이번 게시물은 데브코스 최종 프로젝트 수행간 겪었던 문제를 해결하면서 배운 내용을 작성한 게시글이다.
최종 프로젝트 기간동안 데브코스에서 지원해주는 AWS Glue의 pyspark를 활용해보기 위해 우리 조는 약 4백만 행의 디멘션 테이블부터 최대 4억 행의 팩트 테이블까지 랜덤 생성하였다.
랜덤으로 데이터를 생성하면서 데이터들을 일부러 편향되도록 구성을 하였고(현실에서는 소수의 원인이 다수의 결과를 만듬), 편향된 데이터를 다룰 때 생기는 문제들을 해결하고자 하였다.
여기서는 편향된 데이터를 JOIN시 발생하는 문제를 소개하고, 해결하는 방법들을 소개하고자 한다.
1. 사용 데이터와 환경 조건
user info 테이블
- 약 4백만 명의 유저 정보를 가지고 있는 테이블
- user id로 행이 구분이 됨(Primary key)
airline click log 테이블
- 4억건의 행을 가지고 있음
- 3,143,424 명의 유저의 항공권 클릭 기록
- 즉, DISTINCT(user id)의 갯수가 3,143,424개
- 이 중 30명의 유저가 전체 행의 80%의 기록을 가지고 있는 매우 편향된 테이블
→ 이 두 테이블을 user id로 조인한 후, 연령대별 클릭 기록을 구할 것임
환경
- AWS Glue 3.0의 pyspark를 사용
- G1.X wortker, 10 DPUs
- shuffle partition = 36
2. 조인부터 해보기
일단 data skew를 생각하지 말고, 정말 간단하게 조인부터한 후, 집계하는 SQL문을 작성해보자.
SELECT age - MOD(age, 10) as age_group, COUNT(1)
FROM airline_click_log acl
JOIN user_info u
ON acl.user_id = u.user_id
GROUP BY 1이제 이 쿼리문을 실행해보자
실행결과
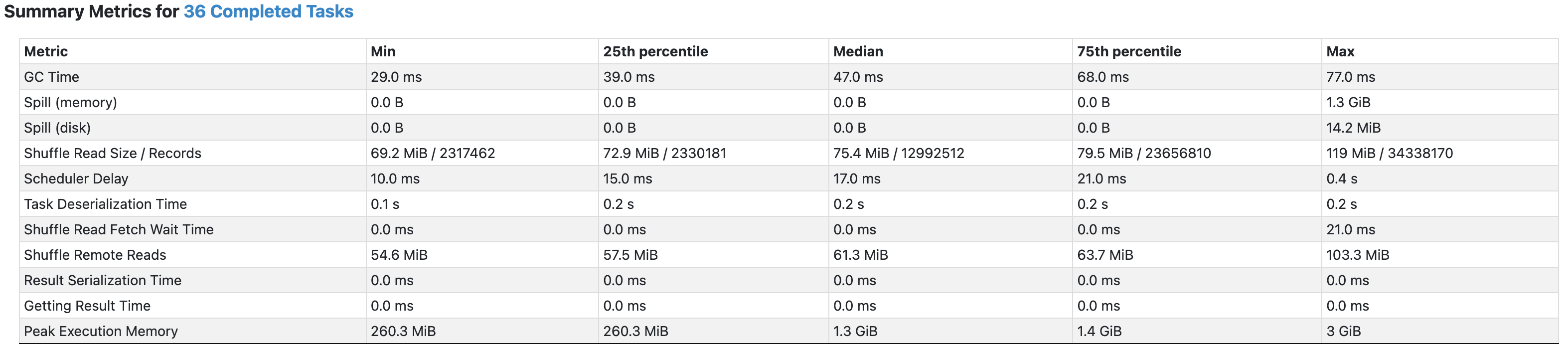
- Max에 해당하는 파티션들에 1.3GB의 memory spill이 발생하였음을 알 수 있다.
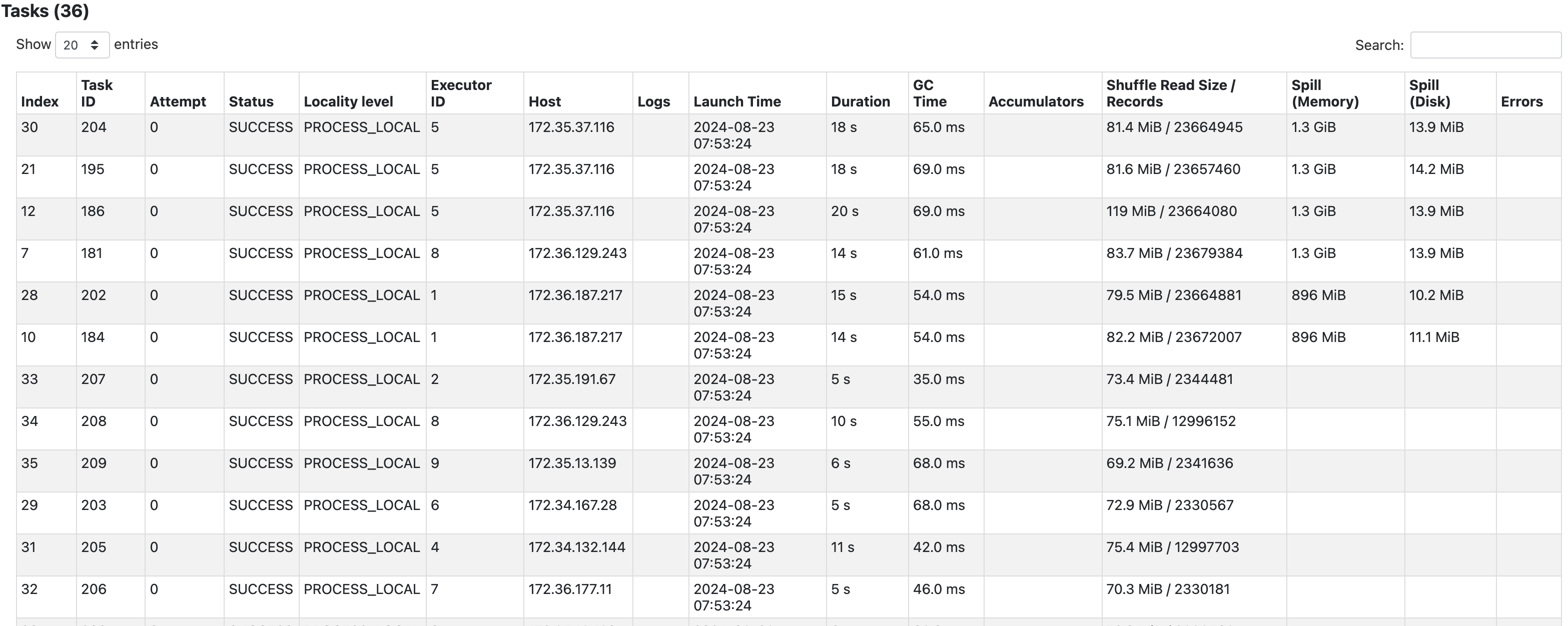
- 총 6개의 태스크에 896MB ~ 1.3GB의 memory spill이 일어났다.
먼저 조인시 결론
spill은 셔플시 메모리가 충분하지 못할 때 발생하는데 메모리 내에서 처리하기 힘든 데이터를 임시로 디스크나 기타 스토리지에 저장후 다시 불러와야해 이 과정에서 발생하는 디스크 입출력과 직렬화/역직렬화 과정으로 시간 소요가 더 길어지게 된다.
따라서, 편향된 데이터를 join시 특정 태스크에서 spill이 발생하게 되어 큰 지연이 발생하고,
다른 태스크들은 이미 작업이 완료되었음에도 이 태스크들을 기다려야 해,
이는 전체 연산시간 지연의 큰 원인이 된다.
3. Salt key
그렇다면, 이러한 데이터 불균형으로 발생하는 spill을 예방할 수는 없을까?
이번 게시글에서는 이를 해결할 수 있는 기법 중 하나로 salting이라는 기법을 소개하고자 한다.
Salting은 “소금 뿌리기”라는 뜻으로, 데이터에 소금을 뿌려 균형을 맞추는다는 개념으로 보면 된다.
특정 컬럼을 기준으로 셔플링을 발생시킬 때 데이터 편향이 발생하는 경우,
이 편향된 데이터를 분산시키기 위해 셔플링 연산에 참여하는 key를 더 추가하는데,
이를 salt key라 한다.
그렇다면, 이 salt key를 어떻게 생성하여 사용하는지 알아보자.
먼저, 데이터 편향이 발생한 팩트 테이블에서는 salt key라는 컬럼을 추가하도록 한다.
추가하는 방법은 다음과 같이 난수를 추가해주면 된다.
다음 예시에서는 편향되어있는 테이블인 airline click log에 0 ~ 4까지 난수를 갖는 salt key컬럼을 추가한다.
SELECT user_id, FLOOR(RAND() * 5) AS salt_key
FROM airline_click_log이제 같이 JOIN 해줄 user info 테이블에도 동일하게 salt key를 추가해주면 효과가 없다!
왜냐하면 user info 테이블에는 user id 마다 각 행이 하나씩 있기 때문에, user id마다 행수를 더 늘려줘야 한다.
늘려주는 갯수는 우리가 위에서 0 ~ 4까지 난수를 5개 줬으니, user id 당 행수를 5개까지 만들어주어야 한다.
다음 예시는 user info 테이블에 0 ~ 4까지의 salt key를 주면서, 그만큼 행들을 추가한다.
SELECT user_id, age, EXPLODE(ARRAY(0, 1, 2, 3, 4)) AS salt_key
FROM user_info이제 이 두 테이블을 user_id와 salt key를 통해 JOIN을 하면 된다.
SELECT age - MOD(age, 10) as age_group, COUNT(1)
FROM (
SELECT user_id, FLOOR(RAND() * 5) AS salt_key
FROM airline_click_log
)
airline_click_log INNER JOIN (
SELECT user_id, age, EXPLODE(ARRAY(0, 1, 2, 3, 4)) AS salt_key
FROM user_info
)
user_info USING(user_id, salt_key)
GROUP BY age_group;그럼 이제부터, 부여한 salt key 갯수마다 얼만큼의 효과가 있는지 살펴보자
Salt size = 10
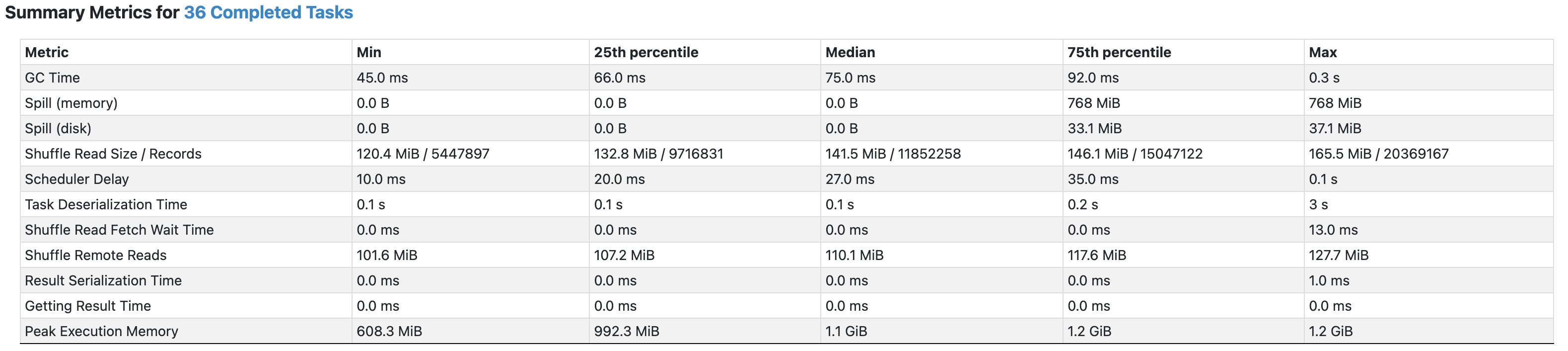
- 이전에는 Max에 해당하는 파티션의 shuffle read records수가 약 3천4백만이었던데 반해,
이번에는 약 2천만으로 감소되는 등 전반적으로 균등하게 퍼진모습을 볼 수 있다. - 하지만, 아직도 skew가 존재하고, spill또한 존재함을 볼 수 있다.
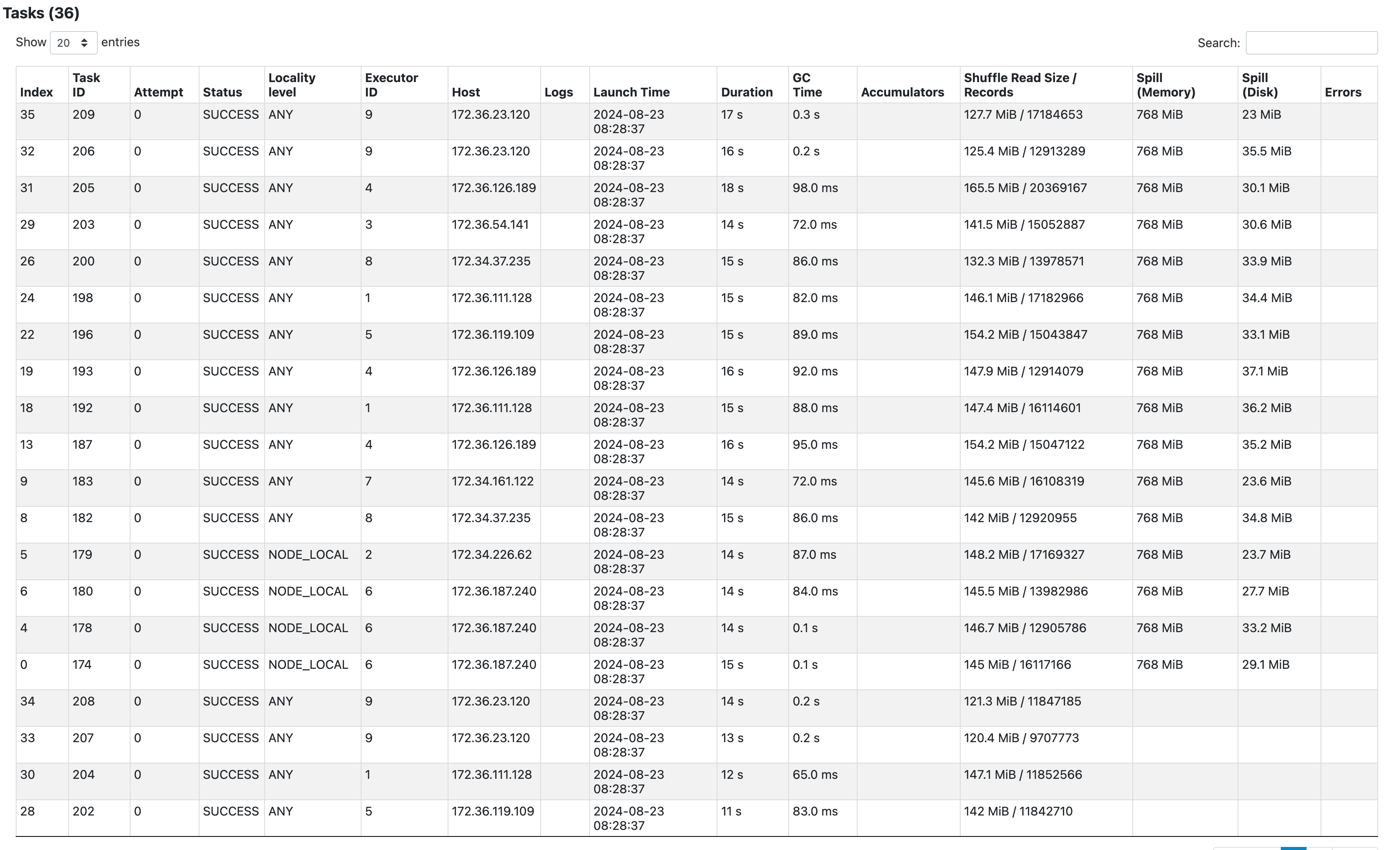
- 파티션당 spill되는 크기는 줄었지만, 오히려 spill되는 파티션의 수가 늘어나 전체적인 spill 양은 더 커졌다.
- 이는 user info 테이블의 크기가 salt size만큼 10배 증가하였기 때문으로 보인다.
Salt size = 20
salt size = 10 정도로는 data skew가 해결되지 않았으니, 이번에는 그 두배로 주어 테스트해보자.
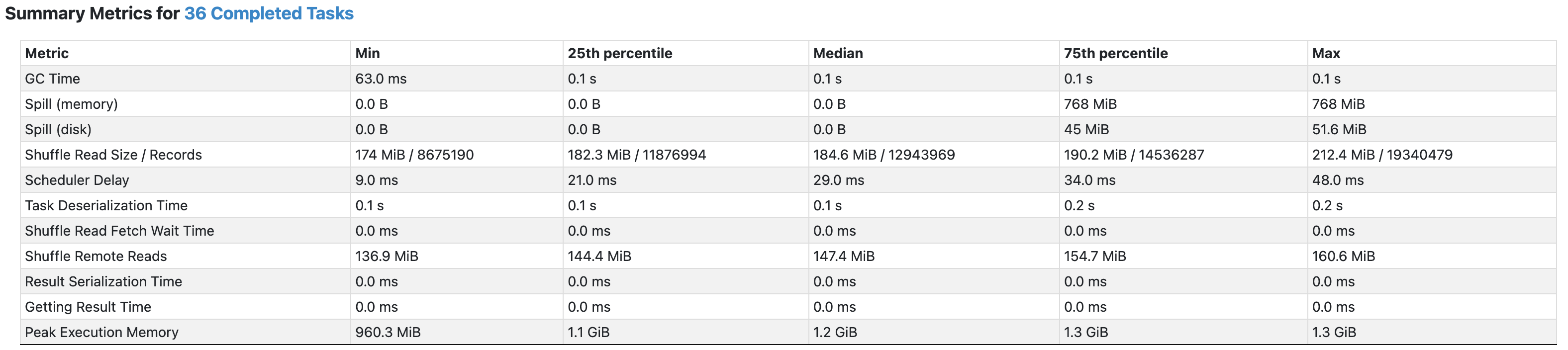
- 10일 때보다 조금은 더 완화되었지만, 그래도 불균일하다.
- 또한, user info 테이블이 20배 커지면서 셔플링되는 사이즈가 전체적으로 더 커졌다.
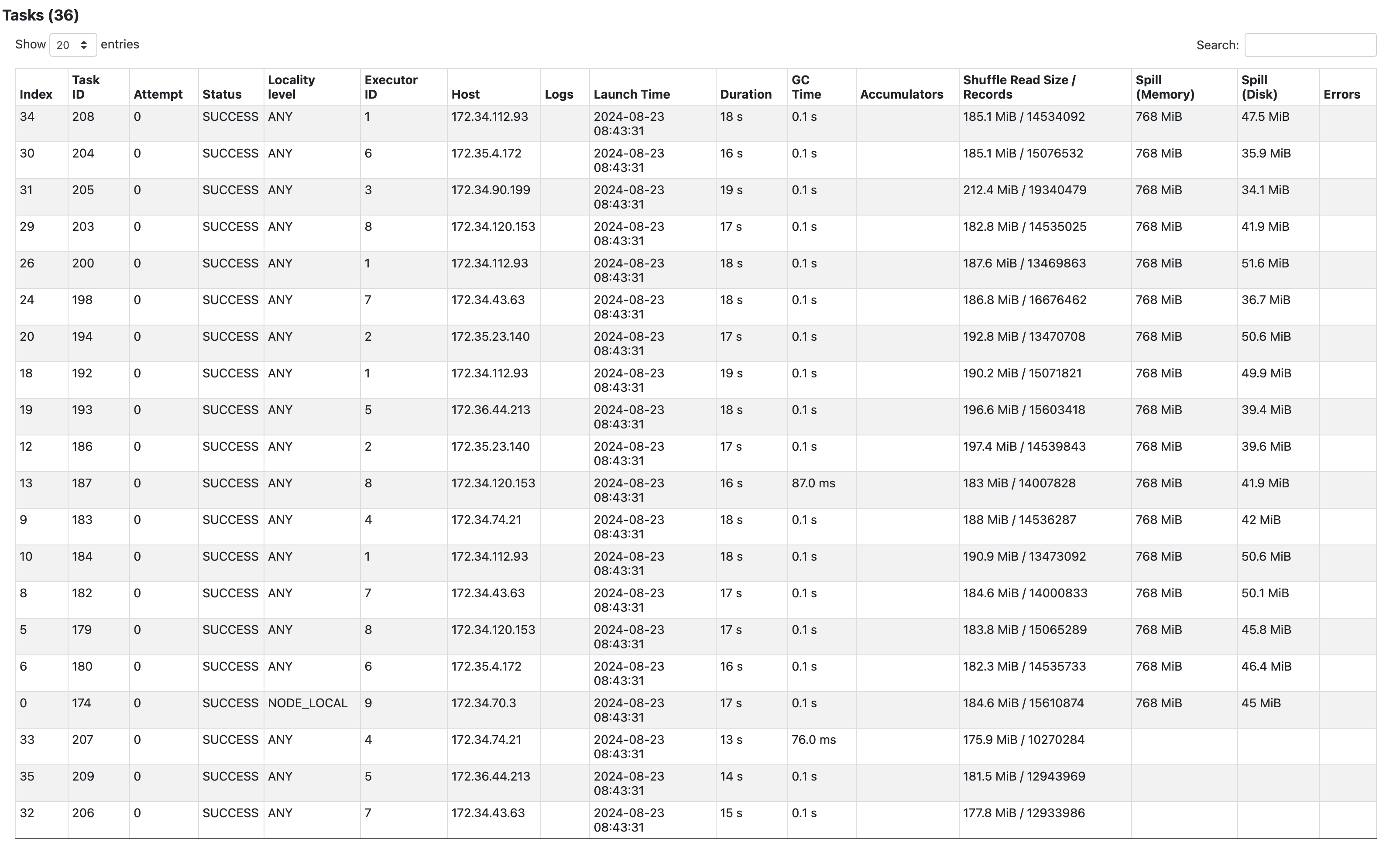
- user info 테이블이 더 커지면서 spill이 일어난 파티션이 한 개 더 증가했다.
기본 Salting시 결론
위 예시들을 통해 편향된 레코드들이 어느정도 균일하게 퍼져나가, spill이 다른 파티션들로 조금 퍼져나간 것도 확인할 수 있었다.
하지만, 이 방법에는 가장 큰 문제가 있다. 바로, user info 테이블의 크기가 너무나 커질 수 있다는 점이다.
그로인해, 오히려 더 많은 크기의 셔플이 발생하였고, 전체적인 spill의 양은 더 늘어났다.
또한, 데이터가 편향된 정도가 너무 극심하다보니, user id당 salt key를 20개씩이나 줬음에도 편향이 완전히 해결되지 않았다.
완전히 해결을 하려면 이보다 훨씬 큰 salt size를 줘야할 것 같은데, 그러기에는 user info의 크기가 너무나 커져 의미가 없다.
4. Salt key 심화
위의 경우에는 user info 테이블의 salt size에 비례하여 폭발적으로 증가시키기 때문에,
오히려 더 많은 spill이 발생하였다.
또한, skew된 정도가 너무나 크다보니, 완전히 data skew를 해결하지도 못 하였다.
그렇다고 salt size를 더 늘리자니, 더 커져가는 user info 테이블의 크기는 너무나 부담스럽다.
그런데, user info 테이블의 모든 행에 굳이 salt key를 여러개씩 부여할 필요가 있을까?
skew가 일어나는 30개의 유저 행에 대해서만 salt key를 여러개주면 되지 않을까?
만일 그렇게 준다면, 30명 유저에 해당하는 user info의 행을 10만개씩으로 늘려도, 증가된 user info 테이블의 크기는 700만 행, 기존의 400만 행의 두배도 안될 것이다.
이런 방법으로 한번 salt key를 부여해보자.
먼저, Salt key별로 쪼갤 행의 최대 갯수(AGGREGATION_SIZE)를 지정해주고, airline click log 테이블의 유저 아이디별 갯수를 집계하자.
이 집계한 데이터는 salt size를 정할 때 사용할 것이다.
또한, 집계한 데이터를 AGGREGATION_SIZE보다 COUNT가 더 많은 유저아이디 행들만 필터링해주자.
이는 브로드캐스트 조인을 위해 데이터 크기를 줄이는 것이다.
AGGREGATION_SIZE = 1_000_000 # 100_000 >> 10_000 >> 1000 >> 100(data skew solved)
clicked_user_counts = airline_click_log.groupBy('user_id').count().filter(col('count') > AGGREGATION_SIZE)- 여기서 새로 생성한 데이터프레임인 clicked user counts는 airline click log 테이블과
user info 테이블에 각각 LEFT JOIN 하여 user id별 salt size를 지정하는 지표가 될 것이다. - 또한, 이렇게 필터링을 한 경우는 대부분 브로드캐스트를 해도 될만큼 데이터가 작아질 수 있는데
왜냐하면, 쏠리는 데이터의 경우 파레토 법칙을 따르기 때문이다.
이처럼 적절한 수준의 필터링 조건이 주어진다면, clicked user counts는 원래 크기 대비 로그스케일로 줄어들 수 있고, 대부분의 경우 로그스케일로 줄더라도 수백만개의 행을 갖는 데이터는 거의 없다고 한다.
- 파레토법칙: 80%의 결과가 20%의 원인에 의해 발생 - 우리의 예시에서는 AGGREGATION_SIZE를 100으로 주었을 때, skew와 spill이 해결되었다.
그 다음, user id별 salting size를 구할 udf와 explode에 사용할 array를 주어진 salting size에 맞게
생성해줄 udf를 만들자
@udf(returnType=IntegerType())
def get_salting_size(count):
if count is None:
return 1
div = count // AGGREGATION_SIZE
remain = count % AGGREGATION_SIZE
if remain == 0:
return div
return div + 1
@udf(returnType=ArrayType(IntegerType()))
def get_salting_array(size):
return list(range(size))- get salting size()의
count is None조건을 통해, 위에서 필터링 했던 파티션 사이즈보다
작은 행을 갖는 user id의 경우 1의 salt size를 갖게된다.
이는, 작은 행을 갖는 user id의 salt key가 예외를 발생시키지 않고 하나씩만 생성되도록 한다.
이제, udf를 활용하여 쿼리를 작성해보자
# airline click log
airline_click_log = airline_click_log.join(broadcast(clicked_user_counts), on='user_id', how='left')
airline_click_log = airline_click_log.withColumn("salting_size", get_salting_size(col('count')))
airline_click_log = airline_click_log.withColumn(
"salting_key", (rand() * col('salting_size')).cast(IntegerType())
)
airline_click_log.createOrReplaceTempView('airline_click_log')
# user info
user_info = user_info.join(broadcast(clicked_user_counts), on='user_id', how='left')
user_info = user_info.withColumn('salting_size', get_salting_size(col('count')))
user_info = user_info.withColumn(
'salting_key', explode(get_salting_array(col("salting_size")))
)
user_info.createOrReplaceTempView('user_info')
# result
result = spark.sql("""
SELECT age - MOD(age, 10) as age_group, COUNT(1)
FROM airline_click_log acl
JOIN user_info u
ON acl.user_id = u.user_id and acl.salting_key = u.salting_key
GROUP BY 1
""")- 이렇게 하면, user info에 salt key를 줄 때, 우리가 지정한 AGGREGATION_SIZE보다 큰 갯수의 행을 갖는 user id들만 행이 복제될 것이다.
그럼 이제, AGGREGATION_SIZE를 다르게 주어 하나씩 시험해보자
AGGREGATION_SIZE = 1,000,000
airline click log에서 30명의 유저는 대략 1060만행을 갖고, 나머지 유저는 평균 50개의 행을 갖는다.
- airline click log 유저별 행 갯수 사진

그렇다면 AGGREGATION_SIZE를 백만으로 둔다면, 30명의 유저만 11개의 salt key에 의해 쪼개질 것이다.
이는 이전의 salt size = 10으로 둔 경우와 비슷해보이지만, user info의 크기는 이전에는 10배였던 것에 반해, 기존 크기에 30 x (11 - 1) = 300개의 행만 추가된 형태일 것이다.
한번 실험 결과를 보자.
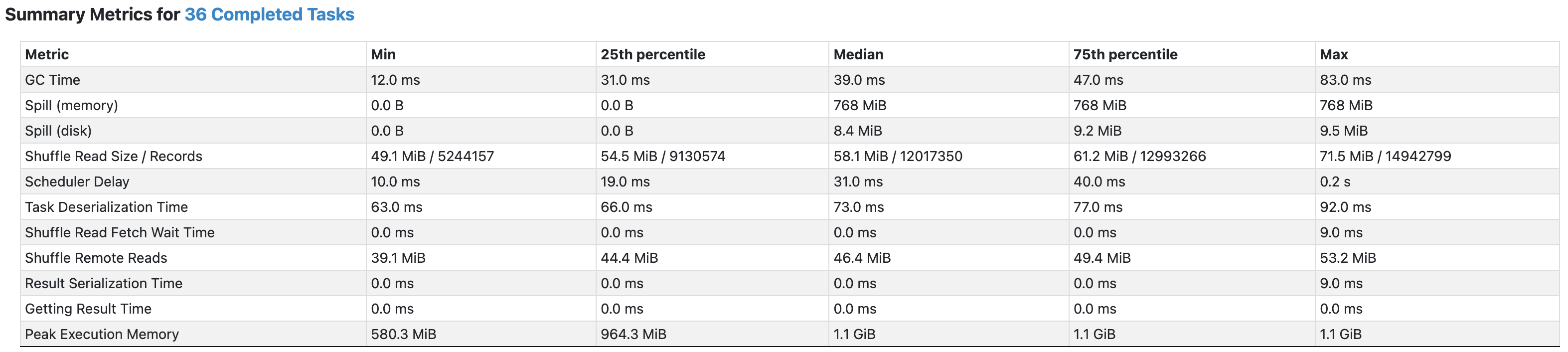
- 각 파티션의 shuffle read size가 이전의 salt size = 10인 경우보다 반절가량 작아진 것을 볼 수 있다.
- 또한, 불필요한 user id에도 salt key를 여러개주었던 이전과 달리, 필요한 행만 salt key를 여러개 할당하여 skew도 조금 더 해결된 모습이다.
AGGREGATION_SIZE = 100
하지만, 아직까지도 data skew가 완전히 해결되지 않았다.
워낙에 skew된 정도가 크기 때문인데, 30명의 유저는 각 1060만행을 갖고, 나머지 유저는 약 50건의 행들을 갖기 때문이다.
이러한 격차를 줄이기 위해 이번에는 30명의 유저가 각 salt key당 100개의 행을 갖도록 그 정도를 줄여보자
이 정도로 줄이더라도 30명의 유저는 user info 테이블에서 각각 약 10.6만행이 추가된 형태로
user info 테이블은 약 318만행이 추가된 정도의 크기를 가질 것이다.
이는, 이전에서 salt size = 10일 때 증가한 크기인 기존의 10배보다 훨씬 작은 크기이다.
결과를 한번 보자.

- 각 파티션당 약 105MB이 셔플이 일어났고, 드디어 spill이 일어나지 않은 모습을 볼 수 있다
Salt key 심화 결론
모든 행에 지정한 갯수의 salt key들을 부여하지 않고, skew가 일어난 특정 행에만 salt key를 부여함으로써 디멘션 테이블인 user info 테이블의 증가량을 대폭 줄였고, 덕분에 salt size를 더 크게 주어 Salting의 효과를 극대화할 수 있었다.
이를 통해 극단적으로 편향된 데이터들의 조인을 data skew 현상 없이 수행할 수 있었다.
5. 쿼리 최적화
이번 예시의 경우 사실, 쿼리를 최적화하는 게 더 큰 효과를 발휘할 수 있다.
기존에는 처음부터 4억건의 행과 4백만개 이상의 행을 조인하였지만, 4억건의 행을 갖는
airline click log 테이블을 먼저 user id로 집계한 후, user info와 조인하여 집계하는 형태로 한다면
조인시 셔플링되는 데이터의 수가 대폭 감소할 것이며, 따라서 spill과 data skew또한 해결이 될 것이다.
처음 집계시에는 4억건의 행을 집계하기는 하겠지만, 집계 연산은 조인연산보다 훨씬 비용이 적다.
최적화된 쿼리는 다음과 같다.
SELECT
u.age - MOD(u.age, 10) AS age_group, SUM(click_count)
FROM user_info u
JOIN (
SELECT user_id, COUNT(user_id) as click_count
FROM airline_click_log
WHERE user_id IS NOT NULL
GROUP BY user_id
) ucc
ON u.user_id = ucc.user_id
GROUP BY age_group;이제 실험결과를 보자

- 집계 후에 조인을 함으로써 읽어지는 행의 수가 대폭 줄었다.
집계된 airline click log (약 3백만개, 4억건 대비 90% 이상 감소) JOIN user info (약 4백만개) - 따라서, 셔플링 되는 행의 수도 대폭 감소하였고, 당연히 spil도 해결된 모습이다.
- 또한, user id로 집계를 먼저 수행하였으므로 user id로 조인시 data skew 또한 발생하지 않았다.
쿼리 최적화 결론
조인과 같은 다량의 셔플링을 발생시키는 연산의 경우, 가장 우선으로 고려해야할 방안은 바로
연산에 참여하는 행의 갯수를 최대한 줄이는 것이다.
이처럼 참여하는 행의 갯수를 대폭 줄임으로써 셔플링되는 행의 갯수도 대폭 감소하고 이에 따른 spill 감소는 물론, data skew의 정도도 줄일 수 있다.
6. 결론
이번 게시글을 통해서 편향된 데이터를 조인시 발생하는 data skew 현상과 이에따른 성능저하에 대해 살펴보고, 이를 해결할 기법 중 하나인 Salting에 대해 알아보았다.
salt key라는 조인에 참여하는 행을 더 추가함으로써, 편향되는 데이터를 균일하게 퍼뜨리도록 하여
data skew 현상을 완화하였다.
또한, 모든 컬럼 값에 대해 여러개의 salt key를 부여하지 않고, skew가 있는 컬럼 값에 대해서만
적절한 갯수의 salt key를 부여함으로써 Salting의 효과를 극대화하여 매우 극단적으로 편향된 데이터의 조인 연산을 data skew 없이 수행하는 것을 확인할 수 있었다.
하지만, 그보다도 더 좋은 방법은 가능하다면 조인에 참여하는 행의 갯수를 최대한 줄이는 것이었다.
조인 전, 조인에 참여하는 키를 기준으로 팩트 테이블을 집계하여 조인에 참여하는 행의 수를 90%이상 감소시켰고, 이는 곧 성능의 극적인 향상으로 이어졌다.
이처럼, 대용량 데이터를 처리할 때에는 항상 연산에 참여하는 행의 수를 최대한으로 줄일 수 있는 쿼리 최적화를 수행하고, 그 후에도 문제가 생긴다면 Salting과 같은 기법을 사용한다면 더 극적인 효과를 얻을 것이다.
References
https://jason-heo.github.io/bigdata/2021/03/01/skewed-data-groupby-join.html
https://gyuhoonk.github.io/spark-salting
https://mesh.dev/20220130-dev-notes-008-salting-method-and-examples/
