metric learning의 학습 방법 중 하나이다.
샴 쌍둥이에서 착안된 네트워크로, 샴 네트워크라고 한다.
두 네트워크의 구조가 서로 닮아있고, 서로의 weight를 공유한다.
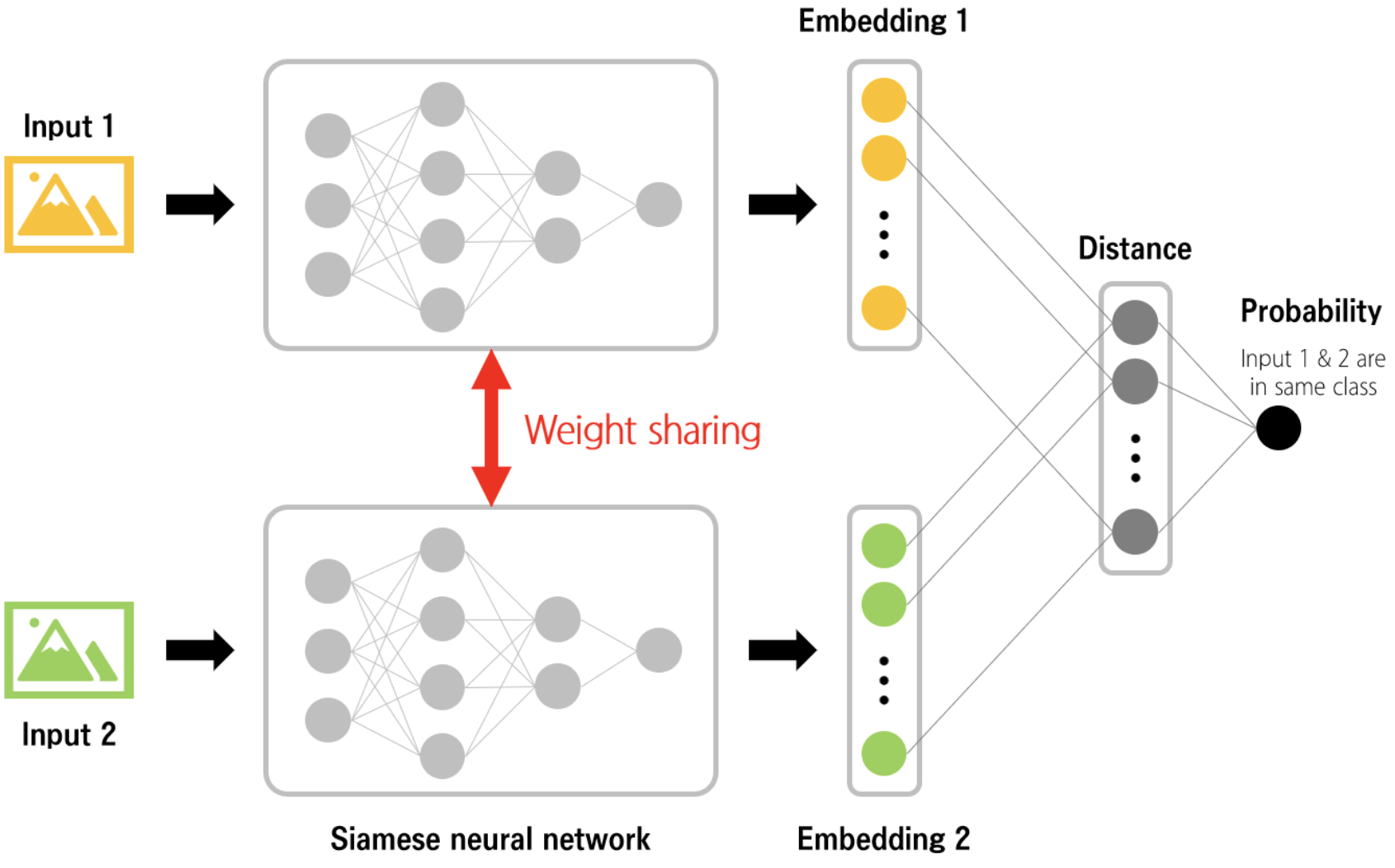
Siamese Network 샴 네트워크 :
| 장점 | 단점 |
|---|---|
| 각 class에 해당하는 데이터 개수가 적을 때에도 학습이 가능함. | 한 task에 쓰였던 model이 다른 task들에 활용되기 어렵다.(not generalizable) |
| 불균형한 데이터로도 학습이 가능함. | input의 변형 데이터에 sensitive함. |
| 데이터의 pair을 input으로 받기 때문에 class 당 data의 pair을 만들다 보면 결국 training data의 개수가 많아짐. |
내가 맞추고 싶은 이미지(현장 이미지)와 이 이미지의 정답 이미지(등록 이미지)의 쌍(2개)이 input으로 들어가고, 서로 비슷한 네트워크(유사/비슷한 parameter, weight)를 통해 각 input images가 embedding(이미지의 벡터화) 된다.
이 embedding된 값들의 차이를 L1(멘하탄)/L2(유클리디언) 등의 거리 측정 norm으로 계산하여 구한 값을 통해 각 image의 유사/비유사도를 알 수 있다.
거리의 차이를 그대로 유사/비유사의 척도로도 쓸 수 있지만, 보통은 0~1 사이로 정규화 한다.
이 때 정규화한 값의 threshold(유사(같은 class)/비유사(다른 class)라고 판단하는 기준 값)는 학습 과정 중, 가장 높은 정확성을 보이는 값으로 선정될 수 있다.
이 값을 통해 서로 유사하면(같은 쌍, positive pair) 값이 0, 서로 유사하지 않으면(다른 쌍, negative pair) margin 즉 거리를 떨어지게(멀어지게) 학습 시키는 함수를 *
Constrative loss function(대조 손실 함수→절대적 거리(margin) 고려)이라고 한다.
그러나 이 margin 값(threshold, 즉 서로 다른 클래스들의 샘플이 최소 어느 정도 떨어져 있어야 하는지의 임계값)을 설정하는데 어려움이 있다.
또한 negative pair 간의 거리가 margin을 약간 넘는 경우와, 크게 넘는 경우에 동일하게 패널티를 부여해 네트워크가 명확히 학습하지 못한다는 단점이 있다.
이를 보완하기 위해 **
Triplet Loss함수(→상대적 거리의 차이를 학습)가 있다.
Anchor(기준이 되는 sample), Positive(anchor과 같은 class로 거리 최소화하도록 학습함.), Negative(anchor와 다른 class로 거리 최대화하도록 학습함.) 3가지 샘플로 학습을 한다.
* Constrative loss function 함수
** Triplet Loss 함수
*d*(*A*,*P*): 앵커와 양성 샘플 간의 거리𝑑(𝐴,𝑁)*d*(*A*,*N*): 앵커와 음성 샘플 간의 거리margin: 양성 샘플과 음성 샘플 간의 최소 거리 차이
(이 값은 모델이 양성과 음성을 구분할 수 있도록 하는 임계값)
