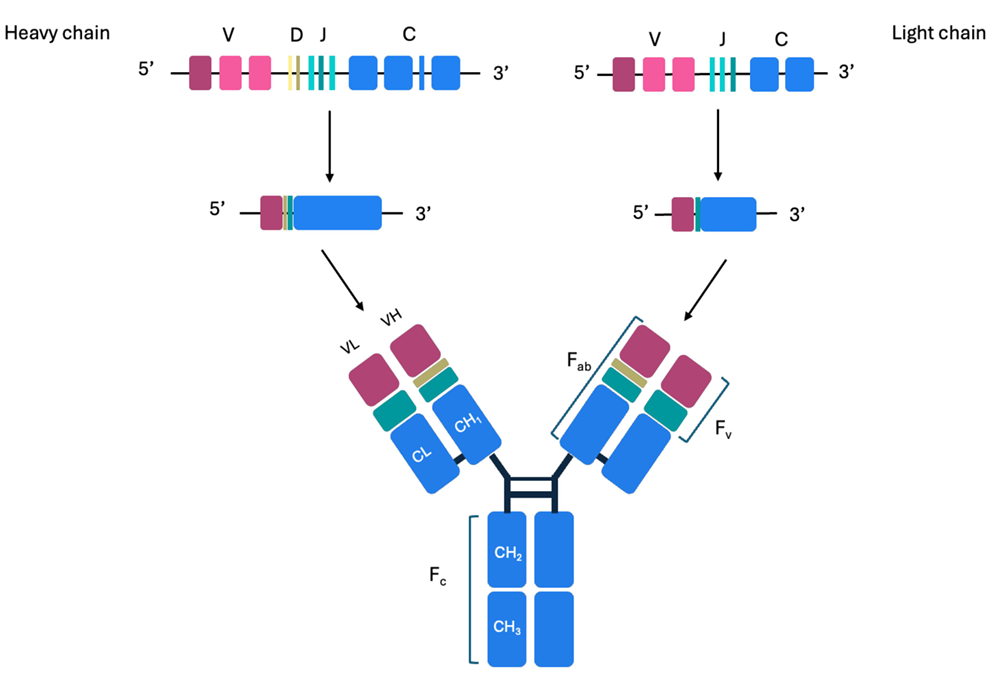
10.[논문 리뷰] Antibody Structure and Function: The Basis for Engineering Therapeutics
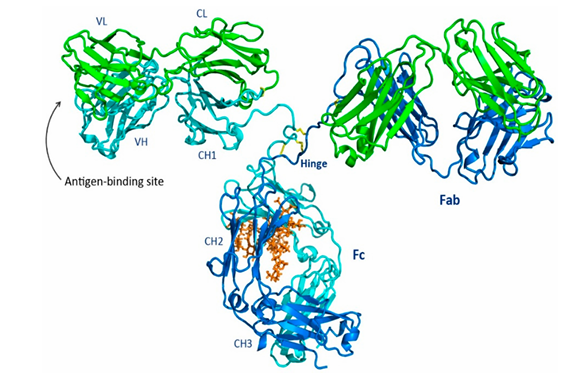
면역계가 침입자를 인식하고 제거하기 위해 생성하는 단백질.가벼운 사슬. 항체의 한쪽 팔을 구성.무거운 사슬. 항체의 중심 축과 팔을 형성.항체는 Y자 모양의 단백질로, 두 개의 같은 Light Chain과 두 개의 같은 Heavy Chain이 붙어 만들어짐이 네 개의
11.[논문 리뷰] MULAN: Multimodal Protein Language Model for Sequence and Structure Encoding
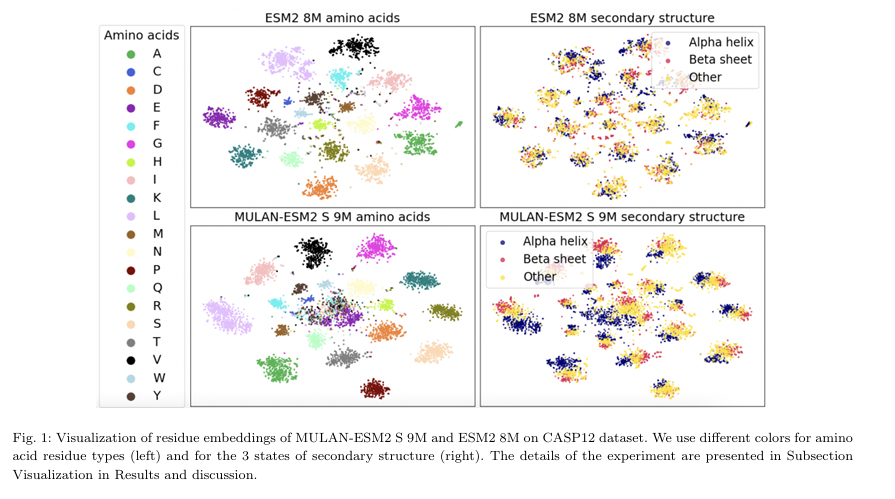
기존 단백질 언어 모델(PLM)에 구조 정보를 효율적으로 통합하기 위한 새로운 모델 MULANESM2 등 기존 sequence-only PLM 위에 구조 정보를 통합할 수 있는 lightweight adapter를 추가하여, 구조 인식 능력을 크게 향상시키면서도 파라미
12.[논문 리뷰] Evolutionary-scale prediction of atomic level protein structure with a language model
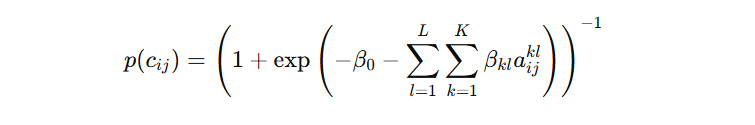
단백질 서열만 보고 구조나 기능을 예측하는 언어 모델Transformer 기반 BERT 같은 모델을 사용사람의 문장 대신, 단백질 서열(아미노산 나열)을 입력훈련할 때는 “이 마스킹된 아미노산은 뭘까?”를 맞히는 식으로 학습 (= Masked Language Model
13.[논문 리뷰] An Integrative Strategy Enhancing Nanobody Thermostability via CDR Grafting, InSilico Mutagenesis Screening, and Multiplex Evaluation
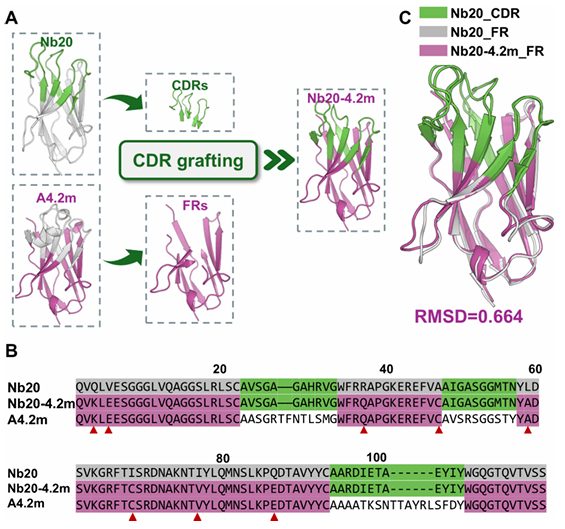
나노바디는 항체보다 작고 안정적이지만, 열안정성은 개별 분자마다 큰 차이를 보이며, 응용 시 안정성이 낮으면 단백질이 변성되고 약효가 떨어짐.특정 SARS-CoV-2 나노바디(Nb20)를 기반으로 열안정성을 향상시키되, 항원 결합능력(affinity)을 유지하는 것을
14.[논문 리뷰] Transfer learning to leverage larger datasets for improved prediction of protein stability changes
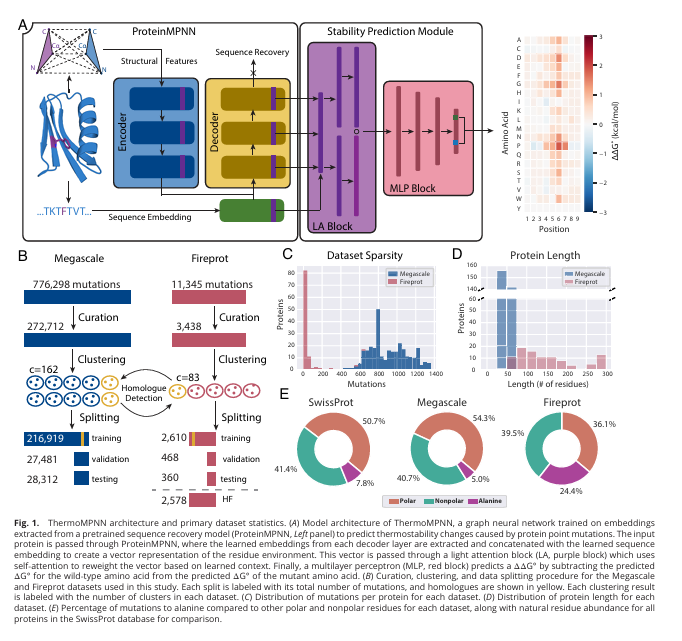
단백질의 단일 아미노산 변이(single-point mutation)가 단백질 안정성(thermodynamic stability)에 미치는 영향을 정확히 예측하기 위한 딥러닝 기반 예측 모델 ThermoMPNN을 제안목표: 기존 구조 기반 모델 ProteinMPNN을
15.[논문 리뷰] A Python library for probabilistic analysis of single-cell omics data
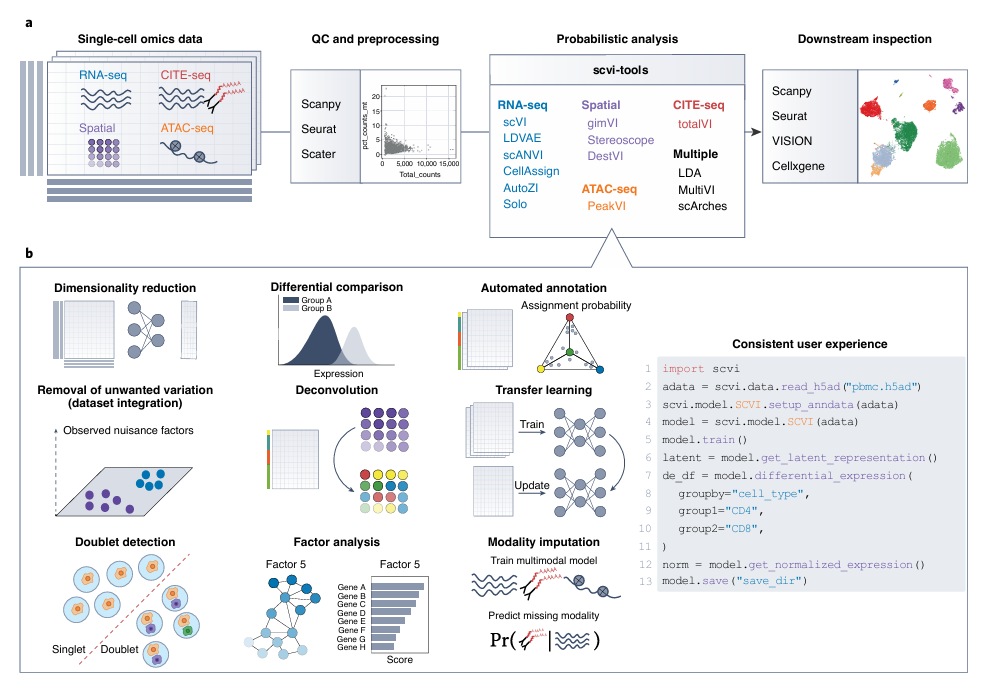
단일세포 오믹스 데이터를 확률적 방법으로 분석하기 위한 Python 기반 오픈소스 라이브러리인 scvi-tools🔧 1. 배경 및 필요성🔹 단일세포 오믹스 분석의 핵심 작업들차원 축소세포 클러스터링세포 상태 주석(annotation)잡음/배치 효과 제거차등 발현 분
16.[논문 리뷰] Single-sequence protein structure prediction using a language model and deep learning
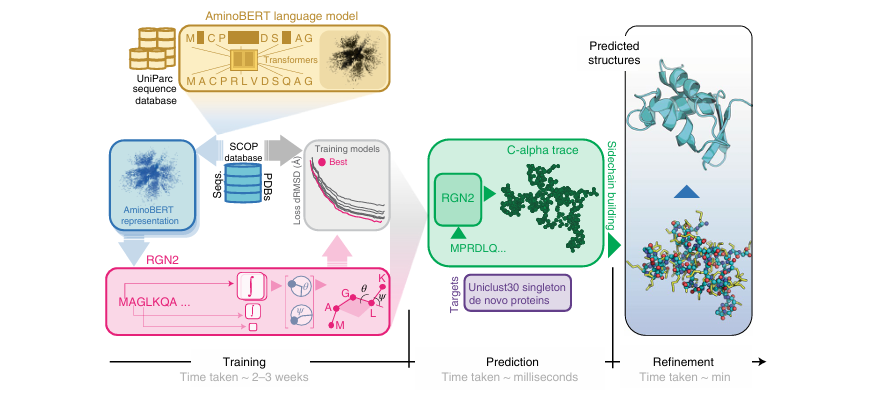
단일 아미노산 서열만을 기반으로 3차원 단백질 구조를 예측하는 새로운 모델 RGN2🧠 배경 및 필요성기존 구조 예측 모델들(예: AlphaFold2)은 고정밀 예측을 위해 MSA (Multiple Sequence Alignment) 기반 공진화 정보에 의존함. 하지만
17.[논문 리뷰] AF2χ Predicting protein side-chain rotamer distributions with AlphaFold2
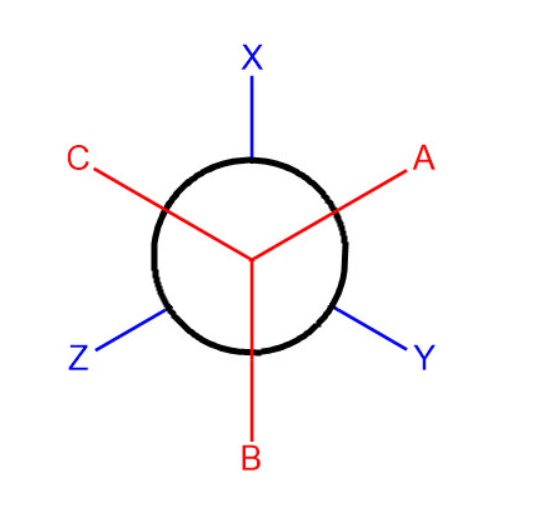
단백질 Sidechain의 유연성은 구성(conformation) 엔트로피의 핵심이며, 폴딩·안정성·분자 상호작용 같은 과정에 영향을 줌기존 실험·예측 도구(AlphaFold)는 용액에서의 Sidechain 이질성을 체계적으로 다루기 어려움특히, sidechain 배치
18.[논문 리뷰] De novo-designed pMHC bindersfacilitate T cell–mediatedcytotoxicity toward cancer cells
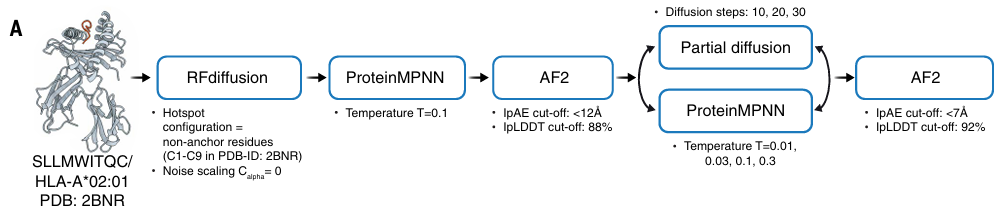
CD8⁺ T 세포의 기본 메커니즘감염/돌연변이로 생긴 세포 내부 단백질 조각(펩타이드)을 세포 표면의 MHC-I 복합체가 전시하고, TCR이 그 pMHC-I(펩타이드+MHC-I) 를 인식해 반응 MHC-I는 α1/α2/α3의 세 도메인과 β2-마이크로글로불린(β2m)으
19.[논문 리뷰] DUET: a server for predicting effects of mutations on protein stability using an integrated computational approach
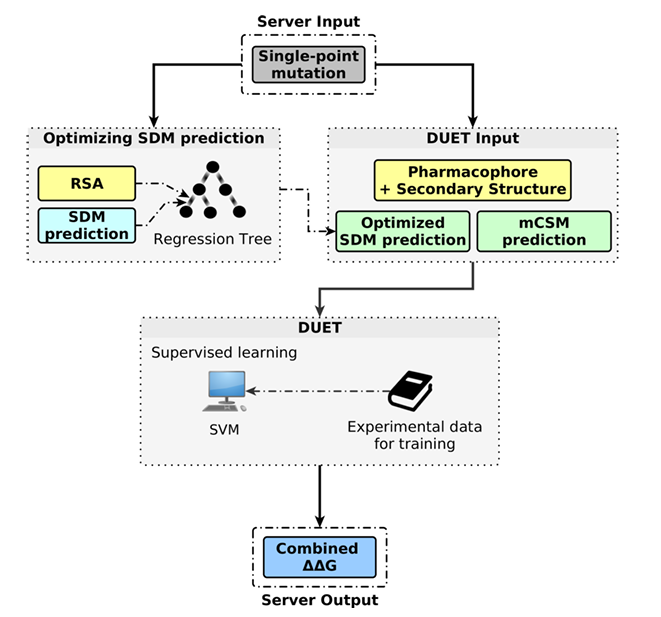
💡 INTRODUCTION✅ 무엇을 하는 서버인지DUET은 단일 아미노산 치환(미스센스 변이)이 단백질의 안정성(ΔΔG) 에 미치는 영향을 예측하는 웹 서버야. 서로 관점이 다른 두 방법—mCSM(구조 기반 그래프 서명)과 SDM(환경-특이적 치환표에 기반한 통계 퍼
20.[논문 리뷰] Protein folding stability estimation with explicit consideration of unfolded states
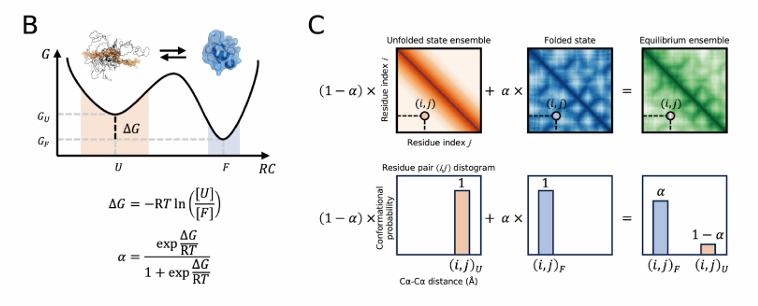
접힌 상태뿐 아니라 ‘풀린(unfolded) 상태’를 명시적으로 모델링해서 단백질의 절대 접힘 안정성(ΔG)을 예측하는 딥러닝 모델 IFUM을 제안ΔG와 접힘/풀림 상태의 평형 앙상블(distogram)을 공동 학습해서 정확도를 끌어올린 게 포인트기존 방법(구조예측 A
21.[논문 리뷰] ProSTAGE: Predicting Effects of Mutations on Protein Stability by Using Protein Embeddings and Graph Convolutional Networks
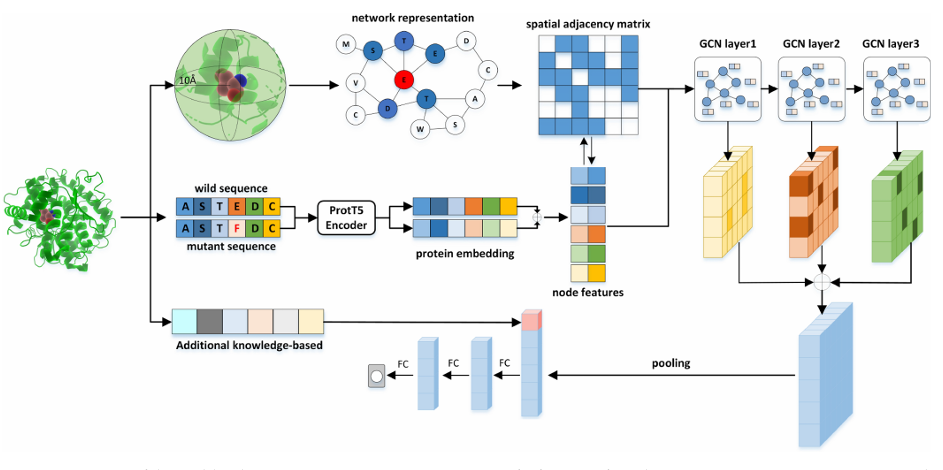
단백질의 단일 점돌연변이가 안정성(ΔΔG)에 미치는 영향을 더 빠르고 정확하게 예측하기 위해, 서열 언어모델 임베딩과 3D 그래프 기반 모델을 결합한 새 방법 ProSTAGE를 제안보편적으로 쓰이던 학습셋(S2648)의 거의 두 배 규모 데이터로 훈련했고, 여러 독립
22.[논문 리뷰] Optimization of a sarbecovirus llama nanobody–antigen binding interface via a combined computational and phage display protein engineering approach
나노바디(VHH)는 작아서 조직 침투가 좋고, 큰 단백질로 가려진 숨은 에피토프에도 잘 닿는 장점이 있음하지만 작은 크기 = 결합면(paratope)이 작다는 뜻이기도 함따라서, 인식할 수 있는 항원 스펙트럼이 좁고(넓은 ‘breadth’ 확보가 어려움), 특히 바이러
23.[논문 리뷰] NanoBinder: a machine learning assisted nanobody binding prediction tool using Rosetta energy scores
나노바디는 작고 안정적이지만, 나노바디 전용 설계 도구가 부족Rosetta: 강력하지만 False Negative 가 높아 대규모 실험 스크리닝이 필요해 비용·시간·노동이 증가NanoBinder: Rosetta에서 뽑은 에너지 점수를 Feature 로 쓰고, 랜덤 포레
24.[논문 리뷰] The Therapeutic Nanobody Profiler, characterising and predicting nanobody developability to improve therapeutic design
나노바디는 항체와 구조적 특징이 달라 기존 항체용 개발가능성(developability) 예측 도구를 그대로 쓰기 어려움저자들은 TAP(antibody용 지침)을 확장·개조해 나노바디 전용 지표 세트와 도구(TNP)를 만들고, 임상 단계 VHH 36개와 추가 108개에
25.[논문 리뷰] TITANiAN: Robust Prediction of T-cell Epitope Immunogenicity using Adversarial Domain Adaptation Network
주제와 중요성T-cell immunogenicity(펩타이드가 T-cell 반응을 유도하는 능력)는 단백질 치료제와 백신의 안전성과 효능을 좌우하는 핵심 요소현 상황의 한계딥러닝이 in silico 예측에 유망하지만, 면역원성 데이터가 포괄적으로 부족한 것이 큰 난제무
26.[논문 리뷰] Germline-aware deep learning models and benchmarks for predicting antibody VH–VL pairing
문제의식: VH–VL Pair는 항체의 다양성·안정성·항원 결합 특이성을 좌우함생산성 있는 VH–VL 조합을 실험으로 찾는 일은 노동집약적이고 비용이 큼제안: 새 벤치마크 데이터셋과 세 가지 음성 샘플링 전략① 임의(random) 페어링② V-gene 불일치(V-gen
27.[논문 리뷰] Revealing bias in antibody language models through systematic training data processing with OAS-explore
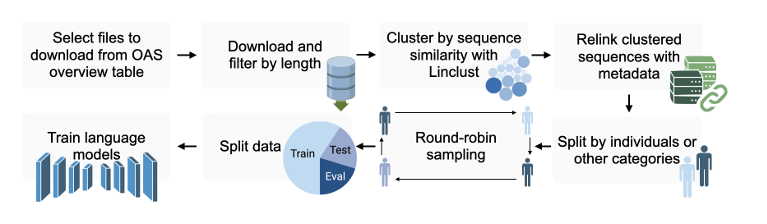
항체 언어 모델(Antibody LMs)의 활용면역 수용체(항체/항TCR 등) 서열로 학습한 언어모델은인간화(humanization), 항원 특이성 예측 등 다양한 면역학·치료제 설계 작업에 이미 활용되고 있음하지만 이런 모델들은 소수 공여자(donor)에 치우친 데이
28.[논문 리뷰] Property Enhancer – a data efficient multi-objective approach for functional antibody optimization
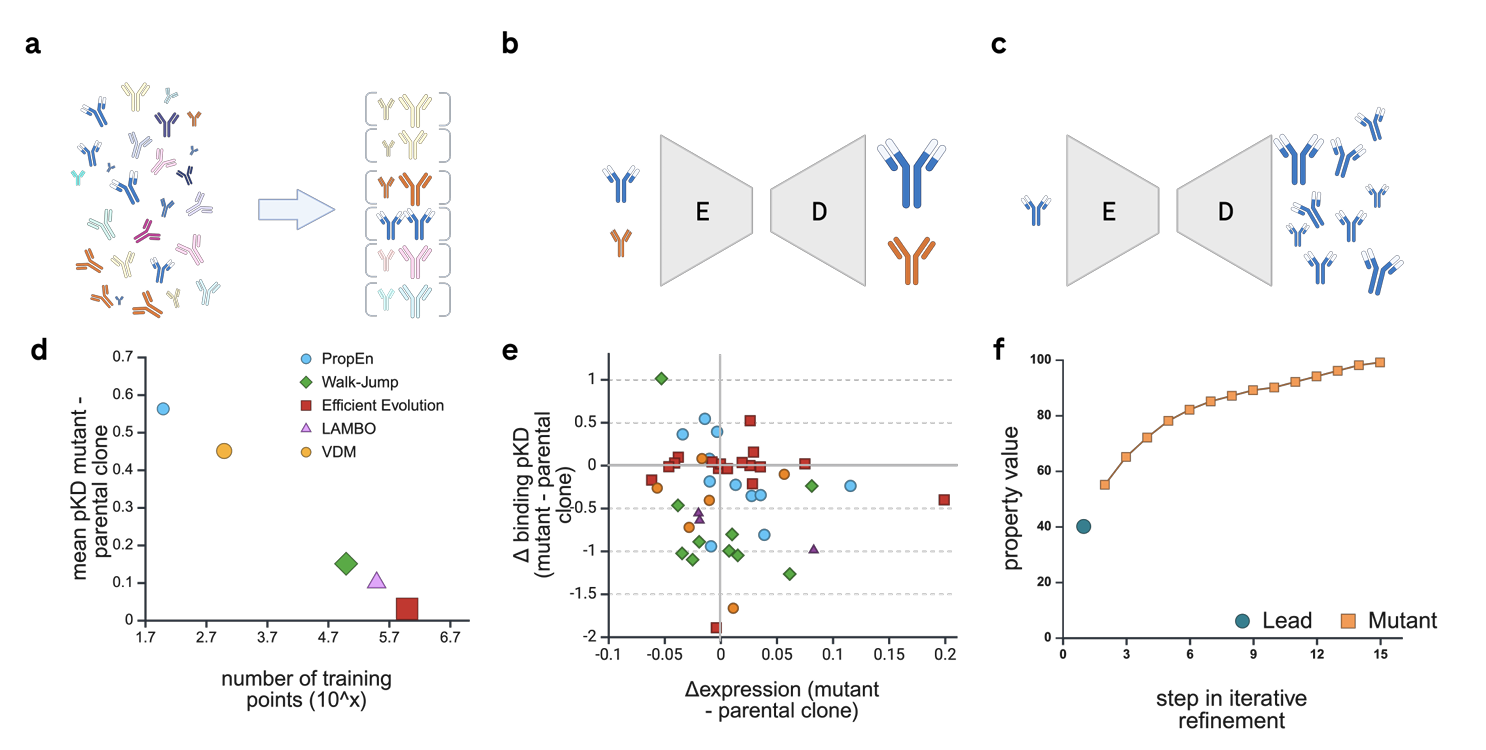
(1) 항체 lead 최적화의 어려움컴퓨터로 항체 후보(lead)를 설계·개선하는 과정고품질 데이터가 적음실험으로 정확히 측정된 항체 데이터가 많지 않음실험 검증이 비싸고 느림여러 개발 가능성(developability) 특성을 동시에 최적화해야 함예: 결합 친화도(a
29.[논문 리뷰] Rational design of antibodies with pH-dependent antigen-binding properties using structural insights from broadly neutralizing antibodies against α-neurotoxins
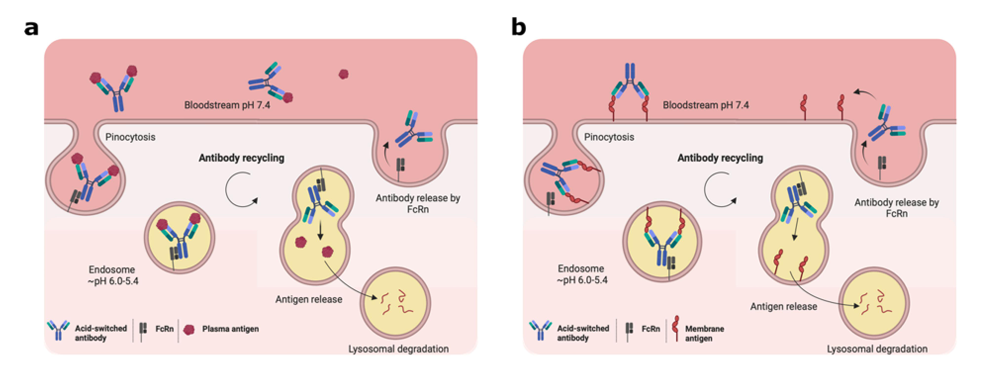
세포 밖·안의 pH는 세포 속 수많은 화학 반응에 꼭 필요함특히 항체가 재활용되는 과정(endosome 안에서 일어나는 FcRn 매개 재활용)에 pH가 큰 역할을 해서,요즘은 항체의 특이성과 기능을 조절하기 위해 pH를 이용하는 전략이 많이 연구됨항체 재활용 과정(1)
30.[논문 리뷰] Predicting the conformational flexibility of antibody and T cell receptor complementarity-determining regions
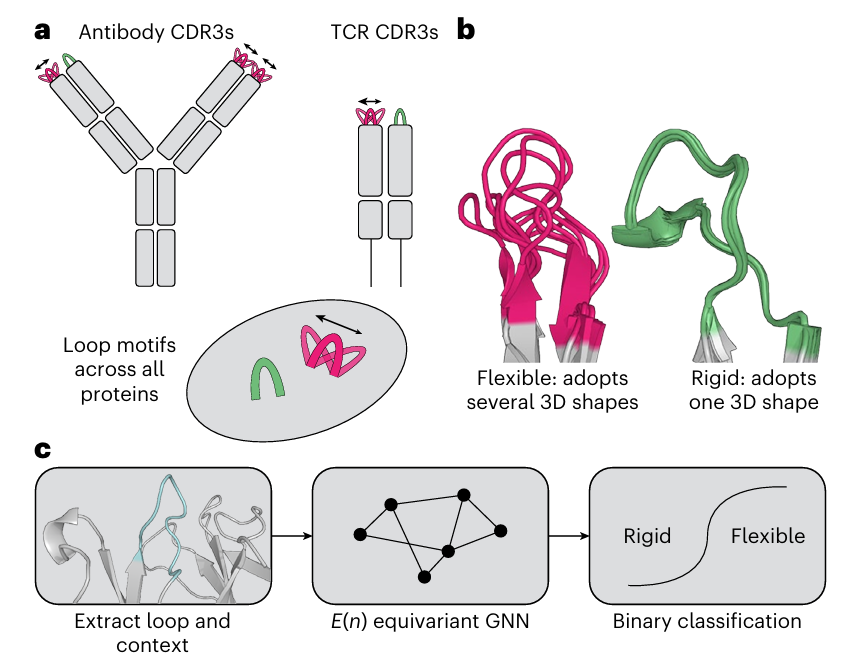
단백질은 보통 여러 안정한 구조(conformation) 사이를 오가며 기능을 하는데,항체/TCR의 CDR 루프 유연성은 결합 친화도·특이성에 큰 영향을 줌AlphaFold 같은 방법으로 정적인 단일 구조는 잘 맞추지만, 구조적 유연성을 믿을 만하게 예측하는 건 아직
31.[논문 리뷰] Rethinking what pLDDT really tells us about protein flexibility
pLDDT는 ‘내재적 유연성’이 아니라, 모델이 예측한 구조에 대한 국소적 불확실성/신뢰도(confidence) 지표에 가까움그래서 “pLDDT 낮음 → 유연/무질서일 가능성”은 어느 정도 말이 되지만, “pLDDT 높음 → rigid(안 움직임)”은 성립하지 않는다고
32.[논문 요약] Are frameworks independent from CDRs in antibodies? Exploring CDR - framework correlation networks of antibodies
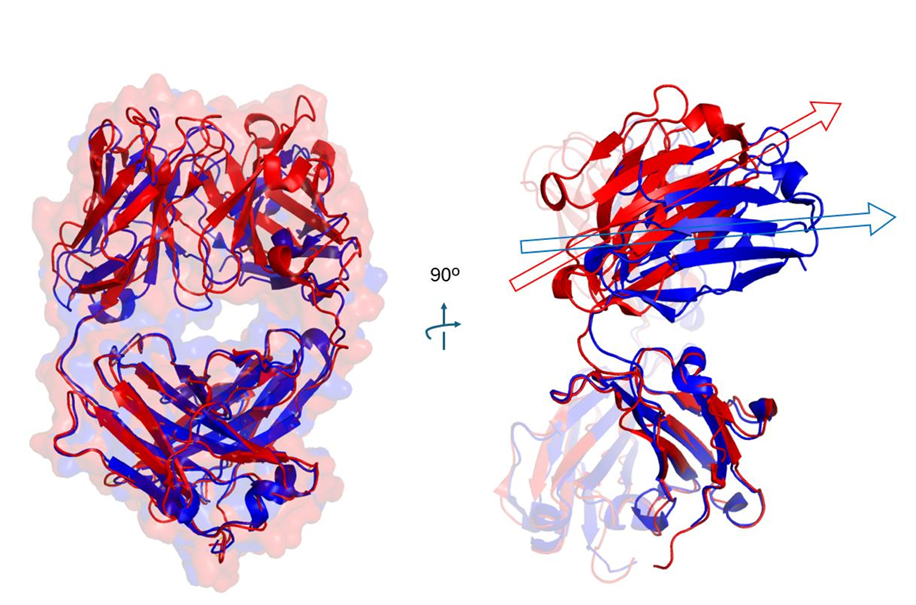
단일클론항체(mAb)가 치료제에서 크게 성공하면서, 항체 설계에서 humanization(인간화) 과정의 중요성이 커지고 있음인간화의 핵심은 비인간 항체의 CDR(항원결합부위 루프) 을 인간 framework(FW) 에 grafting 해서 면역원성(immunogeni
33.[논문 리뷰] Drug-like antibodies with low immunogenicity in human panels designed with Latent-X2
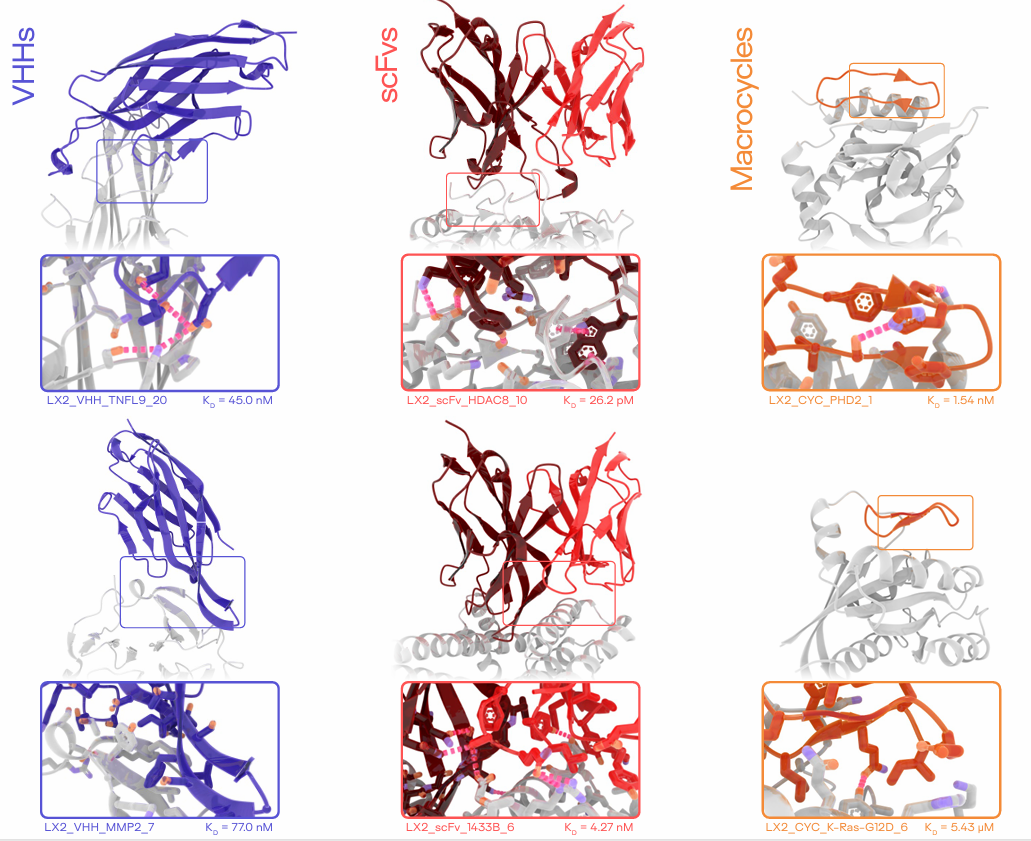
처음부터 developable(개발 가능) 하고 non-immunogenic(비면역원성) 인 약물 분자를 직접 설계하는 계산 시스템이 목표\-> Latent-X2로 달성했다고 주장 Latent-X2frontier generative model이며, zero-shot으로
34.[논문 리뷰] Biophysical properties of the clinical-stage antibody landscape
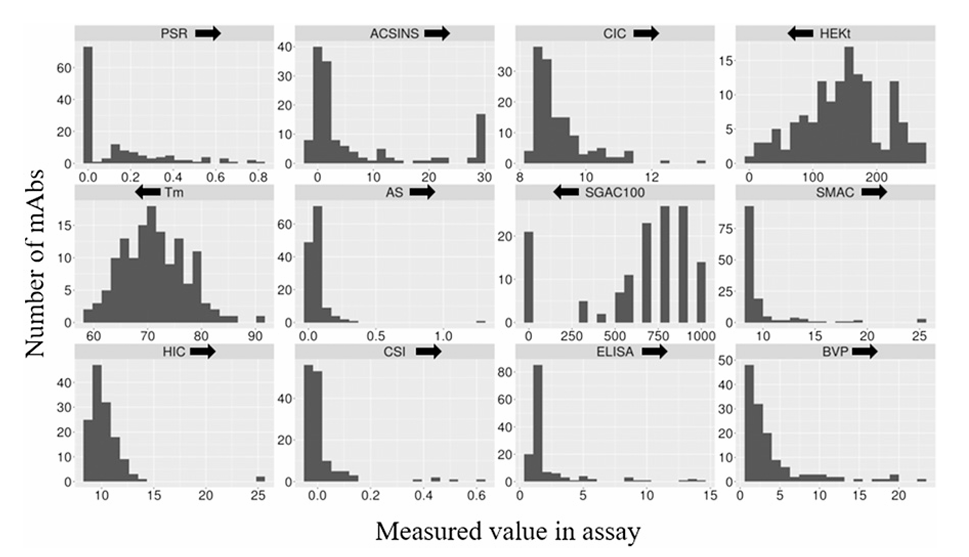
항체는 타깃 결합 외에도 제조 가능성, 저장 안정성, 오프타깃 stickiness(끈적임) 같은 developability 요건을 만족해야 하고, 이 논문은 phase 2/3 또는 승인된 항체들의 developability 지표 분포를 대규모로 제시하며, “경고(red
35.[논문 리뷰] Biophysical cartography of the native and human-engineered antibody landscapes quantifies the plasticity of antibody developability
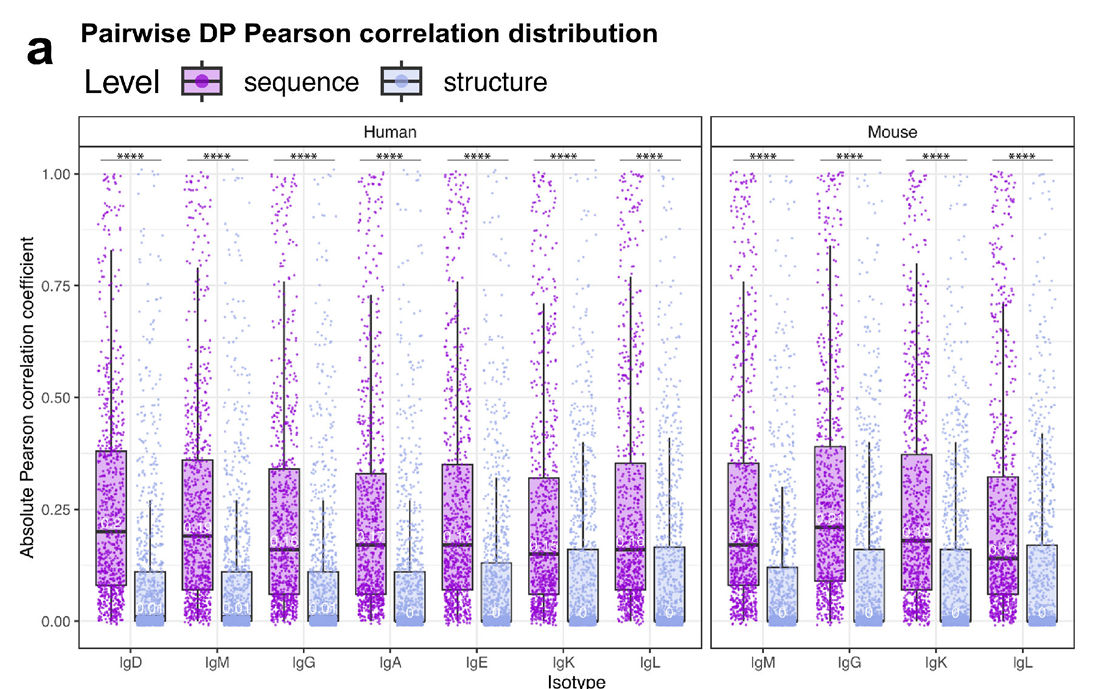
“developability”: 효과적인 단클론항체(mAb) 치료제 설계는 여러 파라미터를 동시에 맞춰야 하는 최적화 문제항체가 물리화학적 성질(physicochemical properties) 때문에 발견→개발 단계들을 끝까지 통과할 수 있는 능력을 의미자연 항체(n
36.[논문 리뷰] De novo design of epitope-specific antibodies via a structure-driven computational workflow
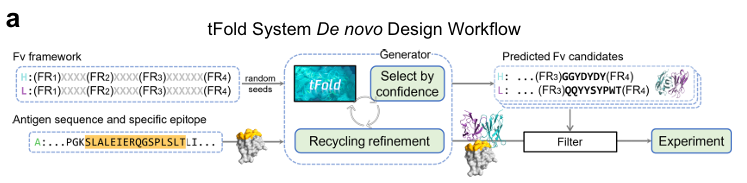
배경: 항체 시장/기존 개발 방식의 한계항체는 클론 B 세포(clonal B cells)가 만들어내며,인체 적응면역(adaptive immune system)에서 외부 물질/항원(antigen)을 특이적으로 인식하고 반응하는 핵심 분자임치료 단백질 중에서도 항체는 대표
37.[논문 리뷰] Advancing Protein Design via Multi-Agent Reinforcement Learning with Pareto-Based Collaborative Optimization
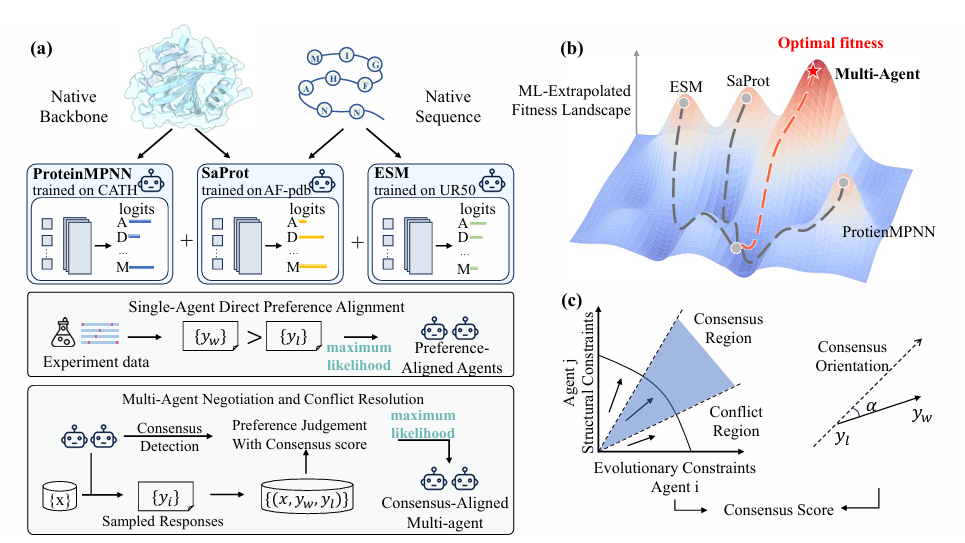
기존 방법들은 구조적으로 잘 접히는 단백질과 원하는 기능이 좋은 단백질을 동시에 만족시키는 데 어려움이 있음① 구조 기반 모델단백질이 안정적으로 접히는 구조(foldability) 를 잘 맞춤하지만 기능적 성질은 놓칠 수 있음② 단백질 언어모델(Protein Langu
38.[논문 리뷰] VibeGen: Agentic end-to-end de novo protein design for tailored dynamics using a language diffusion model
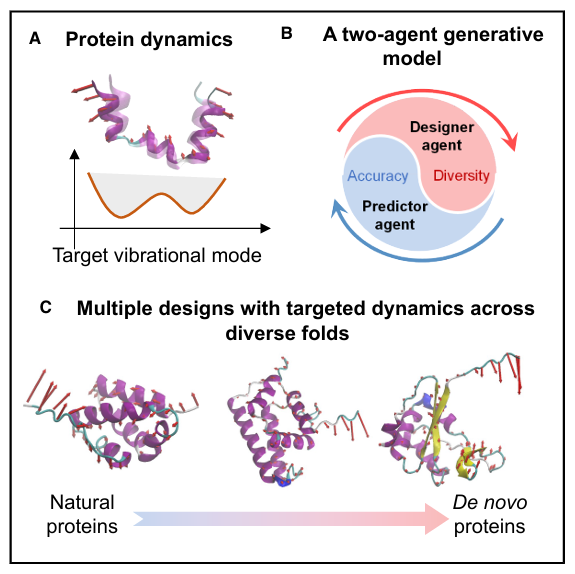
“원하는 단백질의 움직임(동역학)을 먼저 정해 놓고, 그 움직임을 만족하는 새로운 단백질 서열을 생성하는 AI 시스템”을 제안하는 논문A. Protein dynamics단백질의 움직임 자체를 목표로 삼는다는 점을 보여줌“Target vibrational mode”: 단