

좌표 압축이란?
입력으로 주어지는 값의 범위에 비해 입력의 개수가 턱없이 작을 때, 배열의 값에 새로운 인덱스를 부여하는 기술을 말한다.
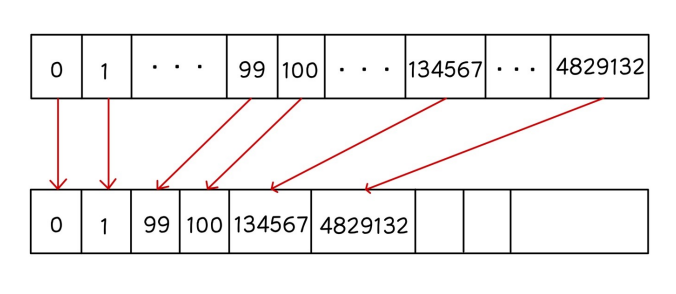
만약 들어오는 좌표의 종류가 {1, 23434, 9495444, 124, 8, 249833876, 23434} 라면,
이를 순서대로 정렬하고 {1, 8, 124, 23434, 23434, 9495444, 249833876}, 중복을 제거하여,
{1, 8, 124, 23434, 9495444, 249833876} 라는 새로운 좌표 배열을 만든다.
sort(v.begin(), v.end());
v.erase(unique(v.begin(), v.end()), v.end());그러면 저 수들을 1은 0, 8은 1, 124는 2... 처럼 새로운 배열의 인덱스로 치환할 수 있다. 이처럼 입력으로 주어지는 값의 범위에 비해 입력의 개수가 턱없이 작을 때는 메모리 공간을 절약하기 위해 좌표 압축을 하는 게 좋다.
그리고 압축된 배열에서 원래 배열의 원소 위치를 찾고 싶을 때는, lower_bound 함수로 해당 원소의 인덱스를 찾으면 된다.
int index = lower_bound(v.begin(), v.end(), num) - v.begin(); 오름차순으로 정렬된 N개의 원소에서 이분 탐색으로 원하는 값을 찾는 시간복잡도는 O(logN)이니까 lower_bound로 찾아주면 O(logN)만에 찾을 수 있다.
C++ 코드로 구현
#include <iostream>
using namespace std;
bool index[100'000'000]; // 메모리 초과
int main()
{
// 입력으로 주어지는 값의 범위는 1억인 반면에
// 입력의 개수는 1천으로 턱없이 작다!
// 배열을 그대로 사용하면 메모리 초과가 발생할 수 있다!
for(int i = 0; i < 1000; i++){
int val;
cin >> val;
index[val] = true;
}
for(int i = 0; i < 1000; i++){
int val;
cin >> val;
if(index[val]) cout << "배열에 있는 값\n";
else cout << "배열에 없는 값\n";
}
return 0;
}#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
vector<int> arr(100'000'000); // 메모리 초과 위험
// 좌표 압축
vector<int> compression(const vector<int> &arr){
vector<int> v = arr;
sort(v.begin(), v.end()); // 오름차순 정렬
v.erase(unique(v.begin(), v.end()), v.end()); // 중복 원소 제거
return v;
}
int main()
{
// arr에 입력값을 주었다고 가정하자.
// 좌표 압축
vector<int> pressed = compression(arr);
// 압축된 새 배열에서 특정 값의 인덱스 찾기 (이진 탐색)
int search = 123123;
int index = lower_bound(pressed.begin(), pressed.end(), search) - pressed.begin();
return 0;
}문제
https://www.acmicpc.net/problem/18870
수직선 위에 N개의 좌표 X1, X2, ..., XN이 있다. 이 좌표에 좌표 압축을 적용하려고 한다.
Xi를 좌표 압축한 결과 X'i의 값은 Xi > Xj를 만족하는 서로 다른 좌표의 개수와 같아야 한다.
X1, X2, ..., XN에 좌표 압축을 적용한 결과 X'1, X'2, ..., X'N를 출력해보자.
입력
첫째 줄에 N이 주어진다.
둘째 줄에는 공백 한 칸으로 구분된 X1, X2, ..., XN이 주어진다.
출력
첫째 줄에 X'1, X'2, ..., X'N을 공백 한 칸으로 구분해서 출력한다.
제한
- 1 ≤ N ≤ 1,000,000
- -10^9 ≤ Xi ≤ 10^9
입력의 개수 N은 100만 개인 반면에, 각 입력의 최댓값은 10억이므로 좌표 압축을 해야 메모리 초과가 나지 않는다.
예제
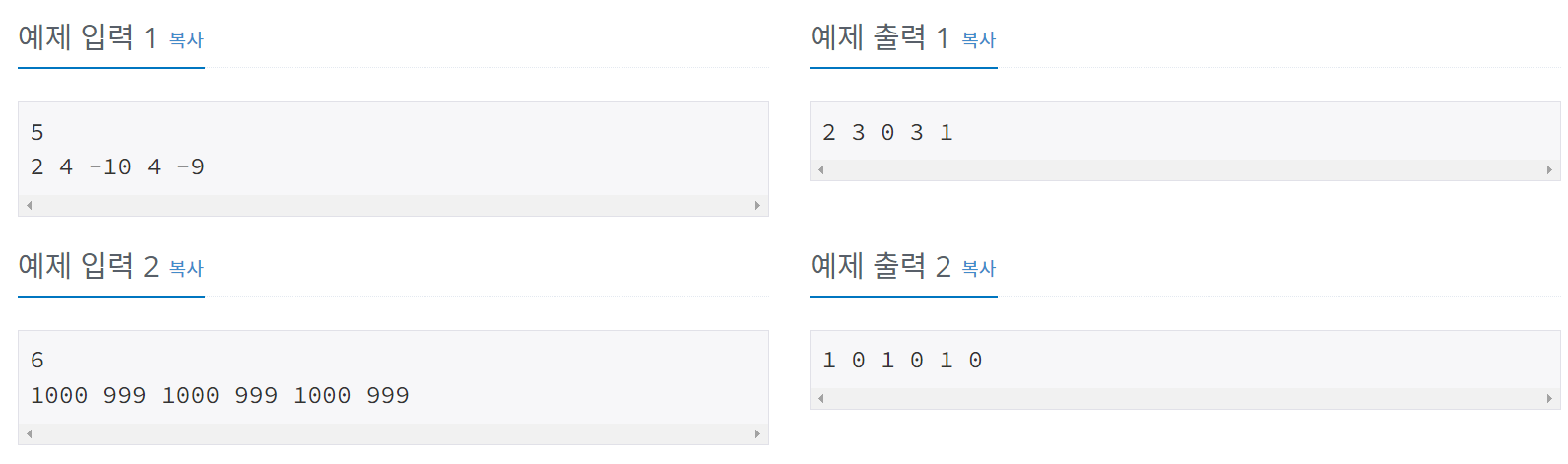
예제 입력 1
5
2 4 -10 4 -9
sort: -10 -9 2 4 4
unique, erase: -10 -9 2 4

예제 출력 1
2 3 0 3 1
풀이
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
const int MAX = 1000001;
int arr[MAX];
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
int n;
cin >> n; // 최대 100만
vector<int> v;
for(int i = 0; i < n; i++){
cin >> arr[i]; // 최대 10억
// 좌표 압축을 위해 복사본 벡터를 만든다.
v.push_back(arr[i]);
}
// unique 함수는 '연속으로' 중복된 원소들을 벡터의 맨 뒤로 보내므로
// 정렬을 먼저 해줘야 한다.
sort(v.begin(), v.end());
// unique 함수는 맨 뒤로 보낸 중복 원소들의 시작 위치를 반환한다.
// erase 함수는 그 위치부터 마지막 원소까지 삭제한다.
// 결과적으로, 중복 원소들이 삭제된다.
v.erase(unique(v.begin(), v.end()), v.end());
// 원래 배열의 원소가 새 배열의 어느 위치로 압축되었는지 출력
for(int i = 0; i < n; i++){
int idx = lower_bound(v.begin(), v.end(), arr[i]) - v.begin();
cout << idx << " ";
}
return 0;
}

정리 감사합니다! 잘보고 갑니다!