1. 정규화
1-1. 이상현상(anomaly)
1) 정규화가 필요한 이유, 이상현상
지금까지 관계형 DBMS에서는 테이블을 여러 개로 나눠 저장했다. 그런데 하나의 테이블에 모든 데이터를 저장하면 더 편리하지 않을까? 모든 데이터를 하나의 테이블에 저장했을 때 생기는 문제를 알아보자. 학생정보시스템이 아래와 같이 구성되어있다고 가정해보자.
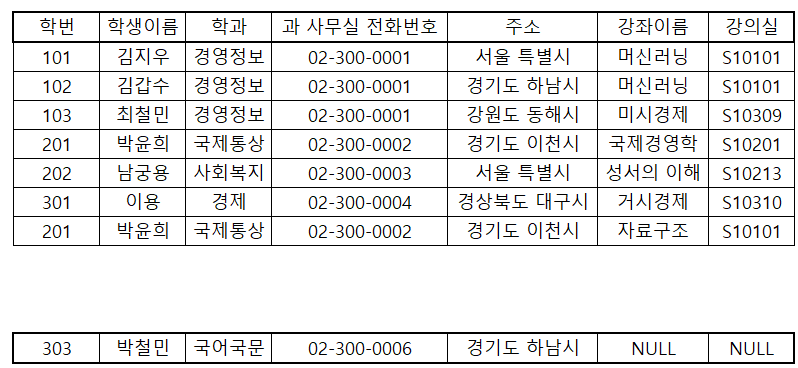
위와 같은 원본 테이블이 있다고 가정하자. 이 테이블에 삭제(DELETE), 변경(UPDATE), 삽입(INSERT) 동작을 할 때 어떤 문제가 발생할 수 있을까?
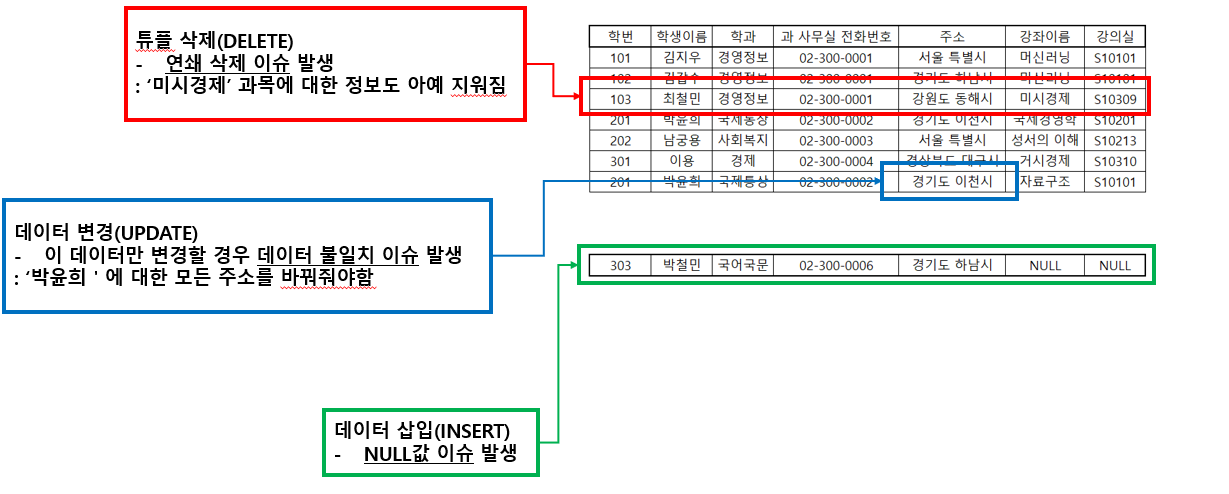
위와 같이 삭제 이상, 수정 이상, 삽입 이상이 발생하는 현상을 이상현상(anomaly)라고 하며, 이 때문에 하나의 테이블에 모든 데이터를 담으면 안되고, 이런 이상현상을 피하기 위해 정규화를 진행해야 한다. 아래에서 실제 데이터로 확인해보자.
2) SQL로 확인하는 이상현상
DROP TABLE IF EXISTS sample;
CREATE TABLE sample(
index SERIAL -- 기본키 설정을 위해 임의로 설정
, stno INT
, stname VARCHAR(4)
, major VARCHAR(8)
, calling VARCHAR(11)
, address VARCHAR(20)
, lecture VARCHAR(10)
, room VARCHAR(6)
)
;
INSERT INTO sample(stno, stname, major, calling, address, lecture, room)
VALUES
(101, '김지우', '경영정보', '02-300-0001', '서울특별시', '머신러닝', 'S10101')
, (102, '김갑수', '경영정보', '02-300-0001', '경기도 하남시', '머신러닝', 'S10101')
, (103, '최철민', '경영정보', '02-300-0001', '강원도 동해시', '미시경제', 'S10309')
, (201, '박윤희', '국제통상', '02-300-0002', '경기도 이천시', '국제경영학', 'S10201')
, (202, '남궁용', '사회복지', '02-300-0003', '서울특별시', '성서의 이해', 'S10213')
, (301, '이용', '경제', '02-300-0004', '경상북도 대구시', '거시경제', 'S10310')
, (201, '박윤희', '국제통상', '02-300-0002', '경기도 이천시', '자료구조', 'S10101')
;
- 삭제이상
'미시경제'는 어느 강의실에서 진행되는지 쿼리를 짜서 확인해보자.
-- 미시경제가 어느 강의실에서 진행되는지 확인하기
SELECT
lecture
, room
FROM
sample
WHERE
lecture = '미시경제'
;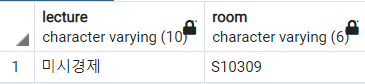
미시경제는 S10309에서 진행됨을 알 수 있다. 이제 최철민 학생을 제거하고, 동일하게 미시경제가 어느 강의실에서 진행되는지 확인해보자.
-- 최철민 학생 제거
DELETE FROM sample
WHERE
stname = '최철민'
;
-- 미시경제가 어느 강의실에서 진행되는지 확인하기
SELECT
lecture
, room
FROM
sample
WHERE
lecture = '미시경제'
;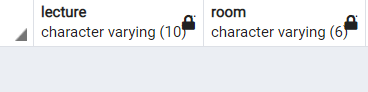
최철민 학생을 제거했을 뿐인데, 미시경제가 어느 강의실에서 진행되는지까지 지워졌다. 이런 이상현상을 삭제이상이라고 한다.
- 수정 이상
'박윤희' 학생이 '경기도 천안시'로 이사를 갔다고 해보자. 따라서 박윤희 학생의 주소를 바꾸려 하는데, 실수로 하나만 바꿨다고 하자.
-- 박윤희 학생 주소 변경
UPDATE
sample
SET
address = '경기도 천안시'
WHERE
stname = '박윤희'
AND lecture = '자료구조' -- 설명을 위해 강의명을 조건으로 추가함
;
-- 박윤희 학생 주소 확인
SELECT
stno
, stname
, address
, lecture
FROM
sample
WHERE
stname = '박윤희'
;
UPDATE 조건으로 이름만 제시하면 되지만, 설명을 위해 강의명도 조건으로 추가했다. 위 결과를 보면 박윤희는 한 사람인데 주소가 서로 다르다. 이런 이상현상을 수정이상(=갱신이상)이라고 한다.
- 삽입이상
다른학교에서 '박철민'학생이 편입을 했다고 하자. 그래서 이 학생의 데이터를 추가하고자 한다.
-- '박철민' 학생 데이터 추가
INSERT INTO sample(stno, stname, major, calling, address, lecture, room)
VALUES
(303, '박철민', '국어국문', '02-300-0006', '경기도 하남시', NULL, NULL)
;
-- 결과 확인
SELECT
*
FROM
sample
;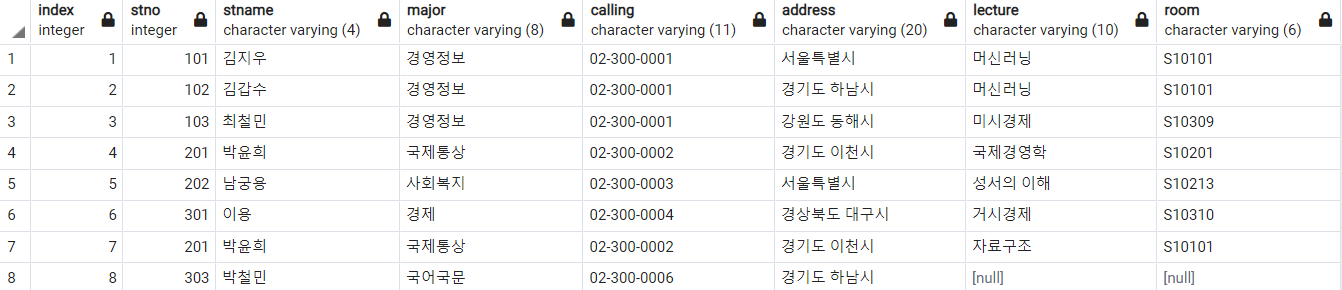
박철민 학생 데이터가 추가되긴 했으나, 뭔가 이상하다. 교과목과 강의실이 모두 NULL이다. 이 경우 제약조건에 위배되는 것은 아니지만, 테이블이 더러워진다. 이런 이상현상을 삽입이상이라고 한다.
1-2. 결정자와 함수적 종속성
1) 결정자(determinant)
어떤 속성이 다른 속성의 값을 결정할 수 있으면 그 속성을 결정자(determinant)라고 한다. 속성 값을 결정한다는 것은, 그 속성의 값을 알고 있으면 다른 속성도 연쇄적으로 알 수 있는 경우를 이야기한다.
앞서 살펴봤던 학생정보시스템 데이터에서 결정자에 대해 생각해보자.

위 테이블에서 학번을 알면 학생 이름을 알 수 있다.(물론 학과, 주소도 알 수 있다.) 그런데 동명이인이 있을 수도 있으므로 학생 이름을 안다고 하더라도 주소를 알 수는 없다. 마찬가지로 강의실을 안다고 해도 강좌이름을 알 수는 없다.(동일한 강의실을 사용하는 강좌가 여러 개 있음)
이처럼 특정한 속성이 결정되면, 다른 속성들도 전부 알 수 있는 것을 결정자라고 한다. 학생 테이블에서는 학번, 강의 테이블에서는 강좌번호가 결정자이다. 결정자는 화살표(→)로 표시한다. 이 때 화살표 오른쪽에 있는 속성은 '종속속성'이라 한다. 위 관계를 결정자로 표시하면 아래와 같다.
- 학번 → 학생이름
- 학번 → 학과
- 학번 → 주소
- 강좌이름 → 강의실
- 학과 → 과 사무실 전화번호
2) 함수적 종속성
학번이 학생이름의 결정자임을 위에서 살펴보았다. 이 때 학생이름은 학번에 함수적으로 종속한다고 표현한다. 결정자에는 반드시 한 개의 종속속성이 대응됨을 기억하자.
정규화의 목적은 완전 함수 종속성을 만들어주는 것이 목표이다. 그리고 제거해야할 함수 종속성은 부분 함수 종속성, 이행 함수 종속성이다. 이 틀이 매우매우 중요하다. 위에서 살펴본 학생 정보 시스템 데이터를 생각해보자.

-
완전 함수 종속성 : 복합키로 지정되어있는 기본키의 경우, 부분집합이 결정자가 되면 안된다.
예를 들어 기본키가 (학번, 강좌이름)이라고 할 때, 강좌이름 → 강의실이 성립한다. 기본키의 부분집합인 강좌이름이 결정자가 되므로 이 테이블은 완전 함수 종속성을 만족하지 못한다. -
부분 함수 종속성 : 위와 같이 기본키의 부분집합이 결정자일 때를 의미한다. 결정자 표시 방법에 의하면 다음과 같다.
-
이행 함수 종속성 : 종속속성이 다른 속성의 결정자가 되는 경우를 의미한다. 결정자 표시 방법에 의하면 다음과 같다.
3) 이상현상이 발생하는 경우
(꼭 외우자) 이상현상은 기본키가 아니면서 결정자인 속성이 테이블에 있을 때 발생한다. 학생 정보 시스템에서 이상현상은 왜 발생했을까? 바로 (강좌이름 → 강의실)이 포함되어있기 때문이다. 강좌이름은 해당 테이블에서 기본키는 아니면서 강의실을 결정한다. 따라서 이상현상 발생의 주 원인이 되었다.
1-3. 정규화 과정
1) 제 1정규형
정규화란 이상현상이 발생하는 테이블을 분해하여 이상현상을 없애는 과정이다. 함수 종속성에 따라 등급으로 구분하며 정규형 수준이 높을 수록 이상현상이 많이 줄어든다. 가장 낮은 차원의 정규화가 제 1정규형이다.
제 1정규형은 모든 속성 값이 원자값을 가지면 만족한다. 따라서 학생정보시스템은 이미 제 1정규형을 만족한 상태였다. 그런데 데이터 무결성 제약조건 중 도메인 제약조건에 의해 이미 원자값으로 이루어져 있을 것이다. 기억이 나지 않으면 여기를 참고하면 된다.
2) 제 2정규형
제 1정규형을 만족하고 기본키가 아닌 속성이 기본키에 완전 함수 종속일 때 제 2 정규형이라고 한다. 다시 말하면 제 1정규형을 만족하고 부분 함수 종속성이 없다면 제 2 정규형을 만족한다.
학사정보시스템을 제 2정규형에 맞춰 분할해보자.

3) 제 3정규형
제 2정규형을 만족하고 이행 함수 종속성이 없다면 제 3정규형을 만족한다.
학사정보시스템에서는 (학번 → 학과 → 과 사무실 전화번호)가 이행 함수 종속성에 해당되므로 속성들을 나눠주면 된다.
제 3정규형에 맞춰 분할해보자.
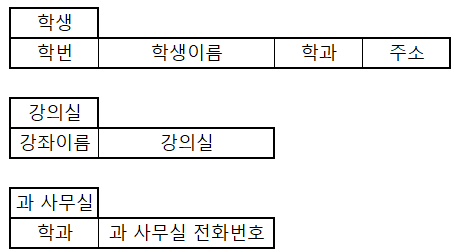
이렇게 분할한 후 기본키를 추가해주고 외래키를 지정해주면 관계형 DBMS에서 사용할 수 있는 테이블들이 된 것이다.
4) BCNF
BCNF는 제 3정규형을 조금 더 강화한 정규화 단계이다. 제 3정규형을 만족하고 모든 결정자가 후보키로 설정되어야 한다. 아래와 같은 테이블이 있다고 해보자. 강좌와 담당 교수는 1대 1 대응 된다고 가정하자.
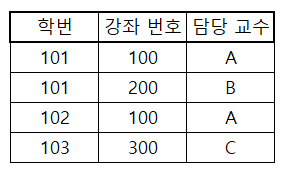
위 테이블에서 후보키는 (학번, 강좌 번호)와 (학번, 담당 교수)이다. 가정에 따라 담당 교수를 알면 강좌 번호도 알 수 있다.(역도 성립) 그런데 문제는 담당 교수는 후보키가 아니라는 것이다. 따라서 BCNF를 만족시키기 위해 테이블을 분할한다.
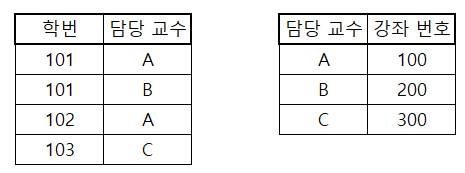
위와 같이 분할해주면 BCNF까지 만족하는 데이터베이스가 된다!
참고 : 정규형
5) 제 4정규형 ~ 제 6정규형
정규화 과정 중 최고 단계는 제 6정규형이다. 그런데 사실 BCNF까지만 만족하더라도 운영하는 데에 큰 문제가 없다. 따라서 보통 정규화 단계는 BCNF에서 멈춘다.
