우선순위 큐
우선순위 큐는 말 그대로 우선순위를 가진 큐이다. 원래의 큐는 선입선출(FIFO) 원칙에 의하여 먼저 들어온 데이터가 먼저 나가게 된다. 하지만 우선순위 큐에서는 우선 순위가 높은 데이터가 먼처 출력된다.
우선순위 큐는 사실 가장 일반적인 큐라 할 수 있는데 스택이나 큐도 우선순위 큐를 사용하여 얼마든지 구현할 수 있기 때문이다.
우선순위 큐의 응용 분야는 다음과 같다.
- 시물레이션 시스템
- 네트워크 트래픽 제어
- 운영 체제에서의 작업 스케쥴링
- 데이터 압축: 허프만(Huffman) 코딩 알고리즘
- 최단 거리 알고리즘(Dijkstra 알고리즘), 최소 신장 트리 알고리즘(Prim 알고리즘)
우선순위 큐의 구현 방법
우선순위 큐를 구현하는 방법은 여러 가지가 있는데 배열, 연결 리스트, 히프 등을 이용하는 방법이 있다.
배열을 사용한 구현
배열을 사용해 구현하는 방법에는 정렬되지 않은 상태로 구현하는 방법과 정렬된 상태로 구현하는 방법이 있다.
정렬되지 않은 경우
- 항복들은 정렬되지 않은 상태로 배열에 삽입
- 삭제는 우선순위가 가장 높은 키를 검색한 뒤 삭제하는 방식으로 연산
- 삽입 복잡도: O(1), 삭제 복잡도: O(n)
정렬된 경우
- 항목들은 키 값에 따라 정렬되어 배열에 삽입
- 삽입 위치를 찾기 위해 순차탐색, 이진탐색 등을 이용
- 삭제는 한쪽 끝에서만 수행(우선순위가 젤 높음)
- 삽입 복잡도: O(n), 삭제 복잡도: O(1)
연결 리스트를 사용한 구현
연결 리스트 역시 정렬되지 않은 방법과 정렬된 방법이 있다.
정렬되지 않은 경우
- 삽입/삭제 시 배열 구현과 유사
- 배열에서 리스트로 자료구조가 바뀐것 뿐
- 삽입 복잡도: O(1), 삭제 복잡도: O(n)
정렬된 리스트 구현

- 항목들은 키 값에 따라 정렬되어 리스트에 삽입
- 삭제는 한쪽 끝에서만 수행
- 삽입 복잡도: O(n), 삭제 복잡도: O(1)
힙(heap)을 사용하는 방법
힙이란 완전 이진 트리의 일종으로 우선순위 큐를 위하여 특별히 만들어진 자료구조이다. 히프는 “느슨한 정렬” 상태를 유지한다. 즉, 완전히 정렬된 것은 아니지만 정렬이 아예 안 된 것도 아니라는 뜻이다.
힙의 시간 복잡도는 다음과 같다.
- 삽입의 시간 복잡도:
- 삭제의 시간 복잡도:
- 최소값 또는 최대값을 찾는 복잡도:
삽입과 삭제의 시간 복잡도가 인 이유는 최악의 경우 트리의 가장 아래 레벨까지 내려가야 하는데 완전 이진 트리의 높이는 이기 때문이다.
단말 노드가 존재하는 마지막 레벨을 제외하고는 각 레벨마다 개의 노드가 존재한다.
우선순위 큐는 힙을 이용하여 구현하는 것이 가장 효율적이다. 그러므로 힙에 대해 알아보고자 한다.
힙(heap)
힙은 더미라는 뜻으로 여러개의 값들 중에서 가장 큰 값이나 가장 작은 값을 빠르게 찾아내도록 만들어진 자료구조이다. 간단히 말하면 부모 노드의 키 값이 자식 노드의 키 값도 항상 큰 완전 이진 트리(complete binary tree)를 말한다. 힙의 부모 노드와 자식 노드 간에 다음과 같은 조건이 항상 성립하는 트리이다.
아래는 힙 트리를 그림으로 표현한 것이다.
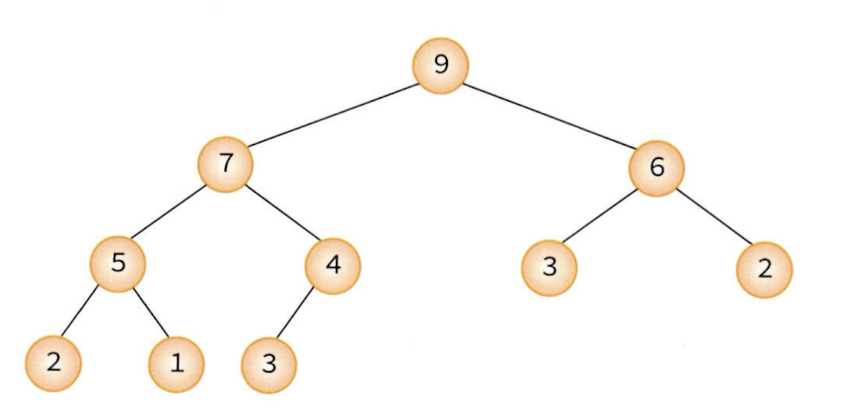
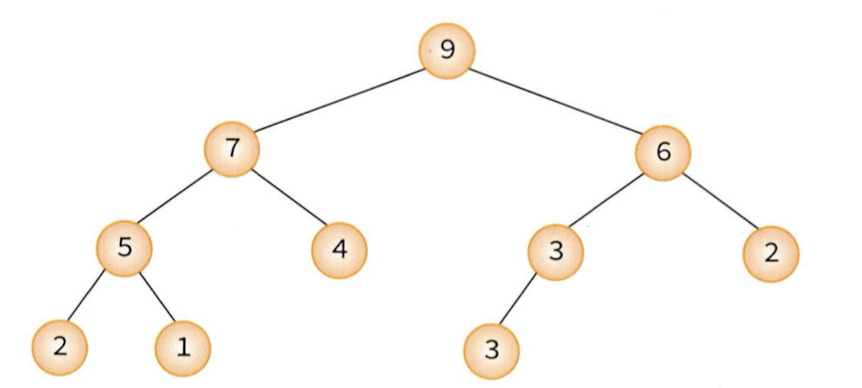
힙은 완전 이진 트리라고 하였기 때문에 아래는 힙이 아니다.
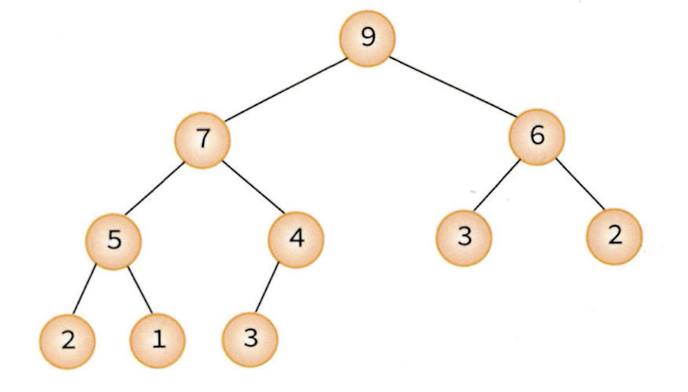
힙의 종류
힙에는 두 가지의 힙 트리가 존재한다.
- 최대 힙(Max heap): 부모 노드의 키 값이 자식 노드의 키값보다 크거나 같은 완전 이진 트리
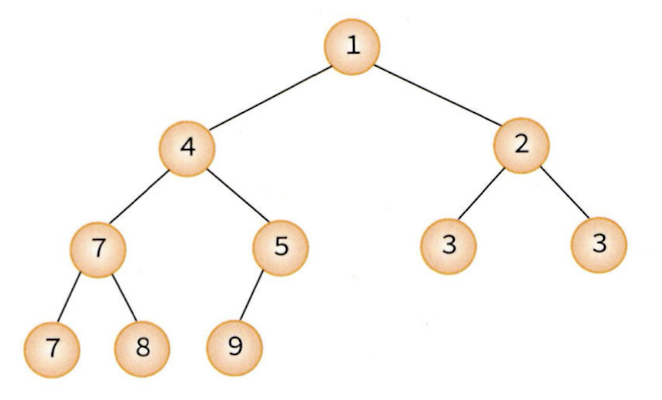
- 최소 힙(min heap): 부모 노드의 키값이 자식 노드의 키값보다 작거나 같은 완전 이진 트리
힙의 구현
힙은 완전 이진 트리이기 때문에 각각의 노드에 차례대로 번호를 붙일 수 있다. 이 번호를 배열의 인덱스로 생각하면 배열에 히프의 노드들을 저장할 수 있다. 따라서 히프를 저장하는 표준적인 자료구조는 배열이다.
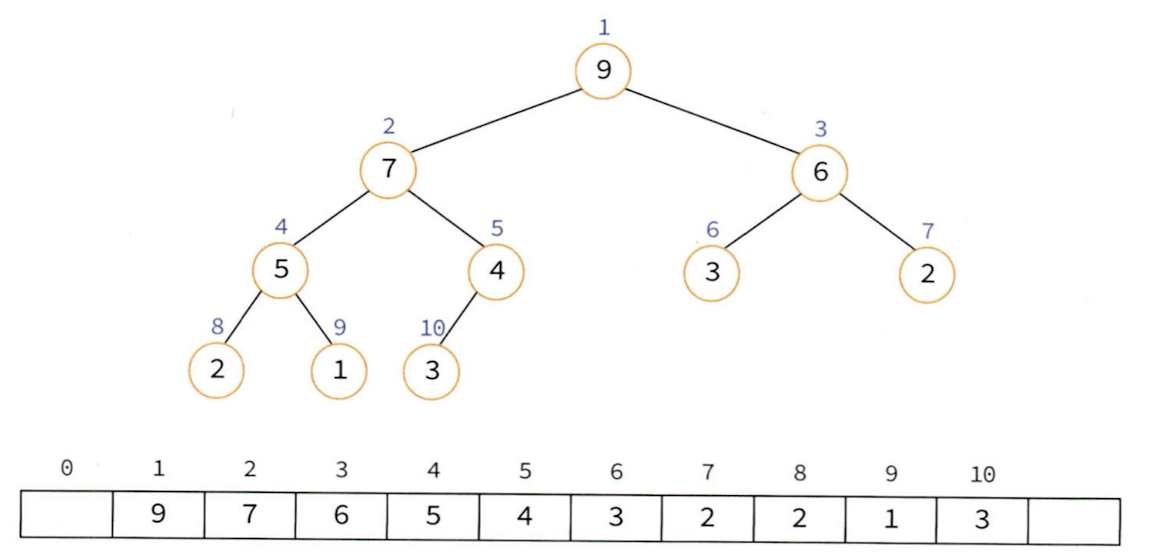
힙을 배열로 구현하면 생가는 장점은 부모노드와 자식노드를 찾기 쉽다는 점이다.
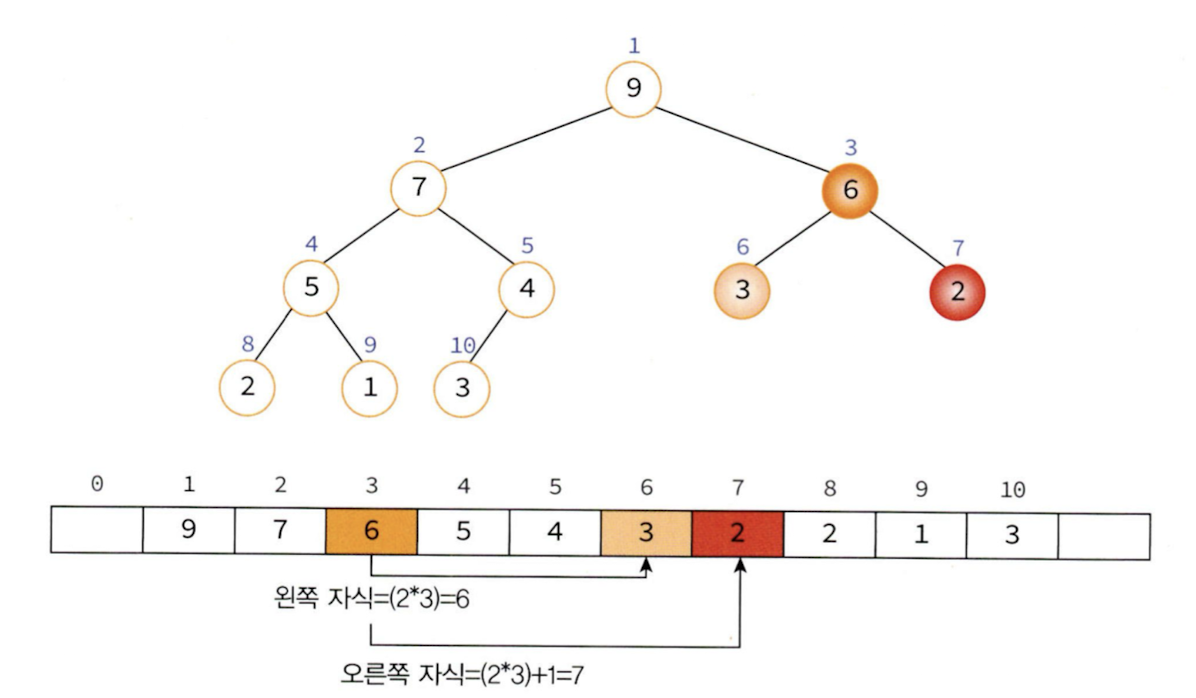
- 왼쪽 자식의 인덱스 = (부모의 인덱스) * 2
- 오른쪽 자식의 인덱스 = (부모의 인덱스) * 2 + 1
- 부모의 인덱스 = (자식의 인덱스) / 2
삽입 연산
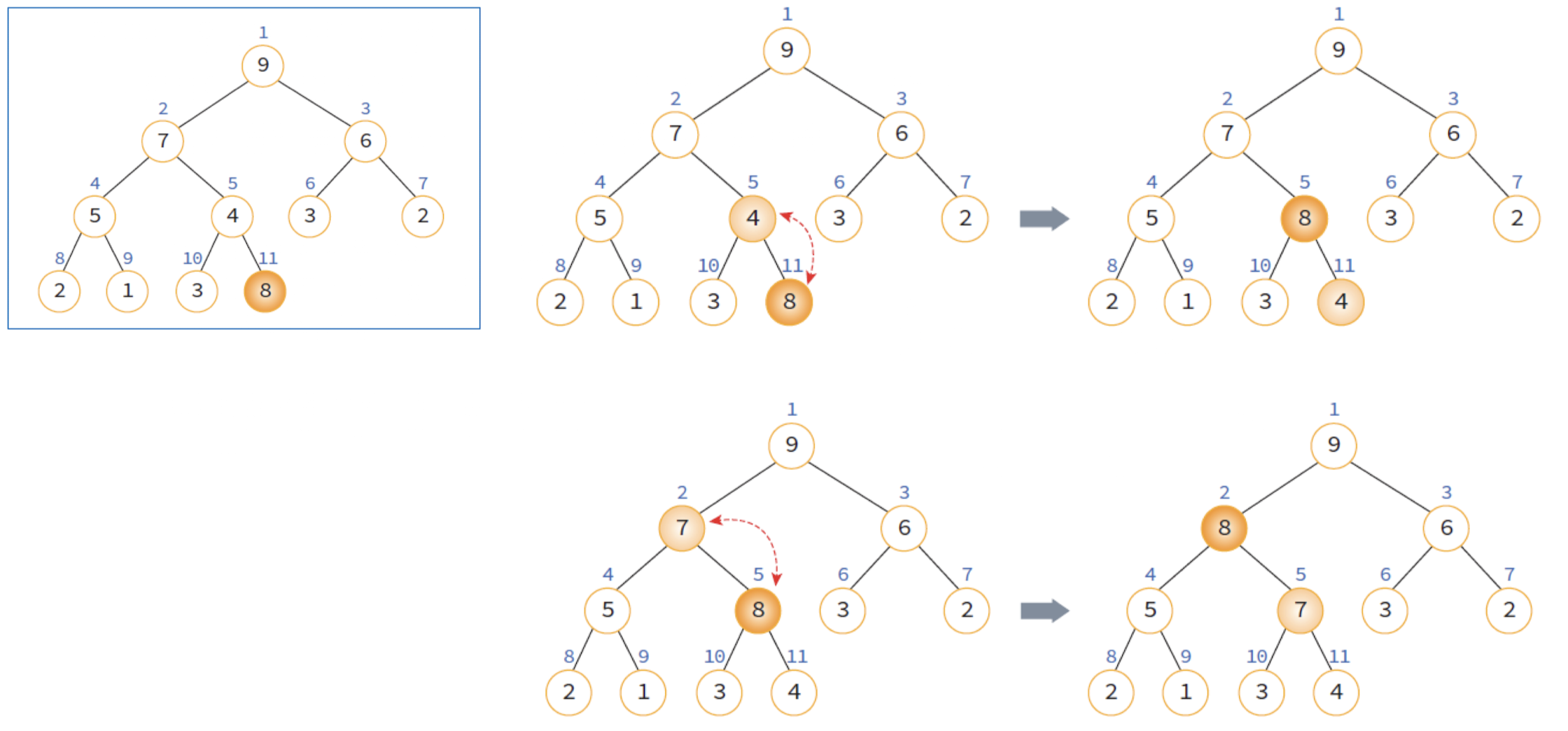
힙의 삽입 연산은 아래와 같은 순서로 진행된다.
- 힙에 새로운 요소가 들어오면, 일단 새로운 노드를 힙의 마지막 노드에 이어서 삽입
- 삽입 후에 새로운 노드를 부모 노드들과 교환해서 히프의 성질 만족 시켜주기
다음은 삽입 과정을 그림으로 나타낸 것이다.
아래는 코드로 구현한 것이다.
void insert_max_heap(HeapType* h, element item) {
int i;
i = ++(h->heap_size);
// 루트 노드이거나 자식 노드가 부모 노드보다 작다면 종료
while ((i != 1) && (item.key > h->heap[i / 2].key)) {
h->heap[i] = h->heap[i / 2]; // 부모 노드를 자식 노드에 복사
i /= 2; // 인덱스를 부모 노드로 바꿔줌
}
// 반복문을 탈출한 후에 새 데이터를 실제로 대입
h->heap[i] = item;
}코드로 구현할 때의 특징은 실제 값을 가장 마지막으로 할당한다는 점이다. 위 코드는 아래와 같은 순서로 삽입이 이뤄진다.
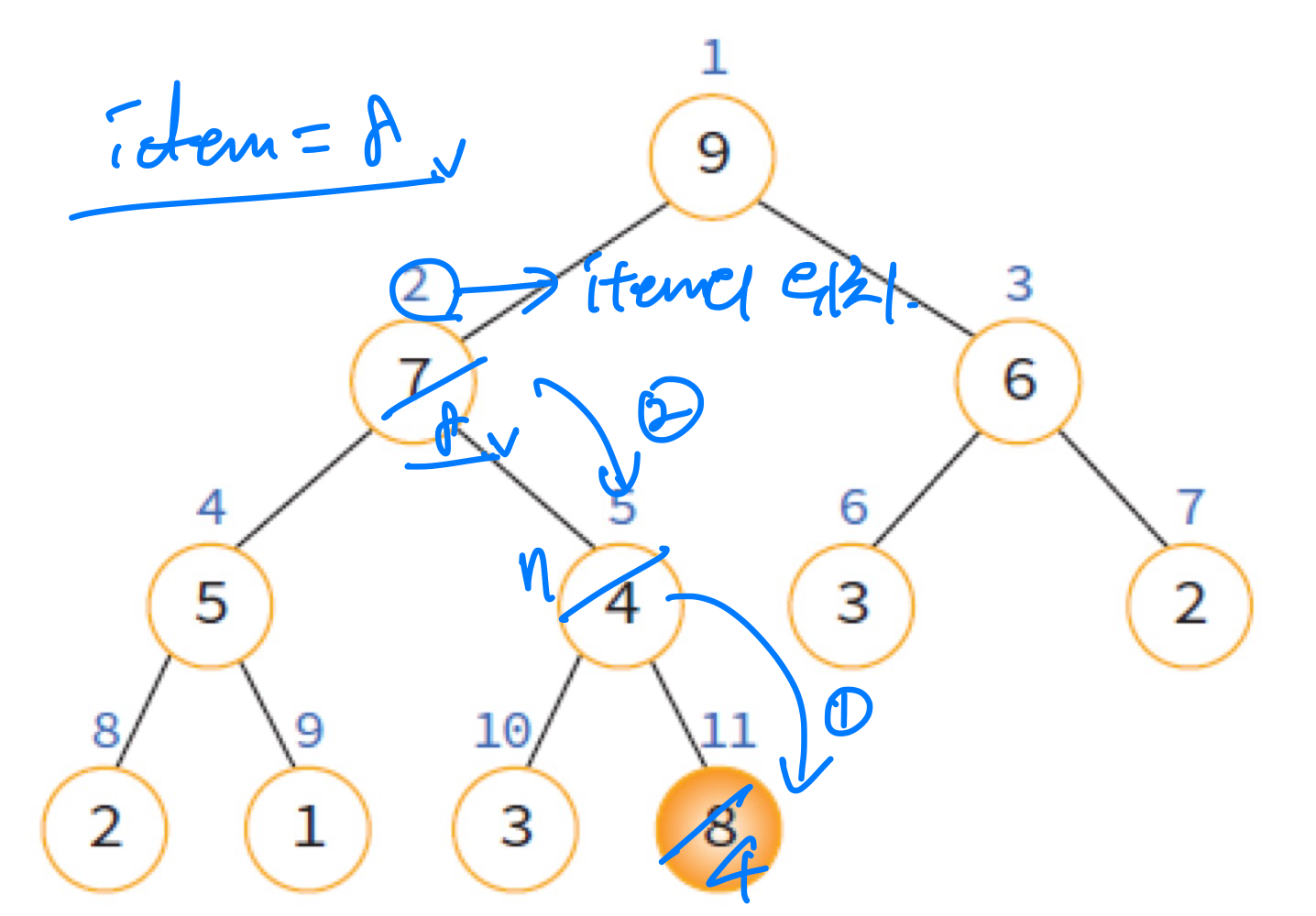
- 새 데이터를 제외한 가장 마지막 노드의 번호를 i에 저장
- i가 루트 노드의 인덱스가 되거나 새 데이터가 자식 노드보다 클 경우 반복문 종료
- 아직 자리를 찾지 못했다면, 부모 노드를 자식 노드에 저장하고 인덱스를 부모 노드로 바꿔줌
- 새 데이터를 저장할 위치를 찾았다면 가장 마지막에 데이터 저장
아래는 이 과정을 그림으로 나타낸 것이다.
삭제 연산
최대 힙에서 삭제 연산은 최대값을 가진 요소를 삭제하는 것이다. 최대 힙에서 최대값은 루트 노드이므로 루트 노드가 삭제된다. 삭제 연산은 다음 과정을 통해 진행된다.
- 루트 노드를 삭제한다.
- 마지막 노드를 루트 노드로 이동한다.
- 루트에서부터 단말 노드까지의 경로에 있는 노드들을 교환하며 히프 성질을 만족시킨다.
아래는 위 과정을 그림으로 나타낸 것이다.
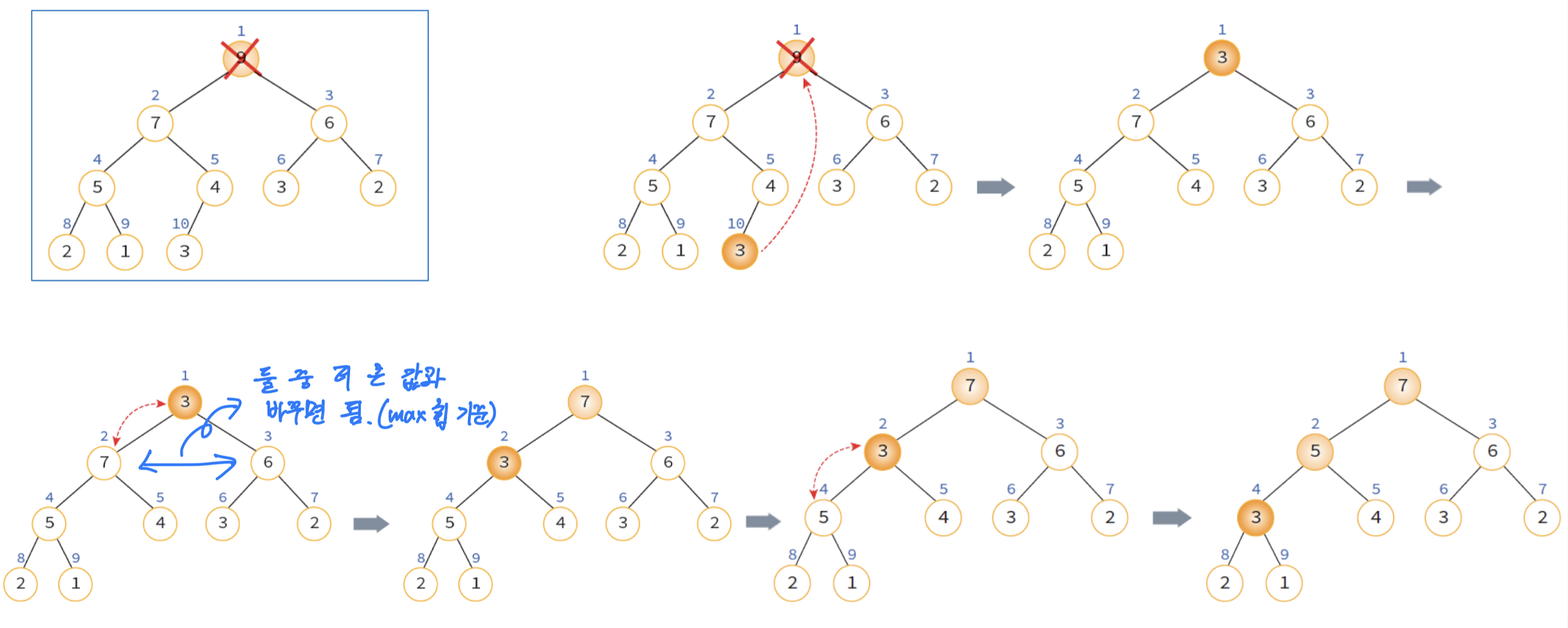
삭제 연산 코드
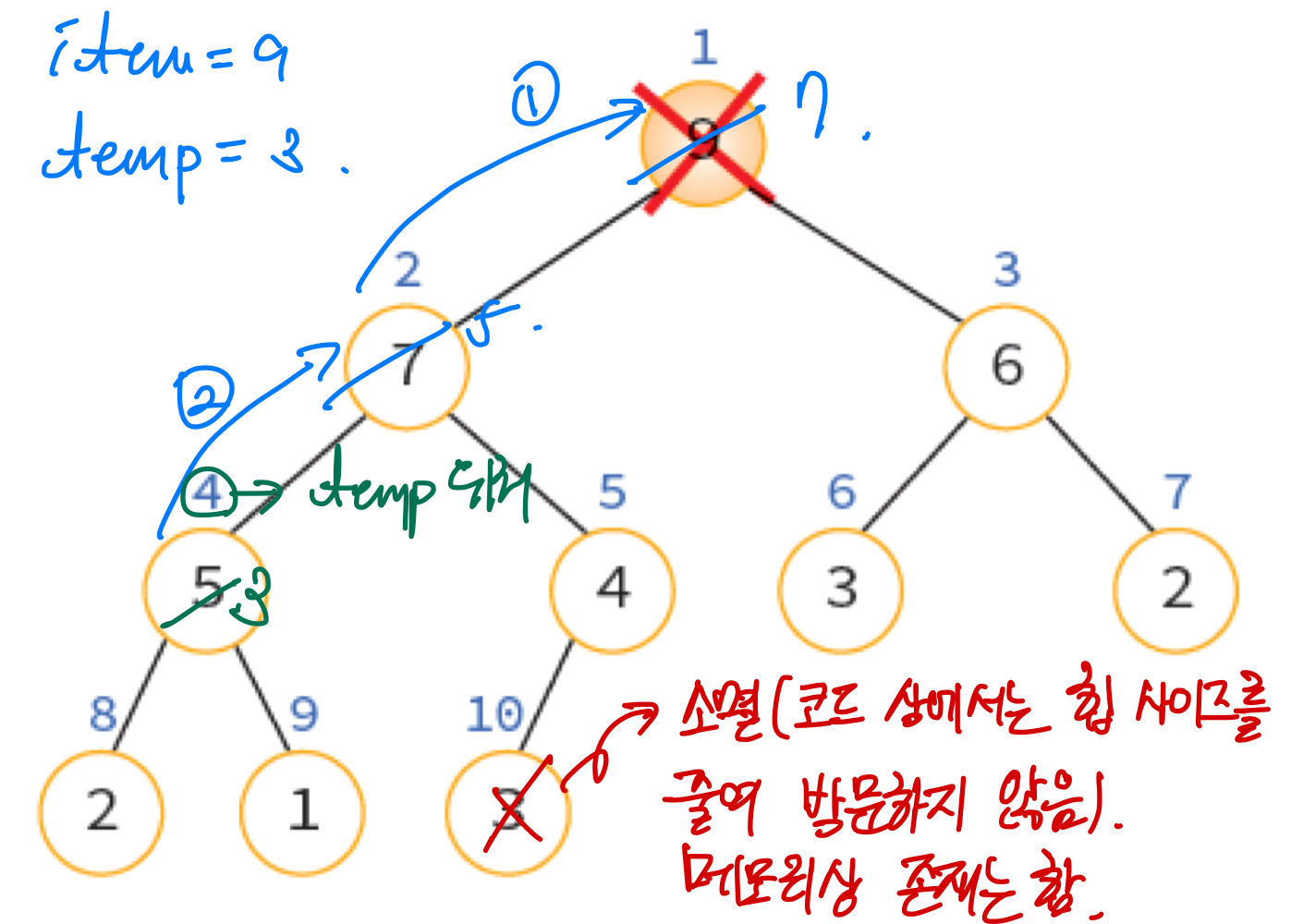
element delete_max_heap(HeapType* h) {
int parent, child;
element item, temp;
item = h->heap[1];
temp = h->heap[(h->heap_size)--];
parent = 1;
child = 2;
// 힙의 크기보다 벗어나서 할당될 수는 없기에
// child는 힙 크기보다 작을 때 반복
while (child <= h->heap_size) {
// 반복문과 다르게 등호가 없는 이유는 실제 할당을 해야 하기 때문
if ((child < h->heap_size)
// 왼쪽 자식 노드와 오른쪽 자식 노드 중 더 큰 값과 교환
&& (h->heap[child].key < h->heap[child + 1].key))
child++; // 오른쪽 자식 노드가 더 크다면 자식 인덱스 1 증가
// 마지막에 있던 단말 노드가 자식 노드보다 크다면 탈출
if (temp.key >= h->heap[child].key) break;
h->heap[parent] = h->heap[child]; // 부모 노드에 자식 노드 대입
parent = child; // 자식 노드가 더 크다면 부모 인덱스를 자식 인덱스 바꿈
child *= 2; // 자식 노드는 더 하위 자식 노드로 옮김
}
// 반복문 탈출 후 실제 값 대입
// 반복문은 할당할 위치만 찾아준거임
h->heap[parent] = temp;
return item;
}삭제 연산 역시 코드로 구현할 때는 인덱스의 위치를 반복문을 통해 찾아준 뒤 실제 할당은 반복문 탈출 후 이뤄진다.
아래는 위 과정을 그림으로 나타낸 것이다.
전체 프로그램
#include <stdio.h>
#include <stdlib.h>
#define MAX_ELEMENT 200
typedef struct {
int key;
} element;
typedef struct {
element heap[MAX_ELEMENT];
int heap_size;
} HeapType;
HeapType* create() {
return (HeapType*)malloc(sizeof(HeapType));
}
void init(HeapType* h) {
h->heap_size = 0;
}
void insert_max_heap(HeapType* h, element item) {
int i;
i = ++(h->heap_size);
// 루트 노드이거나 자식 노드가 부모 노드보다 작다면 종료
while ((i != 1) && (item.key > h->heap[i / 2].key)) {
h->heap[i] = h->heap[i / 2]; // 부모 노드를 자식 노드에 복사
i /= 2; // 인덱스를 부모 노드로 바꿔줌
}
// 반복문을 탈출한 후에 새 데이터를 실제로 대입
h->heap[i] = item;
}
element delete_max_heap(HeapType* h) {
int parent, child;
element item, temp;
item = h->heap[1];
temp = h->heap[(h->heap_size)--];
parent = 1;
child = 2;
// 힙의 크기보다 벗어나서 할당될 수는 없기에
// child는 힙 크기보다 작을 때 반복
while (child <= h->heap_size) {
// 반복문과 다르게 등호가 없는 이유는 실제 할당을 해야 하기 때문
if ((child < h->heap_size)
// 왼쪽 자식 노드와 오른쪽 자식 노드 중 더 큰 값과 교환
&& (h->heap[child].key < h->heap[child + 1].key))
child++; // 오른쪽 자식 노드가 더 크다면 자식 인덱스 1 증가
// 마지막에 있던 단말 노드가 자식 노드보다 크다면 탈출
if (temp.key >= h->heap[child].key) break;
h->heap[parent] = h->heap[child]; // 부모 노드에 자식 노드 대입
parent = child; // 자식 노드가 더 크다면 부모 인덱스를 자식 인덱스 바꿈
child *= 2; // 자식 노드는 더 하위 자식 노드로 옮김
}
// 반복문 탈출 후 실제 값 대입
// 반복문은 할당할 위치만 찾아준거임
h->heap[parent] = temp;
return item;
}
int main() {
element e1 = { 10 }, e2 = { 5 }, e3 = { 30 };
element e4, e5, e6;
HeapType* heap;
heap = create();
init(heap);
insert_max_heap(heap, e1);
insert_max_heap(heap, e2);
insert_max_heap(heap, e3);
e4 = delete_max_heap(heap);
printf("< %d > ", e4.key); // 30
e5 = delete_max_heap(heap);
printf("< %d > ", e5.key); // 10
e6 = delete_max_heap(heap);
printf("< %d > ", e6.key); // 5
free(heap);
return 0;
}
힙 정렬
최대 힙을 이용하면 정렬을 할 수 있다. 먼저 정렬해야 할 n개의 요소들을 최대 힙에 삽입하고, 한번에 하나씩 요소를 힙에서 삭제하면 저장하면 된다.
최소 힙으로 정렬할 경우 삭제되는 요소들은 값이 증가되는 순서이다.
힙 정렬의 시간 복잡도는 경우 요소의 개수가 n개이고, 힙 트리의 시간 복잡도는 이므로 이 된다.
아래는 힙 정렬을 구현한 코드이다.
// 위에 작성한 힙 코드에 이어서 작성
// 오름차순 정렬
void heap_sort(element a[], int n) {
int i;
HeapType* h;
h = create();
init(h);
for (i = 0; i < n; i++)
insert_max_heap(h, a[i]);
for (i = (n - 1); i >= 0; i--)
// 배열의 뒤에서부터 저장(최대 힙인 경우)
a[i] = delete_max_heap(h);
free(h);
}
#define SIZE 8
int main() {
element list[SIZE] = { 23, 56, 11, 9, 56, 99, 27, 34 };
heap_sort(list, SIZE);
for (int i = 0; i < SIZE; i++)
printf("%d ", list[i].key);
printf("\n");
return 0;
}출처
C언어로 쉽게 풀어쓴 자료구조 - 천인구
