쉘 정렬
쉘 정렬은 삽입 정렬의 일반화된 형태로, 데이터의 정렬 속도를 높이기 위해 고안된 정렬 알고리즘이다. 삽입 정렬은 데이터가 거의 정렬된 상태에서 빠르게 동작하지만, 데이터가 무작위로 배치된 경우에는 성능이 떨어진다. 쉘 정렬은 이를 개선하기 위해 데이터를 부분적으로 정렬(partially sorted)하는 과정을 거친 후, 최종적으로 삽입 정렬을 적용한다.
삽입 정렬의 문제점
삽입 정렬은 인접한 요소를 비교하며 정렬하기 때문에, 정렬 대상이 멀리 떨어진 위치에 있는 요소를 올바른 위치로 이동시키려면 많은 교환(혹은 이동)이 필요하다.
예를 들어, 작은 값이 맨 뒤에 있을 경우, 맨 앞의 위치로 이동하려면 한 칸씩 이동하며 비교해야 하므로 연속적인 이동이 반복된다.
쉘 정렬에서의 개선
쉘 정렬은 간격(gap)을 사용하여 비교하므로, 초기에는 리스트의 멀리 떨어진 요소들끼리 먼저 정렬된다.
예를 들어, 간격이 크다면 멀리 떨어진 값들 간의 정렬을 통해 데이터가 대략적으로 정렬된 상태로 변한다.
이후 간격을 점차 줄이면서 정렬 범위를 좁히면, 각 값이 삽입될 위치에 더 가까워진 상태에서 비교/교환이 이뤄진다.
마지막에 간격이 1인 경우가 되면 삽입 정렬과 수행하는 것은 똑같지만, 거의 정렬이 완료된 상태이므로 굉장히 빠르게 수행된다.
장점 VS 단점
장점
- 데이터가 무작위로 분포되어 있어도 삽입 정렬보다 빠르게 동작한다.
- 간단한 구현에 비해 상당히 효율적이다.
단점
- 간격을 선택하는 방법에 따라 성능이 크게 달라질 수 있다.
- 안정적인 정렬 알고리즘이 아니다.(동일한 값의 순서가 보장되지 않음)
알고리즘 개념
1. 간격(gap) 설정
- 리스트를 일정한 간격으로 나눠 부분 리스트를 생성한다.
- 간격이 클수록 비교 요소가 리스트 전체에 퍼져 있으므로, 정렬의 전체적인 형태를 잡아준다.
- 간격은 항상 홀수로 지정한다. (짝수인 경우 골고루 정렬되지 않는 단점이 있음)
2. 부분 리스트 정렬
- 각 간격에 따라 나눠진 부분 리스트를 삽입 정렬로 정렬한다.
3. 간격 축소
- 간격을 줄이고 다시 삽입 정렬을 수행한다.
- 간격이 1이 되면, 즉 모든 요소를 대상으로 삽입 정렬을 수행한다.
쉘 정렬의 전체 과정
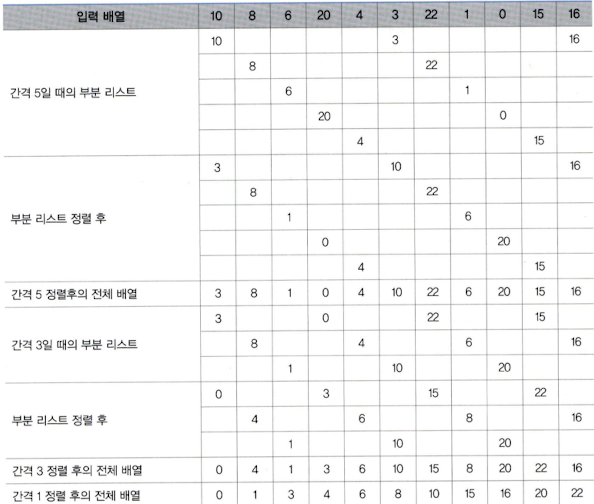
10, 8, 6, 20, 4, 3, 22, 1, 0, 15, 16 이렇게 데이터가 주워졌을 때 정렬되는 과정이다. 각 간격에 맞춰 버블 정렬을 수행하고, 간격이 1이 될 때까지 반복하여 최종적으로 정렬하는 모습을 볼 수 있다.
전체 코드
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX_SIZE 10
int n;
void print_sort(int list[], int n) {
int i;
for (i = 0; i < n; i++)
printf("%d ", list[i]);
printf("\n");
}
void inc_insertion_sort(int list[], int first, int last, int gap) {
int i, j, key;
for (i = first + gap; i <= last; i = i + gap) {
key = list[i]; // gap만큼 떨어져 있는 키와 비교
for (j = i - gap; j >= first && list[j] > key; j = j - gap)
list[j + gap] = list[j];
list[j + gap] = key;
}
}
void shell_sort(int list[], int n) {
int i, gap;
for (gap = n / 2; gap > 0; gap = gap / 2) {
if ((gap % 2) == 0) gap++; // gap은 홀수일 때 더 성능 좋음
for (i = 0; i < gap; i++)
inc_insertion_sort(list, i, n - 1, gap);
printf("gap=%d ", gap);
print_sort(list, n);
}
}
int main(void) {
int list[] = { 10, 8, 6, 20, 4, 3, 22, 1, 0, 15, 16 };
shell_sort(list, 11);
return 0;
}시간 복잡도 VS 공간 복잡도
시간 복잡도
- 최악: 간격이 적절하지 않은 경우 이다.
- 평균: 간격을 잘 선택한 경우 이다.
- 최선: 이미 정렬에 가까운 경우 이다.
공간 복잡도
추가 메모리를 거의 사용하지 않은 제자리 정렬이므로 공간 복잡도는 이다.
출처
C언어로 쉽게 풀어쓴 자료구조 - 천인구
