[ 사용된 기술 및 패키지 ]
- python
- pandas / numpy
- folium
- haversine(좌표간 거리 구하는 패키지)
- K-Mneans 알고리즘
[ 담당 업무 ]
- 팀장
- 데이터 수집 및 처리
- 지도 시각화
- 결과 해석(지표 생성)
1. 프로젝트 개요
재활용 쓰레기가 제대로 처리되지 않고 막 버려지고 있는 현실에 문제의식을 느끼고 재활용 쓰레기를 잘 모을 수 있도록 재활용 쓰레기 회수 로봇의 최적의 설치 위치를 데이터를 기반으로 선정하고자 했다.
가정에서는 재활용을 잘 하고 있다는 가정 하에 길거리를 다니는 사람들을 위한 위치 선정에 포커스를 맞췄다. 따라서 유동인구를 위한 버스정류장 데이터와 쓰레기 생성 위치에 가중치를 주기 위한 점포 인허가 정보를 사용했다.
이 프로젝트는 나의 첫 프로젝트로 21년 6월부터 21년 8월까지 진행된 '양재 AI허브 AI 실무 개발자 양성 교육' 중 데이터분석 코스에서 진행한 데이터 분석 프로젝트이다.
2. 프로젝트 배경 및 문제 정의
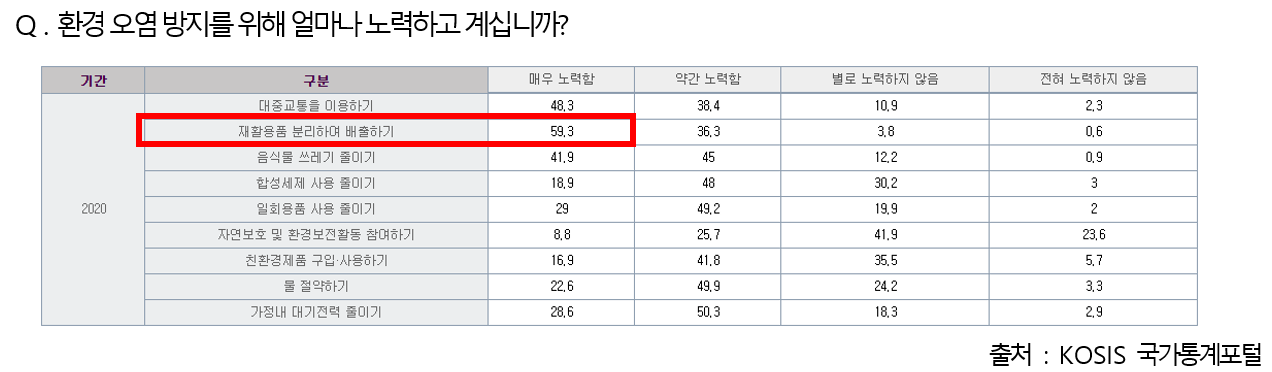 국가 통계 포털에 따르면 사람들은 환경 오염 방지를 위해 노력하는 일이 분리수거라고 답한 비율이 과반을 넘는다.
국가 통계 포털에 따르면 사람들은 환경 오염 방지를 위해 노력하는 일이 분리수거라고 답한 비율이 과반을 넘는다.
 위 사진처럼 길거리에 놓여있는 쓰레기 봉투에 음료수 캔, 플라스틱 용기 등의 재활용품들이 그냥 버려져 있거나 지자체에서 공공 쓰레기통을 운영하고 있지만 일반쓰레기통만 있어 재활용이 잘 되지 않는 모습을 쉽게 볼 수 있다.
위 사진처럼 길거리에 놓여있는 쓰레기 봉투에 음료수 캔, 플라스틱 용기 등의 재활용품들이 그냥 버려져 있거나 지자체에서 공공 쓰레기통을 운영하고 있지만 일반쓰레기통만 있어 재활용이 잘 되지 않는 모습을 쉽게 볼 수 있다.
환경 오염 방지를 위해 재활용에 힘쓰는 사람들과 길거리에 그냥 버려진 재활용 쓰레기, 이 둘의 연결 고리는 무엇일까? 우리는 이 문제를 재활용 쓰레기를 버릴 적절한 인프라가 구성되지 않았다고 생각했다. 위에서 본 설문에서 재활용에 대한 의지는 이미 확인했으므로 재활용 쓰레기를 버릴 수 있는 시설이 적절한 곳에 있다면 이런 문제는 해결될 것이라고 생각했다.
인공지능 재활용 쓰레기 회수 로봇은 당시에도 이미 수퍼빈에서 운영 중이었기 때문에 회수로봇을 만들기보다는 적절한 위치를 선정하는 것이 더 효율적이라고 생각하여 프로젝트 주제를 재활용 쓰레기 회수 로봇의 위치 선정으로 정했다.
3. 분석
우선 우리는 서울시 서대문구만을 타겟으로 결정했다. 그 이유는 처음부터 서울시 전체 혹은 전국을 대상으로 데이터를 분석할 경우 데이터의 특성을 충분히 파악하지 못한다고 판단했기 때문이고, 서대문구에는 여러 개의 대학이 있고, 홍대나 신촌 같이 큰 상권이 있는 곳이기 때문에 서대문구를 타겟으로 정했다.
3-1. 데이터 출처 및 선정 이유
데이터는 공공데이터를 사용했다. 서울 열린데이터 광장에서 휴게음식 판매 점포 인허가 정보 데이터, 버스정류장 위치 및 승하차 승객 수 데이터를 사용했다.
- 점포 인허가 정보 데이터
- 유동인구가 많더라도 쓰레기가 직접적으로 생길 수 있는 환경이 아니라면, 재활용 쓰레기는 나오지 않을 것이다. 따라서 길거리에 버려지는 재활용 쓰레기가 나오는 점포들의 데이터가 필요했다.
- 우리가 주목한 점포는 카페, 편의점, 페스트푸드 판매점 등이다.
- 버스 정류장 관련 데이터
- 유동인구에 대한 직접적인 데이터 사용에 제한이 있어 간접적으로나마 유동인구를 파악할 수 있는 버스 정류장 관련 데이터를 사용했다.
- 비슷한 데이터인 지하철역 정보도 함께 확인했었는데, 지하철 노선은 버스 노선보다 적기 때문에 결과가 지하철역 주변에 몰리는 현상이 발생했다. 따라서 지하철 데이터는 유동인구를 파악하는 데이터에서 제외했다.
우리는 점포 데이터와 버스 데이터 중 점포 데이터에 중점을 두기로 했다. 왜냐하면 아래 예시와 같이 주택 밀집 지역은 버스 승하차 인원은 많지만 실질적으로 재활용 쓰레기를 만드는 경우가 적다고 판단했기 때문이다.(빨간색 원은 아파트 단지를 표시한 것)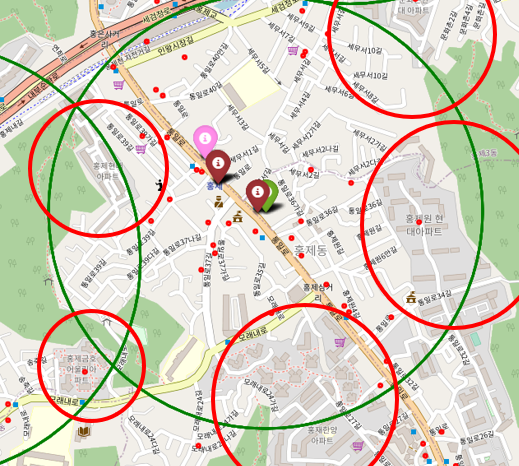
3-2. 주요 방법론
- 점포 데이터 : K-Means 알고리즘을 사용하여 점포들의 위치를 군집화했다. 최적의 군집 개수는 엘보우(elbow) 기법을 사용하여 선택했다.
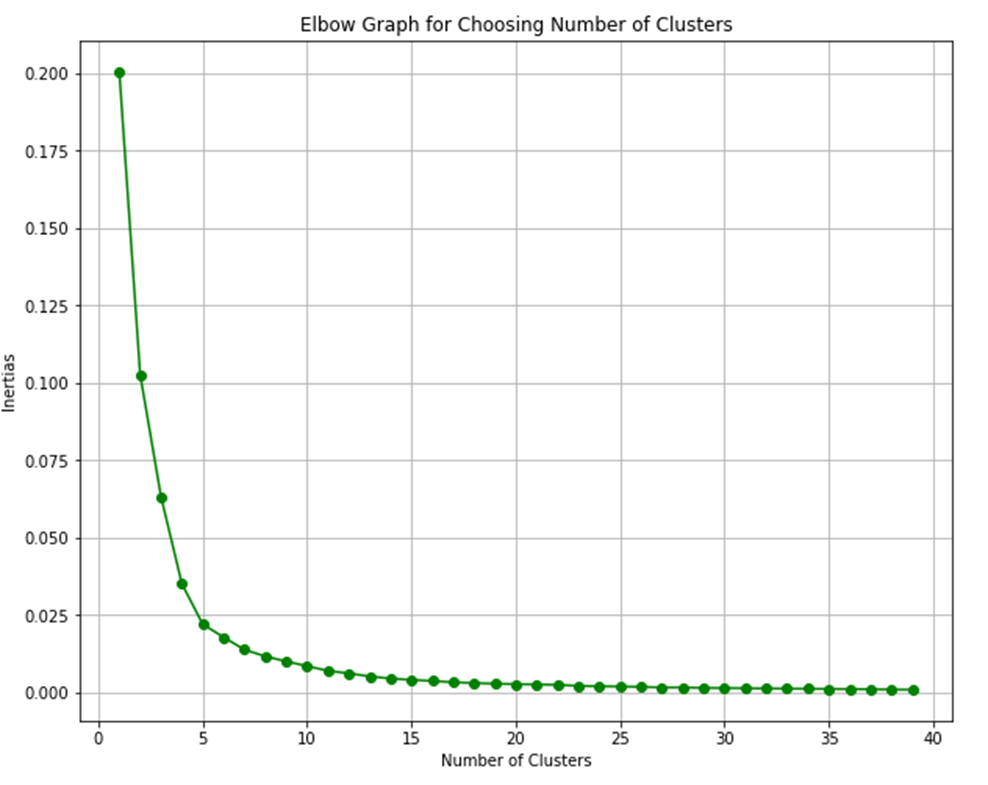
- 군집의 개수를 늘리며 이너셔(inertia)를 확인하여 최적의 군집 개수를 선택하는 방법이다. 이너셔는 군집 중심점에서 군집에 속한 데이터들의 거리 제곱 합이다. 이 방법으로 서대문구에 위치한 점포들의 군집 개수는 15개로 선택했다.
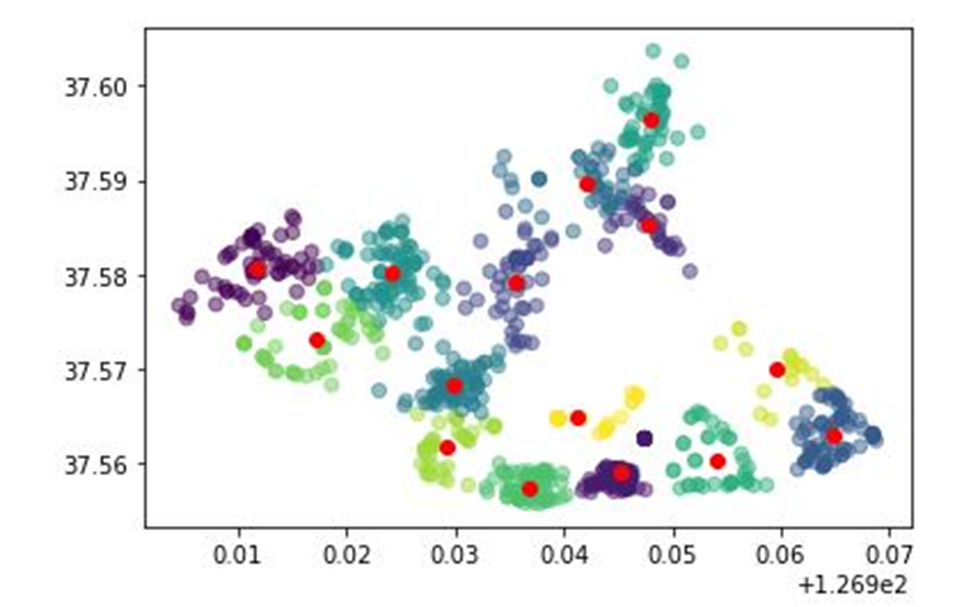
- 군집 내의 점포 개수를 카운팅하여 점수화했다. 클러스터 점수는 (점포 개수 10)으로 계산 했다.
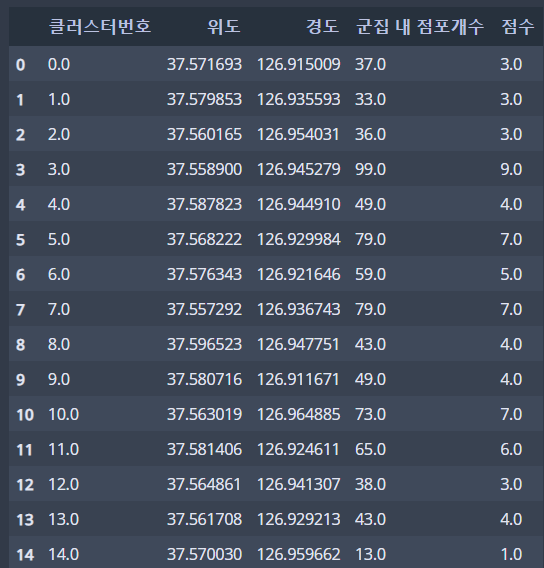
- 군집의 개수를 늘리며 이너셔(inertia)를 확인하여 최적의 군집 개수를 선택하는 방법이다. 이너셔는 군집 중심점에서 군집에 속한 데이터들의 거리 제곱 합이다. 이 방법으로 서대문구에 위치한 점포들의 군집 개수는 15개로 선택했다.
- 버스 정류장 데이터
- 버스 총 승하차 승객수를 히스토그램으로 그리면 아래와 같다.
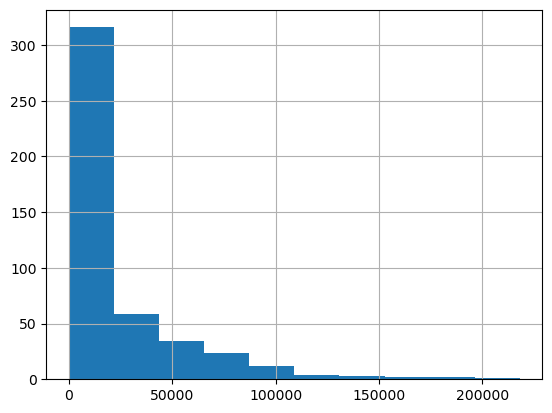
- 대부분의 버스 정류장은 승하차 인원이 5만명도 안된다. 우리는 총 승하차 인원이 5만명 이상인 버스정류장에 집중하기로 했고, 5만 이상, 8만 이상인 버스 정류장을 선택했다.
- 버스 총 승하차 승객수를 히스토그램으로 그리면 아래와 같다.
- 점포들과 클러스터, 주요 버스 정류장을 folium 패키지를 사용하여 지도에 시각화를 진행했다.
4. 최종 결과
아래와 같이 처리한 데이터들을 지도에 시각화 했다. 시각화 자료의 범례는 다음과 같다.
[ 범례 ]
- 빨간색 점 : 개별 점포 위치
- 노란색 마커 / 원 : 상위 점수 클러스터(점포의 개수가 많은 클러스터) 중심 / 클러스터 경계
- 초록색 마커 / 원: 하위 점수 클러스터(점포의 개수가 적은 클러스터) 중심 / 클러스터 경계
- 분홍색 마커 : 총 승하차 승객수가 5만 이상, 8만 이하인 버스 정류장
- 짙은 빨간색 마커 : 총 승하차 승객수가 8만 이상인 버스 정류장
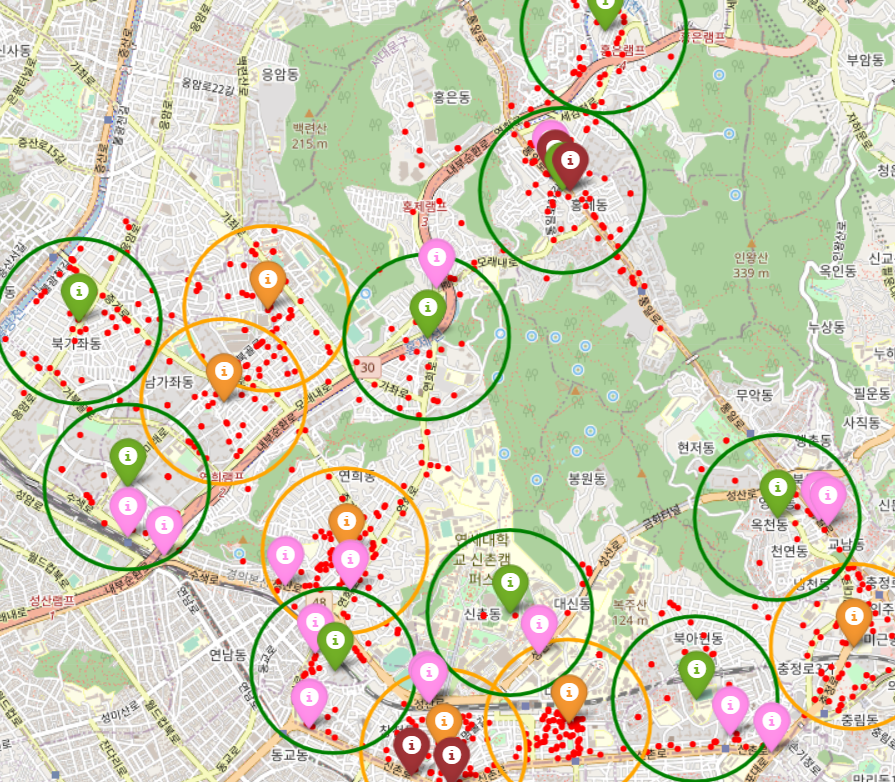
점포를 기준으로 군집화 한 결과와 그 안에 주요 버스정류장이 있는 지역에 우선적으로 회수 로봇이 설치되어야 된다고 생각했다. 예를 들면 아래와 같은 지역이다.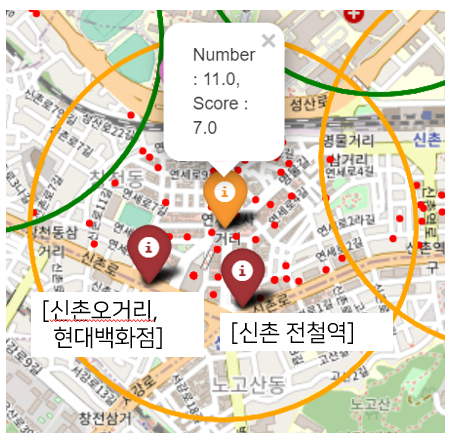
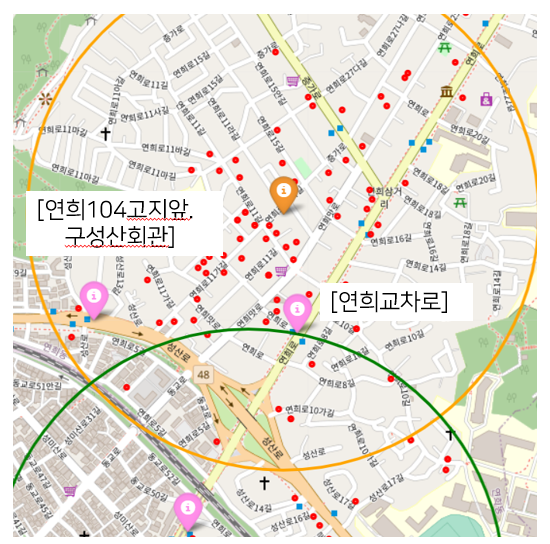
우리는 쓰레기 회수 로봇은 전력을 필요로 하고 설치에는 시의 승인이 있어야하기 때문에 대략적인 설치 위치만을 제공했다. 이 부분은 현실적인 문제가 있기에 데이터만으로 풀어내는 데에는 한계가 있었다.
5. 느낀점
5-1. 첫 프로젝트
이 프로젝트는 내가 진행한 첫 프로젝트이다. 사실 코딩 공부를 시작한지도 얼마 안된터라 코드 작성, 구글링, 팀원들과 협업 등 생소한 것이 너무도 많은 시간이었다. 그러나 프로젝트를 진행하며 소통하는 방법, 결과물을 공유하는 방법, 구글링하는 방법 등 많은 것들을 익혔다.
5-2. 알고리즘 시행착오
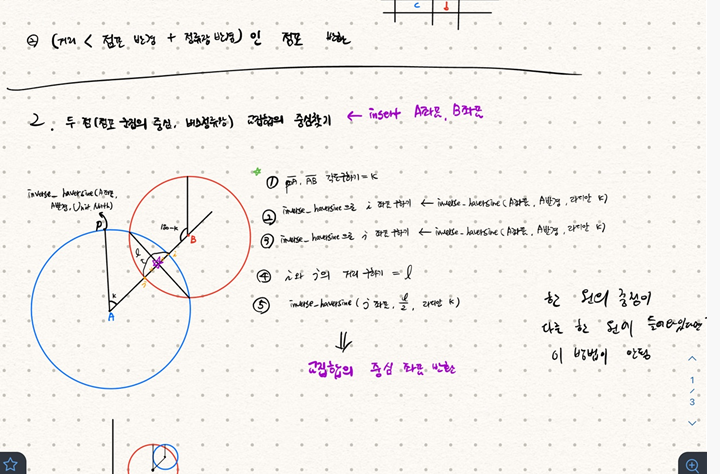 처음에는 한 클러스터의 중심은 다른 클러스터 내에 없다는 가정 하에 위와 같은 알고리즘을 생각해보았다. 그런데 이 외에도 계산해야 하는 경우의 수가 너무 많아 어려움을 느꼈다.(클러스터의 중심이 다른 원 위에 있는 경우, 두 클러스터에 교점이 없는 경우 등)
처음에는 한 클러스터의 중심은 다른 클러스터 내에 없다는 가정 하에 위와 같은 알고리즘을 생각해보았다. 그런데 이 외에도 계산해야 하는 경우의 수가 너무 많아 어려움을 느꼈다.(클러스터의 중심이 다른 원 위에 있는 경우, 두 클러스터에 교점이 없는 경우 등)
그러던 중 회수 로봇에 전기 공급, 지자체의 허가 등 현실적인 문제로 회수 로봇의 위치를 특정할 수 없다는 결론을 얻고 해당 알고리즘은 사용하지 않는 것으로 결정했다.비록 이 방법을 사용하지는 못했지만 문제를 해결하기 위해 이것 저것 생각하고 고민하는 시간 덕분에 이 프로젝트에 더 깊이 생각할 수 있었다고 생각한다.
5-3. 왜?라는 질문의 중요성
우리 팀원 중에는 정년 퇴직을 하신 팀원(=박선생님)이 있었는데, 그 분 덕분에 우리 프로젝트를 갈무리할 수 있었다고 생각한다. 박선생님은 회의 중 나오는 안건 대부분에 "왜?"라고 질문하셨다. 그리고 우리는 자신들의 주장에 근거를 제시하면서 어느 부분에서 논리가 부족한지, 왜 이 주장은 말이 안 되는지 스스로 깨닫게 되었다. 박선생님께서 "왜?"라는 질문을 해주신 덕분에 느리지만 단단한 한 걸음을 내딛었다고 생각한다. 앞으로 어떤 프로젝트를 하던, 어떤 일을 하게 되던 "왜?"라는 질문을 달고 살아야 겠다.
