
분석 문제 정의 : 어떤 문제를 머신러닝 방법론을 이용해서 해결할 것이냐! 머신러닝 방법론을 기준으로 문제를 정의하는 것
데이터 정의를 할땐 어떤 특징(feature)을 사용할 것인지 정의해야한다.
머신러닝 문제 정의: 머신러닝 task
1. 분류 : 데이터를 비슷한 부류로 나누는 방법, 데이터가 어떤 부류로 나뉘는지 이미 알고 있는 경우에 사용
2. 회귀 : 데이터의 특정 값을 예측하는 방법. 데이터의 값을 이미 알고있는 경우에 사용
3. 클러스터링 : 데이터를 비슷한 부류로 나눈 방법. 데이터가 어떤 부류로 나뉘는지 몰라도 사용 가능
4. 추천 : 어떤 User에게 어떤 item을 제안하는 방법. 주로 과거이용기록, 유저의 특징, 아이템의 특징등을 사용
5. 랭킹 : 주어진 평가 기준에 따라 순위를 매기는 방법
베이스라인 선정 (기존 사례 조사):
ex)Iris dataset으로 검색
하려는 일을 과거에 한 사례가 있으면 참고해보는 것.
데이터 수집 : 정의한 데이터를 실제로 가져와서 data mart를 구축하는 작업
분석 데이터 정의에 맞는 데이터를 직접 가져온다. (수집) -> 직접 수집 해야하는 경우(Web Crawling)
데이터가 Data Warehouse에 없는 경우라면, data engineer에게 요청
- 어떤 데이터를 가져오냐에 따라 분석 결과의 품질 결정(Data Quality)
- 정의한 데이터는 실제 저장되어 있는 데이터와 1:1 매칭이 안될수도 있다(데이터 정합성평가)
데이터 마트 생성
1. 이미 Data warehouse에 정의가 되어있다면 sql을 사용해서 데이터 가져옴
2. 데이터가 원하는 형태로 합쳐지는지 테스트하는 것을 '데이터 정합성 평가' 라고 한다
3. 분석에 필요한 데이터가 어느 기간에 수집된 데이턴지, 어떤 기관에서 수집한 데이턴지, 정의한 특징을 모두 포함하고 있는지 확인 (Sanity check)
데이터 정합성 평가
1. 데이터를 합칠 때 생기는 이슈들을 체크하는 과정
2. 두 개의 테이블 합친다면(JOIN operation) 체크해야할 것
1. user_id, time column이 존재하나? O
2. row가 정의된 단위(unit)이 일치하는가? X
:time unit(단위)가 다르다 (yymmddhhmmss VS yymmddhh0000) 초 단위를 시간 (hour)단위로 합쳐줍니다.
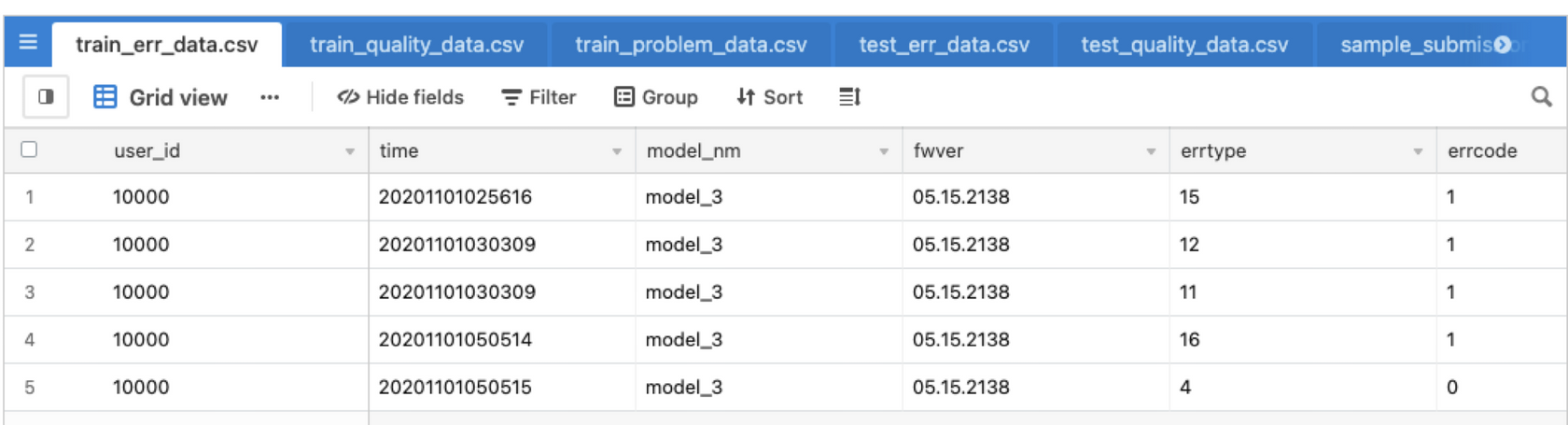
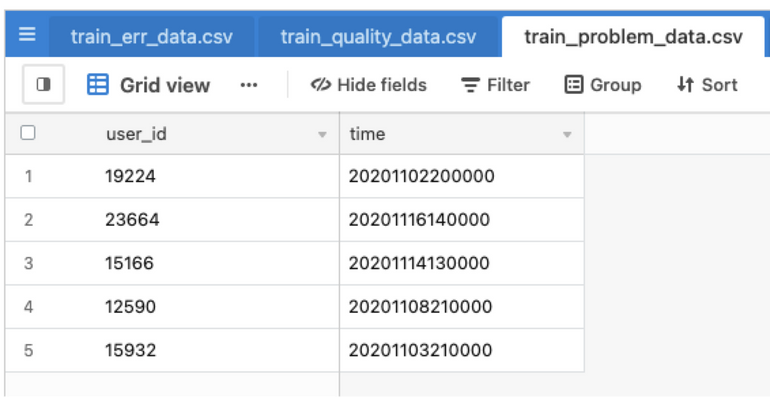
데이터 취합
- 정합성 평가를 통과했다면, 원하는 데이터를 합칩니다.
- JOIN 연산의 결과가 처음 생각했던 것과 맞는지 체크합니다. (Sanity Check)
데이터 포맷 통일
- 취합한 결과가 table(in DBMS)인데, 분석할 때는 csv file이 필요한 경우에는 변경해줍니다.
- 분석 도구의 input type을 보고 결정합니다.
EDA(Exploratory Data Analysis) 데이터에서 분석에 필요한 여러가지 통계량을 계산하고, 시각화를 통해서 확인하는 작업
-분석을 하면서 데이터에서 확인하고 싶은 정보들을 확인하는 과정
-데이터에 대해서 많이 알수록 EDA도 잘할 수 있다(Domain knowledge)
편의를 위해서 Iris dataset이 모듈2까지 거쳐서 다음과 같이 정의되었다고 가정해봅니다.
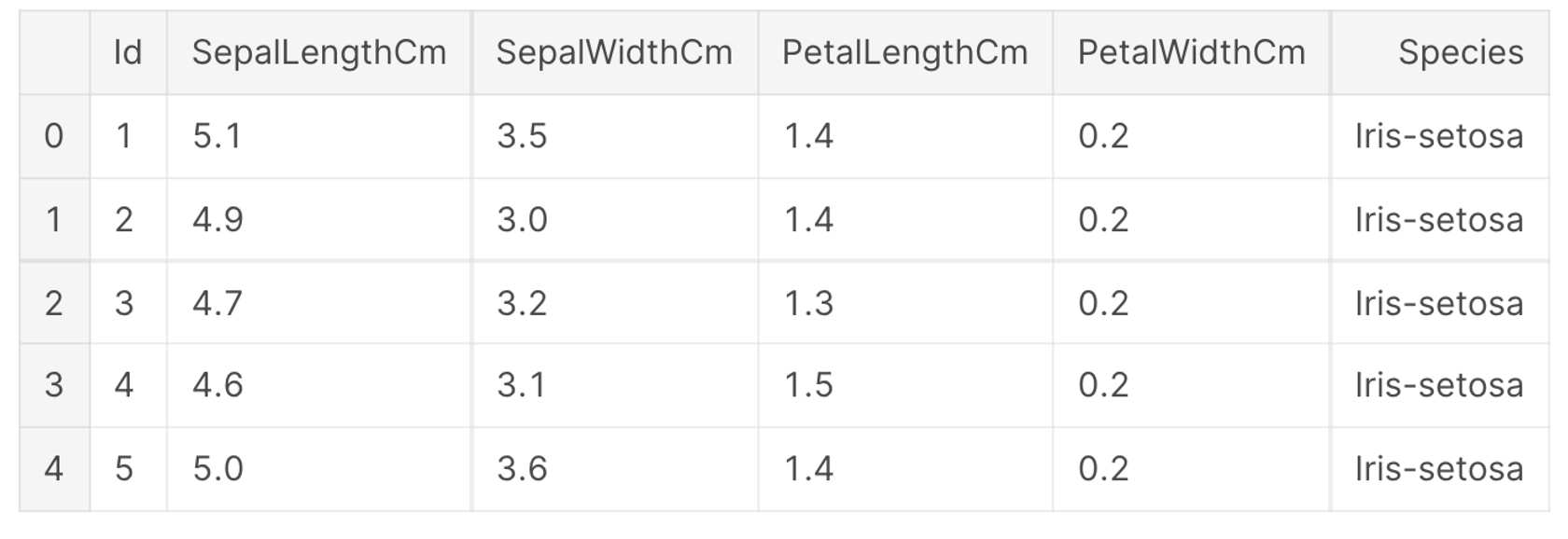
데이터 크기 확인
- 주어진 Iris dataset의 크기는 150 rows, 6 columns 입니다. (150 x 6)
- pandas를 기준으로 메모리 사용량은 대략 7.2KB 입니다.
데이터 분포 확인
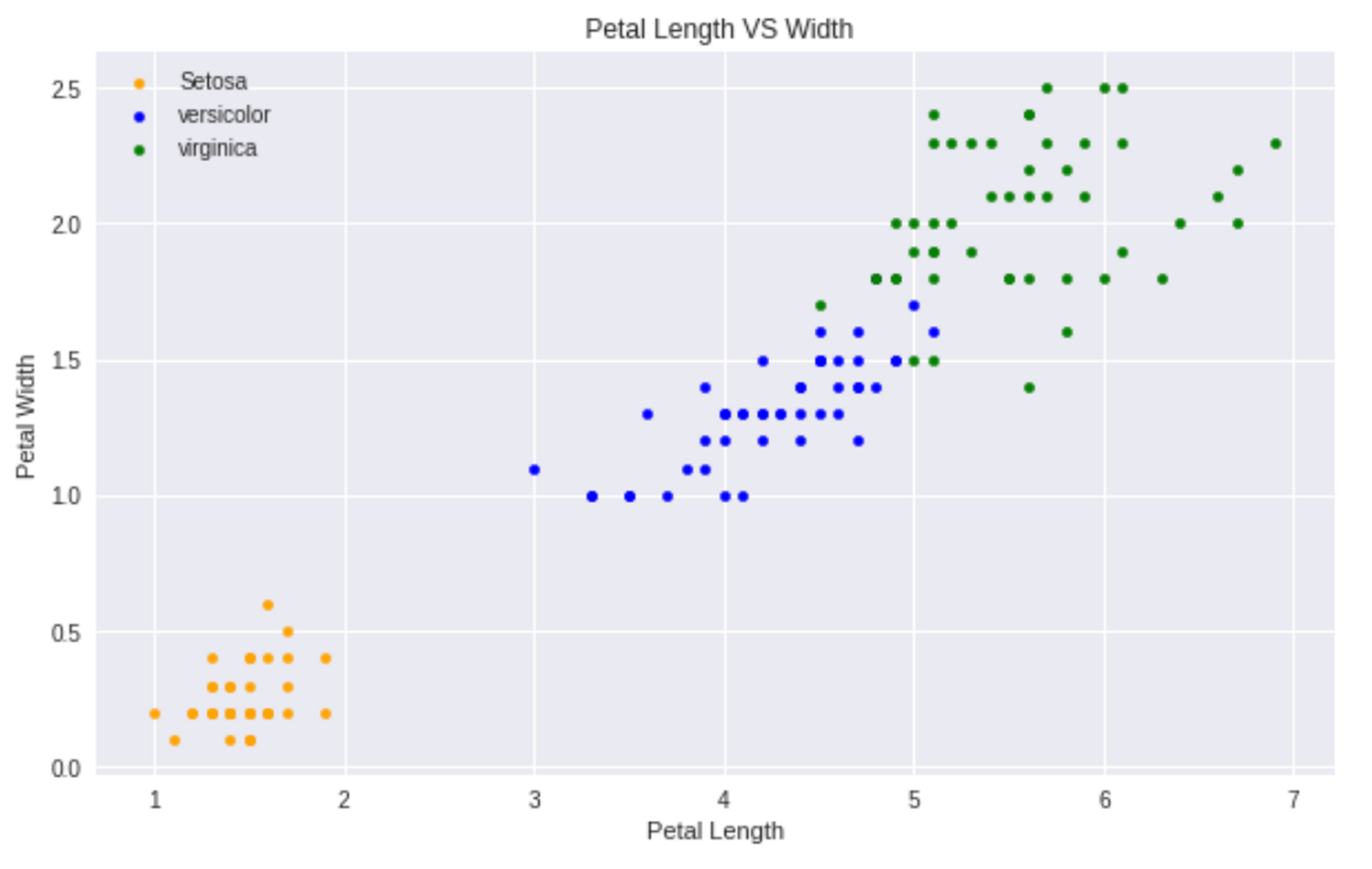
-target distribution
-Petal(꽃잎) Length VS Petal Width
-Feature Histogram
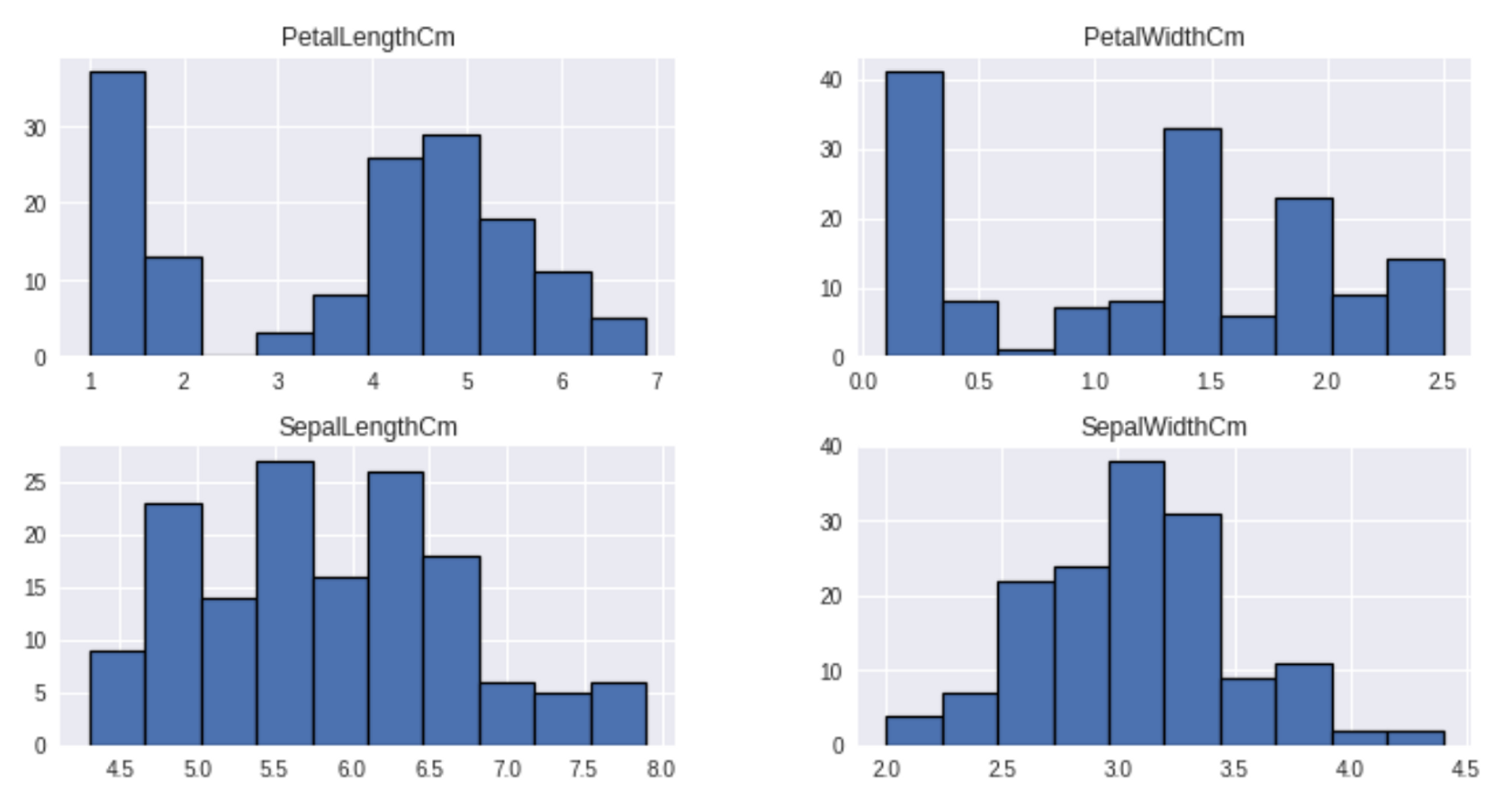
데이터 시각화
하는 이유 : 전체에 대한 요약적인 정보를 한눈에 보기 위해서.
데이터가 너무 많을 경우 (샘플링을 해서 본다)
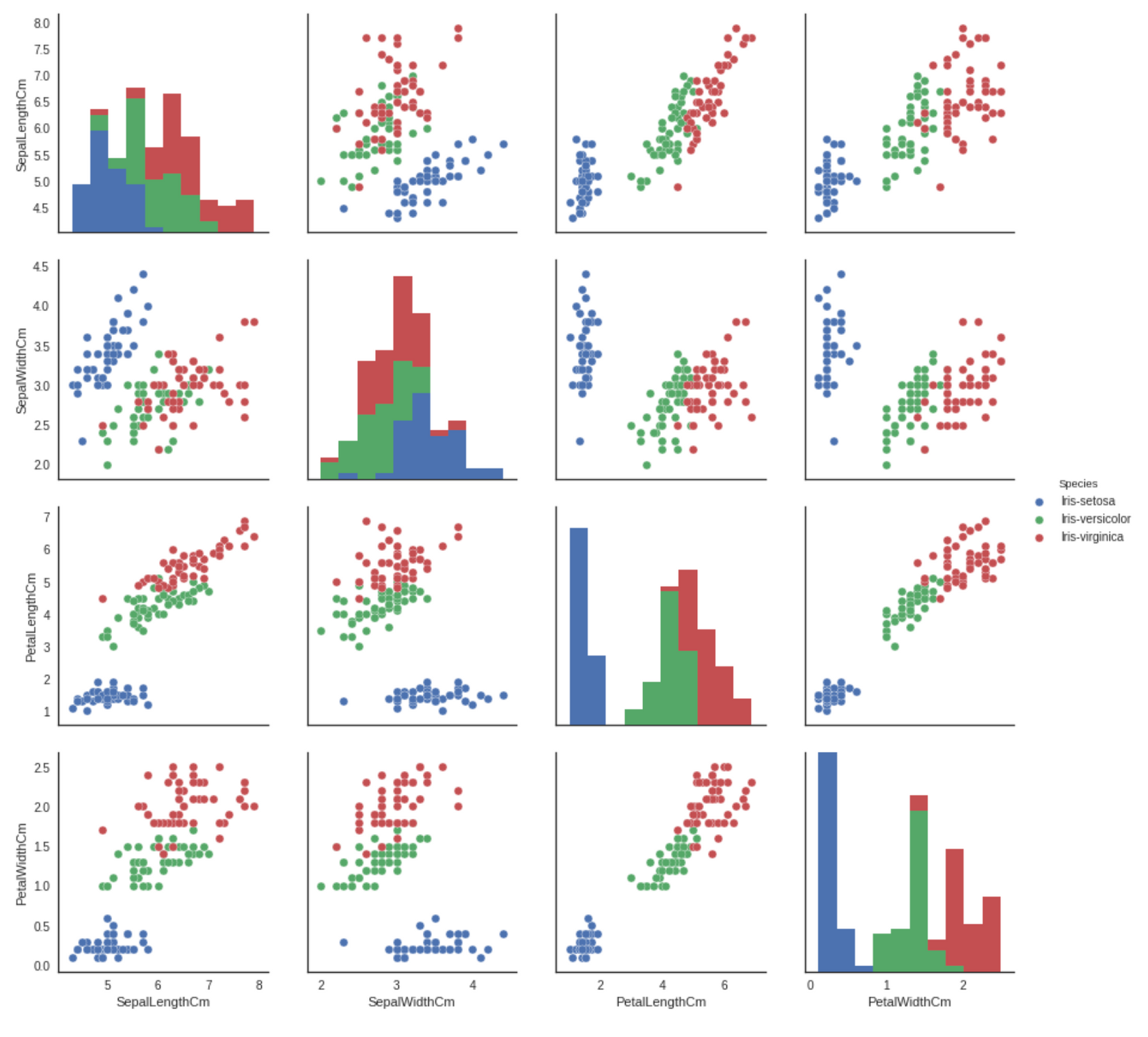
-Pairplot (numeric feature)
-Boxplot
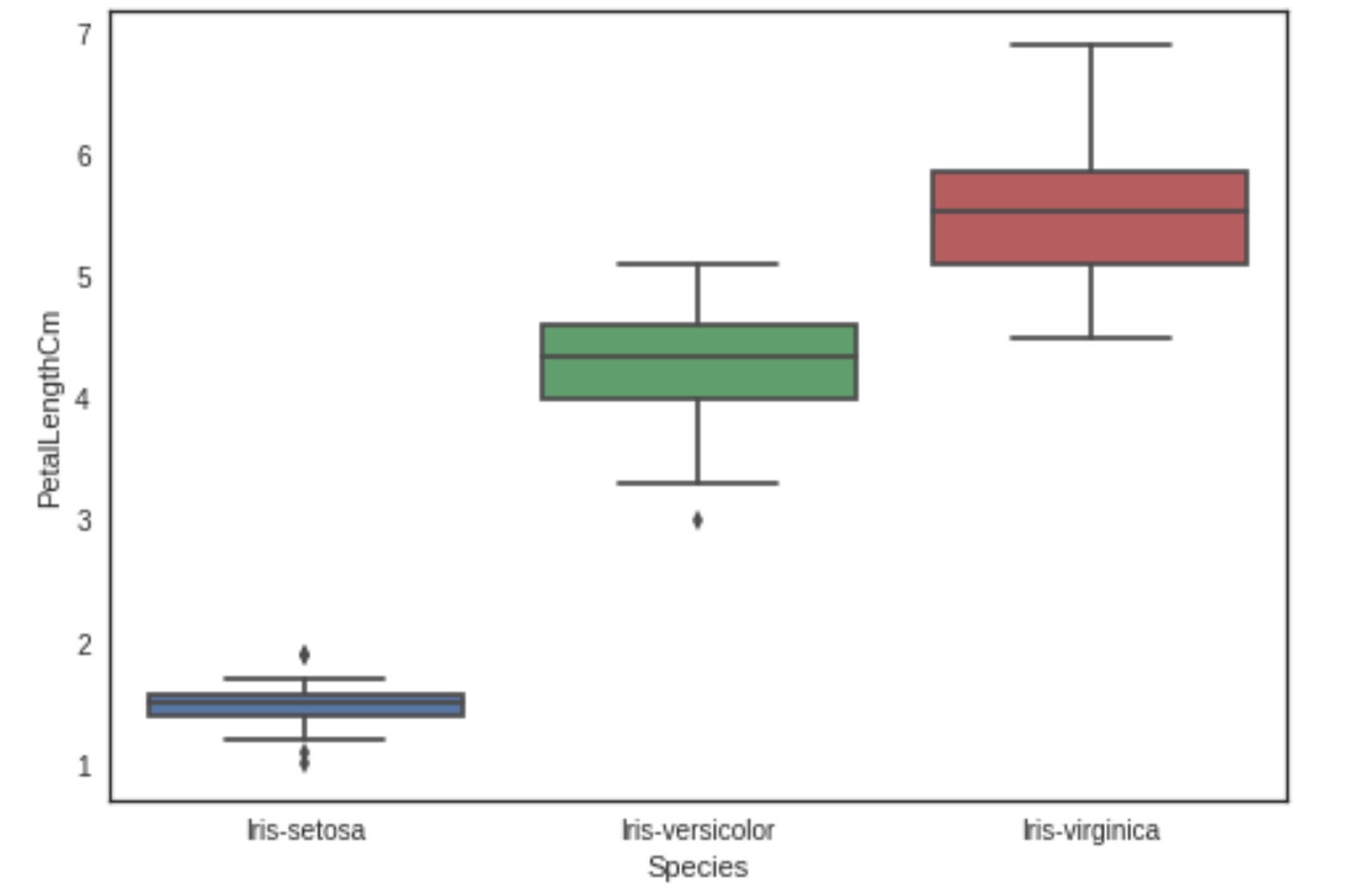
데이터의 대략적인 분포를 보여준다
통계량 분석
-Correlation Matrix(상관계수분석)
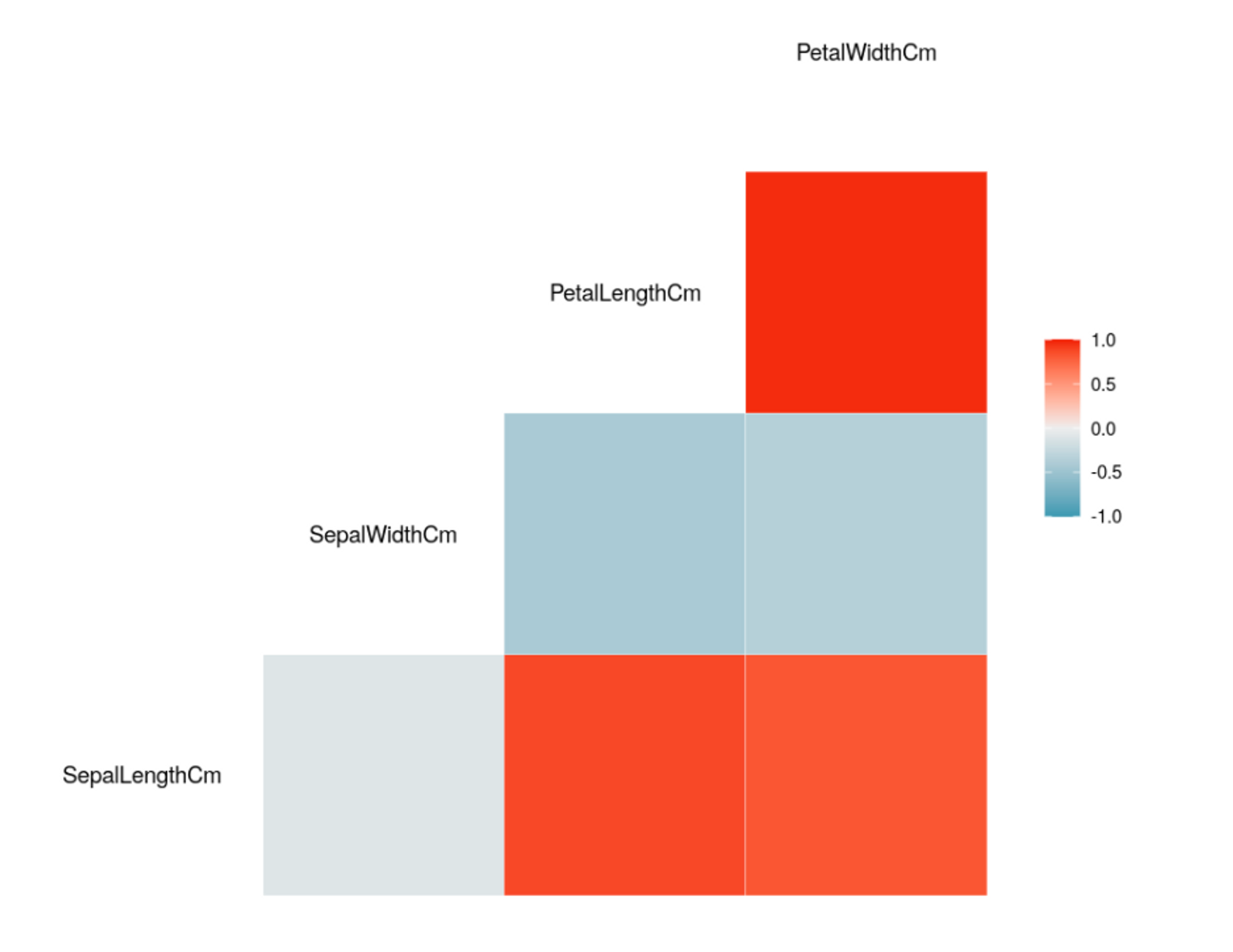
각 컬럼들끼리 얼마나 연관성이 있는지 수치적으로 나타낸것 (0에 가까울수록 관계가 없다)
-비슷한 feature가 있으면 하나를 없앨 수 있음
Reference
1. https://www.kaggle.com/benhamner/python-data-visualizations
2. https://www.kaggle.com/ash316/ml-from-scratch-with-iris
3. https://www.kaggle.com/upadorprofzs/basic-visualization-techniques
data : https://www.kaggle.com/datasets/uciml/iris

정보 감사합니다.