오늘은 Image Compression 관련해서 CVPR 2024에 Accept되었던 논문 중 하나인 Generative Latent Coding for Ultra-Low Bitrate Image Compression에 대해서 리뷰해보도록 하겠습니다.
📌 Paper(CVF Open Access) Link :https://openaccess.thecvf.com/content/CVPR2024/papers/Jia_Generative_Latent_Coding_for_Ultra-Low_Bitrate_Image_Compression_CVPR_2024_paper.pdf
Introduction
Digital visual data들이 폭발적으로 증가하고 있는 추세에 따라, 어떻게 하면 효율을 극대화하면서 이미지를 압축할 수 있을지에 대한 관심 또한 증가하게 되었습니다. 이러한 이미지 압축 방식에는 JPEG과 같은 traditional compression 방식부터 최근 들어 주목받는 learned image compression model을 사용하는 방식까지 다양하게 있었는데요, 저자들은 이 중 대다수의 방식들이 pixel-space transform coding paradigm을 사용하고 있다고 말합니다.
💡 Pixel-space transform coding
이미지의 픽셀들을 transform module을 사용해서 comapct representation으로 변환해주는 coding❓ 왜 사용하나요?
중복되는 것을 제거해줌으로서 이후에 적용할 entropy coding process에 들어가는 bit cost를 감소시킬 수 있기 때문
Problem
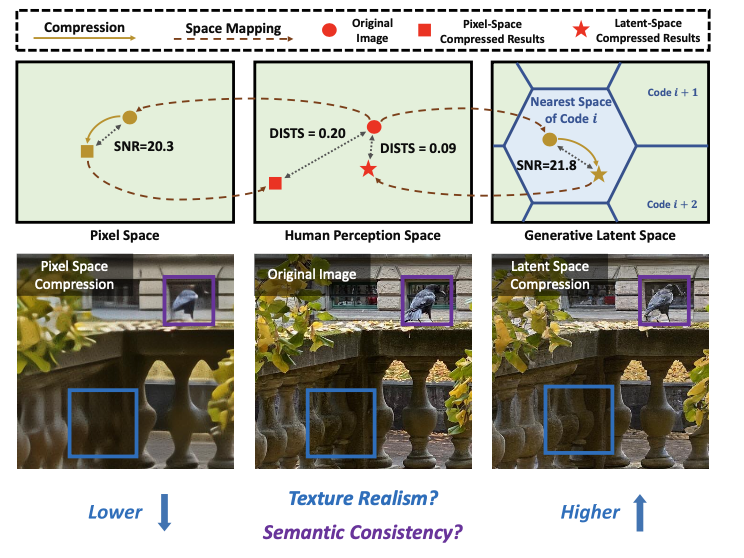
하지만 이에 대해 저자들은 실제 사람은 semantic consistency와 이미지의 texture realism을 우선시하는데, 이건 pixel-space transform module만으로는 적절하게 반영하기가 어렵다고 지적합니다.
즉, pixel-space에서 compression을 했을 때 발생하는 distortion들이 디지털 관점에서는 적절한 왜곡일지 몰라도, 인간의 인식(perception)의 관점에서 보았을 때는 어색하거나, 퀄리티가 떨어져보일 수도 있다는 의미입니다. 왜냐하면 우리 인간의 시각 체계 혹은 인식 체계는 중요시하는 정보들이 기계와는 다르기 때문이죠.
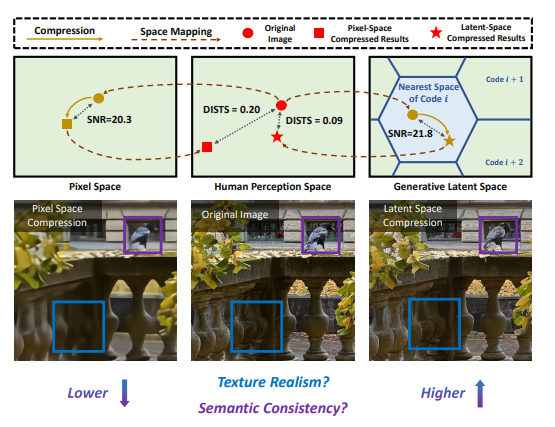
저자들은 특히나 low bitrate에서 이러한 문제가 크게 발생한다고 강조하는데요, 위의 사진 왼쪽에 보이는 그림처럼 pixel-space generative image codec(MS-ILLM)을 사용했을 경우 visual quality가 많이 떨어진 것을 확인할 수가 있습니다. 심지어 perceptual supervision이나 adversarial supervision과 같은 기법을 같이 사용했는데도 말이죠.
Bitrate?
어떤 데이터 혹은 정보를 전달할 때 필요한 비트 수라고 생각하면 됩니다. 따라서 이미지 압축 도메인에서 Low bitrate란 압축률을 높게 해서 이미지를 표현하는 비트 수를 많이 줄인 경우이지요.
그렇다면 어떻게 해야 인간의 인식(perception) 체계에 잘 맞게 이미지를 잘 압축할 수가 있을까요?
Solution
저자들이 제시하는 방법은 Generative Latent Coding, 즉 GLC입니다.
GLC의 기본적인 개념은 다음과 같습니다.
- 이미지를 human perception을 잘 반영하는 generative latent space로 Encoding
- 해당 latent space 안에서 transform coding을 실행
즉, transform coding을 pixel-space가 아닌 latent space에서 하겠다는거죠.
📌 그렇다면 가장 중요한 이 Latent Space는 어떻게 만들까?
이 논문에서는 Generative VQ-VAE를 이용하고, 세 가지의 장점을 제시합니다.
- VQ-VAE의 discrete code는 semantic visual component를 잘 반영할 수가 있음
- Generative VQ-VAE는 high-realism texture reconstruction을 하는데 매우 좋은 생성 능력을 가지고 있음
- Discrete variational bottleneck은 자연스럽게 compression에 적합한 낮은 엔트로피와 distortion-robust한 특성을 가지는 latent space를 만들어낼 수 있음
❓ Discrete variational bottleneck?
VQ-VAE에서는 연속적인 latent space를 discrete한 codebook의 벡터들로 mapping합니다. 이 때, 원본 데이터는 latent space와 codebook의 벡터들로 압축되면서 점점 훨씬 더 작은 공간으로 압축되는데, 이를 "bottleneck",즉 병목 현상이라고 부르곤 합니다.또한 최종적으로는 discrete한 형태를 띄며 이는 variational한 방법을 사용했기 때문에 Discrete variational bottleneck이란 말을 쓴 것 같습니다.
=> 결국 위와 같은 특성들 덕분에 GLC는 human perception에 더 잘 맞는 프레임워크가 될 수 있으며 훨씬 좋은 visual quality를 보여줄 수 있습니다.
이제 GLC를 구현할 때 염두해야하는 두가지 중요한 질문에 대해서 살펴보겠습니다.
1. 어떻게 generative latents를 효율적으로 압축할 것인가?
- VQ-VAE latent를 압축하는 가장 직관적인 접근은 indices-map coding
- 그러나 indices 간의 redundancy reduction이 비효율적이고 rate-variable coding support가 부족하기 때문에 한계가 존재
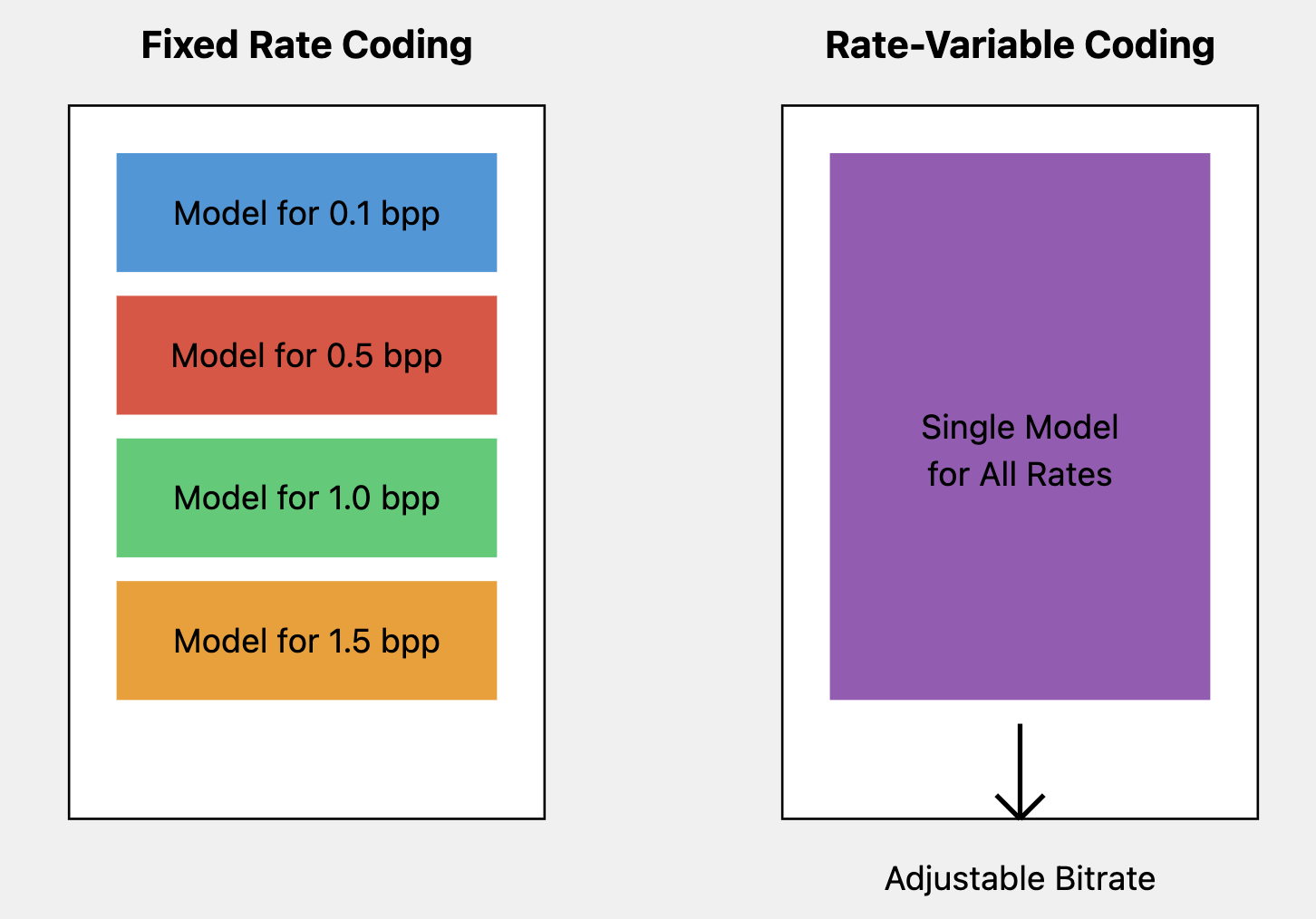
❓ rate-variable coding
하나의 compression 모델로 다양한 압축률(bitrate)을 달성할 수 있는 코딩 방식보통 compression 모델은 고정된 압축률(bitrate)을 가지기 때문에 다른 압축률을 달성하기 위해서는 다시 압축을 시켜야한다는 비효율성이 존재(Fix-rate coding)
이 때 rate-variable coding을 사용한다면 단일 모델로 다양한 bitrate를 달성할 수 있기 때문에 높은 효율성을 확보할 수 있음
- 따라서 novel generative-latent-space transform coding approach를 제안할 것
- 이 접근 방식은 높은 압축률에서 latent redundancy를 줄이기 위해 효율적인 rate-variable structure을 적용할 것
- 그리고 categorical hyper module을 소개하여 의 bitrate를 충분히 감소시킬 것
2. Generative latent coding을 어떻게 supervise할 것인가?
- 최근의 code prediction transformers로부터 영감을 받아서, a code-prediction-based supervision을 제안할 것
- 이게 학습 과정에서 홀로 적용된 auxiliary supervision으로서 역할을 하며 semantic consistency를 향상시킬 것
GLC Method
Overview
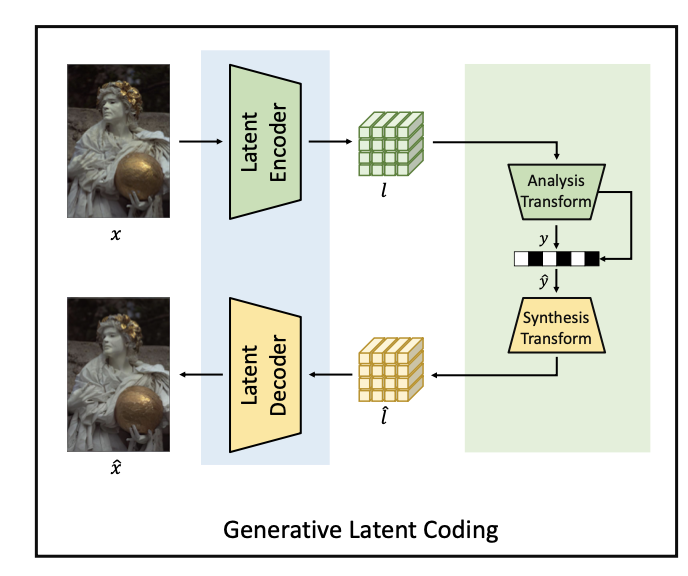
GLC의 전체적인 아키텍처는 위의 그림과 같이 간단합니다.
- Image()를 generative latent auto-encoder()를 이용하여 perception-aligned latent space로 Encoding
=>> - low bitrate에서 latent representation에 transform coding(analysis transform) 적용
=>> - Entropt coding을 위해 scalar-quantize 적용
=>> - 를 latent representation으로 transform 해주기 위해 synthesis transform 적용
=>> - latent decoder 를 이용하여 reconstruction 생성
=>>
Generative Latent Auto-Encoder()
이 논문에서는 human-perception을 잘 반영한 latent space를 얻기 위해 Generative VQ-VAE를 auto-encoder로 사용하였습니다.
이미지를 codebook 안의 visual semantic elements들과 mapping하고 generative image decoding과정을 합침으로서 semantic consistency와 texture realism을 보장할 수 있었습니다.
Transform Coding in Latent Space
Introduction에서 말한대로, VQ-indices-map coding을 다이렉트로 써서 을 압축시키기엔, 해당 coding이 latents 간의 상관관계 고려가 부족하고, redundancy reduction도 충분하지가 않아서 high bit cost를 발생시킵니다.
따라서 GLC에서는 VQ step을 latent redundancy의 효과적인 감소를 위해 대체하게 됩니다.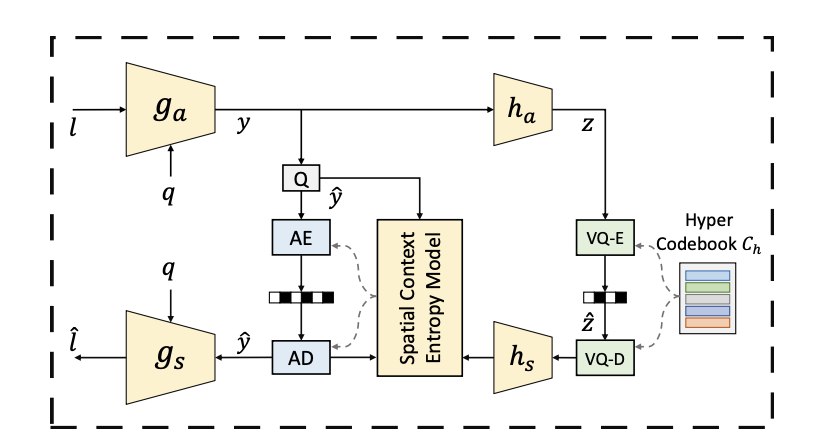 위의 사진은 transform coding module의 모델 구조를 나타낸 것인데, latent가 를 통해 code 로 transform되고, 그런 다음에 로 quantized 됩니다. 의 확률을 기반으로 에 entropy coding이 적용되며, 이 때 categorical hyper module과 quadtree-patition-based spatial context module이 평가에 사용됩니다.
위의 사진은 transform coding module의 모델 구조를 나타낸 것인데, latent가 를 통해 code 로 transform되고, 그런 다음에 로 quantized 됩니다. 의 확률을 기반으로 에 entropy coding이 적용되며, 이 때 categorical hyper module과 quadtree-patition-based spatial context module이 평가에 사용됩니다.
Categorical Hyper Module
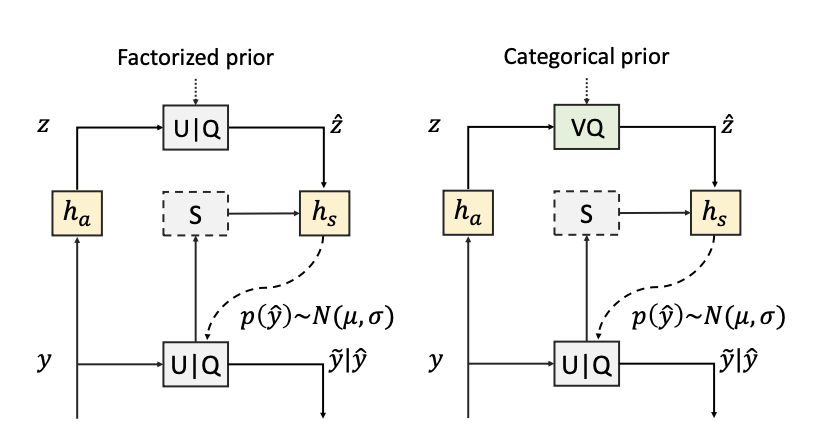
이 논문에서는 제안한 Categorical Hyper Module 전에 최신 compression scheme에서 자주 쓰였던 모듈이 있었는데요. 바로 Factorized hyper module 입니다.
❓ Factorized hyper module
Variational image compression with a scale hyperprior(Ballé et al, ICLR 2018)에서 제안된 방법으로, 쉽게말해서 의 효율적인 확률 분포 모델링을 위한 spatial side information을 제공해주는 모듈입니다.다시말해, Latent variables의 분포를 모델링하기 위한 추가적인 정보들을 제공하는 모듈이라고 생각하면 되죠.
이렇게 얻어진 spatial information을 가지고 있는 는 Decoder에서 가장 먼저 복원되고, 복원한 는 를 통과하며 의 확률 분포 정보인 을 얻습니다. 그리고 이렇게 얻어진 확률 분포 정보를 기반으로 를 효과적으로 reconstruction하여 최종적으로 image를 복원할 수 있습니다.
이 방법론을 제안한 논문에서는 이와 같은 요소를 hyper prior이라고 부릅니다.

근데 아주 낮은(ultra-low) bitrate에서는, factorized 가 high bit cost를 발생시키며 색깔이나 texture 같은 low-level information을 encoding 하는 경향이 있음을 확인했습니다.
따라서 이러한 문제를 다루기 위해 저자들은 Categorical hyper module을 제안했으며, 이는 basic semantic elements를 저장하기 위해 hyper codebook을 사용합니다.
그리고 이 모듈은 a hyper analysis transform , a hyper synthesis transform , 그리고 a hyper codebook 로 구성이 됩니다.
이 때, 와 는 hyper-code를 의미하고, 는 안의 nearest lookup에 의한 VQ를 의미합니다. Factorized hyper module 구조와 비교하면 uniform noise와 quantization하는 부분이 VQ로 바뀌었음을 알 수 있죠.
엄청 큰 차이가 있는지는 모르겠지만 저자들은 categorical 가 high-level information을 좀 더 잘 capture하고 더 적은 bit로 인코딩할 수 있음을 강조합니다.
Rate-Variable Transformation
보통 많은 압축 모델들은 모델 하나당 고정된 압축률 하나만을 다룰 수가 있었습니다. 그런데 보다 실용적인 적용을 위해서는 하나의 모델로 여러가지 압축률을 다룰 수 있어야했기 때문에, 이를 해결하기 위해 나온 것이 Rate-variable coding입니다.
Latent variable을 압축하는데 쓰이는 VQ-indices-map coding 방식은, codebook이 오직 하나의 분포만을 모델링할 수 있었기 때문에 여러 압축률을 사용하기에 한계가 있었습니다.
하지만 latent를 unified Gaussian distribution으로 변환해주고, 이 Gaussian의 variable parameter(means, scales)을 사용하면 variable-rate를 가능케할 수 있습니다. 이러한 방법 중 하나로서, scaler 를 통합하는 DCVC(Deep Contextual Video Compression) series를 GLC는 transform coding 과정에서 참고하여 rate-variable compression을 달성할 수 있었습니다.
Progressive Training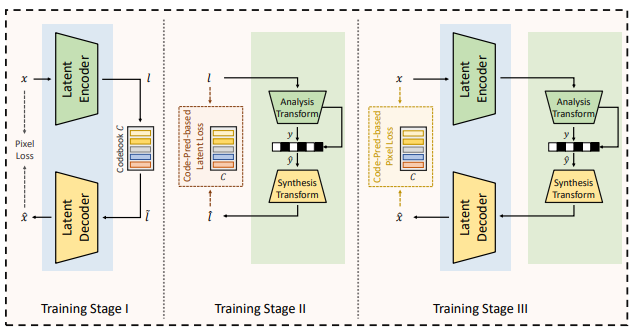
본 논문에서는 GLC의 잠재력을 최대한 끌어내기 위해 세 단계에 걸쳐 학습을 진행합니다.
Stage I: Auto-Encoder Learning
먼저, Human-perception에 최대한 맞는 latent space를 얻기위해 와 의 initialization으로 generative VQ-VAE의 학습을 시작합니다. latent space의 spasity를 보장하기 위해 auxiliary codebook 가 nearest VQ를 실행하며 적용되고 을 로 transform 하죠.
이 단계에서의 loss 함수를 살펴보면 네개의 loss로 구성이 되어있는 것을 알 수가 있습니다.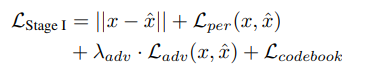 그 구성은 순서대로 아래와 같습니다.
그 구성은 순서대로 아래와 같습니다.
- reconstruction loss
- perceptual loss
- : the LPIPS loss calculated using VGG extracted features - adversarial loss
- : the adaptive Patch-GAN adversarial loss with a weight of = 0.8 - codebook loss
-- : the stop-gradient operator
- β = 0.25
Stage II : Transform Coding Learning
Latent Space에 대해서 학습을 진행했으므로 다음으로는 transform coding에 대한 학습이 필요합니다. 이 경우에는 앞에서 학습한 auto-encoder 와 를 fix합니다.
또한 latent가 올바른 VQ-indecies를 예측할 수 있도록 함으로서 semantic consistency를 향상시키기 위해 보조 code predictor 를 도입할 것이라고 말합니다.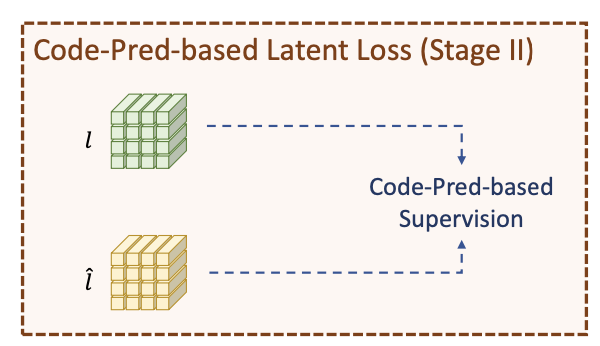 위의 그림처럼 latent 을 다음과 같은 수식을 통해 VQ-indices로 encode 합니다.
위의 그림처럼 latent 을 다음과 같은 수식을 통해 VQ-indices로 encode 합니다.
그 다음으로는 반대로 이러한 indices를 CP를 이용해 예측합니다
따라서 code-predict-based loss는 다음과 같은 식으로 구성할 수 있죠.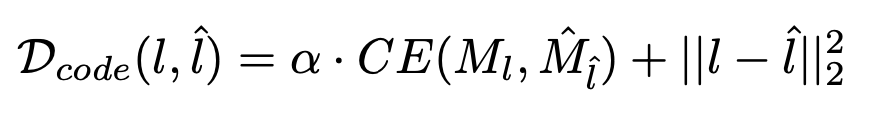 여기서 는 cross-entropy loss를 의미하며 는 0.5 입니다.
여기서 는 cross-entropy loss를 의미하며 는 0.5 입니다.
이제 위의 식을 이용하면 transform coding의 전체적인 supervision을 rate-distortion trade-off를 이용하여 완성할 수 있습니다.
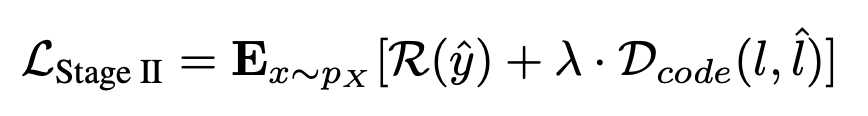 여기서 은 estimated Rate이고, 는 trade-off를 조절하는 coefficient 입니다.
여기서 은 estimated Rate이고, 는 trade-off를 조절하는 coefficient 입니다.
근데 이 식에는 생략된 것이 있는데요, 바로 categorical hyper module에 이용되는 codebook 학습을 위한 codebook loss 입니다. 저자들은 간결함을 위해 생략했다고 말하지만 올바른 모델 학습을 위해서는 여기서도 Stage I의 codebook loss 식을 통해 학습시켜주어야 합니다.
Stage III : Joint Training
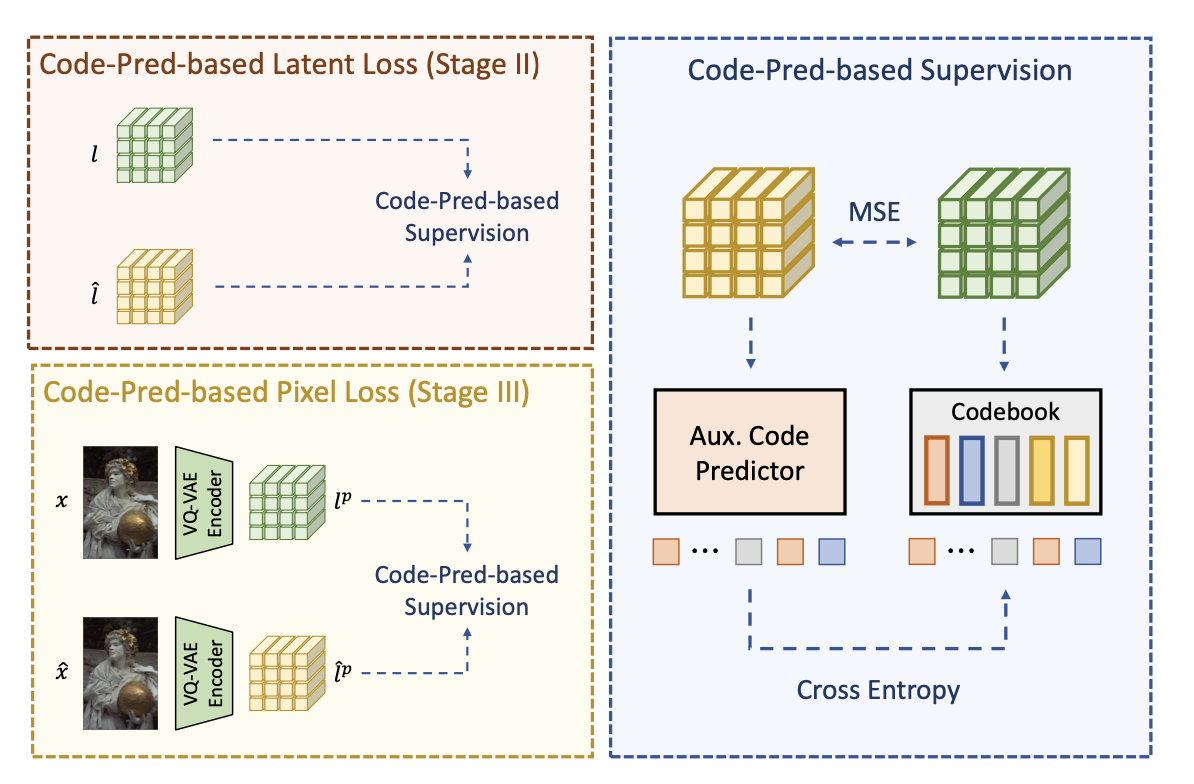 마지막으로, 더 나은 압축 퍼포먼스를 위해 전체적인 네트워크를 pixel-space supervision에서 fine-tune 해주어야 합니다.
마지막으로, 더 나은 압축 퍼포먼스를 위해 전체적인 네트워크를 pixel-space supervision에서 fine-tune 해주어야 합니다.
이를 위해서 Code-prediction-based latent supervision을 pixel space로 확장을 해줄 것인데, 여기서는 Stage I에서 학습되었던 를 와 의 인코딩을 위해 사용합니다. 따라서 이렇게 인코딩한 와 를 가지고 code-prediction-based pixel loss 를 계산해줍니다.
따라서 최종적인 pixel supervision은 아래와 같으며(Stage I의 식과 굉장히 유사합니다) 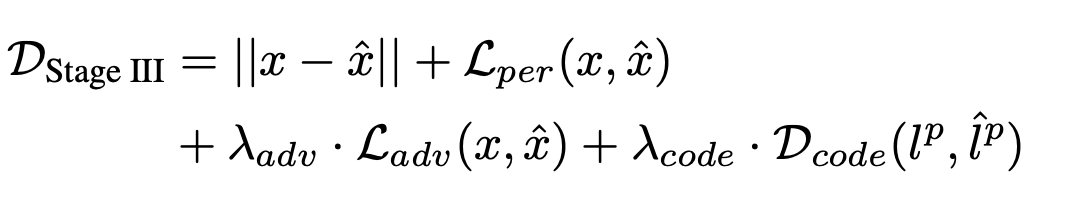
그리고 Rate-Distortion trade-off Loss는 아래와 같습니다.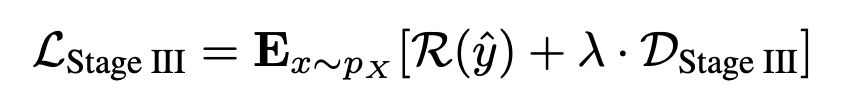
Experiment
Training Detail
- GLC는 natural image compression과 facial image compression 둘 다를 위해 학습
- Natural Image Compression
- Dataset- Stage I : ImageNet training set
- Stage II, III : OpenImage test set
- Randomly cropped 256 x 256 patches
- Facial image
- Dataset- All stages : FFHQ dataset
- resolution : 512 x 512
- Optimizer : AdamW
- Batch size : 8
Main Results 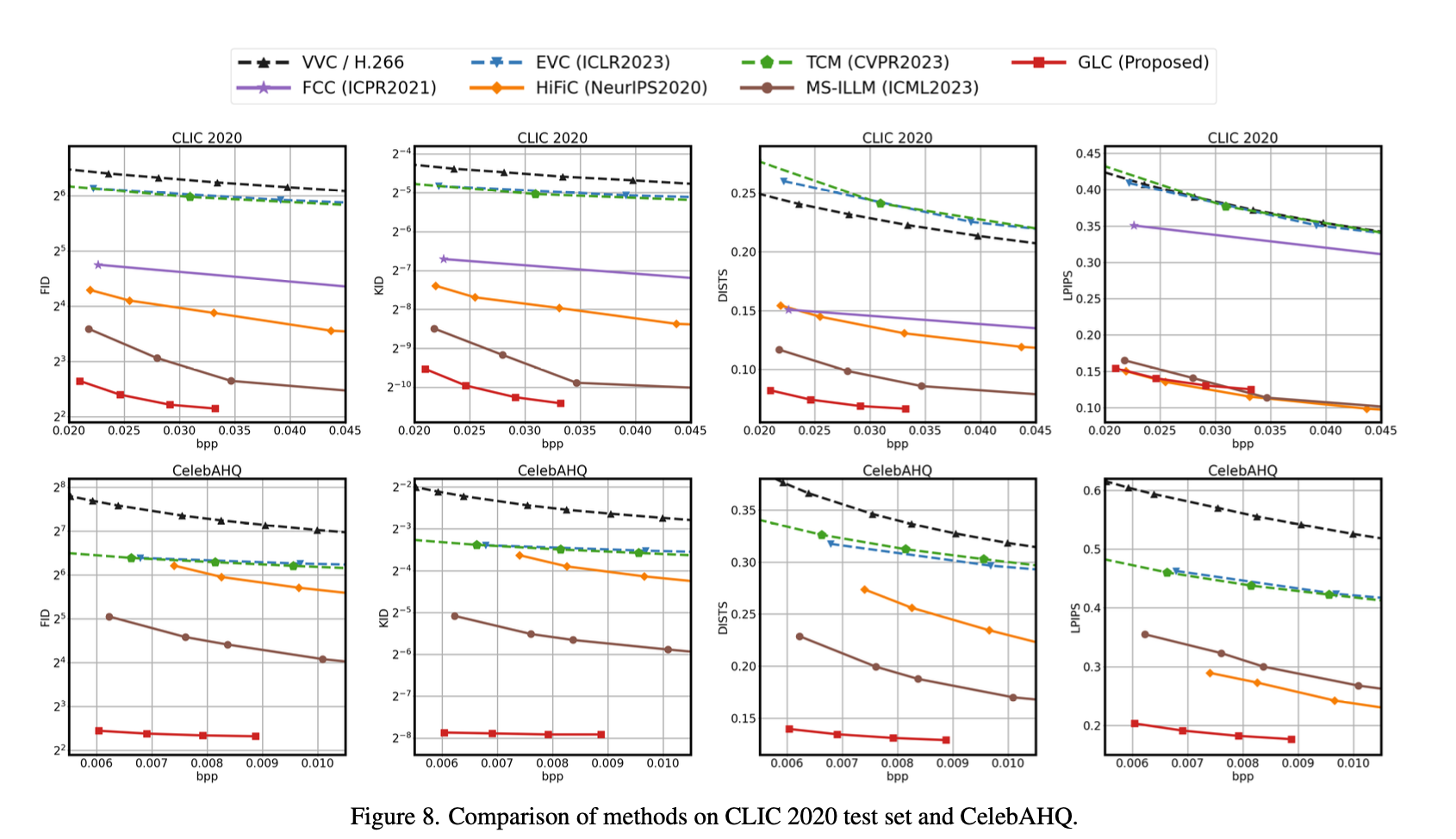
 위의 사진들에서 보이는 것처럼 다양한 evaluation metric과 natural/facial image compression에서 다른 baseline 모델에 비해 훨씬 좋은 성능을 보여줌을 확인할 수가 있었습니다.
위의 사진들에서 보이는 것처럼 다양한 evaluation metric과 natural/facial image compression에서 다른 baseline 모델에 비해 훨씬 좋은 성능을 보여줌을 확인할 수가 있었습니다.
Conclusion
저자들이 제안한 Generative latent coding(GLC) scheme는 high-fidelity와 high-realism을 보장하는 generative compression을 ultra-low bitrate에서 달성할 수 있었습니다. 다른 pixe-domain codecs들과 다르게 이 모듈은 transfor coding을 generative VQ-VAE의 latent domain에서 실행했고, categorical hyper module과 code-prediction based supervision 기법들도 통합하여 많은 벤치마크에서 정말 좋은 성능을 보여주었습니다.
하지만 특정 데이터셋으로 학습을 진행했기 때문에 generalization capability가 항상 만족스럽지는 못했는데요. 예를들면 screen content와 같은 것들에 대해서는 깔끔하고 정확한 reconstruction을 보장하지 못했습니다. 따라서 다음 과제로는, 모델 구조와 학습 전략을 향상시켜 GLC의 generalization ability를 증가시키는 것에 있음을 밝혔습니다.
Compression 모델 중에 나름 최신(CVPR 2024)에 나온 논문이라 한번 리뷰를 진행해보았는데요, diffusion 모델을 사용하지 않은 점과 전통적인 구조에서 그렇게 크게 구조를 뒤바꾸지 않은 점이 흥미로웠습니다. 하지만 VQ-VAE와 같은 모델들이 아직은 어색해서 코드를 읽어보며 좀 더 확실하게 이해해야겠다는 생각이 들었습니다.
최신 compression 모델인 PerCo나 HFD 모델도 baseline 모델로서 비교를 supplementary materials에서 했다는데, CVF Open Access에서 pdf를 가져와서 그런가 추가 자료들이 빠져있어서 확인하지 못한게 못내 아쉬웠습니다.
다음에 가져오는 논문도 compression 쪽이 될 것 같은데, 그 때는 코드도 같이 가져와서 리뷰해보도록 하겠습니다.
