✅ Abstract
“원하는 단백질의 움직임(동역학)을 먼저 정해 놓고, 그 움직임을 만족하는 새로운 단백질 서열을 생성하는 AI 시스템”을 제안하는 논문
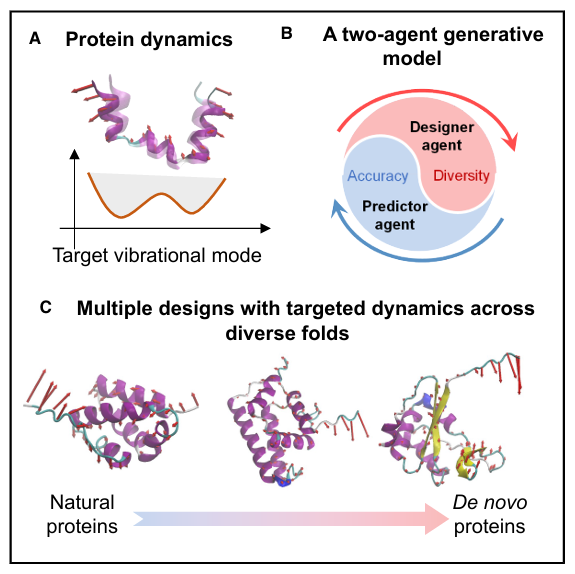
A. Protein dynamics
단백질의 움직임 자체를 목표로 삼는다는 점을 보여줌
“Target vibrational mode”: 단백질이 어떻게 흔들리고 휘고 움직일지를 나타내는 목표 진동 모드를 의미
예전에는 “이 단백질을 어떤 모양으로 접히게 할까?” 를 많이 생각했다면,
이 논문은 “이 단백질이 어떤 식으로 움직이게 만들까?” 를 먼저 생각한다는 것
B. A two-agent generative model
여기서는 두 개의 에이전트가 협력하는 생성 모델을 보여줌
Designer agent와 Predictor agent가 있고, 그 사이에서 Accuracy와 Diversity가 함께 강조
Designer agent: 목표 움직임에 맞는 단백질 서열을 만들어냄
Predictor agent: 그 서열이 정말 목표 움직임을 낼지 평가함
둘이 같이 작동하면서
정확한 설계도 얻고, 한 가지 답만이 아니라 다양한 후보도 얻는다
C. Multiple designs with targeted dynamics across diverse folds
같은 목표 동역학을 만족하더라도 서로 다른 구조(fold)의 단백질이 나올 수 있다는 점을 보여줌
같은 “움직임”을 실현하는 방법이 하나만 있는 게 아니다
구조는 달라도 비슷한 기능적 움직임을 만들 수 있다
그래서 단백질 설계를 “구조 중심”에서 “움직임 중심”으로 바꾸자는 주장
(1) Protein dynamics, not static structure, is treated as the primary design target
정적인 구조가 아니라 단백질의 동역학이 주된 설계 목표
즉, “어떤 모양으로 접히느냐”보다 “어떻게 움직이느냐”를 우선함
(2) A dual-agent generative-predictive system enables dynamics-conditioned design
생성기 + 예측기의 이중 에이전트 시스템으로, 동역학 조건이 주어진 설계가 가능하다는 뜻
(3) VibeGen generates de novo proteins matching prescribed vibrational motions
VibeGen은 미리 지정한 진동 운동 패턴에 맞는 새로운 de novo 단백질을 생성할 수 있음
(4) Multiple distinct protein folds realize similar low-frequency dynamic behavior
서로 다른 fold를 가진 단백질도 비슷한 low frequency 동적 거동(큰 움직임만 반영)을 구현할 수 있음
단백질은 움직임을 통해 기능하는데, 대부분의 기존 설계 도구는 정적인 구조에 집중해왔음
즉, 단백질은 흔히 정적인 형태로 설명되지만, 실제 기능은 운동에 의해 좌우된다.
이 연구는 진동 동역학(vibrational dynamics)을 지정해서 단백질을 설계하는 생성 프레임워크를 소개
그리고 이 과정에서 서로 다른 많은 fold가 비슷한 기능적 움직임을 실현할 수 있음을 보여주며, 이는 단백질 설계를 구조 중심이 아니라 움직임 중심의 family로 다시 보게 만듦
단백질을 “완성된 조각상”처럼 보지 말고, “실제로 움직이는 기계”처럼 봐야 한다
VibeGen이라는 생성형 AI 모델
agentic dual-model architecture를 기반
하나는 protein designer로서 특정 진동 모드에 맞는 서열 후보를 만들고,
다른 하나는 protein predictor로서 그 후보의 동적 정확성을 평가함
그 다음, full-atom 분자동역학 시뮬레이션으로 직접 검증한 결과, 설계된 단백질은 backbone 전체에서 지정된 normal mode amplitude를 정확하게 재현하면서도, 동시에 안정적이고 기능적으로 관련 있는 구조를 취함
또한 생성된 서열은 de novo였고, 자연 단백질과 유의미한 유사성이 없었음
결국 이 모델은 서열 ↔ 진동 거동 사이에 직접적이고 양방향적인 연결을 세우며, 원하는 동적/기능적 특성을 가진 생체분자를 효율적으로 설계할 수 있는 길을 염
✅ Introduction
단백질이 정적인 구조물이 아니라 dynamic molecular machines
단백질의 많은 기능은 시간과 공간에 걸친 구조 변화(conformational fluctuations)에서 나옴
에너지 관점에서는 단백질이 울퉁불퉁한 에너지 지형 위에서 여러 구조 상태를 오가며, 펨토초 단위 결합 진동부터 밀리초 수준의 도메인 재배열까지 다양한 움직임을 보임
이런 동역학이 촉매작용(catalysis), 알로스테리(allostery), 기계적 신호전달(mechanotransduction) 같은 중요한 기능을 떠받침
- dihydrofolate reductase, adenylate kinase 같은 효소에서는 loop motion이나 lid fluctuation이 활성 부위에서 촉매 잔기 정렬과 기질 격리에 도움을 줄 수 있음
- 알로스테리에서는 리간드 결합이 구조 평형을 바꾸며 신호전달을 조절함
- GPCR에서는 transmembrane helix 재배열이 활성화와 관련됨
즉, 단백질은 “모양이 맞아서”만 작동하는 게 아니라,
필요한 타이밍에 필요한 방향으로 움직일 수 있어야 작동함
논문은 여러 동역학 중에서도 low-frequency vibrations가 중요하다고 말함
이 low-frequency vibrations(저주파 진동)은
- 촉매 반응의 에너지 장벽을 낮추고
- 큰 구조 변화(conformation shift)를 돕고
- 리간드 결합에도 관여할 수 있음
또한 기능적으로 중요한 전이 경로가 종종 하나 혹은 소수의 low-frequency normal mode의 궤적에서 나타난다는 기존 연구들이 있음
즉,
단백질 안에는 빠르고 작은 흔들림도 많지만,
그중에서도 전체적으로 크고 느리게 움직이는 집단 운동이 기능적으로 특히 중요하다고 보는 것
단백질 움직임이 망가지면 병이 생길 수 있음
- p53 암 돌연변이는 구조 유연성이 줄어 DNA 결합이 잘 안 될 수 있고
- CFTR 돌연변이는 이온 수송에 중요한 gating dynamics를 망가뜨릴 수 있음
즉, 단백질의 “움직임”은 그냥 부수적인 특징이 아니라,
기능의 핵심 결정요인임
단백질 동역학을 연구하는 기존 방법들
실험 방법
- NMR spectroscopy
- HDX mass spectrometry
- cryo-EM
- single-molecule FRET
- terahertz spectroscopy
계산 방법
- MD (molecular dynamics)
- NMA (normal mode analysis)
- ENM (elastic network model)
하지만 문제는,
이 방법들은 특정 단백질을 깊게 이해하는 데는 좋지만
시간과 자원이 많이 들고,
특히 전통적인 MD는 대규모로 확장하기 어렵다는 점
그래서 많은 단백질에 대해 기능-동역학-구조-서열을 효율적으로 연결하는 일은 아직 어렵고, 원하는 동역학을 기준으로 단백질을 설계하는 일도 드묾
최근 AI가 단백질 연구를 많이 바꿨으나, AlphaFold2 같은 folding model들은 대개 하나의 equilibrium conformation, 즉 대표적인 정적 구조 하나를 예측하는 데 집중함
그래서 단백질 기능에 중요한 진동 동역학 자체는 충분히 다루지 못함
AlphaFold3등은 새로운 binder, 대칭 구조, 다양한 복합체를 만드는 데 도움이 되지만,
설계 backbone이나 기능 motif의 정적인 형상을 기준으로 생각하고,
동역학으로 직접 조건을 거는 메커니즘이 부족함
즉, 현실적인 움직임까지 고려한 단백질 설계는 아직 드묾
이 문제를 해결하기 위해 이 논문은 단백질 generation agents로 이루어진 모델을 제안
목표는 정적 구조가 아니라 key dynamics signature
특히 low-frequency normal mode shape vector를 주된 설계 조건으로 사용
이를 바탕으로 정확하면서도 다양한 단백질 설계를 하겠다는 것
static structure prediction과 orthogonal 한 방식임
즉 “목표 fold를 정하고 그걸 맞추는” 방식이 아니라,
목표 저주파 normal mode shape를 정하고, 그걸 만족하는 서열을 생성하는 방식
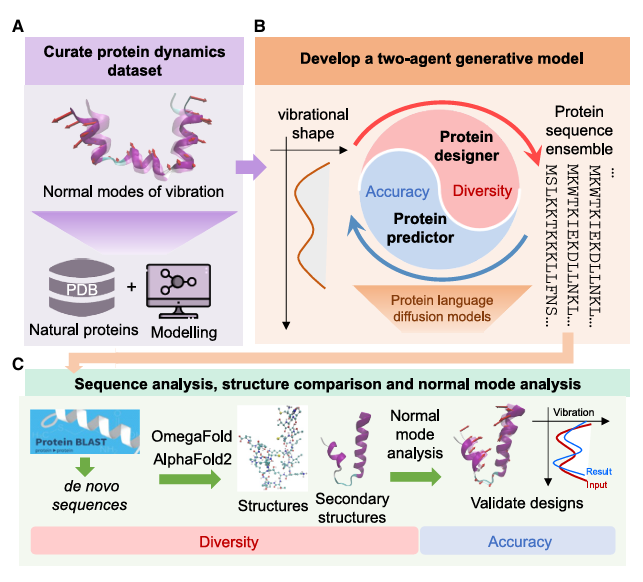
Figure 1A. Curate protein dynamics dataset
먼저 연구진은 많은 PDB 단백질에 대해
NMA + full-atom MD를 이용해
nontrivial low-frequency vibrational normal mode를 계산하고,
그걸 각 단백질의 dynamics signature로 사용
->
기존 단백질들을 모아서
“이 단백질은 어떤 식으로 크게 흔들리는가?”
를 데이터셋으로 만듦
Figure 1B. Develop a two-agent generative model
그 다음 protein language diffusion models를 기반으로 한 두 모델을 만든다.
PD (protein designer): 주어진 진동 모양(normal mode shape)에 맞는 단백질 서열을 제안
PP (protein predictor): 주어진 서열이 어떤 normal mode shape를 가질지 예측
실전 생성 단계에서는 둘이 협력
- PD가 여러 서열 후보를 만든다
- PP가 그 후보들이 목표 동역학과 얼마나 맞는지 평가한다
- 그래서 diversity와 accuracy의 균형을 맞춘다
Figure 1C. Analyze and validate generated proteins
마지막으로 생성된 단백질을 검증
protein-protein BLAST로 생성 서열이 기존 자연 단백질과 얼마나 비슷한지 확인하고, de novo인지 확인
OmegaFold, AlphaFold2 같은 folding tool로 원자 구조를 예측
secondary structure를 분석
MD + NMA로 다시 진동 모드를 계산해서, 입력한 설계 목표와 실제 생성 결과가 맞는지 검증
기존 dynamics-aware machine learning과의 차이
- 연속적인 low-frequency normal mode shape를 직접 조건으로 사용
- sequence-dynamics mapping을 양방향으로 배우며
- dynamics를 보조적 정보가 아니라 주된 설계 목표로 끌어올렸다는 점
- sequence ↔ normal mode vibration 사이의 복잡하고 퇴화적인 관계를 양방향으로 학습할 수 있고
- 실제 사용 시에는 주어진 normal mode shape에 맞는 여러 서열을 설계하고
- 그 성능을 즉석에서 예측하며
- 그중 많은 것이 de novo이면서도 설계 목표를 정확히 만족한다고 주장
또 단일 모델보다 두 모델이 협력하는 two-player framework가 더 좋다고 말함
즉, forward prediction과 inverse design을 같이 쓰면 diversity, accuracy, novelty를 동시에 얻기 유리하다는 것
✅ Result
✅ Protein database on low-frequency vibrational normal modes
✅ 왜 low-frequency normal mode를 쓰는가
단백질의 동역학은 여러 시간·공간 규모에서 일어나지만, 그중에서도 low-frequency mode(저주파 모드)가 단백질 기능을 이해하는 데 핵심이면서도 효율적인 signature(대표 지표)라고 말함
기계적 관점에서 보면 이런 low-frequency mode 는 변형 에너지 penalty가 낮은 운동 패턴이고, 주로 단백질의 유연성(flexibility)에 기여함
기존 연구들에서도 low-frequency mode 분석을 통해 ligand binding, conformational change, enzyme catalysis, protein-protein interaction에 대한 통찰을 얻었다고 설명함
쉽게 말하면,
단백질은 수많은 방식으로 흔들리지만, 그중에서도 천천히 크고 집단적으로 움직이는 패턴이 기능과 특히 잘 연결된다고 보는 것그래서 논문은 그걸 설계 목표로 삼음
✅ 이 논문이 실제로 동역학을 어떻게 표현하는가
단백질 동역학의 essential signature를 표현하기 위해 low-frequency normal mode를 채택
그런데 frequency 자체보다, 단백질 전체 backbone을 따라 각 residue가 얼마나 크게 움직이는지의 분포,
즉 vibrational displacement distribution에 집중
이를 얻기 위해 기존 연구들처럼 NMA(normal mode analysis)를 사용함
구체적으로는 먼저 full-atom MD를 CHARMM force field + implicit solvent model로 돌려 구조를 relaxation한 뒤,
그 구조에 대해 Hessian matrix의 고유값 문제를 풀어 normal mode를 계산함
Hessian의 각 성분은 potential energy function의 2차 미분들이다.
논문은 이런 전원자(atomistic) 표현 + 적절한 force field가 coarse-grained 방법보다 더 신뢰도 높은 normal mode 결과를 줄 것으로 기대한다고 말함
또한 첫 6개 mode는 rigid body motion에 해당하는 trivial zero-frequency mode이므로 제외하고, 7번째부터의 nontrivial mode를 봄
이번 모델 연구에서는 그중에서도 가장 낮은 주파수를 가지는 첫 번째 nontrivial normal mode 하나만 샘플링해서 사용함
쉽게 말하면,
먼저 MD로 구조를 조금 안정화시킴
그 구조가 “어떻게 집단적으로 흔들릴 수 있는지” NMA로 계산함
그중 가장 대표적인 느린 큰 움직임 하나를 뽑아 사용함
✅ Figure 2: normal mode shape vector를 어떻게 정의하는가
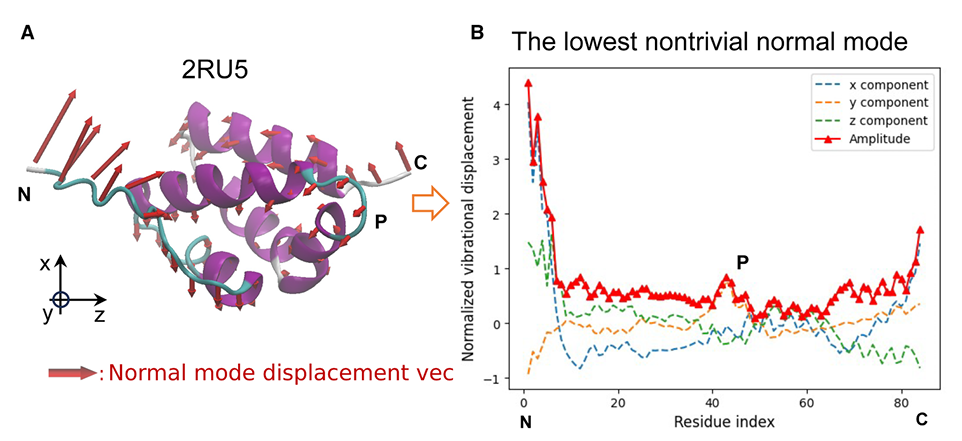
Figure 2A
예시 단백질 PDB: 2RU5의 lowest non-trivial normal mode
빨간 화살표는 각 위치의 displacement vector
Figure 2B
backbone을 따라 residue별 Cα 원자에서 displacement의 x, y, z 성분과 amplitude를 표시
이 분포는 backbone 전체에서 균일하지 않고 heterogeneous하며, local structure와 flexibility에 따라 달라진다고 설명
N, C terminal처럼 구조가 느슨하고 열린 부분은 진동 displacement가 더 큼
backbone 내부의 더 compact한 부분은 displacement가 더 작음
helix 사이를 잇는 turn/coil 부분은 helix보다 덜 구속되어 있어서 더 유연하고, 실제로 Figure 2의 P 지점에서 local maximum amplitude가 관찰됨
즉,
빽빽하고 단단하게 묶여 있는 부분은 덜 움직이고,
열려 있거나 덜 정돈된 부분은 더 많이 움직인다는 뜻
✅ Equation 1, 2: normal mode shape vector
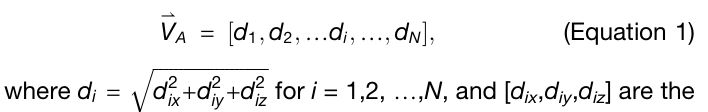
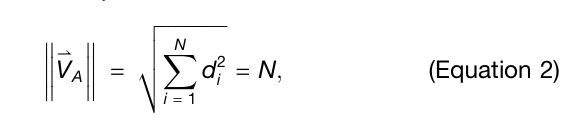
backbone을 따라 진동의 세기를 표현하기 위해 normal mode shape vector 를 정의
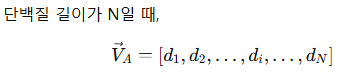
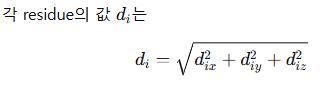
즉, i번째 residue에서의 3차원 displacement vector의 크기
그다음 서로 다른 길이의 단백질끼리 비교하기 위해 이 벡터를 normalize
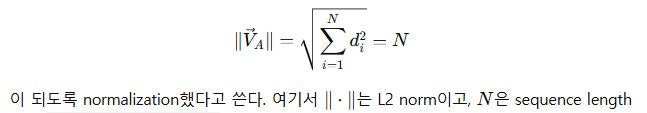
중요한 성질
이 벡터는 성분 자체가 아니라 amplitude를 쓰기 때문에, 좌표계 선택에 의존하지 않는 frame-invariant descriptor
즉, 단백질을 회전시켜도 같은 descriptor로 볼 수 있다는 뜻
또 나중 Figure 5A, 5B에서는 전체적인 모양만 보기 위해 residue index 방향으로 relative frequency cutoff 10%의 low-pass filter를 적용해, high-frequency residue-to-residue fluctuation은 없애고 거친 spatial pattern만 남긴다고 미리 설명
쉽게 말하면,
각 residue마다 “얼마나 크게 움직이는지” 숫자 하나를 주고, 그 숫자들을 줄 세운 벡터가 바로 이 논문의 핵심 입력/출력 표현
✅ 데이터셋 구축: 몇 개의 단백질을 모았는가
자연 단백질에 대한 dynamics signature 데이터셋
2024년 1월 11일 기준 PDB에 있는 단백질들 중 길이 126 aa 이하의 것들
최종적으로 12,924개의 protein monomer chain 결과를 모음
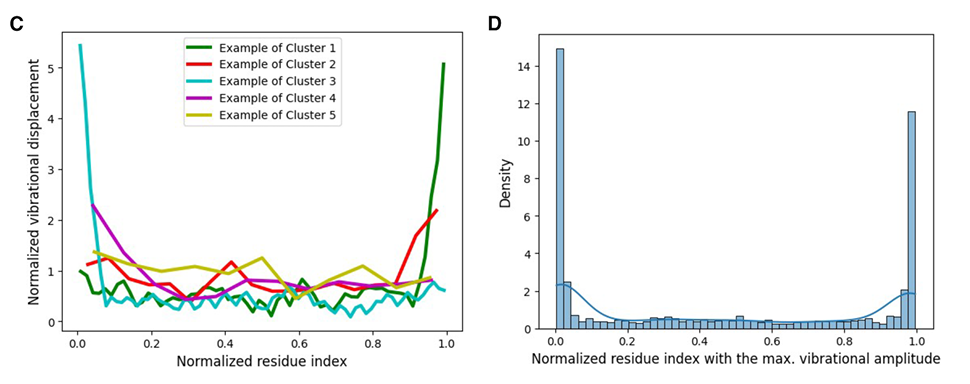
Figure 2C: 이렇게 모은 단백질들의 normalized mode shape vector 예시들
서로 peak 위치가 다양해서, 가장 낮은 비자명 진동 모드 하나만 보더라도 단백질마다 꽤 복잡한 차이가 있다는 걸 의미
Figure 2D: backbone에서 최대 진동 amplitude를 보이는 residue 위치의 분포
양 끝에 peak가 2개 나타나는데, 이는 terminal 쪽이 강하게 진동하는 경향이 흔하다는 뜻
다음 단계는 sequence ↔ normal mode shape vector를 양방향으로 연결하고, 주어진 normal mode shape로부터 단백질을 생성하며, 그 accuracy, diversity, novelty를 평가하는 것
✅ Agentic protein generation model and inverse design for normal mode shapes
✅ 왜 inverse design이 어려운가
논문은 기존의 protein language diffusion models (pLDMs)가 pretrained protein language model의 서열 지식과 diffusion model의 설계 능력을 결합해 복잡한 조건을 protein sequence space로 매핑할 수 있음을 언급
하지만 여기서 다루는 문제, 즉 lowest non-trivial normal mode shape를 보고 단백질 서열을 역으로 설계하는 일은 두 가지 이유로 어렵다고 설명
첫 번째는 복잡성(complexity)
normal mode shape는 backbone의 3D geometry, hierarchical structure, elasticity에 의해 결정되고, local feature(예: secondary structure type)와 global feature(예: topology) 모두에 민감함
따라서 sequence와 normal mode vibration을 직접 연결하는 일은 쉽지 않음
두 번째는 퇴화성(degeneracy)
역학 관점에서 단일 normal mode 정보만으로는 시스템 전체, 예를 들어 Hessian matrix 전체를 규정할 수 없음
게다가 이 논문이 사용하는 벡터는 directional information을 버리고 amplitude만 남긴 표현
그래서 서로 다른 구조와 다른 서열을 가진 단백질들이 비슷하거나 같은 normal mode shape vector를 가질 가능성이 높음
이 때문에 inverse design problem은 본질적으로 highly degenerate 함
대신 이것은 “같은 동적 거동을 실현하는 여러 설계 클래스”를 이해할 가능성도 열어 준다고도 말함
쉽게 말하면,
같은 “움직임 패턴”을 만드는 서열이 하나만 있는 게 아니라 여러 개일 수 있다는 것
이건 어려움이지만, 동시에 다양성의 원천이기도 하다
✅ Figure 3: PD와 PP 두 모델의 구조
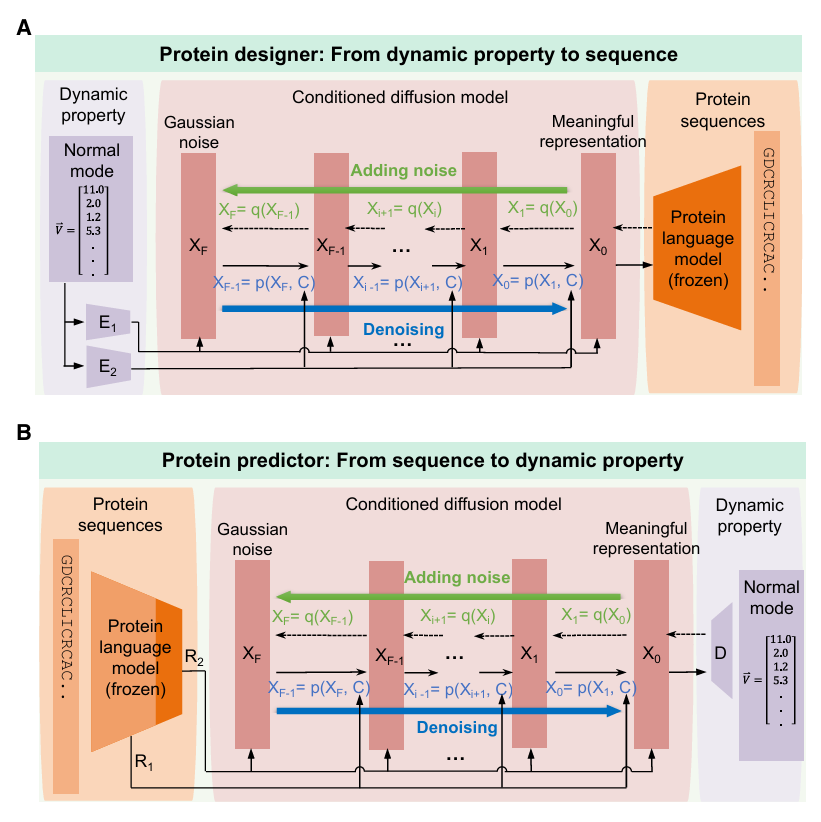
이 문제를 풀기 위해 논문은 두 개의 separate pLDM 모델을 사용
- PD (protein designer): dynamic property → sequence
- PP (protein predictor): sequence → dynamic property
PD: dynamic property에서 sequence로
Figure 3A: PD는 주어진 dynamic property를 바탕으로 protein sequence를 생성
이 모델은 큰 protein sequence corpus로 사전학습된 pLM과
학습 가능한 1D U-Net + attention 기반 diffusion model
을 결합
pLM은 token space와 pretrained latent space 사이를 번역하는 역할
diffusion model은 그 latent space에서 새로운 점을 샘플하고 점점 개선
이때 dynamic property에서 매핑된 E1, E2라는 다중 conditioning channel을 이용해 denoising 과정이 조건부로 진행됨
E1, E2는 trainable encoder
PP: sequence에서 dynamic property로
목표는 sequence로부터 dynamic property를 예측하는 것
denoising 과정에서 pretrained pLM을 통해 얻은 sequence representation을 조건으로 사용
여기에는
- hidden state를 쓰는 R1 channel
- logits의 softmax probability를 쓰는 R2 channel
이 포함
최종 결과는 decoder D를 통해 다시 normal mode shape vector 공간으로 변환
D는 trainable decoder
두 모델은 별도로 학습된다.
PD는 “이런 움직임을 내는 단백질 서열 좀 만들어봐” 담당
PP는 “이 서열이면 어떤 움직임이 나올지 예측해볼게” 담당
✅ 이 두 모델을 실제 생성 시 어떻게 쓰는가
성능을 높이기 위해 논문은 PD와 PP를 collaborative agentic system으로 묶음
주어진 design objective(normal mode vector)가 있으면 PD가 여러 sequence candidate를 생성하고, PP가 즉석에서 각 후보의 normal mode vector를 예측해 성능을 평가
실험에서는 먼저 가장 정확한 설계를 찾는 시나리오로 시작
각 design goal마다 PD가 40개 후보를 만들고, 그중 PP가 예측한 정확도를 기준으로 가장 좋은 하나를 고름
이후 그 sequence를 같은 NMA 프로토콜로 다시 검증하고, 3D 구조는 OmegaFold로 예측
또 protein BLAST와 DSSP를 이용해 novelty, secondary structure, normal mode와의 관계를 봄
✅ Figure 4: 실제 생성 예시들
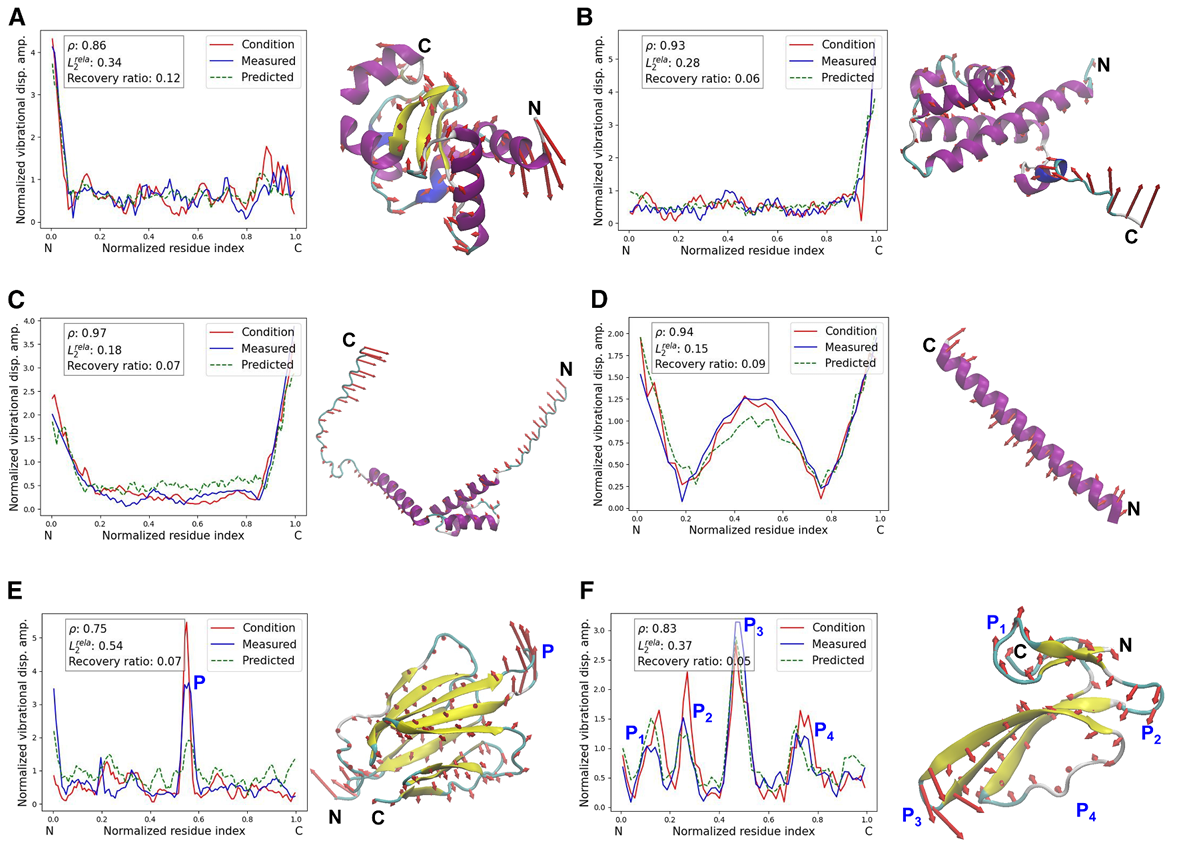
자연 단백질의 normal mode shape vector를 입력으로 넣고, 그에 맞게 생성된 단백질 예시들을 보여줌
빨간 곡선이 input condition, 파란 곡선이 실제 측정된 generated protein의 normal mode shape,
초록 점선이 sequence만 보고 PP가 예측한 normal mode shape
대표적으로 6가지 모양을 보여줌
- A: L-shape
최대 진동이 N-terminal 근처에 집중되고, 나머지 부분은 비교적 약한 amplitude를 가짐
Figure 안의 값은 대략 ρ = 0.86, relative L2 error = 0.34, recovery ratio = 0.12
- B: flipped L-shape
A를 좌우 반전한 형태로, 최대 진동이 C-terminal 근처
값은 ρ = 0.93, relative L2 error = 0.28, recovery ratio = 0.06
- C: U-shape
양쪽 끝, 즉 N과 C terminal 둘 다 강하게 진동하고 가운데는 덜 움직임
값은 ρ = 0.97, relative L2 error = 0.18, recovery ratio = 0.07
- D: W-shape
양쪽 terminal과 중간 부분이 강하게 진동하고, 그 사이에는 거의 0에 가까운 stationary node가 두 개
값은 ρ = 0.94, relative L2 error = 0.15, recovery ratio = 0.09
- E: single internal peak
terminal이 아니라 내부의 한 지점 P에서 진동이 크게 올라감
값은 ρ = 0.75, relative L2 error = 0.54, recovery ratio = 0.07
- F: multiple internal peaks
내부에 P1–P4 같은 여러 peak가 있음
값은 ρ = 0.83, relative L2 error = 0.37, recovery ratio = 0.05
이 단순화된 L/U/W 모양들 위에도 실제 목표 곡선에는 작지만 복잡한 oscillation이 들어 있다고 말함
그럼에도 생성 단백질의 measured normal mode shape는 전체적으로 input design objective를 꽤 잘 따름
정량적 정확도 평가는 Pearson coefficient ρ와 relative L2 error로 함
큰 ρ와 작은 L2 error는 설계가 잘 맞았다는 뜻
논문은 Figure 4 값들을 근거로 generation agents가 다양한 design objective에 대해 정확한 설계를 만들 수 있다고 해석
쉽게 말하면,
목표로 넣은 진동 패턴이 꽤 여러 종류였는데도,
생성된 단백질들이 실제로 그 패턴을 꽤 비슷하게 따라갔다는 뜻
✅ Figure 4 구조 해석: 왜 어떤 구조가 그런 진동을 내는가
B, C 케이스에서는 큰 진동이 terminal 쪽에 집중되어 있는데, 실제로 그 부위에 unstructured coil이 자주 보임
반대로 더 compact한 backbone geometry, 그리고 alpha-helix, beta-sheet처럼 H-bond로 더 구속된 구조는 진동을 억제함
-> 그래서 A–C의 가운데 부위처럼 단단한 부분은 덜 흔들림
open end 근처라고 해도, 그 말단이 alpha-helix처럼 더 구속된 구조를 가지면 상대 진동이 억제될 수 있음
-> 논문은 B의 N-terminal을 예로 듦
beta-sheet 자체보다, beta-sheet 사이를 연결하는 덜 구속된 연결부가 중간 부위의 높은 진동 amplitude에 더 기여하는 경향이 있음
-> 논문은 E의 P, F의 P1–P4를 그 예로 듦
D 케이스는 비교적 짧은 sequence가 거의 continuous alpha-helix 구조를 가지는데, 이를 hydrogen bond로 안정화된 elastic rod로 근사할 수 있고, 관측된 vibration shape가 그 근사와 잘 맞음
✅ recovery ratio와 sequence novelty
논문은 생성된 sequence를, 입력 condition으로 사용한 test set의 known sequence와 비교해 recovery ratio를 봄
recovery ratio가 낮다는 것은 생성된 sequence가 원래 known sequence와 많이 다르다는 뜻
Figure 4의 예시들에서도 recovery ratio가 대체로 낮아서, generated sequence가 known one과 꽤 다르다는 점을 보여 준다.
즉,
이 모델은 단순히 기존 단백질 서열을 복사하는 게 아니라,
같은 동역학 목표를 만족하는 다른 서열을 찾고 있다는 의미
✅ Table 1: BLAST 분석 결과
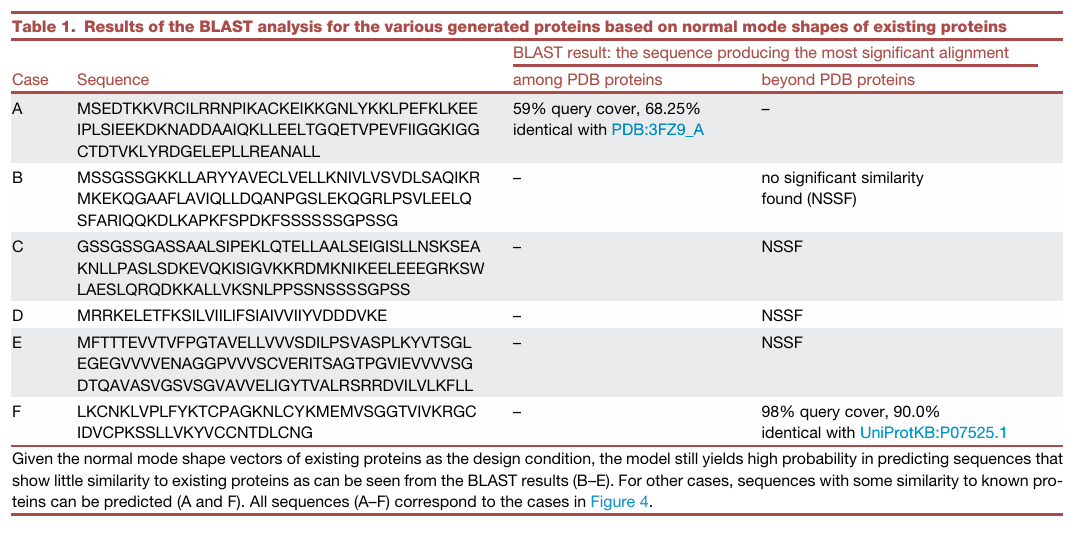
생성 서열이 정말 de novo인지 보기 위해 논문은 predicted amino acid sequence에 대해 BLAST를 수행
Table 1은 Figure 4의 A–F 예시에 대한 결과
- A: PDB:3FZ9_A와 59% query cover, 68.25% identical
- B: no significant similarity found (NSSF)
- C: NSSF
- D: NSSF
- E: NSSF
- F: UniProtKB:P07525.1과 98% query cover, 90.0% identical
입력 design target은 기존 PDB protein의 normal mode shape에서 왔지만,
생성된 sequence 중 많은 경우, 특히 B–E는 기존 known protein과 유의미한 BLAST 유사성이 없어서 de novo로 볼 수 있음
반면 A, F처럼 기존 단백질과 어느 정도 유사한 sequence가 생성될 수도 있음
이는 모델이 PDB의 일부만 학습했고, 기존 PDB의 normal mode shape를 입력으로 쓰며, 문제 자체가 degenerate하기 때문에, 때로는 known protein과 비슷한 해를 “rediscover”할 가능성도 있음
또 하나 중요한 점은, 이렇게 novelty가 높은 generated sequence에 대해서도 PP가 sequence만 보고 예측한 normal mode shape(초록 점선)이 실제 측정된 것(파랑)과 꽤 잘 맞는다는 점
즉, PP는 de novo sequence에도 꽤 신뢰할 만하게 작동한다고 논문은 해석
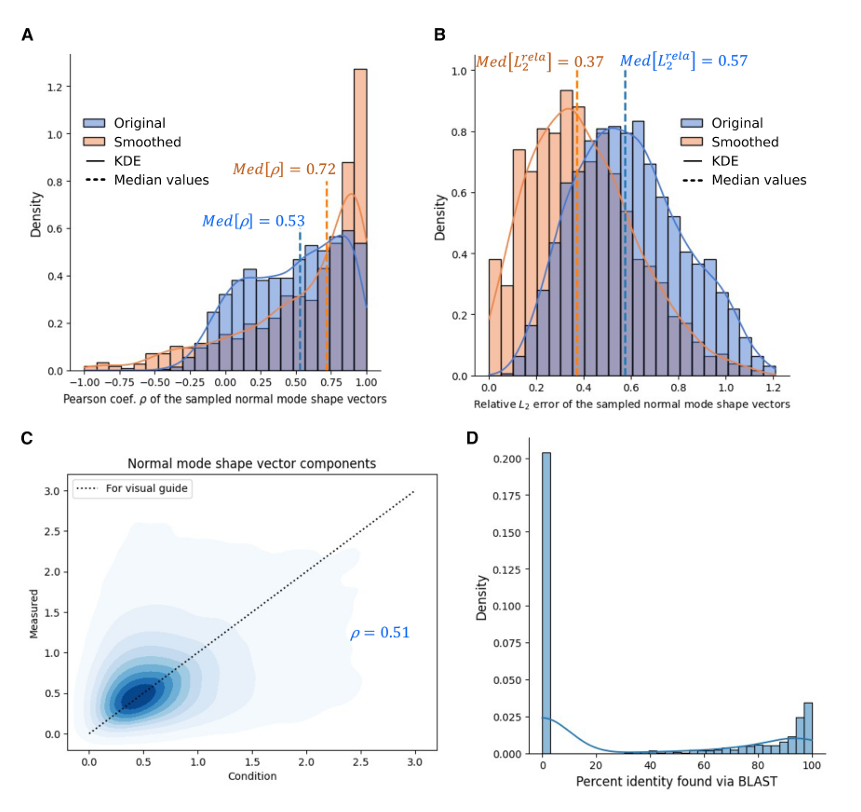
✅ Figure 5: 전체 test set 1,293개에 대한 성능
개별 예시만이 아니라, 논문은 더 큰 규모의 전체 분포도 보여줌
Figure 5: standalone test set의 1,293개 protein을 기반으로 한 결과
- Figure 5A: Pearson coefficient 분포
원래 normal mode shape와 input condition을 비교한 Pearson coefficient 분포(파란색)는 unimodal이고, 가장 높은 population peak가 약 0.87 근처에 있음
이는 꽤 정확한 케이스가 많다는 뜻
하지만 분포는 1.00에서 -0.50 사이까지 넓게 퍼져 있고, median은 0.53
따라서 정확도가 좋은 경우도 많지만, 상대적으로 부정확한 경우도 꽤 존재한다는 뜻
그림에서 smoothing 후 median은 0.72로 표시됨
- Figure 5B: relative L2 error 분포
relative L2 error의 원본 분포(파란색)는 median 0.57이고, smoothing 후에는 0.37로 개선됨
원본 기준으로는 residue-level accuracy가 충분히 높지 않은 경우가 있다는 뜻
- Figure 5C: component-wise comparison
모든 normal mode shape vector의 성분들을 component-wise로 비교하면 점들이 y = x 선 주변에 넓게 퍼져 있고, 전체 Pearson coefficient는 0.51
이는 vector-wise median 0.53과 비슷
논문은 이것을, residue 하나하나 수준에서 아주 정밀하게 맞추는 것은 본질적으로 어려운 문제라는 해석으로 연결
쉽게 말하면,
개별 residue까지 완벽히 맞추는 건 어렵지만,
전체 패턴 수준에서는 꽤 잘 맞추고 있다는 뜻
✅ 왜 smoothing을 하면 성능이 더 좋아지는가
논문은 vibration-based design에서는 residue마다 생기는 작은 oscillation보다, overall shape가 더 중요할 수 있다고 말함
예를 들어 Figure 4의 L, U, W 모양 자체가 binder design 같은 실제 응용에서는 residue-level의 작은 요동보다 더 의미 있을 수 있음
그래서 measured와 conditioned normal mode shape vector에 FFT 기반 low-pass filter를 적용해, 가장 낮은 10% 주파수만 통과시키고 나머지는 제거
그러면 전체 추세는 남기고 residue-to-residue high-frequency oscillation은 줄일 수 있음
그 결과, smoothing한 normal mode shape 기준으로는
Pearson median이 0.53 → 0.72
relative L2 error median이 0.57 → 0.37
로 분명히 개선됨
논문은 이를 근거로, 이 agentic protein generation model은 큰 스케일의 저주파 overall vibration profile을 특히 더 잘 재현한다고 해석
즉,
이 모델은 “세세한 울퉁불퉁함”까지 완벽히 맞추는 것보다,
전체적인 진동 윤곽선을 더 잘 맞추는 모델
그리고 논문은 그게 오히려 biologically relevant한 부분일 수 있다고 봄
- Figure 5D: novelty의 전체 분포
Figure 5D: generated sequence들의 highest percent identity via BLAST 분포를 보여 줌
논문은 이것이 bimodal distribution이라고 말함
왼쪽 큰 peak는 generated protein이 existing/known protein과 거의 닮지 않은 경우로, 즉 totally de novo인 경우
오른쪽의 더 약한 peak는 known protein과 꽤 유사한 경우
이 bimodal 분포는 Table 1의 개별 결과와도 일치하며, 두 peak의 상대적 높이는 모델이 de novo sequence design 쪽을 더 강하게 선호하는 경향이 있음을 시사한다고 해석
논문의 결론은 이 부분에서 아주 분명
이 접근은 protein sequence space를 evolution’s “comfort zone” 밖까지 효과적으로 탐색하며, 가능한 structural/dynamic solution의 repertoire를 크게 확장한다고 주장
✅ Benefits of using protein generation agents in boosting design diversity and accuracy
두 에이전트(PD + PP)를 쓰면 왜 다양성과 정확도가 같이 좋아지는가
PD가 만든 40개 후보 중 PP가 점수화한 상위 4개 서열을 뽑아 비교
즉, 단순히 “하나 잘 맞는 것”만 보는 게 아니라, 같은 목표 normal mode shape에 대해 여러 다른 해가 나오는지, 그리고 PP가 그중 더 좋은 해를 잘 골라내는지를 확인하는 것
✅ Figure 6: 같은 목표 normal mode shape에 대해 여러 설계가 가능함
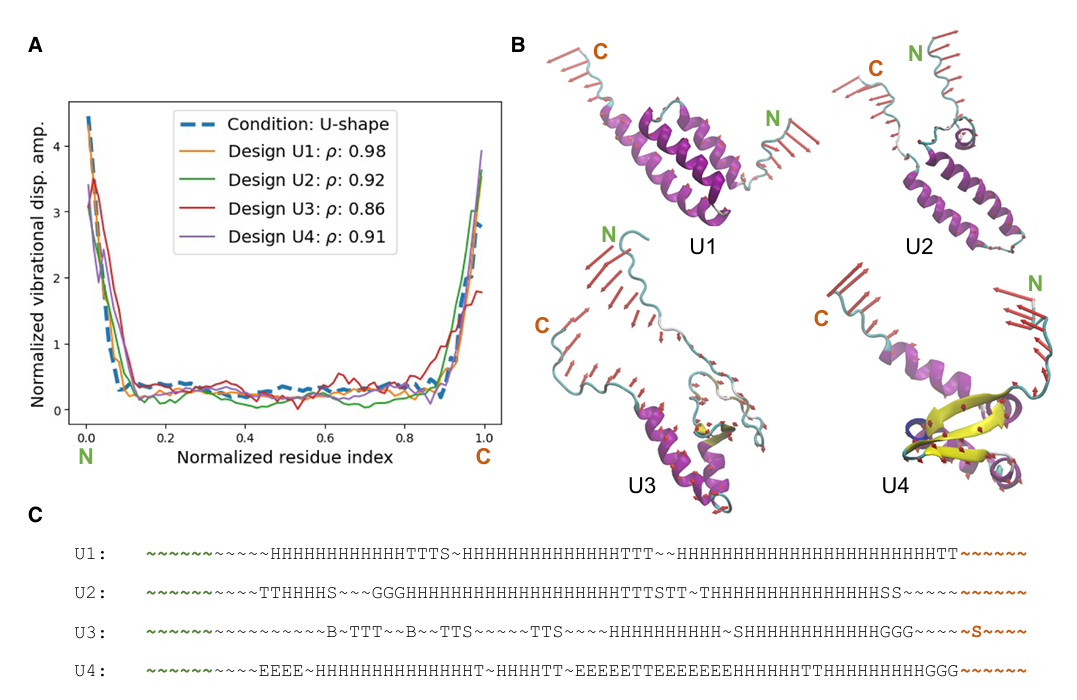
같은 입력 normal mode shape vector를 넣었을 때도 서로 다른 여러 단백질 설계가 나올 수 있음을 보여줌
- U-shape target
U-shape normal mode vector를 목표로 넣음
이때 PD가 만든 40개 후보 중 PP 기준 상위 4개가 U1, U2, U3, U4
이 네 설계의 measured normal mode shape가 condition을 잘 따른다고 보여줌
상관계수 𝜌
U1: ρ = 0.98
U2: ρ = 0.92
U3: ρ = 0.86
U4: ρ = 0.91
즉 네 개 모두 정확도가 높다는 뜻
구조적으로 무엇이 비슷한가
이 네 단백질은 모두 가운데는 비교적 compact core,
그리고 양쪽 끝은 바깥으로 열린 두 말단(open ends) 을 가짐
이것은 U-shape 목표 자체가 양 끝 진동은 크고, 가운데 진동은 작아야 하는 패턴이기 때문에 그에 맞는 구조적 공통점이라고 논문은 해석
secondary structure 수준에서 무엇이 비슷한가
Figure 6C: N-terminal과 C-terminal 근처는 대체로 unstructured coil이 공유됨
논문은 이를 각각 초록색, 빨간색으로 강조했다고 설명
즉, 양 끝이 잘 흔들리려면 덜 구속된 coil 형태가 자주 등장한다는 뜻
무엇이 다른가
반면 가운데 compact core는 다양
U1, U2: 주로 alpha-helix bundle
U3, U4: alpha-helix + beta-sheet 혼합
즉, 핵심 진동 패턴은 같아도 중심부 구조는 여러 방식으로 구현 가능하다는 것
서열 수준에서는 어떤가
논문은 U1–U4의 아미노산 서열(Table 2에 수록됨)도
양끝 근처에서는 어느 정도 비슷하고,
가운데 부분에서는 다양성이 유지된다고 해석
쉽게 말하면,
U-shape처럼 “양끝이 많이 움직이고 가운데는 덜 움직이는” 목표를 만족하려면
양끝은 비슷한 해법(느슨한 coil)이 자주 필요하지만,
가운데는 여러 가지 구조적 해법이 가능하다는 것
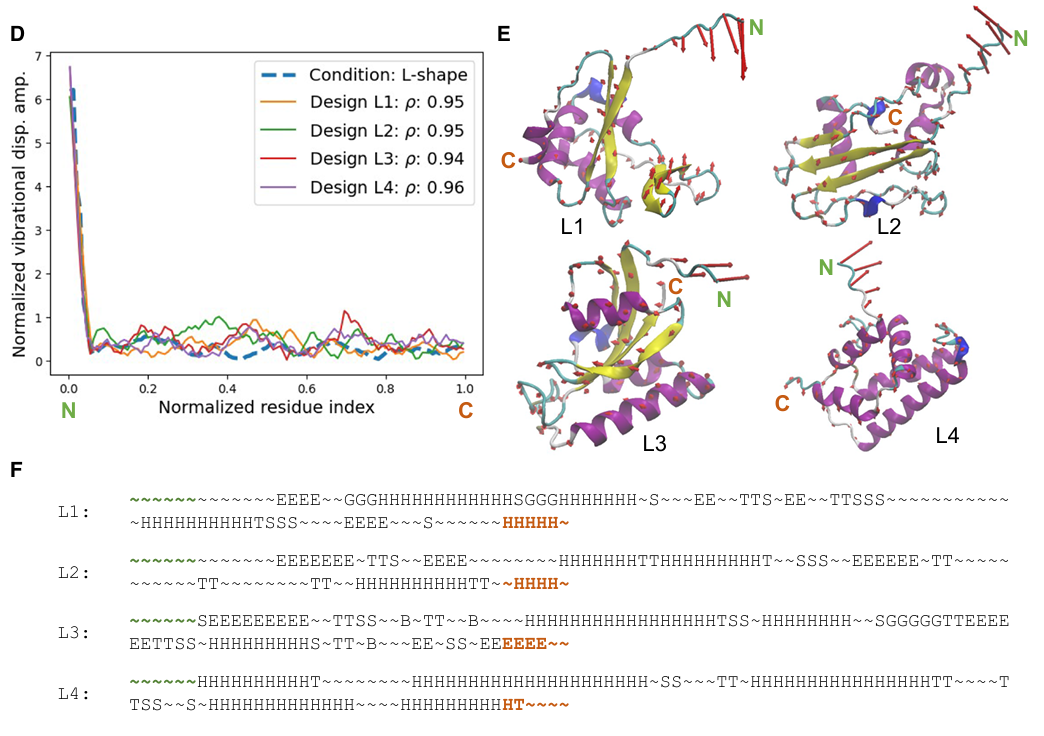
- L-shape target
각 설계의 𝜌
L1: ρ = 0.95
L2: ρ = 0.95
L3: ρ = 0.94
L4: ρ = 0.96
구조적으로 어떤 공통점이 있는가
Figure 6E, 6F를 보면 이들도 특정 부위에서는 비슷하고 특정 부위에서는 다름
U-shape 때와 비슷하게, 목표 진동 profile을 만족시키는 데 필요한 부위들은 유사한 구조 경향을 보이지만, 나머지 부위에서는 여러 가지 다른 구조 조합이 나온다고 설명
secondary structure 그림에서 강조하는 점
Figure 6F: 1D secondary structure sequence를 보면, 일부 위치에서 공통적인 helix/coil 패턴이 있지만, 중간중간 다른 구조 선택도 많음
즉 같은 L-shape 진동을 만족하는 구조적 자유도가 여전히 존재한다는 뜻
- 진동이 큰 부위는 구조적 선택지가 적다
backbone에서 상대적으로 높고 집중된 vibration amplitude를 만들려면,
대체로 less confined coil 또는 turn이 필요
즉, 너무 단단하게 묶인 2차 구조보다는 느슨한 구조가 유리
- 진동이 억제된 부위는 구조적 선택지가 많다
반대로 진동이 억제되어야 하는 부위는
alpha-helix, beta-sheet, 혹은 그 혼합 형태 등 다양한 confined secondary structure로 구현 가능
즉 이쪽은 설계 자유도가 더 큼
따라서 normal mode shape 기반 설계의 다양성은,
특히 “덜 흔들려야 하는 부위”에서 여러 구조 해법이 가능하기 때문에 나옴
✅ Table 2: Figure 6에 나온 후보들의 BLAST 결과
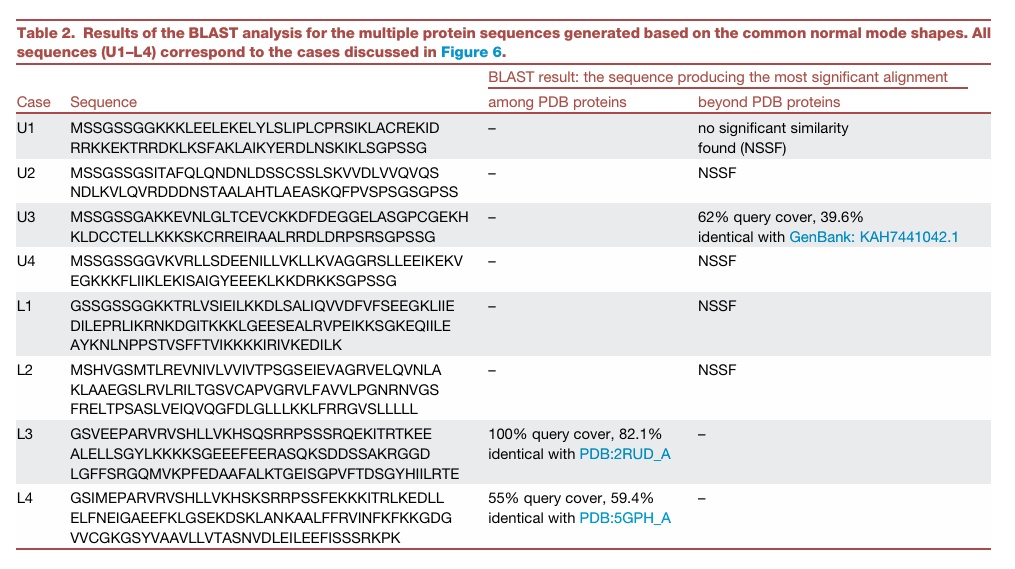
Table 2: Figure 6의 U1–U4, L1–L4에 대해 BLAST 분석 결과
“같은 normal mode shape를 만족하는 여러 설계들 중 상당수가 기존 단백질과 크게 닮지 않은 de novo일 수 있다”는 것
- U 계열
U1: NSSF → no significant similarity found, 즉 의미 있는 유사성이 발견되지 않음
U2: NSSF
U3: 62% query cover, 39.6% identical with GenBank: KAH7441042.1
→ 일부 유사성은 있지만 아주 높은 수준은 아님
U4: NSSF
즉 U-shape 설계 4개 중 3개(U1, U2, U4)는 기존 단백질과 유의미한 유사성이 없고, U3만 제한적인 유사성이 있음
- L 계열
L1: NSSF
L2: NSSF
L3: 100% query cover, 82.1% identical with PDB: 2RUD_A
→ 기존 PDB 단백질과 꽤 유사
L4: 55% query cover, 59.4% identical with PDB: 5GPH_A
→ 부분적 유사성이 있음
즉 L-shape 설계는
L1, L2는 de novo에 가깝고,
L3, L4는 기존 단백질과 어느 정도 유사성을 가짐
✅ Figure 7: PP가 정말 좋은 후보를 골라내는가
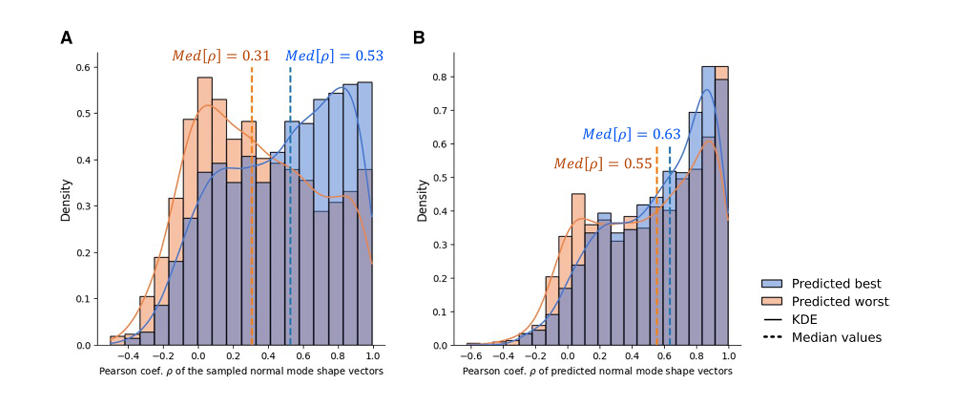
다양성뿐 아니라 정확도 향상에도 PP가 실제로 기여하는지
PD가 만든 40개 후보를 PP가 점수화한 뒤,
- predicted best group
- predicted worst group
으로 나누고, 두 그룹을 비교
Figure 7A: 실제 설계 정확도 비교
각 그룹의 실제 design accuracy를 보여 줌
평가 척도는 sampled normal mode shape vectors의 Pearson coefficient
중앙값(median)
predicted best group(파란색): Med[ρ] = 0.53
predicted worst group(주황색/빨간색): Med[ρ] = 0.31
즉, PP가 좋다고 고른 그룹이 실제로도 더 잘 맞음
-> predicted best group이 predicted worst group을 clearly outperforms 함
쉽게 말하면,
PP가 “이게 더 목표 진동에 맞을 것 같아”라고 고른 애들이
실제로도 더 잘 맞았다는 뜻
Figure 7B: PP 자신의 예측 정확도 비교
PP 자체의 예측 정확도를 두 그룹에서 비교
척도는 Pearson coefficient
중앙값
predicted best group: Med[ρ] = 0.63
predicted worst group: Med[ρ] = 0.55
두 그룹 차이는 Figure 7A 만큼 크지는 않음
하지만 중요한 건, PP가 집단 수준(collective scale)에서는 제대로 구분해낸다는 점
즉, PP는 개별 후보 하나하나를 완벽하게 정밀 순위 매기는 도구라기보다는,
좋은 쪽과 나쁜 쪽을 크게 가르는 내부 평가기로서는 충분히 유용하다는 뜻
Figure 7 해석
- PP를 설계 과정에 통합하는 것이 필수적이다
best와 worst 그룹 사이에 분명한 gap이 있고, 두 그룹 모두 같은 PD에서 생성된 후보들이기 때문에,
design 과정 안에 PP를 넣어야 설계 정확도를 개선할 수 있다고 말함
즉, PD만으로 후보를 많이 만드는 것보다, PP로 내부 평가를 해주는 것이 중요
- PP는 비싼 physics-based test를 줄여준다
PP는 protein sequence에 대해 normal mode shape를 예측할 수 있으므로,
비싼 physics-based validation(MD/NMA 등)를 모든 후보에 돌리지 않아도 됨
먼저 PP가 내부 evaluator처럼 후보를 순위화하고, 그 뒤 상위 후보만 물리 계산으로 검증하면 됨
✅ Results의 핵심 결론
- 같은 target mode를 만족하는 서로 다른 sequence와 fold가 많다
실험 결과를 보면 같은 target mode를 만족하는 sequence와 fold가 많다고 말함
이것은 functional degeneracy의 한 형태로 볼 수 있음
즉, 하나의 target profile은 사실 여러 개의 허용 가능한 해(families of solutions)를 정의한다는 뜻
즉, 같은 기능적 움직임을 실현하는 구조는 하나가 아니고,
sequence-structure space 안에는 그 움직임을 낼 수 있는 여러 “정답 무리”가 있음
그래서 설계 문제는 one-to-one이 아니라 many-to-one mapping에 가까움
구조보다 움직임을 기준으로 family를 정의할 수 있다
같은 기능적 움직임을 내는 단백질 family는, fold나 sequence가 달라도 성립할 수 있다.
이게 이 논문의 가장 큰 메시지 중 하나
- 왜 이런 degeneracy가 생기나
effective elastic manifold
즉 backbone이 sequence-structure space 상의 어떤 유효한 탄성적 다양성 범위 안에 있으면,
구조나 서열이 꽤 달라도 비슷한 저주파 진동 응답을 낼 수 있다는 것
쉽게 말하면,
단백질이 완전히 똑같이 생기지 않아도
“탄성적으로 비슷하게 흔들릴 수 있는 범위” 안에만 들어오면
같은 진동 패턴을 만들 수 있다는 뜻
- 구조-진동 관계를 모델이 어떻게 포착했는가
low-frequency vibration mode를 보면, 진동이 큰 부위는 보통 덜 구속된 coil-like chain termini이고, 진동이 작은 부위는 더 구속된 secondary structure(α-helix, β-sheet)인 경우가 많음
high-amplitude segment를 만들기 위해 coil/turn이 쓰이고
low-amplitude backbone region을 만들기 위해 helix나 sheet가 쓰인다는 패턴이 반복됨
논문은 이것이 secondary structure motif, local flexibility, vibrational amplitude 사이의 관계를 모델이 잘 포착했음을 보여 준다고 해석
- 그래서 다양성은 어디서 나오나
논문은 진동이 작아야 하는 부위는 여러 구조적 선택지가 있으므로,
결국 다양성은 특히 그런 부분에서 많이 나온다고 봄
반대로 진동이 커야 하는 부위는 상대적으로 coil/turn처럼 제한된 선택이 필요해 비슷해지는 경향이 있다고 설명
- 단백질 동역학 실험과도 연결될 수 있다
low-frequency vibrational mode shape가
여러 실험적 probe와도 잘 맞을 수 있다고 말함
예를 들면,
NMR relaxation measurement / order parameter
→ residue 수준의 진폭과 시간척도를 제공해서 이 논문의 mode shape vector와 대응될 수 있음
terahertz spectroscopy
→ 저주파 진동 density에 민감해서 complementary observable 제공
smFRET
→ 거리 변화, 구조 요동, conformational transition을 읽을 수 있어서, 저주파 normal mode의 특정 성분과 연결될 수 있음
즉, 이 논문의 “dynamics-informed design”은 완전히 계산 안에서만 노는 게 아니라,
나중에 실험적 동역학 데이터와도 자연스럽게 연결될 여지가 있다는 뜻
✅ Discussion
- interactive한 dual-component protein language diffusion framework를 만듦
하나는 forward 방향의 모델
하나는 inverse 방향의 모델
로 이루어져 있고,
이 둘이 sequence generation과 vibrational dynamics prediction을 연결해서 de novo protein design을 가능하게 했음
특히 inverse design model이 지정된 normal mode of vibration을 조건으로 sequence를 생성하고, 이후 후보들을 dynamic fidelity 기준으로 엄격히 걸러냄으로써, 기존의 정적 구조 중심 설계(static design paradigm)보다 정확도, 다양성, novelty를 크게 높였다고 주장
- PP를 두 번째 agent로 넣은 agentic two-step 또는 multi-step workflow가 중요하다고 강조
PP가 target shape에서 벗어나는 설계를 걸러 주기 때문에, 평균 correlation coefficient가 올라가고, 이것이 최종 설계 성능이 robust하게 나온 주요 이유라고 말함
논문 표현대로 하면, PD는 생성 과정 자체에 stochasticity가 있지만, PP가 그 확률적 흔들림을 보정해 주면서 generation과 validation을 반복하는 agentic approach를 이루게 됨
이 연구가 biological meaning 측면에서 갖는 의미
이 generative agentic model로 설계된 de novo protein이 단순히 fold만 되는 게 아니라 stable structure를 가지면서 동시에 backbone을 따라 targeted vibrational amplitude profile까지 재현한다는 점을 보여 줌
이것은 곧 sequence와 dynamic behavior 사이의 direct, end-to-end linkage를 세웠다는 뜻이고, 원하는 기능적 동역학을 가진 단백질을 설계하는 강력한 길을 제공한다고 해석
그리고 이 연구는 최근의 static structure prediction과 generative design의 발전을 보완한다고 말함
즉, 구조 중심의 발전 위에 dynamics라는 차원을 추가해서, 단백질 기능을 더 완전하게 이해하는 방향으로 나아간다는 것
여기서 핵심 메시지는, 단백질 기능에는 structure뿐 아니라 dynamics가 본질적이라는 점
하나의 normal mode shape에 대해 왜 여러 해가 나오는가
하나의 normal mode shape만 target으로 줄 때도 서로 primary sequence가 많이 다른 여러 top candidate가 비슷한 정확도로 같은 target profile에 수렴하는 경우가 많다고 말함
이것은 single vibration shape를 설계한다고 해서 backbone geometry가 하나로 고정되는 것은 아님을 뜻함
다시 말해, sequence space에는 큰 degeneracy가 있다는 것
즉, low-frequency normal mode alone으로는 unique sequence나 unique fold를 정할 수 없고, 대신 family of viable solutions에 대응한다고 해석
secondary structure와 vibrational amplitude의 관계에 대한 해석
모델이 secondary structure element를 이용해 local flexibility를 조절하는 것처럼 보인다고 말함
구체적으로는
alpha-helix는 local vibrational amplitude를 억제(suppress)하는 데 자주 쓰이고
beta-sheet + interspersed coil은 더 많은 internal peak를 만드는 데 기여하는 것처럼 보임
이것은 모델이 backbone의 H-bond pattern과 vibrational amplitude 사이의 기본 관계를 어느 정도 “이해”하고 있다는 증거처럼 보인다고 논문은 해석
즉,
alpha helix / beta sheet / coil 같은 structural motif와
low vs. high vibrational amplitude 같은 dynamic pattern 사이에
중요한 연결이 있다는 것
쉽게 말하면,
단단하게 묶인 helix/sheet는 덜 흔들리고
느슨한 coil은 더 잘 흔들린다
는 기본 물리 원리를 모델이 활용하고 있다는 뜻
✅ Method
✅ NMA of PDB protein models in MD
PDB 단백질에 대해 MD 안에서 NMA를 어떻게 했는지 설명
PDB에서 protein structure를 다운로드한 뒤,
atomic structure를 cleaning, separating, completing 해서 개별 polypeptide chain을 만듦
사용 도구는
- VMD (Visual Molecular Dynamics)
- MMTSB tools
- SCWRL4
그 다음 단백질 chain 구조를 CHARMM19 all-atom energy function과 implicit solvent water model을 사용해 energy minimization으로 relaxation
NMA 전에
- 10,000 steps steepest descent
- 이어서 10,000 steps adopted basis Newton–Raphson
으로 추가 relaxation
그리고 NMA는 효율을 위해 CHARMM의 Block Normal Mode (BNM) method를 사용하고, 관심 있는 normal mode의 eigenvalue와 eigenvector를 저장
쉽게 말하면,
- PDB 구조를 정리하고
- 원자 수준 에너지 최소화로 안정화한 뒤
- CHARMM에서 NMA를 돌려 normal mode를 뽑는 방식
✅ Dataset
각 protein case에 대해 핵심 정보는
- PDB ID
- protein sequence
- sequence length
- normal mode frequency
- normal mode shape vector
- 해당 normal mode에서 maximal vibrational displacement를 보이는 residue의 index
consistency와 computational feasibility를 위해 dataset은 현재 ≤126 aa의 monomeric protein chain으로 제한
✅ Design of the architectures of deep learning models and training
PD와 PP 구조
둘 다 protein language diffusion model이고, pretrained pLM + diffusion model 조합
이 중 trainable한 것은 diffusion model
pretrained pLM은 ESM-2 series의 150M parameter medium-sized pretrained model을 사용
diffusion model 쪽에서는, condition이 denoising 과정에 U-net의 multiple channel을 통해 들어감
예를 들면
denoising timestep의 partial input
middle result와의 concatenation
같은 방식
두 모델은 Adam optimizer로 각각 별도로 학습했고, setup은 이전 연구와 비슷
✅ Design accuracy evaluation
Design accuracy evaluation
measured normal mode shape vector와 input design condition을 비교하기 위해 여러 metric을 사용
개별 design과 whole test set 둘 다에 적용
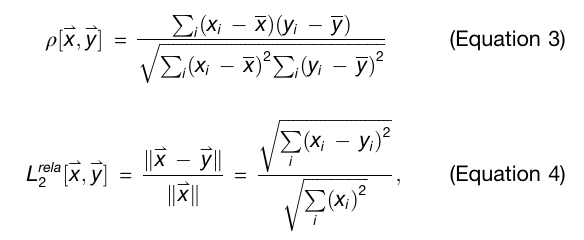
Equation 3: Pearson coefficient
벡터 𝑥와 𝑦에 대해 Pearson coefficient 𝜌[x,y]는 표준 상관계수 정의를 씀
즉, 각 성분 평균을 뺀 뒤 공분산을 표준편차 곱으로 나눈 형태
쉽게 말해, 두 벡터 모양이 얼마나 비슷한 추세를 가지는지를 보는 값
Equation 4: relative L2 error
예측 벡터가 정답 벡터에서 얼마나 떨어졌는지를 정답 벡터 크기로 정규화한 값
작을수록 좋음
x: ground truth 또는 input vector
y: prediction 또는 comparison 대상

Equation 5: scalar에 대한 relative L1 difference
normal mode frequency 같은 scalar에는 relative L1 difference를 씀
x는 reference, y는 predicted/compared value
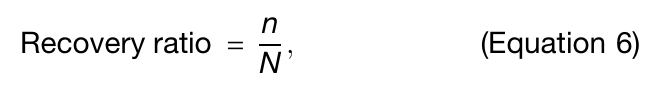
Equation 6: recovery ratio
generated sequence와 input normal mode를 제공한 known sequence를 비교하기 위해 recovery ratio를 정의
n: generated sequence와 known sequence에서 amino acid type이 같은 residue 수
N: sequence length
값 범위는 0~1
즉, 원래 sequence를 얼마나 많이 재현했는가를 보는 척도
낮을수록 더 de novo에 가깝게 볼 수 있음
BLAST analysis
various case에 대해 blastp (protein-protein BLAST) 알고리즘과 nr(non-redundant protein sequence) database를 사용
즉, 생성한 protein sequence가 기존 protein과 얼마나 유사한지 보기 위해 표준적인 protein BLAST를 사용한 것
