01. Subquery
01-01. 개요와 예제
서브쿼리를 이해하기 위해 아래 예시를 먼저 살펴보자.
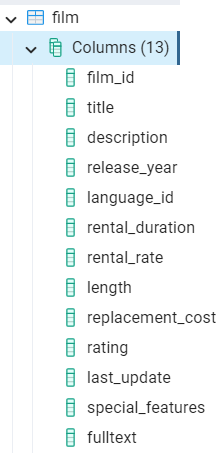 flim 테이블의 스키마
flim 테이블의 스키마
flim 테이블에서 rental_rate가 평균보다 높은 데이터를 찾는 업무가 있다고 해보자. 해당 업무를 수행하기 위해서는 아래 두 단계를 거쳐야한다.
[ subquery 를 사용하지 않고 데이터 조회하기 ]
1. AVG 함수를 사용해서 rental_rate의 평균을 구하기
2. WHERE절에서 평균 rental_rate를 조건으로써 제시하기
-- 평균 rental_rate 구하기
SELECT
AVG (rental_rate)
FROM
film;
-- 평균 rental_rate를 조건으로 제시하기
SELECT
film_id,
title,
rental_rate
FROM
film
WHERE
rental_rate > 2.98;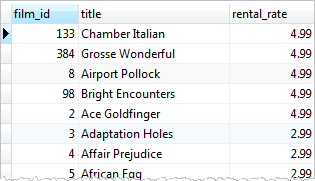
위와 같은 방법으로 평균 rental_rate보다 큰 데이터를 조회했다. 그런데 이 두 단계를 하나로 합칠 수는 없을까? 이 때 사용할 수 있는 것이 subquery이다.(앞으로 서브쿼리라고 부르겠다.)
서브쿼리는 SELECT, INSERT, DELETE, UPDATE와 같이 다른 쿼리 내에 중첩된 쿼리를 의미한다. 서브쿼리를 만들기 위해서는 두 번째 쿼리를 괄호로 묶고 WHERE절에 사용한다.
-- 서브쿼리를 사용하여 동일한 결과 확인하기
SELECT
film_id,
title,
rental_rate
FROM
film
WHERE
rental_rate > (
SELECT
AVG (rental_rate)
FROM
film
);서브쿼리는 inner query라고도한다. 서브쿼리를 포함하고 있는 쿼리는 outer query라고 한다.
서브쿼리가 있을 때 쿼리의 순서는 다음과 같다.
[ 서브쿼리가 있을 때 쿼리 수행 순서 ]
1. 먼저, 서브쿼리를 실행한다.
2. 서브쿼리 결과를 가져와 outer query에 전달한다.
3. outer query를 실행한다.
02. IN 연산자
02-01. 개요와 예제
서브쿼리는 앞서 살펴본 예시와 달리 2개 이상의 값도 사용할 수 있다. 이 때 IN 연산자와 함께 사용한다.(Section 2에서 본 IN과 동일한 논리이다.)
 ↑ inventory 테이블
↑ inventory 테이블
 ↑ rental 테이블
↑ rental 테이블
예를 들어 inventory 테이블에서 날짜가 '2005-05-29'와 사이 '2005-05-30'인 film_id를 조회해보자.
-- 서브쿼리 결과가 여러 개의 row를 반환하는 경우
SELECT
film_id
FROM
film
WHERE
film_id IN (
SELECT
inventory.film_id
FROM
rental
INNER JOIN inventory ON inventory.inventory_id = rental.inventory_id
WHERE
return_date BETWEEN '2005-05-29'
AND '2005-05-30'
)
ORDER BY film_id;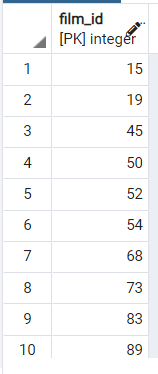 위 쿼리를 해석해보면 아래와 같다
위 쿼리를 해석해보면 아래와 같다
- inventory 테이블과 rental 테이블을 film_id를 key로 조인한다.
- return_date가 '2005-05-29'와 '2005-05-30' 사이인 데이터들의 film_id를 조회한다.
- 서브쿼리에서 조회한 film_id와 일치하는 film_id를 아우터쿼리에서 조회한다.
위 쿼리는 IN을 사용하는 예제를 만들기 위해 일부러 쿼리를 조금 복잡하게 짠 것 같다. 사실 아래와 같이 더 짧게 쿼리를 작성할 수 있다.
-- 더 짧게 쿼리 짜기
SELECT
inventory.film_id
FROM
rental
INNER JOIN inventory
ON rental.inventory_id = inventory.inventory_id
WHERE
rental.return_date BETWEEN '2005-05-29'
AND '2005-05-30'
ORDER BY
inventory.film_id;03. ANY
03-01. 개요와 예제
ANY연산자는 서브쿼리로 구한 데이터를 조건으로 제시되는데, 서브쿼리 결과 집합들과 비교 연산을 하여 한 개라도 조건에 부합하면 데이터를 조회한다.
만약 rental 테이블의 return_date가 '2005-05-29'와 '2005-05-30' 사이인 film_id들 중 가장 큰 film_id보다 작은 film_id 구하기 위해 아래 순서에 따라 쿼리를 나눠서 생각해보자.(= 해당 기간 안에 있는 film_id의 최대값보다 작은 데이터 조회)
- 해당 날짜 사이에 부합하는 film_id를 조회한다.
- ANY 연산자를 사용하기
-- 1. 날짜 안에 있는 film_id 조회하기
SELECT
inventory.film_id
FROM
rental
INNER JOIN inventory
on inventory.inventory_id = rental.inventory_id
WHERE
rental.return_date BETWEEN '2005-05-29'
AND '2005-05-30'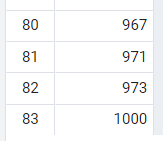
-- 2. ANY를 조건으로 사용하기(1번 쿼리를 서브쿼리로 사용)
SELECT film_id
FROM film
WHERE film_id <= ANY(
SELECT
inventory.film_id
FROM
rental
INNER JOIN inventory
on inventory.inventory_id = rental.inventory_id
WHERE
rental.return_date BETWEEN '2005-05-29'
AND '2005-05-30'
);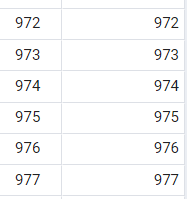
설명을 위해 쿼리 결과 중간을 캡쳐했다. 위 쿼리는 어떻게 동작했을까?
ANY는 서브쿼리 결과 집합에서 한 조건이라도 만족하면 true를 반환한다.
서브쿼리의 결과인 (..., 967, 971, 973, 1000)와 모든 film_id에 대해 비교연산을 진행한다. 서브쿼리 결과집합 데이터 중 하나라도 작은 값을 만족하면 조회되는 것이다.
예를 들어 아우터 쿼리의 결과 중 972는 967, 971보다 크지만, 973보다는 작다. 따라서 하나라도 큰 값이 있으므로 true를 반환하게 된다.
요약하자면, ANY 연산자는 서브쿼리 결과와 비교했을 때 하나라도 그 조건을 만족하면 반환하게 된다!(모든 조건이 OR로 연결된다고 생각하기)
ANY를 사용할 때에는 몇 가지 주의 사항이 있다.
- 서브쿼리는 예제와 같이 하나의 컬럼만 반환해야 한다.
- ANY를 사용할 때에는 비교연산자(=, <, > 등)을 함께 사용한다.
- ANY와 SOME은 동의어이다.
04. ALL
04-01. 개요와 예제
ANY를 이해했다면 ALL은 쉽다. ALl 연산자는 서브쿼리의 결과에 대한 조건을 모두 만족할 때 true를 반환한다.
예제로 볼 쿼리는 film 테이블을 사용해보자.

영화 등급별로 그룹화하고 그룹별로 영화 이름의 평균 길이를 조회한 후, 평균 길이가 최대보다 큰 film_id를 구해보자.
-- 1. 영화 등급별 영화 이름 평균 길이 반환
SELECT
ROUND(AVG(length), 2) avg_length
FROM
film
GROUP BY
rating
ORDER BY
avg_length DESC;
-- 2. 영화 이름 평균 길이 중 최대값 이상인 데이터 조회
SELECT
film_id,
title,
length
FROM
film
WHERE
length > ALL (
SELECT
ROUND(AVG (length),2)
FROM
film
GROUP BY
rating
)
ORDER BY
length;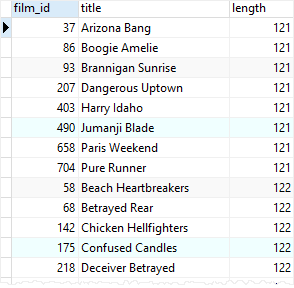
결과를 살펴보면, 서브쿼리의 결과 중 최대값인 120.44보다 길이가 긴 데이터만 조회했음을 볼 수 있다.
05. EXISTS
05-01. 개요와 예제
EXISTS는 말 그대로 해당 데이터가 서브쿼리 결과에 '존재하는지'를 확인하는 연산자이다. EXISTS에 대해 알아보기 위해서는 IN을 먼저 이해해야한다.
이번 예제에서 사용할 데이터는 아래와 같다.
 ↑ color 테이블
↑ color 테이블
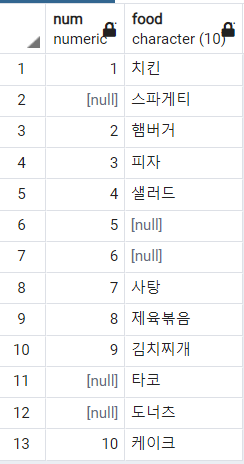 ↑ food 테이블
↑ food 테이블
앞서 살펴본 것처럼 IN 연산자는 WHERE절의 서브쿼리를 먼저 실행한 후 레코드를 하나씩 비교하면서 해당 레코드의 값이 서브쿼리 결과 집합에 있는지 확인한다.(ANY 연산자도 마찬가지)
-- IN 연산자
SELECT *
FROM food
WHERE food.num IN (
SELECT color.num
FROM color
);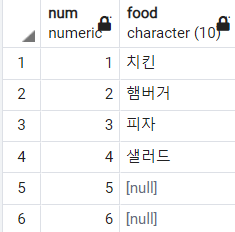 color 테이블에 num을 반환하고, 그 결과 집합 중에서 food의 num이 이에 해당되는 데이터만 조회 되었다.
color 테이블에 num을 반환하고, 그 결과 집합 중에서 food의 num이 이에 해당되는 데이터만 조회 되었다.
그렇다면 EXISTS는 어떻게 동작하는지 확인해보자.
-- EXISTS 연산자
SELECT *
FROM food
WHERE EXISTS (
SELECT color.num
FROM color
);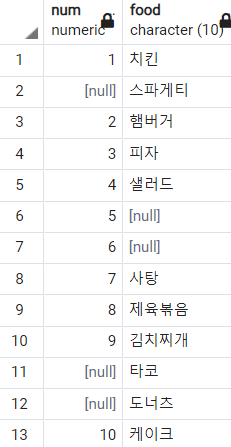 우리가 예상한 것과 다르게 나왔다!! 왜 이렇게 동작한 것일까?
우리가 예상한 것과 다르게 나왔다!! 왜 이렇게 동작한 것일까?
EXISTS는 그 동작이 IN과 반대이다. EXISTS는 테이블에 먼저 접근하여 하나의 레코드를 먼저 추출하고 그 레코드에 대하여 서브쿼리를 실행해 실행 결과가 '존재하면' true를, '존재하지 않으면' false를 반환한다.
이러한 관점에서 위 쿼리를 해석해보면, 예를 들어 (1, 치킨)에 먼저 접근한 후 서브쿼리를 본다. food 테이블과는 무관하게 서브쿼리 결과는 항상 어떤 결과가 있으므로
위의 EXISTS 쿼리를 바꿔보자.(1, 치킨)은 출력된다. (NULL, 스파게티), (2, 햄버거), ... 전부 선택되는 레코드와 상관 없이 항상 서브쿼리의 결과는 존재하기 때문에 모든 레코드가 출력된 것이다.
위 쿼리를 바꿔보자
-- EXISTS를 정확히 사용하기
SELECT *
FROM food
WHERE EXISTS (
SELECT color.num
FROM color
WHERE food.num = color.num
);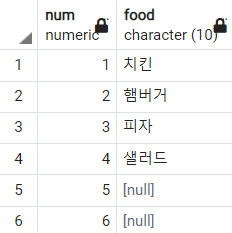
(6, NULL)까지는 잘 나오는 것을 볼 수 있다. 그렇다면 (7, 사탕)부터는 왜 조회가 되지 않은 것일까?
food 테이블에 먼저 접근해 (7, 사탕)을 선택하고, color 테이블과 join한다. 그 결과가 아무것도 반환되지 않으므로(color 테이블에는 num이 7인 레코드가 없다) (7, 사탕)에 대해서는 false가 반환되어 조회되지 않은 것이다.
05-02. NOT EXISTS
NOT EXISTS는 EXISTS와 반대이다. 한 레코드를 대상으로 서브쿼리 실행 결과가 하나라도 있으면 false, 하나도 없으면 true를 반환한다.
-- NOT EXISTS 예제
SELECT *
FROM food
WHERE EXISTS (
SELECT color.num
FROM color
WHERE food.num = color.num
);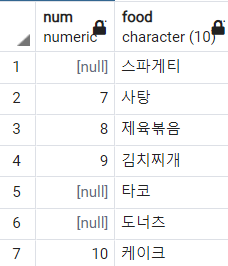
한 가지 의문이 생긴다. color 테이블에도 num이 NULL인 데이터가 있는데, 왜 NOT EXISTS에 나온 것일까? 다시 말해 왜 비교 쿼리 결과가 없다고 나올까?
그 이유는 NULL은 어떤 비교연산을 하더라도 그 결과가 UNKNOWN이 나오기 때문이다. 서브쿼리 결과가 UNKNOWN이기 때문에 그 결과는 없는 것으로 판단하기 때문에 NULL 값이 NOT EXISTS에는 나오는 것이다.
[ EXISTS 출처 ]
