1. SQL 기초
1-1 SQL이란
1) SQL 개요
SQL은 관계형 데이터베이스에서 데이터를 효과적으로 다루기 위해 개발된 언어다. SQL의 가장 큰 특징은 비절차적 언어라는 점이다. 이는 사용자는 자신이 원하는 것(=what)을 제시할 수만 있고 어떻게 처리할지(=how)는 제시할 수 없다는 뜻이다.
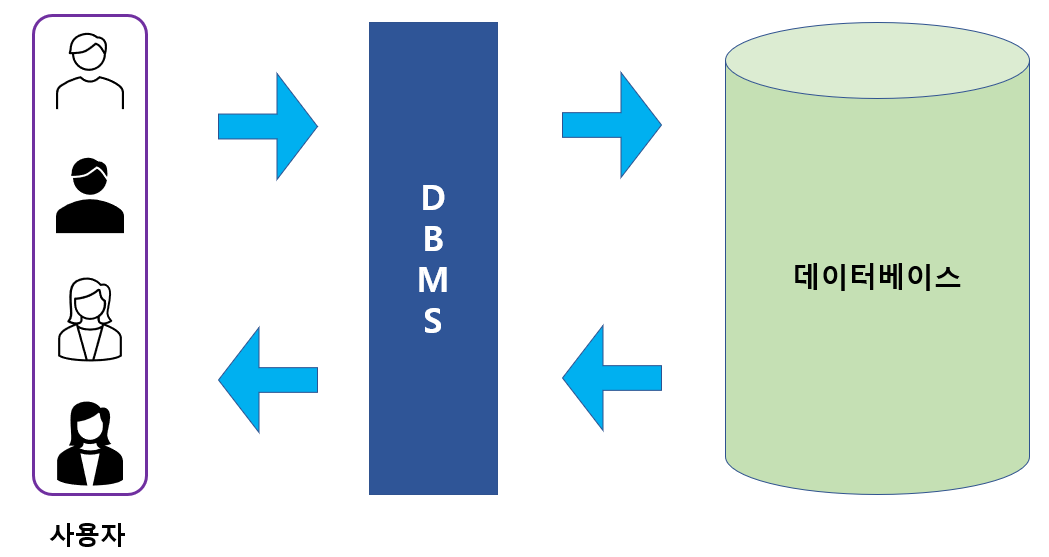 DBMS는 사용자와 데이터베이스 사이에 존재하며, SQL을 사용하여 사용자가 원하는 동작을 입력하면 DBMS가 이를 해석해 동작 방법을 알아서 찾아 명령을 완료하는 구조이다.
DBMS는 사용자와 데이터베이스 사이에 존재하며, SQL을 사용하여 사용자가 원하는 동작을 입력하면 DBMS가 이를 해석해 동작 방법을 알아서 찾아 명령을 완료하는 구조이다.
SQL을 사용하는 방법은 두 가지가 있다.
- MySQL, PostgreSQL 등 SQL 전용 언어를 사용하는 대화식 SQL
- C, Java, Python 등 고급 프로그래밍 언어 안에서 사용하는 내포된(=embedded) SQL
2) SQL 구성 요소
SQL을 구성하는 요소는 5가지가 있다.(교재 기준)
-
데이터 검색
데이터 검색 기능은 원래 데이터 조작어(DML)에 포함되는 명령어지만, 워낙 사용 빈도가 높고 매우 중요한 명령이기 때문에 따로 소개하기도 한다. -
데이터 조작어(DML)
개별 인스턴스에 해당하는 동작을 처리할 때 사용하는 언어이다. SELECT, DELETE, UPDATE, INSERT 등이 있다. -
데이터 정의어(DDL)
데이터 스키마에 대한 동작을 처리할 때 사용하는 언어이다. CREATE, ALTER, DROP 등이 있다. -
데이터 제어어(DCL)
데이터베이스에는 사용자별로 접근 가능한 범위를 관리할 수 있는 기능이 있으며, 데이터 제어어를 통해 권한 설정을 할 수 있다. GRANT, REVOKE가 있다. -
트랜잭션 제어
모든 데이터의 변경 사항을 실시간으로 적용하면 속도 측면에서 이슈가 발생할 수 있다. 따라서 변경사항을 한 번에 모아서 처리하거나 변경사항 적용을 취소한다. 트랜잭션을 제어하기 위한 명령어로는 COMMIT, ROLLBACK이 있다.
1-2. 데이터 조작어 - SELECT
1) SELECT절 소개 및 샘플 데이터 생성
보통 SQL에서 특별한 직무가 아닌 이상 데이터 조작어를 가장 많이 사용한다. 그리고 그 중 압도적으로 많이 사용되는 구문은 SELECT 이다. 원하는 데이터를 조회할 수 있는 SELECT 절은 정확하게 알아둘 필요가 있다.
우리가 사용할 데이터 샘플은 아래와 같다.
DROP TABLE IF EXISTS Employee;
CREATE TABLE Employee(
EMPNO INT PRIMARY KEY,
EMPNAME VARCHAR(8),
TITLE VARCHAR(4),
MANAGER INT,
SALARY INT,
DNO INT
);
INSERT INTO employee
VALUES
(2106, '김창섭', '대리', 1003, 2500000, 2),
(3426, '박영권', '과장', 4377, 3000000, 1),
(3011, '이수민', '부장', 4377, 4000000, 3),
(1003, '조민희', '과장', 4377, 3000000, 2),
(3427, '최종철', '사원', 3011, 1500000, 3),
(1365, '김상원', '사원', 3426, 1500000, 1),
(4377, '이성래', '사장', NULL, 5000000, 2)
;
DROP TABLE IF EXISTS DEPARTMENT;
CREATE TABLE DEPARTMENT(
DEPTNO INT PRIMARY KEY,
DEPTNAME VARCHAR(3),
FLOOR INT
);
INSERT INTO DEPARTMENT
VALUES
(1, '영업', 8),
(2, '기획', 10),
(3, '개발', 9),
(4, '총무', 7)
;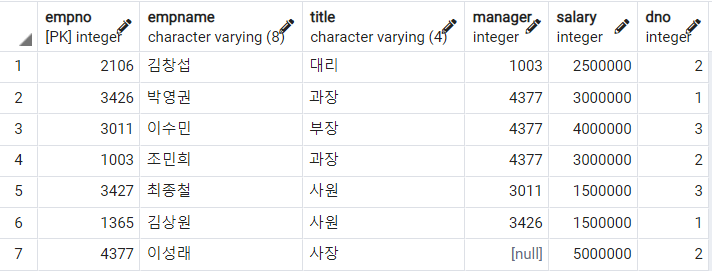

테이블 이름은 각각 Employee, Department이다.
[ 참고 ]
SQL을 작성할 떄에는 대문자/소문자 구분을 하지 않아도 된다. 테이블을 생성할 때 컬럼 이름을 대문자로 썼지만, 실제로 만들어진 테이블을 보면 컬럼 이름이 소문자이다.다만, SQL에서 지정된 특정 단어들은 대문자로 쓰는 것이 일반적인 방법이므로 특정 키워드를 제외하고는 모두 소문자를 쓰도록 하자.
2) SELECT 기본 문법
SELECT절에는 여러 옵션이 들어올 수 있다. 그 중 SELECT, FROM은 필수로 사용되어야 한다.
- 필수 키워드 : SELECT, FROM
- 선택 키워드 : WHERE, GROUP BY, HAVING, ORDER BY
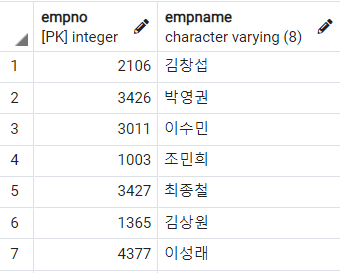
SELECT 절에는 조회하고자 하는 어트리뷰트를 나열하고, FROM절에 조회하려는 릴레이션 이름을 명시한다. Employee 테이블에서 사원 번호(empno), 사원 이름(empname)만 조회해보도록 하자.
SELECT
empno
, empname
FROM
Employee
;
3) Asterisk(*)의 활용
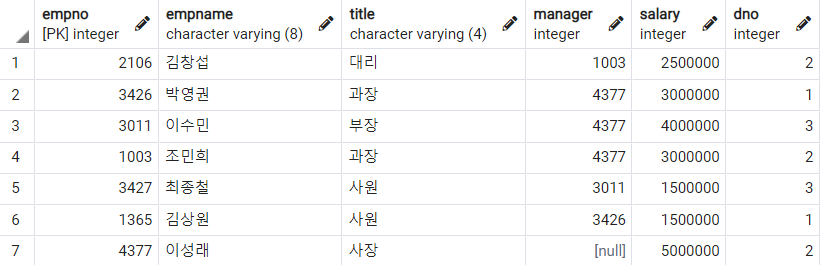
FROM절에 명시한 모든 어트리뷰트를 조회하고 싶을 때에는 특수 기호 Asterisk를 사용한다.
SELECT
*
FROM
Employee
;
4) 별칭(Alias)
SELECT문에서 특정 어트리뷰트나 테이블 이름이 너무 길거나 복잡한 경우 별칭을 붙여 사용할 수 있다. 별칭을 적용하는 키워드는 AS이다.
AS 키워드는 생략이 가능하다. 일반적으로 어트리뷰트에 별칭을 붙일 때에는 생략하지 않고, 테이블 이름에 별칭을 붙일 때에는 생략한다.
-- 속성 이름에 별칭 사용
SELECT
empno AS 사원번호
, empname AS "사원 이름"
FROM
Employee
;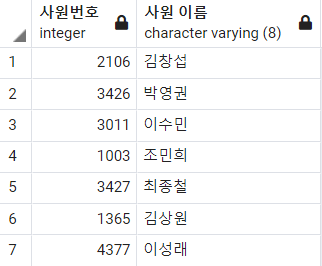
한 가지 눈여겨 볼 것은 별칭에 띄어쓰기가 있는 경우에는 큰 따옴표로 별칭을 묶어주어야 한다는 점이다.
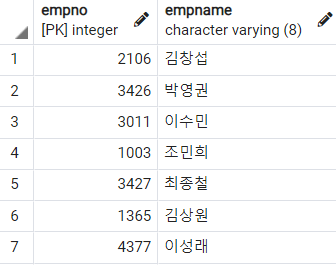
-- Employee 테이블에 'A'라는 별칭 붙이기
SELECT
empno
, empname
FROM
Employee A
;
5) DISTINCT
SELECT절에서 데이터 중복을 없애고 싶을 때 DISTINCT를 사용한다.
-- 중복된 데이터 확인
SELECT
title
FROM
employee
;
-- 중복 데이터 제거
SELECT
DISTINCT title
FROM
employee
;
6) WHERE
앞선 방법들은 어떠한 조건 없이 데이터를 조회했다. 그런데 많은 경우에 조건을 걸어 데이터를 조회해야 한다. SELECT문에서 조건을 거는 방법은 WHERE을 사용하는 것이다. WEHRE 다음에 조건으로 제시하고자 하는 논리연산을 써준다. (논리연산은 WEHRE절 뿐만 아니라 다른 절에서도 사용한다.)
-- DNO가 2인 모든 데이터 조회
SELECT
*
FROM
employee
WHERE
DNO = 2
;
[ WHERE 동작 매커니즘 ]
WEHRE절에는 논리연산이 오고, 제시한 조건과 비교하여 True와 False 판단한다. 그 후 True인 데이터만 화면에 뿌려준다.위 예시를 살펴보면 아래와 같다.
EMPNO EMPNAME ... DNO 조건 비교 결과 2106 김창섭 ... 2 True 3426 박영권 ... 1 False 3011 이수민 ... 3 False 1003 조민희 ... 2 True 3427 최종철 ... 3 False 1365 김상원 ... 1 False 4377 이성래 ... 2 True 따라서 조건 결과가 True인 데이터 (2106, 김창섭, ...), (1003, 조민희, ...), (4377, 이성래, ...)만 조회된 것이다.
[ 논리연산 ]
논리연산은 그 결과가 True나 False로 판단될 수 있는 연산을 의미한다. 논리연산에는 =, ≠, >, ≥, <, ≤가 있다.예를 들어 조건이 'A=B'는 A가 B와 같으면 True를, A가 B와 다르면 False를 반환한다.
7) 문자열 비교
WHERE 절에 특정 문자열을 갖는지에 대한 조건도 제시할 수 있다. WHERE절에 LIKE 키워드와 %를 사용하면 문자열에 대한 조건을 제시할 수 있다.
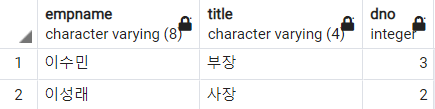
-- 이씨 성을 가진 직원 이름, 직급, 부서 번호 조회
SELECT
empname
, title
, dno
FROM
employee
WHERE
empname LIKE '이%'
;
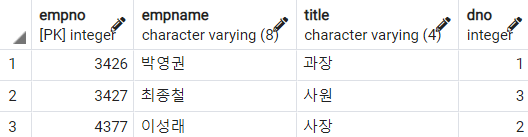
-- 사원 번호에 4가 들어가는 직원 조회
SELECT
empno
, empname
, title
, dno
FROM
employee
WHERE
CAST(empno AS VARCHAR) LIKE '%4%'
;
[ %과 _의 차이]
특정 문자가 포함되어있는지 확인할 때 사용되는 연산자는 %와 _가 있다. 이 둘은 아래와 같은 차이가 있다.
- %는 앞, 뒤에 오는 문자열 개수를 신경쓰지 않고 결과를 반환한다.
- _는 한 글자가 오는 경우만 반환한다.
예제 조건 결과 설명 가나다라마 %나% True . 가나다라마 _나% True '나' 앞에는 한 글자이고, '나' 뒤에는 글자수 상관 없음 가나다라마 _다% Flase '다' 앞에는 두 글자이고, '다' 뒤에는 글자수 상관 없음 가나다라마 _ _다% True . 가나다라마 _ _다 False '다' 뒤에 글자가 있지만, 이 조건으로는 뒤에 있는 글자 고려 x 가나다라마 _ _ _ 라 _ True '라' 앞 뒤 글자수가 다 부합함
8) AND 연산자, OR 연산자
여러 개의 조건은 AND나 OR로 연결할 수 있다. WHERE절 뿐만 아니라 다른 절에서도 AND와 OR은 사용 가능하다. AND는 두 조건이 모두 True일 때만 True, OR은 두 조건이 모두 False일 때 Flase를 반환한다.(1 = True, 0 = False)
| x | y | x AND y |
|---|---|---|
| 1 | 1 | 1 |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 0 |
| x | y | x OR y |
|---|---|---|
| 1 | 1 | 1 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 0 | 0 | 0 |
-- 직급이 과장이면서 1번 부서에서 근무하는 사원 전체 데이터 검색
SELECT *
FROM
employee
WHERE
title='과장'
AND dno=1
;
9) 부정 연산자
영어에서 Not이 있듯이 SQL에도 부정 연산자가 있다. SQL에서는 부정연산을 위해 <>나 != 를 쓴다. 다만, 다른 프로그래밍 언어들도 부정 연산은 대부분 !=를 쓰기 때문에, 통일성을 위해 SQL에서도 가능하면 !=를 쓰도록 하자.
-- 직급이 과장이면서 1번 부서 이외의 부서에서 근무하는 사원 전체 데이터 검색
SELECT *
FROM
employee
WHERE
title = '과장'
AND dno != 1
;
10) BETWEEN 연산자
조건으로 특정 범위를 지정하고 싶을 때 BETWEEN 연산자를 사용한다. 결과를 통해 확인하겠지만, 범위값은 그 값을 포함한다(이상, 이하라는 뜻)
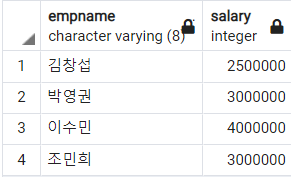
-- 급여가 2백만~4백만 사이인 직원 이름과 급여 조회
SELECT
empname
, salary
FROM
employee
WHERE
salary
BETWEEN 2000000 AND 4000000
;
11) IN
조건을 제시할 때 범위를 사용할 수도 있지만, 특정 리스트를 제시할 수 있다. 리스트를 조건으로 제시할 때에는 IN 연산자를 사용한다.
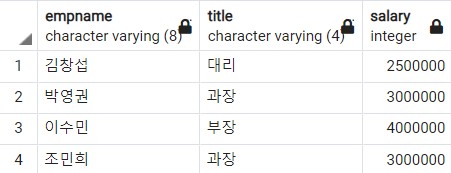
-- 직급이 대리, 과장, 부장인 직원들에 대하여 이름, 직급, 급여 정보 조회
SELECT
empname
, title
, salary
FROM
employee
WHERE
title IN ('대리', '과장', '부장')
;
12) SELECT절에서 산술 연산 하기
SELECT절에는 조회하려는 컬럼을 명시해준다. 이 때 조회하려는 컬럼에 산술연산을 적용한 결과를 반환할 수 있다.
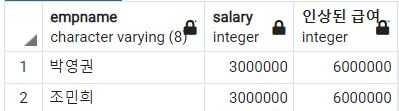
-- 직급이 과장인 직원에 대하여 직원 이름, 원래 급여, 급여가 100% 인상되었을 때의 결과 조회
SELECT
empname
, salary
, salary * 2 AS "인상된 급여"
FROM
employee
WHERE
title='과장'
;
연산은 숫자형 데이터에 대해서만 적용할 수 있으니 주의하자.
-- 숫자형이 아닌 컬럼에 산술연산 써보기
SELECT
empname + '과장'
, salary
, salary * 2 AS "인상된 급여"
FROM
employee
WHERE
title='과장'
;
13) Null의 처리
Null값은 unknown의 의미로 정해지지 않은 값의 의미를 가진다. 헷갈리기 쉬운데, Null은 0이나 ' '이 아니다! SQL에서는 Null의 확산성이라는 개념이 있는데, Null이 포함된 연산은 그 결과가 무조건 Null이 된다는 것이다. 아래 예시를 보자.
[ Null의 확산성 ]
2 2 ⇒ 4
Null 2 ⇒ Null4 > 2 ⇒ True
Null 2 ⇒ Null
위와 같이 Null이 포함된 모든 연산은 그 결과가 Null이다. 따라서 Null을 조건으로 제시할 때에는 논리연산자를 사용할 수 없다.
-- Null값을 다루는 잘못된 예
SELECT
*
FROM
employee
WHERE
manager = NULL
;
그런데 SQL을 사용하다보면 분명 Null값을 다뤄야 할 때가 있다. Null을 다룰 때에는 어떻게 해야할까. 바로 IS NULL 연산자를 사용하면 된다.
-- Null값을 다루는 예 : 매니저가 없는 직원 검색
SELECT
*
FROM
employee
WHERE
manager IS NULL
;
14) ORDER BY
데이터를 조회한 결과는 튜플이 테이블에 삽입된 순서대로 나온다. ORDER BY를 사용하면, 조회 결과를 정렬할 수 있다. 기본적으로는 오름차순(ASC)이 설정되지만, 원한다면 DESC를 추가해주어 내림차순으로 정렬할 수도 있다.
중요한 점은 SELECT절에 명시한 컬럼 중 하나가 정렬 기준으로 제시 되어야 한다.
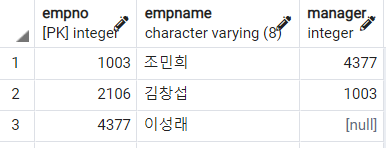
/*
2번 부서에 근무하는 직원 데이터 중 직원 번호, 이름, 상사 직원 번호를 조회하되
급여 사원 번호 기준으로 오름차순 정렬
*/
SELECT
empno
, empname
, manager
FROM
employee
WHERE
dno = 2
ORDER BY
empno
;
15) 집계함수(Aggregation Function)
집계함수는 여러 튜플들을 하나의 값으로 변환하는 함수들을 의미한다.
[ 집계함수 종류 ]
- COUNT : 결과 값들의 개수 반환(중복 값도 모두 counting)
- SUM : 결과 값들의 합 반환
- AVG : 결과 값들의 평균 값 반환
- MAX : 결과 값들 중 최대값 반환
- MIN : 결과 값들 중 최소값 반환
COUNT(*) 제외하고 다른 집계함수는 Null을 제외하고 연산한다. 아래 예시를 보자. 부서 번호가 2번인 직원들 정보이다.

-- COUNT(*)는 Null을 제외되지 않음! 다만, * 대신 특정 컬럼을 제시하면 Null은 제외
SELECT
COUNT(*) AS "전체 컬럼"
,COUNT(manager) AS "특정 컬럼"
, SUM(manager) AS "다른 집계함수 결과 확인 - SUM"
FROM
employee
WHERE
dno = 2
;
16) GROUP BY
집계함수를 적용할 때 그룹을 지어주지 않으면 전체 튜플을 하나로 놓고 집계를 진행한다. SQL에서는 사용자가 제시한 기준에 따라 데이터를 그룹화 할 수 있는데, 이때 사용하는 키워드가 GROUP BY이다. 그룹화는 하나의 집단으로 만든다는 의미이다.
한 가지 중요한 점은 GROUP BY는 반드시 집계함수와 함께 사용된다는 점이다. 그룹화만 하면 에러가 발생한다.(아래 에러코드 확인)
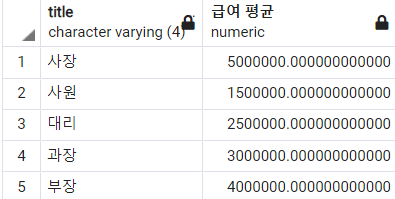
-- 직급별 급여 평균 조회
SELECT
title
, AVG(salary) AS "급여 평균"
FROM
employee
GROUP BY
title
;
또 주의할 점은 GROUP BY절이나 집계함수가 사용되지 않은 컬럼은 사용할 수 없다.
-- 직급별 급여 평균 조회
SELECT
title
, AVG(salary) AS "급여 평균"
, empname
FROM
employee
GROUP BY
title
;
17) HAVING
HAVING은 데이터 조회 시 그룹에 적용되는 조건을 제시할 때 사용한다.
[ WHERE과 HAVING 조건 적용 대상 비교 ]
- WHERE : 각각의 튜플이 조건에 부합하는지 확인
- WHERE dno = 3 ⇒ dno가 3인 모든 튜플 조회
- HAVING : 그룹이 조건에 부합하는지 확인
- HAVING dno = 3 ⇒ dno가 3인 그룹만 조회
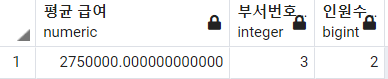
-- 3번 부서에 속한 직원의 평균 급오와 인원수 조회
SELECT
AVG(salary) AS "평균 급여"
, dno AS "부서번호"
, COUNT(*) AS "인원수"
FROM
employee
GROUP BY
dno
HAVING
dno = 3
;
18) ★★★ SELECT절 연산 순서
SELECT의 연산 순서는 매우매우 중요하기 때문에 외우고 있는 것이 좋다. 연산 순서는 아래와 같다.
[ SELECT 연산 순서 ]
FROM → WHERE → GROUP BY → HAVING → SELECT → DISTINCT → ORDER BY → LIMIT
연산 순서가 중요한 점은 이 순서에 따라 명령어 작성 방법이 직관적인 것과 달라지기 때문이다. 예를 들면 아래와 같다.
-- SELECT 연산 순서에 따른 코드 변경 : WHERE절에서 컬럼 별칭 사용하기
SELECT
empname AS name
, title
, salary
FROM
employee
WHERE
name LIKE '김%'
;
SELECT절의 연산 순서보다 WHERE절의 연산 순서가 더 빠르다. 따라서 SELECT절에서 사용한 별칭은 WHERE 적용 이후에 적용되는 것이므로 위와 같은 에러가 발생한 것이다.
이렇게 왠지 될 것 같은 코드도 실행 순서에 따라 달라질 수 있으므로 SELECT 연산 순서를 알고 있으면 코드 작성에 도움이 된다.
