
LCS (Longest Common Subsequence, 최장 공통 부분 수열) 문제는 두 수열이 주어졌을 때, 모두의 부분 수열이 되는 수열 중 가장 긴 것을 찾는 문제이다.
최장 공통 문자열 (Longest Common Substring)
최장 공통 부분 수열 (Longest Common Subsequence)을 구하기 전에 최장 공통 문자열 (Longest Common Substring)부터 먼저 구해보자. 이 과정이 더 쉽고, 최장 공통 부분 수열을 구할 때도 사용되기 때문이다.
두 개의 차이점은 아래 그림을 통해 이해할 수 있다.
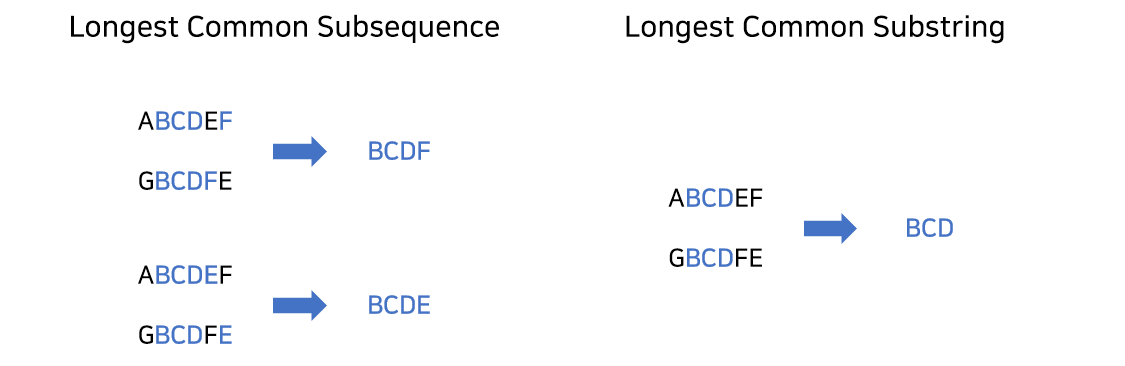
최장 공통 부분 수열은 BCDF, BCDE가 될 수 있다. 부분 수열이기 때문에 문자가 꼭 연속될 필요는 없다.
반면에, 최장 공통 문자열은 BCD이다. 한번에 이어져있는 문자열만 가능하다.
점화식
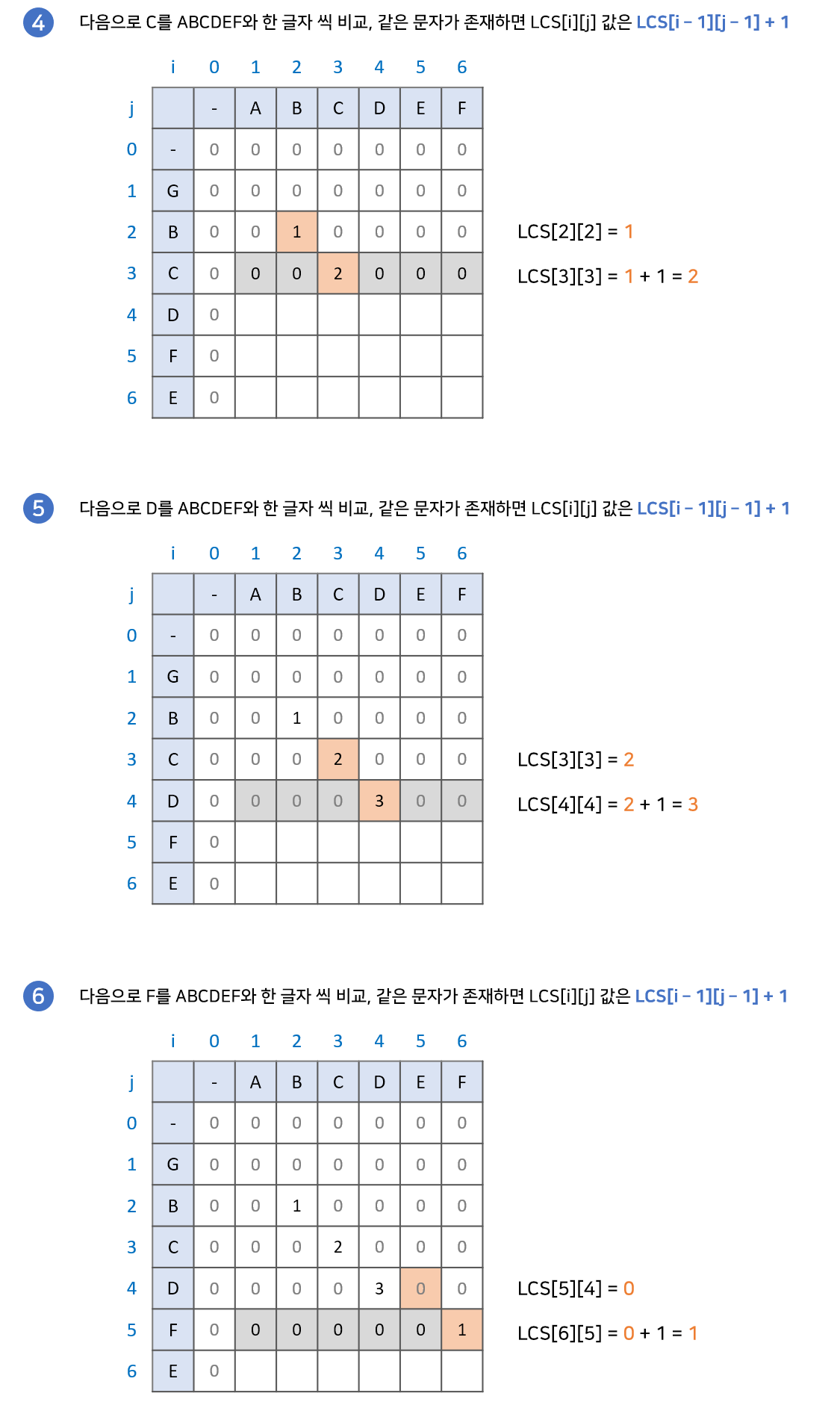
if(a[j] == b[i])
dp[i][j] = dp[i - 1][j - 1] + 1;
else
dp[i][j] = 0;
- i, j가 1 이상일 때부터 검사를 시작한다.
- 문자열 a, b를 한글자씩 비교한다.
- 두 문자가 다르다면, dp[i][j]에 0을 저장한다.
- 두 문자가 같다면, dp[i - 1][j - 1] + 1을 저장한다.
- dp 배열을 모두 채울 때까지 위의 과정을 반복한다.
- dp 배열 원소의 최댓값이 최장 공통 문자열의 길이가 된다.
위 과정이 성립하는 이유는 공통 문자열은 '연속'되어야 하기 때문이다.
현재 두 문자가 같을 때, 두 문자의 앞 글자까지가 공통 문자열이라면 해당 문자열이 계속 이어질 것이고, 아니라면 다시 처음부터 공통 문자열을 만들어 나갈 것이다.
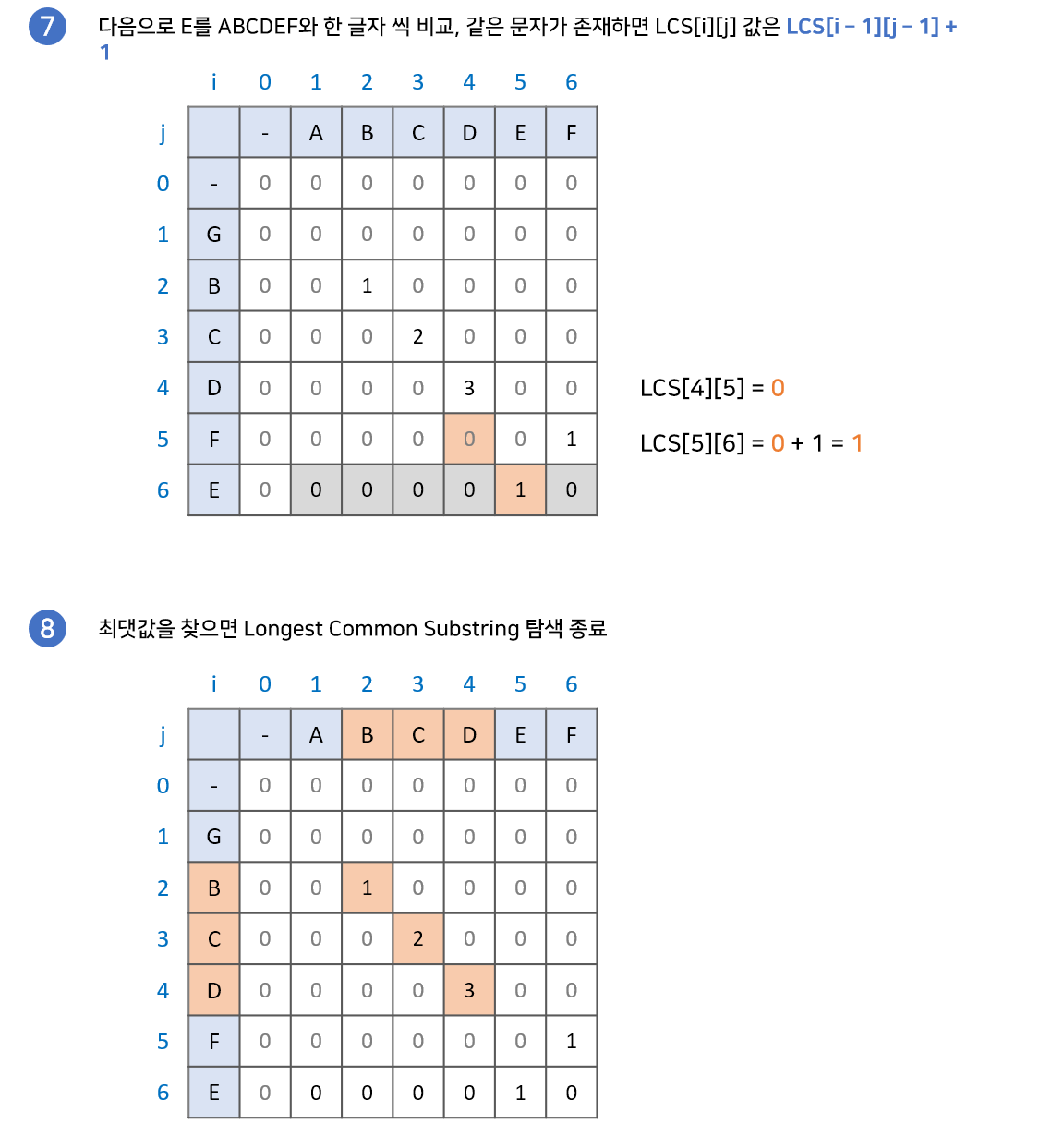
예시를 통해 이해해보자.
알고리즘

LCS 길이 구하기
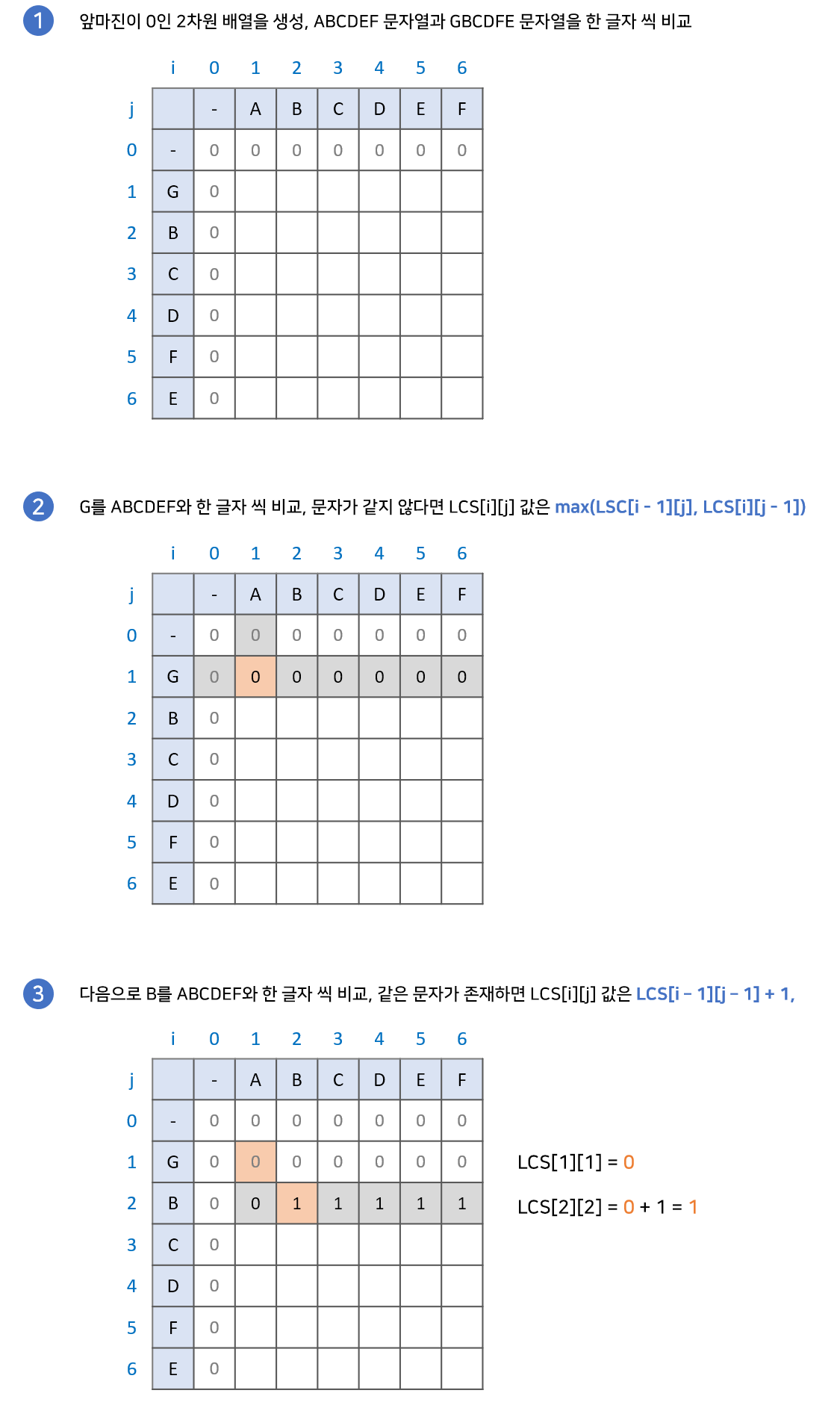
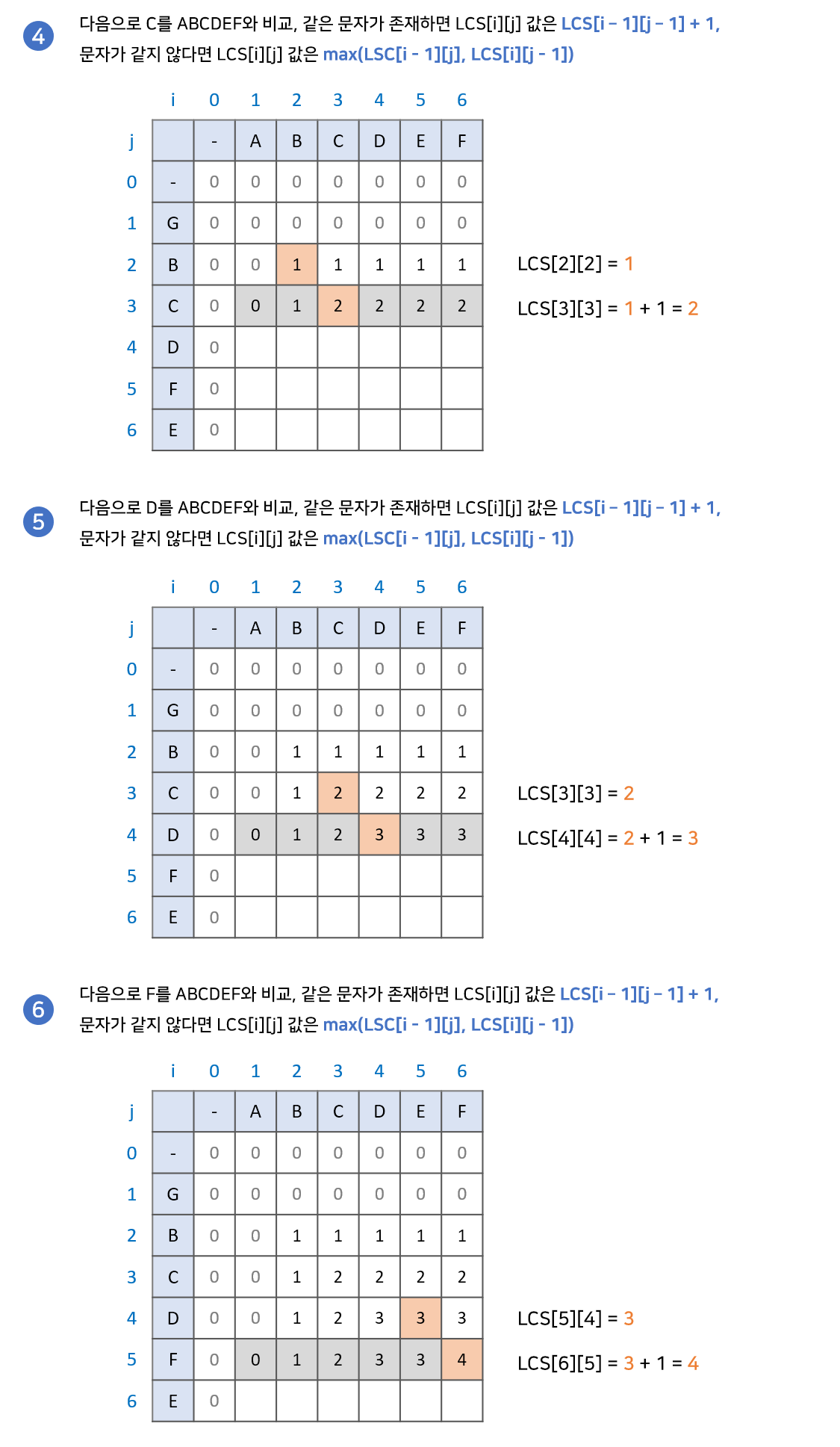
이번에는 최장 공통 부분 수열의 길이를 구해보자.
점화식
if(a[j] == b[i])
dp[i][j] = dp[i - 1][j - 1] + 1;
else
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
- i, j가 1 이상일 때부터 검사를 시작한다.
- 문자열 a, b를 한글자씩 비교한다.
- 두 문자가 다르다면, dp[i - 1][j], dp[i][j - 1] 중에 큰 값을 저장한다.
- 두 문자가 같다면, dp[i - 1][j - 1] + 1을 저장한다.
- dp 배열을 모두 채울 때까지 위의 과정을 반복한다.
- dp 배열의 마지막 원소가 바로 최장 공통 부분 수열의 길이가 된다.
최장 공통 문자열을 구하는 과정과 다른 부분은, 비교하는 문자가 서로 다를 때이다.
부분 수열은 연속된 값이 아니어도 된다. 따라서, 현재 비교하는 문자가 서로 다르더라도 그 이전까지의 최장 공통 부분 수열이 그대로 유지된다.
현재 문자를 비교하는 과정 '이전'의 과정이 바로 dp[i - 1][j], dp[i][j - 1] 이다.
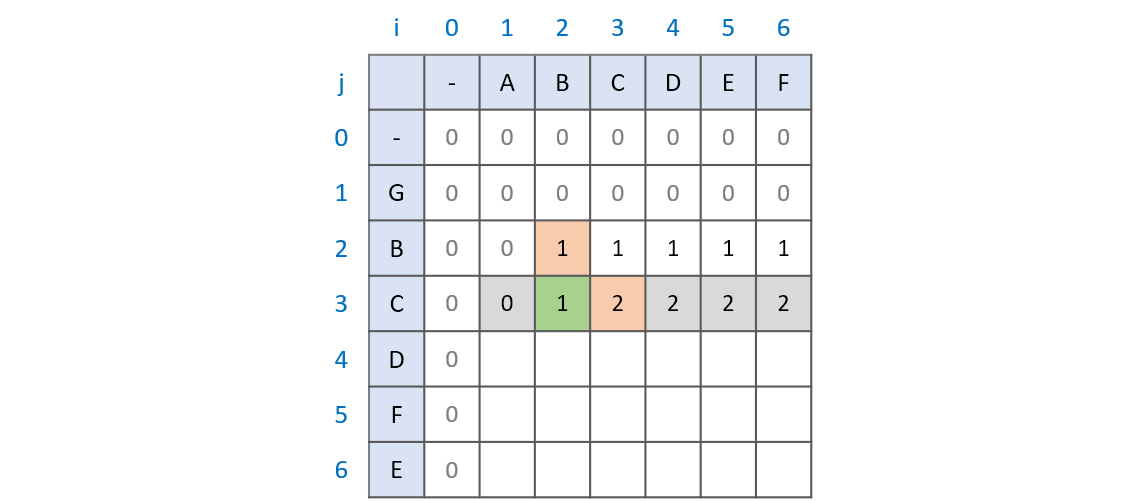
문자열 AB, GBC를 비교하는 과정을 살펴보자. AB, GBC의 최장 공통 부분 수열이 B라는 걸 알기 위해서는 문자열 A와 GBC, 문자열 AB와 GB를 비교하는 과정을 거쳐야 한다.
문자열 AB, GB를 비교하는 과정에서 최장 공통 부분 수열이 B라는 걸 확인했기 때문에, AB, GBC의 최장 공통 부분 수열 역시 B가 되는 것이다.

알고리즘

9251번 문제
https://www.acmicpc.net/problem/9251
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
#include <unordered_set>
#include <set>
using namespace std;
typedef pair<int, int> pii;
typedef long long ll;
const int MAX = 1001;
int dp[MAX][MAX];
int main() {
ios_base::sync_with_stdio(0);
cin.tie(0);
string a, b;
cin >> a >> b;
// 인덱스 조정을 위해 문자열 앞에 공백 추가
a = " " + a;
b = " " + b;
int row = b.size();
int col = a.size();
for(int i = 1; i < row; i++){
for(int j = 1; j < col; j++){
if(a[j] == b[i]) dp[i][j] = dp[i - 1][j - 1] + 1;
else dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
cout << dp[row - 1][col - 1];
}LCS 수열 구하기
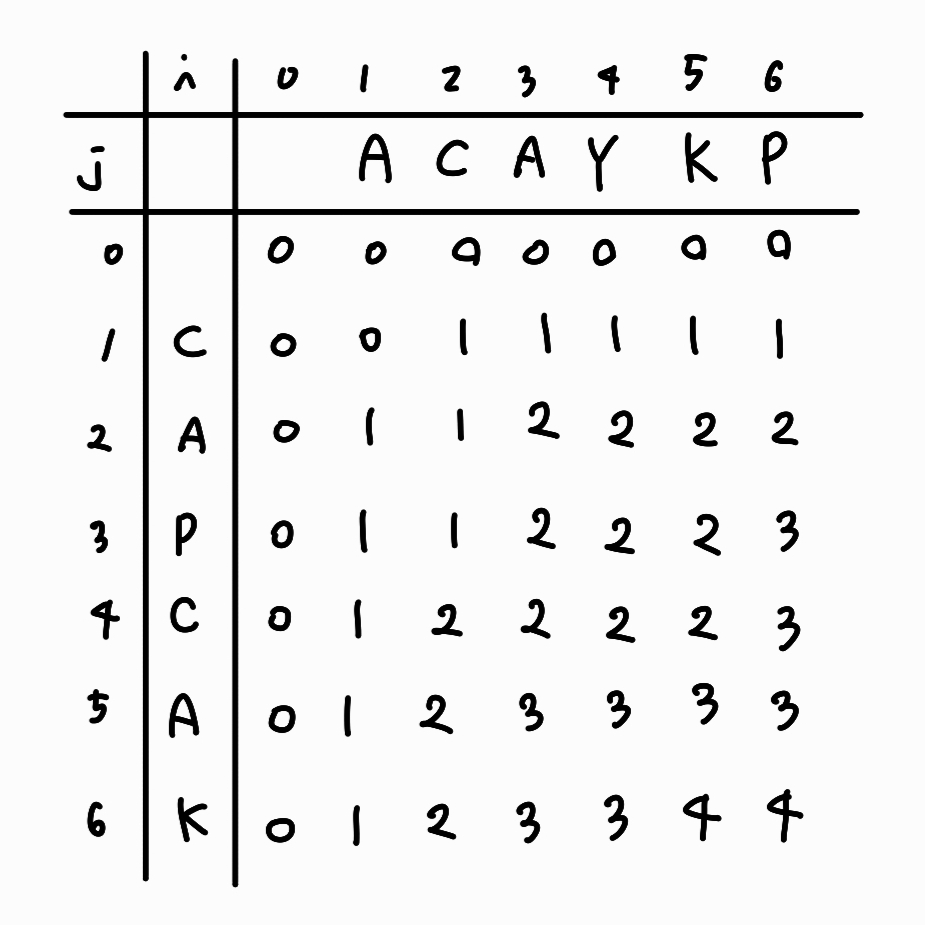
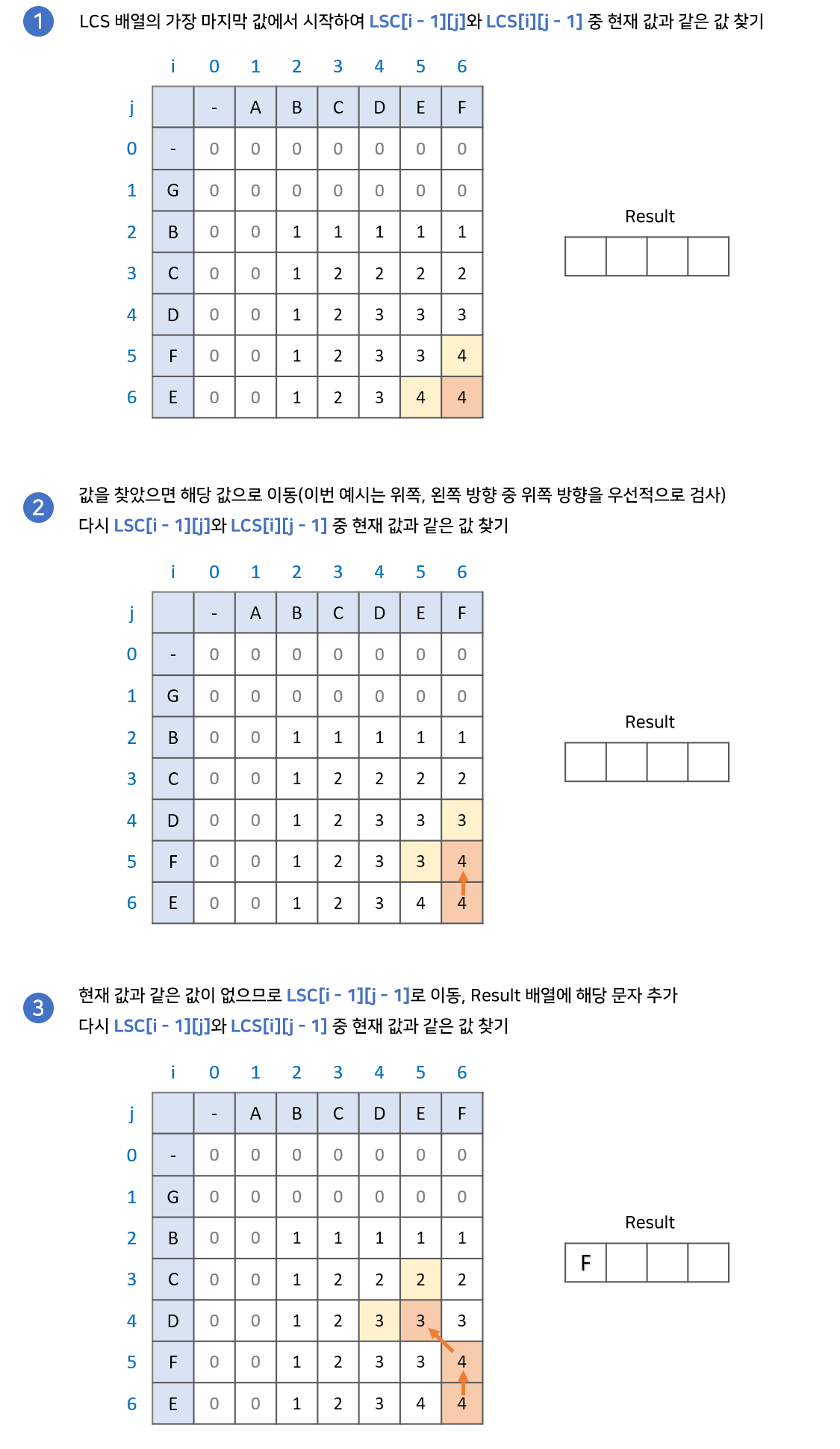
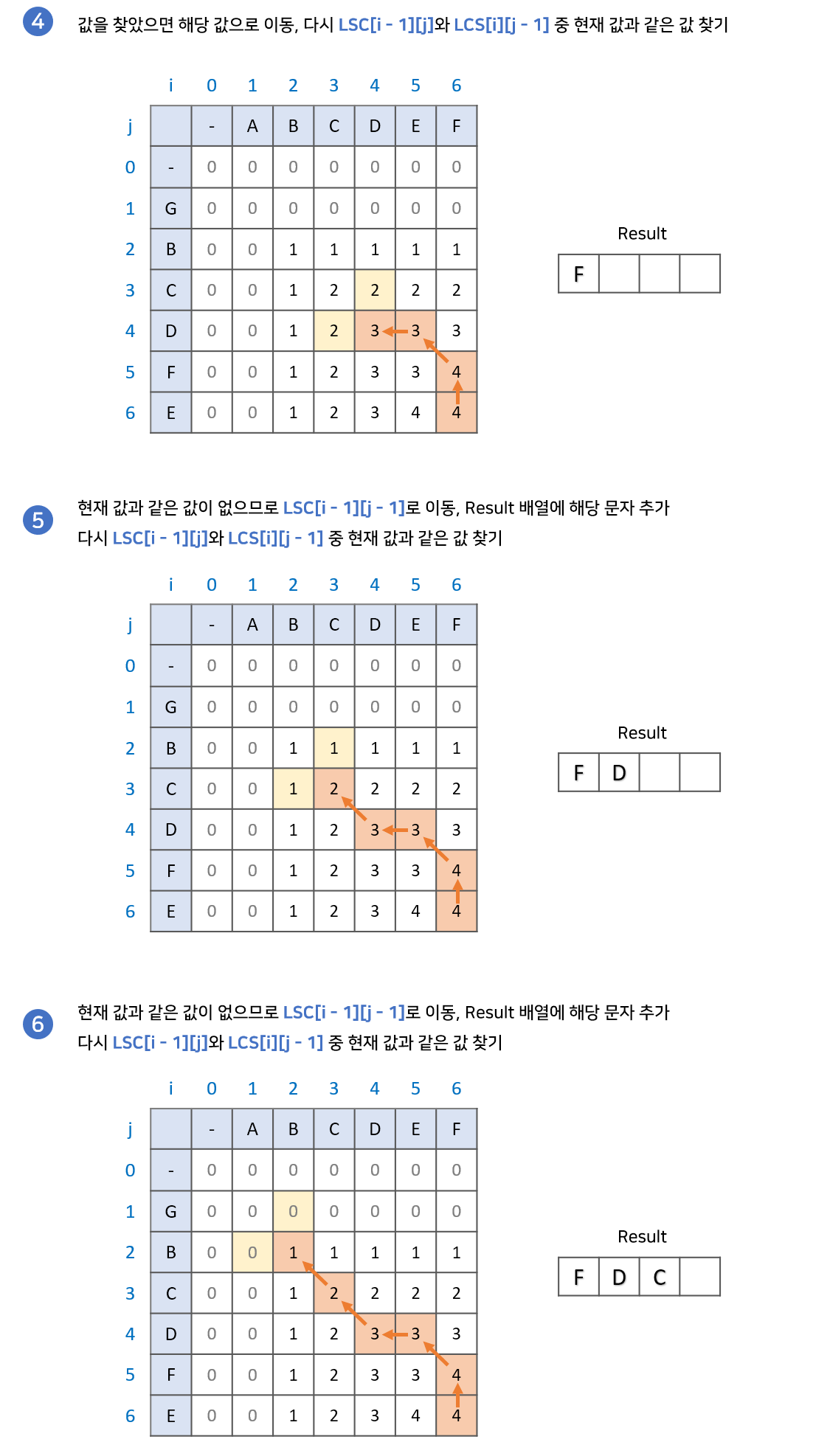
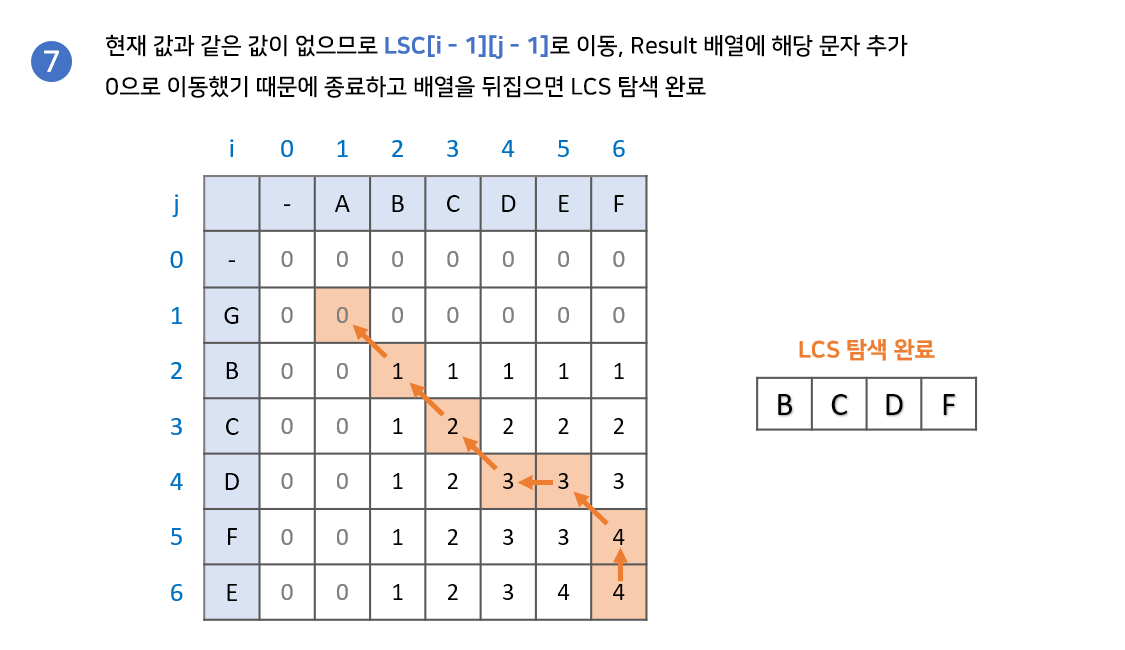
위의 과정을 통해 LCS의 길이를 구했다. 이번에는 dp 배열에 저장된 값을 이용하여 LCS 수열 자체를 구해보자. 경우에 따라 여러가지 답이 나올 수 있다.
- dp 배열의 가장 마지막 원소부터 시작한다. 결과값을 저장할 lcs 배열을 준비한다.
- dp[i - 1][j], dp[i][j - 1] 중에 현재 원소와 같은 값을 찾는다.
2-1. 만약 같은 값이 있다면, 해당 값으로 이동한다.
2-2. 만약 같은 값이 없다면, lcs 배열에 해당 문자를 추가하고 dp[i - 1][j - 1]로 이동한다.- 2번 과정을 반복하다가 dp 배열의 원소가 0인 지점까지 오면 종료한다.
- lcs 배열의 역순이 우리가 구하고자 하는 답이다.
알고리즘
9252번 문제
https://www.acmicpc.net/problem/9252
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
#include <unordered_set>
#include <set>
using namespace std;
typedef pair<int, int> pii;
typedef long long ll;
const int MAX = 1001;
int dp[MAX][MAX];
int main() {
ios_base::sync_with_stdio(0);
cin.tie(0);
string a, b;
cin >> a >> b;
// 인덱스 조정을 위해 문자열 앞에 공백 추가
a = " " + a;
b = " " + b;
int row = b.size();
int col = a.size();
for(int i = 1; i < row; i++){
for(int j = 1; j < col; j++){
if(a[j] == b[i]) dp[i][j] = dp[i - 1][j - 1] + 1;
else dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
string lcs = "";
int n = b.size() - 1;
int m = a.size() - 1;
while(dp[n][m] != 0){
if(dp[n][m] == dp[n - 1][m]){
n--;
}
else if(dp[n][m] == dp[n][m - 1]){
m--;
}
else {
lcs += a[m];
n--;
m--;
}
}
cout << dp[row - 1][col - 1] << "\n"; // 길이
if(lcs.size() > 0){
reverse(lcs.begin(), lcs.end());
cout << lcs; // 수열
}
}참고자료
