데브코스 최종 프로젝트 회고 첫번째.
데이터 파이프라인 작성에 대한 고민들을 담은 게시글이다.
이 게시물에서는 프로젝트 주제와 구성원, 내 역할을 소개하고, 다음의 내용들을 회고한다.
- 계층형 데이터레이크 구조 도입
- 데이터 파이프라인 구조에 대한 고민
- 파이프라인 태스크에 대한 고민
1. 주제
Hello Korea: 외국인 대상 종합 여행 정보 플랫폼
- 웹을 통해 외국인에게 항공권, 관광, 숙박, 행사 정보를 제공하는 서비스
- 추가적인 BI구성을 통해 데이터로부터 유의미한 정보를 제공하고자 함.
2. 인원 및 역할
- 총 5명
- 인프라 구성 전담 1명
- 웹 및 dbt 도입을 통한 데이터 테스트 자동화 1명
- 데이터 ETL 3명
- 항공권 파이프라인, 데이터 웨어하우스 구성, 대용량 데이터 생성 및 처리
- 관광, 행사 정보 파이프라인, 데이터 웨어하우스 구성, 대용량 데이터 생성 및 처리
- 숙박, 날씨 정보 파이프라인, BI 구성, dbt 도입을 통한 데이터 테스트 자동화
내 상세 역할
- 관광 데이터 파이프라인 작성
- 서울의 관광 정보를 API 호출을 통해 수집 및 처리 후 적재
- 행사 데이터 파이프라인 작성
- 공연 정보를 API 호출을 통해 수집 및 처리 후 적재
- 행사 정보를 API 호출을 통해 수집 및 처리 후 적재
- 공연/행사 시설 정보를 API 호출을 통해 수집 및 처리 후 적재
- 데이터 웨어하우스 구성
- 스타스키마 도입
- 데이터 클러스터링
- 자주 호출되는 서브쿼리는 별도의 테이블로 저장
- 임의의 대용량 데이터 생성
- 웹 사용자들의 이용 정보를 랜덤하게 생성
- Data skew를 발생시켜 실 데이터와 유사하게 구성하고자함
- 4백만행의 차원 테이블부터 4억행의 팩트 테이블 생성
- AWS Glue Spark를 이용하여 생성시간을 70분에서 10분으로 단축
- 웹 사용자들의 이용 정보를 랜덤하게 생성
- 대용량 데이터 처리
- AWS Glue spark를 이용하여 대용량 데이터 병렬 연산
- Data skew로 발생하는 spill 해결
3. 프로젝트 세부 회고
3.1. 계층형 데이터레이크 구조 도입
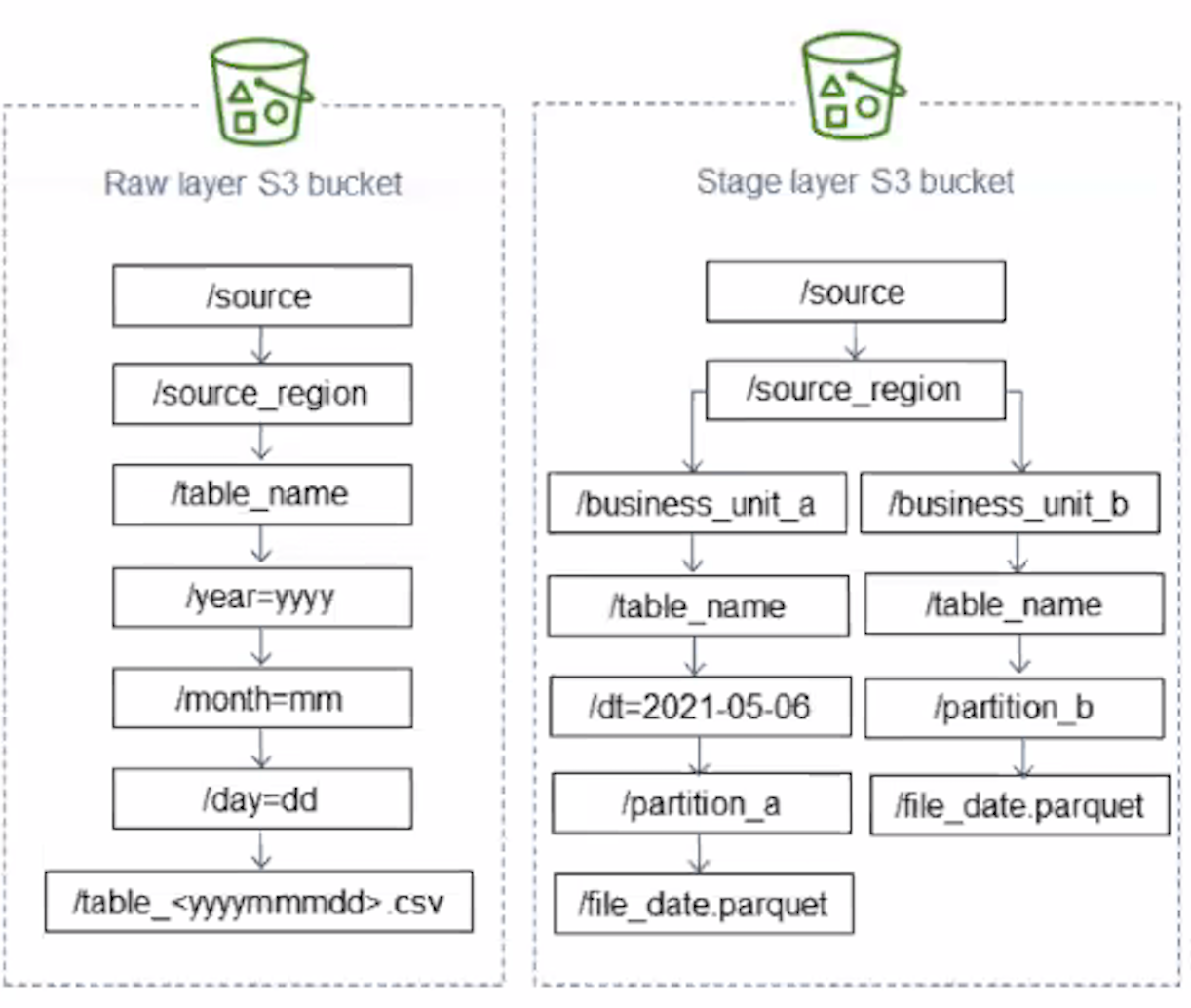
[프로젝트 데이터레이크 구조 예시]
- 계층형 데이터레이크를 도입하여 데이터 관리를 용이하게하고자 함.
- 수집한 데이터의 원본을 저장하는 Raw 계층
- 데이터 웨어하우스에 적재하기 위해 처리한 파일을 저장하는 Stage 계층
- PK에 대한 고유성 보장, 데이터 타입 지정, parquet 파일로 변환 등
- 데이터를 출처별로 Repository를 나누어 적재함
- 데이터를 수집일로 Repository를 세부적으로 나누어 적재함
- 이는 파이프라인 작성시 backfill도 용이했음
- logical date에 맞게 데이터레이크 경로만 찾아가면 되므로
- 이는 파이프라인 작성시 backfill도 용이했음
3.2. 데이터 파이프라인 구조에 대한 고민
- 데이터레이크의 계층별로 데이터를 적재하고, 데이터 웨어하우스에 데이터를 적재하고,
웹서버에 보여주기 위한 데이터를 OLTP 데이터베이스(RDS)에 적재하는 태스크들이 필요했음- 이를 위해 데이터 파이프라인의 구성을 어떻게 해야할지에 대해 고민함
3.2.1. 고민 첫번째: 계층별로 데이터 파이프라인을 구성
- “단일 책임 원칙”을 따르고자 했었음 → 데이터 파이프라인을 계층별로 나누자!
- 예를 들어, 관광 데이터 파이프라인을 다음과 같이 작성했었음
- API를 호출하여 데이터레이크의 Raw 계층에 데이터를 적재하는 파이프라인
- Raw 계층의 데이터를 처리하여 데이터레이크의 Stage 계층에 데이터를 적재 및 데이터 웨어하우스로 COPY하는 파이프라인
- Stage 계층의 데이터를 처리하고 이를 프로덕션 데이터베이스인 RDS에 적재하는 파이프라인
- 하지만, 이렇게 작성하니 여러 문제가 있었음
- 파이프라인 수가 많아지니 오히려 관리가 더 복잡
- 데이터 출처가 관광뿐만 아니라, 행사, 공연, 시설 정보까지 있으므로, 이러한 방식으로 파이프라인을 구성할 경우 수십개의 파이프라인을 관리해야함
- 파이프라인이 이렇게까지 나올 정도로 큰 프로젝트인가? 아님
- 데이터 출처가 관광뿐만 아니라, 행사, 공연, 시설 정보까지 있으므로, 이러한 방식으로 파이프라인을 구성할 경우 수십개의 파이프라인을 관리해야함
- 또한, 계층형 구조를 따라가며 데이터를 적재하는 흐름상 파이프라인 사이의 의존성을 지정하고 관리해주는게 여간 쉬운일이 아니었음
- 파이프라인이 수십개면, 의존성도 수십개..
- 파이프라인간 의존성은 그들간의 스케줄도 일치화 시키고, 일일히 다 잘 작동되는지 확인하고.. 끔찍
- 쓸데 없이 많은 의존성은 데이터 리니지 관리에도 큰 어려움을 줄 것이라고 생각
- 파이프라인 수가 많아지니 오히려 관리가 더 복잡
→ 따라서 이러한 소요들은 불필요하다고 느껴졌고, 다른 구조를 도입하기로 결정함
3.2.2. 고민 두번째: 수집 출처별로 데이터 파이프라인을 구성
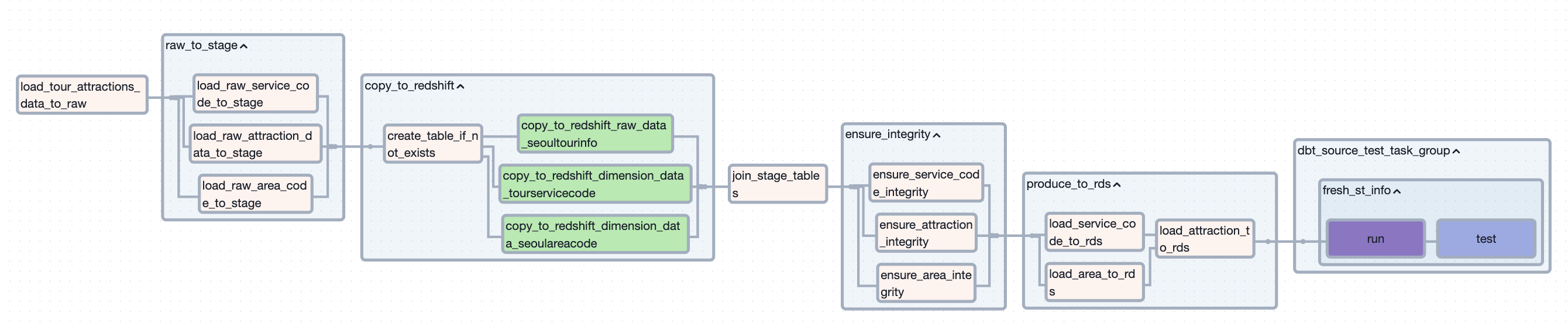
[관광api 출처 파이프라인 구성]
-
계층별로 쪼개놓은 파이프라인을 하나로 합쳐서 수집 출처별로 하나의 데이터 파이프라인을 구성하고자 함
-
대신, 각 계층에 대한 책임을 갖는 태스크들은 그룹핑하여 관리할 수 있도록 함
-
파이프라인간 의존성 문제는 해결할 수 있었음
- 파이프라인 내의 태스크간 의존성 부여는 굉장히 간단함
-
단점으로는 파이프라인 코드가 길어진다는 점이 존재했었음
-
그래도, 단점보다는 장점이 더 크다고 느껴졌기에 이 구조를 채택하여 파이프라인을 구성함
-
그런데도 다른 문제를 식별함
- api 호출 후의 데이터 적재, 처리 태스크들이 실패하여 파이프라인이 실패할 경우
api 호출부터 다시 시작해야했음.- 이는 api 호출 횟수에 제한이 있어 치명적인 문제가 될 수 있음
- 또한, api 호출 태스크는 수행시간이 다른 태스크보다 길어, 파이프라인 재수행 시간이 더 길어질 수 있음
- api 호출 후의 데이터 적재, 처리 태스크들이 실패하여 파이프라인이 실패할 경우
→ 따라서, 이 구조에 api를 호출하는 태스크만 다른 파이프라인으로 분리하기로 결정함
3.2.3 마지막 고민: 수집 출처별로 파이프라인 구성 및 api 호출 파이프라인 분리

[api 호출 파이프라인]
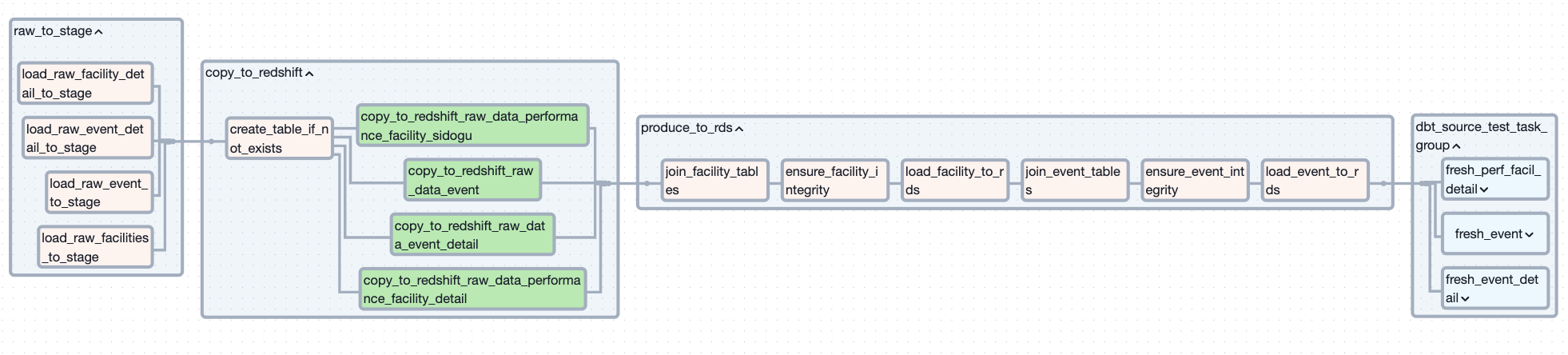
[stage 계층부터의 파이프라인]

[위 두 파이프라인의 의존성]
- api 호출하는 태스크들을 별도의 파이프라인으로 분리함
- 이로써, 호출 후의 태스크가 실패하여 파이프라인이 실패하더라도 api를 다시 호출할 필요가 없어짐
- 또한, 파이프라인 재실행으로 인한 불필요한 api 호출을 막을 수 있음
- 파이프라인간 의존성이 생기지만, 한 개의 의존성만 생기므로 의존성 부여 및 관리도 수월했음
3.2.4. 프로젝트 종료 후 개선안: 데이터 테이블을 기준으로 태스크 그룹핑
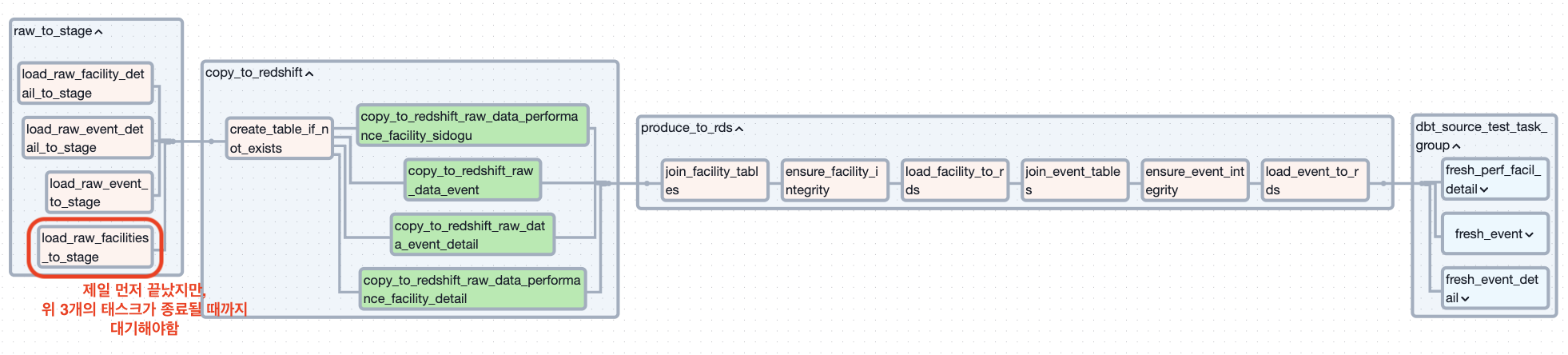
[태스크 병목 예시]
- 프로젝트 마지막에는 태스크들을 계층을 기준으로 그룹핑 했었는데, 이 경우에도 약간의 문제가 눈에 보였음
- 서로의 참조 관계가 아직 강제되지 않는 테이블인데도, 계층별로 태스크가 묶여있으니 다른 테이블에 대한 태스크가 종료가 될 때까지 기다려야하는 문제
- 이는 특정 테이블에 대한 작업이 지나치게 길 경우 병목이 생길 수 있음
- 예를들어, 행사 시설에 해당하는 테이블은 행사 정보 테이블과 무관하게 Redshift까지 적재됨
- 하지만, 행사 시설 테이블은 동일한 그룹내에 있는 오래 걸리는 태스크인 행사 정보 테이블이 종료될 때까지 기다린 후 다음 계층에 대한 태스크를 수행해야함
- 따라서, 개선사항으로 각 테이블의 참조 관계가 강제되는 단계전까지는(여기의 경우 RDS에 해당하는 단계의 전까지) 다루는 테이블 별로 태스크를 그룹핑하는게 태스크 수행시간면에서 더 나아보임
3.3. 파이프라인 태스크에 대한 고민
3.3.1. 태스크를 나누는 기준
-
태스크의 경우 최대한 “단일 책임의 원칙”을 따르도록 작성하고자 함.
- 수집 데이터 원본을 데이터레이크(S3) Raw 계층에 적재(Raw에 대한 책임)
- Raw 계층의 데이터를 변환하여 Stage 계층에 적재(Stage에 대한 책임)
- Stage 계층의 데이터를 데이터웨어하우스로 COPY(데이터웨어하우스에 대한 책임)
- 데이터 무결성 보장을 위한 처리(데이터 무결성 보장에 대한 책임)
- 무결성이 보장된 데이터를 RDS에 데이터 적재(RDS 적재에 대한 책임)
-
데이터를 직접 처리하고 변환하는 부분은 태스크가 아닌 별도의 함수로 작성함
- 데이터를 변환하고 처리하는 부분은 다른 작업들에 비해 그 과정의 수가 많고 복잡함
- 이 모든 과정들을 태스크에 표시한다면 태스크가 쓸데 없이 길어지고 관리가 힘들어질 것이라고 판단
- 다만, 몇몇 처리 과정은 태스크로 명시하였음
- 두 테이블을 조인하는 경우
- 테이블이 조인되어 새로운 테이블을 만드는 작업의 경우 명시가 되어야 한다고 판단했음
- RDS에 데이터를 싣기 전 데이터의 무결성을 보장하는 경우
- 프로덕션쪽인 OLTP에 들어가는 데이터의 무결성 보장은 매우 중요한 부분이기때문에
Airflow UI 상에서도 명시가 되어야 한다고 생각했기 때문 - 이 역시도 데이터를 처리하는 작업은 처리 함수를 호출하여 수행함
- 프로덕션쪽인 OLTP에 들어가는 데이터의 무결성 보장은 매우 중요한 부분이기때문에
- 두 테이블을 조인하는 경우
3.3.2. 태스크간 데이터 공유 시행착오: xcom
- 수집한 원본 데이터를 Raw에 적재하고, 이를 다시 변환하여 Stage에 적재하고…
이러한 과정에서 태스크간에 데이터를 주고받는 일이 필요했음 - 따라서, 처음에는 xcom을 사용하여 태스크끼리 데이터프레임을 주고 받도록 하였음
- 하지만, 다음과 같은 문제가 있었음
- Airflow 공식 문서에서는 xcom은 데이터프레임을 주고받는데 적절하지 않다고 설명함
- xcom은 데이터를 airflow의 메타DB에 저장하며, 데이터프레임처럼 크기가 큰 데이터를 이용할 경우 부하가 생길 수 있음
- 또한, 메타DB의 작은 크기는 크기가 큰 데이터 타입에 제한이 생길 수 있음
- xcom을 통해서 데이터를 주고받는 과정에서 데이터의 직렬화와 역직렬화 과정이 발생함
- 데이터프레임이 json으로 직렬화하는 과정에서 데이터 자료형이 바뀜
- 예를들어, timestamp without timezone같은 시간자료형이 epochtime, timestamp with timezone 중으로 변환됨
- 이러한 점은 정확한 데이터 처리에 문제를 발생시킬 수 있음
- 데이터프레임이 json으로 직렬화하는 과정에서 데이터 자료형이 바뀜
- Airflow 공식 문서에서는 xcom은 데이터프레임을 주고받는데 적절하지 않다고 설명함
→ 따라서, 데이터 공유를 이전 태스크가 저장한 데이터레이크(S3)의 경로를 xcom으로 주고받도록 변경함
3.3.3. 태스크간 데이터 공유 최종방안: 데이터 경로만 xcom으로 넘겨주기
- 직렬화 과정에서 데이터의 스키마가 변형되는 것을 막기 위해 태스크의 작업이 끝나면 ,
작업한 데이터를 데이터레이크인 S3에 저장하고, 저장한 경로만 xcom을 통해 공유하는 방식으로 변경함 - 예를 들면 다음과 같음
- api를 호출하여 받은 데이터프레임을 S3의 Raw 버킷에 csv파일로 저장
- 데이터를 저장한 경로인 s3 key는 xcom에 저장됨
def load_tour_attractions_data_to_raw(**kwargs): ... raw_bucket = Variable.get('S3_RAW_BUCKET') # 데이터가 저장될 경로 s3_key = get_s3_path(kwargs['execution_date'], API_SOURCE, API_CALLED, FILE_PREFIX, 'csv') # Upload to S3 s3 = S3Hook(aws_conn_id='s3_conn') upload_string_to_s3(s3, s3_key, csv_data, raw_bucket) return s3_key # 태스크의 return 값은 xcom에 저장됨 - 다음 태스크는 Raw 버킷에 있는 데이터를 가져오기 위해 xcom_pull()을 통해
해당 데이터의 경로를 가진 s3 key를 가져옴def load_raw_attraction_data_to_stage(**kwargs): ti = kwargs['ti'] raw_bucket = Variable.get('S3_RAW_BUCKET') # get target key path s3_key = ti.xcom_pull(task_ids='load_tour_attractions_data_to_raw') # read csv file decoded to string s3 = S3Hook('s3_conn') csv_string = s3.read_key( key=s3_key, bucket_name=raw_bucket ) # convert csv-string to dataframe df = pd.read_csv(io.BytesIO(csv_string.encode('utf-8'))) # 이제 받아온 데이터를 가지고 원하는 작업을 수행
- 이렇게 하니 데이터의 스키마가 변형될 염려도 없었고, 행여나 발생할 Airflow 메타DB에 대한 부하도 예방할 수 있었음
3.3.4. 태스크 순서에 대한 시행착오
- RDS에 데이터를 적재하는 태스크들을 배치하는 과정에서 문제가 발생함
- “행사 정보” 테이블은 “행사 시설" 테이블을 참조함
- 즉, “행사 시설”의 PK를 “행사 정보”가 FK로 참조하는 관계
- 처음에는 RDS에 테이블을 적재하는 태스크들을 병렬적으로 배치
- 위의 참조 관계로 인해 “행사 정보” 테이블을 먼저 업데이트하는 경우
새로운 행사 시설에서 열리는 행사 정보가 레코드에 있으면,
”행사 시설” 테이블에는 새로운 행사 시설에 대한 행이 없으므로 RDS에서 오류를 발생시킴
- 위의 참조 관계로 인해 “행사 정보” 테이블을 먼저 업데이트하는 경우
- “행사 정보” 테이블은 “행사 시설" 테이블을 참조함
→ 따라서, 테이블들의 참조 관계를 바탕으로 태스크간의 순서를 직렬로 재배치함
3.3.5. 작성 파이프라인 코드
- 공연/행사 관련 데이터 파이프라인
- 관광 데이터 파이프라인
교육을 수료하고, 이래저래 보완할 부분들도 찾아보고, 하반기 채용 원서접수 시기가 겹쳐 수료하고 한 달이 지난 지금에서야 올리기 시작한다.
다음편에는 대용량 데이터 처리를 경험하고 싶어 생성한 최대 4억행의 웹 사용 기록 랜덤 데이터 생성과 이들을 AWS Glue spark로 처리하면서 겪은 시행착오와 Redshift 구성에 대한 회고를 게시할 예정
