프로젝트 종료 후, 관련한 CS 지식들을 살펴보는데 MapReduce에 관해 좋은 내용인 글이 있어 좀 더 자세히 살펴본 후 글을 작성해보았다.
Shuffling 연산간 Combine 연산의 순서와 어느 시점에서 Mapper 노드의 디스크에 Mapping 결과 데이터가 저장되는지가 좀 헷갈렸어서 관련한 내용들을 더 찾아보았다.
MapReduce
- 거대한 입력 데이터를 쪼개어 수많은 머신들에게 분산시켜서 로직을 수행한 다음 결과를 하나로 합치자는 것이 핵심 아이디어임
- 개발자가 코드를 작성하는 부분은 map과 reduce 두 가지 함수임
- map은 전체 데이터를 쪼갠 청크에 대해서 실제로 수행할 로직
- Key Value 쌍의 결과가 나옴
- reduce는 분산되어 처리돤 결과 값을 다시 합쳐주는 과정
- map은 전체 데이터를 쪼갠 청크에 대해서 실제로 수행할 로직
MapReduce 전체 과정
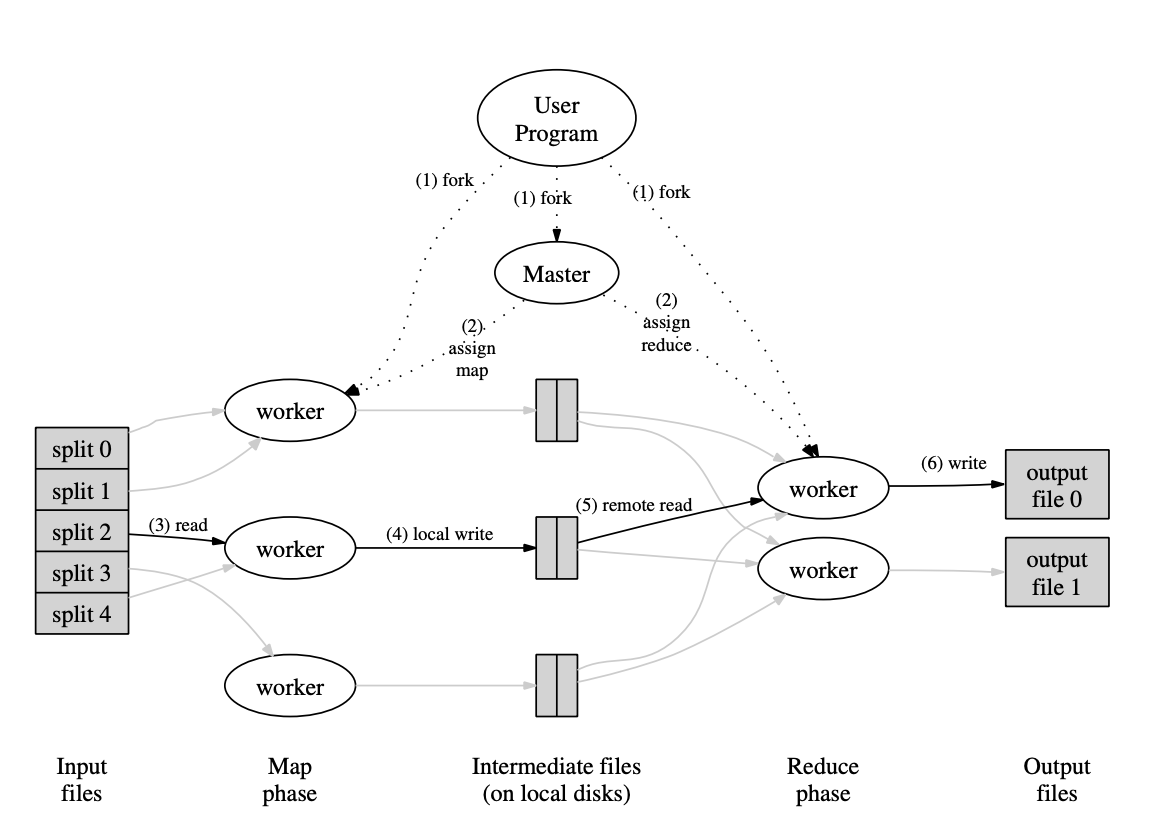
(1) fork
입력 파일은 쪼개어져 분산 파일 시스템에 저장되어있다고 가정.
사용자가 map과 reduce 함수를 정의한 프로그램을 실행시키면 이 프로세스는 각각 Master 노드, map연산을 실행할 워커 노드(Mapper), reduce 연산을 실행할 워커 노드(Reducer)들에 복사됨
(2) assign map and reduce
Master 노드는 Mapper에게 map을 Reducer에게 reduce 역할 지정해줌.
이 때, 사용자는 Mapper, Reducer의 노드 갯수를 지정해줄 수 있음
(3), (4) read, local write
Mapper 노드들은 쪼개어진 데이터 청크를 분산 파일 시스템으로부터 읽어옴.
읽어온 데이터에 사용자가 작성한 Map 함수를 실행하여 Key:Value 형태의 Intermediate 데이터를 생성하고 이를 각 노드의 로컬 디스크에 저장
그 다음, Mapper 노드는 마스터 노드에게 Map을 완료했다고 알려줌
(5), (6) remote read, wrtie
Mapper로부터 Map연산이 완료되었다는 통신을 받은 Master 노드는 Reducer 노드들에게 Reduce 연산을 시작하라고 명령을 내림
Reducer 노드들은 Mapper 노드들의 디스크 공간에 저장되어 있는 Key:Value 쌍의 Intermediate 데이터를 읽어오고, 이 데이터에 reduce 연산을 실행하여 최종 결과물을 산출함
Shuffling
- Mapping으로 생성된 intermediate Key:Value 데이터를 Reducer 노드에 입력으로 전달하기 이전의 과정들
- 구체적으로는 동일한 키 값을 지닌 intermediate Key:Value 쌍은 동일한 Reducer에게 전달되어야하며, 이 매핑 과정을 셔플링이라함
Shuffling 과정
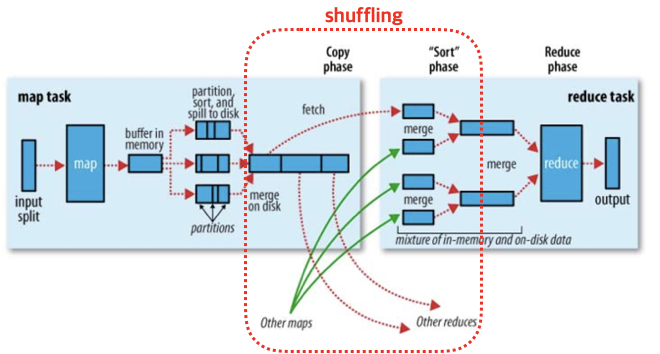
-
Mapper로부터 Map연산후 생성된 intermediate Key:Value 쌍은 일단 메모리 상의 버퍼에 저장됨
- 메모리가 부족할 경우 Spill이 발생할 수 있음.
- 또한, Spill이 발생할 경우 아래 2번 ~ 5번 과정이 수행되며 spill은 여러번 발생할 수 있음
- 즉, 한 Map 태스크간 여러개의 스필된 파일들이 디스크에 저장되며, Map 연산이 완료가 되면 이들을 하나의 파일로 병합하고 다시 정렬하는 과정을 거침
-
그리고 Combining이라는 과정을 거쳐 파티션 내의 Key:Value 데이터들에 대해 Reduce 작업을 미리 진행하여 Reducer 노드들의 부하를 줄여줌(선택사항)
- 이는 수많은 intermediate 데이터들이 Reducer 노드들로 전달되면서 생기는 네트워크 혼잡을 예방해주기도 함.
- 이는 Mapper 노드에서 일어나는 연산이며, 메모리 단에서 일어남
- 불필요하다면 이 과정을 생략할 수도 있음. 이는 사용자가 판단해야할 몫임
- 정렬과 같은 순서에 민감한 연산의 경우 사용하지 않는게 나을 수 있음
-
이제 intermediate Key:Value 쌍의 키 값을 해싱하여 파티션을 결정하는 파티셔닝을 수행
- 이는 해당 키가 처리되어야하는 Reduce task를 기준으로 데이터를 구분해줌
- 즉, 어느 Reducer에서 실행될지 정하여 파일을 나누는 것이 파티셔닝
- 하둡에서는 기본적으로 키 값을 Reducer의 갯수로 해싱하는 방식을 사용(key MOD num of reducers)
- 이는 물리적인게 아닌 논리적인 파티션을 생성함
- 즉, 한 파티션은 한 Mapper 노드에만 존재하는게 아니고, 여러 Mapper노드들로부터 같은 키 값을 갖는(혹은 같은 Reducer에서 수행될) 데이터들의 논리적인 그룹임
- 이는 해당 키가 처리되어야하는 Reduce task를 기준으로 데이터를 구분해줌
-
파티션된 Key:Value 쌍들은 다시 키 값을 기준으로 파티션내에서 정렬하는 과정을 거침
- 이는 한 Reducer 노드 내에서 더 빨리 Reduce 연산을 수행하기 위한 정렬 작업임
-
정렬이 완료되면, Mapper 노드들은 모든 중간 데이터를 디스크에 저장
-
Mapper는 매핑 과정을 완료했다는 알림과 파티셔닝 정보를 Master 노드에게 전달
-
Master 노드는 Reducer 노드들에게 이 정보들을 전달하고, Reduce를 수행할 것을 명령
-
Reducer 노드들은 전달받은 정보들을 바탕으로 자신에게 할당된 파티션들만 Mapper 노드의 디스크로부터 읽어와서 리듀스 작업을 시작
MapReduce의 한계
- 복잡한 셔플링
- 셔플링 과정이 복잡하며 속도가 느림
- 이는 Map과 Reduce 연산에 비해서도 훨씬 큰 지연시간을 보여주기도 함
- 잦은 파일 입출력
- Mapper는 처리한 데이터를 디스크에 쓰고, Reducer는 다시 이 파일을 읽어와 리듀스 연산 후 결과 파일을 분산 파일 시스템에 출력함
- 이런 반복적인 Disk I/O 는 성능 저하의 원인이 됨
- 추후 등장한 Spark는 이러한 단점을 해결하기위해 메모리에서 연산을 수행함
- MapReduce 연산만으로는 현실의 모든 문제를 풀기에 제약이 많음
- Key Value 형식의 데이터만 지원하므로, 입력 데이터를 이러한 구조로 변환해야하는 제약이 있음
- 생산성이 부족함
- 배치 작업 중심임
- 실시간성보다 처리량에 초점이 맞춰짐
References
https://yeomko.tistory.com/31
https://data-flair.training/blogs/hadoop-combiner-tutorial/
https://kadensungbincho.tistory.com/117
https://cloud.google.com/blog/products/bigquery/in-memory-query-execution-in-google-bigquery?hl=en
https://s-space.snu.ac.kr/handle/10371/133243
수정사항
- 2024.10.23: 셔플링 과정 세부 내용 및 참조 링크 추가

포스팅 잘 읽었습니다! 위 내용에서 분산 처리 시스템의 기본적인 개념들이 많이 내포되어 있는것 같아요. 다음과 같은 내용이 더 궁금해졌습니다
1) 태스크 실패시, 어떻게 복구하는지
2) 셔플시 네트워크 혼잡을 어떻게 예방하고 줄일 수 있는지