DBSCAN(Density Based Clustering of Applications with Noise)
intro
DBSCAN은 앞서 살펴본 GMM와 같이 밀도 기반 군집화 알고리즘이다. 아래와 같은 데이터가 있다고 할 때, 이러한 데이터 분포는 K-Means나 GMM으로도 정확한 군집화가 어렵다.
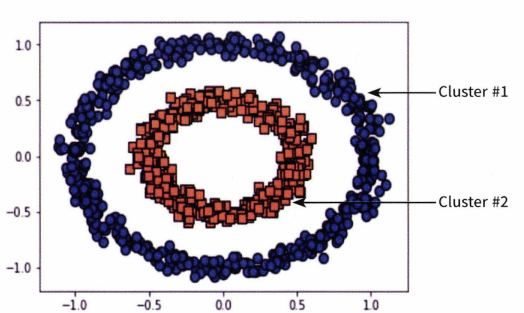
이 때 사용할 수 있는 알고리즘이 바로 DBSCAN이다.
동작 방법
DBSCAN에서 가장 중요한 하이퍼파라미터는 입실론과 최소 데이터 개수이다.
- 입실론 주변 영역 : 개별 데이터를 중심으로 입실론 반경을 가질 영역
- 최소 데이터 개수 : 입실론 반경 안에 포함되어야 하는 데이터 개수
입실론과 최소 데이터 개수로 군집화를 하는 방법을 소개하기 전, DBSCAN에서 사용하는 용어에 대해 소개하려 한다.
- 핵심 포인트 : 주변 영역 안에 최소 데이터 개수 이상의 데이터를 가진 데이터
- 이웃 포인트 : 주변 영역 안에 위치한 데이터
- 경계 포인트 : 최소 데이터 개수 이상의 데이터를 갖지 못하지만, 주변 영역에 핵심 포인트를 갖는 데이터
- 잡음 포인트 : 최소 데이터 개수 이상의 데이터도 갖지 못하고, 주변 영역에 핵심 포인트도 없는 데이터
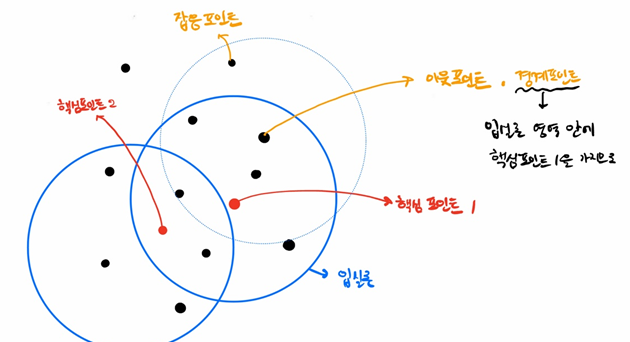
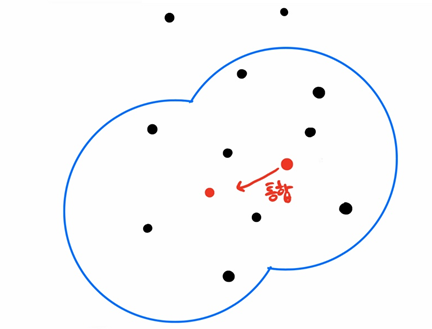 최소 데이터 개수가 5개라고 가정하고 위 그림을 보자. 데이터를 하나하나 돌며 엡실론 영역과 최소 데이터 개수를 확인하는데, 핵십포인트 1과 핵심포인트 2는 모두 기준을 만족한다. 인접한 핵심포인트를 통합하여 하나의 군집으로 만드는 과정을 반복한다.
최소 데이터 개수가 5개라고 가정하고 위 그림을 보자. 데이터를 하나하나 돌며 엡실론 영역과 최소 데이터 개수를 확인하는데, 핵십포인트 1과 핵심포인트 2는 모두 기준을 만족한다. 인접한 핵심포인트를 통합하여 하나의 군집으로 만드는 과정을 반복한다.
DBSCAN의 사용
DBSCAN도 다른 군집화 모델과 같이 sklearn.cluster 모듈에 구현되어있다.
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.8, min_samples=5)
dbscan.fit(data)엡실론 값은 보통 1 이하의 수로 설정한다고 한다. 예측 결과는 다른 군집화 알고리즘과 달리 -1이 나올 수 있다. -1은 잡음 포인트로 분류된 데이터이다.
 ↑ 결과 예시
↑ 결과 예시
