[ 사용된 기술 및 패키지 ]
- python
- pandas / numpy
- matplotlib
- selenium
- konlpy
- wordcloud
[ 담당 업무]
- 팀장
- 크롤링 코드 작성
- 데이터 수집
- 리뷰 토큰화 및 시각화
1. 프로젝트 개요
2019년 5월, '배달의 민족'에 대항하여 쿠팡에서도 음시 배달 서비스 '쿠팡이츠' 출시했다. 그리고 약 2년 후 쿠팡이츠가 시장에서 어떤 위치에 있는지, 소비자들은 쿠팡이츠를 어떻게 생각하는지 궁금해져 이번 프로젝트를 진행했다. (이 프로젝트는 21년 8월에 진행된 프로젝트이고, 최근에서야 이렇게 기록하게 되었다.)
소비자들의 생각을 알기 위해 플레이 스토어 리뷰와 쿠팡이츠에 대한 트위터를 크롤링하여 분석했다. 워드클라우드를 띄워 주요 단어들을 확인했고 시간이 흐름에 따라 변화하는 평점 등의 정보를 확인했다.
2. 프로젝트 배경
2021년 여름, 코로나19의 여파로 집에 머무는 시간이 많아진 탓에 음식 배달업은 뜨거운 감자가 되었다. 따라서 음식 배달업에 뛰어드는 기업이 많아졌고 '배달의 민족'의 대항하는 서비스들을 줄줄이 출시 했다. 그 중 '로켓 배송'을 내세워 등장한 '쿠팡이츠'가 배달업에서 자리매김을 했다.
쿠팡이츠 출시 후 2년 간의 사업 결과와 코로나19로 인한 배달업 성행, 쿠팡이츠는 소비자들에게 어떤 이미지일지 문득 궁금해졌고, 데이터를 기반으로 쿠팡이츠의 기업 이미지를 확인해보고자 했다.
3. 분석
3-1. 데이터 수집
쿠팡이츠의 이미지를 분석하기 위한 최적의 데이터는 실제 사용자들의 리뷰이다. 우리가 사용한 데이터는 아래와 같다.
- 구글 플레이 스토어
- 앱을 실제로 사용해본 사람들의 리뷰를 확인하기 위하여
- 쿠팡이츠와 관련된 트위터 게시글
- 앱에 관한 내용 이외에 쿠팡이츠 자체에 대한 의견을 확인하기 위하여
쿠팡이츠는 당시 세 개의 앱을 출시했다. 소비자들이 음식을 주문할 수 있는 '쿠팡이츠', 점주들이 플랫폼에 가게 정보를 올리는 '쿠팡이츠 스토어', 라이더들이 배차를 잡는 '쿠팡이츠 라이더스'가 그것이다. 따라서 플레이 스토어에서는 세 가지 앱 모두 리뷰를 모았다.


 구글 플레이 스토어와 트위터는 모두 동적인 웹이기 때문에 selenium 라이브러리를 사용하여 리뷰를 모았다.
구글 플레이 스토어와 트위터는 모두 동적인 웹이기 때문에 selenium 라이브러리를 사용하여 리뷰를 모았다.
3-2. 텍스트 분석
이렇게 모은 리뷰는 평점으로 긍정 리뷰와 부정 리뷰를 분류했다. 5점 만점에 평점 4점 이상은 긍정 리뷰, 3점 이하는 부정 리뷰로 가정했다.
분석을 위해 자연어 처리를 도와주는 파이썬 라이브러리 konlpy를 사용하여 토큰화 해주었다. 불용어 처리는 서강대학교 정재학 교수님께서 블로그에 불용어 사전을 오픈해주셔서 사용했다.(정재학 교수님 블로그 링크)
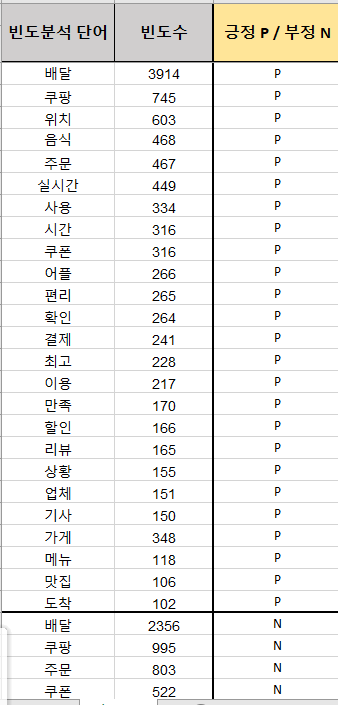 긍/부정 리뷰로 분류하고 토큰화하한 결과이다. 그리고 토큰화 한 데이터를 워드클라우드로 변화해 보았다.
긍/부정 리뷰로 분류하고 토큰화하한 결과이다. 그리고 토큰화 한 데이터를 워드클라우드로 변화해 보았다.
 ↑ 긍정리뷰 워드 클라우드
↑ 긍정리뷰 워드 클라우드
 ↑ 부정리뷰 워드 클라우드
↑ 부정리뷰 워드 클라우드
3-3. 시계열 분석
시간이 쿠팡이츠 출시 후 시간의 변화에 따라 평점이 어떻게 변화하는지 그래프를 그려 확인해보았다.
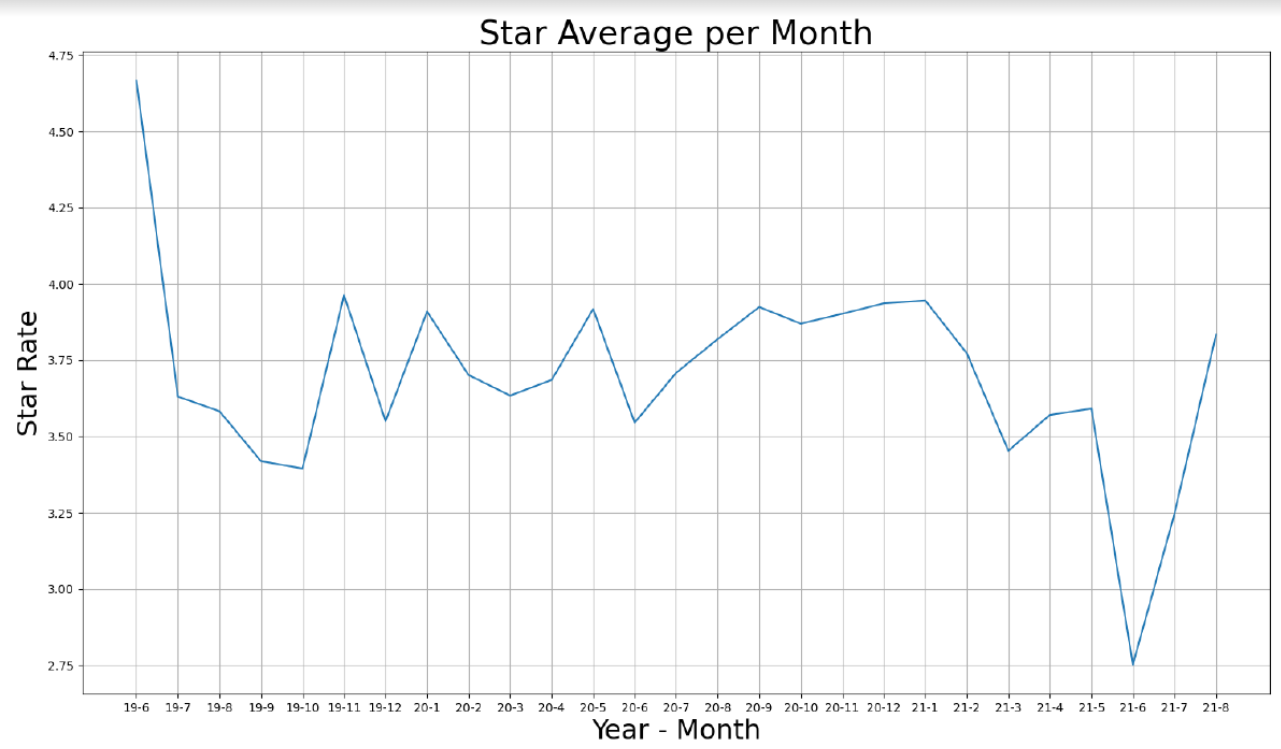 21년 6월, 평균 평점 3점대를 유지하다가 21년 6월에 평균 평점 2점대로 떨어지게 된다. 그 원인을 찾아보니 라이더 등급제 및 등급을 기반한 차별 문제가 사회적 문제로 떠올랐기 때문이었다.
21년 6월, 평균 평점 3점대를 유지하다가 21년 6월에 평균 평점 2점대로 떨어지게 된다. 그 원인을 찾아보니 라이더 등급제 및 등급을 기반한 차별 문제가 사회적 문제로 떠올랐기 때문이었다.
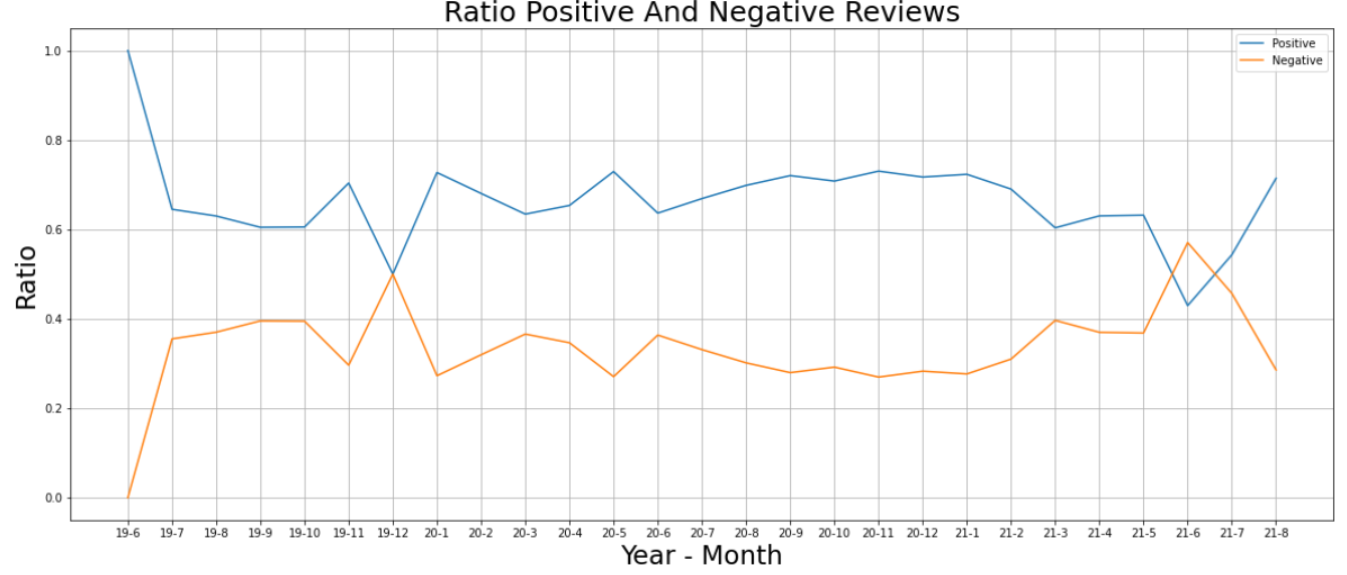 긍정리뷰와 부정리뷰의 비율을 시각화해보았는데 마찬가지로 21년 6월에 부정리뷰 비율이 긍정리뷰비율을 앞질렀다.
긍정리뷰와 부정리뷰의 비율을 시각화해보았는데 마찬가지로 21년 6월에 부정리뷰 비율이 긍정리뷰비율을 앞질렀다.
4. 최종 결과
우리는 텍스트, 시계열 분석의 결과로 쿠팡이츠의 개선 사항을 정리해보았다.
- 다양한 수단으로 더 많은 라이더를 확보하려는 전략을 사용했지만 자가용 주차 문제, 속도 문제 등 다른 이슈가 많아져 오히려 고객에게 불편함을 제공하므로, 배송 방법을 고객이 선택할 수 있게 해야한다.
- 주문 취소, 배차 취소 등의 프로세스를 점검해야한다.
- '로켓 배송'을 마케팅 전략으로 삼았지만, 그에 비해 배송이 너무 느리므로 배송 관련 프로세스를 점검해야한다.
- 라이더, 점주 등을 등급화 하거나 차별하는 문제는 기업 이미지 자체에 타격이 있으므로 자중해야 할 것이다.
5. 한계
- 사용자, 점주, 라이더 세 부류의 리뷰 데이터를 사용했지만, 시간이 부족하여 세 가지 데이터셋을 따로 확인하지 못했다.
- 긍정리뷰와 부정리뷰를 평점으로 나누는 방법은 너무 단순한 분류라고 생각했다. 감정분석 등의 방법을 도입하여 조금 더 정밀한 방법으로 분류해야 할 것 같다.
6. 느낀점
6-1. 데이터 분석의 재미
음식 배달은 우리 삶에 밀접한 관련이 있는 주제이다. 나는 항상 서비스의 소비자 입장이었는지만 이번 기회를 통해 간접적으로나마 서비스의 공급자가 된 것 같았다. 서비스를 어떻게 개선해야 할지, 이슈는 무엇인지를 데이터를 기반으로 파악할 수 있는 귀한 시간이었다.
특히 크롤링에 대해 배운 후 실제 프로젝트에 녹여 사용해보니 더욱 재미가 있었다.
6-2. 중간 산출물의 중요성
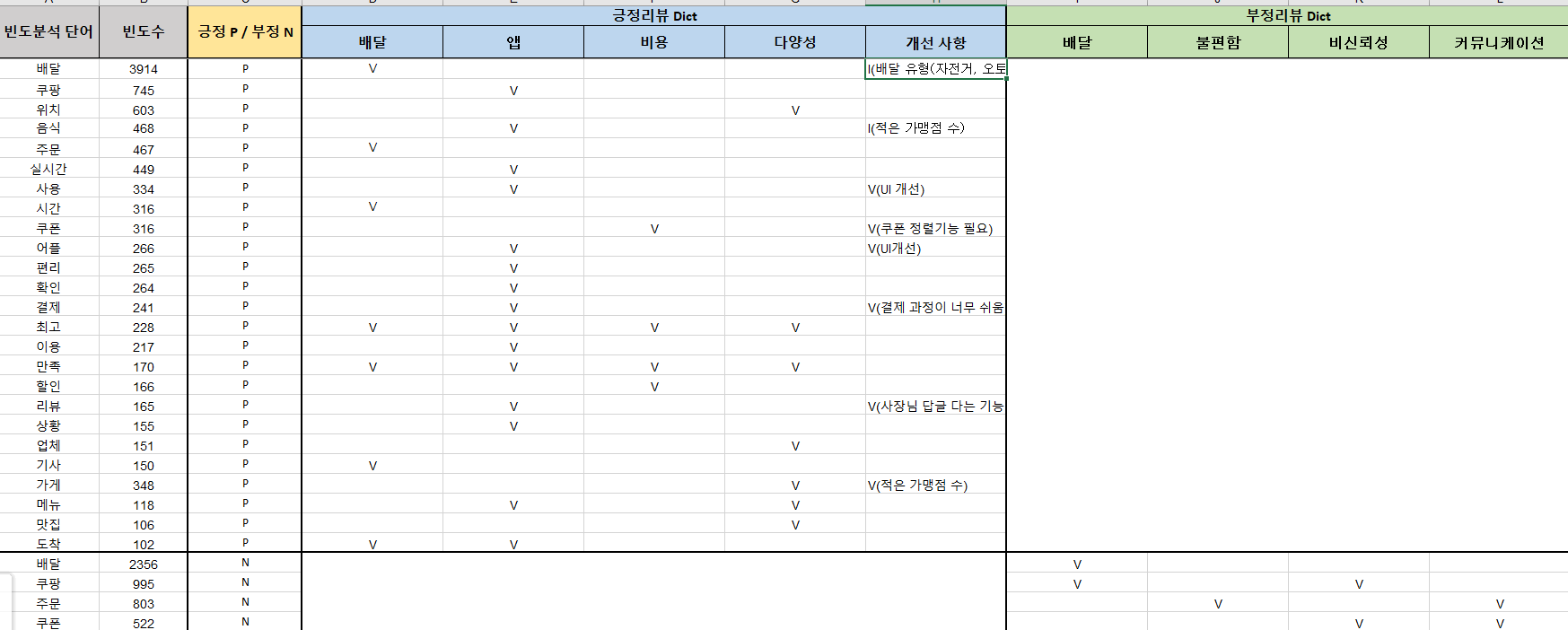 이번 프로젝트에서는 중간 산출물을 냈다. 위 이미지는 리뷰 토큰화 결과를 키워드 분석한 결과이다. 해당 중간 산출물을 만들면서 데이터를 파악하는데에 도움이 크게 되었다.
이번 프로젝트에서는 중간 산출물을 냈다. 위 이미지는 리뷰 토큰화 결과를 키워드 분석한 결과이다. 해당 중간 산출물을 만들면서 데이터를 파악하는데에 도움이 크게 되었다.
앞으로도 최종 결과만을 생각하는 것이 아니라 돌다리 건너듯 프로젝트 중간에도 산출물을 만들어 흐름을 정리하며 데이터를 바라보는 습관이 필요할 것 같다.
