[AWS EKS] EKS Observability 3 - EKS 콘솔 및 로깅, CloudWatch, Metrics-server & kwatch
AWS EKS Workshop Study 3기
이 글은 CloudNet@팀의 AWS EKS Workshop Study(AEWS) 3기 스터디 내용을 바탕으로 작성되었습니다.
AEWS는 CloudNet@의 '가시다'님께서 진행하는 스터디로, EKS를 학습하는 과정입니다.
EKS를 깊이 있게 이해할 기회를 주시고, 소중한 지식을 나눠주시는 가시다님께 다시 한번 감사드립니다.
이 글이 EKS를 학습하는 분들께 도움이 되길 바랍니다.
1. Amazon EKS Console 개요 및 주요 기능
1.1 개요
Amazon EKS는 AWS에서 관리하는 Kubernetes 클러스터로, 사용자는 EKS 콘솔을 통해 클러스터 상태를 모니터링하고 다양한 Kubernetes 리소스를 관리할 수 있습니다.
EKS 콘솔에서는 Pods, ReplicaSets, Deployments, Nodes, Services, ConfigMaps, Secrets 등의 리소스를 직접 확인할 수 있으며, IAM 권한을 활용하여 접근을 제어할 수 있습니다.
🔹 주요 기능
- Kubernetes API 기반 리소스 조회
- IAM 권한을 통한 접근 제어
- EKS 클러스터의 상태 및 설정 관리
- 워크로드(Workloads), 네트워크, 스토리지, 인증(Authentication), 보안(Authorization) 정책 확인
- Custom Resource Definitions(CRD) 및 Webhook 설정 지원
📌 관련 공식 문서
1.2 Kubernetes API를 통한 리소스 조회
EKS 콘솔에서는 Kubernetes API를 통해 Pods, Deployments, Services, Nodes, ConfigMaps, Secrets 등의 정보를 조회할 수 있습니다.
이를 통해 클러스터의 상태를 실시간으로 확인하고, 문제를 탐색할 수 있습니다.
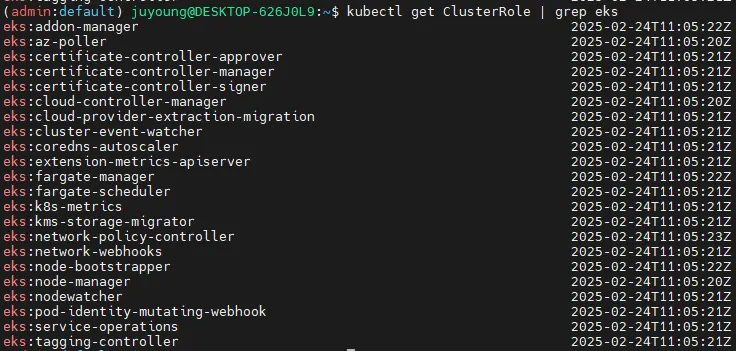
# EKS에서 제공하는 ClusterRole 목록 확인
kubectl get ClusterRole | grep eks예시 출력
eks:addon-manager 2023-05-08T04:22:45Z
eks:az-poller 2023-05-08T04:22:42Z
eks:certificate-controller-approver 2023-05-08T04:22:42Z
...
📌 참고:
EKS 클러스터에 대한 리소스를 조회하려면 적절한 IAM 역할과 권한이 필요합니다.
EKS 클러스터 ARN 예시: arn:aws:eks:ap-northeast-2:911283464785:cluster/myeks
1.3. EKS 콘솔의 주요 메뉴 및 기능
EKS 콘솔에서 제공하는 메뉴와 그 기능을 정리하면 다음과 같습니다.
1. Workloads (워크로드)
- Pods: 네임스페이스 필터링, 구조화된 보기(Structured View) 및 원시 보기(Raw View) 지원
- ReplicaSets, Deployments, DaemonSets 상태 확인 가능
- 관련 문서: EKS Workloads View
2. Cluster (클러스터)
- Nodes: 노드 상태 및 메타데이터 확인
- Taints, Conditions, Labels, Annotations 등 상세 정보 제공
- Namespaces 및 API Services 관리
3. Service and Networking (서비스 및 네트워크)
- Pods as a Service: Pod 간의 네트워크 연결 정보 조회
- Endpoints & Ingresses: 서비스 네트워크 구성 및 엔드포인트 정보
- Load Balancer: Classic Load Balancer(CLB) / Network Load Balancer(NLB) URL 확인 가능
4. Config and Secrets (설정 및 보안 정보)
- ConfigMap & Secrets 관리
- ConfigMap 및 Secret 데이터를 콘솔에서 직접 확인 가능
- 디코드(Decode) 지원을 통해 Base64로 인코딩된 Secret을 읽을 수 있음
5. Storage (스토리지)
- Persistent Volume Claim (PVC): 볼륨의 상태, 주석(Annotations), 이벤트 확인
- Volume Attachments: PVC가 연결된 CSI(Node) 정보 확인 가능
- Storage Classes 및 CSI Drivers 지원
6. Authentication (인증)
- Service Account 정보 확인
- IAM 역할과 add-on 연동 가능
- Service Account와 IAM Role을 매핑하여 특정 Kubernetes 리소스 접근을 제어할 수 있음
7. Authorization (권한 관리)
- Cluster Roles, Roles, ClusterRoleBindings, RoleBindings 조회
- Roles에 적용된 정책 및 규칙 확인 가능
8. Policy (정책)
- Limit Ranges, Resource Quotas 확인 가능
- Network Policies: 특정 네임스페이스나 Pod 간의 네트워크 트래픽 제한 정책 설정
- Pod Disruption Budgets(PDB): Pod의 일정 비율 이상이 중단되지 않도록 보호
- Pod Security Policies(PSP): 보안 정책 설정 가능
- 기본적으로 eks.privileged 정책이 적용됨
9. Extensions (확장 기능)
- Custom Resource Definitions (CRD): Kubernetes에서 확장 리소스 지원
- Webhook Configurations
- Mutating Webhook Configurations: 요청을 변경하는 Webhook 설정
- Validating Webhook Configurations: 요청을 검증하는 Webhook 설정
2. EKS 로깅(Logging in EKS)
2.1 개요
EKS(Elastic Kubernetes Service)에서는 컨트롤 플레인(Control Plane), 노드(Node), 애플리케이션(Application) 로깅을 통해 클러스터 상태를 모니터링하고 문제를 진단할 수 있습니다.
AWS에서는 CloudWatch Logs를 활용하여 EKS의 로깅 데이터를 관리할 수 있으며, 다양한 로그 유형을 활성화하여 API 요청, 감사 로그, 인증 정보, 스케줄링, 컨트롤러 동작 등을 추적할 수 있습니다.
📌 관련 공식 문서
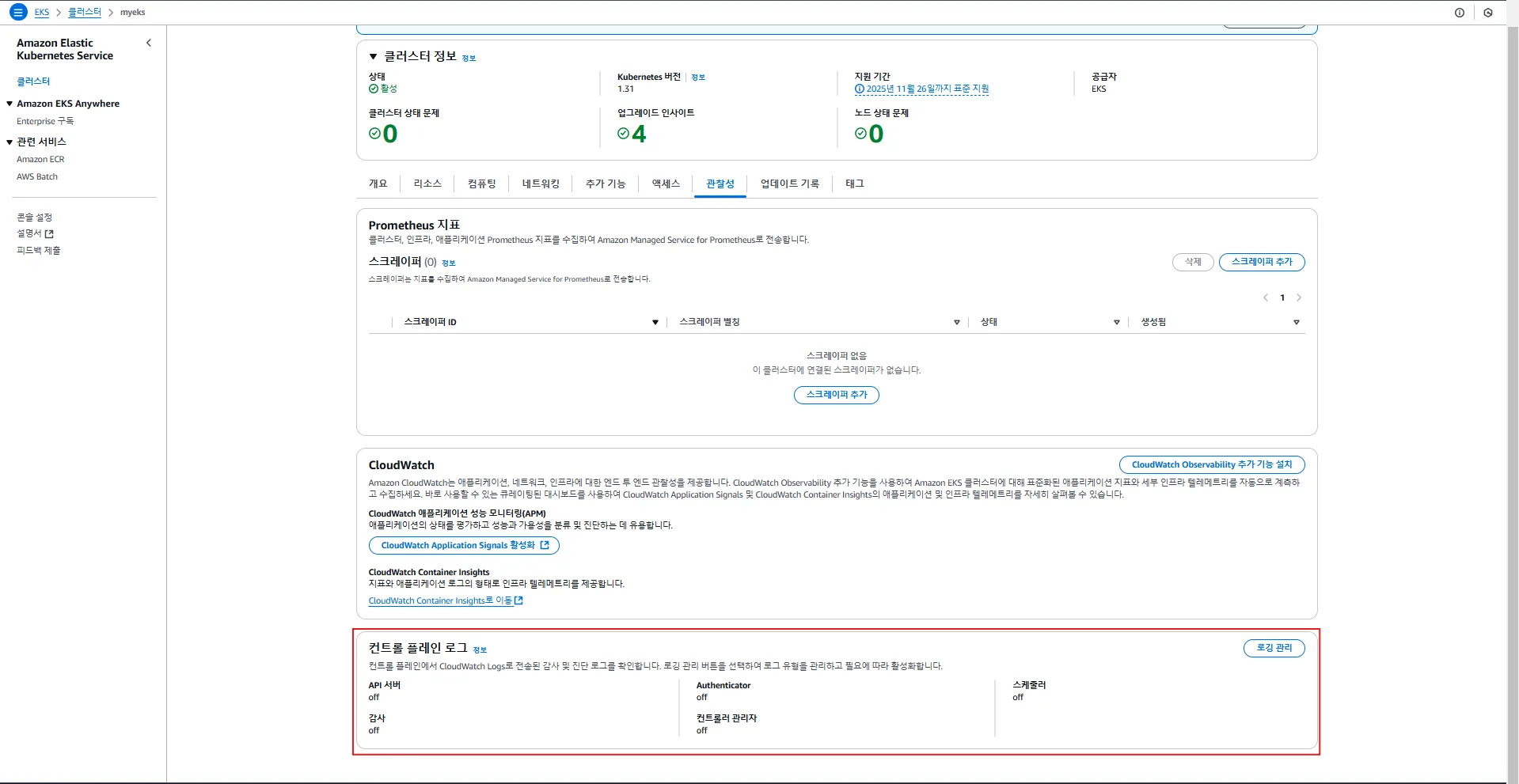
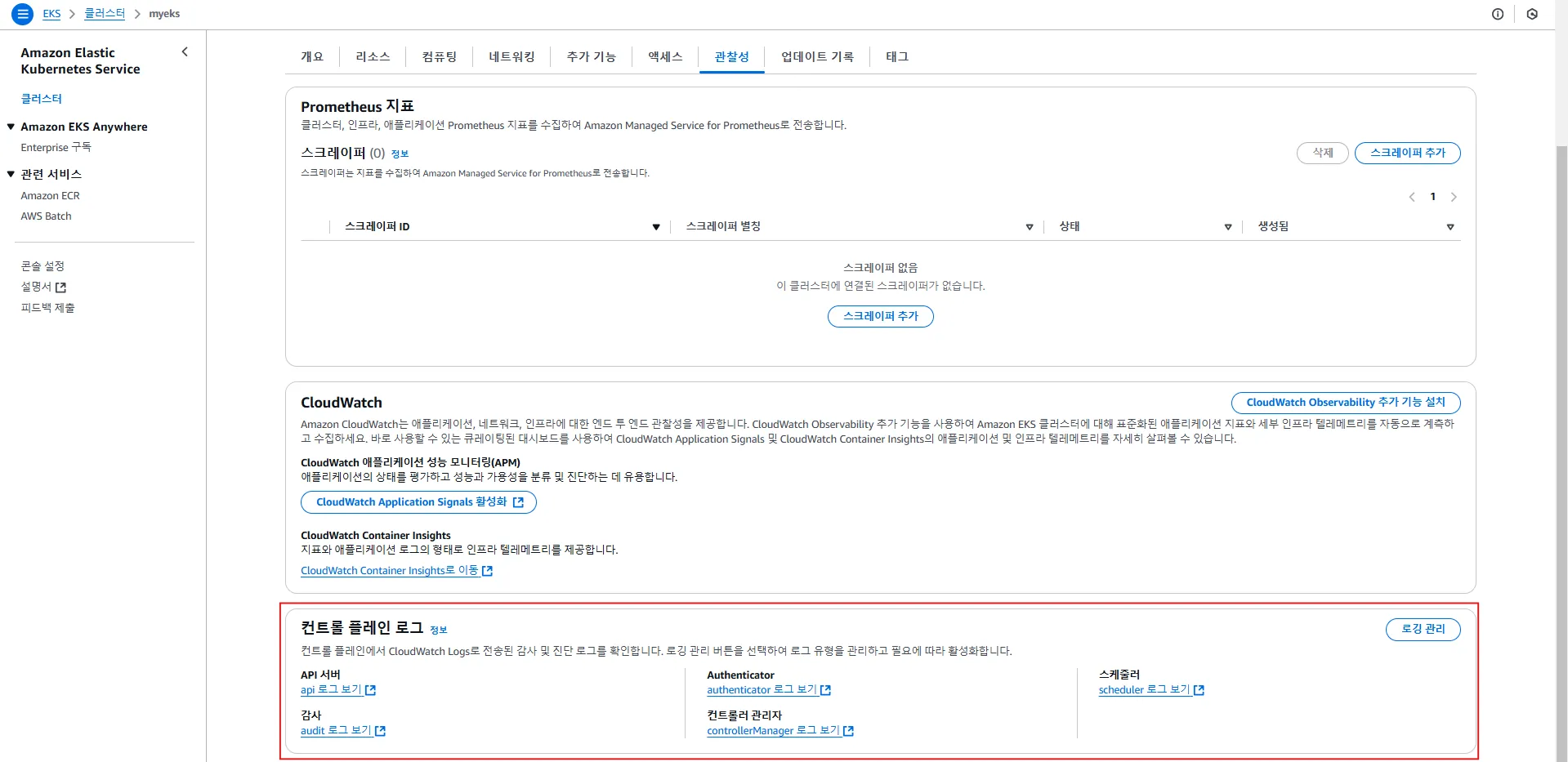
2.2 EKS 컨트롤 플레인 로깅
2.2.1. 컨트롤 플레인 로깅이란?
컨트롤 플레인(Control Plane) 로깅은 EKS 클러스터의 핵심 구성 요소(Kubernetes API 서버, 감사 로그, 인증 로그, 스케줄러 등)의 로그를 수집하는 기능입니다.
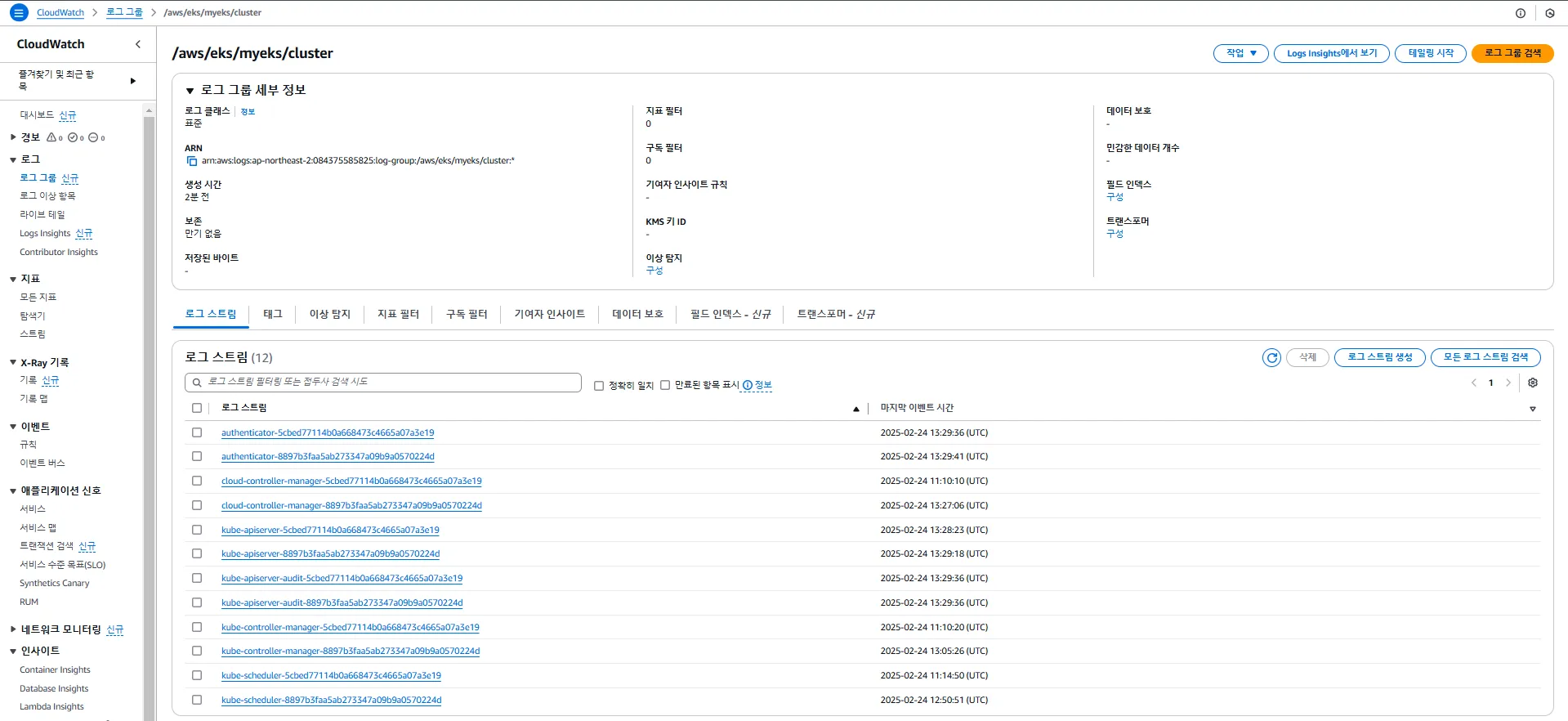
로그는 AWS CloudWatch Logs의 /aws/eks/<cluster-name>/cluster 그룹에 저장됩니다.
📌 참고:
- eksctl을 통해 배포된 클러스터는 기본적으로 모든 로깅이 비활성화되어 있음
- Terraform으로 배포된 경우, 기본적으로 API 서버, Audit, Authenticator 로그가 활성화될 가능성이 높음
2.2 EKS 컨트롤 플레인 로깅
2.2.1 컨트롤 플레인 로깅이란?
컨트롤 플레인(Control Plane) 로깅은 EKS 클러스터의 핵심 구성 요소(Kubernetes API 서버, 감사 로그, 인증 로그, 스케줄러 등)의 로그를 수집하는 기능입니다.
로그는 AWS CloudWatch Logs의 /aws/eks/<cluster-name>/cluster 그룹에 저장됩니다.
📌 참고:
- eksctl을 통해 배포된 클러스터는 기본적으로 모든 로깅이 비활성화되어 있음
- Terraform으로 배포된 경우, 기본적으로
API 서버,Audit,Authenticator로그가 활성화될 가능성이 높음
2.2.2 컨트롤 플레인 로그 유형
| 로그 유형 | 설명 | 로그 스트림 예시 |
|---|---|---|
API 서버 (api) | kube-apiserver의 요청 및 응답 로그 | kube-apiserver-<nnn...> |
감사 로그 (audit) | Kubernetes API 요청의 감사를 기록 | kube-apiserver-audit-<nnn...> |
인증 로그 (authenticator) | 클러스터에 대한 인증 요청 로그 | authenticator-<nnn...> |
컨트롤러 매니저 (controllerManager) | 클러스터 컨트롤러 동작 기록 | kube-controller-manager-<nnn...> |
스케줄러 (scheduler) | Kubernetes 스케줄러 관련 로그 | kube-scheduler-<nnn...> |
2.2.3 컨트롤 플레인 로깅 활성화
다음 명령어를 사용하여 컨트롤 플레인 로깅을 활성화할 수 있습니다.
# 모든 로깅 활성화
aws eks update-cluster-config --region ap-northeast-2 --name $CLUSTER_NAME \
--logging '{"clusterLogging":[{"types":["api","audit","authenticator","controllerManager","scheduler"],"enabled":true}]}'📌 설명:
update-cluster-config: EKS 클러스터 설정을 업데이트하는 명령어clusterLogging: 활성화할 로그 유형 지정
활성화 전
활성화
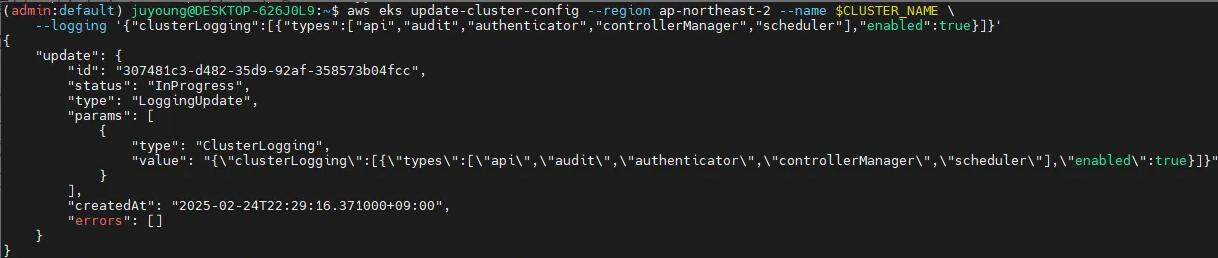
활성화 후
2.2.4 컨트롤 플레인 로그 조회
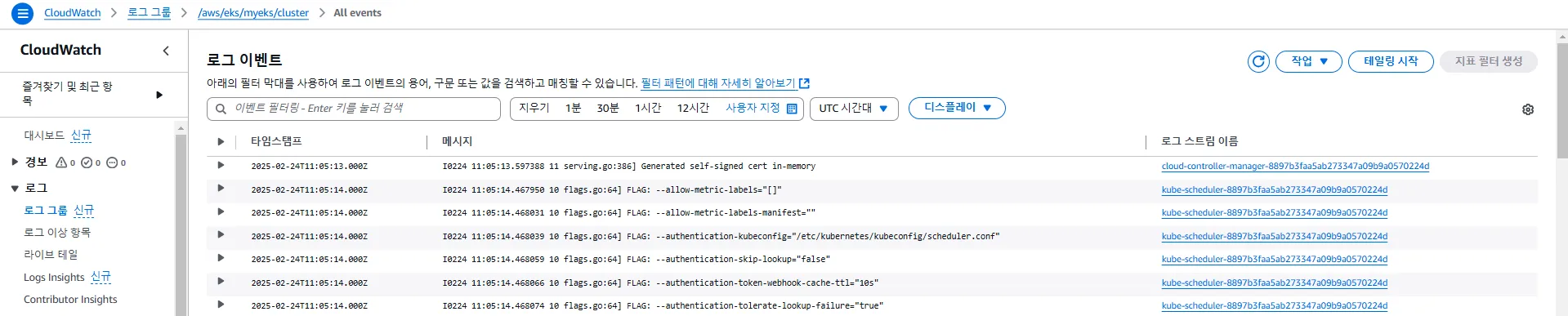
활성화된 로깅 데이터를 AWS CLI를 사용하여 확인할 수 있습니다.
# 로그 그룹 확인
aws logs describe-log-groups | jq
# 로그 tail 확인 : aws logs tail help
aws logs tail /aws/eks/$CLUSTER_NAME/cluster | more
# 최신 로그 확인
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --follow
# 필터 패턴
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --filter-pattern <필터 패턴>
# 특정 로그 스트림 조회
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix <로그 스트림 prefix> --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-apiserver --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-apiserver-audit --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-scheduler --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix authenticator --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-controller-manager --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix cloud-controller-manager --follow
kubectl scale deployment -n kube-system coredns --replicas=1
kubectl scale deployment -n kube-system coredns --replicas=2
# 시간 범위를 지정하여 로그 조회: 1초(s) 1분(m) 1시간(h) 하루(d) 한주(w)
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m
# 간략한 출력 형식 적용
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m --format short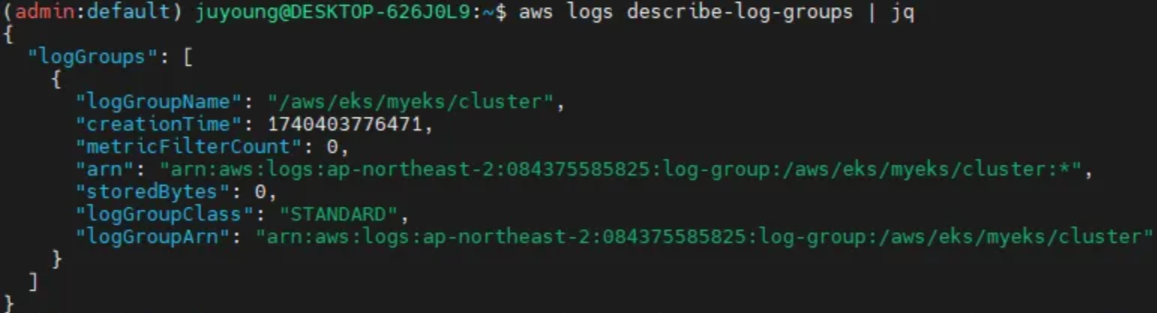

2.3 CloudWatch Log Insights 활용
CloudWatch Log Insights를 활용하면 EKS 컨트롤 플레인 로그를 효율적으로 분석할 수 있습니다.
📌 관련 문서:
CloudWatch Log Insights (EKS Workshop)
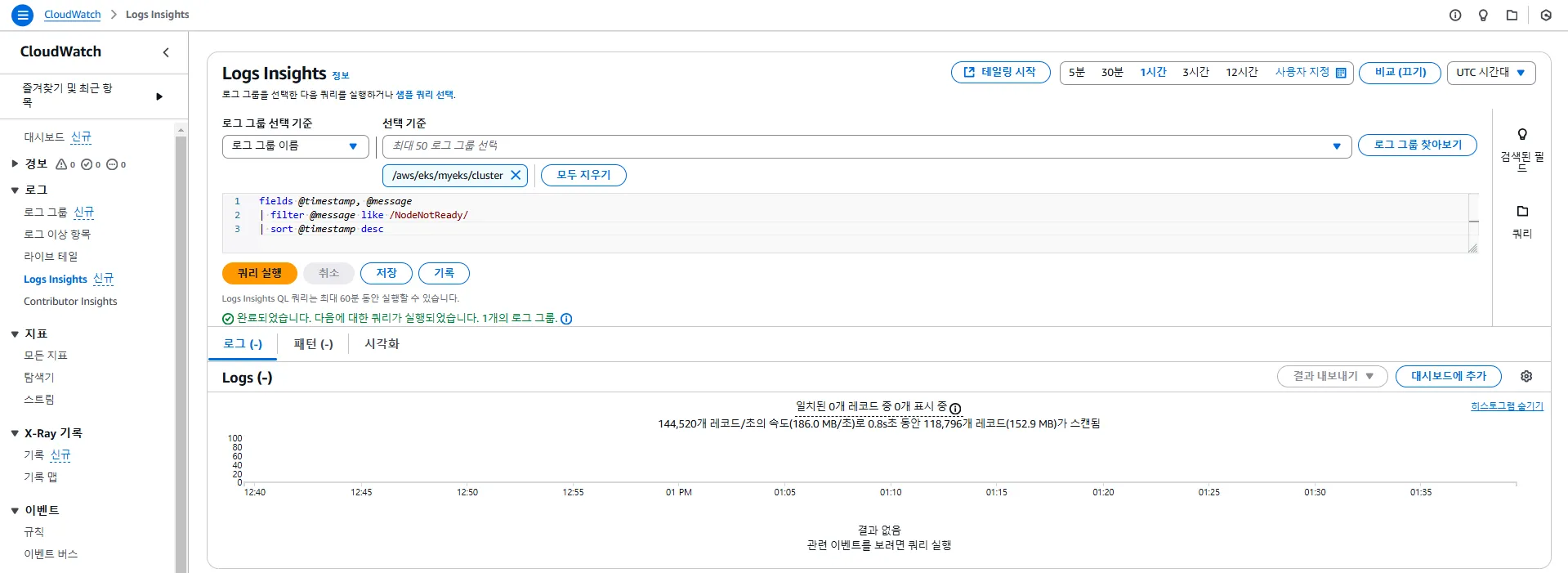
# EC2 Instance가 NodeNotReady 상태인 로그 검색
fields @timestamp, @message
| filter @message like /NodeNotReady/
| sort @timestamp desc
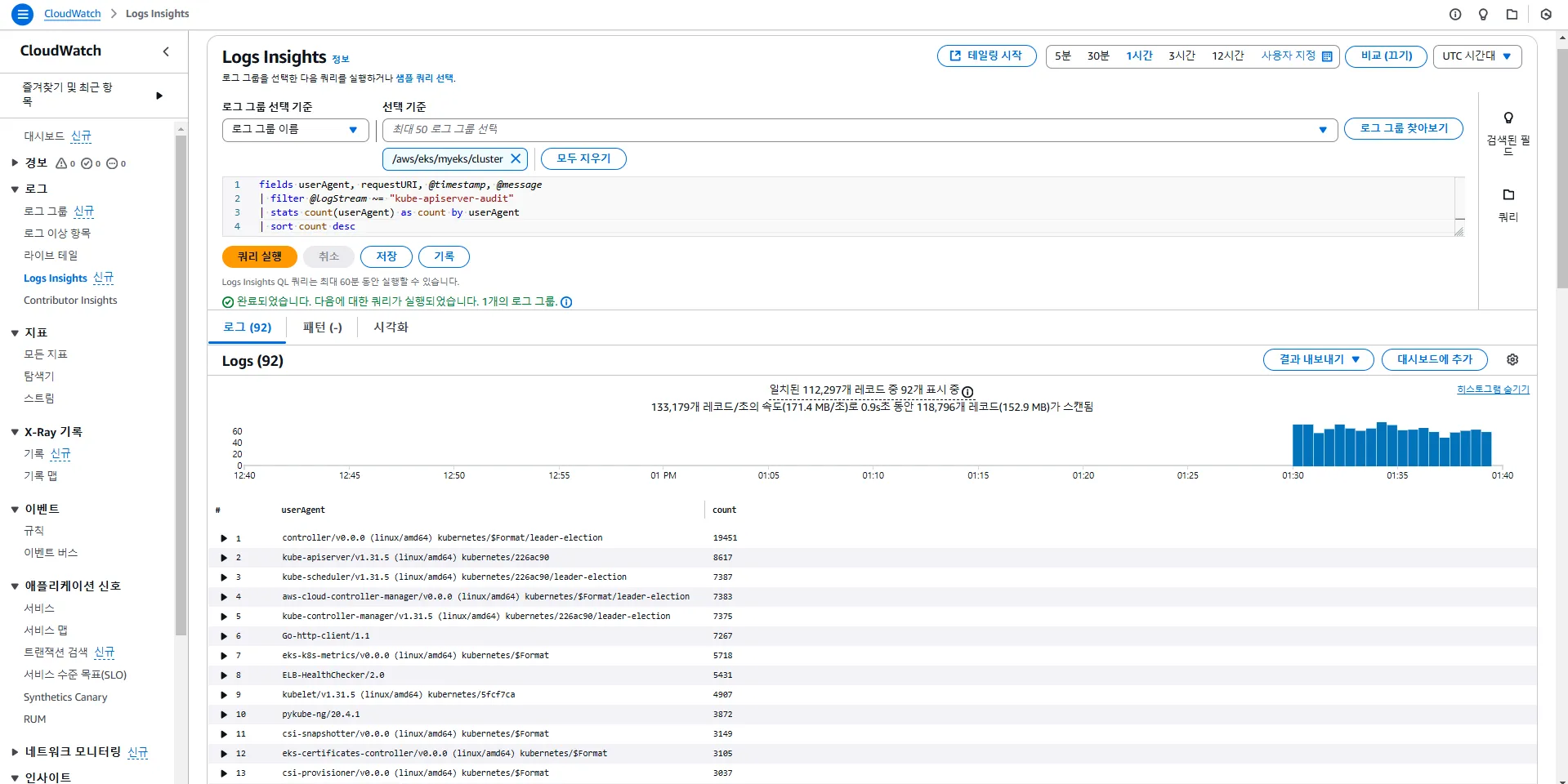
# kube-apiserver-audit 로그에서 userAgent 정렬해서 아래 4개 필드 정보 검색
fields userAgent, requestURI, @timestamp, @message
| filter @logStream ~= "kube-apiserver-audit"
| stats count(userAgent) as count by userAgent
| sort count desc
#
fields @timestamp, @message
| filter @logStream ~= "kube-scheduler"
| sort @timestamp desc
#
fields @timestamp, @message
| filter @logStream ~= "authenticator"
| sort @timestamp desc
#
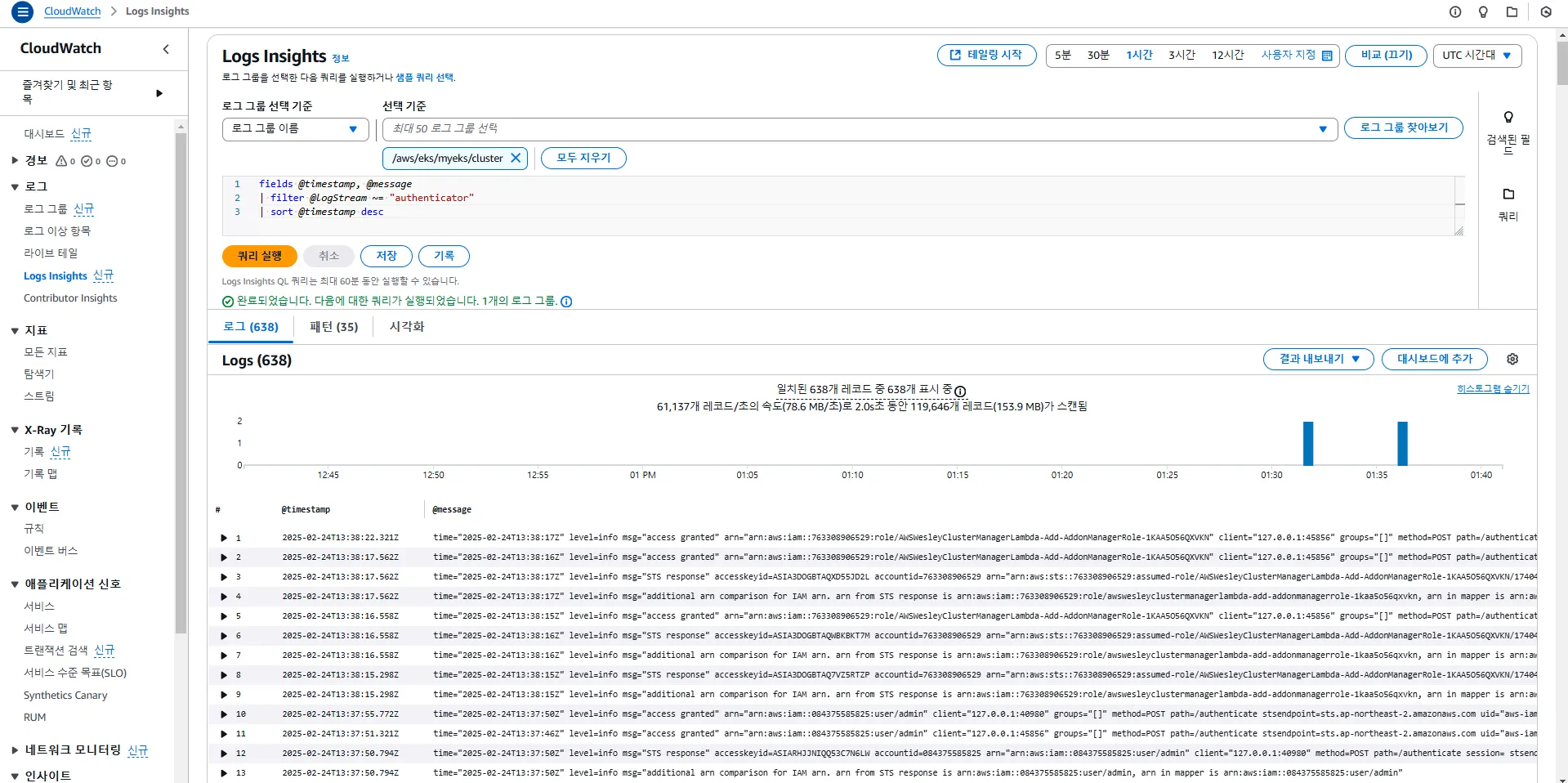
fields @timestamp, @message
| filter @logStream ~= "kube-controller-manager"
| sort @timestamp desc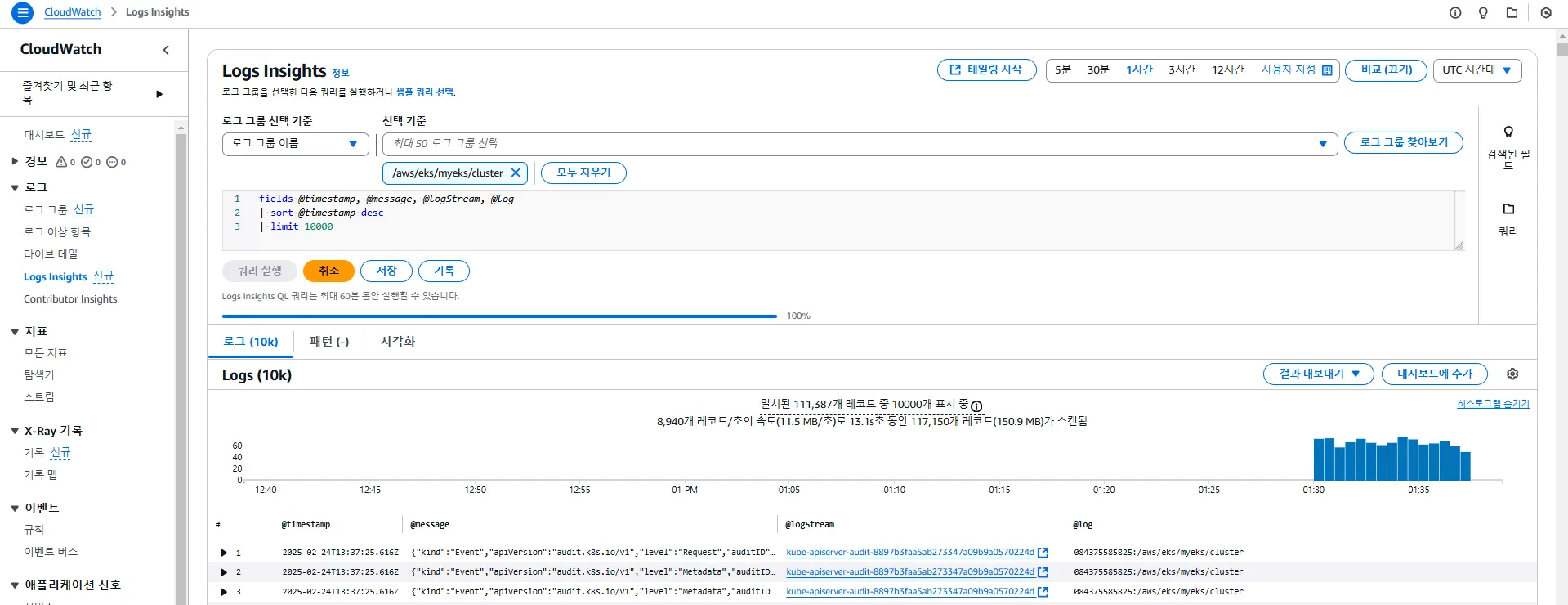
2.4 컨트롤 플레인 로깅 비활성화
컨트롤 플레인 로깅이 불필요할 경우 다음 명령어를 사용하여 비활성화할 수 있습니다.
# EKS Control Plane 로깅(CloudWatch Logs) 비활성화
eksctl utils update-cluster-logging --cluster $CLUSTER_NAME --region ap-northeast-2 --disable-types all --approve
# 로그 그룹 삭제
aws logs delete-log-group --log-group-name /aws/eks/$CLUSTER_NAME/cluster
2.5 애플리케이션 로깅 (Application Logging)
EKS에서 애플리케이션 로깅을 설정하면 컨테이너(Pod)에서 발생하는 로그를 CloudWatch Logs로 수집할 수 있습니다.
2.5.1 NGINX 웹서버 배포 및 로깅
Helm을 활용하여 NGINX를 배포하고, Ingress를 통해 로깅을 확인할 수 있습니다. Helm 링크
# Helm 저장소 추가 및 업데이트
helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo update
# 도메인, 인증서 확인
echo $MyDomain $CERT_ARN
# NGINX Helm 차트 설정 파일 작성
cat <<EOT > nginx-values.yaml
service:
type: NodePort
networkPolicy:
enabled: false
resourcesPreset: "nano"
ingress:
enabled: true
ingressClassName: alb
hostname: nginx.$MyDomain
pathType: Prefix
path: /
annotations:
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/load-balancer-name: $CLUSTER_NAME-ingress-alb
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/ssl-redirect: "443"
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/target-type: ip
EOT
cat nginx-values.yaml
# NGINX 배포
helm install nginx bitnami/nginx --version 19.0.0 -f nginx-values.yaml
# 배포 상태 확인
kubectl get ingress,deploy,svc,ep nginx
kubectl describe deploy nginx # Resource - Limits/Requests 확인
kubectl get targetgroupbindings # ALB TG 확인
# 접속 주소 확인 및 접속
echo -e "Nginx WebServer URL = https://nginx.$MyDomain"
curl -s https://nginx.$MyDomain
# 로그 조회
kubectl stern deploy/nginx
혹은
kubectl logs deploy/nginx -f
# 반복적인 요청 테스트
while true; do curl -s https://nginx.$MyDomain | grep title; date; sleep 1; done
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; sleep 1; done

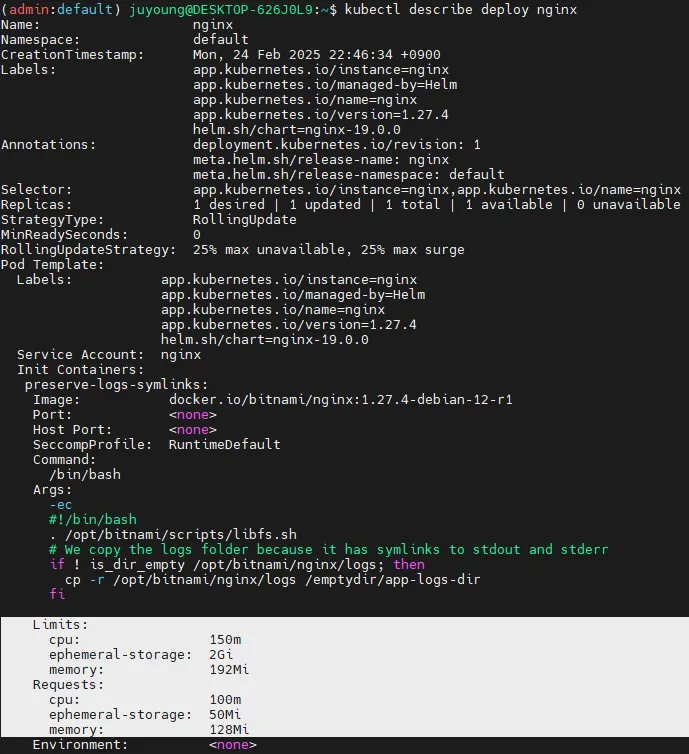
→ 컨테이너의 자원 제한 설정을 확인한 결과, yaml의 resourcesPreset: "nano"가 적용되어 컨테이너의 CPU 요청(request) 50m, 제한(limit) 100m / 메모리 요청(request) 64Mi, 제한(limit) 128Mi로 설정되어 있음을 확인

3. Metrics-server 및 kwatch 활용한 Kubernetes 모니터링
3.1 개요
Kubernetes 환경에서 리소스 모니터링 및 알림 시스템 구축은 클러스터의 안정성과 성능을 유지하는 데 필수적입니다.
이를 위해 Kubernetes는 Metrics-server를 활용하여 리소스 사용량을 수집하고, kwatch를 통해 클러스터 이벤트(예: 파드 충돌, PVC 사용량 초과 등)를 감지하고 알림을 제공합니다.
📌 관련 공식 문서 및 참고자료
3.2 Metrics-server를 이용한 리소스 모니터링
3.2.1 Metrics-server란?
Metrics-server는 Kubernetes 클러스터의 리소스 사용량(CPU, 메모리)을 수집 및 집계하는 애드온 구성 요소입니다.
클러스터 내부에서 실행되며, kubelet에서 cAdvisor(Container Advisor)를 통해 수집된 데이터를 기반으로 정보를 제공합니다.
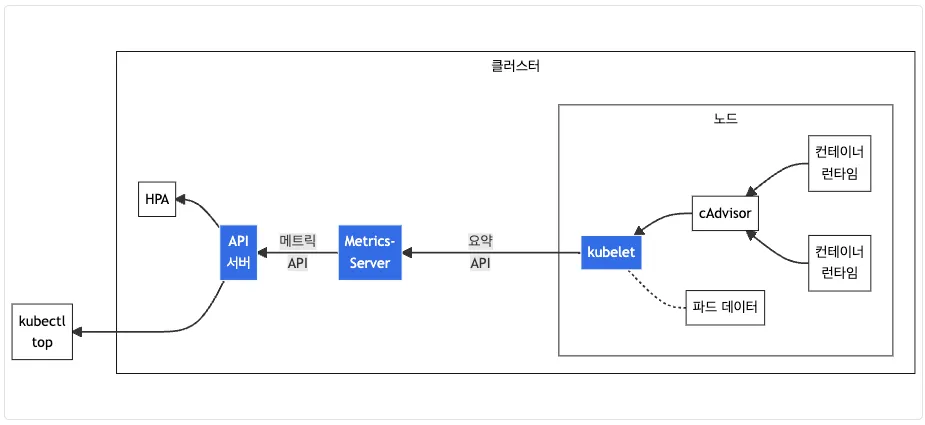
📌 Metrics-server의 주요 역할
kubectl top node및kubectl top pod명령어 지원- HPA(Horizontal Pod Autoscaler) 및 Cluster Autoscaler에 리소스 메트릭 제공
- 15초 간격으로 cAdvisor를 통해 데이터를 수집 및 집계
3.2.2 Metrics-server 상태 확인
# Metrics-server 파드 실행 여부 확인
kubectl get pod -n kube-system -l app.kubernetes.io/name=metrics-server
# API 서비스 활성화 확인
kubectl api-resources | grep metrics
kubectl get apiservices |egrep '(AVAILABLE|metrics)'
# 노드 및 파드 메트릭 확인
# 전체 노드의 리소스 사용량 확인
kubectl top node
# 모든 네임스페이스의 파드 리소스 사용량 확인
kubectl top pod -A
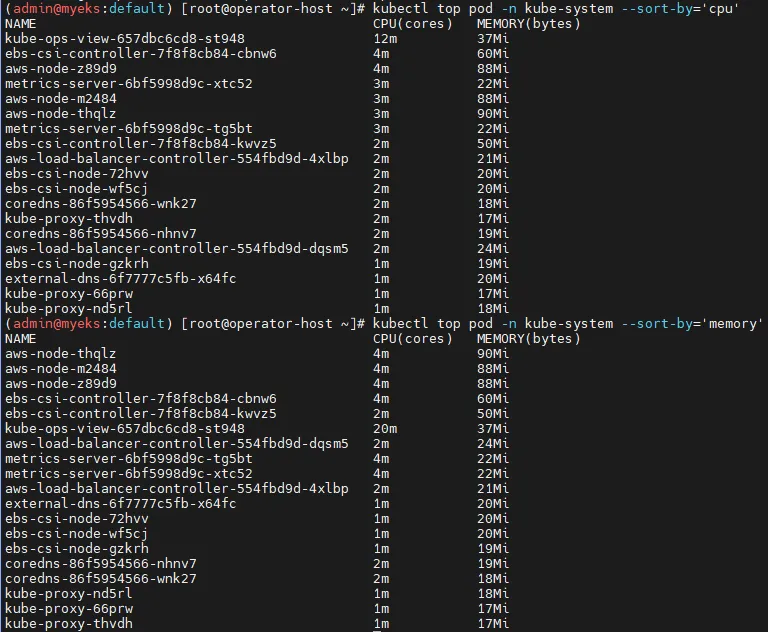
# 특정 네임스페이스에서 CPU 사용량 기준 정렬
kubectl top pod -n kube-system --sort-by='cpu'
# 특정 네임스페이스에서 메모리 사용량 기준 정렬
kubectl top pod -n kube-system --sort-by='memory'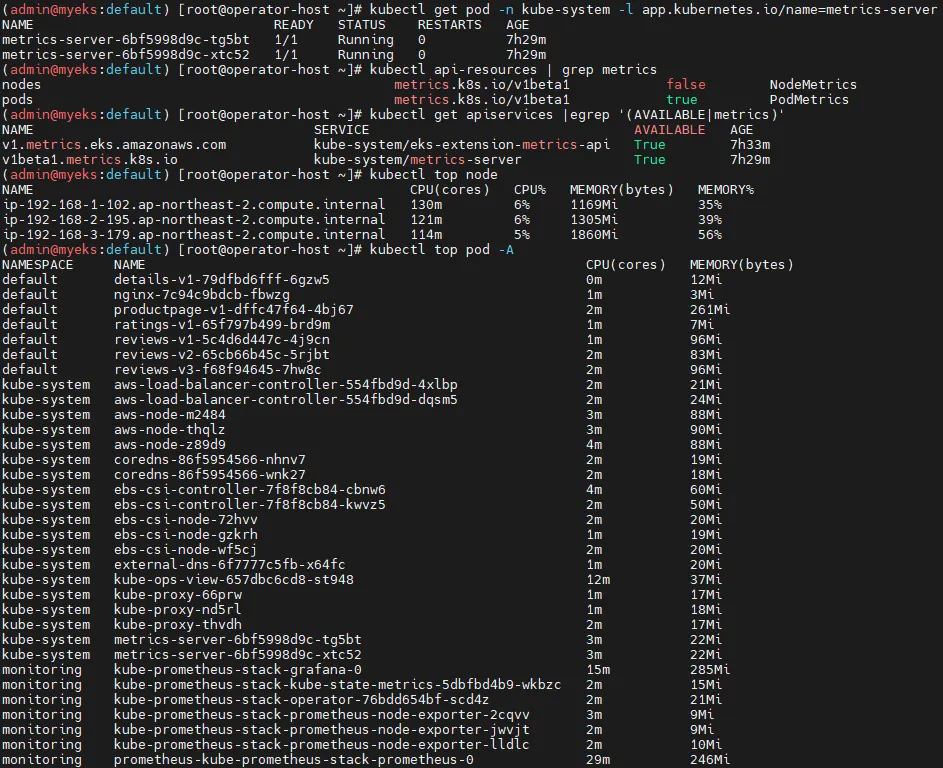
3.3 kwatch를 활용한 클러스터 이벤트 모니터링
3.3.1 kwatch란?
kwatch는 Kubernetes 클러스터에서 발생하는 이벤트(파드 충돌, PVC 사용량 초과 등)를 감지하고, Slack 및 Discord와 같은 알림 채널로 즉시 알림을 전송하는 모니터링 도구입니다.
📌 kwatch 주요 기능
- 파드 크래시 및 애플리케이션 오류 감지
- PVC(퍼시스턴트 볼륨 클레임) 사용량 초과 감지 및 알림
- Slack, Discord, Webhook을 통한 알림 전송
- 간편한 ConfigMap 설정을 통해 이벤트 감지 조건 조정 가능
3.3.2 kwatch 설치 및 설정
# 닉네임 설정
NICK=<각자 자신의 닉네임>
NICK=gasida
# ConfigMap 생성 및 적용
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
alert:
slack:
webhook: '<웹훅 URL>'
title: $NICK-eks
pvcMonitor:
enabled: true
interval: 5
threshold: 70
EOF
# kwatch 배포
kubectl apply -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.5/deploy/deploy.yaml
# 배포 확인
kubectl get pods -n kwatch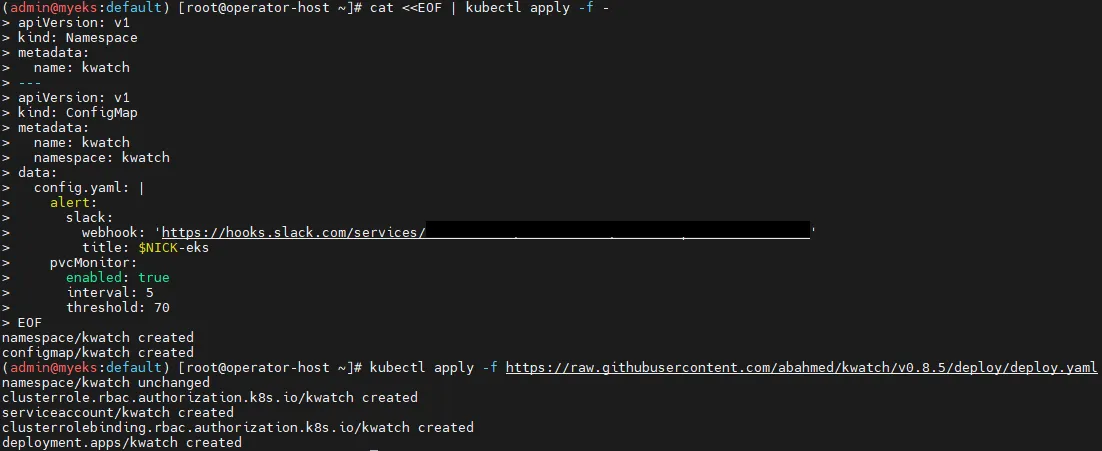

3.3.3 kwatch 이벤트 감지 테스트
# 터미널1
watch kubectl get pod
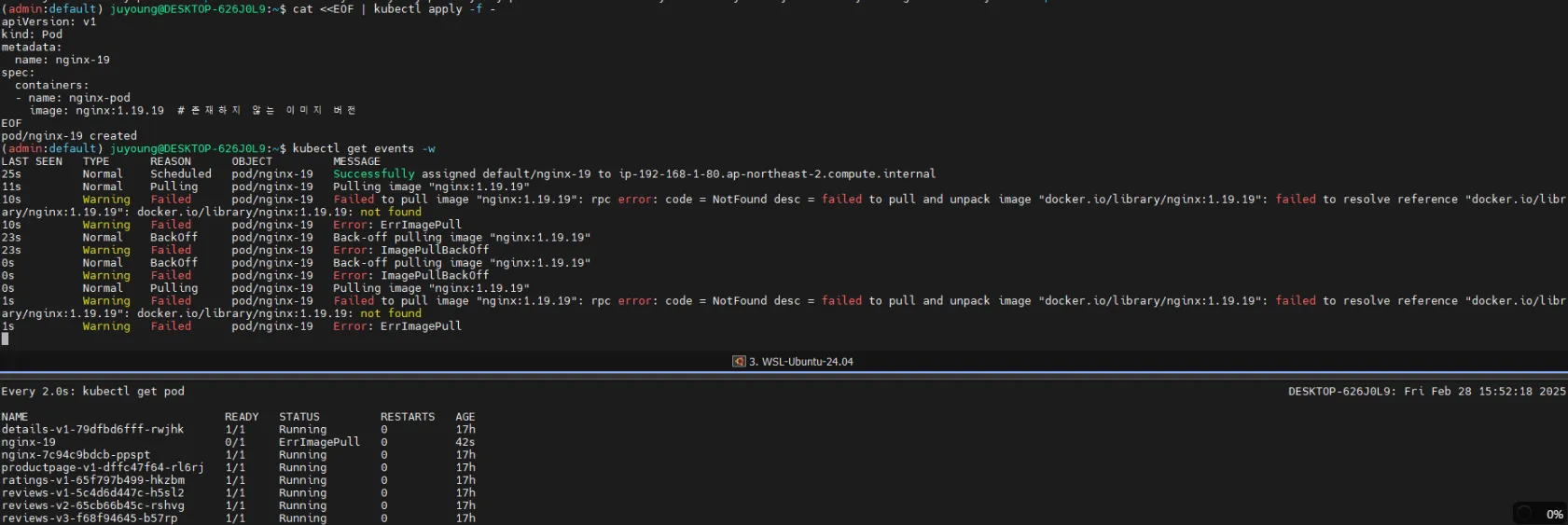
# 잘못된 이미지 버전의 파드 배포
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: nginx-19
spec:
containers:
- name: nginx-pod
image: nginx:1.19.19 # 존재하지 않는 이미지 버전
EOF
# 실시간 이벤트 확인
kubectl get events -w
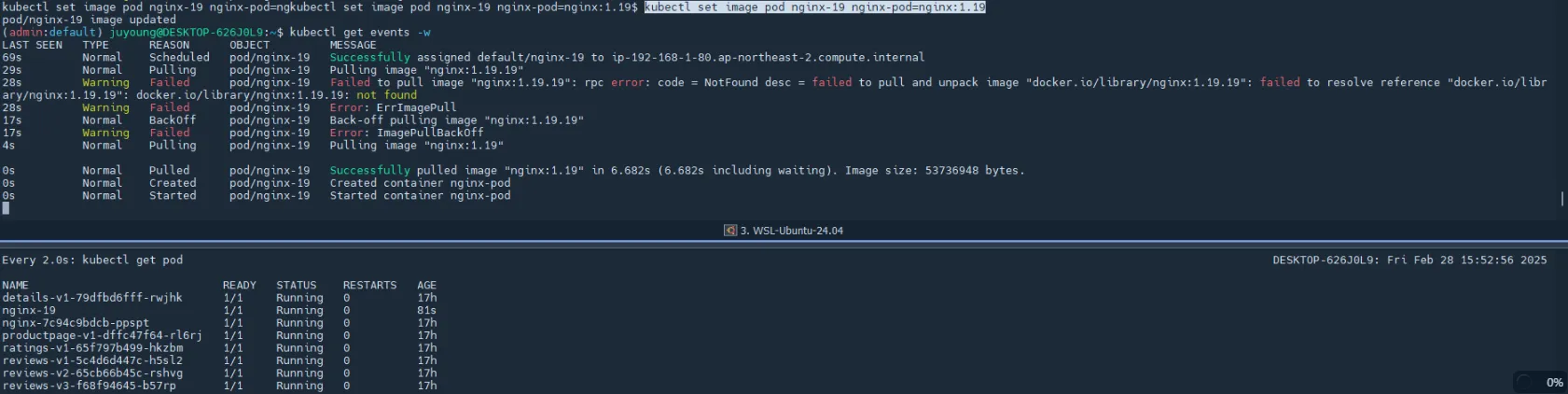
# 파드 이미지 업데이트 (오류 수정) : set 사용 - iamge 등 일부 리소스 값을 변경 가능
kubectl set
kubectl set image pod nginx-19 nginx-pod=nginx:1.19
# 파드 삭제
kubectl delete pod nginx-19📌 결과:
- kwatch는 해당 파드의 ImagePullBackOff 오류를 감지하고 Slack에 알림을 전송
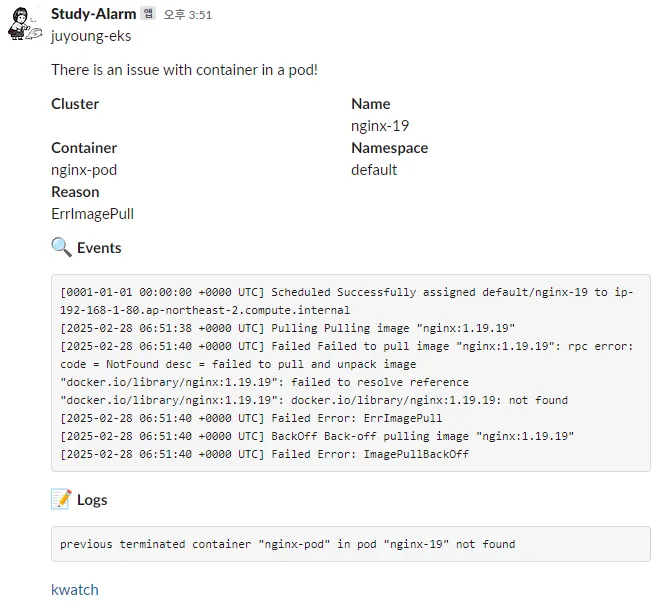
3.4 kwatch 및 Metrics-server 삭제
3.4.1 kwatch 삭제
kubectl delete -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.5/deploy/deploy.yaml3.4.2 Metrics-server 삭제
Metrics-server는 Kubernetes 애드온으로 기본적으로 제공되며, 제거할 필요가 없습니다.
만약 직접 배포한 경우, 다음 명령어를 실행하여 제거할 수 있습니다.
kubectl delete -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml