01. Grouping Sets
01-01. 개요 및 샘플 데이터 생성
DROP TABLE IF EXISTS sales;
CREATE TABLE sales (
brand VARCHAR NOT NULL,
segment VARCHAR NOT NULL,
quantity INT NOT NULL,
PRIMARY KEY (brand, segment)
);
INSERT INTO sales (brand, segment, quantity)
VALUES
('ABC', 'Premium', 100),
('ABC', 'Basic', 200),
('XYZ', 'Premium', 100),
('XYZ', 'Basic', 300);
GROUPING SETS는 특정 항목에 대한 소계를 나타내준다. 기준으로 제시한 컬럼들로 조합할 수 있는 모든 경우의 조합으로 데이터를 조회한다. 두 개의 컬럼을 기준으로 그룹화 한다면, GROUPING SETS의 결과는 아래와 같다.
(기준1, 기준2)
(기준1, NULL)
(기준2, NULL)
(NULL, NULL)
기준으로 제시되는 컬럼들은 GROUP BY절 하위에 각 컬럼별로 ()를 사용하여 묶어서 사용한다.
01-02. 예제
GROUPING SETS 키워드를 사용하지 않고 구현해보자. 그룹화한 데이터를 UNION ALL로 결합할 것이다.
UNION ALL을 사용할 때에는 결합하려는 테이블들이 동일한 컬럼을 가지고 있어야하므로 SELECT 절에 NULL을 함께 넣어줄 것이다.
-- GROUPING SETS를 사용하지 않고 구현해보기
SELECT
brand,
segment,
SUM (quantity)
FROM
sales
GROUP BY
brand,
segment
UNION ALL
SELECT
brand,
NULL,
SUM (quantity)
FROM
sales
GROUP BY
brand
UNION ALL
SELECT
NULL,
segment,
SUM (quantity)
FROM
sales
GROUP BY
segment
UNION ALL
SELECT
NULL,
NULL,
SUM (quantity)
FROM
sales;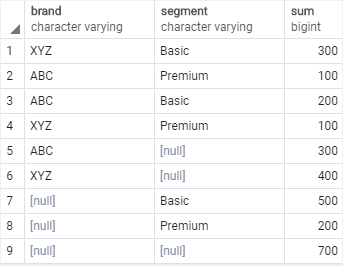
이 형태가 우리가 구하고 싶었던 GROUPING SETS의 결과이다.
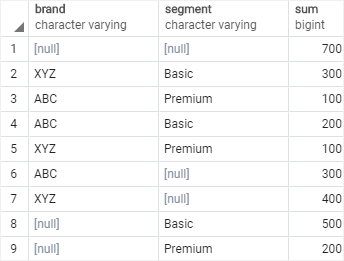
이번에는 GROUPING SETS을 사용해보자.
--GROUPING SETS 사용
SELECT
brand,
segment,
SUM (quantity)
FROM
sales
GROUP BY
GROUPING SETS (
(brand, segment),
(brand),
(segment),
() -- 두 기준 모두 NULL인 경우
);
GROUPING SETS를 사용하지 않고도 구현할 수 있는데 이 키워드는 왜 있을까? GROUPING SETS를 사용하지 않았을 때의 문제점은 아래와 같다.
- 코드가 너무 길어져 읽기가 어렵다.
- 쿼리를 여러 번 진행 후에 합치는 형식이기 때문에 테이블을 불필요하게 여러 번 스캔해야 한다. 이는 곧 성능 저하 문제를 가져온다.
상기 이유로 소계를 확인하고 싶을 때 GROUPING SETS를 사용하는 것이다.
01-03. Grouping function
GROUPING()이라는 함수가 있다. GROUPING SETS를 사용할 때 어떤 컬럼을 그룹화 기준으로 사용했는지 나타내준다. (기준에 속하면 0, 속하지 않으면 1)
중요한 것은 GROUPING() 함수의 인자는 반드시 GROUP BY절에 지정된 것과 일치해야 한다는 것이다.
-- GROUPING() 함수 사용해보기
SELECT
GROUPING(brand) grouping_brand,
GROUPING(segment) grouping_segment,
brand,
segment,
SUM (quantity)
FROM
sales
GROUP BY
GROUPING SETS (
(brand),
(segment),
()
)
ORDER BY
brand,
segment;
위와 같이 소계 기준에 부합되는 경우에는 0, 아닌 경우에는 1을 반환한다.
GROUPING() 함수를 HAVING절 안에 사용하여 특정 그룹만 조회할 수 있다.
SELECT
GROUPING(brand) grouping_brand,
GROUPING(segment) grouping_segment,
brand,
segment,
SUM (quantity)
FROM
sales
GROUP BY
GROUPING SETS (
(brand),
(segment),
()
)
HAVING GROUPING(brand) = 0
ORDER BY
brand,
segment;
02. Cube
02-01. 개요
PostgreSQL CUBE는 GROUP BY절의 하위 절이다. 위에서 본 GROUPING SETS는 각 그룹별로 소계를 확인하기에 좋지만, 각 경우의 수를 직접 다 지정해줘야하는 번거로움이 있다. CUBE를 사용하여 모든 경우의 수를 반환할 수 있다. 마찬가지로 GROUPP BY 하위에 사용된다.
...
GROUP BY
GROUPING SETS (
(c1,c2,c3), (c1,c2), (c1,c3), (c2,c3), (c1), (c2), (c3), ()
)
...위 구문은 CUBE를 사용하여 줄일 수 있다.
...
GROUP BY
CUBE(c1, c2, c3)
...
CUBE는 부분적으로도 사용 가능하다. 아래 예시를 통해 확인해보자.
02-02. 예제
아래와 같은 테이블을 샘플로 사용해보자.
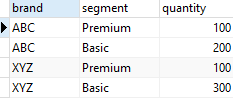
-- CUBE 사용해보기
SELECT
brand,
segment,
SUM (quantity)
FROM
sales
GROUP BY
CUBE (brand, segment)
ORDER BY
brand,
segment;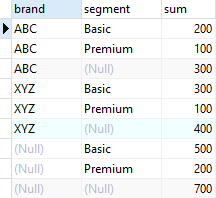
-- 부분 CUBE 사용해보기
SELECT
brand,
segment,
SUM (quantity)
FROM
sales
GROUP BY
brand,
CUBE (segment)
ORDER BY
brand,
segment;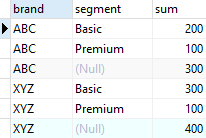 brand컬럼은 CUBE로 지정하지 않았다. CUBE로 지정한 segment에 대해서만 모든 경우를 반환하여 데이터를 조회한다.
brand컬럼은 CUBE로 지정하지 않았다. CUBE로 지정한 segment에 대해서만 모든 경우를 반환하여 데이터를 조회한다.
03. ROLLUP
03-01. 개요
위에서 살펴본 CUBE는 모든 조합으로 데이터를 조회한다. 그에 반해 ROLL UP은 컬럼을 계층구조로 이해하고 조합을 만든다.
예를 들어, CUBE (c1,c2,c3)은 가능한 모든 조합을 전부 반환하므로 8개의 조합이나 된다.
(c1, c2, c3)
(c1, c2)
(c2, c3)
(c1,c3)
(c1)
(c2)
(c3)
()하지만, ROLLUP(c1,c2,c3)은 계층 구조가 c1 > c2 > c3과 같다고 가정하여 4개의 조합만 생성한다.
(c1, c2, c3)
(c1, c2)
(c1)
()ROLLUP는 일반적으로 년 > 월 > 일의 계층 구조를 고려하여 연, 월, 날짜별로 데이터를 집계하는 것이다.
CUBE와 마찬가지로 부분적으로만 수행할 수도 있다.
03-02. 예제
아래 테이블을 사용해보자.
--ROLLUP 사용하기
SELECT
brand,
segment,
SUM (quantity)
FROM
sales
GROUP BY
ROLLUP (brand, segment)
ORDER BY
brand,
segment;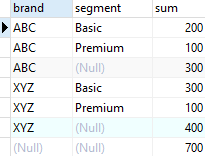
위 결과를 확인해보면 brand > segment를 계층으로 지정한 것으로 볼 수 있다. 지정한 컬럼의 순서를 바꿔보자
-- ROLLUP 컬럼 순서 변경하기
SELECT
segment,
brand,
SUM (quantity)
FROM
sales
GROUP BY
ROLLUP (segment, brand)
ORDER BY
segment,
brand;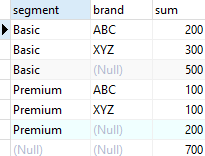
첫 번째 예제와 결과가 확연히 달라진 것을 확인할 수 있다.
-- 부분 ROLLUP 사용하기
SELECT
segment,
brand,
SUM (quantity)
FROM
sales
GROUP BY
segment,
ROLLUP (brand)
ORDER BY
segment,
brand;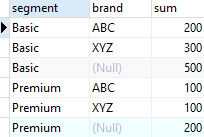
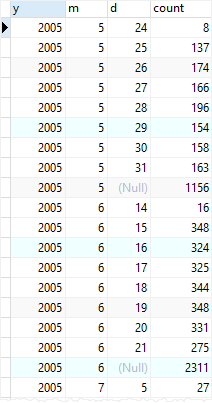
연, 월, 일 순으로 데이터를 조회하는 예를 확인해보자. rental 테이블에는 날짜 데이터가 있다.
-- ROLLUP 사용하여 날짜 데이터 확인하기
SELECT
EXTRACT (YEAR FROM rental_date) y,
EXTRACT (MONTH FROM rental_date) M,
EXTRACT (DAY FROM rental_date) d,
COUNT (rental_id)
FROM
rental
GROUP BY
ROLLUP (
EXTRACT (YEAR FROM rental_date),
EXTRACT (MONTH FROM rental_date),
EXTRACT (DAY FROM rental_date)
);