들어가며
본 프로젝트는 이전의 구어체로 구성된 카카오톡 대화 추상 요약 서비스에 이어서 문어체로 구성된 뉴스 데이터의 추출 요약을 시도해 보고자 한다. 이로써 한국어 텍스트 데이터에서 문어체, 구어체를 모두 다룸으로써 어체에 따라서 어떤 서비스가 유리하고, 또 어떤 모델이 유리한지 한국어 데이터에 대한 전반적인 이해를 할 수 있게 될 것이다. 또한 fine-tune BERT for Extractive Summarization 논문을 이해하고 논문 저자가 공개한 코드를 기반으로 구현해 보는 시간이 될 것이다.
논문 소개
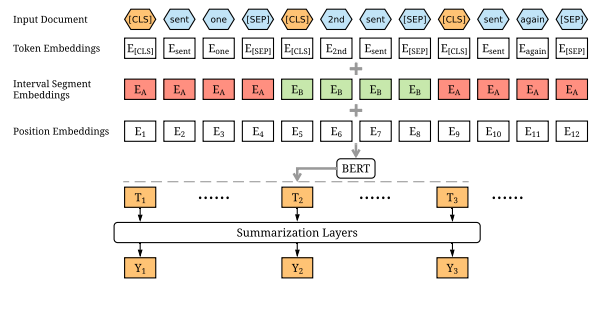
해당 프로젝트는 fine-tune BERT for Extractive Summarization를 기반으로 구현되었다. 해당 논문은 2019년 발표 당시에 CNN/Daily Mail에서 SOTA를 기록하였다. 이 논문의 특징으로는 Encoding Multiple Sentences, Interval segment Embedding, Summarization Layers, Experiments를 뽑을 수 있다. 위의 그림을 살펴보면서 이 네 가지 특징에 대해서 살펴보도록 하겠다.
1. Encoding Multiple Sentences
문장의 시작에는 [CLS] 토큰을, 문장의 끝에는 [SEP] 토큰을 삽입하여 기존 [SEP]만 사용하여 문장들을 구분하던 BERT 모델을 개선했다. 이러한 방식처럼 여러 개의 [CLS] 토큰을 사용하면 각 문장의 feature를 [CLS] 토큰에 저장할 수 있어 성능 향상을 기대할 수 있다.
2. Interval segment Embedding
이 기법은 여러 문장이 포함된 문장에서 문서를 구분하기 위해서 사용된다. 기존의 방식은 문장 1~2가 있으면 A, B로 구분한다. 하지만 요약 문서의 특성상 여러 문장이 포함되므로 문장 1~4를 A, B, A, B로 번갈아가며 구분 지어준다.
3. Summarization Layers
해당 모델은 BERT로부터 문장 vector에 대한 정보를 얻은 다음에 추출 요약을 위해 문서 단위의 feature를 잡아야 한다. 그래서 해당 결괏값 위에 summarization-specfic layers를 쌓아준다.
1) Recurrent Neural Network
Transformer와 RNN 결합 시 성능이 좋았으며 BERT output을 LSTM layer로 넘겨줘 마지막 단계에서는 sigmoid classifier를 사용한다.
2) Simple Classifier
기존 BERT와 같이 Linear layer 및 Sigmoid function을 사용하였다.
3) Inter-sentence Transformer
문장 representations을 위하여 Transformer layer을 사용하며 마지막 단계에서는 Transformer layer로부터 나온 문장 vector를 sigmoid classifier 넣는다. 추가적으로 설명을 덧붙이면 Layer가 2개일 때의 성능이 제일 좋았다.
논문에서 가장 좋은 성능을 나타낸 Summarization Layers는 Inter-sentence Transformer이다. 그렇기 때문에 해당 Layers를 중심으로 살펴보도록 하겠다.
4. Experiments
실험 조건은 Training, Prediction에 대해서 알아보도록 하겠다. Datasets도 중요하지만 논문과는 다르게 한국어 데이터로 프로젝트를 진행할 것이기 때문에 Datasets에 대해서는 생략하도록 하겠다.
1) Training
- Train Steps = 50,000
- Batch size = 36
- Learning rate = 2e-3
- Warmup steps = 10,000 steps
- Optimizer = Adm(with β=0.9, β2=0.999
2) Prediction
- Top-3 문장 추출
- Trigram Blocking으로 추론시 중복을 막는다. 요약문과 후보문 사이에 trigram overlapping이 발생하며 후보문을 스킵한다.
마치며
오늘은 KlueBERT를 활용한 뉴스 세 줄 요약 프로젝트의 기반이 되는 논문을 간략하게 살펴보았다. 다음 시간에는 데이터에 대해서 자세히 알아보도록 하겠다.
github로 이동하기 : KlueBERT를 활용한 뉴스 세 줄 요약 서비스
