KlueBERT를 활용한 뉴스 세 줄 요약 서비스
1.KlueBERT를 활용한 뉴스 세 줄 요약 서비스_1(ft.논문 소개)
들어가며 본 프로젝트는 이전의 구어체로 구성된 카카오톡 대화 추상 요약 서비스에 이어서 문어체로 구성된 뉴스 데이터의 추출 요약을 시도해보고자 한다. 이로써 한국어 텍스트 데이터에서 문어체, 구어체를 모두 다룸으로써 어체에 따라서 어떤 서비스가 유리하고, 또 어떤 모델
2023년 3월 22일
2.KlueBERT를 활용한 뉴스 세 줄 요약 서비스_2(ft.데이터)

들어가며 이번 포스팅에서 다룰 주제는 데이터이다. KlueBERT를 활용한 뉴스 세 줄 요약 프로젝트에서 사용한 데이터의 수집부터 소개 및 데이터 토크나이저까지 데이터에 대해 전반적으로 살펴보고자 한다. 데이터단문 데이터 수집 이번 프로젝트에 사용한 데이터는 AIH
2023년 3월 22일
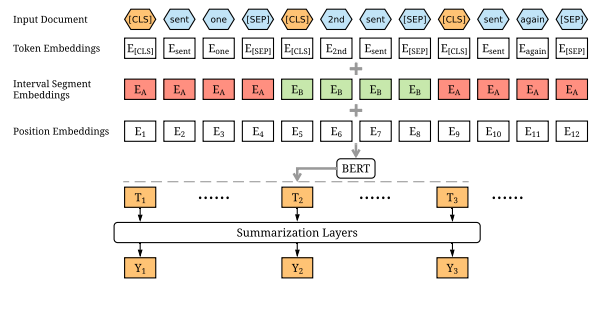
3.KlueBERT를 활용한 뉴스 세 줄 요약 서비스_3(ft.모델)
들어가며 이번 포스팅은 KlueBERT를 활용한 뉴스 세 줄 요약의 모델에 대해서 살펴보도록 하겠다. 먼저 어떤 사전학습 모델을 사용하였는지 살펴볼 것이고, RNN, Classifier, Transformer 부분의 클래스를 살펴볼 것이다. 그리고 모델 학습과 하이퍼파
2023년 3월 23일
4.KlueBERT를 활용한 뉴스 세 줄 요약 서비스_4(ft.평가)
모델을 만들었다면 이제는 이 모델이 제대로 된 모델인지, 또 잘못된 부분은 어떤 것이 있는지 확인하기 위해서 평가를 해야 한다. 평가에 대한 여러 지표가 있지만 추출 요약에서는 Rouge를 사용할 것이다. 그렇기 때문에 이번 포스팅에서는 Rouge 지표를 왜 선택했으며
2023년 3월 29일