1. Karpenter 개요
1.1 Karpenter란?
Karpenter는 Kubernetes 클러스터에서 자동으로 컴퓨팅 리소스를 프로비저닝하고 관리하는 오픈소스 솔루션입니다.
기존 Cluster Autoscaler(CAS)와 달리, 몇 초 안에 최적의 인스턴스를 프로비저닝하고, 불필요한 노드를 제거하는 등 지능적인 노드 수명 주기 관리 기능을 제공합니다.
- Karpenter 공식 문서 및 참고 자료
1.2 Karpenter의 핵심 특징
- 몇 초 안에 최적의 인스턴스를 자동 프로비저닝
- 불필요한 노드를 자동 종료하여 비용 절감
- AWS Graviton, Spot Instance 등을 활용한 최적의 비용 대비 성능 제공
- Kubernetes 스케줄러와 협력하여 Pod 요구사항을 만족하는 최적의 노드 선택
- Auto Scaling Group(ASG) 없이도 독립적으로 노드 관리 가능
1.3 Karpenter vs. 기존 Cluster Autoscaler (CAS) 비교
| 비교 항목 | Cluster Autoscaler (CAS) | Karpenter |
|---|---|---|
| 노드 생성 속도 | 수 분 소요 | 수 초 이내 |
| 인스턴스 선택 방식 | ASG에 의해 제한 | EC2 전체에서 최적 선택 |
| 불필요한 노드 종료 | 일부만 가능 | 적극적으로 통합(Consolidation) |
| 워크로드 기반 최적화 | ASG 설정 필요 | Provisioner 정책 기반 |
| 온디맨드 vs. 스팟 활용 | 고정된 ASG 내 선택 | 동적으로 최적의 비용 인스턴스 선택 |
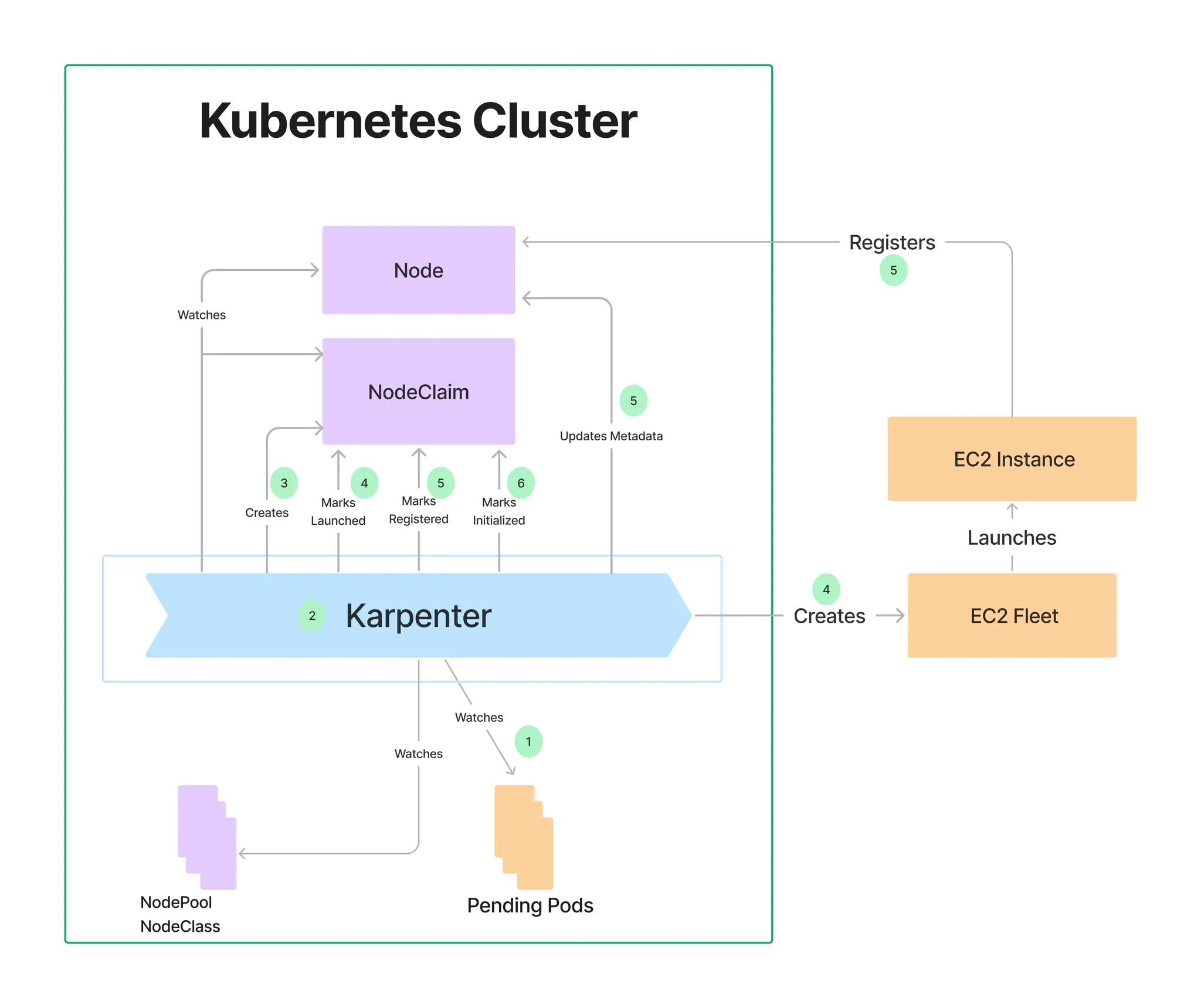
2. Karpenter 동작 방식
2.1 주요 기능
Karpenter는 Kubernetes 스케줄러와 협력하여 동적으로 노드를 관리합니다.
주요 동작 방식은 다음과 같습니다.
1. Provisioning (노드 생성)
- 클러스터에서 실행되지 못하고
Pending상태인 Pod가 발생하면 Karpenter가 이를 감지 - Pod의 요구 사항(CPU, 메모리, 가용 영역, 인스턴스 유형 등)을 분석하여 최적의 EC2 인스턴스를 프로비저닝
- AWS EC2 Fleet API를 호출하여 최적의 인스턴스를 프로비저닝 (온디맨드 및 스팟 혼합 활용)
- 노드풀(NodePool)을 통해 요구사항을 사전에 정의 가능 (예: 특정 인스턴스 타입, AZ 등)
2. Deprovisioning (노드 정리)
- 기존 노드의 사용률을 지속적으로 모니터링
- 클러스터에서 사용되지 않는 노드를 감지하여 자동으로 종료
- 설정 가능한 자동 만료 옵션 제공:
ttlSecondsAfterEmpty: 노드에 데몬셋을 제외한 Pod이 없으면 설정한 시간이 지난 후 자동 제거ttlSecondsUntilExpired: 지정된 시간이 지난 노드는 자동 cordon/drain 후 제거하여 최신 AMI 유지 및 리소스 효율성 증대
- 노드가 적절히 drain되지 않을 경우 운영 비효율 발생 가능성 존재하므로 주의 필요
3. Consolidation (노드 통합 및 최적화)
- 여러 개의 작은 노드를 하나의 큰 노드로 통합하여 효율적인 리소스 사용
- 기존보다 저렴한 노드가 존재할 경우 교체
- AWS Spot Instance를 적극 활용하여 비용 절감
- 노드 수를 최소화하면서도 성능을 유지하는 방식으로 리소스를 조정
- Pod 재스케줄링을 최소화하여 중단 비용 최소화 전략 적용
Karpenter는 Kubernetes의 표준 스케줄링 제약을 따르며, 가용성을 유지하는 동시에 리소스를 최소화하는 전략을 사용합니다.
2.2 동작 흐름
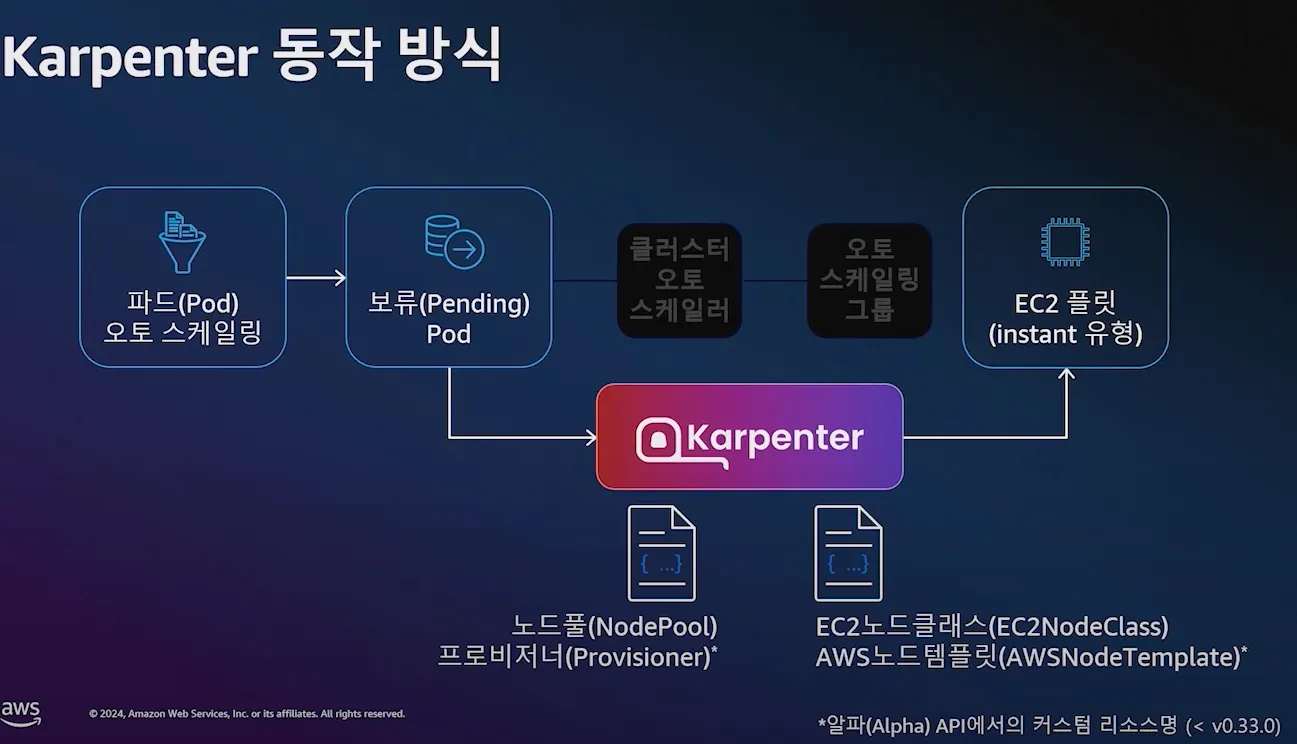
https://www.youtube.com/watch?v=jLuVZX6WQsw
- 파드(Pod) 오토 스케일링 → 보류(Pending) Pod → Karpenter → EC2 플릿(instant 유형)
- Kubernetes에서
Pending상태의 Pod가 감지됨 - Karpenter가 Pod의 요구 사항을 분석
- EC2 Fleet API를 호출하여 최적의 인스턴스를 선택하고 생성
- 새로운 노드가 클러스터에 조인되면, Kube-scheduler가 Pod를 해당 노드에 배치
- 불필요한 노드는 자동으로 제거되거나, 최적의 노드로 통합
3. Karpenter의 주요 기능 및 활용 전략
3.1 Node Provisioning (노드 프로비저닝)
- Pod의 요구사항을 분석하여 최적의 인스턴스를 선택
- AWS EC2 Fleet API를 활용하여 비용 대비 성능이 가장 좋은 인스턴스 요청
- Kubernetes 스케줄러와 협력하여 적절한 노드 배치
- ASG 없이도 독립적으로 노드 관리 가능
📌 노드 생성 예시
- Pending 상태의 Pod 발생 시 Karpenter가 감지하여 적절한 노드 프로비저닝
- AWS Graviton, Spot Instance, 온디맨드 인스턴스 등을 고려하여 최적의 비용 절감
- 워크로드 요구사항을 반영하여 노드 크기, 유형 등을 동적으로 결정
3.2 Node Deprovisioning (불필요한 노드 자동 정리)
- 클러스터 내 사용되지 않는 노드를 감지하고 자동 종료
- 특정 노드의 가용성이 낮거나 비용이 비효율적일 경우, 새로운 노드로 대체
- 필요할 경우 워크로드를 다른 노드로 이동하여 클러스터 최적화
📌 노드 자동 정리 시나리오
- 클러스터에서 사용률이 낮은 노드 감지 → 기존 워크로드를 다른 노드로 이동 후 종료
- Spot Instance가 종료되기 전에 새로운 인스턴스를 배포하여 서비스 중단 방지
3.3 Consolidation (노드 통합 및 최적화)
Karpenter의 Consolidation 기능은 클러스터 내 리소스 사용률을 최적화하여 비용 절감을 유도합니다.
✅ Consolidation 주요 기능
- 여러 개의 작은 노드를 하나의 큰 노드로 통합
- 기존보다 더 저렴한 노드가 존재할 경우 교체
- 사용되지 않는 노드를 감지하여 자동으로 종료
📌 Consolidation 시나리오
- 기존 작은 노드 여러 개를 제거하고, 하나의 큰 노드로 통합
- 특정 시간 동안 사용되지 않은 노드를 감지하여 자동 종료
- AWS Spot Instance 활용으로 비용 절감
📌 Consolidation 동작 원리
- Consolidation 주기 동안 대기
- 대상 노드 식별
- Consolidation 기능이 활성화 된 Provisioner에 의해 구동된 노드
- do-not-consolidate 어노테이션이 설정되지 않은 노드
- 초기화가 완료되었으며, reports Ready이며, 모든 확장 리소스가 등록된 노드
- 중단 비용을 기준으로 노드 정렬
- 중단 비용 예) 파드가 많이 배치되어서 재스케줄링 영향이 큰 경우 등 , 오래 기동된 노드 TTL, 비용 관련
- 최저 중단 비용을 가진 노드가 존재하지 않을 경우의 스케줄링을 시뮬레이션
- 기존 노드에 Pod 스케줄링 가능 → 기존 노드 유지
- 더 저렴한 노드에 스케줄링 가능 → 노드 변경
- Pod가 동일 혹은 더 비싼 노드를 요구 → 기존 유지
📌 노드 통합 활성화
apiversion: karpenter.sh/v1beta1
kind: NodePool
spec:
disruption:
consolidationPolicy: whenUnderutilized3.4 비용 최적화 및 리소스 활용 극대화
Karpenter는 비용 최적화를 위해 다양한 AWS 컴퓨팅 옵션을 동적으로 활용합니다.
✅ 비용 절감 전략
- AWS Graviton 프로세서를 활용하여 비용 절감
- Spot Instance를 우선적으로 사용하지만, 필요할 경우 온디맨드도 선택
- 워크로드 요구사항에 맞춰 인스턴스 크기를 자동 조정
📌 비용 최적화 예시
kind: Provisioner
spec:
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["spot", "on-demand"]Spot Instance를 우선적으로 사용하되, 필요할 경우 온디맨드 인스턴스 활용
4. NodePool 구성 전략과 활용법
Karpenter는 NodePool 개념을 도입하여, 다양한 워크로드 요구 사항을 충족하는 인스턴스를 배포합니다.
4.1 NodePool 활용 방식
- 특정 워크로드에 맞는 인스턴스 타입, 가용 영역(AZ), 구입 옵션 설정 가능
- 다양한 노드 유형을 한 번에 관리하여 최적의 비용 대비 성능 제공
4.2 NodePool 설정 예시
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: karpenter.k8s.aws/instance-family
operator: In
values: ["c5", "m5", "r5"]
- key: karpenter.k8s.aws/instance-size
operator: NotIn
values: ["nano", "micro", "small"]
- key: topology.kubernetes.io/zone
operator: In
values: ["us-west-2a", "us-west-2b"]
...
limits:
cpu: 100특정 가용 영역(AZ)에서 특정 인스턴스 패밀리만 사용하도록 설정 가능
4.3 NodePool 구성 방식
NodePool은 용도에 맞게 컴퓨팅 리소스를 정의하여 효율적인 리소스 관리를 가능케 합니다.
-
단일 구성(Single Configuration)
- 한 NodePool을 여러 팀 및 다양한 워크로드에 활용
- 예시: Graviton과 x86 혼합하여 사용 가능
-
복수 구성(Multiple Configuration)
- 다양한 목적에 따라 분리된 NodePool 운용
- 예시: 팀 간의 보안 격리, 서로 다른 하드웨어 이미지 사용, 성능 간섭 방지
-
가중치 구성(Weighted Configuration)
- NodePool 우선 순위 지정하여 비용 절감 극대화
- 예시: 예약 인스턴스 및 절감형 플랜을 우선 적용한 후 스팟, Graviton, 온디맨드를 순차적으로 활용
4.4 오버 프로비저닝 전략
Karpenter를 사용해도 EC2 인스턴스가 프로비저닝되고 데몬셋 설치까지 최소 1~2분 소요되기 때문에, 긴급 확장을 대비하여 미리 '더미 파드'로 여유 공간을 확보할 필요가 있습니다.
- 낮은 우선순위 파드 활용(PriorityClass를 활용한 깡통 파드 배치)
- TopologySpreadConstraints 및 PodAntiAffinity로 가용 영역 분산
- KEDA를 연계한 미리 증설된 파드 운영으로 대규모 스케일링 대비
5. 노드 생성 심층 분석
1. 스케줄링 (Scheduling)
- kube-scheduler와 협력하여 노드 스케줄링 제약 조건 분석 (리소스 요청, NodeSelector, 어피니티 등)
- 보류 상태(Pending) Pod을 Watch API로 실시간 모니터링하여 즉각 대응
2. 배치(Batching)
- 보류 Pod을 일정 시간(1~10초) 동안 단일 배치로 그룹화하여 효율적인 EC2 Fleet 요청 수행
- 긴밀한 확장 윈도우 알고리즘(Idle 1초, 최대 10초)으로 불필요한 프로비저닝 최소화
3. 빈 패킹(Bin Packing)
- 최소한의 노드 수로 최대한 많은 Pod을 효율적으로 배치
- 비용 중심의 빈 패킹(사용률이 아닌 비용 중심의 접근)을 통해 최적화
- 호스트 포트, 볼륨 토폴로지, 데몬셋 등의 고려를 포함한 정밀한 시뮬레이션 수행
4. 의사 결정(Decision Making)
- EC2 Fleet API를 활용하여 가용 영역, 용량 유형, 가격 등을 고려한 최적의 인스턴스를 선택
- 온디맨드는 lowest-price 전략, 스팟은 price-capacity-optimized 전략으로 중단 가능성 최소화
6. Drift 메커니즘 및 활용
- 선언된 스펙과 실제 운영 노드 간의 불일치를 자동 감지 및 조정
- 설정 변경, AMI 업그레이드, Kubernetes 버전 업그레이드 시 자동 Drift 처리 수행
- AWS Systems Manager Parameter Store와 통합하여 항상 최신 AMI 버전 유지로 보안성 및 운영 편의성 증대
7. 노드 중단(Disruption) 심층 분석
7.1 노드 중단 개요
- 노드 중단은 Drift, Expiration, Interruption(스팟 중단), Consolidation으로 구분됨
- 중단 처리 워크플로우: 후보 노드 선정 → 대체 노드 생성 → 드레이닝 → 노드 종료
7.2 스팟 중단 대처
- 스팟 중단 이벤트 핸들러 내장, EventBridge를 통해 중단 2분 전 알림 수신
- 별도의 핸들러 구축 없이 자동 대응 및 신속한 Pod 재배치(2분 이내)
7.3 노드 Consolidation을 통한 비용 최적화
- 파드 재스케줄링을 최소화하며 적은 수의 효율적인 노드로 비용 절감
- 오래된 노드 및 사용률이 낮은 노드를 우선적으로 통합
8. 운영 사례 효과
(무신사 및 위대한 상상 사례 참고)
- 비용 70% 절감
- 스팟 인스턴스 활용률 75~93% 향상
- 노드 프로비저닝 속도 1.5배 증가
- CPU 활용률 평균 80% 유지 가능
9. Karpenter 실습 환경 구축
9.1 기존 환경 삭제
Karpenter 실습을 위한 EKS 클러스터를 구성하기 전에 기존 환경을 정리합니다. AWS CLI를 활용하여 기존 EKS 클러스터와 관련된 리소스를 제거합니다.
# [운영서버 EC2]에서 기존 EKS 클러스터 원클릭 삭제
# eksctl delete cluster --name $CLUSTER_NAME && aws cloudformation delete-stack --stack-name $CLUSTER_NAME
nohup sh -c "eksctl delete cluster --name $CLUSTER_NAME && aws cloudformation delete-stack --stack-name $CLUSTER_NAME" > /root/delete.log 2>&1 &
# (옵션) 삭제 과정 확인
tail -f delete.log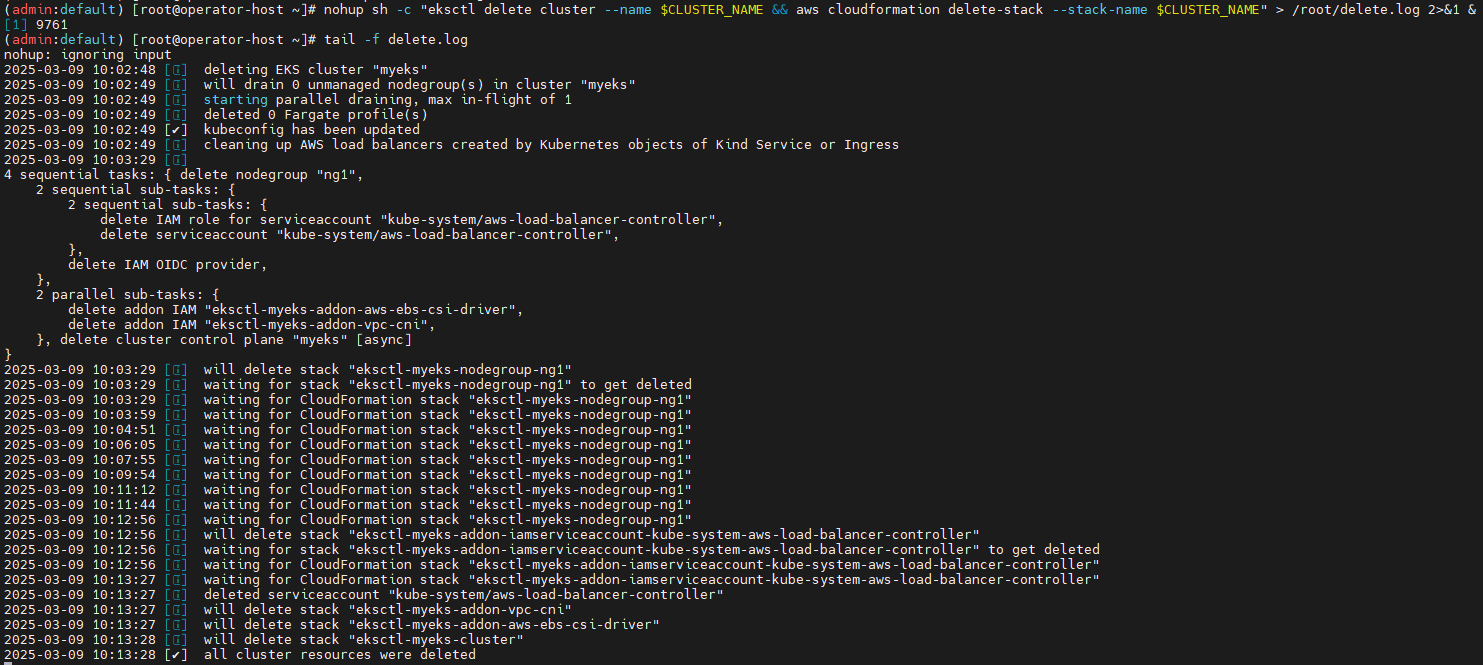
9.2 필수 유틸리티 설치
Karpenter 환경을 구축하기 위해 다음과 같은 도구를 설치합니다.
- AWS CLI - AWS 자격증명 및 클러스터 관리
- kubectl - Kubernetes CLI
- eksctl (v0.202.0 이상) - EKS 클러스터 관리
- Helm - Kubernetes 패키지 매니저
- eks-node-view - EKS 노드 모니터링
9.3 환경 변수 설정
클러스터 및 AWS 관련 환경 변수를 설정합니다.
# 변수 설정
export KARPENTER_NAMESPACE="kube-system"
export KARPENTER_VERSION="1.2.1"
export K8S_VERSION="1.32"
export AWS_PARTITION="aws" # if you are not using standard partitions, you may need to configure to aws-cn / aws-us-gov
export CLUSTER_NAME="gasida-karpenter-demo" # ${USER}-karpenter-demo
export AWS_DEFAULT_REGION="ap-northeast-2"
export AWS_ACCOUNT_ID="$(aws sts get-caller-identity --query Account --output text)"
export TEMPOUT="$(mktemp)"
export ALIAS_VERSION="$(aws ssm get-parameter --name "/aws/service/eks/optimized-ami/${K8S_VERSION}/amazon-linux-2023/x86_64/standard/recommended/image_id" --query Parameter.Value | xargs aws ec2 describe-images --query 'Images[0].Name' --image-ids | sed -r 's/^.*(v[[:digit:]]+).*$/\1/')"
# 설정 확인
echo "${KARPENTER_NAMESPACE}" "${KARPENTER_VERSION}" "${K8S_VERSION}" "${CLUSTER_NAME}" "${AWS_DEFAULT_REGION}" "${AWS_ACCOUNT_ID}" "${TEMPOUT}" "${ALIAS_VERSION}"
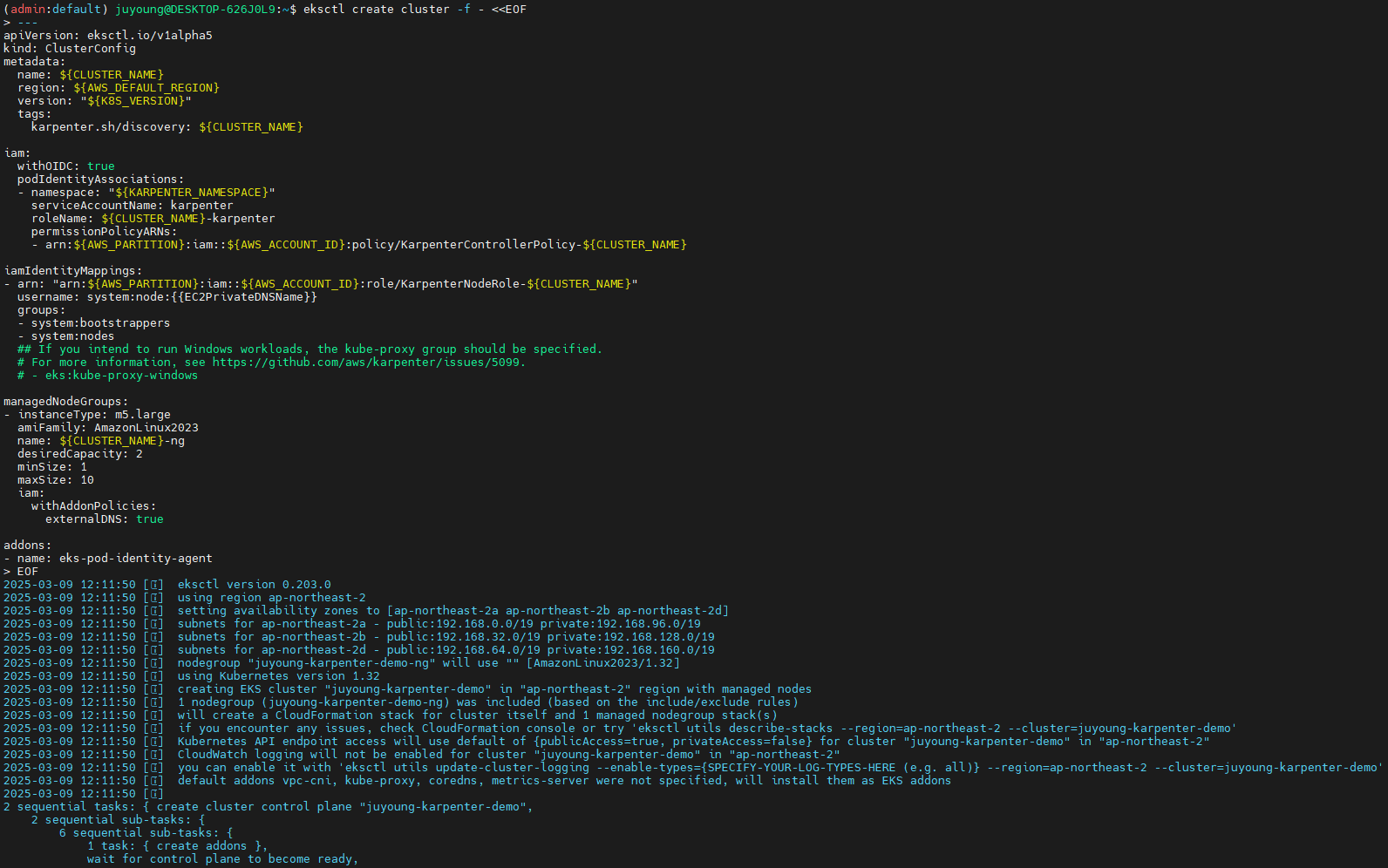
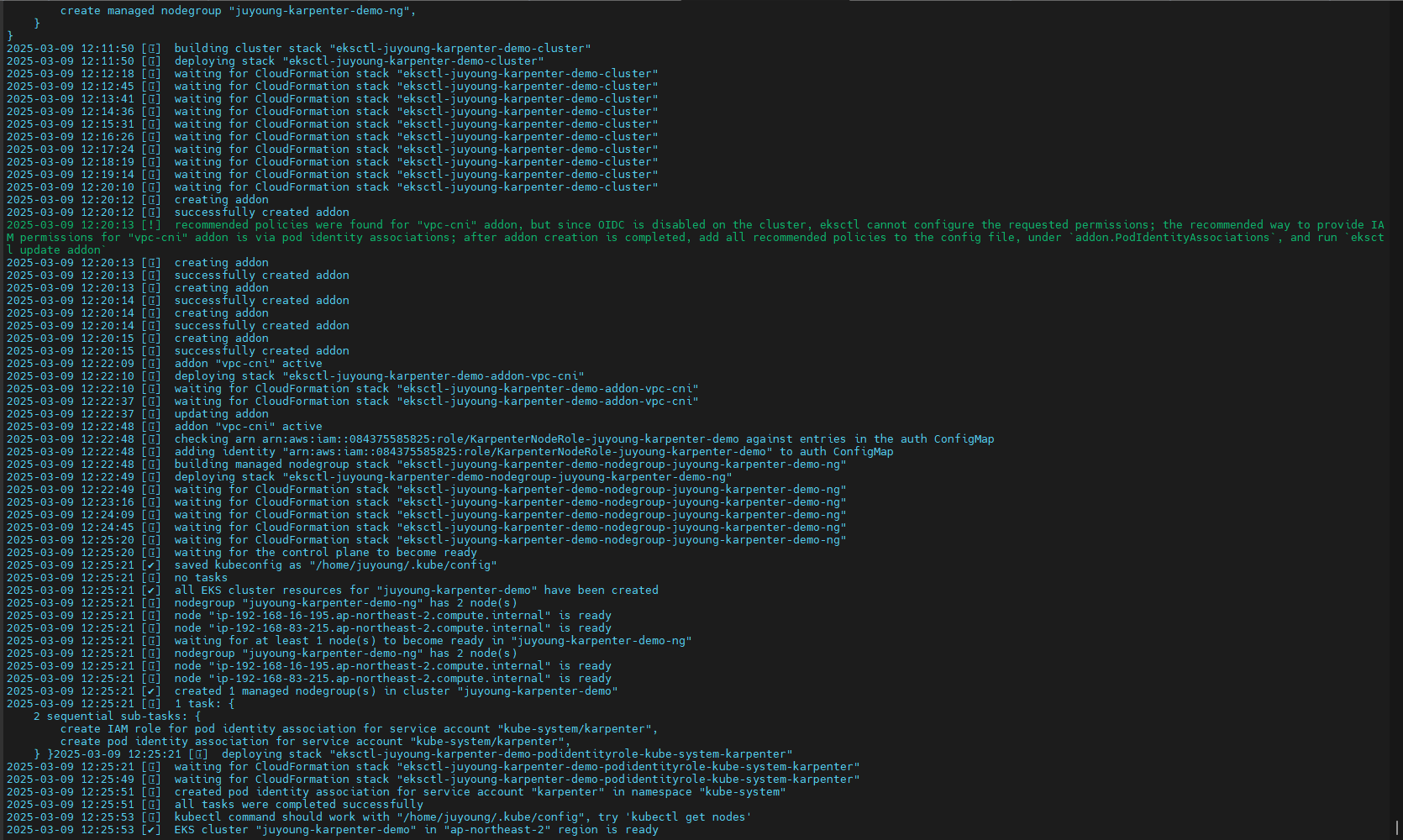
9.4 EKS 클러스터 생성
CloudFormation을 사용하여 필요한 인프라를 배포한 후 EKS 클러스터를 생성합니다.
# CloudFormation 스택으로 IAM Policy/Role, SQS, Event/Rule 생성 : 3분 정도 소요
## IAM Policy : KarpenterControllerPolicy-gasida-karpenter-demo
## IAM Role : KarpenterNodeRole-gasida-karpenter-demo
curl -fsSL https://raw.githubusercontent.com/aws/karpenter-provider-aws/v"${KARPENTER_VERSION}"/website/content/en/preview/getting-started/getting-started-with-karpenter/cloudformation.yaml > "${TEMPOUT}" \
&& aws cloudformation deploy \
--stack-name "Karpenter-${CLUSTER_NAME}" \
--template-file "${TEMPOUT}" \
--capabilities CAPABILITY_NAMED_IAM \
--parameter-overrides "ClusterName=${CLUSTER_NAME}"
# EKS 클러스터 생성 : 15분 정도 소요
eksctl create cluster -f - <<EOF
---
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: ${CLUSTER_NAME}
region: ${AWS_DEFAULT_REGION}
version: "${K8S_VERSION}"
tags:
karpenter.sh/discovery: ${CLUSTER_NAME}
iam:
withOIDC: true
podIdentityAssociations:
- namespace: "${KARPENTER_NAMESPACE}"
serviceAccountName: karpenter
roleName: ${CLUSTER_NAME}-karpenter
permissionPolicyARNs:
- arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:policy/KarpenterControllerPolicy-${CLUSTER_NAME}
iamIdentityMappings:
- arn: "arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:role/KarpenterNodeRole-${CLUSTER_NAME}"
username: system:node:{{EC2PrivateDNSName}}
groups:
- system:bootstrappers
- system:nodes
## If you intend to run Windows workloads, the kube-proxy group should be specified.
# For more information, see https://github.com/aws/karpenter/issues/5099.
# - eks:kube-proxy-windows
managedNodeGroups:
- instanceType: m5.large
amiFamily: AmazonLinux2023
name: ${CLUSTER_NAME}-ng
desiredCapacity: 2
minSize: 1
maxSize: 10
iam:
withAddonPolicies:
externalDNS: true
addons:
- name: eks-pod-identity-agent
EOF
# eks 배포 확인
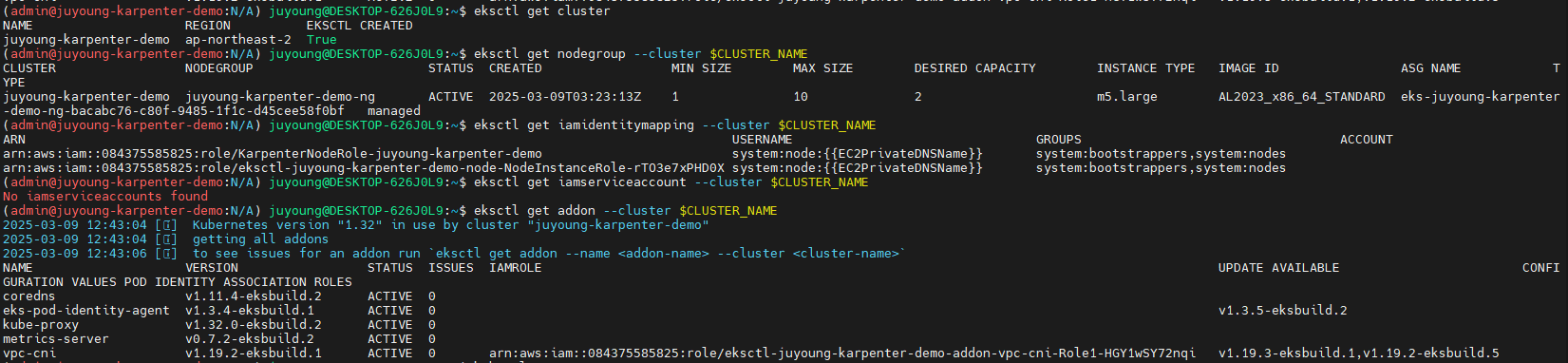
eksctl get cluster
eksctl get nodegroup --cluster $CLUSTER_NAME
eksctl get iamidentitymapping --cluster $CLUSTER_NAME
eksctl get iamserviceaccount --cluster $CLUSTER_NAME
eksctl get addon --cluster $CLUSTER_NAME
#
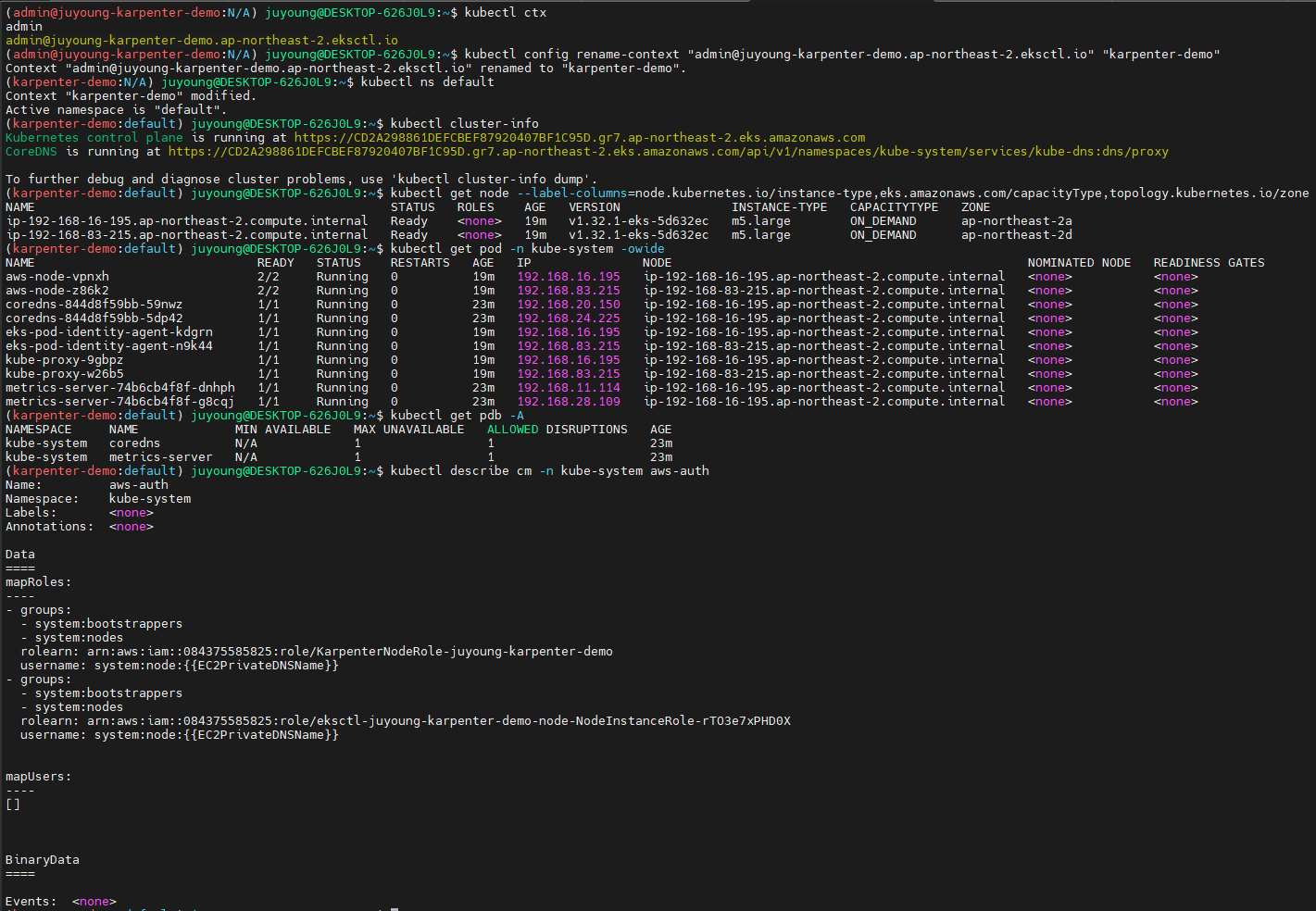
kubectl ctx
kubectl config rename-context "<각자 자신의 IAM User>@<자신의 Nickname>-karpenter-demo.ap-northeast-2.eksctl.io" "karpenter-demo"
kubectl config rename-context "admin@gasida-karpenter-demo.ap-northeast-2.eksctl.io" "karpenter-demo"
# k8s 확인
kubectl ns default
kubectl cluster-info
kubectl get node --label-columns=node.kubernetes.io/instance-type,eks.amazonaws.com/capacityType,topology.kubernetes.io/zone
kubectl get pod -n kube-system -owide
kubectl get pdb -A
kubectl describe cm -n kube-system aws-auth
# EC2 Spot Fleet의 service-linked-role 생성 확인 : 만들어있는것을 확인하는 거라 아래 에러 출력이 정상!
# If the role has already been successfully created, you will see:
# An error occurred (InvalidInput) when calling the CreateServiceLinkedRole operation: Service role name AWSServiceRoleForEC2Spot has been taken in this account, please try a different suffix.
aws iam create-service-linked-role --aws-service-name spot.amazonaws.com || true
9.5 실습 동작 확인을 위한 도구 설치 : kube-ops-view
# kube-ops-view
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --set service.main.type=LoadBalancer --set env.TZ="Asia/Seoul" --namespace kube-system
echo -e "http://$(kubectl get svc -n kube-system kube-ops-view -o jsonpath="{.status.loadBalancer.ingress[0].hostname}"):8080/#scale=1.5"
open "http://$(kubectl get svc -n kube-system kube-ops-view -o jsonpath="{.status.loadBalancer.ingress[0].hostname}"):8080/#scale=1.5"
9.6 Karpenter 설치
Karpenter의 DNS 정책 및 노드 용량 관리
-
Karpenter는 기본적으로
ClusterFirst포드 DNS 정책을 사용합니다. Karpenter가 DNS 서비스 포드의 용량을 관리해야 하는 경우, Karpenter가 시작될 때 DNS가 실행되지 않을 수 있습니다. 이를 방지하기 위해 포드의 DNS 정책을Default로 설정해야 합니다.
--set dnsPolicy=Default -
Karpenter는 클러스터 내 CloudProvider 머신과 CustomResources 간의 매핑을 유지하기 위해 다음과 같은 태그를 활용합니다.
karpenter.sh/managed-bykarpenter.sh/nodepoolkubernetes.io/cluster/${CLUSTER_NAME}
Helm을 사용하여 Karpenter를 설치합니다.
# Logout of helm registry to perform an unauthenticated pull against the public ECR
helm registry logout public.ecr.aws
# Karpenter 설치를 위한 변수 설정 및 확인
export CLUSTER_ENDPOINT="$(aws eks describe-cluster --name "${CLUSTER_NAME}" --query "cluster.endpoint" --output text)"
export KARPENTER_IAM_ROLE_ARN="arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:role/${CLUSTER_NAME}-karpenter"
echo "${CLUSTER_ENDPOINT} ${KARPENTER_IAM_ROLE_ARN}"
# Karpenter 설치
helm upgrade --install karpenter oci://public.ecr.aws/karpenter/karpenter --version "${KARPENTER_VERSION}" --namespace "${KARPENTER_NAMESPACE}" --create-namespace \
--set "settings.clusterName=${CLUSTER_NAME}" \
--set "settings.interruptionQueue=${CLUSTER_NAME}" \
--set controller.resources.requests.cpu=1 \
--set controller.resources.requests.memory=1Gi \
--set controller.resources.limits.cpu=1 \
--set controller.resources.limits.memory=1Gi \
--wait
# 설치 확인
helm list -n kube-system
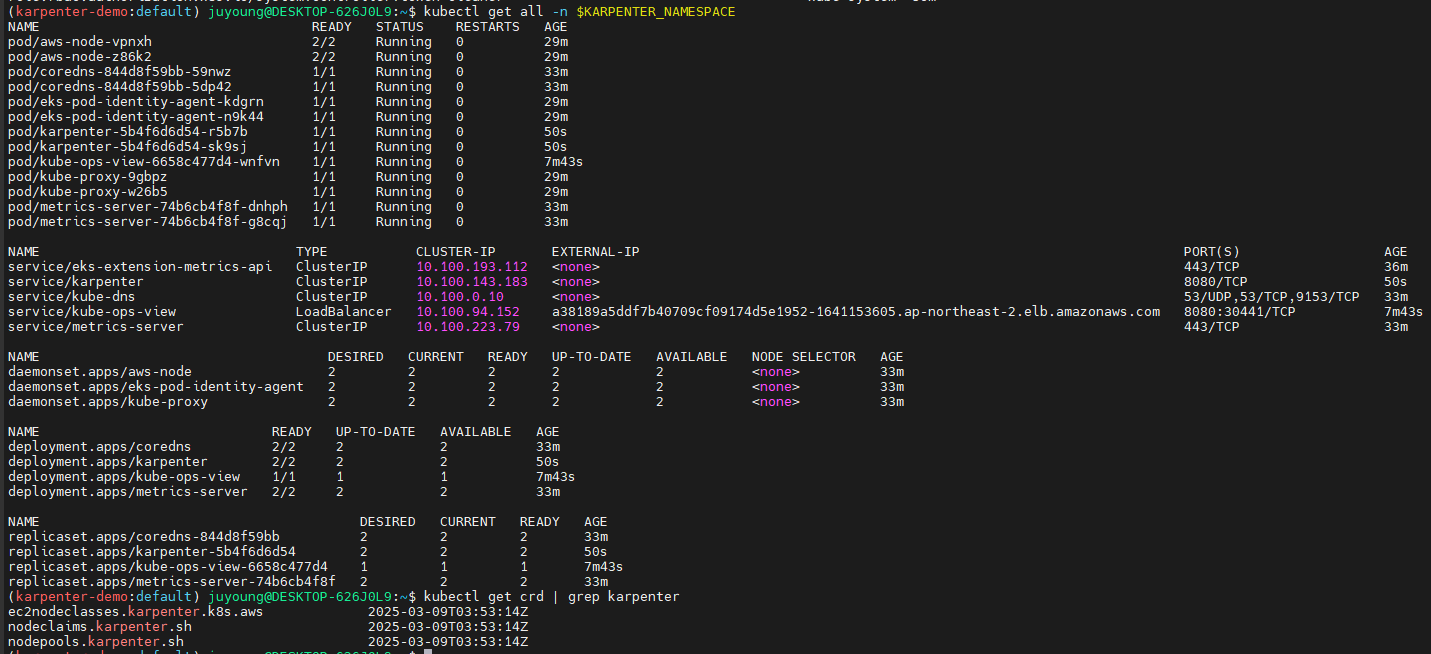
kubectl get-all -n $KARPENTER_NAMESPACE
kubectl get all -n $KARPENTER_NAMESPACE
kubectl get crd | grep karpenter
ec2nodeclasses.karpenter.k8s.aws 2025-03-02T06:11:47Z
nodeclaims.karpenter.sh 2025-03-02T06:11:47Z
nodepools.karpenter.sh 2025-03-02T06:11:47Z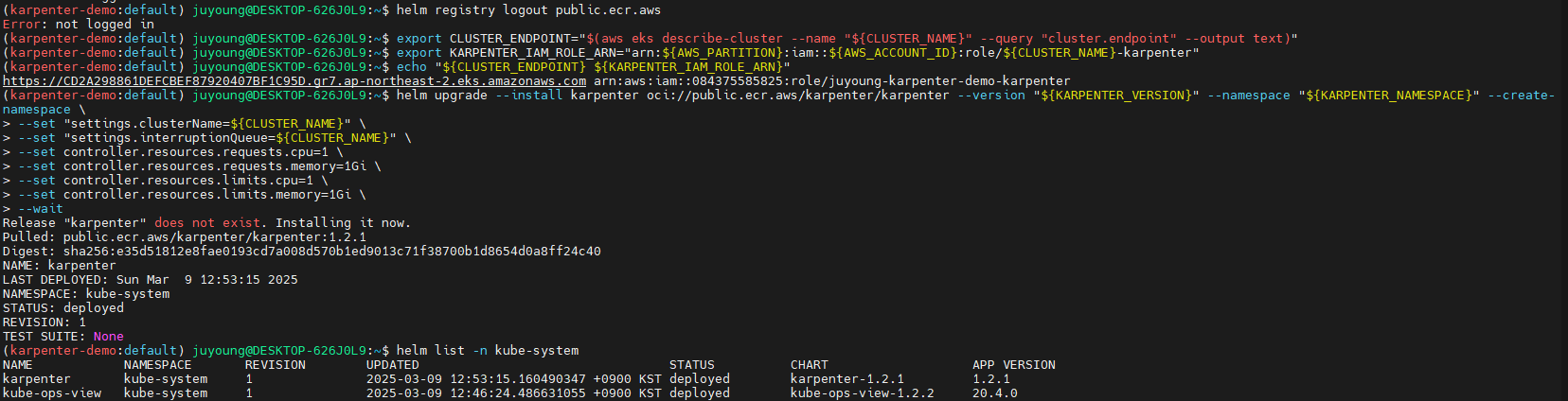
9.7 Prometheus, Grafana 설치
#
helm repo add grafana-charts https://grafana.github.io/helm-charts
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
kubectl create namespace monitoring
# 프로메테우스 설치
curl -fsSL https://raw.githubusercontent.com/aws/karpenter-provider-aws/v"${KARPENTER_VERSION}"/website/content/en/preview/getting-started/getting-started-with-karpenter/prometheus-values.yaml | envsubst | tee prometheus-values.yaml
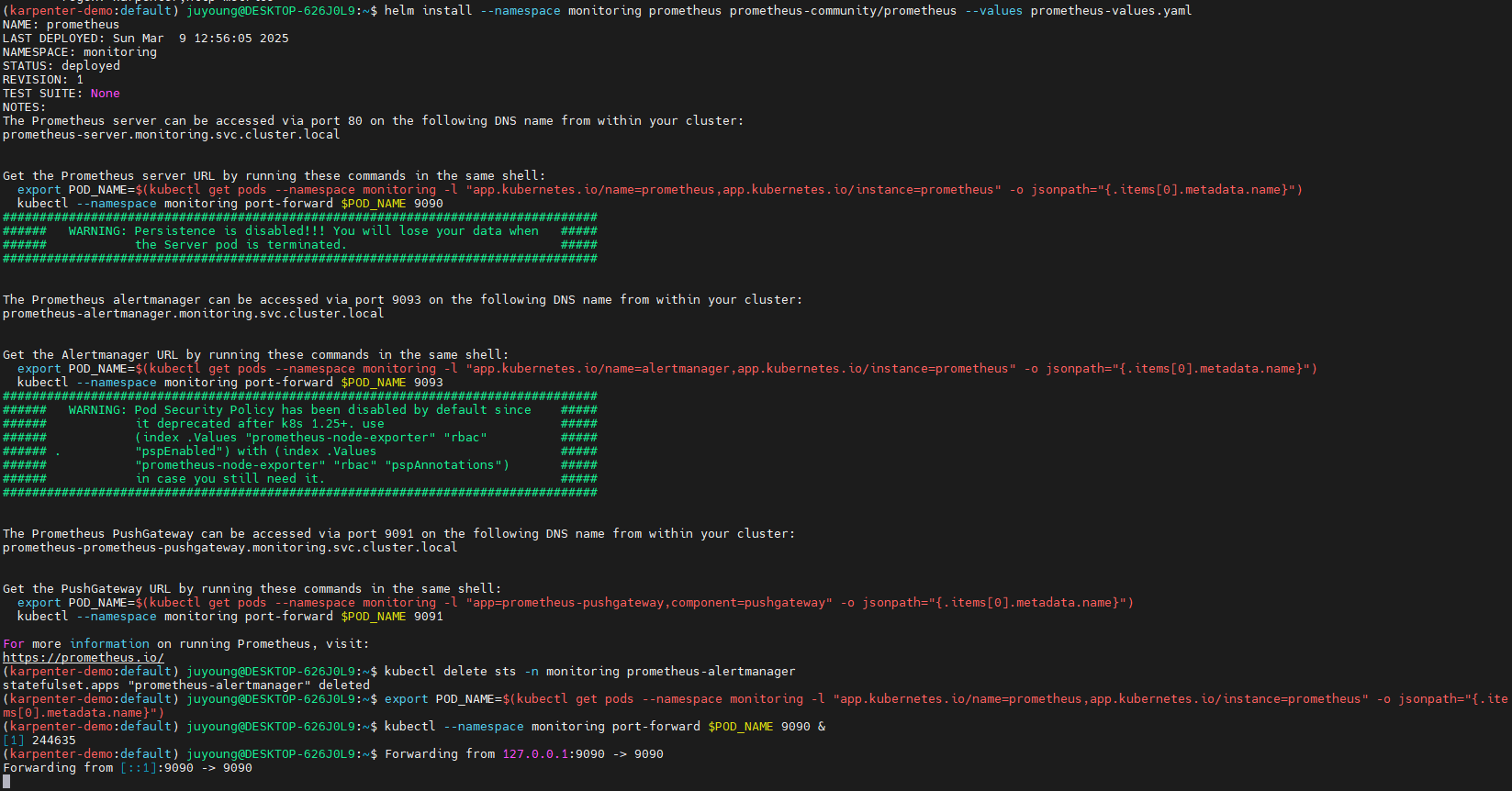
helm install --namespace monitoring prometheus prometheus-community/prometheus --values prometheus-values.yaml
extraScrapeConfigs: |
- job_name: karpenter
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- kube-system
relabel_configs:
- source_labels:
- __meta_kubernetes_endpoints_name
- __meta_kubernetes_endpoint_port_name
action: keep
regex: karpenter;http-metrics
# 프로메테우스 얼럿매니저 미사용으로 삭제
kubectl delete sts -n monitoring prometheus-alertmanager
# 프로메테우스 접속 설정
export POD_NAME=$(kubectl get pods --namespace monitoring -l "app.kubernetes.io/name=prometheus,app.kubernetes.io/instance=prometheus" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace monitoring port-forward $POD_NAME 9090 &
open http://127.0.0.1:9090
# 그라파나 설치
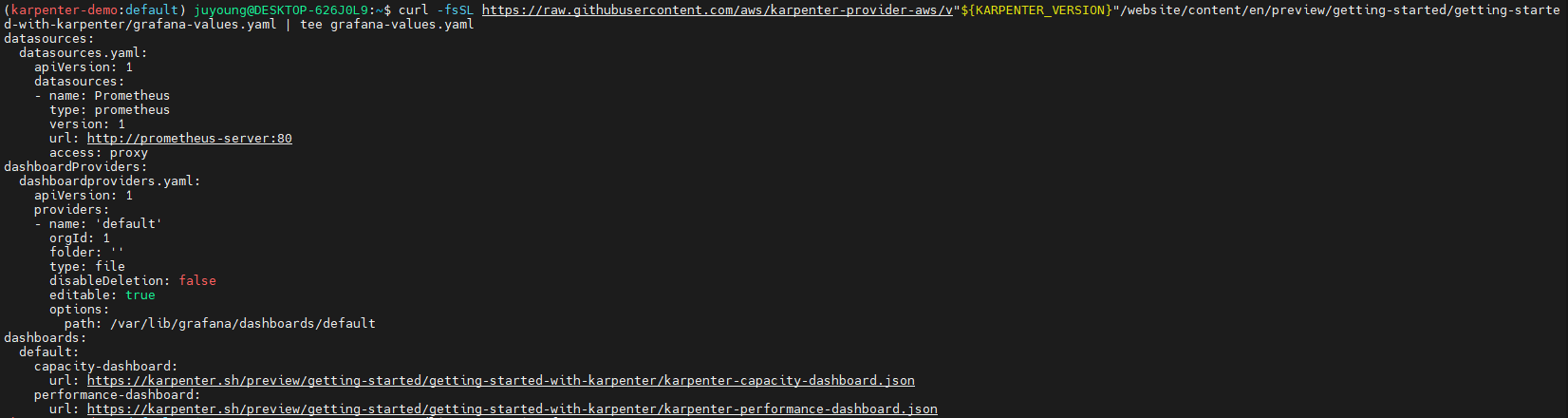
curl -fsSL https://raw.githubusercontent.com/aws/karpenter-provider-aws/v"${KARPENTER_VERSION}"/website/content/en/preview/getting-started/getting-started-with-karpenter/grafana-values.yaml | tee grafana-values.yaml
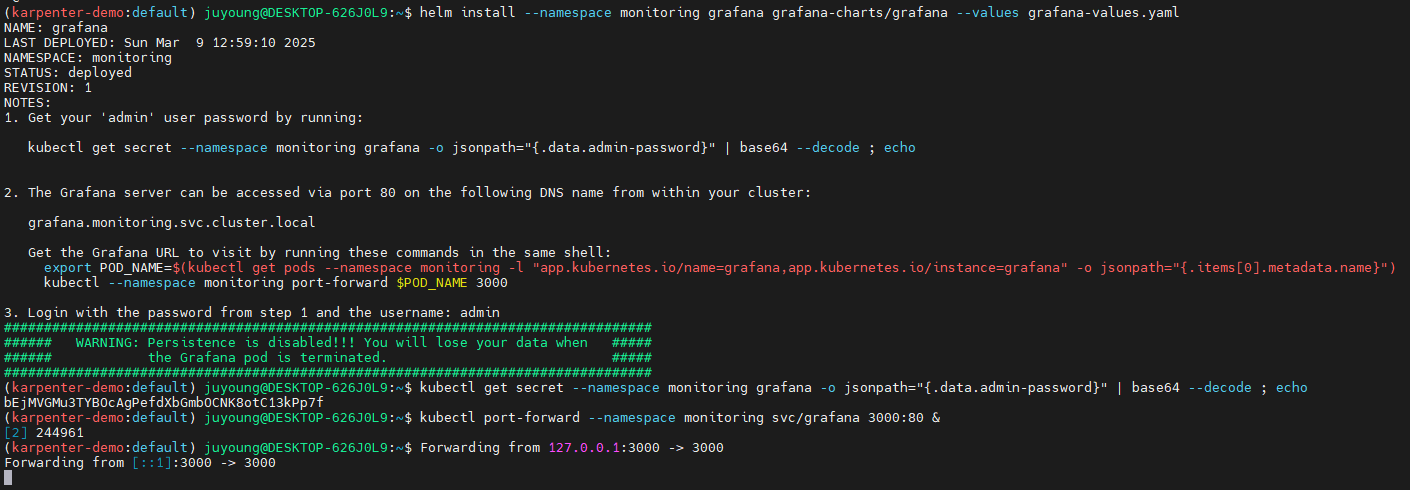
helm install --namespace monitoring grafana grafana-charts/grafana --values grafana-values.yaml
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
version: 1
url: http://prometheus-server:80
access: proxy
dashboardProviders:
dashboardproviders.yaml:
apiVersion: 1
providers:
- name: 'default'
orgId: 1
folder: ''
type: file
disableDeletion: false
editable: true
options:
path: /var/lib/grafana/dashboards/default
dashboards:
default:
capacity-dashboard:
url: https://karpenter.sh/preview/getting-started/getting-started-with-karpenter/karpenter-capacity-dashboard.json
performance-dashboard:
url: https://karpenter.sh/preview/getting-started/getting-started-with-karpenter/karpenter-performance-dashboard.json
# admin 암호
kubectl get secret --namespace monitoring grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
17JUGSjgxK20m4NEnAaG7GzyBjqAMHMFxRnXItLj
# 그라파나 접속
kubectl port-forward --namespace monitoring svc/grafana 3000:80 &
open http://127.0.0.1:3000
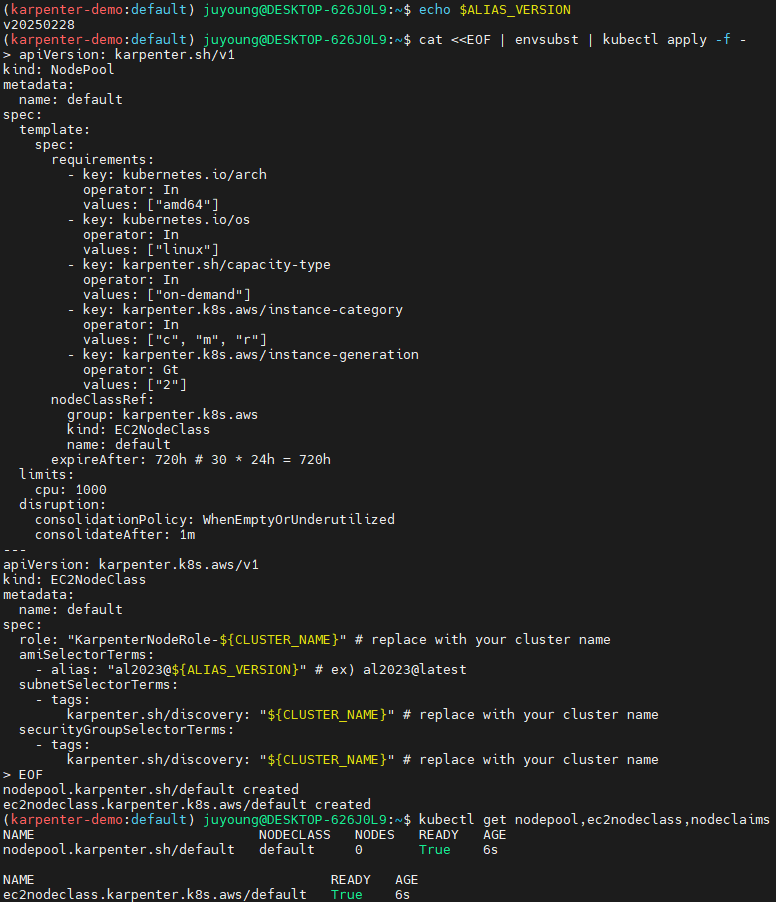
9.8 NodePool (Provisioner) 생성
Karpenter의 노드 관리 및 최적화 전략
-
관리 리소스 탐색: Karpenter는
securityGroupSelector및subnetSelector를 활용하여 클러스터 내에서 적절한 노드를 탐색하고 관리합니다.
또한,karpenter.sh/discovery태그를 이용하여 클러스터와 연동된 리소스를 자동으로 감지하여 노드 프로비저닝을 최적화합니다. -
자동 정리 정책 (
consolidationPolicy): 미사용 노드는 자동으로 정리되며, 데몬셋을 제외한 빈 노드는 통합될 수 있습니다.
특히,consolidationPolicy: WhenEmptyOrUnderutilized설정을 통해 노드가 비어 있거나 부분적으로만 사용될 경우 자동으로 통합하여 클러스터 비용을 절감할 수 있습니다. -
유연한 NodePool 관리: 단일 Karpenter NodePool은 다양한 Pod 형태를 처리하며, 레이블 및 친화성을 기반으로 최적의 노드를 선택합니다.
이를 통해, 각기 다른 워크로드를 단일 NodePool에서 효과적으로 운영할 수 있어 복잡한 노드 그룹 관리를 줄일 수 있습니다. -
자동 확장 및 비용 최적화: Karpenter는
consolidationPolicy를 설정하여 불필요한 노드를 종료하고, 클러스터 비용을 최적화할 수 있습니다.
필요 시 consolidateAfter를 Never로 설정하여 특정 노드를 유지하며 자동 통합을 방지할 수도 있습니다. -
자동 확장 및 비용 최적화: Karpenter는 consolidationPolicy를 설정하여 빈 노드를 종료하고 클러스터 비용을 최적화할 수 있습니다. 필요 시 consolidateAfter를 Never로 설정하여 통합을 방지할 수도 있습니다.
-
제한된 용량 내 운영: NodePool은 전체 노드 용량의 합이 사전 정의된 한도를 초과하지 않도록 제어됩니다.
Karpenter는 생성된 모든 용량을 지속적으로 추적하여 사전에 설정된 리소스 한도를 초과하지 않도록 조정합니다.
Karpenter의 노드 자동 프로비저닝을 위한 기본 NodePool을 생성합니다.
#
echo $ALIAS_VERSION
v20250228
#
cat <<EOF | envsubst | kubectl apply -f -
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["c", "m", "r"]
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values: ["2"]
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: default
expireAfter: 720h # 30 * 24h = 720h
limits:
cpu: 1000
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
consolidateAfter: 1m
---
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
role: "KarpenterNodeRole-${CLUSTER_NAME}" # replace with your cluster name
amiSelectorTerms:
- alias: "al2023@${ALIAS_VERSION}" # ex) al2023@latest
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
EOF
# NodePool 확인
kubectl get nodepool,ec2nodeclass,nodeclaims이제 Karpenter가 활성화되어 노드 프로비저닝을 시작할 준비가 되었습니다.
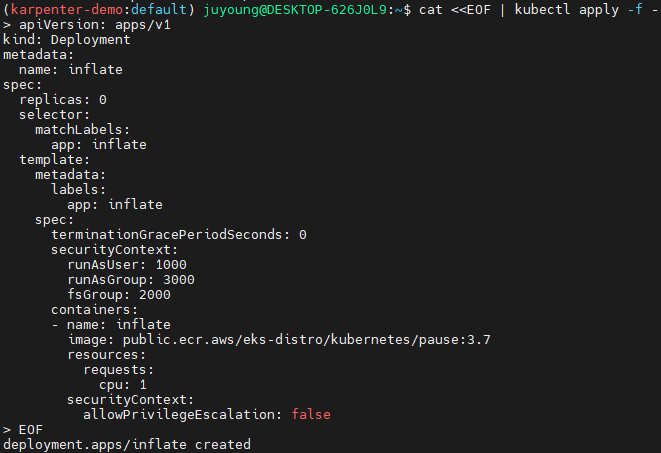
10. Karpenter 스케일링 테스트
10.1 노드 자동 확장 테스트 (Scale Up)
이 디플로이먼트는 pause 이미지를 사용하며 복제본 0개로 시작합니다.
# pause 파드 1개에 CPU 1개 최소 보장 할당할 수 있게 디플로이먼트 배포
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 0
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
terminationGracePeriodSeconds: 0
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
resources:
requests:
cpu: 1
securityContext:
allowPrivilegeEscalation: false
EOF
# [신규 터미널] 모니터링
eks-node-viewer --resources cpu,memory
eks-node-viewer --resources cpu,memory --node-selector "karpenter.sh/registered=true" --extra-labels eks-node-viewer/node-age
# Scale up
kubectl get pod
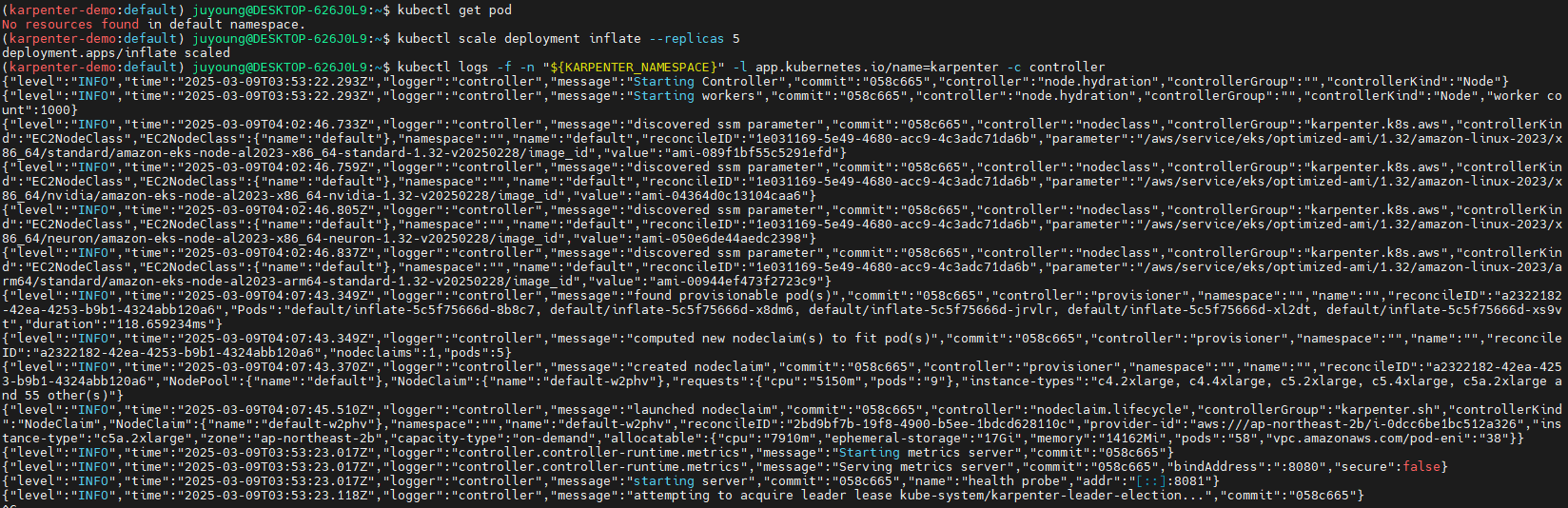
kubectl scale deployment inflate --replicas 5
# 출력 로그 분석해보자!
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
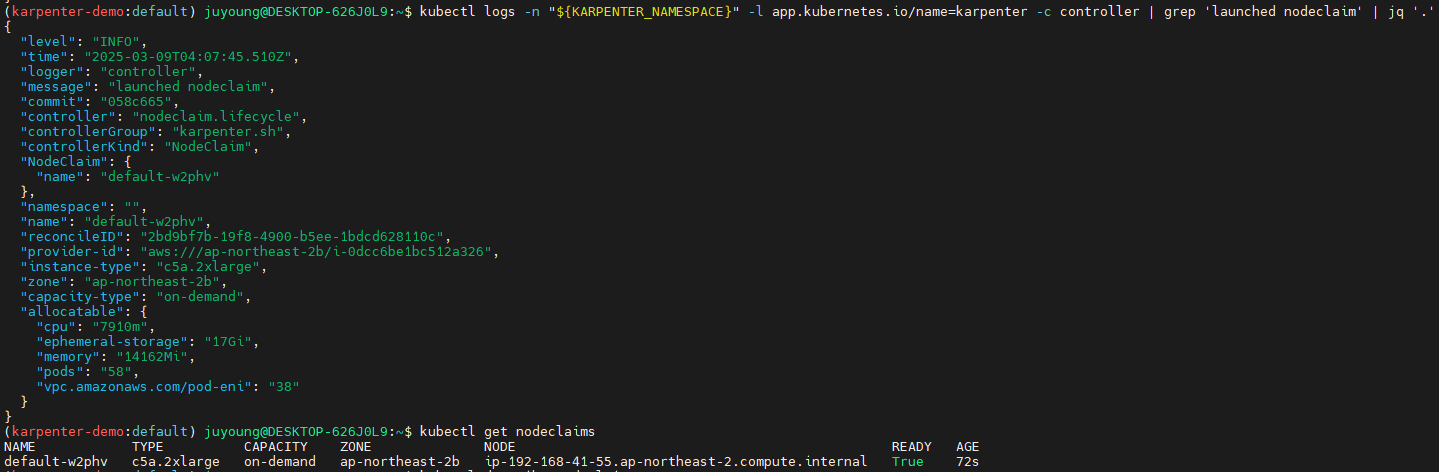
kubectl logs -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | grep 'launched nodeclaim' | jq '.'
{
"level": "INFO",
"time": "2025-03-02T07:43:14.316Z",
"logger": "controller",
"message": "launched nodeclaim",
"commit": "058c665",
"controller": "nodeclaim.lifecycle",
"controllerGroup": "karpenter.sh",
"controllerKind": "NodeClaim",
"NodeClaim": {
"name": "default-x7ntc"
},
"namespace": "",
"name": "default-x7ntc",
"reconcileID": "51854f39-e885-45a5-895c-e55a15b160f0",
"provider-id": "aws:///ap-northeast-2c/i-062705e52143939a6",
"instance-type": "c5a.2xlarge",
"zone": "ap-northeast-2c",
"capacity-type": "on-demand",
"allocatable": {
"cpu": "7910m",
"ephemeral-storage": "17Gi",
"memory": "14162Mi",
"pods": "58",
"vpc.amazonaws.com/pod-eni": "38"
}
}
# 확인
kubectl get nodeclaims
NAME TYPE CAPACITY ZONE NODE READY AGE
default-8f5vd c5a.2xlarge on-demand ap-northeast-2c ip-192-168-176-171.ap-northeast-2.compute.internal True 79s
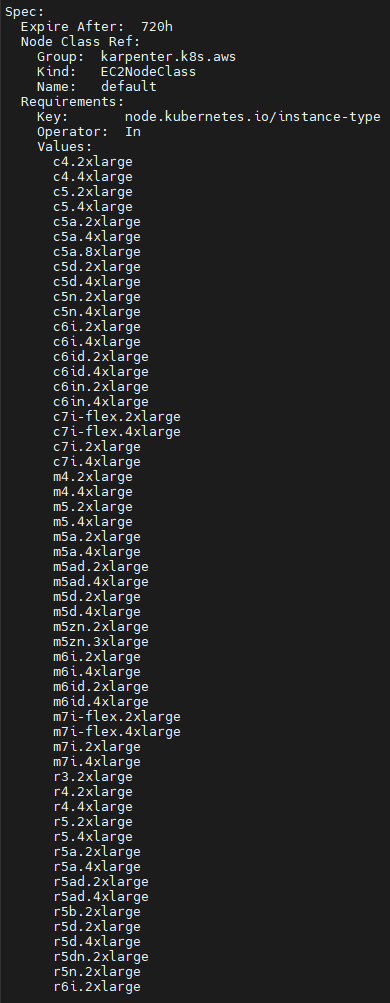
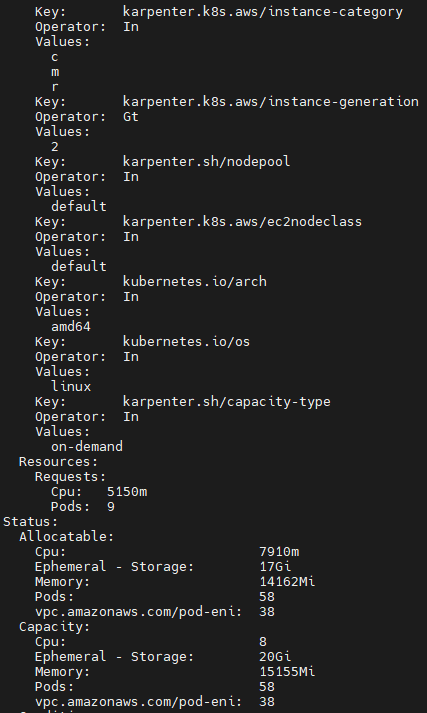
kubectl describe nodeclaims
...
Spec:
Expire After: 720h
Node Class Ref:
Group: karpenter.k8s.aws
Kind: EC2NodeClass
Name: default
Requirements:
Key: karpenter.k8s.aws/instance-category
Operator: In
Values:
c
m
r
Key: node.kubernetes.io/instance-type
Operator: In
Values:
c4.2xlarge
c4.4xlarge
c5.2xlarge
c5.4xlarge
c5a.2xlarge
c5a.4xlarge
c5a.8xlarge
c5d.2xlarge
c5d.4xlarge
...
...
Key: karpenter.sh/capacity-type
Operator: In
Values:
on-demand
Resources:
Requests:
Cpu: 4150m
Pods: 8
Status:
Allocatable:
Cpu: 7910m
Ephemeral - Storage: 17Gi
Memory: 14162Mi
Pods: 58
vpc.amazonaws.com/pod-eni: 38
Capacity:
Cpu: 8
Ephemeral - Storage: 20Gi
Memory: 15155Mi
Pods: 58
vpc.amazonaws.com/pod-eni: 38
...
#
kubectl get node -l karpenter.sh/registered=true -o jsonpath="{.items[0].metadata.labels}" | jq '.'
...
"karpenter.sh/initialized": "true",
"karpenter.sh/nodepool": "default",
"karpenter.sh/registered": "true",
...
# (옵션) 더욱 더 Scale up!
kubectl scale deployment inflate --replicas 30-
Deployment 배포
-
Scale up 전


-
Scale up 후


-
kubectl describe nodeclaims
-
생성된 노드 정보
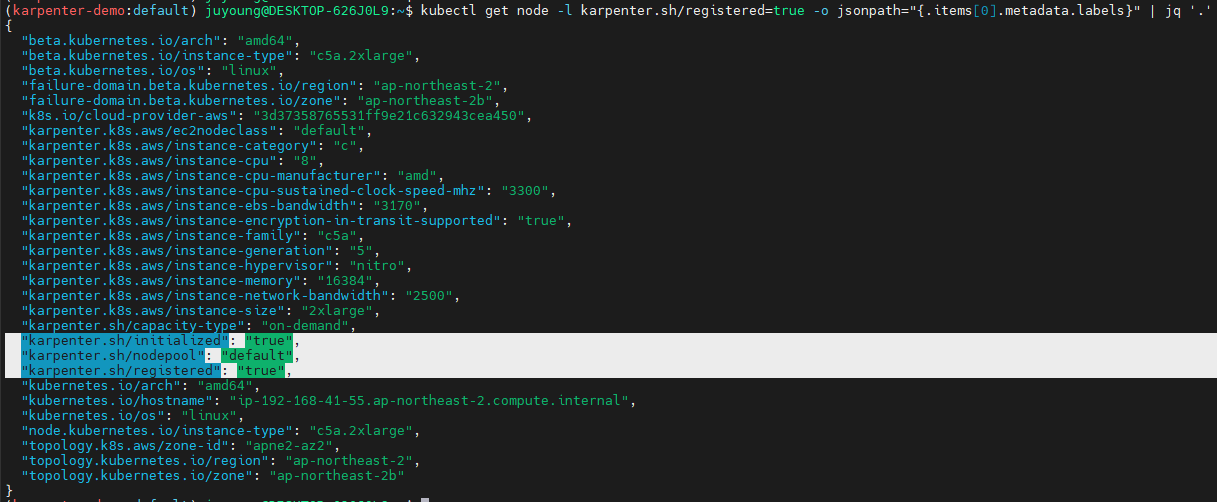
-
CreateFleet 이벤트 확인
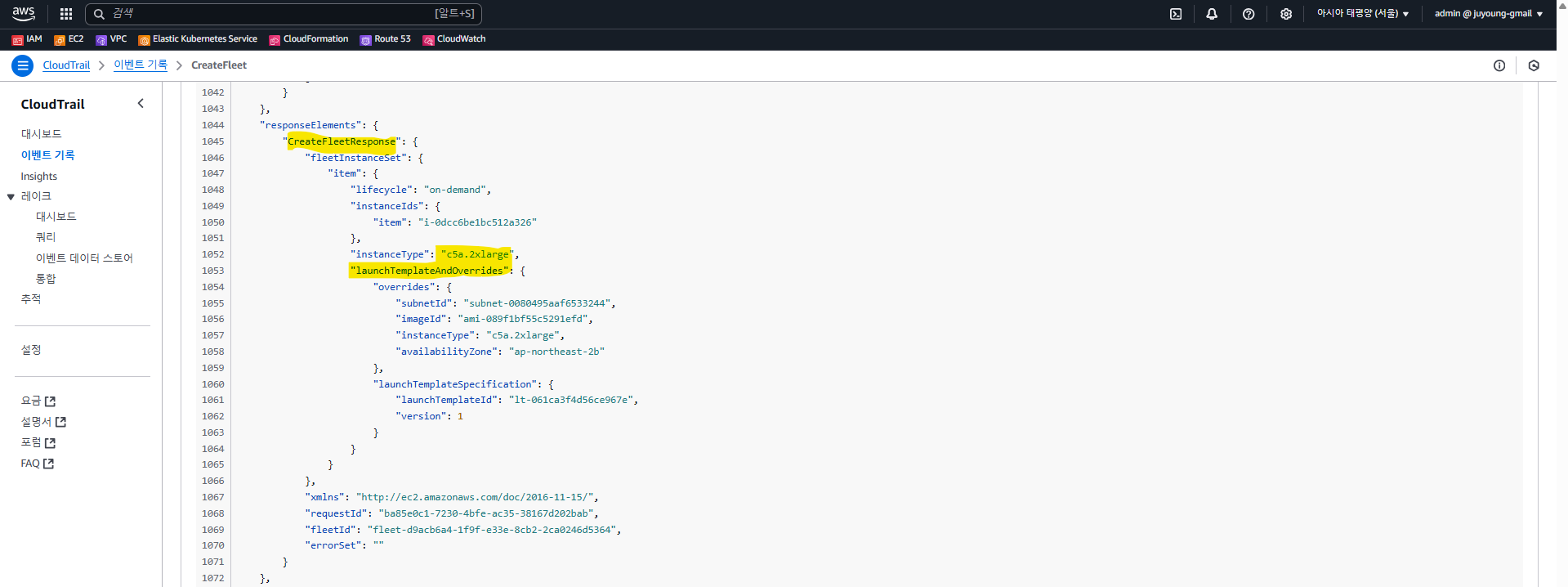
-
Karpenter로 배포한 노드 tag 정보
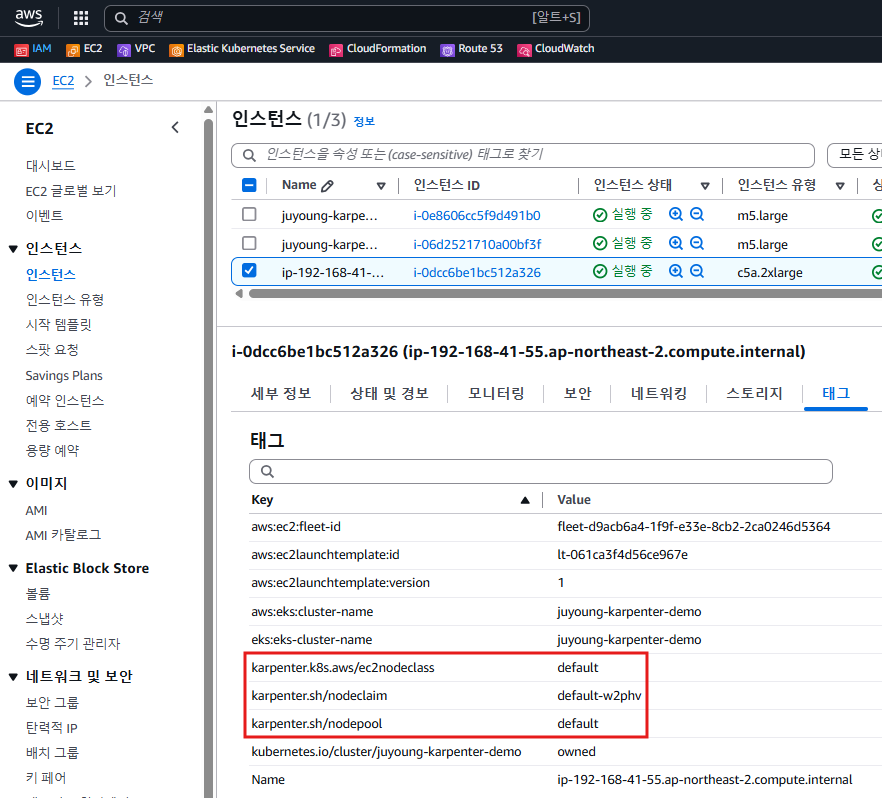
-
Prometheus 메트릭

-
Grafana
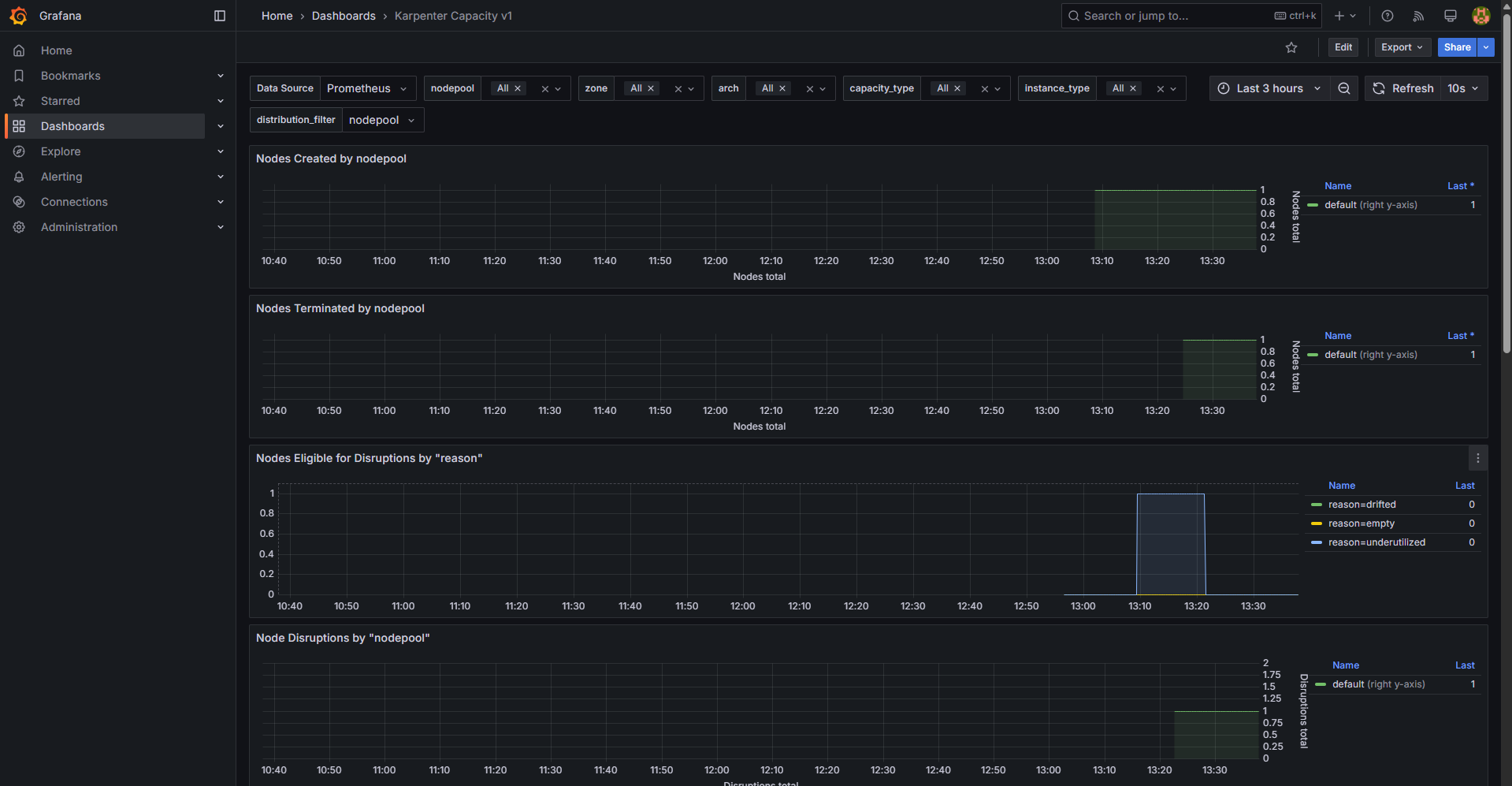
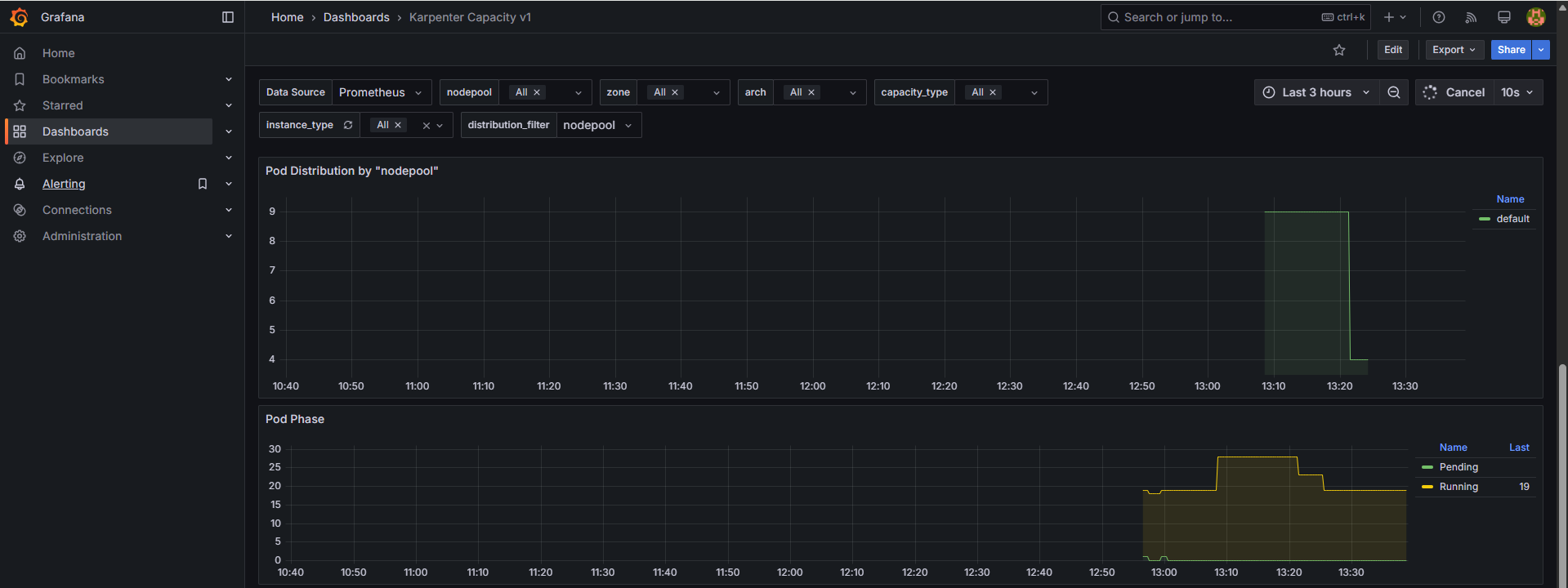
10.2 노드 자동 축소 테스트 (Scale Down)
# Now, delete the deployment. After a short amount of time, Karpenter should terminate the empty nodes due to consolidation.
kubectl delete deployment inflate && date
# 출력 로그 분석해보자!
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
...
{
"level": "INFO",
"time": "2025-03-02T06:53:28.780Z",
"logger": "controller",
"message": "disrupting nodeclaim(s) via delete, terminating 1 nodes (1 pods) ip-192-168-131-97.ap-northeast-2.compute.internal/c5a.large/on-demand",
"commit": "058c665",
"controller": "disruption",
"namespace": "",
"name": "",
"reconcileID": "86a3a45c-2604-4a71-808a-21290301d096",
"command-id": "51914aee-4e09-436f-af6d-794163c3d1c2",
"reason": "underutilized"
}
{
"level": "INFO",
"time": "2025-03-02T06:53:29.532Z",
"logger": "controller",
"message": "tainted node",
"commit": "058c665",
"controller": "node.termination",
"controllerGroup": "",
"controllerKind": "Node",
"Node": {
"name": "ip-192-168-131-97.ap-northeast-2.compute.internal"
},
"namespace": "",
"name": "ip-192-168-131-97.ap-northeast-2.compute.internal",
"reconcileID": "617bcb4d-5498-44d9-ba1e-6c8b7d97c405",
"taint.Key": "karpenter.sh/disrupted",
"taint.Value": "",
"taint.Effect": "NoSchedule"
}
{
"level": "INFO",
"time": "2025-03-02T06:54:03.234Z",
"logger": "controller",
"message": "deleted node",
"commit": "058c665",
"controller": "node.termination",
"controllerGroup": "",
"controllerKind": "Node",
"Node": {
"name": "ip-192-168-131-97.ap-northeast-2.compute.internal"
},
"namespace": "",
"name": "ip-192-168-131-97.ap-northeast-2.compute.internal",
"reconcileID": "8c71fb19-b7ae-4037-afef-fbf1c7343f84"
}
{
"level": "INFO",
"time": "2025-03-02T06:54:03.488Z",
"logger": "controller",
"message": "deleted nodeclaim",
"commit": "058c665",
"controller": "nodeclaim.lifecycle",
"controllerGroup": "karpenter.sh",
"controllerKind": "NodeClaim",
"NodeClaim": {
"name": "default-mfkgp"
},
"namespace": "",
"name": "default-mfkgp",
"reconcileID": "757b4d88-2bf2-412c-bf83-3149f9517d85",
"Node": {
"name": "ip-192-168-131-97.ap-northeast-2.compute.internal"
},
"provider-id": "aws:///ap-northeast-2a/i-00f22c8bde3faf646"
}
{
"level": "INFO",
"time": "2025-03-02T07:25:55.661Z",
"logger": "controller",
"message": "disrupting nodeclaim(s) via delete, terminating 1 nodes (0 pods) ip-192-168-176-171.ap-northeast-2.compute.internal/c5a.2xlarge/on-demand",
"commit": "058c665",
"controller": "disruption",
"namespace": "",
"name": "",
"reconcileID": "0942417e-7ecb-437a-85db-adc553ccade9",
"command-id": "b2b7c689-91ca-43c5-ac1c-2052bf7418c1",
"reason": "empty"
}
{
"level": "INFO",
"time": "2025-03-02T07:25:56.783Z",
"logger": "controller",
"message": "tainted node",
"commit": "058c665",
"controller": "node.termination",
"controllerGroup": "",
"controllerKind": "Node",
"Node": {
"name": "ip-192-168-176-171.ap-northeast-2.compute.internal"
},
"namespace": "",
"name": "ip-192-168-176-171.ap-northeast-2.compute.internal",
"reconcileID": "6254e6be-2445-4402-b829-0bb75fa540e0",
"taint.Key": "karpenter.sh/disrupted",
"taint.Value": "",
"taint.Effect": "NoSchedule"
}
{
"level": "INFO",
"time": "2025-03-02T07:26:49.195Z",
"logger": "controller",
"message": "deleted node",
"commit": "058c665",
"controller": "node.termination",
"controllerGroup": "",
"controllerKind": "Node",
"Node": {
"name": "ip-192-168-176-171.ap-northeast-2.compute.internal"
},
"namespace": "",
"name": "ip-192-168-176-171.ap-northeast-2.compute.internal",
"reconcileID": "6c126a63-8bfa-4828-8ef6-5d22b8c1e7cc"
}
#
kubectl get nodeclaims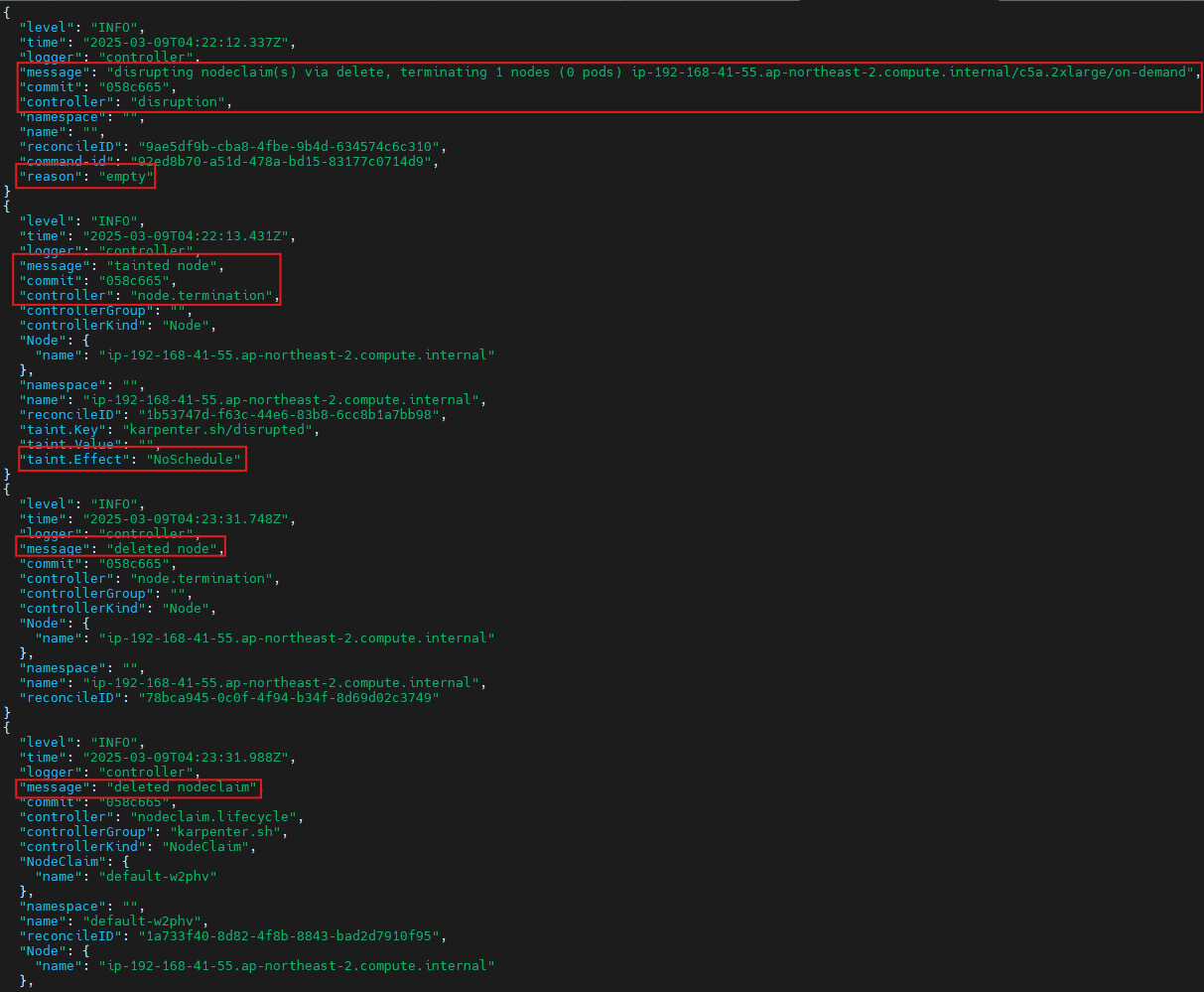

-
CloudTrail 이벤트 확인

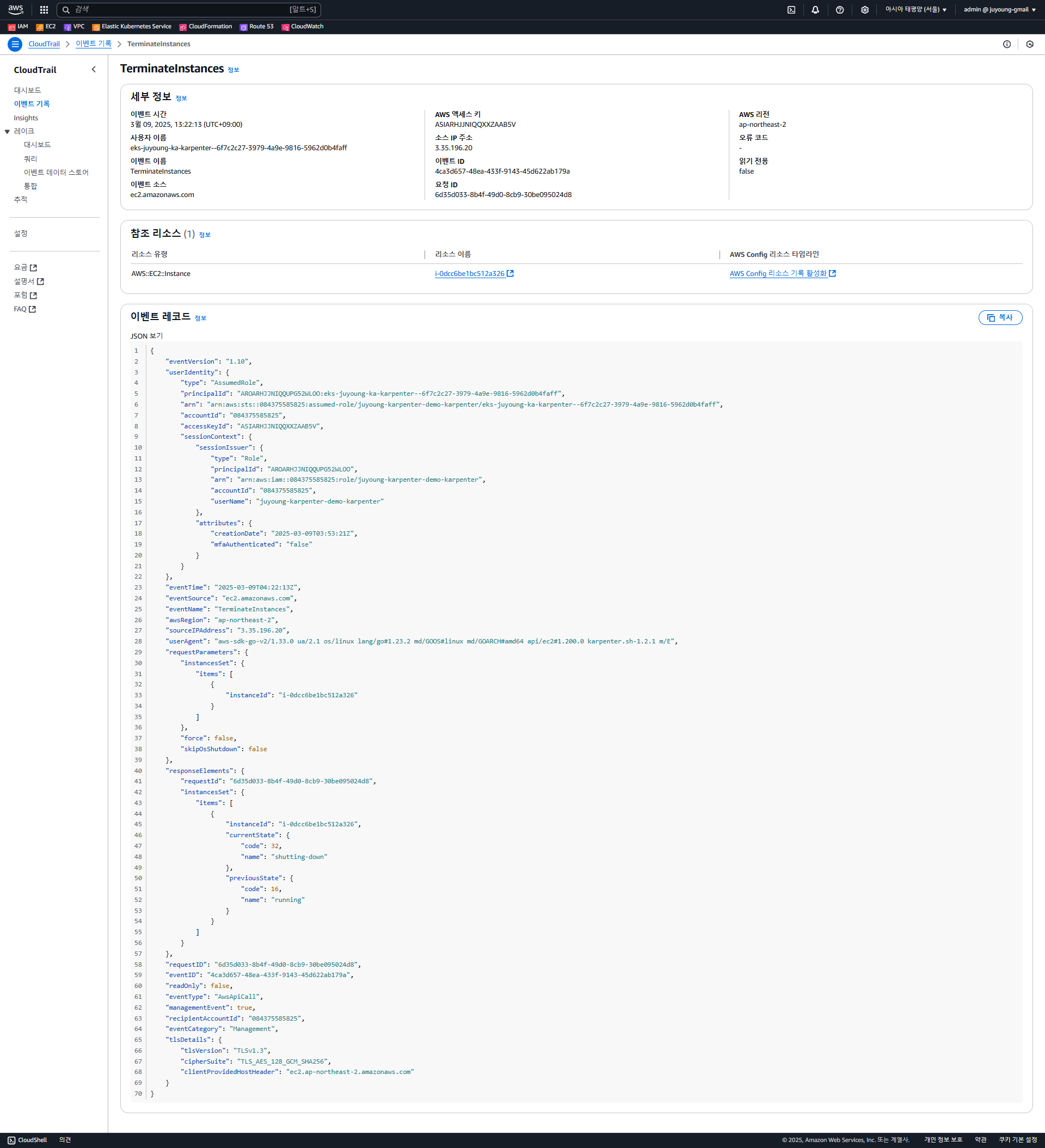
-
Grafana
11. Disruption (구 Consolidation)
11.1 개요
Karpenter의 Disruption(구 Consolidation) 기능은 클러스터의 컴퓨팅 자원을 최적화하는 중요한 기능으로, 비용 효율성을 극대화하면서 인프라의 가용성을 유지하는 역할을 합니다. 주요 개념으로 Expiration(만료), Drift(드리프트), Consolidation(통합)이 포함됩니다.
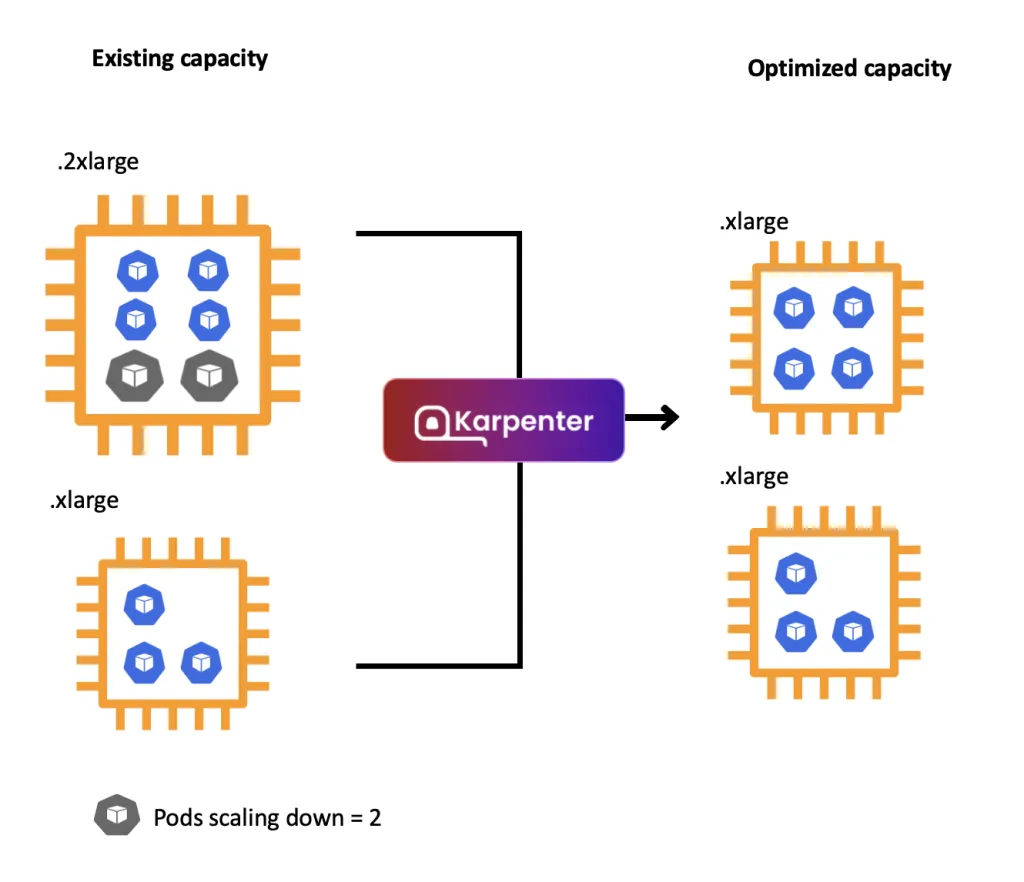
- Expiration(만료): 기본적으로 720시간(30일) 후 인스턴스를 자동으로 만료시켜 최신 상태를 유지합니다.
- Drift(드리프트): NodePool 및 EC2NodeClass의 구성 변경 사항을 감지하여 필요한 변경 사항을 적용합니다.
- Consolidation(통합): 비용 효율성을 극대화하기 위해 리소스 사용률이 낮은 인스턴스를 더 적은 개수로 통합합니다.
관련 자료:
11.2 Spot-to-Spot Consolidation
Spot 인스턴스를 사용할 때 일반적인 온디맨드(주문형) 통합 방식과는 다른 접근 방식이 필요합니다.
- 온디맨드 통합: 규모 조정 및 최저 가격을 주요 지표로 사용하여 최적화합니다.
- 스팟 간 통합: Karpenter가 최소 15개 이상의 다양한 인스턴스 유형을 포함한 인스턴스 구성을 필요로 하며, 가용성이 낮고 중단 빈도가 높은 인스턴스를 선택하지 않도록 설계됩니다.
Karpenter는 AWS EC2 Fleet Instance API를 호출하여 적절한 노드 풀(NodePool) 구성에 맞는 인스턴스 유형을 선택합니다.
- EC2 Fleet Instance API는 시작된 인스턴스 목록과 시작할 수 없는 인스턴스 목록을 즉시 반환합니다.
- 시작할 수 없는 경우 Karpenter는 대체 용량을 요청하거나 soft 일정 제약 조건을 제거할 수 있습니다.
11.3 Karpenter NodePool 및 EC2NodeClass 생성
Karpenter를 사용하여 NodePool 및 EC2NodeClass를 생성할 수 있습니다.
# 기존 NodePool 삭제
kubectl delete nodepool,ec2nodeclass default
# 모니터링
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
eks-node-viewer --resources cpu,memory --node-selector "karpenter.sh/registered=true" --extra-labels eks-node-viewer/node-age
watch -d "kubectl get nodes -L karpenter.sh/nodepool -L node.kubernetes.io/instance-type -L karpenter.sh/capacity-type"
# NodePool 및 EC2NodeClass 생성
cat <<EOF | envsubst | kubectl apply -f -
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: default
requirements:
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["c", "m", "r"]
- key: karpenter.k8s.aws/instance-size
operator: NotIn
values: ["nano","micro","small","medium"]
- key: karpenter.k8s.aws/instance-hypervisor
operator: In
values: ["nitro"]
expireAfter: 1h # nodes are terminated automatically after 1 hour
limits:
cpu: "1000"
memory: 1000Gi
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized # policy enables Karpenter to replace nodes when they are either empty or underutilized
consolidateAfter: 1m
---
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
role: "KarpenterNodeRole-${CLUSTER_NAME}" # replace with your cluster name
amiSelectorTerms:
- alias: "al2023@latest"
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
EOF
# 확인
kubectl get nodepool,ec2nodeclass
# 샘플 워크로드 Deployment 배포
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 5
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
terminationGracePeriodSeconds: 0
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
resources:
requests:
cpu: 1
memory: 1.5Gi
securityContext:
allowPrivilegeEscalation: false
EOF
# 노드 정보 확인
kubectl get nodes -L karpenter.sh/nodepool -L node.kubernetes.io/instance-type -L karpenter.sh/capacity-type
kubectl get nodeclaims
kubectl describe nodeclaims
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
kubectl logs -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | grep 'launched nodeclaim' | jq '.'
# 확장 테스트
# Scale the inflate workload from 5 to 12 replicas, triggering Karpenter to provision additional capacity
kubectl scale deployment/inflate --replicas 12
# This changes the total memory request for this deployment to around 12Gi,
# which when adjusted to account for the roughly 600Mi reserved for the kubelet on each node means that this will fit on 2 instances of type m5.large:
kubectl get nodeclaims
# 축소 테스트
# Scale down the workload back down to 5 replicas
kubectl scale deployment/inflate --replicas 5
kubectl get nodeclaims
NAME TYPE CAPACITY ZONE NODE READY AGE
default-ffnzp c6g.2xlarge on-demand ap-northeast-2c ip-192-168-185-240.ap-northeast-2.compute.internal True 14m
# Karpenter 로그 확인
# We can check the Karpenter logs to get an idea of what actions it took in response to our scaling in the deployment. Wait about 5-10 seconds before running the following command:
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
{
"level": "INFO",
"time": "2025-03-02T08:19:13.969Z",
"logger": "controller",
"message": "disrupting nodeclaim(s) via delete, terminating 1 nodes (5 pods) ip-192-168-132-48.ap-northeast-2.compute.internal/c6g.2xlarge/on-demand",
"commit": "058c665",
"controller": "disruption",
"namespace": "",
"name": "",
"reconcileID": "a900df38-7189-42aa-a3b3-9fcaf944dcf4",
"command-id": "4b7ef3a5-6962-48a9-bd38-c9898580bb75",
"reason": "underutilized"
}
# Karpenter can also further consolidate if a node can be replaced with a cheaper variant in response to workload changes.
# This can be demonstrated by scaling the inflate deployment replicas down to 1, with a total memory request of around 1Gi:
kubectl scale deployment/inflate --replicas 1
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
{
"level": "INFO",
"time": "2025-03-02T08:23:59.683Z",
"logger": "controller",
"message": "disrupting nodeclaim(s) via replace, terminating 1 nodes (1 pods) ip-192-168-185-240.ap-northeast-2.compute.internal/c6g.2xlarge/on-demand and replacing with on-demand node from types c6g.large, c7g.large, c5a.large, c6gd.large, m6g.large and 55 other(s)",
"commit": "058c665",
"controller": "disruption",
"namespace": "",
"name": "",
"reconcileID": "6669c544-e065-4c97-b594-ec1fb68b68b5",
"command-id": "b115c17f-3e29-48bc-8da8-d7073f189624",
"reason": "underutilized"
}
kubectl get nodeclaims
NAME TYPE CAPACITY ZONE NODE READY AGE
default-ff7xn c6g.large on-demand ap-northeast-2b ip-192-168-109-5.ap-northeast-2.compute.internal True 78s
default-ffnzp c6g.2xlarge on-demand ap-northeast-2c ip-192-168-185-240.ap-northeast-2.compute.internal True 16m
kubectl get nodeclaims
NAME TYPE CAPACITY ZONE NODE READY AGE
default-ff7xn c6g.large on-demand ap-northeast-2b ip-192-168-109-5.ap-northeast-2.compute.internal True 3m3s
# 삭제
kubectl delete deployment inflate
kubectl delete nodepool,ec2nodeclass default-
NodePool 및 EC2NodeClass 생성, 확인
-
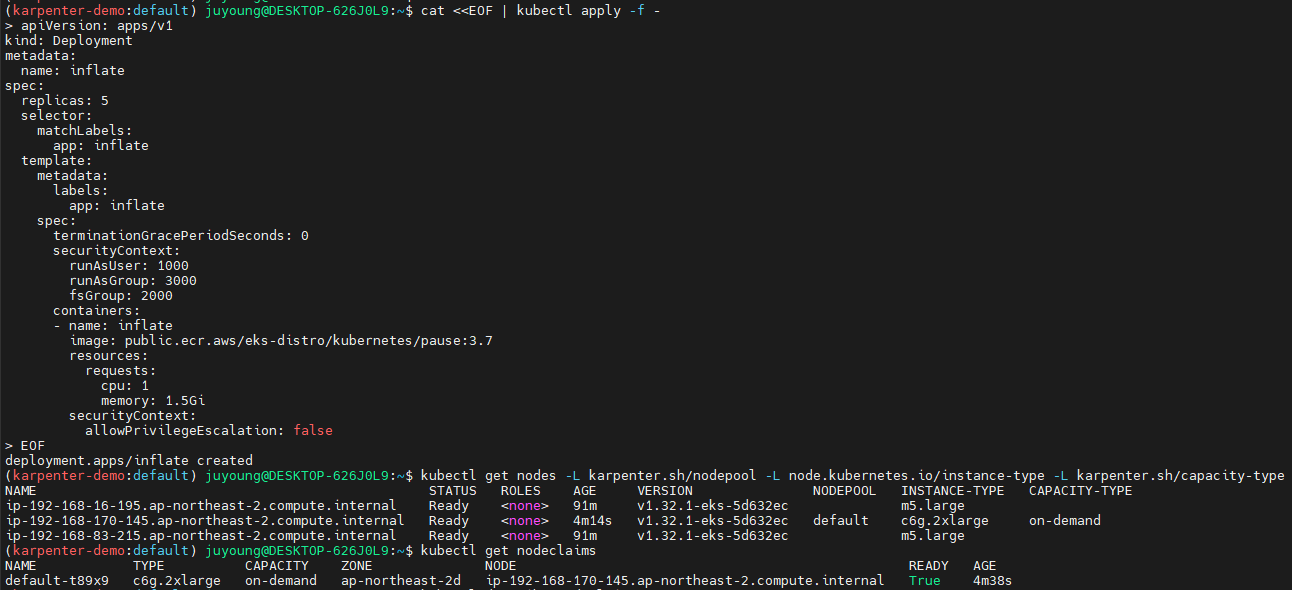
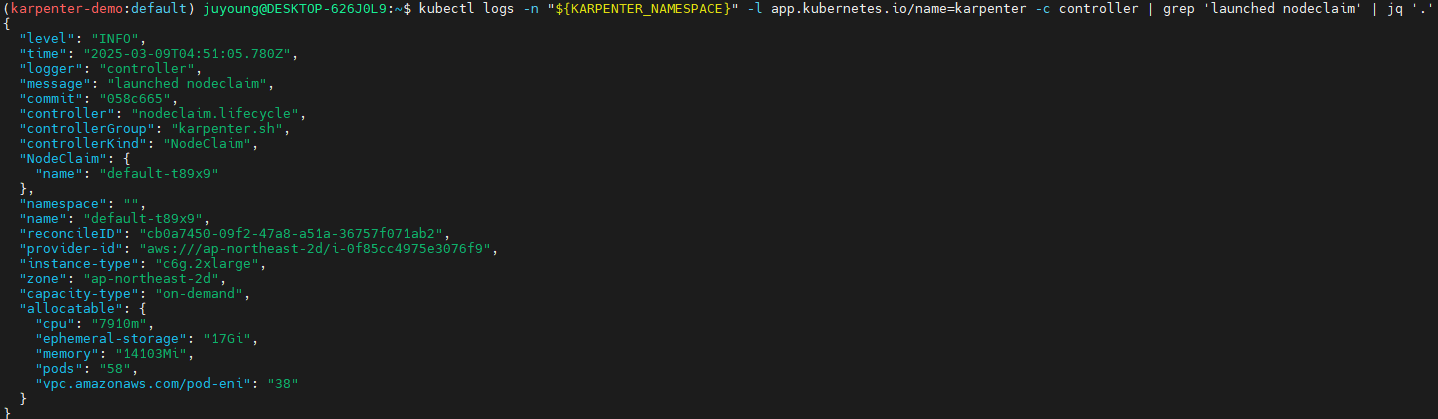
Deployment 배포 및 노드, 로그 정보 확인
-
확장 테스트: replicas 5 → 12 ⇒ 노드 1개 추가(c6g.2xlarge)




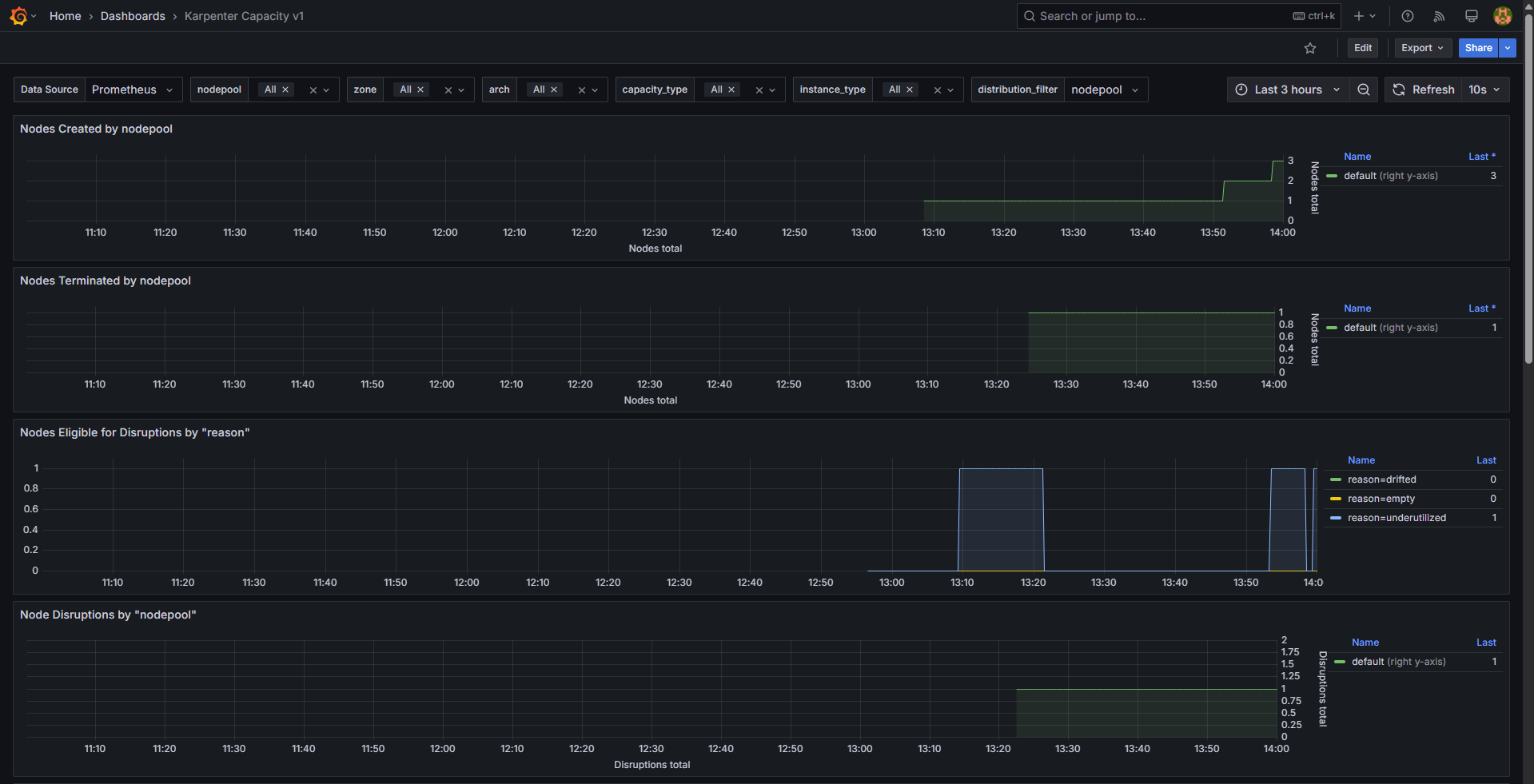
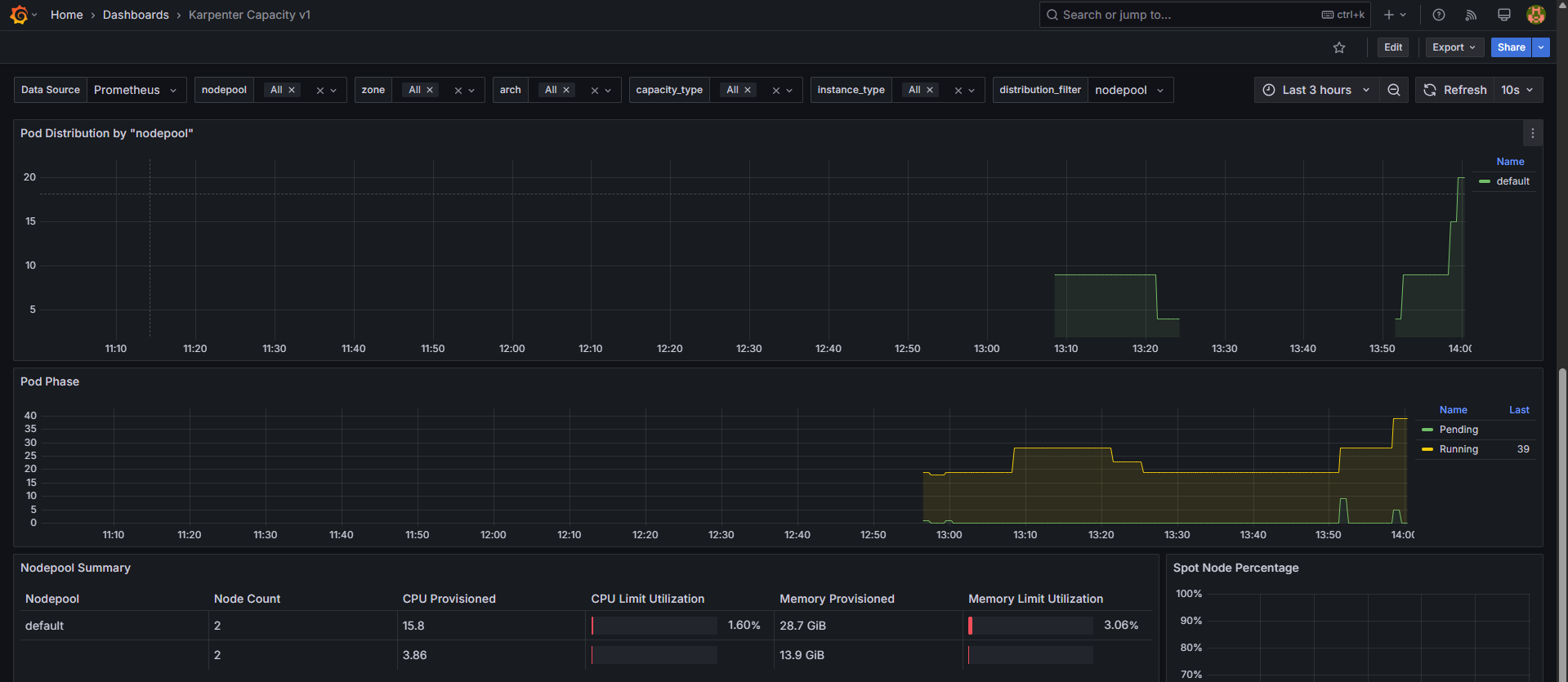
-
축소 테스트 1: replicas 12 → 5 ⇒ 노드 1개 삭제(c6g.2xlarge)





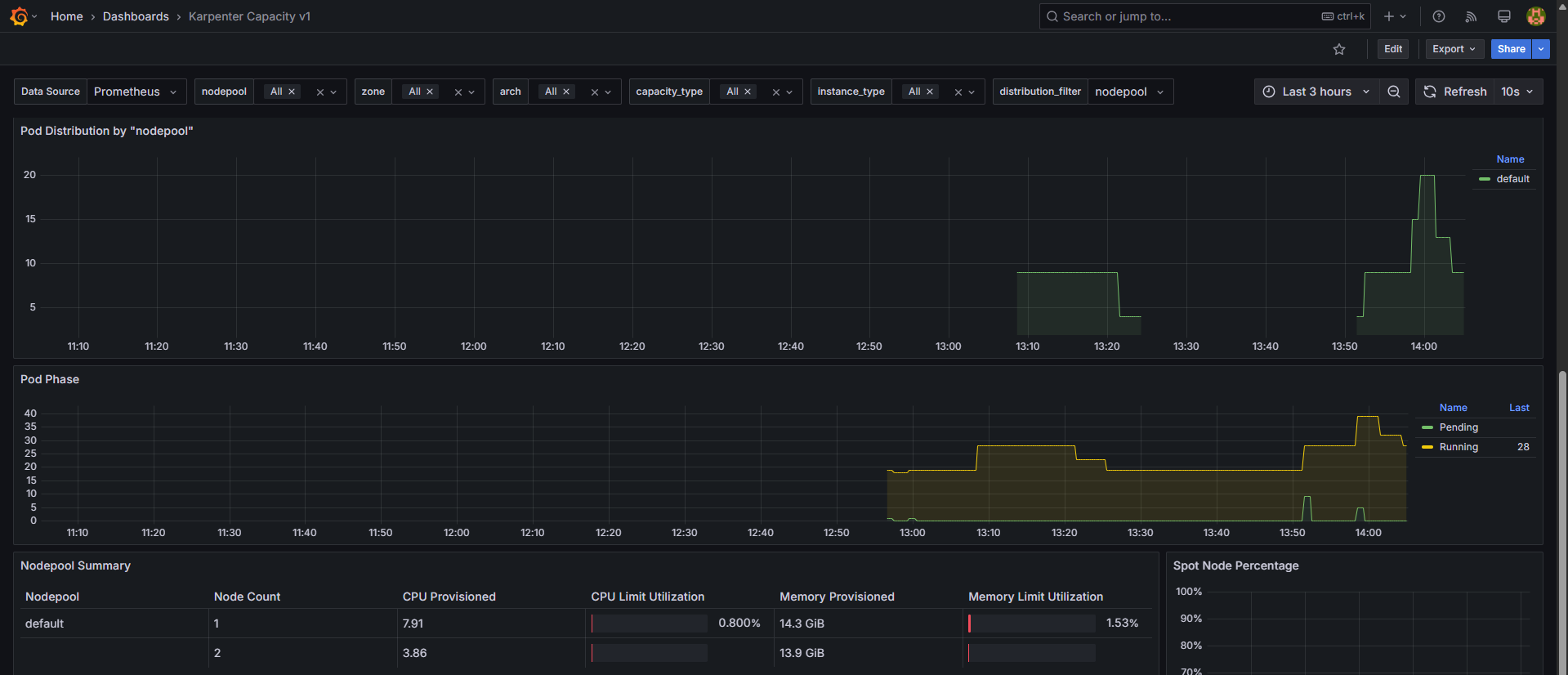
-
축소 테스트 2: replicas 5 → 1 ⇒ 노드 1개 변경(c6g.2xlarge → c6g.large)




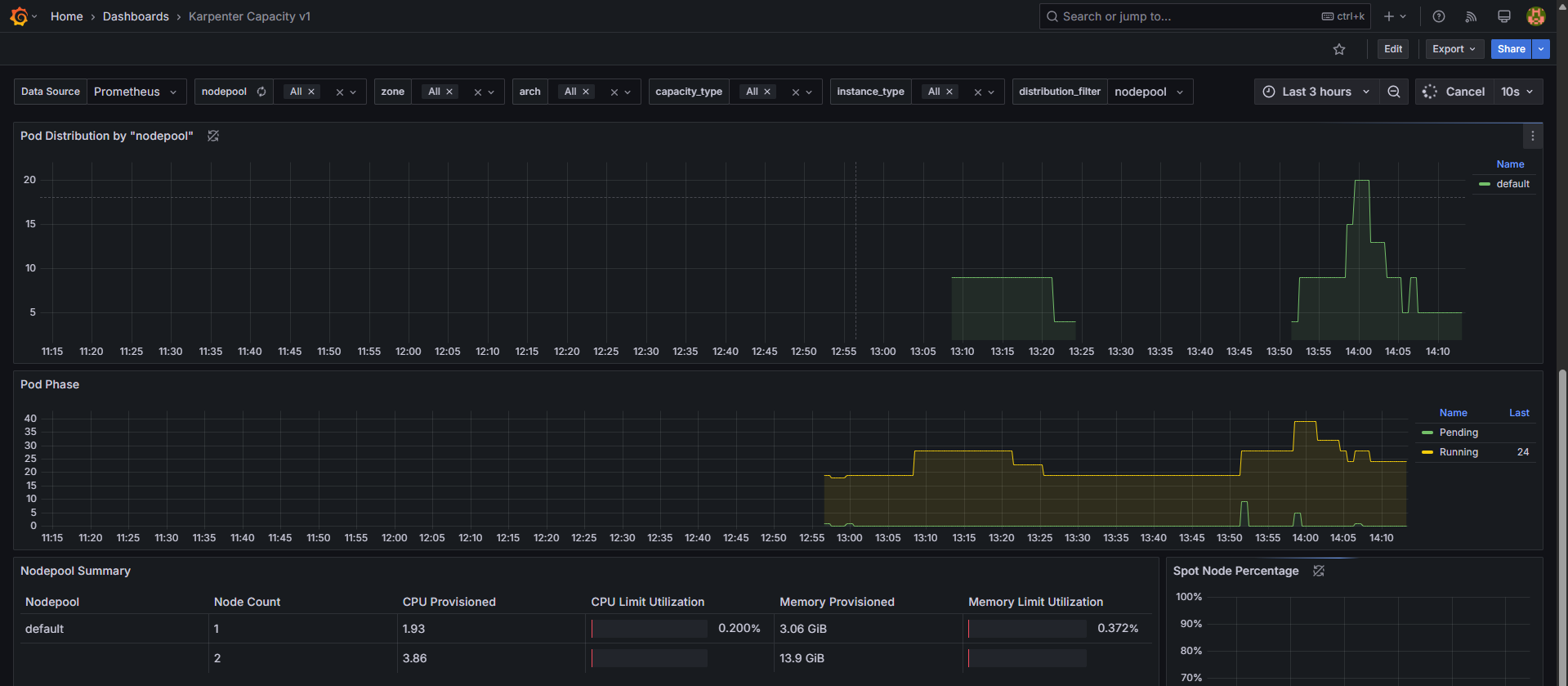
11.4 Spot-to-Spot Consolidation 실습
Spot-to-Spot Consolidation을 활성화하여 실습을 진행할 수 있습니다.
# 모니터링
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
eks-node-viewer --resources cpu,memory --node-selector "karpenter.sh/registered=true"
# Create a Karpenter NodePool and EC2NodeClass
cat <<EOF | envsubst | kubectl apply -f -
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: default
requirements:
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.sh/capacity-type
operator: In
values: ["spot"]
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["c", "m", "r"]
- key: karpenter.k8s.aws/instance-size
operator: NotIn
values: ["nano","micro","small","medium"]
- key: karpenter.k8s.aws/instance-hypervisor
operator: In
values: ["nitro"]
expireAfter: 1h # nodes are terminated automatically after 1 hour
limits:
cpu: "1000"
memory: 1000Gi
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized # policy enables Karpenter to replace nodes when they are either empty or underutilized
consolidateAfter: 1m
---
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
role: "KarpenterNodeRole-${CLUSTER_NAME}" # replace with your cluster name
amiSelectorTerms:
- alias: "bottlerocket@latest"
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
EOF
# 확인
kubectl get nodepool,ec2nodeclass
# Deploy a sample workload
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 5
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
terminationGracePeriodSeconds: 0
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
resources:
requests:
cpu: 1
memory: 1.5Gi
securityContext:
allowPrivilegeEscalation: false
EOF
#
kubectl get nodes -L karpenter.sh/nodepool -L node.kubernetes.io/instance-type -L karpenter.sh/capacity-type
kubectl get nodeclaims
kubectl describe nodeclaims
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
kubectl logs -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | grep 'launched nodeclaim' | jq '.'
# Scale the inflate workload from 5 to 12 replicas, triggering Karpenter to provision additional capacity
kubectl scale deployment/inflate --replicas 12
# This changes the total memory request for this deployment to around 12Gi,
# which when adjusted to account for the roughly 600Mi reserved for the kubelet on each node means that this will fit on 2 instances of type m5.large:
kubectl get nodeclaims
# Scale down the workload back down to 5 replicas
kubectl scale deployment/inflate --replicas 5
kubectl get nodeclaims
# We can check the Karpenter logs to get an idea of what actions it took in response to our scaling in the deployment. Wait about 5-10 seconds before running the following command:
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
# Karpenter can also further consolidate if a node can be replaced with a cheaper variant in response to workload changes.
# This can be demonstrated by scaling the inflate deployment replicas down to 1, with a total memory request of around 1Gi:
kubectl scale deployment/inflate --replicas 1
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
kubectl get nodeclaims
# 삭제
kubectl delete deployment inflate
kubectl delete nodepool,ec2nodeclass default-
테스트 전

-
NodePool 및 EC2NodeClass 생성, 확인
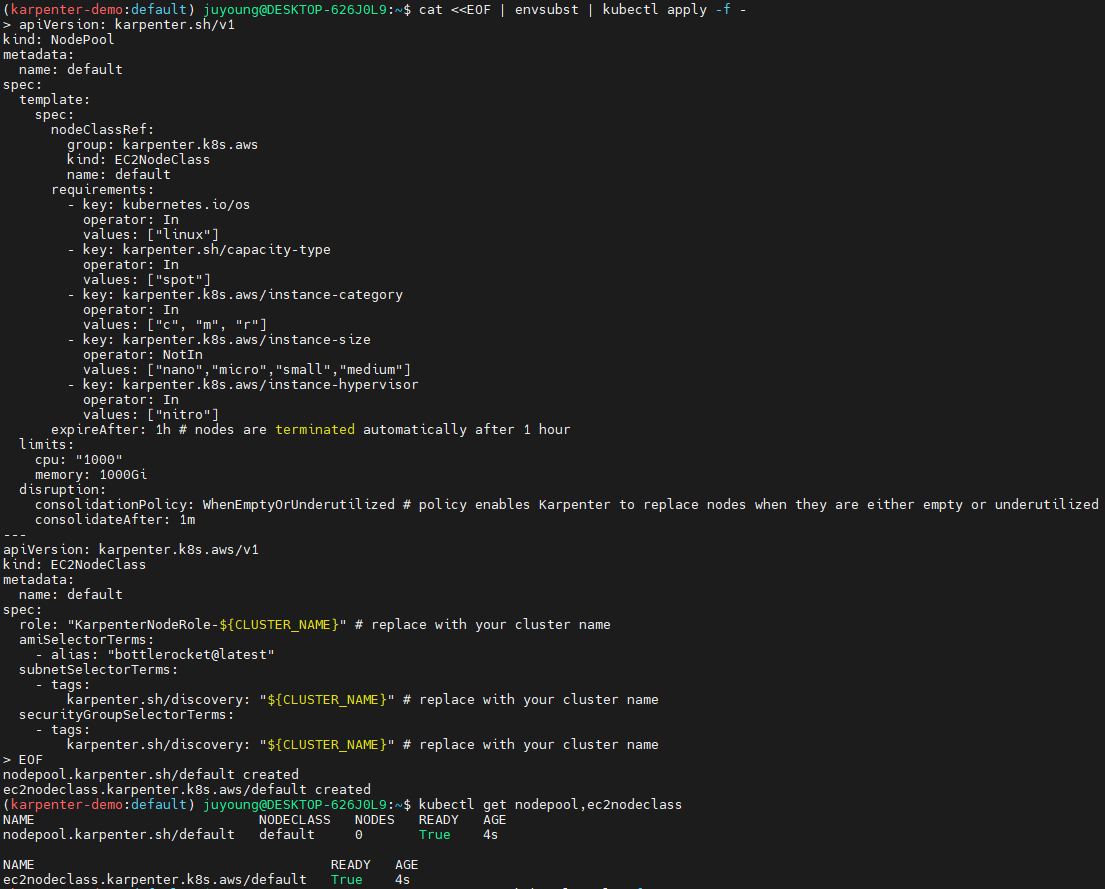
-
Deployment 배포 및 확인
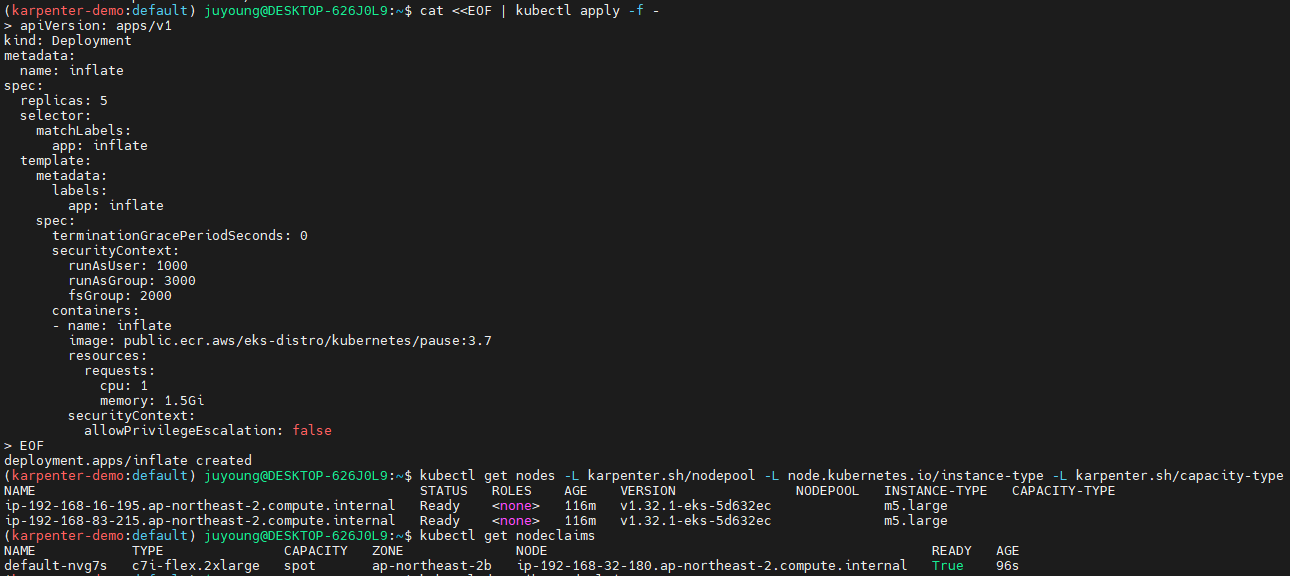
-
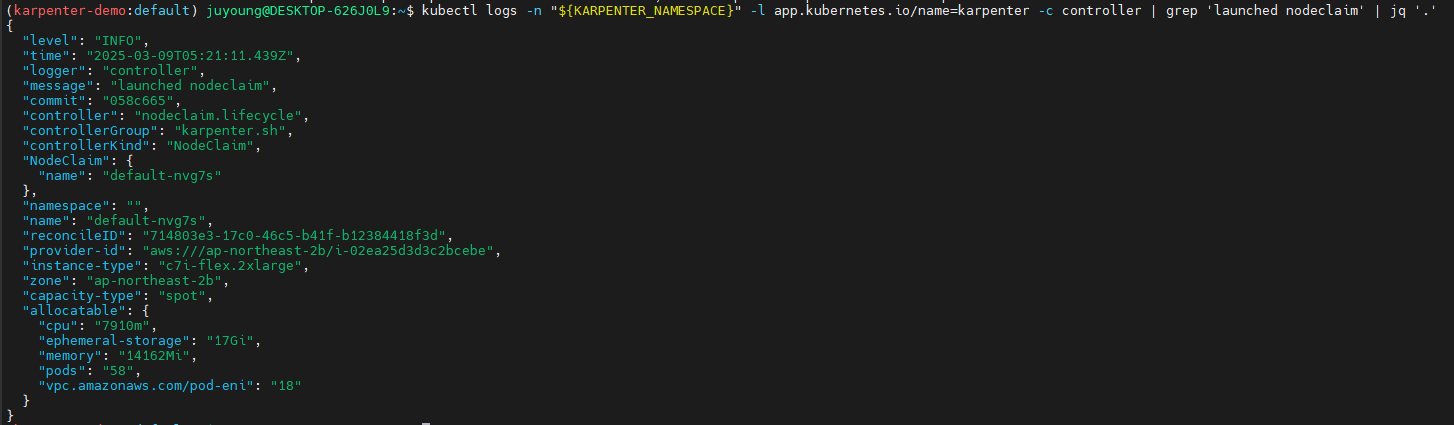
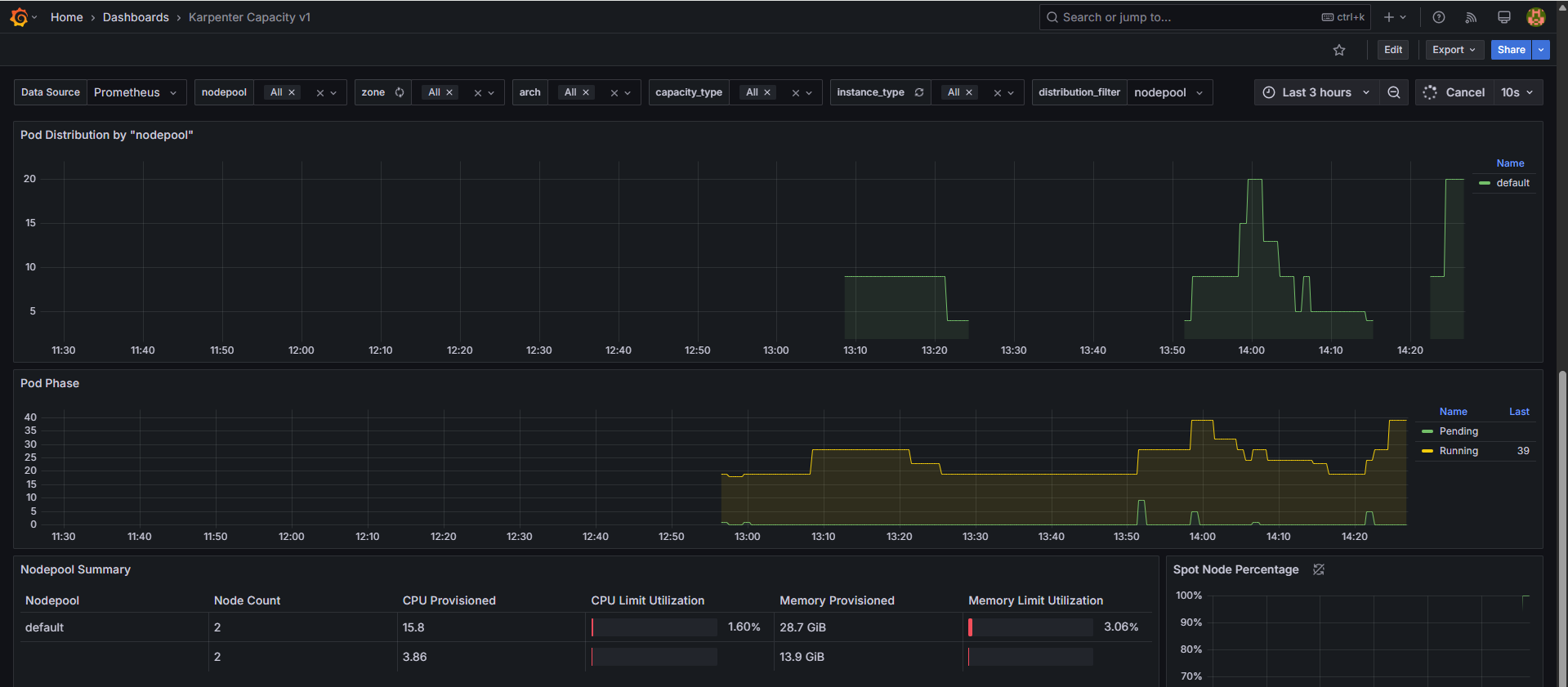
확장 테스트: replicas 5 → 12 ⇒ 노드 1개 추가(
instance-type: c7i-flex.2xlarge,capacity-type: spot)



-
축소 테스트 1: replicas 12 → 5 ⇒ 노드 1개 삭제(
instance-type: c7i-flex.2xlarge,capacity-type: spot)




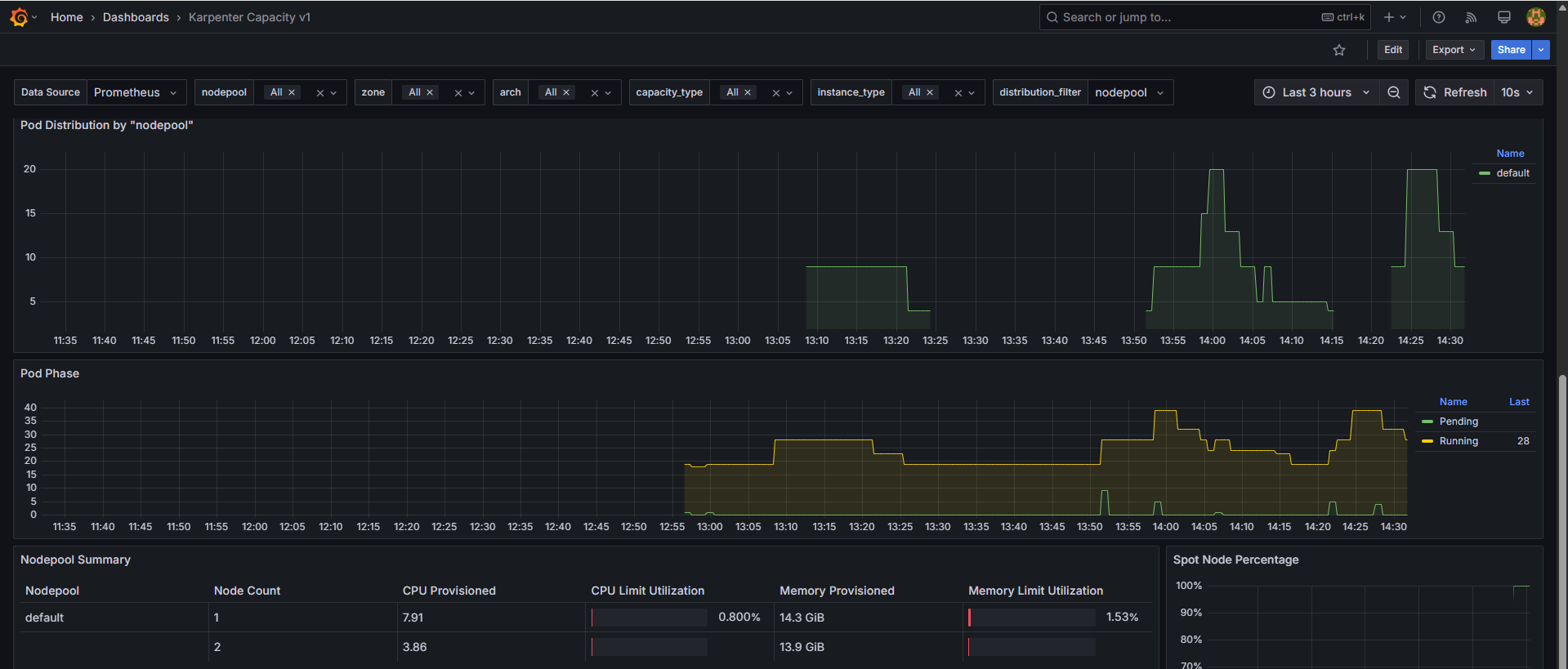
-
축소 테스트 2: replicas 5 → 1 ⇒ 노드 1개 변경(
instance-type:c7i-flex.2xlarge→ 변동 X)



12. 실습 리소스 삭제
# Karpenter helm 삭제
helm uninstall karpenter --namespace "${KARPENTER_NAMESPACE}"
# Karpenter IAM Role 등 생성한 CloudFormation 삭제
aws cloudformation delete-stack --stack-name "Karpenter-${CLUSTER_NAME}"
# EC2 Launch Template 삭제
aws ec2 describe-launch-templates --filters "Name=tag:karpenter.k8s.aws/cluster,Values=${CLUSTER_NAME}" |
jq -r ".LaunchTemplates[].LaunchTemplateName" |
xargs -I{} aws ec2 delete-launch-template --launch-template-name {}
# 클러스터 삭제
eksctl delete cluster --name "${CLUSTER_NAME}"클러스터 삭제 이후에도, Karpenter IAM Role 생성한 CloudFormation 삭제가 잘 안될 경우 AWS CloudFormation 관리 콘솔에서 직접 삭제한다.
