✅ Introduction
항체 언어 모델(Antibody LMs)의 활용
면역 수용체(항체/항TCR 등) 서열로 학습한 언어모델은
인간화(humanization), 항원 특이성 예측 등 다양한 면역학·치료제 설계 작업에 이미 활용되고 있음
하지만 이런 모델들은 소수 공여자(donor)에 치우친 데이터로 학습되는 경우가 많아,
데이터 편향 → 일반화 성능 저하 가능성이 제기됨
핵심 데이터 소스: OAS
Observed Antibody Space (OAS)는 현재 공개된 항체 서열 데이터 중 가장 큰 컬렉션이며,
사실상 모든 공개 항체 LMs의 주요 학습 데이터 원천으로 쓰이고 있음
문제점: 투명성/재현성 부족
OAS 기반으로 학습된 기존 항체 LM에 대해,
어떤 필터링/전처리 전략을 썼는지에 대한 일관된 검증이나 체계적 분석이 없고,
재현 가능한 공용(preprocessing) 파이프라인이 부재하며,
각 모델이 실제로 사용한 학습용 서열 세트 자체가 공개되지 않았음
이 투명성 부족 때문에 현재 항체 LM의 진짜 능력과 한계를 정확히 평가하기 어렵고, 더 나은 학습 전략을 설계하기도 어려움
이 논문의 주요 기여: OAS용 공개 전처리 파이프라인 제시
24억(2.4 billion) 개의 unpaired 항체 서열(OAS 내)을 대상으로 작동하는, 오픈 소스 처리 파이프라인을 제안
이 파이프라인을 통해 다음이 가능
공여자(donor), 종(species), 체인 타입(chain type: heavy/light 등), 그 밖의 메타데이터 기준으로
사용자가 원하는 대로 필터링 및 균형 잡힌 샘플링을 수행
OAS 편향 분석 결과
파이프라인으로 분석해보니,
단 13명의 개인이 전체 human 항체 서열의 70% 이상을 차지한다는 심각한 편향이 확인됨
즉, 현재 LM가 “대규모 데이터”로 보이지만 실제로는 극도로 적은 수의 공여자에 의존하고 있을 수 있음
RoBERTa 기반 항체 LM 17개 학습
제안한 파이프라인을 사용해,
서로 다른 데이터 구성(도너 조합, 체인 구성 등)을 갖는 여러 데이터셋을 만들고,
거기에 대해 17개의 RoBERTa 스타일 항체 LMs를 학습시켜 비교
모델 일반화 실험에서의 주요 관찰
(1) 체인 타입 간 일반화 실패
한 체인 타입(예: heavy)로 학습한 모델이 다른 체인 타입(light 등)으로 잘 일반화하지 못함
(2) 인간 ↔ 마우스 레퍼토리 간 전이 학습 한계
인간 데이터로 학습한 모델이 마우스 레퍼토리에, 혹은 그 반대로 충분히 잘 전이되지 못함
(3) 개인·배치(batch)-특이적 효과
특정 공여자나 특정 서열 배치 조건에 따른 개별적/배치 특이 효과가 성능에 유의미한 영향을 준다는 것을 확인
도너 다양성 확장이 해결책이 아니었음
단순히 공여자 수를 늘려 도너 다양성을 확장해도,
“새 논문에서 온, 한 번도 보지 못한 개인”에 대한 일반화 성능이 유의미하게 개선되지 않았음
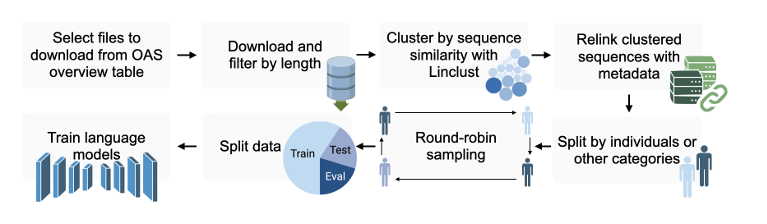
Figure 1: OAS 처리 파이프라인 구조
OAS overview table에서 필요한 파일 선택
선택한 파일 다운로드 후, 서열 길이 기반 필터링 수행
Linclust를 이용해 서열 유사도 기반 클러스터링
각 클러스터를 OAS 메타데이터(도너, 종, 체인 타입 등)와 다시 매핑(relink)
개인별 혹은 다른 기준(종, 체인, 실험 조건 등)에 따라 서열을 그룹/분할
라운드로빈(round-robin) 방식 샘플링
각 그룹/개인/범주가 균형 있게 포함되도록 데이터 추출
Train / Test / Eval 세트로 데이터 분할
이 분할된 균형 데이터셋을 사용해 언어 모델(항체 LM) 학습
✅ Result
✅ OAS 기반 항체 LM 학습 데이터를 위한 처리 파이프라인
✅ Processing pipeline 단계 (OAS-explore)
항체 전용 LM에서 데이터 구성(누구·어떤 체인·어떤 종) 이 성능에 어떤 영향을 주는지 보기 위해
Snakemake 기반 파이프라인 OAS-explore를 제작
이 파이프라인은 OAS 데이터를 항체 LM pretraining용으로 통합 처리
(1) V(D)J 서열 다운로드
OAS overview table을 기반으로 V(D)J 서열을 다운
(2) 길이 필터링(length filtering)
AntiBERTa에서 사용한 것과 유사한 길이 기준을 적용해, 너무 짧거나 비정상적인 서열을 제거
(3) 유사도 기반 클러스터링 (Linclust)
Linclust로 서열을 클러스터링해, 유사 서열들을 묶음
(4) 메타데이터 재매핑(relink)
클러스터링된 서열을 다시 OAS 메타데이터(도너, 종, 체인 타입 등)에 연결
이렇게 하면 이후에 메타데이터 기준 필터링, “특정 메타데이터 subset에서의 성능 분석”이 가능
(5) 새 단계: 도너 단위 분할 & 라운드로빈 샘플링
데이터를 개별 도너 단위로 분할하고, 라운드로빈(round-robin) 방식으로 샘플을 뽑아
특정 도너에 치우치지 않도록 훈련 데이터의 도너 구성을 균형화할 수 있게 함
(6) Train / Test / Eval 분할 & 토크나이즈 & 학습
최종적으로 데이터를 학습/테스트/평가 세트로 나누고,
서열을 토크나이즈한 뒤,
이 데이터로 항체 LMs를 학습
✅ OAS 구성 분석
(1) 규모와 구성
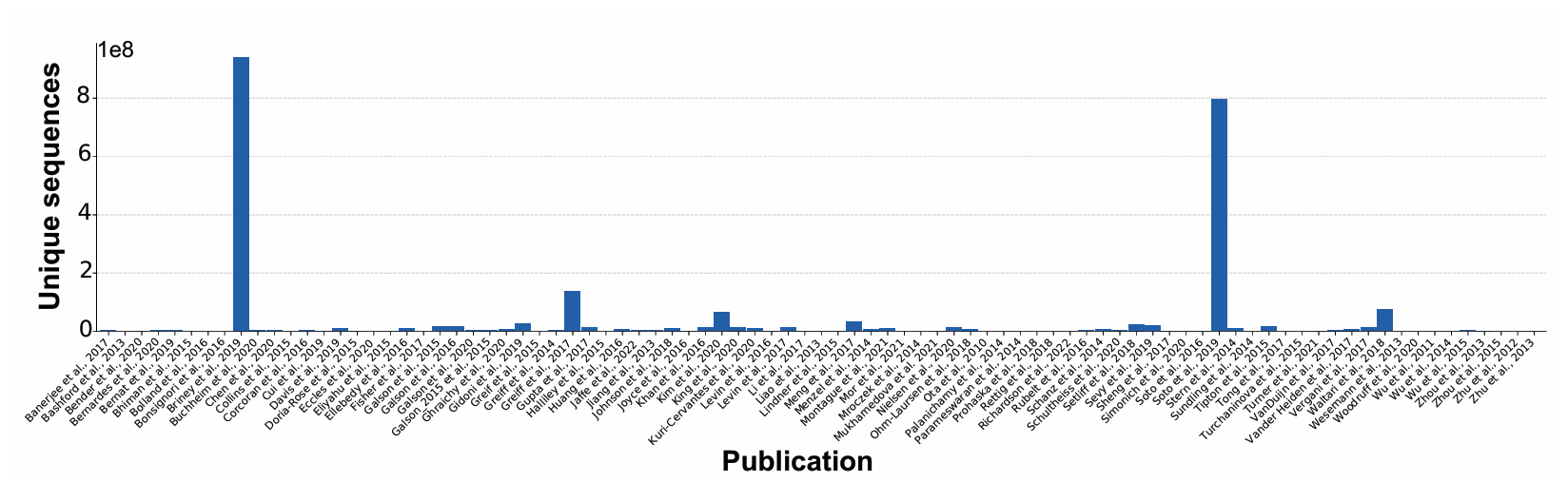
OAS에는 약 24억 개(2.4 billion) 의 대부분 인간 유래(unpaired) 항체 서열이 들어 있음
(2) 극단적인 논문·도너 편향
이 중 71%가 단 두 편의 연구에서만 나온 데이터:
Briney et al. 2019 (도너 10명)
Soto et al. 2019 (도너 3명)
즉, “수십억 서열”처럼 보이지만 실제로는 아주 적은 수의 개인에게 편중되어 있음
(3) 실험에 쓰인 데이터 선택
Briney et al. 데이터는 상당수가 FR1 길이 필터 기준을 통과하지 못해 탈락함
그래서 본 논문의 실험에서는 주로 Soto et al. 데이터를 사용
(4) 도너 다양성의 실상
OAS에는 630명 이상의 개인이 등장하긴 하지만,
대부분은 극히 적은 서열만 가지고 있어,
실질적인 데이터 기여는 극소수 도너에 집중되어 있음
(5) 기존 항체 LMs에도 같은 편향 존재
이런 도너 편향은 기존 항체 LMs(AntiBERTa, AntiBERTy, AbLang, IgBert, Sapiens 등)의 학습 데이터에도 그대로 반영되어 있음
논문에서는 이 편향이 모델 성능과 일반화 능력에 어떤 영향을 주는지 체계적으로 분석
✅ 학습 데이터에서 체인 타입과 종(species)의 중요성
✅ 기존 모델들의 설계 선택
일부 항체 LMs는 인간 데이터만 사용 (예: Sapiens)
다른 모델들은 OAS에 있는 여러 종 혼합 데이터 사용 (예: AntiBERTy, AbLang)
항체는 두 종류의 사슬로 구성:
무거운 사슬(IGH)
가벼운 사슬(IGK, IGL)
설계 방식:
어떤 모델은 heavy+light를 섞어서 하나의 모델로 학습 (예: AntiBERTa)
어떤 모델은 체인별로 분리된 모델 학습 (예: Sapiens)
또 다른 접근:
일반 단백질 PLM을 먼저 학습 후, 항체 데이터에 파인튜닝 (예: IgBert)
문제: 이런 “종 혼합 vs 인간만”, “체인 합침 vs 분리” 선택이
실제 성능과 일반화에 어떤 영향을 주는지 체계적으로 알려진 바가 거의 없음
그래서 저자들은 이 부분을 정량적으로 평가
✅ 혼합/분리 학습 설정에서의 모델 성능
실험 설계: 총 9개의 RoBERTa 모델을 학습
각 모델: 100만 개(1M) 서열 사용, 최대 10 epoch 학습
(1) 인간 데이터 전용 모델 (Human only)
heavy-only 모델
light-only 모델
heavy+light 50:50 혼합 모델
(2) 마우스 데이터 전용 모델 (Mouse only)
heavy-only 모델
light-only 모델
heavy+light 50:50 혼합 모델
(3) 인간+마우스 혼합 데이터 모델 (Mixed human-mouse)
heavy-only 모델
light-only 모델
heavy+light 50:50 혼합 모델
테스트 세트 구성: 각 종/체인 조합마다 10만 개(100k) 서열을 사용
훈련에 쓰이지 않은 도너에서 가져온 서열만 사용해 도너 독립성을 확보
체인과 종마다 고유한 테스트 세트를 만듦
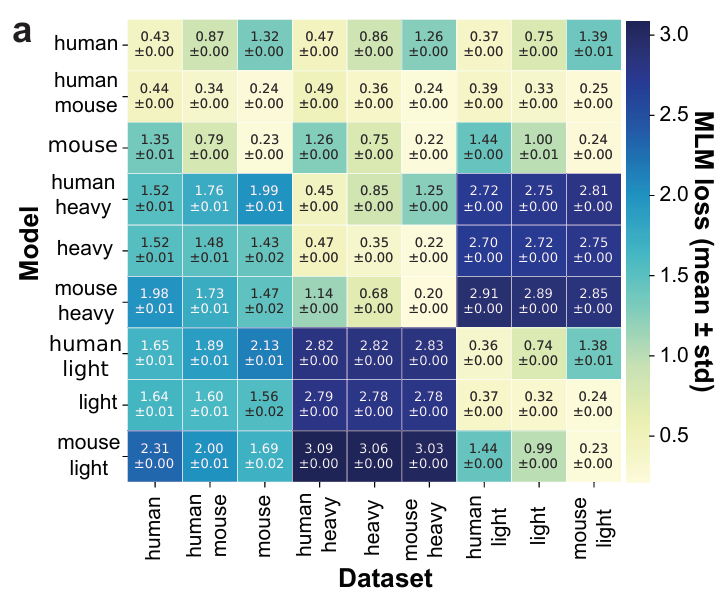
✅ 결과 (Figure 2a)
모델이 하는 일은 “항체 서열 중 가려진 아미노산을 맞추는 것”
(1) train–test 구성 일치 시 성능 최고
모델은 자신이 학습한 데이터 구성(종·체인 타입)과
동일한 테스트 세트에서 가장 낮은 MLM loss를 보임
(2) Cross-chain generalization ≈ 거의 없음
heavy 서열로 학습한 모델을 light 서열에 적용하면
loss가 훈련 시작 시 랜덤 초기화 모델 수준에 가깝게 높아짐
즉, heavy로 배운 정보가 light에 거의 전이되지 않음 (반대도 마찬가지)
(3) Cross-species generalization: 제한적
인간 ↔ 마우스 간 일반화는 cross-chain보다는 낫지만,
여전히 충분히 좋다고 보기 어려운 수준에 머뭄
(4) 혼합 데이터 모델의 성능
인간+마우스, heavy+light를 섞어 학습한 모델들은
각 개별 테스트 세트(예: human heavy, mouse light 등)에서
해당 타입 전용 모델과 거의 비슷한 성능을 냄
즉, mixed training이 큰 손해 없이 여러 조건을 동시에 커버할 수 있음
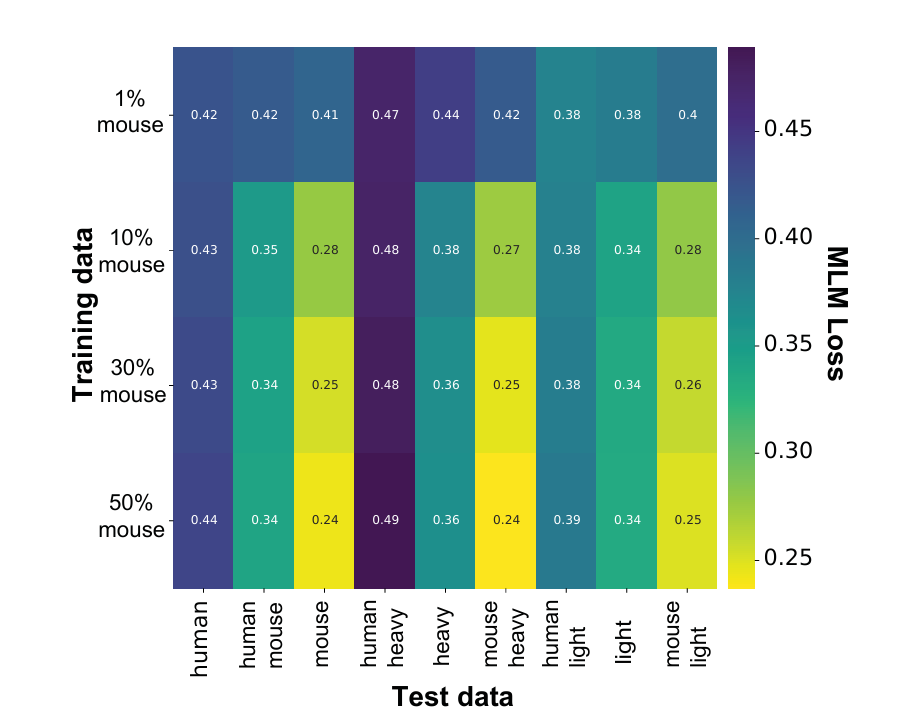
(5) 극소량의 마우스 데이터 효과 (1% 실험)
거의 전부 human 데이터지만, 거기에 단 1%의 mouse 서열만 추가해도
mouse 테스트 세트 MLM loss가 0.41까지 크게 개선
(mouse 데이터 0%일 때는 1.3 수준)
해석:
모델이 매우 적은 양의 마우스 서열만으로도 인간 데이터에서 배운 표현을 바탕으로 마우스 레퍼토리에 대한 지식 일부를 전이할 수 있음을 시사
✅ 결과 (Figure 2b)
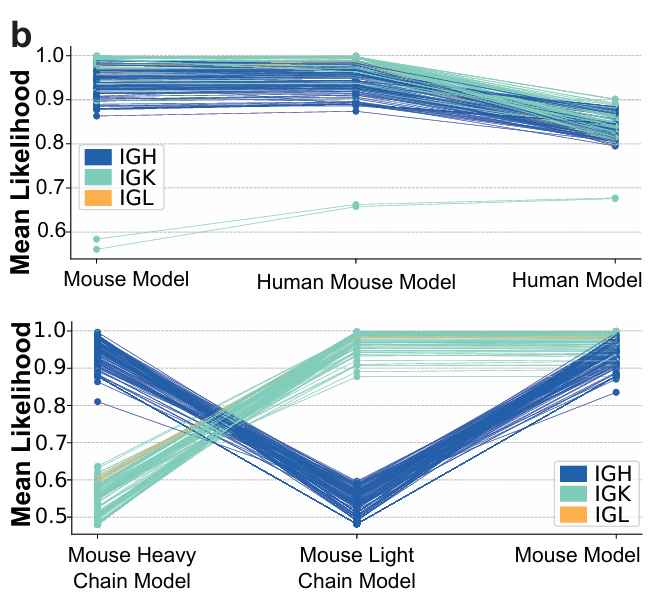
대상: 한 마우스 골수 레퍼토리의 5%에 해당하는 서열들
지표: 각 모델이 부여한 평균 아미노산 likelihood(AA-likelihood)
표현:
x축: 모델이 학습한 데이터 구성(어떤 종/체인 조합인지),
색: 체인 타입(IGH, IGK, IGL).
핵심: 마우스 또는 혼합 데이터로 학습한 모델일수록,
이 마우스 서열들에 더 높은 likelihood를 부여함을 보여줌
✅ 종(species) 정체성이 서열 likelihood를 지배함
PLM이 매기는 likelihood가 학습 데이터에 얼마나 민감한지를 분석
PLM 기반 likelihood는 이미
결합 친화도 증가 돌연변이 제안, 항체 humanization 설계에 활용되고 있음
따라서 “어떤 데이터로 학습했는지”가 likelihood 해석에 직접적인 영향을 줄 수 있음
서열 𝑠에 대한 평균 likelihood(각 위치의 조건부 확률을 평균낸 값):
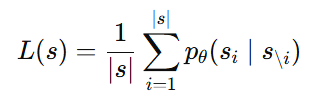
✅ 결과(Figure 3a)
마우스 항체 서열의 경우, 마우스 전용 모델 또는 종 혼합(mixed) 모델이
인간 전용 모델보다 훨씬 더 높은 평균 likelihood를 부여
heavy vs light 체인 비교에서도 유사한 패턴
heavy 모델은 heavy 서열에, light 모델은 light 서열에 더 높은 likelihood를 주는 경향
→ 체인 타입 및 종 정체성이 likelihood를 강하게 좌우
✅ Model performance depends on individual and batch of origin
전체 문제의식: OAS는 소수의 개인(donor) 데이터에 심하게 의존함
그래서 항체 LM이
“보편적인 항체 언어(universal antibody language)”를 학습하는지,
아니면 특정 개인/실험 배치에 특화된 패턴만 학습하는지
이를 보기 위해, “한 명의 개인 데이터로 학습한 모델 vs 여러 개인 데이터로 학습한 모델”을 체계적으로 비교
✅ Generalization across individuals
학습 데이터 설정
네 종류의 모델 (모두 Soto et al. 데이터/파생 데이터 기반):
단일 도너 모델 3개 (HIP-1, HIP-2, HIP-3): 각 모델은 해당 개인의 서열만 사용해 학습
Soto-All 모델: HIP-1/2/3 세 명의 데이터를 합쳐서 학습한 모델
OAS-wo-Soto 모델: HIP-1/2/3을 제외한 나머지 OAS 데이터로,
라운드로빈 샘플링을 사용해 만든 보다 균형 잡힌 데이터셋으로 학습
일부 불균형은 남지만, 최종 약 9천만(90M) 서열로 구성되며,
비교 대상으로 쓰인 다른 세트 및 기존 연구들의 학습 데이터보다
훨씬 균형적인 분포를 가짐
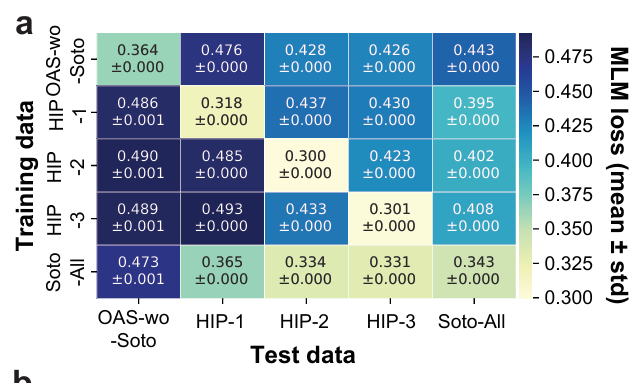
Figure 3a: 자기 도너 vs 다른 도너
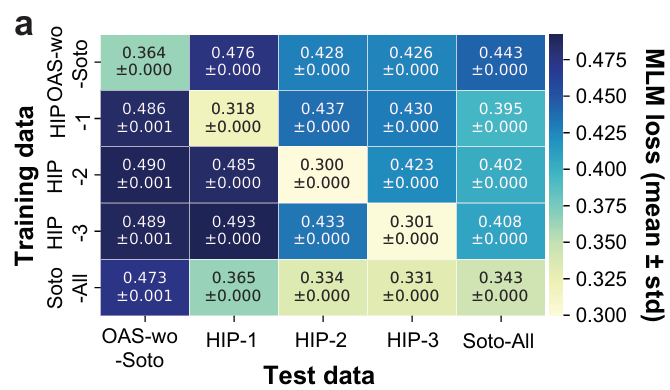
결과: 모든 모델은 “자신이 학습된 데이터 구성”과 일치하는 테스트 세트에서 최고 성능(최저 MLM loss)를 냄
새로운(보지 않은) 개인에 대한 일반화는 전반적으로 제한적
OAS-wo-Soto 모델은, unseen individuals에 대해 HIP-1/2/3 단일 도너 모델과 비슷한 수준의 성능을 보임
즉, 단순히 “개인 수를 늘리기만 해도 일반화가 자동으로 좋아지지는 않는다”는 결론
Figure 3b: 추가 held-out 개인 10명에서의 성능
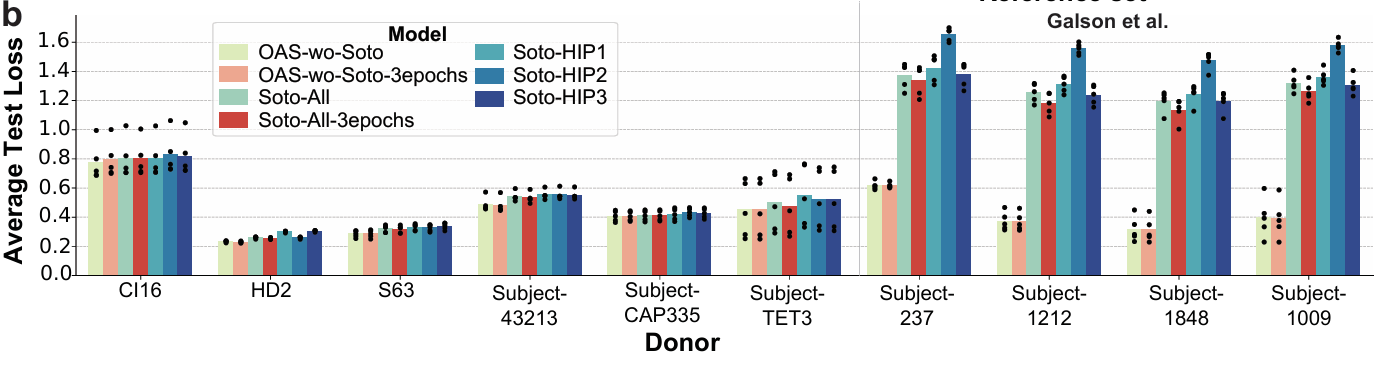
10명의 별도 개인(held-out donors)에 대해 모델들을 평가
HD2, S63 등 일부 개인
모든 모델(단일 도너 포함)이 학습-테스트 구성이 잘 맞을 때와 거의 비슷한 낮은 loss를 달성
→ 어떤 개인에 대해서는 비교적 잘 일반화
백신 연구(vaccine studies)에서 나온 4명의 개인
(Subject-237, -1009, -1212, -1848)
소수 도너로 학습한 모델(HIP-1, Soto-All 등)이 균형형 OAS-wo-Soto 모델보다 훨씬 나쁜 성능을 보임
OAS-wo-Soto 모델은 해당 연구 그룹의 다른 개인들의 데이터도 포함해 학습했기 때문에,
batch-specific effect(연구실/실험 조건 특유 패턴)를 어느 정도 보정/보완할 수 있었던 것으로 보임
추가 학습 실험
보이지 않은 개인에 대한 성능을 높이기 위해 모델들을 추가로 2 epoch 더 학습시켜 봤지만, unseen individuals에 대한 성능은 개선되지 않았음
기존 모델과의 비교
저자들의 모델들은 공개된 기존 모델 IgBert, AntiBERTa-2와 비교했을 때
동등하거나 더 나은 성능을 보임
요약 포인트
모델은 “누구의 데이터로 학습했는가”에 매우 민감
균형 잡힌 다수 도너 데이터(OAS-wo-Soto)는 특정 배치/연구에 과적합된 모델보다 batch 효과를 완화하고 더 견고한 성능을 보일 수 있음
그러나 “개인 수를 단순히 늘리는 것만으로는” 완전한 도너-불변(universal) 표현을 얻기에 충분하지 않음
✅ Humanization of antibody sequences
항체 LM을 humanization에 사용할 때의 전제:
모델이 “무엇이 인간 항체다운지(humanness)”를 내재적으로 학습했다고 가정
그러나, 학습 데이터가 편향되어 있다면, 모델이 학습한 “humanness” 개념도 왜곡될 위험이 있음
논문에서는 학습 데이터 구성이 humanization 결과에 실제로 차이를 만드는지 검증
데이터셋: 실험적으로 humanization이 수행된 이력이 있는 항체 25개를 사용
모델 기반 humanization 절차: 모델이 제안하는 방향으로 반복적으로 돌연변이를 도입해 더 “human-like” 서열을 만들어 가는 방식
평가지표: promB scoring system
서열 안의 9-mer들이 어느 reference DB에 얼마나 자주 등장하는지로 “자연스러움”을 측정
reference를 다르게 잡아 모델이 만든 humanized 서열이 얼마나 “사람다운지” 평가
비교한 reference:
OAS (항체 레퍼토리)
Human reference genome 기반
SwissProt (일반 단백질 DB)
✅ Figure 3c 및 결과
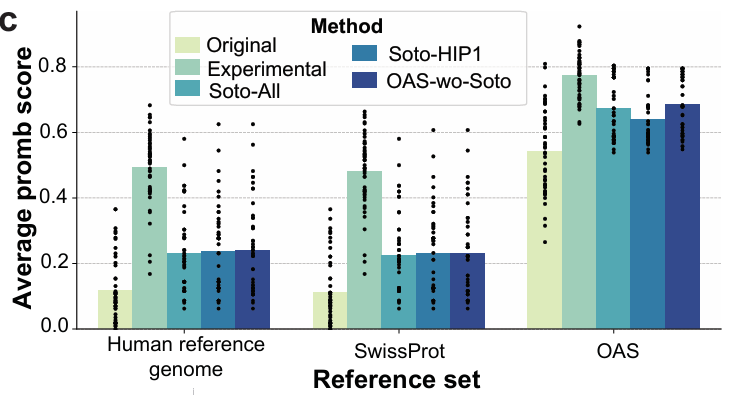
다양한 reference를 사용해 humanization score를 비교
OAS를 reference로 사용할 때 모델이 만들어낸 humanized 서열의 점수가
실제 실험에서 얻어진 humanized 서열과 거의 비슷한 수준
즉, OAS 기준으로 보면 모델 기반 humanization이 꽤 그럴듯하게 동작한다.
OAS를 reference로 보면
모델이 만든 humanized 서열 ≈ 실제 실험 humanized 서열
→ humanization 꽤 잘한 것처럼 보임
다른 reference (예: human reference genome 기반, SwissProt 등)를 사용할 때
같은 모델 humanized 서열의 점수가 뚝 떨어짐, 실험 humanized보다 유의하게 나쁨.
→ 방금까지 human-like 하다더니, 여기서 보니 별로인데? 가 됨
동일한 모델 기반 humanized 서열들이 실험적 humanization보다 유의하게 낮은 점수를 받음
→ OAS에 맞춰 보면 좋아 보이지만, reference를 바꾸면 “덜 인간적”으로 평가될 수 있음을 시사
모델 간 비교
서로 다른 학습 데이터 구성을 가진 모델들 사이에서, 어떤 reference를 쓰더라도 유의미한 점수 차이는 관찰되지 않았음
현재 사용한 promB 스코어만으로는 training data diversity가 humanization 품질에 미치는 미묘한 효과를 잡아내기 어려울 수 있음
더 정교한 humanization 평가 도구가 필요하다고 제안
핵심 정리
항체 LMs는 데이터에 포함된 특정 개인·실험 배치의 패턴에 강하게 의존하며, “완전히 보편적인 항체 언어”를 학습했다고 보긴 어려움
다수 도너를 사용한 균형 데이터(OAS-wo-Soto)는 일부 batch effect를 완화하지만,
단순히 도너 수를 늘리는 것만으로 unseen individual에 완전히 잘 일반화되지는 않음
Humanization 실험에서 모델 기반 humanization은 OAS를 기준으로 보면 실험 결과에 근접하지만,
reference를 바꾸면 성능이 크게 떨어질 수 있어, 훈련 데이터 편향에 맞춘 “humanness” 정의일 가능성이 있음
✅ Discussion
전체 결론
저자들은 OAS-explore 파이프라인을 이용해 OAS에서 여러 서브셋을 만들고,
총 17개의 RoBERTa 기반 항체 LM을 학습
그 결과, 모델들이 새로운 개인(new individuals), 보지 못한 배치(unseen experimental batches) 에 대해 일반화에 어려움을 겪는다는 것을 확인
향후 연구 방향
“개인 특이 효과”와 “배치 특이 효과”라는 두 가지 요인을 분리해서 분석(disentangle)하고, 이 편향을 줄이기 위한 전처리·샘플링 전략을 체계적으로 개발해야 한다고 제안
본 연구의 한계
종(species) 비교(특히 인간 vs 마우스) 실험에서 사용 가능한 마우스 서열이 부족해 훈련 세트 규모가 작았다는 한계
인간 데이터의 경우, 라운드로빈 샘플링이 단순 랜덤 샘플링보다 도너 간 균형을 더 잘 맞추는 것으로 나타남
그럼에도 불구하고 일부 도너는 여전히 과대표집(over-represented) 상태로 남아 있었음
따라서 더 많은(다양한) 개인의 데이터가 필요하며, 그래야 항체 LMs의 진짜 generalizability를 달성할 수 있다고 봄
총 정리
- 체인·종 섞어서 학습 vs 나눠서 학습
cross-chain generalization은 거의 안 된다.
heavy로 학습한 모델을 light에 쓰면, 랜덤 수준.
종(human/mouse)도 완전 호환은 아니다.
인간↔마우스 cross-species generalization은 조금 되지만 제한적.
혼합 데이터(mixed)로 학습해도 손해는 거의 없다.
human+mouse, heavy+light를 같이 넣어 학습한 모델이,
각 조건 전용 모델과 비슷한 수준으로 해당 조건 test에서 성능을 낸다.
아주 소량의 mouse 데이터(1%)만 추가해도 mouse 성능이 확 좋아진다.
→ “사람+쥐 같이 넣는 게 이득이 될 수 있다”는 근거.
- OAS 편향 & humanization 툴
OAS에 논문·도너 편향이 심하다.
LM 기반 humanization을 OAS 기준(promB, OAS DB)으로 평가하면 잘 나와 보이는데,
다른 reference로 보면 성능이 떨어진다.
→ 모델이 배운 “humanness”가 OAS에 특화된 규칙일 수 있다는 의심.
✅ Data processing
길이 필터링 기준 (Leem et al. [6]과 동일)
FR1: 최소 20 잔기
FR4: 최소 10 잔기
CDR1: 5–12 잔기
CDR2: 1–10 잔기
CDR3: 5–38 잔기
이 중 FR1 조건이 가장 강력한 필터, 가장 많은 서열이 여기에서 걸러짐
✅ Antibody humanization (항체 인간화 절차)
Humanization: 동물에서 유래한 항체 후보 서열인간에서 사용 가능하도록 변형하는 과정
목표: 항원 결합 기능은 유지하면서, 인간 면역계가 이 항체를 “이물질”로 인식할 확률을 줄이기 위해 자연 human 항체와 유사한 아미노산 조성을 갖게 만드는 것
사용한 알고리즘 (iterative LM-based humanization)
이전 LM 기반 humanization 연구에서 쓰인 방식을 그대로 사용
전체 서열을 입력하고, 한 위치만 마스킹하여 대체 아미노산 후보의 log-likelihood를 계산
원래 아미노산보다 더 높은 log-likelihood를 갖는 후보가 있으면, 그 중 가장 높은 값을 가진 아미노산으로 치환
치환된 새 서열을 다시 모델에 넣고, 다음 위치에 대해 동일한 과정을 반복
더 이상 치환 제안이 없을 때까지 반복 → 최종 humanized 서열
