들어가며
HuggingFace에 들어가면 이미 사전훈련된 수많은 모델들을 확인할 수 있다. 방대한 데이터와 사이즈가 큰 파라미터로 사전훈련된 모델을 사용함으로 우리는 비용과 시간을 절약하며 좋은 성능의 모델을 만들 수 있다. 오늘 알아볼 것은 이러한 사전훈련된 모델을 어떻게 가져와서 내가 사용하고자 하는 도메인에 적용할 수 있을까에 대한 질문에서 시작될 것이다.
feature-extraction, fine-tuning가 필요한 이유
BERT 같은 모델은 텍스트 시퀀스에 있는 마스킹 된 단어를 예측하도록 사전 훈련한다. 이렇게 사전훈련된 모델은 언어의 특징을 잘 파악하고 있지만 텍스트 분류와 같은 작업에 바로 적용되지는 못한다. 그렇기 때문에 언어 모델링층을 바꾸는 수정이 필요하다. 조금 더 자세한 내용은 아래의 이미지의 구조를 분해하며 파악해 보겠다.
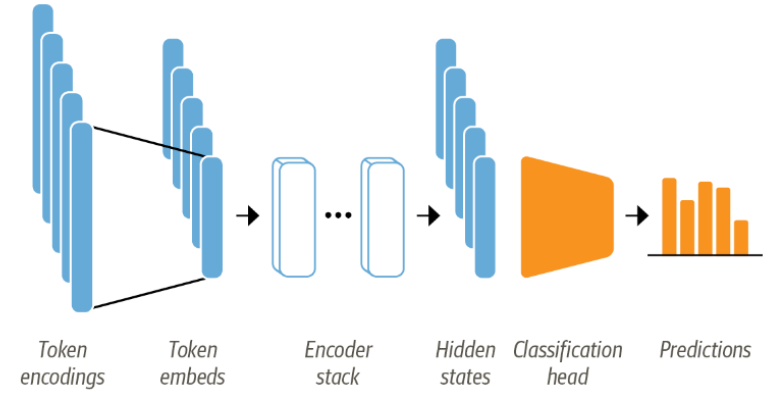
- 텍스트를 토큰화해서 토큰 인코딩을 한다. 여기서 토큰 인코딩의 차원은 어휘사전의 크기가 결정한다.
- 토큰 인코딩을 저차원 공간의 벡터인 토큰 임베딩으로 변환한다.
- 토큰 임베딩을 인코더 블록 층에 통과시켜 각 입력 토큰에 대한 은닉상태를 만든다.
- 각 hidden state는 언어 모델링의 사전훈련 목표를 달성하기 위해 마스킹 된 입력 토큰을 예측하는 층으로 전달한다.
- 마지막으로 언어 모델링층을 해당 도메인, 여기서는 분류층으로 바꾼다.
feature-extraction
feature-extraction은 사전 훈련된 모델을 수정하지 않고 hidden state를 특성으로 사용해 분류 모델을 훈련하는 것을 의미한다.
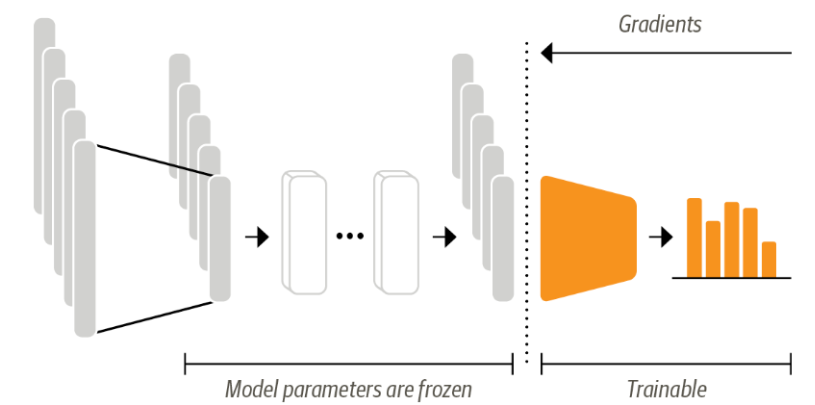
위의 그림과 같이 훈련하는 동안에는 body의 가중치를 freezing 하고 hidden state를 분류 모델의 특성으로 사용한다. 이때 모델은 주로 그레디언트에 의존하지 않는 기법인 랜덤 포레스트, 신경망 분류층 같은 기법의 모델을 사용한다.
이러한 feature-extraction의 장점은 빠르게 훈련해야 할 때 작거나 얕은 모델을 사용하지만 성능을 향상시킬 수 있다. 그리고 hidden state를 한 번만 미리 계산함으로 GPU를 사용하지 못할 때 유용하게 쓰인다.
with torch.no_grad(): # 그레디언트 자동 계산을 비활성화
output = model(**inputs).last_hidden_state #마지막 은닉상태 추출fine-tuning
fine-tuning은 feature-extraction과 반대로 사전 훈련된 모델의 파라미터까지도 모두 업데이트하기 위해 전체 모델을 end-to-end로 훈련한다.
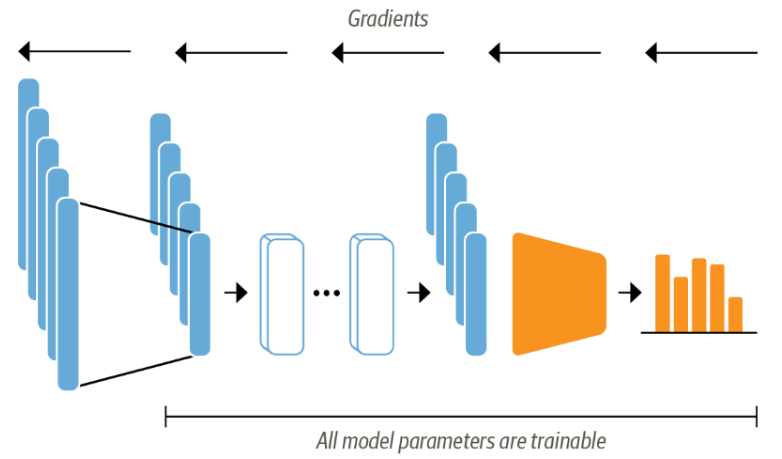
위의 그림과 같이 트랜스포머를 end-to-end로 미세 튜닝하기 위해서는 hidden state를 freezing 하지 않고 전체 모델을 훈련한다. 그리고 분류 헤드는 미분이 가능해야 한다. 따라서 이 방식은 신경망으로 분류작업을 수행한다. 입력으로 사용되는 hidden state를 훈련하면 분류 모델에 적합하게 모델 손실이 감소하도록 수정되며 성능이 올라간다.
마치며
이렇게 오늘은 feature-extraction과 fine-tuning을 알아보았다. 각 상황에 따라 필요한 기법을 골라서 사용하면 좋을 것 같다.
