✅ Abstract
문제의식: VH–VL Pair는 항체의 다양성·안정성·항원 결합 특이성을 좌우함
생산성 있는 VH–VL 조합을 실험으로 찾는 일은 노동집약적이고 비용이 큼
제안: 새 벤치마크 데이터셋과 세 가지 음성 샘플링 전략① 임의(random) 페어링
② V-gene 불일치(V-gene mismatching)
③ 전체 V(D)J 생식계열 불일치(full V(D)J germline mismatching))
로 학습한 세 가지 딥러닝 모델을 포함하는 포괄적 프레임워크를 제시
데이터 구성: 자연 페어들을 포함하고, 위 세 종류의 합성 음성(미스매치) 페어를 추가해 점차 현실적인 생물학적 제약을 모사
모델 성능: 경량 BERT 기반 모델이 자연 페어 vs 합성 페어 구분에서 정확도 90% 이상 달성
핵심 결과: V(D)J 정보에 근거한 음성 샘플링이 일반화 성능과 생물학적 해석가능성을 유의하게 향상
의의: 재현 가능한 기준선(baseline)과 생물학적으로 정당화된 벤치마크를 제공해, 항체 공학용 효율적 계산 도구 개발의 토대를 마련
✅ Introduction
✅ (1) 항체 개요
B세포가 만드는 Y자 형태 단백질로, 적응면역의 핵심 효과기
항원 인식의 높은 특이성은 가변영역(variable regions) 덕분
✅ (2) 다양성의 분자적 근거—V(D)J 재조합
B세포 발달 중 V(가변)–D(다양성)–J(결합) 유전자가 재배열됨
말단탈옥산뉴클레오티딜전이효소(TdT) 등이 매개하는 접합부 삽입/삭제로 추가 다양성 생성
결과적으로 면역계는 매우 다양한 항원을 인식할 수 있는 레퍼토리를 갖춤
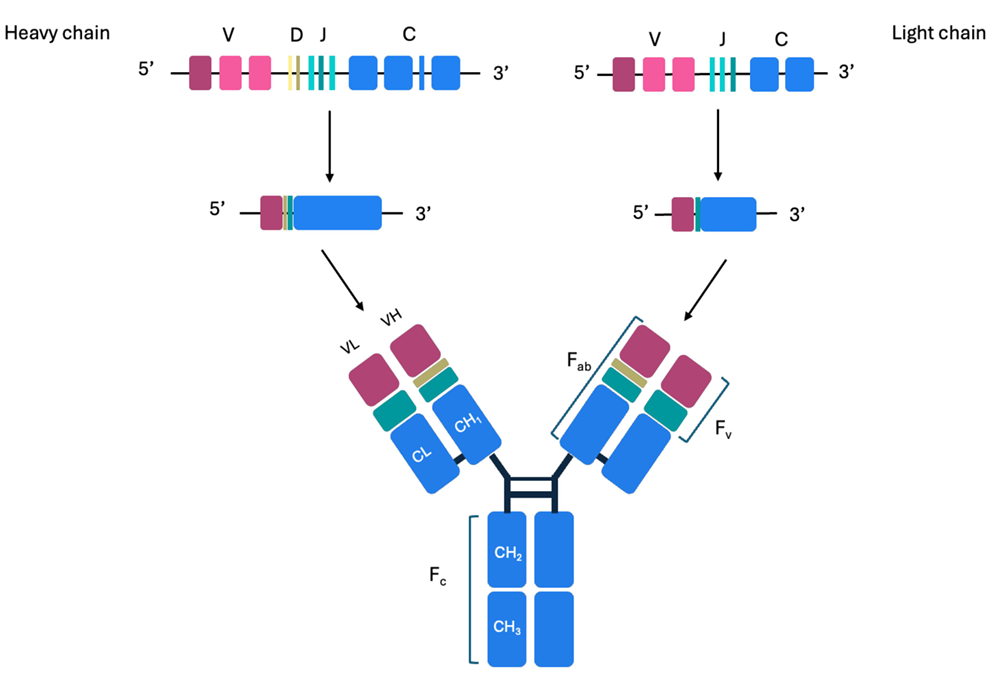
(figure 1.) V(D)J 재조합으로 Fv(VH·VL)가 형성되어 항원 특이성을 부여하며, 그 뒤의 C(상수) 구역은 Fc 뼈대를 암호화
✅ (3) VH–VL 페어링의 역할
기능적 항체는 VH–VL 비공유 결합으로 Fv를 이루며, 사슬 간 상호작용이 구조·기능을 규정(특이성·친화도·안정성에 영향)
자연 레퍼토리에서 흔한 조합이 있긴 하지만, 전통 견해는 “대체로 무작위 페어링으로도 기능적 항체 형성”이었음
그러나 최근 구조·계산 연구는 VH–VL 인터페이스 기하가 V·J 생식계열 선택의 영향을 받음을 보였고,
실험 데이터는 특정 V(D)J 조합이 생산적 조립에 필수이며 비자연(미스매치) 페어링은 구조적 적합성과 항원 결합을 저해할 수 있음을 보여줌
✅ (4) 실험적·계산적 접근
공학적으로 페어링 다양성을 활용하기 위해 VL-shuffling(같은 VH에 다양한 VL 재조합) 같은 전략이 쓰이나, 복제·발현·스크리닝이 많이 들어 비용·시간 부담 큼
계산적 예측은 유망하지만, 확인된 “비-페어링” VH/VL 데이터셋의 공공 부재로 학습·평가가 어려움
✅ (5) 딥러닝 진전과 항체 전용 LMs
단백질 분야의 DL과 트랜스포머 기반 언어모델의 성공
일부는 페어드 데이터로 학습/미세조정:
BALM-paired는 천연 페어만으로 학습
IgBERT/IgT5는 비페어로 사전학습 후 OAS 페어로 파인튜닝
이들 모델은 서열 복원, 구조 예측, 발현 수준 추정 등에서 성과를 냈지만, VH–VL 페어링 자체를 예측 과제로 다룬 사례는 소수
PARA: 유사도 기반 셔플로 만든 미스매치를 네이티브와 대비해 분류(AUC-ROC 높음)
p-IgGen: 페어 생성 모델로 설계됐지만, 네이티브 페어에 더 높은 가능도를 주어 페어링 신호 포착을 시사
✅ (6) 트랜스포머 바깥의 대안들
HuMatch: V-germline 라벨이 붙은 인간 항체 서열로 CNN 학습(주 과제는 인간화지만 페어링 분류 컴포넌트 포함)
ImmunoMatch: AntiBERTa2를 단일 B세포 유래 VH–VL 페어로 파인튜닝, 자연 페어 vs 무작위 미스매치를 구분
SynPair: 대조학습 기반, 문제를 밀집 검색(dense-retrieval)으로 정식화하여 ImmunoMatch를 상회하는 SOTA 페어링 예측
✅ (7) 표준 부재와 음성(negative) 정의의 중요성
현재 표준화된 데이터셋/평가 프레임워크 부재, 임시방편 미스매칭 전략과 엄밀 비교 부족
→ 연구 간 결과 해석이 어려움
최근 연구는 데이터셋 구성, 특히 음성 정의가 모델이 무엇을 학습하고 얼마나 일반화하는지를 좌우함을 보여줌
항체-항원 결합 맥락의 Ursu 등은 음성 샘플 선택이 단지 정확도뿐 아니라 생물학적 규칙 복원 가능성까지 결정한다고 지적
⇒ VH–VL 페어링 예측에서도 편향을 줄이고 해석가능성을 높이는 음성 설계가 핵심
✅ (8) 이 논문의 해결책—벤치마크·모델·평가 설계
전용 벤치마크 데이터셋 제시: 과제를 이진 분류로 두고, 세 가지 생물학적으로 동기화된 음성 샘플링을 구성
(① 임의 재조합, ② V-gene 미스매치, ③ 전체 V(D)J 미스매치)
→ 생물학적 제약을 더 잘 반영하는 구조화·해석가능 음성 집합을 만듦
세 모델을 베이스라인으로 제시
구조는 IgBERT 임베딩 + MLP 분류기의 단순하지만 효과적인 조합
테스트 분할도 세 가지로 표준화: ① random, ② v-gene, ③ germlines 분할
→ 통제된 조건에서 공정 비교 가능
✅ (9) 핵심 기여
벤치마크 데이터셋: 자연 페어 양성과, 세 전략으로 만든 음성을 포함
새 미스매치 생성 코드도 제공
참조 모델: 세 음성 전략별 IgBERT-기반 분류기를 학습·평가해 표준 기준선으로 제시
모델 개발 성과: 자연 vs 합성 페어 구분 정확도 >90%
또한 AlphaFold3의 ipTM(사슬 인터페이스 지표)을 이 작업에 시험해 보았는데, 전용 방법의 필요성을 시사
생물학적 통찰: 생식계열 정체성(germline identity)이 성능에 영향
특히 전체 V(D)J 기반 미스매치가 가장 생물학적으로 판별력 높은 피처를 제공
개발가능성(Developability) 연관성: 다양한 페어링 모델을 개발성 지표와 비교했고, 실험적 열안정성과 초기적 상관을 관찰
→ 초기 항체 최적화·개발성 평가 단계에서 잠재적 활용성이 있음을 시사
✅ Result
✅ 대규모 페어드 데이터셋 구축 + 음성(미스매치) 샘플링
출발점: OAS(Observed Antibody Space)에서 1,954,079개 VH/VL 페어를 수집
VJ(경쇄), VDJ(중쇄) Germline 주석·전처리·클러스터링 후 1,357,155개 고품질 네이티브 페어를 남김(중쇄 1,348,625개, 경쇄 595,539개 유니크 시퀀스)
총 11,976개 Germline 조합 확인
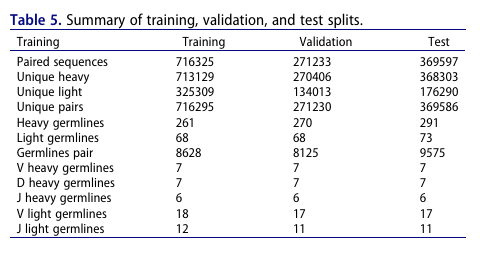
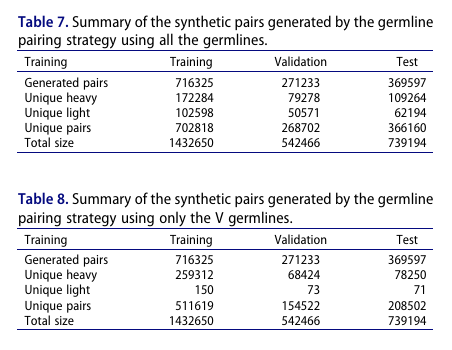
평가의 현실성을 높이기 위해 Germline 기원에 따라 데이터 분할: 학습 716,325 / 검증 271,233 / 테스트 369,597 페어
음성(미스매치) 생성 전략(양성과 수를 맞춰 클래스 균형 유지):
(1) Randomly paired: VH와 VL을 무작위 셔플(자연 페어와 동일 조합이 나오지 않도록 보장)
(2) Germline-paired: 관찰 데이터로부터 통계적으로 드물거나 관측되지 않은 Germline 조합을 선택해, 해당 조합의 Germline 풀에서 VH와 VL을 각기 독립 샘플링
가용 시퀀스 수의 곱에 비례하는 확률분포를 두고, 고빈도 치우침을 완화하는 스무딩 파라미터를 적용
이 절차를 두 가지 인코딩으로 수행:
(1) V-germline(예: H: VH1, L: KV1),
(2) Full germline(예: H: VH1-VD2-VJ3, L: KV1-KJ2)
음성 샘플 수는 항상 양성과 동일하게 맞춤
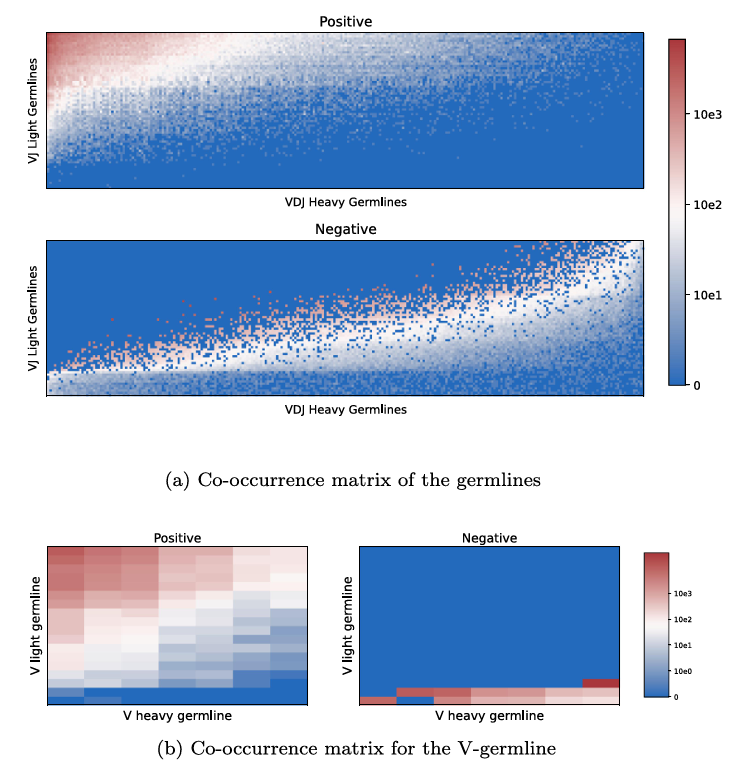
(Figure 2.) 훈련 분할에서의 (VDJ 중쇄 × VJ 경쇄) Germline 공존(co-occurrence) 분포(양성)와, 각 설정에서 관측되지 않은 조합에 대해 생성한 음성 페어 수(음성)를 보여줌
✅ 잠재 공간 시각화 — germline 기반 음성에서 클래스 분리
모델 특징 추출기: IgBERT 인코더 + 분류 헤드
각 데이터셋(무작위, germline, V-only germline)에서 양·음성 합쳐 4,096개를 샘플
IgBERT가 1024차원 페어 임베딩을 만들고, 이를 t-SNE와 UMAP으로 2D 투영
관찰:
무작위 음성은 네이티브와 강하게 중첩되어 분리가 어려움
저먼라인 기반 두 설정에서는 양·음성이 뚜렷한 클러스터를 형성하고, 특히 V-only가 가장 잘 분리됨(UMAP에서 거의 완전 분리)
반면 full germline과 random은 여전히 상당한 중첩이 남아 가장 난해한 설정으로 남음
✅ 서열 유사도 분석—합성 페어의 이질성 정량화
분석 대상 4셋: naive(자연 페어), random, germline(full), germline-V(V-only)
동일한 1,000개 중쇄가 모든 셋에 등장하도록 뽑고, 각 페어의 VH+VL을 이어붙인 문자열로 비교
정의:
Intra-similarity(동일 셋 내 모든 페어 쌍): 정규화 레벤슈타인 유사도
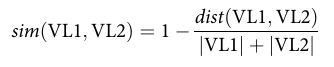
Inter-similarity(각 음성 페어 ↔ 같은 VH를 공유하는 naive 페어): 식(1)로 계산
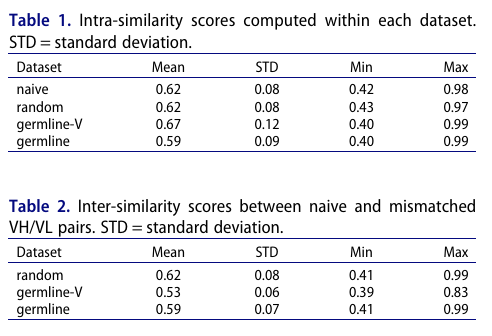
표 1: Intra-similarity(셋 내) — 평균/표준편차/최소/최대
germline-V: 0.67 / 0.12 / 0.40 / 0.99
(가장 높음 → 이 설정이 셋 내부적으로 더 동질적)
germline(full): 0.59 / 0.09 / 0.40 / 0.99 (가장 낮음)
표 2: Inter-similarity(음성 ↔ 해당 naive) — 평균/표준편차/최소/최대
germline-V: 0.53 / 0.06 / 0.39 / 0.83
(가장 낮음 → naive와 가장 멀다, 즉 가장 큰 발산)
germline(full): 0.59 / 0.07 / 0.41 / 0.99
요지: V-only germline 음성은 (1) 셋 내부 유사도는 가장 높고, (2) 대응하는 naive와의 유사도는 가장 낮아(=가장 이질적) 분류 신호가 가장 강함
✅ “무작위 미스매치”의 germline 중복이 분리 한계를 만든다
무작위 셔플로 만든 음성 페어의 VDJ/VJ germline 조합이, naive에서 전혀 관측되지 않았던 완전히 새로운 조합일 확률은?
방법: 무작위 음성(훈련)에서 10,000 페어 샘플
→ 각 VH/VL의 VDJ/VJ를 추출
→ naive 훈련셋에서 등장한 모든 VDJ×VJ 조합 목록과 비교(각 조합의 naive 유래 시퀀스 수도 집계)
결과: 무작위 음성 표본에서 완전히 새로운 germline 조합은 0.3%에 불과
즉, 대부분이 이미 naive 훈련셋에 존재하던 조합

이 때문에 잠재공간에서 무작위 음성과 naive가 겹쳐 분리하기 어려움(그림 3a)
반면 germline 정보를 이용해 의도적으로 분포를 분리한 다른 음성 전략(저먼라인·V-only)은 더 뚜렷한 구분을 만듦
결론적으로 germline 정체성은 VH/VL 페어 호환성을 좌우하는 핵심 단서이며, 효과적인 음성 설계에도 결정적
한 줄 요약
연구팀은 진짜로 맞는 VH–VL 짝(약 135만 쌍)을 모으고, 일부러 틀린 짝을 세 방식으로 만들어서 모델을 가르침
그냥 무작위로 섞은 틀린 짝은 진짜와 너무 겹쳐서 구분이 잘 안 됐고,
germline 정보(V, 혹은 VDJ 전체)를 일부러 안 맞게 만든 틀린 짝은 진짜와 확실히 달라져서 모델이 더 잘 배웠음
특히 V-gene만 안 맞춘 방식(“germline-V”)이 “틀린 예시”로 가장 알맞았음
✅ Model evaluation (다양한 음성 샘플링 전략)
아키텍처: IgBERT 인코더 + MLP 분류기
음성 샘플링 3종(random, germline, germline-V)으로 각각 학습하고,
데이터 분할 3종(random, v-gene, germlines)에서 Accuracy, F1, AUC-ROC로 평가
(추가 지표: Precision/Recall/MCC/AUC-PR은 보충표)
VDJ germline 모델: 전반적으로 가장 안정적
v-gene germlines 분할에서 Accuracy/F1/AUC 모두 0.9 초과로 높음(랜덤 분할에선 미스매치 쌍에 “새로운 VDJ/VJ 조합”이 거의 없어 효과 ↓)
V germline 모델: v-gene 분할에서 F1=0.98, AUC-ROC=1.0로 거의 완벽
다만 random·germlines 분할에선 성능 하락
→ 부분적 germline 정보만 쓸 때 일반화가 약해짐
Random 모델: 전반적으로 가장 약함
그래도 VDJ/V germline 데이터셋에서는 random 분할보다 나아짐(두 문제의 분리 가능성 차이 때문)
결론: germline-aware 분할/학습이 더 생물학적으로 타당하고 일반화 가능한 예측을 만듦
germline-agnostic 벤치마크에선 데이터 누출 위험과 성능 과대평가가 생길 수 있음
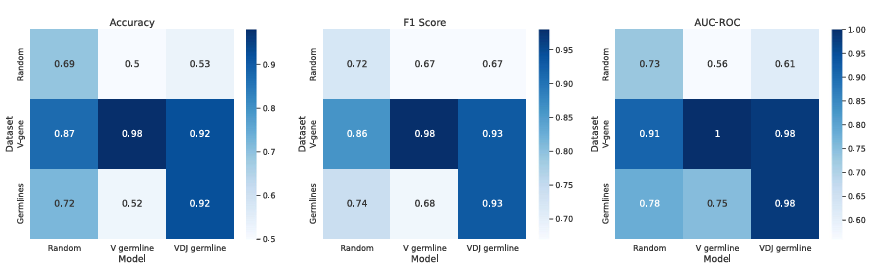
(Figure 4.) 각 모델×분할 조합의 점수를 색으로 표시(진하기=상대 성능)
요점: “틀린 예시”도 germline 정보를 써서 설계해야, 진짜와 확실히 달라지고 모델이 일반화해서 잘 맞춘다.
VDJ 전부를 고려해 학습한 모델이 시험이 달라져도 제일 안정적이긴 함
germline-V로 학습한 모델은 v-gene 시험에서 거의 완벽하지만, 다른 시험에선 살짝 약해짐(부분 정보에 치우쳐 배운 탓)
✅ VDJ influence on the final output
목적: VDJ 모델의 출력이 무거운 사슬 D-gene에 얼마나 좌우되는지 점검
자연 페어 전체로 (HD, VJ) 그리드 구성 후,
(i) 쌍 개수, (ii) 평균 예측확률을 계산
상단 패널=개수 min-max 정규화, 중간=원 스케일 확률, 하단=각 VJ 열 내부에서 0–1 정규화(D의 상대적 영향 강조)
관찰: D-gene은 접합 다양성 영향으로 주석 신뢰도가 낮음
예상대로 V–J 효과(세로 줄무늬)가 지배적이고, D-gene의 미세한 문맥 의존 효과도 보이지만 모델이 과민해지지 않음(강건)
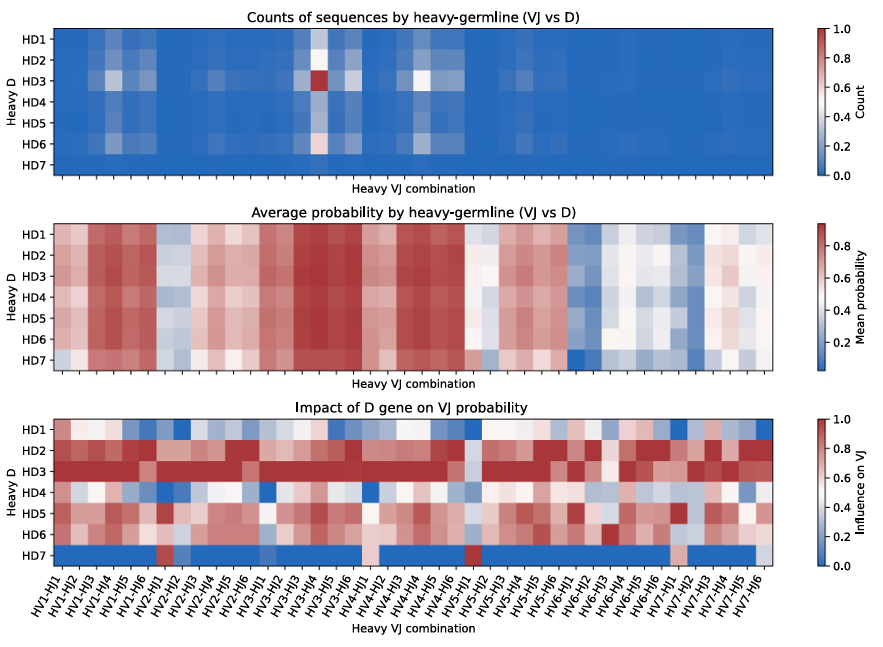
요약: D-gene이 결과를 좌우하나?
실제론 V와 J의 영향이 더 큼(세로 줄무늬처럼 보임). D는 문맥에 따라 살짝 영향을 주지만 주인공은 아님.
→ 모델이 한 부분(D)만 보고 치팅하는 건 아니고, 균형 있게 배우고 있음.
✅ Benchmark framework & SOTA 비교
공정한 비교를 위해 3개 분할(random, v-gene, germlines)과 두 기준선을 정의: Topline(가능한 최상 성능), Bottomline(최저선)
Topline에 근접/도달한 접근은 사용 가능한 신호를 최적으로 쓴 것, Bottomline 이하는 비효율로 간주
이 프레임으로 p-IgGen, Humatch, ImmunoMatch를 평가(SynPair는 코드 미공개로 제외)
결과 요약:
p-IgGen: random 분할에서 준수(F1은 Humatch에 근접)하지만 v-gene·germlines에선 AUC-ROC/Accuracy가 하락
Humatch/ImmunoMatch: 분할 전반에 안정적이며 특히 v-gene에서 AUC-ROC 강함
그러나 F1·Accuracy는 Topline에 못 미침(이진 분류 보정(calibration) 한계 시사)
Topline은 모든 지표·분할에서 지속적 우위(개선 여지 큼)
Bottomline도 v-gene에선 의외의 경쟁력(그 분할의 신호가 단순할 수 있음을 시사)
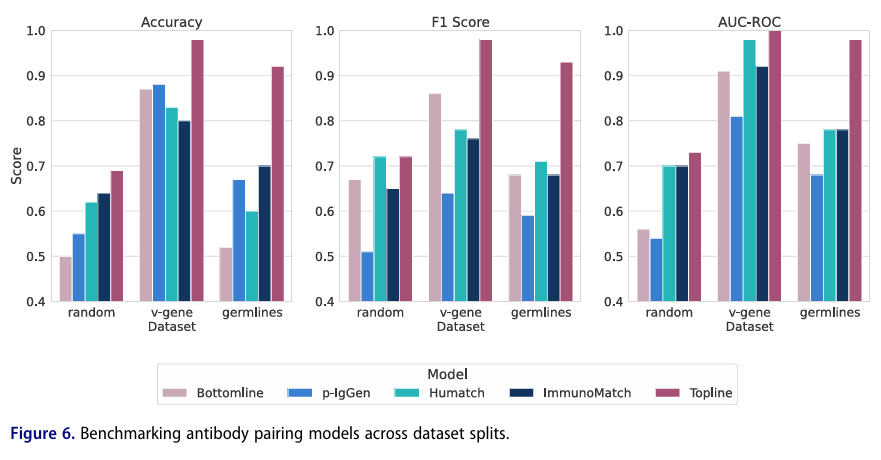
요약
Topline: “이 데이터에서 낼 수 있는 거의 최상” 느낌
Bottomline: “최저선”
p-IgGen: 쉬운 test(random)에서는 괜찮지만, v-gene·germlines처럼 까다로운 시험에선 성능이 떨어짐
HuMatch / ImmunoMatch: 전반적으로 안정적이지만, 최고선(Topline)에는 못 미침
Bottomline이 v-gene 시험에서 의외로 선전
→ test 시 비교적 단순한 신호만으로도 어느 정도 풀린다는 힌트
요점: 논문의 germline-aware 방식이 공정한 조건에서도 경쟁력 있고, 아직 개선 여지(Topline과 차이)가 뚜렷함
✅ PARA task 비교
배경: 외부 표준이 부재해 직접 비교가 어렵기 때문에, PARA 프레임(쌍 랭킹 문제)에서 참조형 평가를 추가
테스트 삼중항 (VH, VL1, VL2)을 만들고, 모델이 진짜 짝 VH–VL1의 점수를 미스매치 VH–VL2보다 높게 매기면 성공
(PARA의 원데이터/가중치는 비공개이므로 간접적 비교임.)
결과: VDJ germline 모델의 AUC-ROC가 PARA 논문의 참조값 0.82에 근접
→ 외부 벤치마크에서도 경쟁력 확인
Random 모델은 Accuracy·F1이 좋아 보이는데, 이는 PARA의 음성 생성이 random 미스매치에 더 가깝기 때문일 수 있음
ImmunoMatch가 강한 것도, random 미스매치로 학습된 모델이기 때문이라는 해석과 부합
PARA는 최종적 기준은 아니지만, 전반 결과는 germline-aware 학습의 가치를 뒷받침
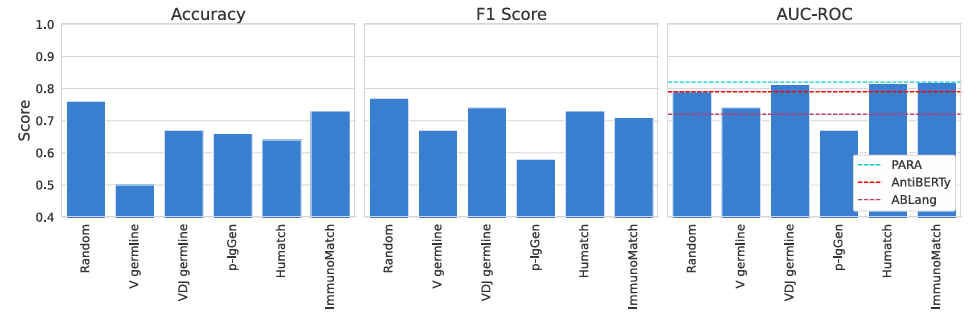
요약
PARA: “두 개의 후보 VL 중 누가 진짜 짝인지 고르기"
논문 germline(VDJ) 모델이 참고 기준치에 거의 근접
→ 외부 과제에서도 경쟁력
반면 random 기반 모델들이 PARA에서 상대적으로 괜찮아 보이는 건, PARA의 틀린 예시가 무작위 섞기와 더 비슷해서 그럼
→ 결론은 같다: germline을 고려해 학습해야 여러 상황에서도 잘 맞춘다
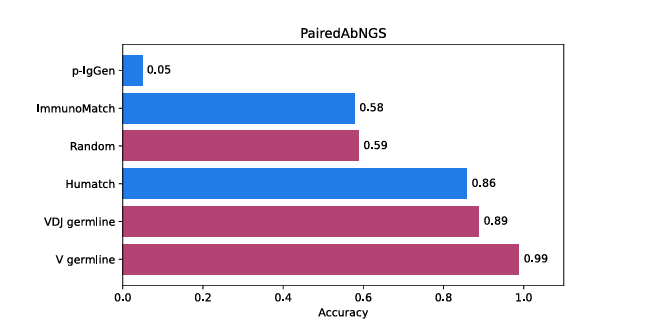
✅ PairedAbNGS(7.2M 쌍) 외부 벤치마크 결과
외부 대형 데이터셋 PairedAbNGS(약 1,440만 productive 사슬, 7.2M 페어, 3.7M 유니크 페어)로 모델들을 추가 평가
학습/검증/시험 셋과 겹치는 서열은 제거해서 공정 비교를 보장
결과: germline 기반 모델(VDJ, V)이 가장 높은 정확도를 꾸준히 보였고, 그다음이 HuMatch
→ germline 정보가 페어링 호환성 판단의 핵심 단서라는 점을 외부 데이터에서도 확인
참고: PairedAbNGS는 모두 “진짜 페어(양성)”만 포함하므로, 이 평가에선 정확도(Accuracy)만 비교했어(실험적으로 검증된 “음성”이 없어 PR/AUC 같은 음성-양성 구분 평가는 불가)
✅ AlphaFold3 ipTM으로는 “맞는/틀린 페어”를 가르기 어렵다
가설: ipTM(인터페이스 품질 지표)이 맞는 VH–VL과 틀린 VH–VL을 구분할 수 있을까?
실험: 180개 항체에 대해 원래 페어, random 합성 페어, germline 합성 페어에서 ipTM을 비교
평균 ipTM은 원래 0.89±0.02, random 0.90±0.01, germline 0.89±0.03으로 유의차가 없었음
(Mann–Whitney U)
해석: (1) AlphaFold3 학습에 쓰인 PDB 항체는 엔지니어드/친화도 성숙 쪽이 많아 일반 항체 분포를 온전히 대표하지 못하고, (2) germline 페어링 편향은 전사/유전체 수준 요인과 연관돼 단순 인터페이스 품질 지표로는 포착이 어려움
→ 페어링 전용 모델이 필요
✅ “개발성(developability)”과의 상관
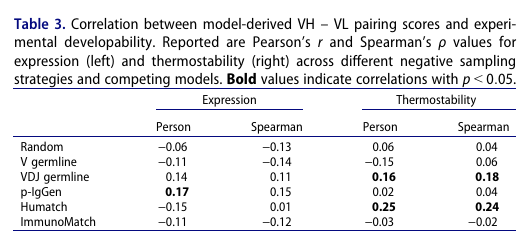
목적: 페어링 점수가 개발성 지표(발현량·열안정성)와 초기 신호라도 갖는지 확인
Jain et al.의 137개 항체 데이터(HEK 발현, Fab 용융온도)로, 모델 점수 vs 실험값의 Pearson/Spearman 상관을 계산
(각 모델과 random/V germline/VDJ germline 세팅 포함)
결과 요약(효과는 전반적으로 작다는 점이 핵심):
발현량: p-IgGen이 가장 뚜렷한 경향(예: r≈0.17, ρ≈0.15)
열안정성: HuMatch가 가장 큰 상관(예: r≈0.25, ρ≈0.24)
VDJ germline 모델도 유의한 양의 상관(예: r≈0.16, ρ≈0.18)으로 초기 신호를 보임
다만 효과 크기는 작아 예비적 결론으로 봐야 함(표본 137개)
결론: 현재 모델들의 페어링 점수만으로 개발성 예측을 크게 끌어올리긴 부족하지만, VDJ germline 모델에서 열안정성 신호가 보인 건 고무적
더 큰 데이터로 확증이 필요
✅ 쓸만한 Result 요약
-
어떻게 negative 데이터를 잘 만들 것이냐
-
germline-V 기준으로 자연 pair 와 다르게 만든 것이 가장 negative 데이터를 잘 만들었다
-
D-gene 영향은 거의 없다
✅ Discussion and conclusion
문제: VH–VL 짝맞춤 예측은 여전히 미개척 분야이고, 현실적인 negative 데이터가 부족해서 과거 연구들이 즉흥적/비현실적 미스매치를 써 왔고, 그게 일반화·해석가능성을 해쳐왔음
핵심 해법: 자연 페어 대규모 데이터로 재현 가능한 벤치마크를 만들고, negative 샘플링 3종(random, germline-V, germline-VDJ)을 표준화
평가 결과 germline-VDJ 미스매치가 가장 정보력이 큰 negative
모델·비교: 세 가지 IgBERT 기반 기준선 모델을 제공했고, PARA·p-IgGen·ImmunoMatch와 공정 비교
데이터 분할과 과제 난도에 따라 성능이 크게 변하므로, germline-aware 평가가 필수
germline 기반 모델은 대형 외부 PairedAbNGS(∼7M 쌍)에서도 강함
파급효과: 현실적인 “비-페어” 예시를 만들 수 있으니, 생성 모델에서 생물학적으로 말이 안 되는 조합을 벌점 주는 손실 설계에 활용 가능
✅ Materials and Methods
✅ Dataset(데이터)
OAS에서 195만 쌍을 모아 잘린 서열 제거 후, germline(V/D/J 표기: IMGT)로 주석
완전 주석된 1,622,802 쌍(유니크 페어 1,622,674, 유니크 heavy 1,604,717, 유니크 light 699,889)을 유지
Heavy VDJ 조합 294, Light VJ 조합 76이 관찰됨(가능 조합 22,344 중 관찰된 페어 12,416)
중복 줄이려고 Linclust(≥80% ID)로 클러스터링 → 대표서열만 남겨 1,357,155 쌍, 유니크 heavy 1,348,625, 유니크 light 595,539, 관찰된 germline 조합 11,976으로 요약
전체 자연계 조합해도 12,000 개 정도
✅ Germline-aware split(분할)
학습/검증/시험을 germline 기준으로 분리(무작위 아님)
-> 분할을 germline 기준으로 나눠서 현실적인 일반화를 시험하도록 설계
목적: 학습에 없던 germline 조합이 시험에 나와도 진짜/가짜 페어를 구분하게 하려는 것
이 방식은 비인간종(예: 마우스)로 확장할 때도 유리
아이디어: 데이터 D에서 heavy-germline 집합 𝐺𝐻, light-germline 집합 𝐺𝐿을 잡고,
시험셋 𝐷2에는 𝐺𝐻,𝐷2와 𝐺𝐿,𝐷2가 학습셋
𝐷1의 것과 겹치지 않게 만듦
(즉, 새 germline 조합 포함)
구현(Algorithm 1): 일부 heavy 조합 𝑇1을 뽑아 그에 해당하는 페어들을 시험셋에 먼저 넣고, light도 같은 방식으로 채운 뒤 남은 것으로 학습셋을 구성
✅ Negative dataset 준비(가짜 페어 만들기)
Germline pairing(핵심 방법)
무작위로만 음성을 만들지 않고, 관찰된 적 없는 germline 조합으로 체계적 음성을 만듦
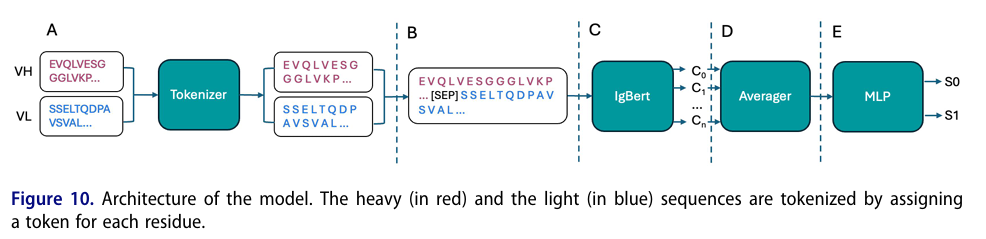
✅ 아키텍처
IgBERT 인코더 + 작은 MLP 헤드 구조
VH·VL를 잔기 단위로 토크나이즈하고 [SEP]으로 경계를 표시해 하나의 시퀀스로 연결
→ IgBERT(고정)를 통과해 잔기별 1024차 임베딩을 얻고, 평균 풀링으로 페어 하나의 벡터로 만들고 2층 MLP가 “진짜 페어 vs 합성 페어” 확률을 출력
학습 중엔 분류 헤드만 최적화(Adam + CE loss)
왜 IgBERT?
표현력이 PARA(45M)보다 깊고 큼(≈400M)
이번 연구의 초점이 모델 크기가 아니라 negative 샘플링 전략의 효과이므로, 인코더는 강하게 고정하고 데이터 설계의 영향을 보려 함
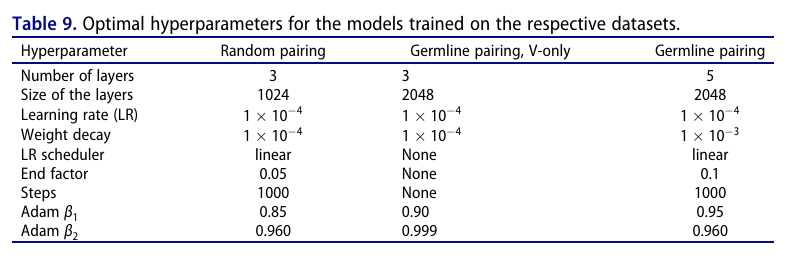
✅ 하이퍼파라미터
✅ 트레이닝
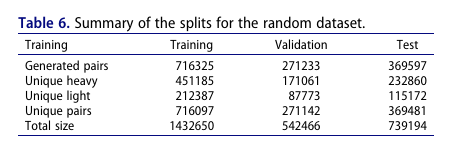
1 epoch 학습
학습 1,432,650 샘플, 검증 739,194, 총 44,771 업데이트, batch 32
환경: A100
삼중항( VH, VL1, VL2 )를 만든다:
VL1은 VH의 진짜 짝, VL2는 VL1과 유사도가 낮은 라이트 체인
모델에 (VH, VL1)·(VH, VL2)를 각각 넣어 점수 s₁, s₂를 받고,
(VH, VL1)을 양성, (VH, VL2)를 음성으로 라벨링
N개의 삼중항 → 2N개의 (점수, 라벨)로 묶어 최종 지표를 계산
VL2 고르기(가까운 가짜 만들기): 라이트 체인 1만 개 샘플의 쌍별 Levenshtein 유사도를 계산해 평균 μ, 표준편차 σ를 구하고, 각 (VH, VL1)마다 sim(VL1, VL2) < μ − σ를 만족하는 낮은 유사도 VL2를 찾음
(검증/시험에서 각각 생성)
