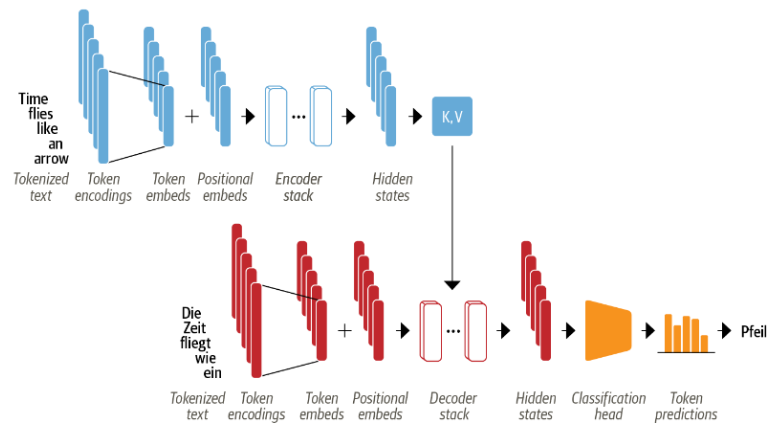
들어가며
우리는 지금까지 NLTK, KoNLPy 등 다양한 Framework를 사용하였다. 이번 시리즈에서 배울 것은 최근 NLP 분야에서 가장 주목받고 있는 Framework인 Huggingface의 transformers 라이브러리에 대해서 알아보고자 한다.
transformers란
transformers는 크게 pretrained model과 tokenizer를 지원하고 있으며. 언어는 PyTorch, Tensorflow, JAX 등 다양한 언어를 지원하고 있다. 아래 링크로 해당 사이트에 들어가면 BERT, BART, GPT 등 현재 NLP에서 굵직하게 쓰이는 많은 모델들을 가져와 사용할 수 있다.
추가적으로 transformers를 사용하기 위해서는 먼저 아래의 코드를 실행하여 설치를 해야 한다.
pip install transformers다양한 Task
- 텍스트 분류
- 개체명 인식
- 질문과 답변
- 요약
- 번역
- 텍스트 생성
다양한 기법
- 레이블 부족 문제 해결
- 실제 모델 서빙을 위한 메모리 절약 및 속도 향상
- fine-tuning
- pre-train
- feature-extraction
- 다중 언어
transformers의 구조
해당 Framework를 사용하기에 앞서 구조를 파악해 보겠다.
- Processors : Task를 정의하고 DataSet을 가공
- Tokenizer : 텍스트 데이터를 전처리
- Model : HuggingFace 사이트에서 Task에 적절한 모델을 선택한다.
- Optimization : optimizer와 schedule(warm up등) 관리
- Trainer : 모델 학습 과정을 관리
- Config : checkpoint를 저장하여 weight, tokenizer, model 불러올 수 있도록 설정 및 저장
- push_to_hub : Huggingface에 학습한 모델 로드
마치며
이러한 transformers의 구조를 바탕으로 위에서 말한 NLP의 다양한 Task 및 기법들을 살펴보도록 하겠다. transformers를 잘 활용하면 실제 모델 연구와 서비스 개발에 있어 매우 효율적으로 진행할 수 있을 것이다.
