데브코스 최종 프로젝트 두번째 이자 마지막.
아무래도 데이터를 직접 다루는 부분이다보니, 한 게시글로 작성하게되어 두 편만에 회고가 끝났다.
시리즈 내 저번 게시물로부터 이어지며, 이번 게시물은 다음의 내용을 포함
- 대용량 데이터를 생성하면서 겪은 시행착오
- 대용량 데이터를 처리하며 개선한 방안들
- Redshift 쿼리최적화 방안들
3.4. 대용량 데이터 생성기
3.4.1. 생성 배경
- 대용량 데이터를 직접 처리해보면서 데이터 엔지니어가 현업에서 직면하는 문제들을 겪어보고 싶었음
- 최종 프로젝트간 교육기관에서 AWS Glue를 지원했음
- 이를 통해 클라우드 환경에서 spark가 사용이 가능했는데, 막상 활용할 곳이 없었음
- 따라서, 최대 억단위의 행을 갖는 테이블을 만들고, 이들에 대한 연산들을 수행해보자! 라는 생각으로 대용량 데이터를 생성하기로 함
3.4.2. 첫번째 시도: 로컬에서 Pandas를 이용하여 생성
- 처음에는 로컬 PC에서 Pandas와 랜덤 모듈인 Faker를 이용하여 수백만 행 이상의 디멘션 테이블부터 생성하고자함
- 하지만, 1000만 행 x 8개 컬럼을 갖는 유저 정보 테이블을 생성하고, 데이터레이크에 적재하는데만 70분 이상의 소요시간이 걸림
- 또한, 데이터 생성간 사용되는 메모리의 부족은 중간에 프로세스가 중단되는 문제를 일으키도 함
→ 따라서 데이터 생성에 AWS Glue의 Spark를 이용해서 병렬 연산하면 개선되지 않을까? 하는 생각이 들어 AWS Glue 도입을 결정함
3.4.3. 두번째 시도: AWS Glue에서 Spark 데이터프레임을 이용하여 생성
- Spark의 병렬 연산을 이용하여 테이블들을 생성하고자 하였음.
- 이를 도입함으로써 70분 이상의 유저정보 테이블 생성시간이 11분정도로 단축되었음.
- 또한, 로컬에서는 다른 작업을 하면 되니 작업의 효율성도 증대됨
- 하지만, 여러 문제들이 발생함
- pickle 에러: 디멘션 테이블의 임의의 행을 각 파티션에서 샘플링하여 그 행을 기반으로 팩트 테이블을 생성하려니 발생한 에러
- 이는 워커노드에서 샘플링 함수 호출시 드라이버 노드의 SparkContext 객체를 참조하게 되고, Spark는 SparkContext를 직렬화하여 워커노드로 전송하고자함.
하지만, SparkContext는 직렬화할 수 없는 객체이므로 pickle 에러를 발생시킴 - 디멘션 테이블의 각 파티션을 mapping하는 방식(mapPartition())으로 수정하여 해결했으나, 그럼에도 너무나 긴 시간이 소요가 됐음(40분 이상)
- 이는 워커노드에서 샘플링 함수 호출시 드라이버 노드의 SparkContext 객체를 참조하게 되고, Spark는 SparkContext를 직렬화하여 워커노드로 전송하고자함.
- 또한, 랜덤 모듈이 항상 고유한 값을 생성하는 것은 아니었음.
즉, 디멘션 테이블에서 중복 행이 발생
- pickle 에러: 디멘션 테이블의 임의의 행을 각 파티션에서 샘플링하여 그 행을 기반으로 팩트 테이블을 생성하려니 발생한 에러
→ 따라서, 팩트 테이블을 먼저 랜덤 모듈로 생성하고, 팩트 테이블을 distinct하는 방식으로 디멘션 테이블을 구성키로 함
3.4.4. 최종 데이터 생성안: 팩트 테이블 생성 후, 디멘션 테이블 생성
- 기존 디멘션 테이블의 각 파티션을 mapPartition()을 통해 행을 변형하는 방식으로 팩트 테이블을 생성하는 과정에서 많은 수행시간이 발생함
- 따라서, 팩트 테이블을 랜덤모듈로 먼저 생성하기로 함
- 40분 이상의 소요시간을 10~20분 내외로 단축
- 랜덤 값에 skew를 주어 실 데이터와 유사하게 구성하고자 함
- 디멘션 테이블을 팩트 테이블의 user_id와 같은 행을 distinct 시켜 생성함
- 기존의 데이터 중복 문제를 해결
→ 최대 4억행의 팩트 테이블을 먼저 생성하고, 이로부터 약 4백만 행의 디멘션 테이블들을 생성
3.4.5. 프로젝트 종료 후 개선사항: output partition 조정
- 프로젝트 수행간에는 생성 및 처리 후 별도의 output partition을 조정하지 않았음
- 이미 출력되는 파티션별 크기가 100MB 정도여서 필요성을 크게 못 느꼈음
- repartition() 혹은 coalesce()를 사용시 전체 연산시간이 더 소요되었기 때문에, 추가적인 셔플링 혹은 파티션 감소는 필요없다고 판단
- 하지만, output 파티션을 조정하는데 다른 이유도 있다는 것을 깨달음
- 데이터의 특성을 안다면, 특정 컬럼을 기준으로 repartition시 데이터 압축 효율이 증가하여 전체 데이터 크기가 감소함
- 이는 스토리지의 공간과 비용면에서 이점이 있으며, 이후에 있을 연산에도 크기가 줄어 이점이 생길 수 있음
→ 특정 컬럼을 기준으로 ouput partition을 조정함으로써 테이블 데이터의 크기를 최대 90%까지 감소 시킬 수 있었음
3.5. 대용량 데이터 처리
- 이제 데이터를 생성했으니, 생성한 데이터들을 통해 집계, 조인 연산을 통해 분석 테이블을 만들고자 하였음
- 데이터에 skew를 주어 생성하여 이러한 연산시 특정 파티션에 데이터가 몰리게되고, 이는 파티션을 처리하는 워커 노드의 메모리를 넘어서 spill이라는 현상을 야기함
- spill: 메모리 용량 초과시 Spark는 초과된 데이터를 임시적으로 직렬화하여 디스크에 저장함
- 이러한 과정에서 발생하는 직렬화/역직렬화 과정과 디스크 입출력은 전체 연산시간 지연의 큰 원인이 됨
- spill: 메모리 용량 초과시 Spark는 초과된 데이터를 임시적으로 직렬화하여 디스크에 저장함
- 이러한 spill을 해결하기 위해 다양한 방법으로 실험하고, 개선함
3.5.1. 첫번째 개선사항: 입력 파티션 조정

[input partition 조정 전 셔플된 행 수]
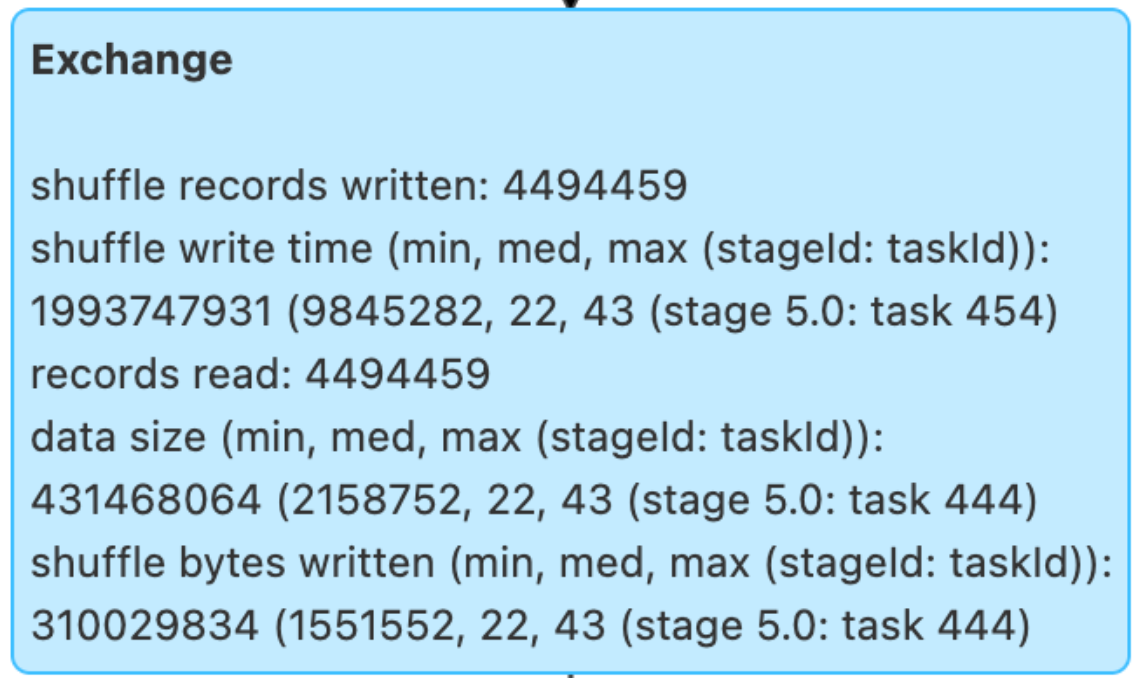
[input partition 조정 후 셔플된 행 수]
- 조인 연산에 사용될 컬럼을 기준으로 입력에 들어갈 파일의 파티션들을 나눔
- 이를 통해 연산시 2천 5백만행의 셔플링 발생을 450만행의 셔플링으로 줄였고, 쿼리 연산시간을 16% 감소시킴
3.5.2. 두번째 개선사항: 셔플 파티션 조정
- spill을 해결하기 위해 셔플 파티션 수를 증가시켜 파티션에 들어가게되는 데이터의 크기를 감소시킴
- AWS Glue에서 10 DPU 설정시 기본 셔플 파티션의 갯수는 36개
 [36 shuffle partition, 특정 파티션에서 spill이 일어난 모습]
[36 shuffle partition, 특정 파티션에서 spill이 일어난 모습]
- 최적의 성능을 낼것으로 생각하는 셔플 파티션의 수는 72개 이상
- 10 DPU = 10 executors → 1 driver node, 9 worker nodes
-
1 worker당 4vCPU, 16GB 메모리
- 워커 하나당 최대 8개의 태스크 감당 가능
→ 9 worker x 8 task = 72 tasks, 한 번에 72개의 태스크 연산이 가능함
-
- 10 DPU = 10 executors → 1 driver node, 9 worker nodes
- 따라서, 셔플 파티션의 수를 36에서 72로 조정
 [72 shuffle partition, spill이 없는 모습]
[72 shuffle partition, spill이 없는 모습]
→ 조인연산에 해당하는 stage의 시간이 42.98초에서 18.72초로 감소

[36 shuffle partition stages]

[72 shuffle partition stages]
3.5.3. 최종 개선사항: 쿼리 최적화
- 조인에 참여하는 행의 갯수를 최대한 줄이는 방향으로 쿼리를 작성하여 개선
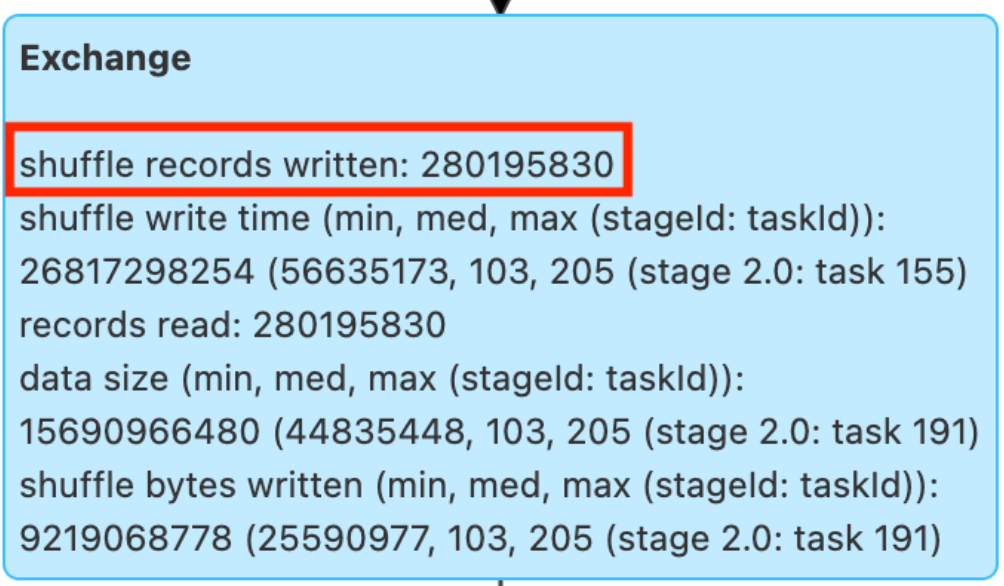
[최적화 전 셔플링 레코드 수]

[최적화 후 셔플링 레코드 수]
- 조인에 참여하는 컬럼을 기준으로 미리 집계하여 조인에 참여하는 행의 갯수를 2억 8천만에서 2천 5백만 행으로 감소
→ 쿼리 수행 시간을 40% 감소시킴
3.5.4. 프로젝트 종료 후 개선안 제안: Salt key 도입
- Salting은 음식에 소금을 쳐 맛의 균형을 맞추듯, 데이터에 salt key라는 소금을 뿌려 데이터의 균형을 맞추는 기법
- 이러한 기법을 통해 skew를 완화하여 spill을 예방할 수 있음
- 하지만, 수많은 레코드에 컬럼을 추가하는 등의 추가 연산이 발생하므로 안하는 것이 오히려 더 빠른 경우들도 있으니 사용에 주의가 필요함
- 프로젝트 상에서는 해당 기법은 불필요하나, 개인적인 학습을 목표로 진행함
- 세부 내용은 아래 게시글 통해 확인
Salting 게시글
3.6. 데이터웨어하우스 구성
- API를 통해 수집한 데이터와 임의로 생성한 웹 사용 정보 대용량 데이터를 적재
- API를 통해 수집한 데이터는 차원 테이블의 성격을 가짐
- 대용량 데이터는 차원 테이블과 팩트 테이블들로 구성
- Redshift 단일노드 환경으로 구성(교육기관에서 지원)
3.6.1. 다차원 데이터 모델링

- 대용량 데이터를 팩트 테이블과 그들과의 관계를 맺는 차원 테이블로 구성함
- 이는 반정규화된 형태로 셔플링을 발생시키는 조인 연산을 감소시킴
- 차원 테이블을 정규화하지 않은 스타 스키마 형태를 채택함
3.6.2. 정렬키 지정(클러스터링)
-
단일 노드 환경으로 인해 분산키 지정은 제한되었음
-
다만, 적절한 정렬키 지정을 통해 쿼리 성능 향상을 이뤄낼 수 있었음
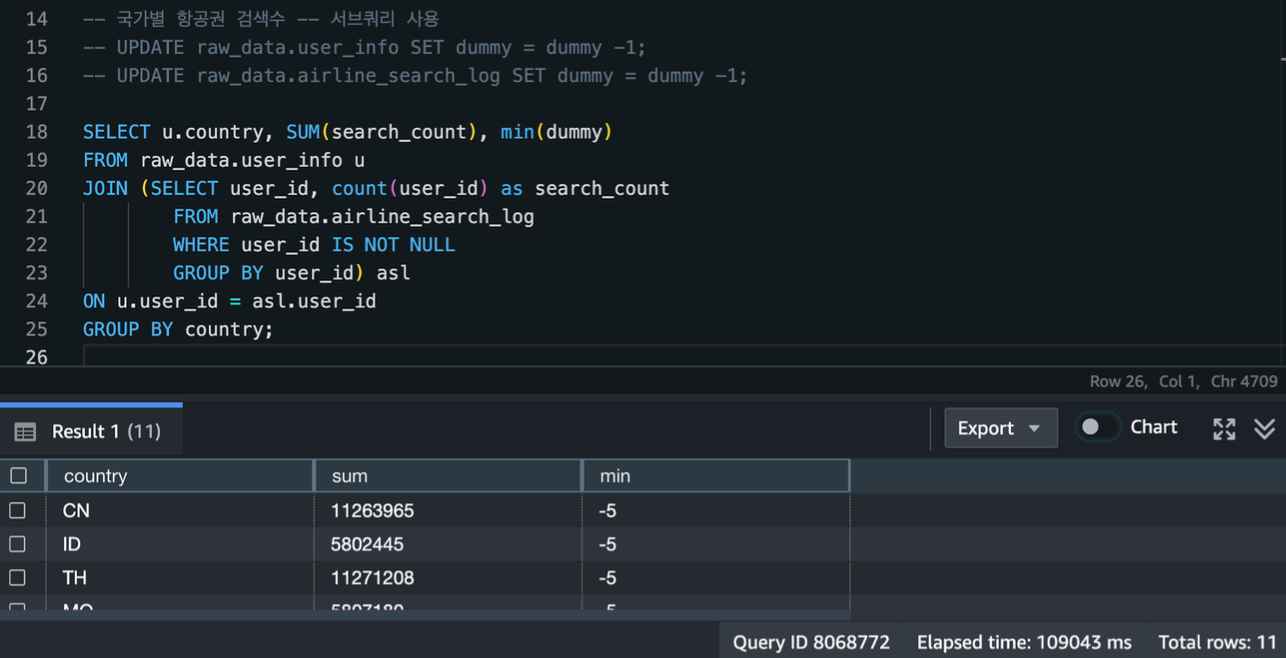
[정렬 키 지정 전 분석 쿼리 수행: 약 109초 소요]
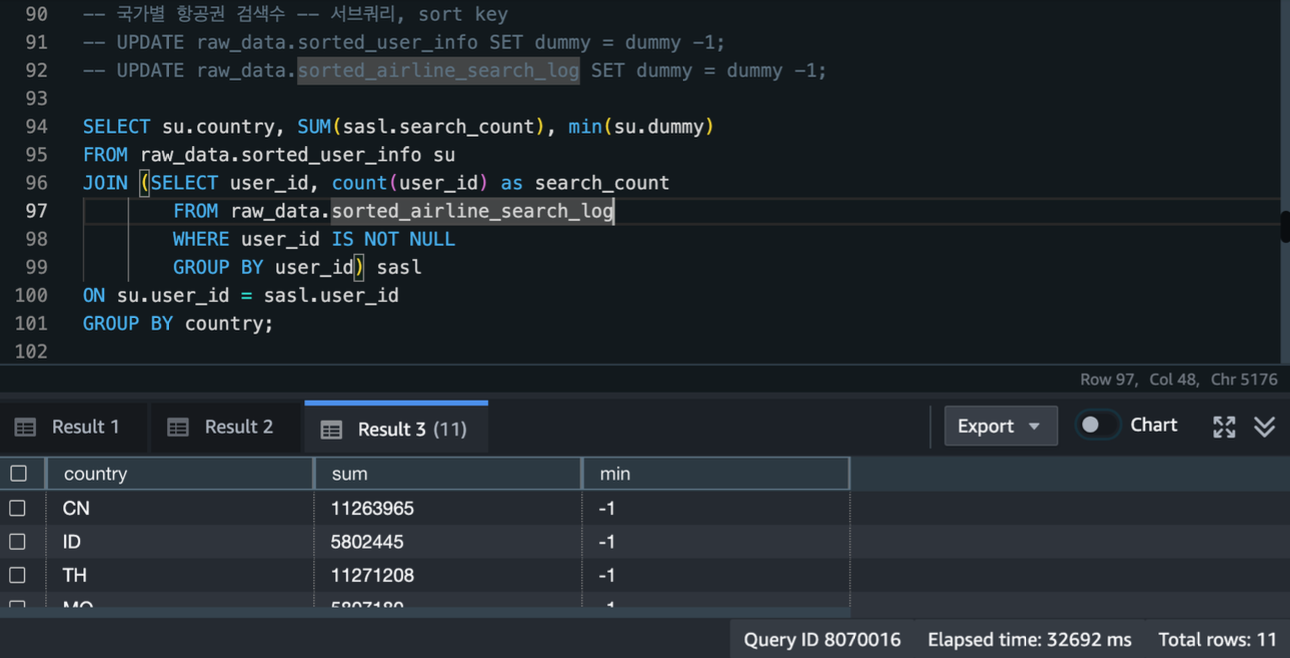
[정렬키 지정 후 분석 쿼리 수행: 약 32초 소요]
- user_id 컬럼을 정렬키로 지정한 sorted_airline_search_log 테이블을 이용하여 쿼리 수행시 정렬키 지정 전보다 수행시간이 약 77초 더 빠른 모습
3.6.3. 성능 측정시 어려웠던 점
-
성능을 테스트할 때 Redshift의 캐싱 기능으로 인해 측정이 어려웠었음
- 캐싱: 특정 쿼리의 결과를 저장해놓고, 나중에 동일 쿼리 수행시 저장한 결과를 보여줌
-
Redshift는 결과 캐싱을 수행하지만, 다음의 조건이 모두 충족될 때만 캐시된 결과를 사용
- 쿼리를 제출하는 사용자가 쿼리에 사용되는 객체에 대한 액세스 권한을 보유합니다.
- 쿼리 내 테이블 또는 보기가 수정되지 않았습니다.
- 쿼리는 실행 시마다 평가되어야 하는 함수(예: GETDATE)를 사용하지 않습니다.
- 이는 실제로 GETDATE 수행시에도 캐싱이 되어서 의미가 없었음
- 쿼리는 Amazon Redshift Spectrum 외부 테이블을 참조하지 않습니다.
- 쿼리 결과에 영향을 미칠 수 있는 구성 파라미터가 변경되지 않았습니다.
- 구문상 쿼리가 캐시된 쿼리와 일치합니다.
→ 의미 없는 dummy 컬럼의 값을 수정한 후, 성능 테스트를 진행
-
추가로 정렬키는 서브쿼리에서는 다음과 같은 제한 사항이 있으므로, 자주 호출하는 서브 쿼리의 경우 테이블로 별도로 저장함
- 서브 쿼리는 일반적으로 메인 쿼리와 독립적으로 실행되기 때문에, 정렬 키의 데이터 프루닝 효과가 충분히 발휘되지 않을 수 있음
프로젝트 회고를 다 마무리하였다.
회고를 하면서 아쉬웠던 점들이 보이는데,
첫번째는 셔플링 연산 최적화시 메모리 크기를 직접 계산하여 조정하는 것보다 단순히 파티션 수를 조정해가며 최적화했다는 점이다.
Spark는 메모리를 할당하고 관리하는 기준이 있는데, 이를 따로 참고하지 않고 파티션의 수를 조정해가며 했던 점이 좀 아쉽다.
메모리 계산하고 최적화했으면 더 좋은 성능이 나오지 않았을까 싶다.
데브코스에서 AWS 자원들을 다 지원 종료했으니, 추가적인 개선을 통한 테스트는 못 해보겠지만,
Spark 메모리 관리에 대해 좀 정리하여 게시할 생각이다.
두번째는 Redshift의 분산키 활용을 못했다는 점이다.
이는 Redshift 인스턴스가 단일 노드였기 때문인데, 사실 이 정도만 해도 우리 프로젝트에는 지장은 없었으니..
그래도 분산키로 데이터 파티션들 나눠보고 성능 비교도 해봤으면 좋았을 걸 하는 아쉬움이 남는다.
이것도 관련해서 Redshift의 분산키와 분산처리 방식에 대해 정리해서 게시할 생각이다.
