1. 데이터 조작어
1-1. INSERT
1) 개요
INSERT는 어떤 릴레이션에 인스턴스를 추가할 때 사용하는 구문이다. 데이터를 추가할 때 참조 무결성 제약조건은 참조 되는 릴레이션에는 제약이 없지만, 참조 하는 릴레이션에서는 제약이 걸릴 수 있다. (주의할 점은 참조 되는 릴레이션에 데이터를 추가할 때 다른 제약조건에는 걸릴 수도 있다.)
2) 사용
-- 릴레이션에 데이터 추가
INSERT INTO Department(deptno, deptname, floor)
VALUES (5, '마케팅', 2);
추가할 어트리뷰트 이름을 지정하지 않으면 해당 릴레이션에 존재하는 모든 어트리뷰트가 자동으로 들어간다.
VALUES 키워드 대신 SELECT문이 들어올 수 있다. 이 경우 SELECT문의 결과가 지정한 테이블에 추가된다.
-- Employee 테이블에서 급여가 300만원 이상인 직원만 High_salary 테이블에 넣기
INSERT INTO High_salary
SELECT
empname
, title
, salary
FROM
Employee
WHERE
salary >= 3000000;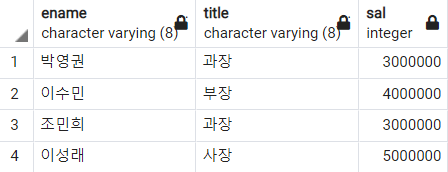
1-2. DELETE
1) 개요
한 릴레이션에서 특정 인스턴스를 삭제할 때 DELETE문을 사용한다. 주의할 점은 WHERE절에 반드시 조건을 제시해야 한다는 점이다. 조건을 제시하지 않으면 모든 인스턴스가 전부 삭제되기 떄문이다.
2) 사용
-- 마케팅 부서 삭제하기
DELETE FROM department
WHERE deptname = '마케팅'
1-3. UPDATE
1) 개요
한 릴레이션에서 특정 특정 인스턴스의 어트리뷰트 값을 수정할 때 사용한다. 기본키나 외래키 값을 변경할 경우 무결성 제약조건에 위배될 수 있다. DELETE문과 마찬가지로 WHERE절에 반드시 조건을 제시해야 한다. 그렇지 않으면 해당 어트리뷰트의 모든 값이 변경되기 때문이다.
2) 사용
-- 직급이 '사원'인 직원들의 급여를 10% 인상하고, 대리로 변경하라
UPDATE
employee
SET
salary = salary * 1.1
, title = '대리'
WHERE
title = '사원';
2. 조인(JOIN)
2-1. JOIN
1) JOIN 소개 및 샘플데이터 생성
JOIN은 공통된 어트리뷰트를 기반으로 하나 이상의 릴레이션을 병합하는 역할을 한다. 아래는 JOIN을 연습하기 위한 샘플 데이터이다. 우리는 fruit_no와 snack_no를 기준으로 JOIN에 대해 알아보도록 하겠다.
DROP TABLE IF EXISTS fruit;
CREATE TABLE fruit(
fruit_no INT PRIMARY KEY,
fruit_name VARCHAR(10)
);
INSERT INTO fruit
VALUES
(1, '사과'),
(2, '바나나'),
(3, '배');
DROP TABLE IF EXISTS snack;
CREATE TABLE snack(
snack_no INT PRIMARY KEY,
snack_name VARCHAR(10)
);
INSERT INTO snack
VALUES
(2, '과자'),
(3, '아이스크림'),
(4, '사탕'),
(5, '껌');
기본적으로 JOIN을 사용하는 방법은 아래와 같다. SELECT ~ FROM절까지 써주고, 사용하려는 JOIN 연산자 + 테이블 이름을 명시하고, ON절 뒤에 기준이 되는 어트리뷰트를 써준다. 아래를 확인해보자.
SELECT
col1
, col2
, col3
FROM
table_a
JOIN 연산자 table_b
ON table_a.어트리뷰트이름 = table_b.어트리뷰트이름이 때 결합 조건으로 제시되는 어트리뷰는 서로 동일한 도메인을 가지고 있어야 한다.(어트리뷰트 이름은 달라도 괜찮다.)
2) JOIN의 종류
JOIN에는 여러 종류가 있으며 아래와 같다.
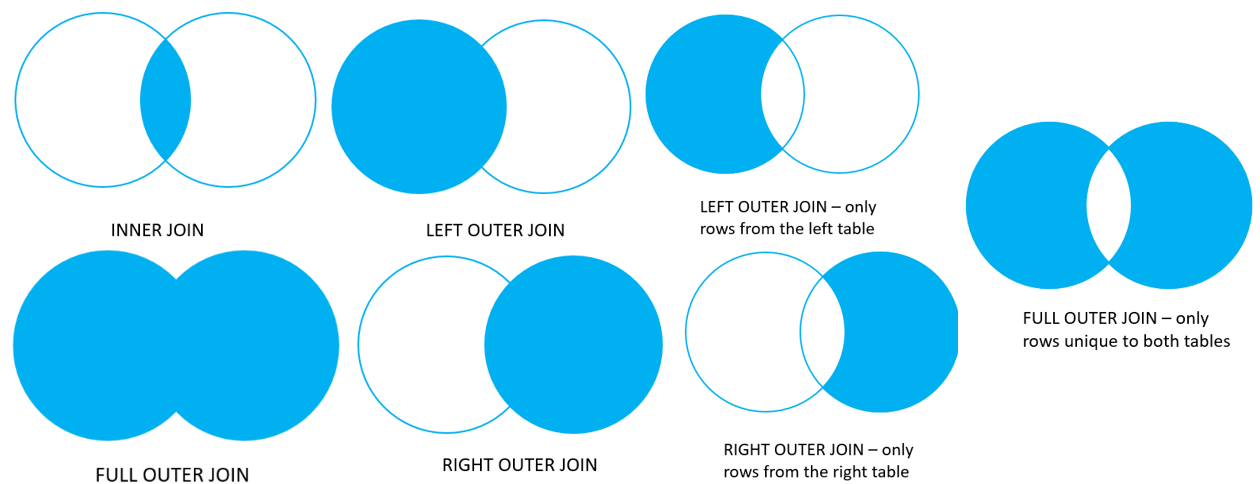 출처 : PostgreSQL Tutorial
출처 : PostgreSQL Tutorial
JOIN은 벤다이어그램으로 표현하면 이해에 도움이 되므로 위 그림을 자주 보도록 하자.
3) INNER JOIN(=NATURAL JOIN)
INNER JOIN은 아래 사진과 같이 교집합 형태로 두 테이블을 결합한다.
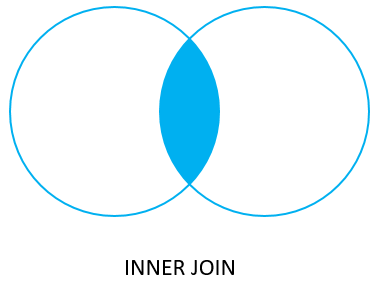
-- fuit_no와 snack_no가 같은 데이터 조회
SELECT *
FROM
fruit f
INNER JOIN snack s
ON f.fruit_no = s.snack_no
;
fruit, snack 테이블에서 일련번호가 같은 데이터를 조회했다. 이 결과 fruit 테이블에서 (1, 사과) 튜플과 snack 테이블에 (4, 껌) 튜플은 조회되지 않았다. 왜냐하면 fruit 테이블 일련번호와 snack 일련번호가 동시에 존재하는 튜플만 조회했기 때문이다.
3) LEFT JOIN(= LEFT OUTER JOIN)
LEFT JOIN은 처음 제시되는 테이블, 즉 FROM절에 제시되는 테이블을 기준으로 삼고, 제시되는 컬럼이 같은 데이터를 조회한다.
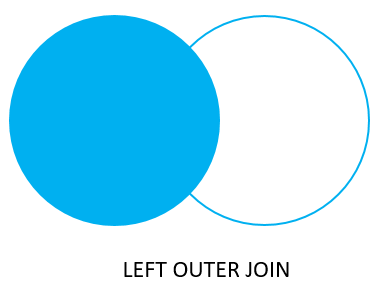
아래 예시를 보자.
-- fuit 테이블을 기준으로 LEFT JOIN
SELECT *
FROM
fruit f
LEFT JOIN snack s
ON f.fruit_no = s.snack_no
;
INNER JOIN의 결과와 달리 (1, 사과) 튜플도 검색되었고, snack 부분에는 NULL로 채워져있다. 이와 같이 먼저 제시된 테이블의 모든 튜플을 조회하고, 기준 컬럼에서 매칭되는 튜플이 없다면 NULL을 넣는다.
LEFT OUTER JOIN은 LEFT JOIN과 그 결과가 완전히 동일하다.
4) RIGHT JOIN(= RIGHT OUTER JOIN)
RIGHT JOIN은 LEFT JOIN과 반대이다. JOIN절에 제시되는 테이블을 기준으로 삼는다.
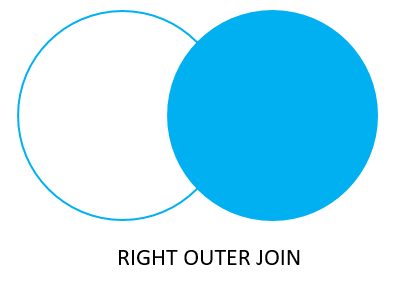
아래 예시를 보자.
-- snack 테이블을 기준으로 RIGHT JOIN
SELECT *
FROM
fruit f
RIGHT OUTER JOIN snack s
ON f.fruit_no = s.snack_no
;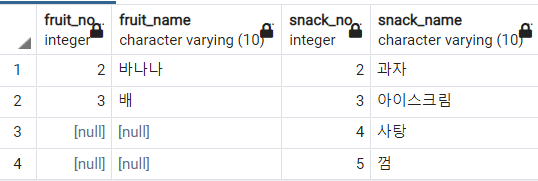
RIGHT JOIN의 기준이 되는 테이블은 snack 테이블이기 때문에 우선 모든 튜플을 다 반환한다. 그리고 일련번호를 기준으로 매칭되는 튜플을 fruit에서 찾는데, 매칭되는 튜플이 없는 경우(일련번호가 4, 5인 경우) NULL을 넣는다.
LEFT OUTER JOIN과 마찬가지로 RIGHT OUTER JOIN은 RIGHT JOIN과 완전히 동일하다.
5) LEFT/RIGHT JOIN NULL 조건 제시
온전히 한 테이블에만 속해있는 데이터를 조회하려면 어떻게 해야할까? 다시 말해 아래 벤다이어그램처럼 데이터를 조회하려면 어떻게 해야할까?
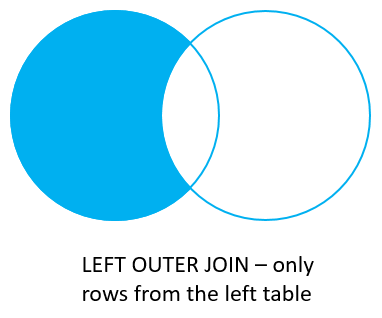
WHERE절을 사용하여 NULL조건을 제시하면 된다.
-- LEFT JOIN -> NULL 데이터 다루기
SELECT *
FROM
fruit f
LEFT OUTER JOIN snack s
ON f.fruit_no = s.snack_no
WHERE
s.snack_no IS NULL
;
이 때 WHERE절에 NULL인 어트리뷰트를 잘 넣어야하는데, JOIN 기준으로 넣었던 어트리뷰트를 조건으로 제시해야한다.
6) FULL OUTER JOIN
벤다이어그램 상으로 교집합, 차집합은 구해보았다. 그렇다면 합집합도 구할 수 있지 않을까? 합집합을 구하기 위해서는 FULL OUTER JOIN을 사용한다.

-- fruit 테이블과 snack 테이블 FULL OUTER JOIN
SELECT *
FROM
fruit f
FULL OUTER JOIN snack s
ON f.fruit_no = s.snack_no
;
일련번호가 겹치지 않는 데이터에 대해서는 먼저 제시된 테이블이던, 나중에 제시된 테이블이던 모두 NULL을 넣는다.
7) 3개 이상 테이블 JOIN
-- 새로운 테이블 하나 더 생성
DROP TABLE IF EXISTS car;
CREATE TABLE car(
car_no INT PRIMARY KEY,
car_name VARCHAR(10)
);
INSERT INTO car
VALUES
(3, '그랜저'),
(4, '소나타'),
(5, '1톤트럭')
;3개 이상의 테이블을 조인하는 방법은 두 개의 테이블을 조인하는 것과 크게 다르지 않다. 두 가지 방법이 있다. ANSI 표준을 따르거나 Oracle 문법을 따르는 방법이 있다.
-- 방법 1 : ANSI 표준
SELECT *
FROM fruit f
JOIN snack s
ON f.fruit_no = s.snack_no
JOIN car c
ON s.snack_no = c.car_no
;
-- 방법 2 : Oracle 문법
SELECT *
FROM fruit f, snack s, car c
WHERE
f.fruit_no = s.snack_no
AND s.snack_no = c.car_no
;2-2. UNION
1) UNION 개념과 주의점
여러 테이블을 하나의 테이블로 결합하고 싶을 때 UNION을 사용할 수 있다. 첫 번째 테이블과 두 번째 테이블을 행 방향으로 붙인다.
query 1 col1 col2 col3 1 2 3 4 5 6 UNION
query 2 col1 col2 col3 a b c d e f ↓↓↓
UNION 결과 col1 col2 col3 1 2 3 4 5 6 a b c d e f
UNION 사용 시 주의할 점은 각각의 쿼리 결과가 동일한 컬럼으로 구성되어 있어야 한다는 점이다. (col1, col2, col3), (cola, colb, colc)이면 붙일 수 없다.
2) 실습
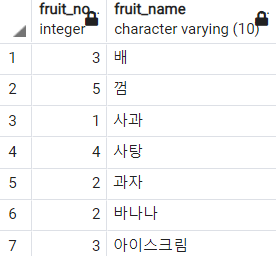
-- UNION 올바른 예
SELECT *
FROM
fruit
UNION
SELECT *
FROM
snack
;
-- UNION 틀린 예
SELECT
fruit_name
, fruit_no
FROM
fruit
UNION
SELECT *
FROM
snack
;
조회한 어트리뷰트 개수나 순서가 다른 경우에 UNION에 에러가 발생한다.
-- UNION 틀린 예
SELECT
fruit_no
FROM
fruit
UNION
SELECT *
FROM
snack
;fruit 테이블은 (fruit_no)만 조회하고 snack 테이블은 (snack_no, snack_name)을 조회했다. 조회한 어트리뷰트 개수가 다르기 때문에 UNION에 실패했다.

3. 서브쿼리(Subquery)
3-1. 서브쿼리
1) 서브쿼리를 사용하는 이유
서브쿼리를 이해하기 위해 아래 예시를 SQL로 작성해보자.
fruit 테이블에서 과일 이름이 가장 긴 튜플 반환하기
위 업무를 수행하기 위해서는 두 단계에 걸쳐 쿼리를 작성해야 한다.
-- 1단계 : 가장 긴 과일 이름 길이 반환
SELECT
MAX(LENGTH(fruit_name))
FROM
fruit
;-- 2단계 : 길이가 3인 과일 이름 조회
SELECT
fruit_name
FROM
fruit
WHERE
LENGTH(fruit_name) = 3
;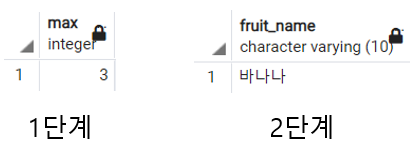
과일 이름 길이가 최대인 데이터를 성공적으로 찾았다. 그런데 이 간단한 작업을 두 번의 쿼리에 걸쳐 작성해야한다니, 조금 불편하다. 그래서 우리는 서브쿼리를 사용한다.
서브쿼리는 하나의 쿼리 안에 작성된 또 다른 쿼리를 의미한다.
2) 서브쿼리 동작
위와 같은 작업을 하나의 쿼리로 완성해보자. 서브쿼리는 소괄호 안에 작성한다.
-- 서브쿼리를 이용해 하나의 쿼리로 작성하기
SELECT
fruit_name
FROM
fruit
WHERE
LENGTH(fruit_name) = (
SELECT
MAX(LENGTH(fruit_name))
FROM
fruit
)
;
서브쿼리가 있을 때 SQL은 서브쿼리를 먼저 수행한다. 위 쿼리에서는 길이가 최대인 값을 먼저 찾고, 그 다음에 서브쿼리 결과를 조건에 넣어 본 쿼리를 수행한다.
3-2. IN과 EXISTS
1) IN
지난주, SQL 기초 시간에 IN 연산자에 대해 배웠다. IN 연산자는 조건으로 제시되는 집합에 특정 어트리뷰트 값이 존재하면 반환하는 연산자이다. 다음 절에 나올 EXISTS를 이해하기 위해서 IN의 동작 방법을 이해할 필요가 있다. 아래 예시를 통해 IN 연산자의 내부 동작을 살펴보자.
-- IN 연산자 사용하기
SELECT *
FROM
snack
WHERE
snack_no IN (
SELECT
fruit_no
FROM
fruit
)
;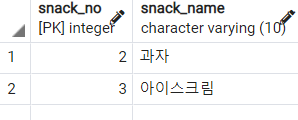
우선 위 쿼리를 해석하면, "fruit 테이블의 fruit_no와 snack 테이블의 snack_no가 동일한 데이터를 조회하라"이다. 서브쿼리의 결과를 기반으로 snack_no와 비교하여 데이터를 조회한다.
IN 연산자의 동작은 아래와 같다.(EXISTS와 동작 방법이 다르므로 주의!)
- 서브 쿼리에 먼저 접근하여 데이터를 조회한다.
- 본 쿼리의 튜플을 하나씩 접근하여 서브 쿼리 결과와 비교하여 True/False를 판단한다.
IN 연산자는 서브쿼리에 먼저 접근한다을 잘 기억하자.
2) EXISTS
이번에는 IN에서 수행한 작업을 EXISTS를 사용하여 수행해보자.
-- EXISTS의 부정확한 사용
SELECT *
FROM
snack s
WHERE EXISTS (
SELECT
fruit_no
FROM
fruit f
)
;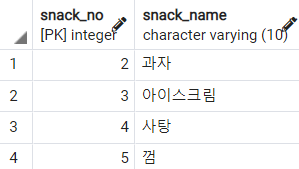
뭔가 이상하다. snack 테이블의 모든 데이터가 조회됐다. 왜그럴까? EXISTS의 동작은 아래와 같다.
- 튜플 하나 접근
- 서브 쿼리와 조인하여 결과 값이 있으면 반환, 없으면 pass
위 쿼리를 살펴보면, 우선 (2, 과자), (3, 아이스크림), (4, 사탕)...과 같이 튜플에 접근하고 서브쿼리를 확인한다. 그런데 서브쿼리는 항상 fruit 일련번호가 나오는 쿼리이므로, 모든 튜플이 반환되는 것이다.
그렇다면 우리가 최초에 수행하고자 했던 작업을 수행해보자.
-- EXISTS의 정확한 사용
SELECT *
FROM
snack s
WHERE EXISTS (
SELECT
fruit_no
FROM
fruit f
WHERE
s.snack_no = f.fruit_no
)
;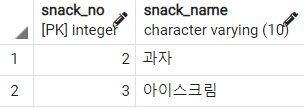
(2, 과자)에 먼저 접근하고, 서브쿼리를 실행한다. (2, 과자)와 fruit 테이블을 JOIN하면 그 결과로 튜플이 하나 이상 나오기 때문에 본 쿼리에서 (2, 과자)는 반환된다. (3, 아이스크림)도 마찬가지로 서브쿼리 결과로 반환되는 튜플이 있기 때문에 본 쿼리 결과로 반환된다.
(4, 사탕)은 어떨까? (4, 사탕)과 서브쿼리를 조인하면, fruit 테이블에는 일련번호가 4인 테이터가 없기 때문에 서브쿼리 결과가 아무 것도 안나온다. 따라서 (4, 사탕)은 본 쿼리에서 pass된다.
출처 : IN, EXISTS 차이, 내 블로그
