들어가며
지난 시간의 KoBART를 할용한 카카오톡 대화 요약 서비스_1(feat.개요와 데이터 다루기)에 이어서 모델과 평가 지표에 대해서 다루어보도록 하겠다.
1. 모델링
1) fine-tuning
fine-tuning의 경우는 Hugging Face에서 사전학습된 모델인 gogamza/kobart-base-v2를 가져와 사용하였다. 그리고 BartForConditionalGeneration을 사용하여 생성 요약이 가능하도록 모델에 head를 추가하였다.
- 해당 모델 같은 경우는 한국어 위키 백과 이외, 뉴스, 책, 모두의 말뭉치 v1.0(대화, 뉴스, ...), 청와대 국민청원 등의 다양한 데이터를 활용하였다.
- 학습시에는 Text Infilling기법을 사용하여 Noising 하였다.
2) 도메인 적응(post-pretrain)
gogamza/kobart-base-v2 해당 모델의 파라미터를 추상 요약에 적합하게 파라미터를 업데이트하는 것이다. 도메인에 맞게 post-pretrain 하여 적응시킨 후 파라미터가 업데이트되었다면 이를 가지고 다시 fine-tuning 해야 한다.
1) BART Nosing 기법
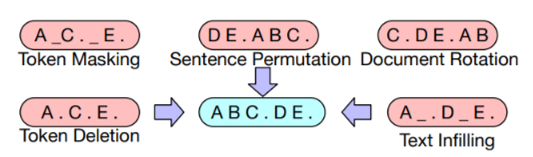
BART의 가장 큰 장점 중 하나는 Noising이 자유롭다는 것인데 논문에서는 위의 5개 기법을 사용하였다.
- Token Masking: 임의의 토큰을 마스킹하고 복구하는 방식
- Token Deletion: 임의의 토큰을 삭제하고 그 토큰의 위치를 찾는 방식
- Text Infilling: 푸아송 분포를 따르는 길이의 text span을 생성해 하나의 마스크 토큰으로 마스킹하고, 그 토큰에 몇 개의 토큰이 존재하는지 예측
- Sentence Permutaion: 문장의 순서를 랜덤으로 섞는 방식
- Document Rotation: 토큰 하나를 정해 그 토큰을 시작점으로 하여 회전시킨 후, 문서의 시작점을 찾도록 학습
이 프로젝트에서는 Token Masking 즉 MLM 기법을 사용하여 학습을 진행하였으며 Train Data : 1599992, val Data : 200004를 가진 AIHub - 한국어 SNS 데이터를 사용하였다. 그리고 Masking 하는 코드는 아래와 같이 작성하였다.
2) 해당 코드(2023.04.07 수정) - 추가 개선편에 조금 더 자세히 기술했다.
def add_padding_data(inputs, config, tokenizer, is_mlm=False):
if is_mlm:
mask_num = int(len(inputs)*config.masking_rate)
mask_positions = random.sample([x for x in range(len(inputs))], mask_num)
corrupt_token = []
for pos in range(len(inputs)):
if pos in mask_positions:
corrupt_token.append(tokenizer.mask_token_id)
else:
corrupt_token.append(inputs[pos])
if len(corrupt_token) < config.max_len:
pad = [tokenizer.pad_token_id] * (config.max_len - len(corrupt_token))
inputs = np.concatenate([corrupt_token, pad])
else:
inputs = corrupt_token[:config.max_len]
else:
if len(inputs) < config.max_len:
pad = [tokenizer.pad_token_id] * (config.max_len - len(inputs))
inputs = np.concatenate([inputs, pad])
else:
inputs = inputs[:config.max_len]
return inputs추가적으로 masking이 된 토큰에만 손실함수를 계산할 수 있도록 masking된 position을 가져와 label에 적용하였다. 이를 위해 masking되지 않은 부분에는 -100을 주어 손실 함수를 계산하지 않도록 하였다.
def add_ignored_data(inputs, config, corrupt_token, tokenizer):
none_mask = []
corrupt_token = [x for x in corrupt_token if x != tokenizer.pad_token_id]
for i in range(len(corrupt_token)):
if corrupt_token[i] != tokenizer.mask_token_id:
none_mask.append(i)
for mask_num in none_mask:
inputs[mask_num] = config.ignore_index
if len(inputs) < config.max_len:
pad = [config.ignore_index] *(config.max_len - len(inputs)) # ignore_index즉 -100으로 패딩을 만들 것인데 max_len - lne(inpu)
inputs = np.concatenate([inputs, pad])
else:
inputs = inputs[:config.max_len]
return inputs2. 평가지표
1) ROUGE-1, ROUGE-2, ROUGE-L
평가 지표는 ROUGE 사용하였다. ROUGE에는 대표적으로 ROUGE-1, ROUGE-2, ROUGE-L이 있다.
-
ROUGE-1: 이 지표는 원문과 생성된 요약 사이의 unigram(1-그램) 일치를 측정한다. 단어 단위의 정확도와 재현율을 계산하여 원문의 단어와 요약의 단어 간 일치도를 평가한다.
-
ROUGE-2: 이 지표는 원문과 생성된 요약 사이의 bigram(2-그램) 일치를 측정한다. 연속된 두 단어의 일치를 살펴보기 때문에 문장 구조와 의미의 유사성을 좀 더 정확하게 평가할 수 있다.
-
ROUGE-L: 이 지표는 최장 공통 부분문자열(Longest Common Subsequence, LCS)을 기반으로 한다. LCS는 원문과 생성된 요약사이의 공통 문자열을 찾아 일치도를 측정한다. 문자열에서 순서를 유지하되, 연속적이지 않아도 되는 가장 깉 공통 부분 문자열을 찾는 방법이다. 즉, ROUGE-L은 원문과 요약 간의 순서를 고려하면서도, 연속적이지 않은 단어나 구문도 일치로 간주할 수 있는 장점이 있다.
생성 요약(e.g., abstractive summarization)에는 ROUGE-L이 가장 적합하다고 여겨진다. 왜냐하면 생성 요약은 단순히 원문에서 문장을 추출하는 것이 아니라, 새로운 문장을 구성하기 때문이다. ROUGE-L은 순서를 고려하면서도, 연속적이지 않은 단어나 구문을 일치로 간주하기 때문에, 생성 요약의 성능을 보다 정확하게 평가할 수 있다.
예를 들어서 보다 더 자세하게 설명하자 원문이 "나는 집에서 자고 있다." 라는 문장이 생성 요약을 통해서 "집에서 나는 자고 있다."로 요약 되었다고 가정해보자. 이런 경우에는 "나", "집에서", "자고 있다."의 공통 부분 문자열을 고려하여 두 문장간의 일치도를 계산하는 것이다. 다시 한번 더 얘기하지만 순서와 연속성을 고려하지 않기 때문에 원문의 정보를 얼마나 잘 보존하는지 측정하는 데 적합하다.
2) recall, precision, F1-score
추가적으로 recall, precision, F1-score가 있다. 이 둘 중 무엇이 더 중요한지 따져야한다면 이번 프로젝트에서는 precision이 더 중요하다.
- recall이 더 중요한 경우는 양성인 데이터를 음성으로 잘못 판단하게 되면 큰 영향을 미치는 경우
- precision이 더 중요한 경우는 음성인 데이터를 양성으로 잘못 판단하게 되면 큰 영향을 미치는 경우
이유는 간단하다. 핵심 단어를 추상 요약하지 못하는 것이 치명적일까? 틀린 단어를 추상 요약하는 것이 치명적일까? 고객의 입장에서 생각해 보면 핵심이 되지 않는 단어가 들어갈 수는 있다. 하지만 이는 그래도 내가 입력한 정보이기에 큰 이슈는 되지 않는다. 반대로 불필요한 단어가 들어가 정보가 왜곡된다면 분명 치명적일 것이다. 그 이유는 정보의 조작에 대한 문제가 제기될 수 있기 때문이다. 그렇기 때문에 precision이 더 중요한 것이다.
3) 평가지표 최종 선정
다시 정리하자면 recall은 중요한 부분을 최대한 포함하는지를 판단하며, precision은 불필요한 부분을 제외하느냐를 판단한다. 결국 서비스를 제공하기 위해서 precision 더 중요하기는 하지만 핵심 단어를 잘 표현하는 것도 중요하기 때문에 보다 더 좋은 성능을 위해서는 recall과 precision의 조화를 이룬 F1-score를 기준으로 평가 기준을 삼아야 할 것이다.
4) 해당 코드
!pip install rouge
from rouge import Rouge
rouge = Rouge()
def compute_metrics(pred):
labels_ids = pred.label_ids
pred_ids = pred.predictions
pred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
labels_ids[labels_ids == -100] = tokenizer.pad_token_id
label_str = tokenizer.batch_decode(labels_ids, skip_special_tokens=True)
return rouge.get_scores(pred_str, label_str, avg=True)
마치며
이번 포스팅에서는 모델링 기법과 평가 지표에 대해서 알아보았다. 다음 포스팅에서는 생성 전력과 Hugging Face에 모델 업로드를 하는 방법을 살펴보도록 하겠다.
github로 이동 : KoBART를 활용한 카카오톡 대화 요약 서비스
