이 글은 CloudNet@팀의 AWS EKS Workshop Study(AEWS) 3기 스터디 내용을 바탕으로 작성되었습니다.
AEWS는 CloudNet@의 '가시다'님께서 진행하는 스터디로, EKS를 학습하는 과정입니다.
EKS를 깊이 있게 이해할 기회를 주시고, 소중한 지식을 나눠주시는 가시다님께 다시 한번 감사드립니다.
이 글이 EKS를 학습하는 분들께 도움이 되길 바랍니다.
1. Grafana 소개 및 웹 접속
Grafana는 TSDB(Time-Series Database) 데이터를 시각화하고 모니터링할 수 있는 오픈소스 솔루션입니다. 다양한 데이터 소스를 지원하며, Prometheus와 같은 모니터링 시스템과 연동하여 메트릭, 로그, 트레이스를 시각적으로 분석할 수 있습니다.
- Grafana 공식 문서 및 리소스
Grafana는 데이터 저장 기능이 없으며, 현재 실습 환경에서는 Prometheus를 데이터 소스로 사용합니다.
1.1 Grafana 접속 정보 및 로그인
Grafana 기본 로그인 정보는 다음과 같습니다.
- 기본 계정:
admin - 비밀번호:
prom-operator
# Grafana 버전 확인
kubectl exec -it -n monitoring sts/kube-prometheus-stack-grafana -- grafana-cli --version
# Ingress 정보 확인
kubectl get ingress -n monitoring kube-prometheus-stack-grafana
kubectl describe ingress -n monitoring kube-prometheus-stack-grafana
# Ingress 도메인으로 웹 접속
echo -e "Grafana Web URL = https://grafana.$MyDomain"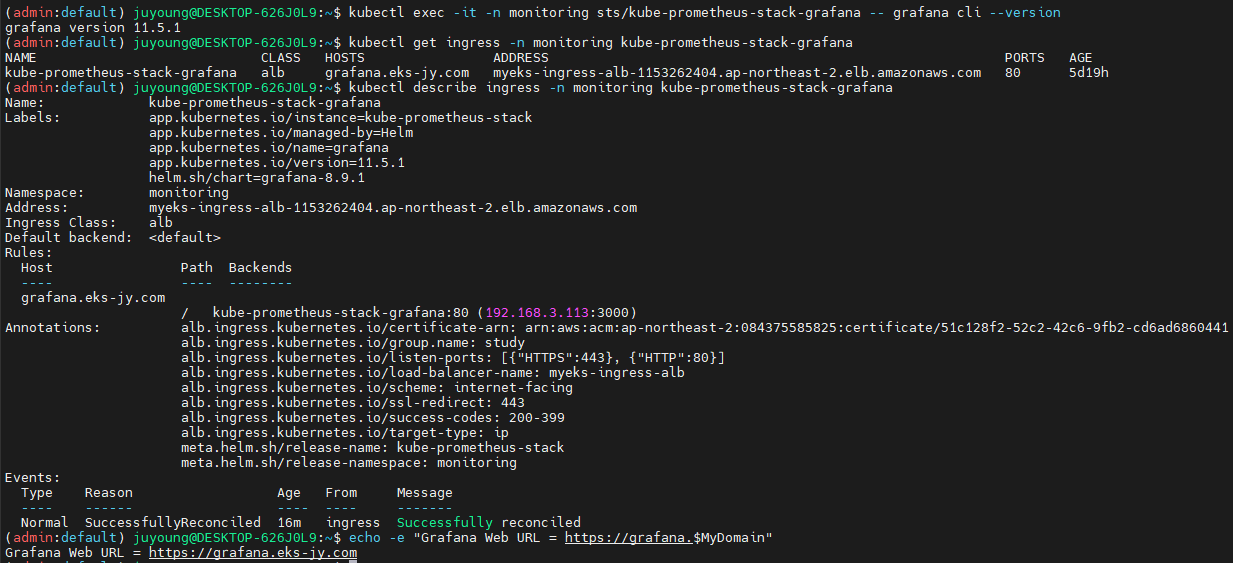
1.2 Grafana 웹 인터페이스 주요 기능
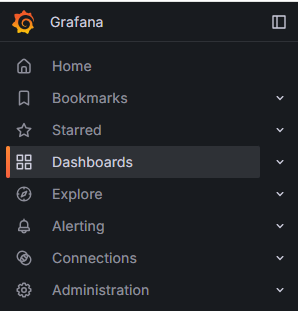
- Search Dashboards: 대시보드 검색
- Starred Dashboards: 즐겨찾기한 대시보드 목록
- Dashboards: 전체 대시보드 목록 확인
- Explore: PromQL을 사용하여 메트릭을 탐색
- Alerting: 경고(Alert) 설정 및 관리
- Connections: 데이터 소스 및 설정 확인
- Administrator: 사용자 및 조직 관리, 플러그인 설정
2. Grafana 데이터 소스 설정
Grafana는 Prometheus를 데이터 소스로 사용하여 메트릭을 수집합니다.
2.1 데이터 소스 연결 확인
스택의 경우 자동으로 Prometheus를 데이터 소스로 추가해둡니다.

# Prometheus 서비스 주소 확인
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus
# 테스트용 Pod 배포
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: Pod
metadata:
name: netshoot-pod
spec:
containers:
- name: netshoot-pod
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
terminationGracePeriodSeconds: 0
EOF
kubectl get pod netshoot-pod
# 데이터 소스 연결 확인
kubectl exec -it netshoot-pod -- nslookup kube-prometheus-stack-prometheus.monitoring
kubectl exec -it netshoot-pod -- curl -s kube-prometheus-stack-prometheus.monitoring:9090/graph -v ; echo
# 테스트 Pod 삭제
kubectl delete pod netshoot-pod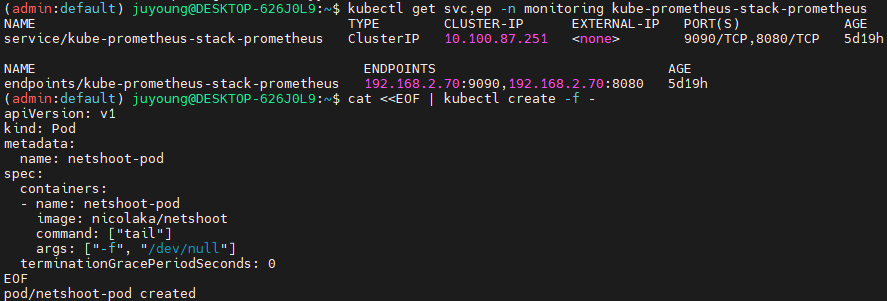
3. Grafana 대시보드 활용
Grafana는 기본적으로 다양한 대시보드를 제공합니다. 또한, 공식 대시보드를 가져와서 사용할 수도 있습니다.
3.1 기본 대시보드 확인
# Dashboards → Browse 에서 확인 가능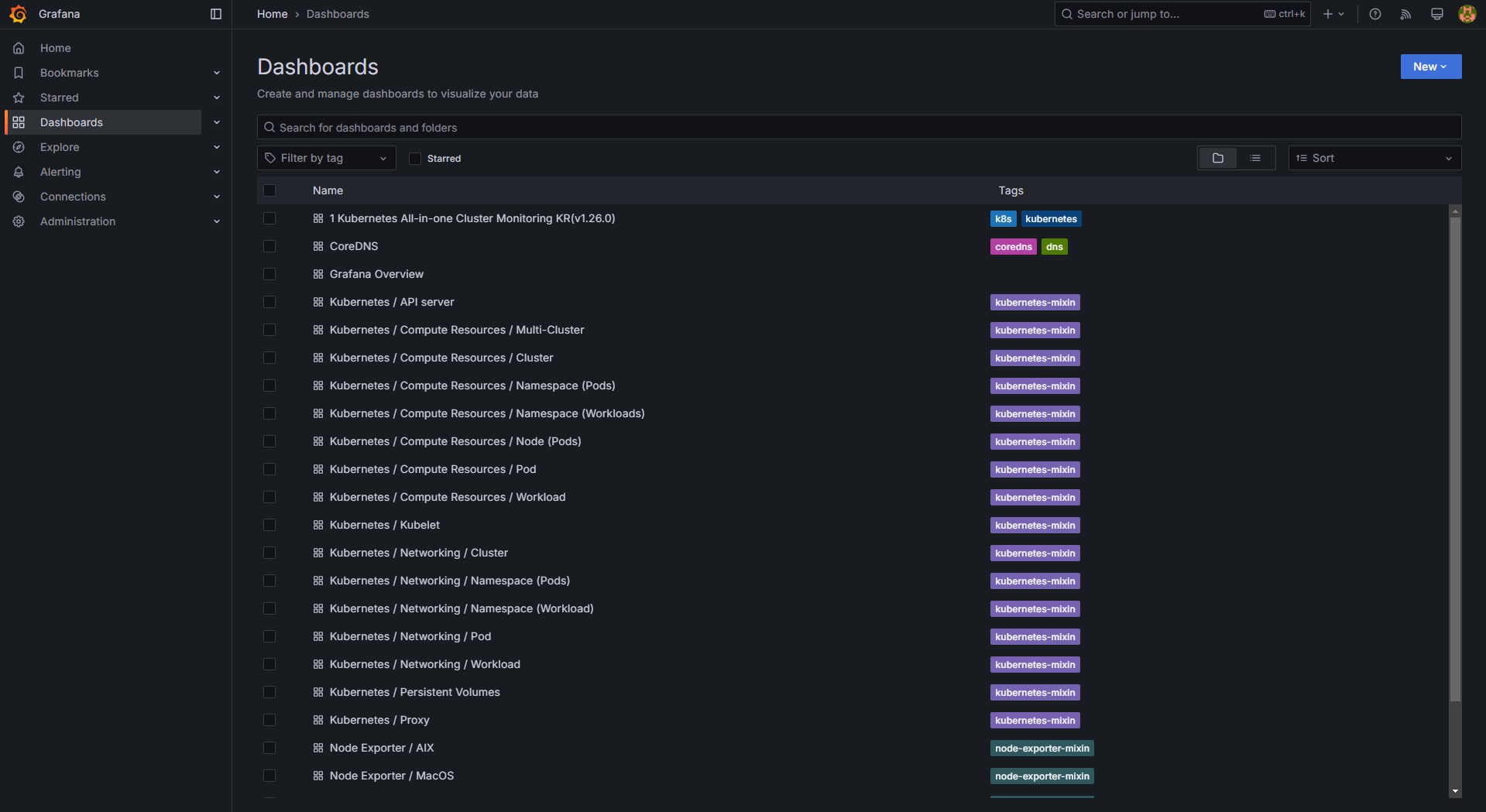
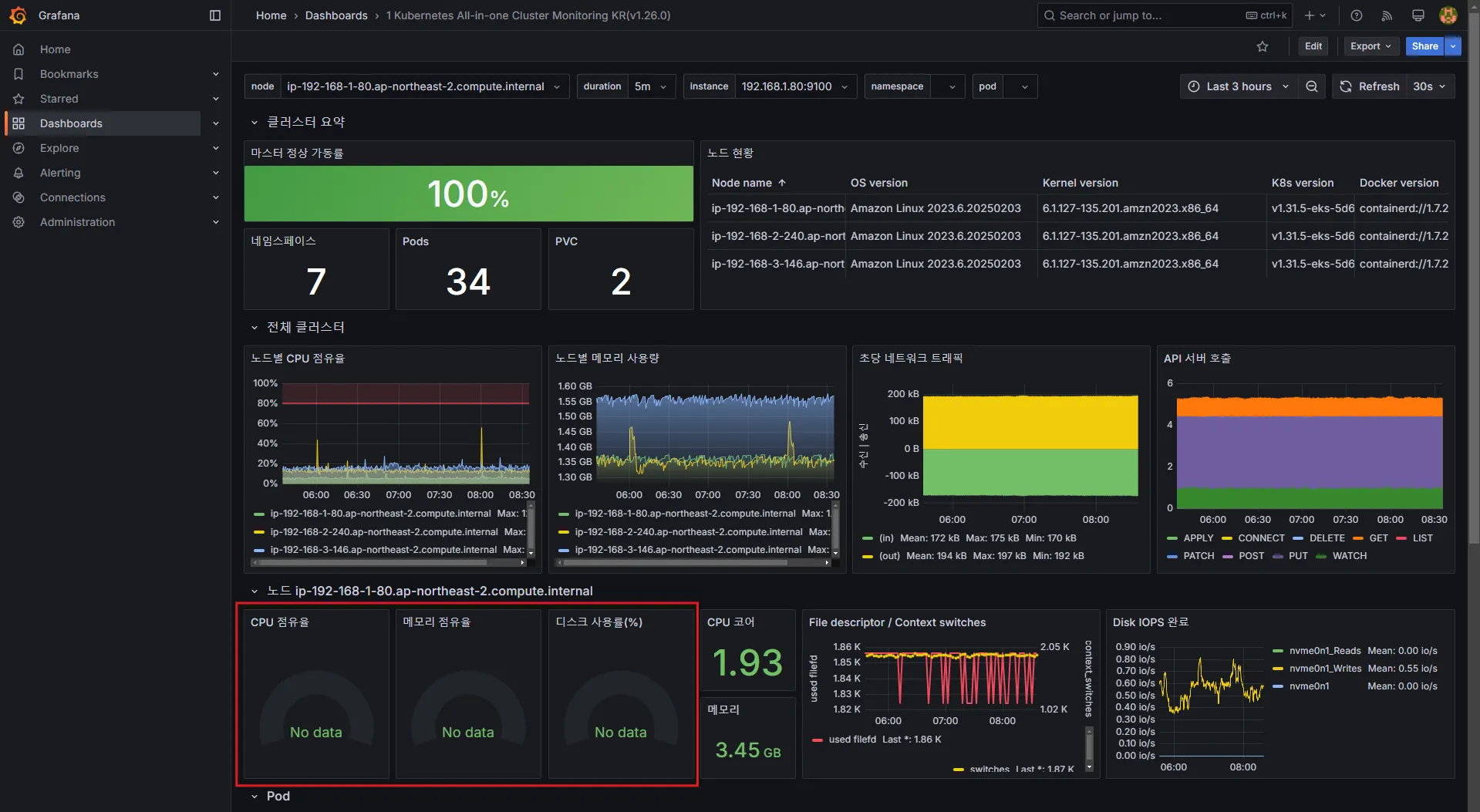
기본 대시보드는 다음과 같이 구성되어 있습니다.
- 자원 사용량: Cluster/POD Resources
- 노드 자원 사용량: Node Exporter
- 주요 애플리케이션 모니터링: CoreDNS, Kube Proxy 등
3.2 공식 대시보드 가져오기
공식 Grafana 대시보드는 다음 사이트에서 확인할 수 있습니다.
대시보드를 추가하려면 Dashboard → New → Import 에서 아래 ID를 입력 후 Import 버튼을 클릭합니다.

추천 대시보드 목록:
- Kubernetes / Views / Global (
15757) - 1 Kubernetes All-in-One Cluster Monitoring KR (
17900) - Node Exporter Full (
1860) - Node Exporter for Prometheus Dashboard based on 11074 (
15172) - Kube-State-Metrics-V2 (
13332) - Amazon EKS AWS CNI Metrics (
16032) - NGINX Monitoring (
12708)
4. Grafana 대시보드 커스터마이징
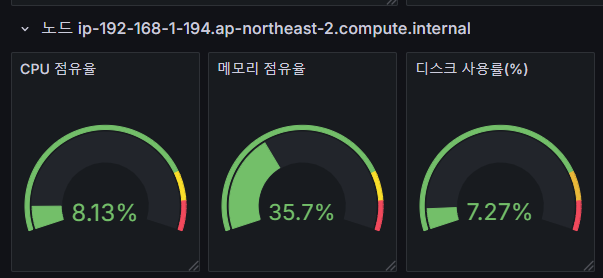
4.1 CPU, 메모리, 디스크 사용량 시각화 수정
기본 대시보드의 CPU 사용량 패널을 수정하려면 다음 쿼리를 사용합니다.
# 기존 : CPU 점유율
sum by (node) (irate(node_cpu_seconds_total{mode!~"guest.*|idle|iowait", node="$node"}[5m]))
# 변경 전 쿼리 시도
node_cpu_seconds_total
node_cpu_seconds_total{mode!~"guest.*|idle|iowait"}
avg(node_cpu_seconds_total{mode!~"guest.*|idle|iowait"}) by (node)
avg(node_cpu_seconds_total{mode!~"guest.*|idle|iowait"}) by (instance)
# 수정 : CPU 점유율
sum by (instance) (irate(node_cpu_seconds_total{mode!~"guest.*|idle|iowait", instance="$instance"}[5m]))
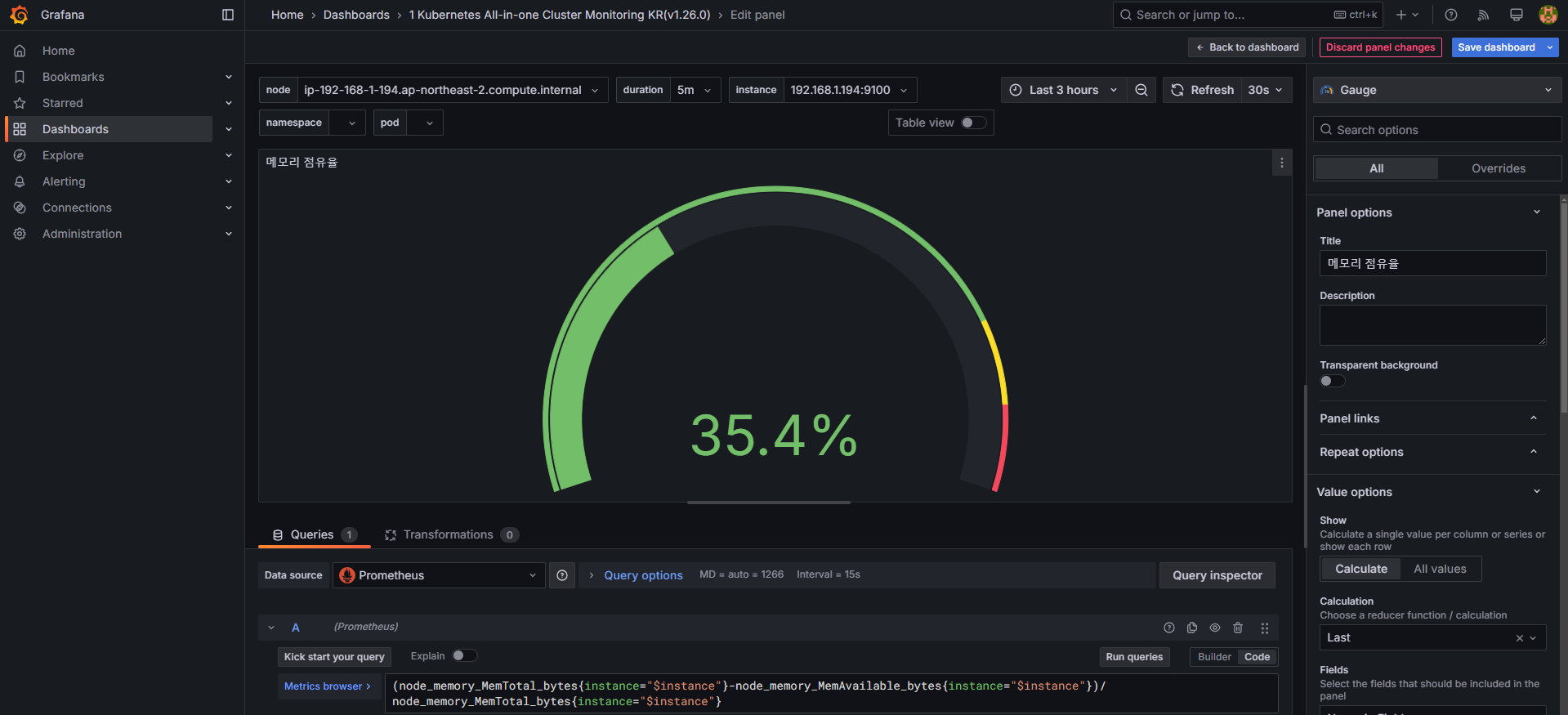
# 수정 : 메모리 점유율
(node_memory_MemTotal_bytes{instance="$instance"}-node_memory_MemAvailable_bytes{instance="$instance"})/node_memory_MemTotal_bytes{instance="$instance"}
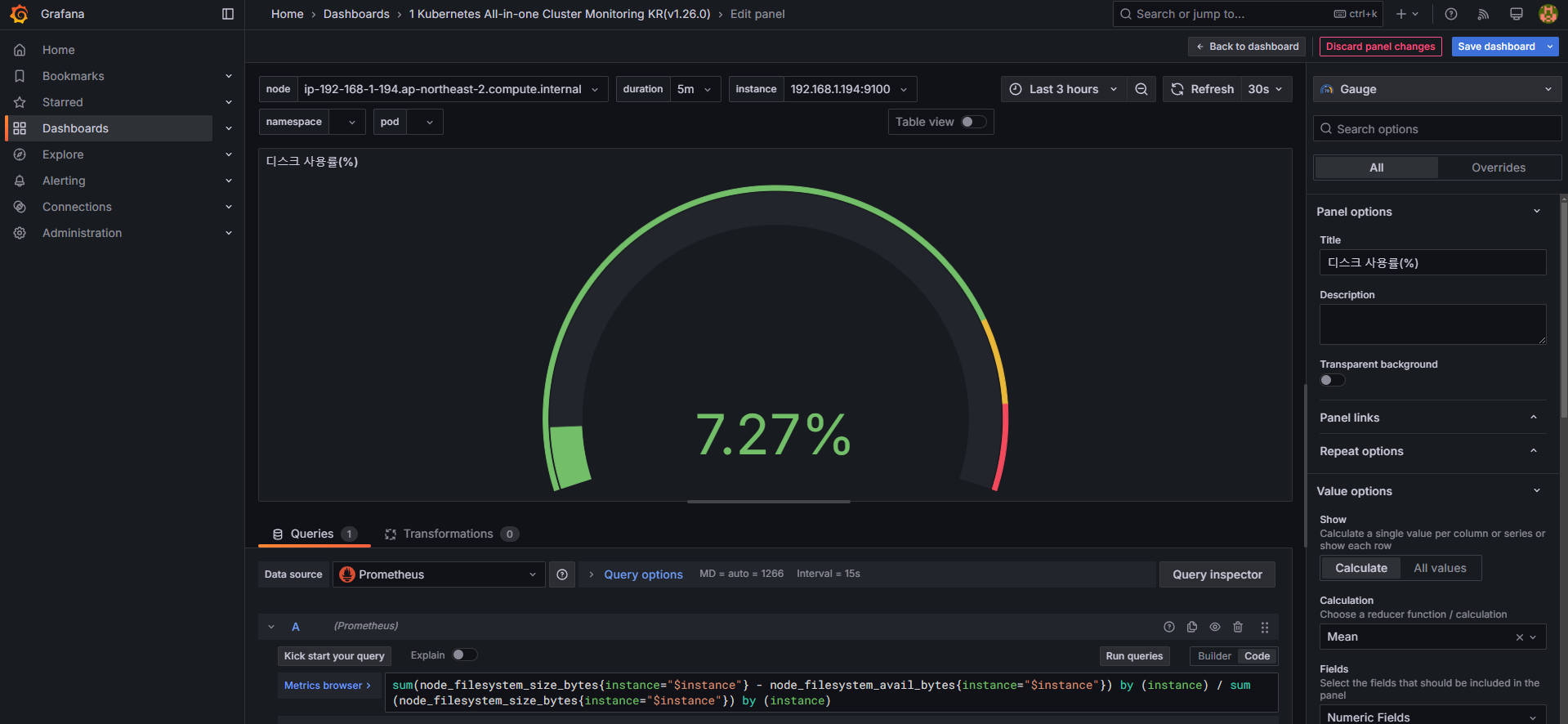
# 수정 : 디스크 사용률
sum(node_filesystem_size_bytes{instance="$instance"} - node_filesystem_avail_bytes{instance="$instance"}) by (instance) / sum(node_filesystem_size_bytes{instance="$instance"}) by (instance)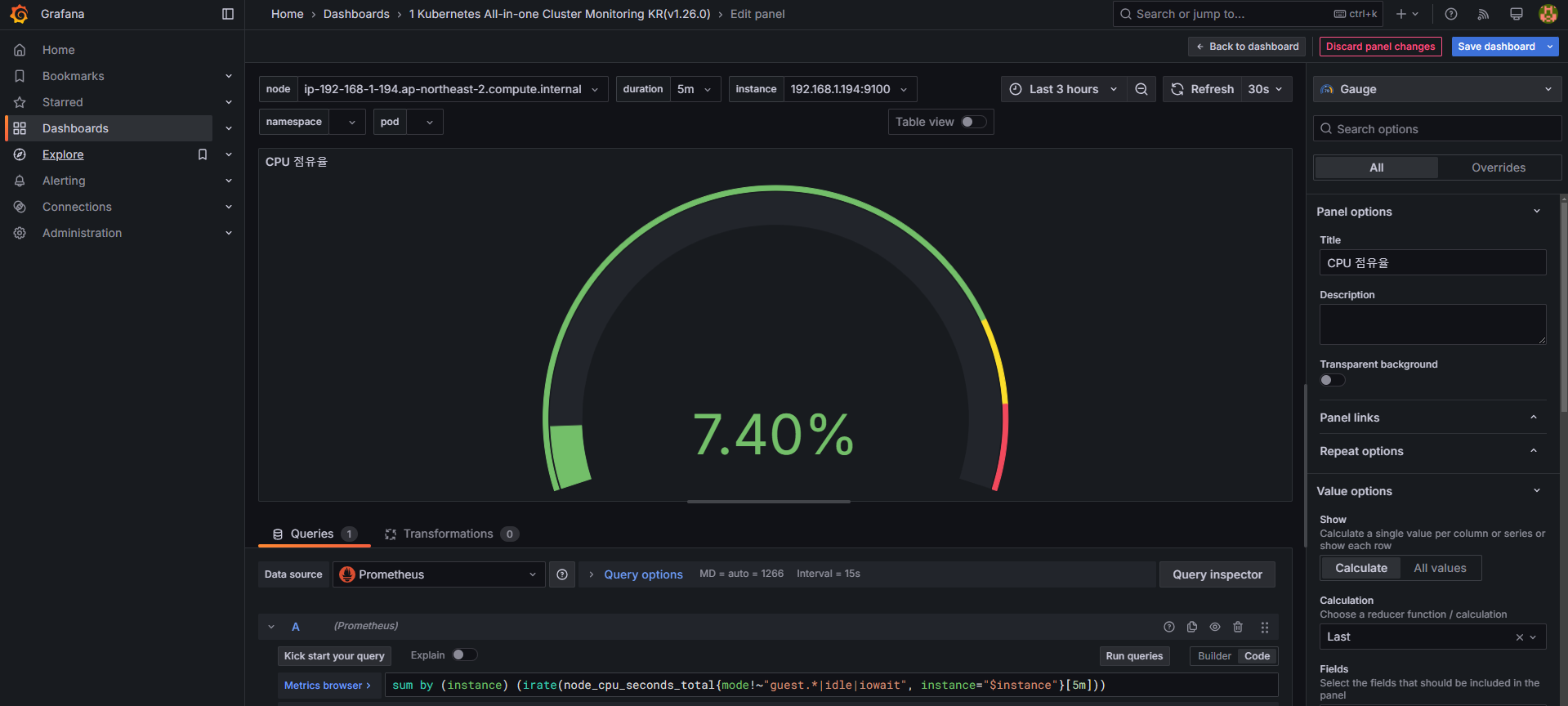
4.2 네임스페이스 및 파드 필터링 추가
-
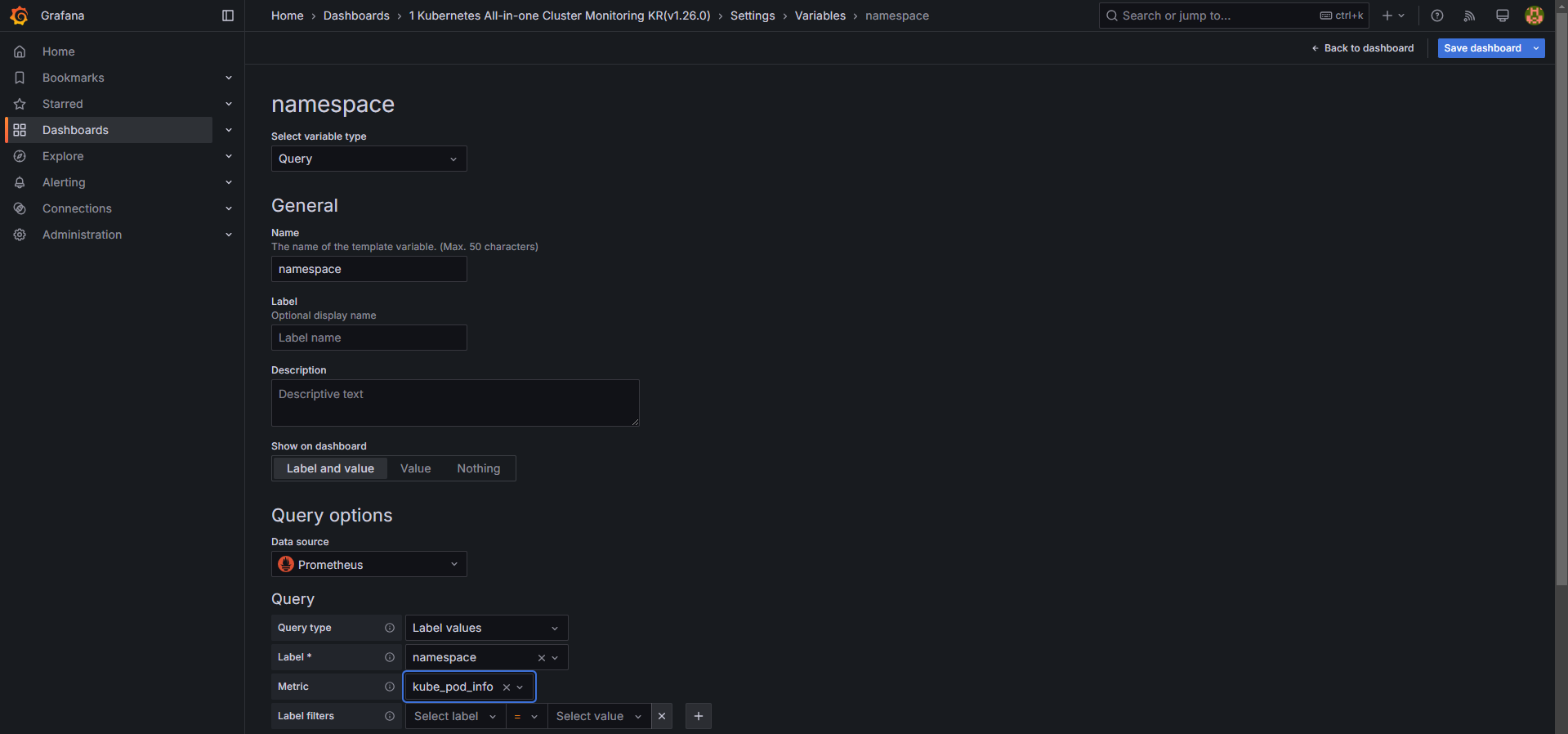
Edit → Settings → Variables 에서
namespace및pod값을 설정합니다. -
kube_pod_info테이블을 활용하여 올바른 네임스페이스 정보를 표시하도록 설정합니다.
-
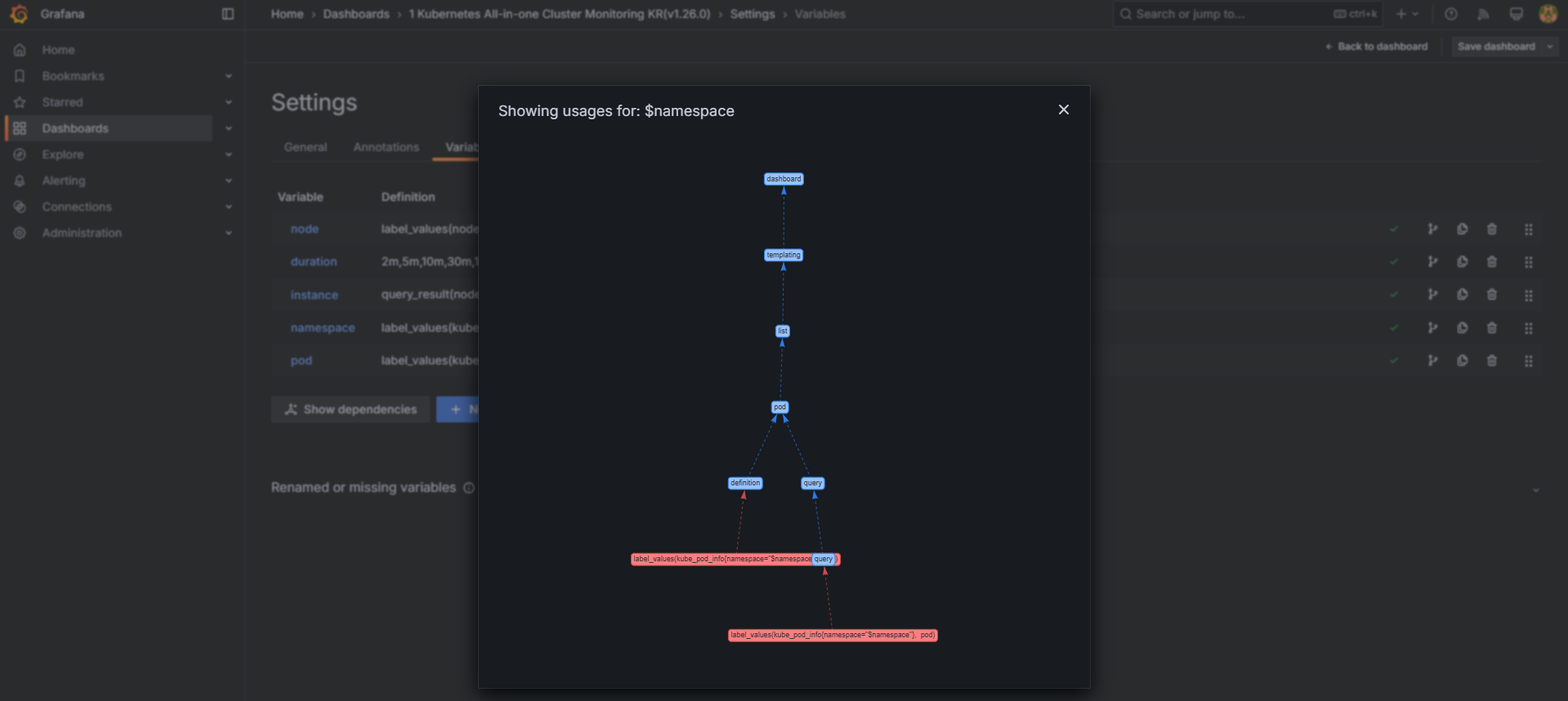
Edit → Settings → Variables → namespace → Show usages 에서 pod variable이 namespace를 하위에 종속 관계 확인
-
네임스페이스 및 파드 필터링 확인

4.3 파드 리소스 할당 제한 추가
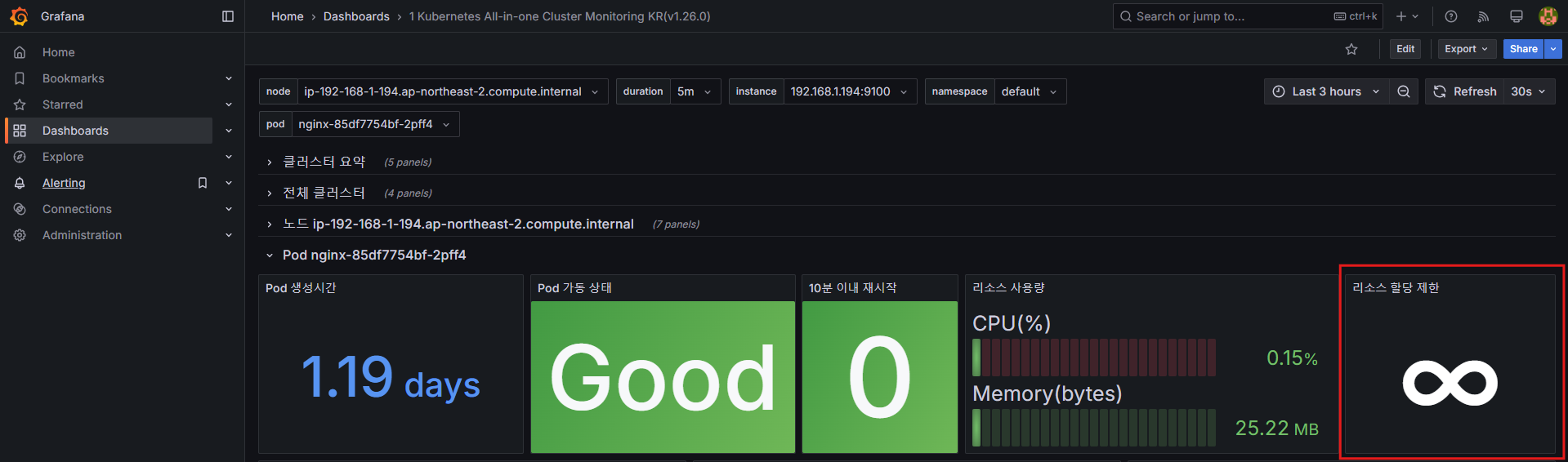
default 네임스페이스의 nginx 파드 정보를 확인합니다.
-
변경 전
-
CPU
# 기존 쿼리
sum(kube_pod_container_resource_limits_cpu_cores{pod="$pod"})
# 변경 전 쿼리 시도
kube_pod_container_resource_limits_cpu_cores
kube_pod_container_resource_limits
kube_pod_container_resource_limits{resource="cpu"}
# 변경 쿼리
sum(kube_pod_container_resource_limits{resource="cpu", pod="$pod"})- Memory
# 기존 쿼리
sum(kube_pod_container_resource_limits_memory_bytes{pod="$pod"})
# 변경 쿼리
sum(kube_pod_container_resource_limits{resource="memory", pod="$pod"})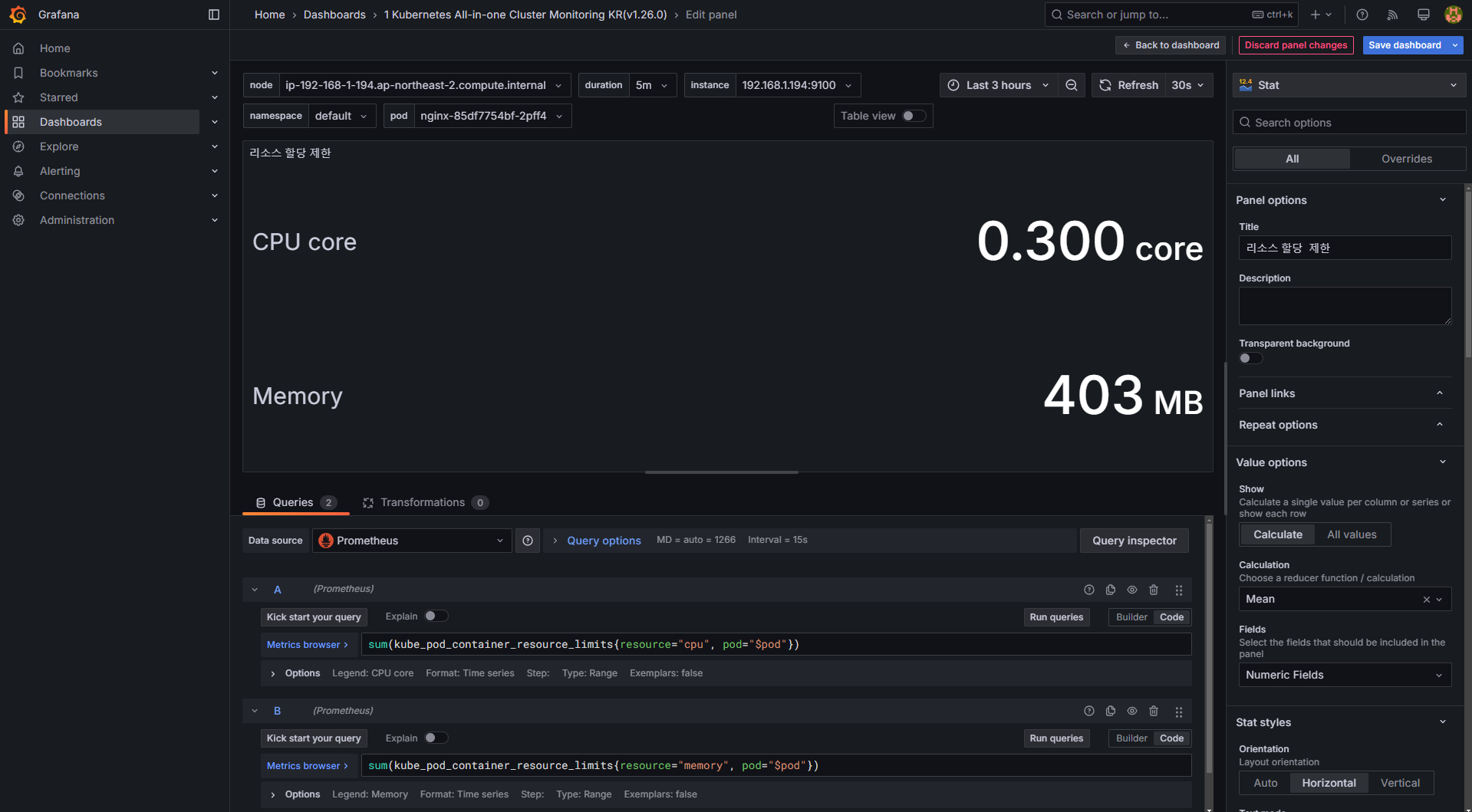
- 변경 후
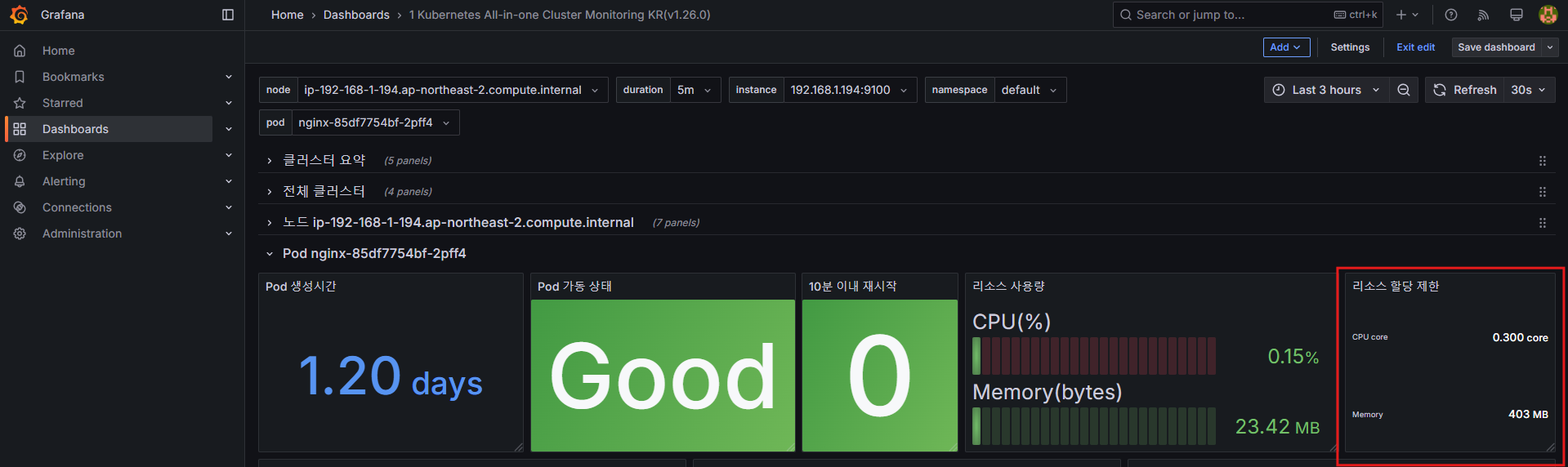
5. Amazon EKS AWS CNI Metrics 모니터링
AWS CNI 관련 메트릭을 수집하려면 PodMonitor를 설정해야 합니다.
5.1 PodMonitor 설정
# PodMonitor 배포
cat <<EOF | kubectl create -f -
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: aws-cni-metrics
namespace: kube-system
spec:
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
podMetricsEndpoints:
- interval: 30s
path: /metrics
port: metrics
selector:
matchLabels:
k8s-app: aws-node
EOF
# PodMonitor 확인
kubectl get podmonitor -n kube-system5.2 대시보드 추가
# 대시보드 추가
Dashboard → New → Import → 16032 입력 후 Load → 데이터 소스로 Prometheus 선택 후 Import 클릭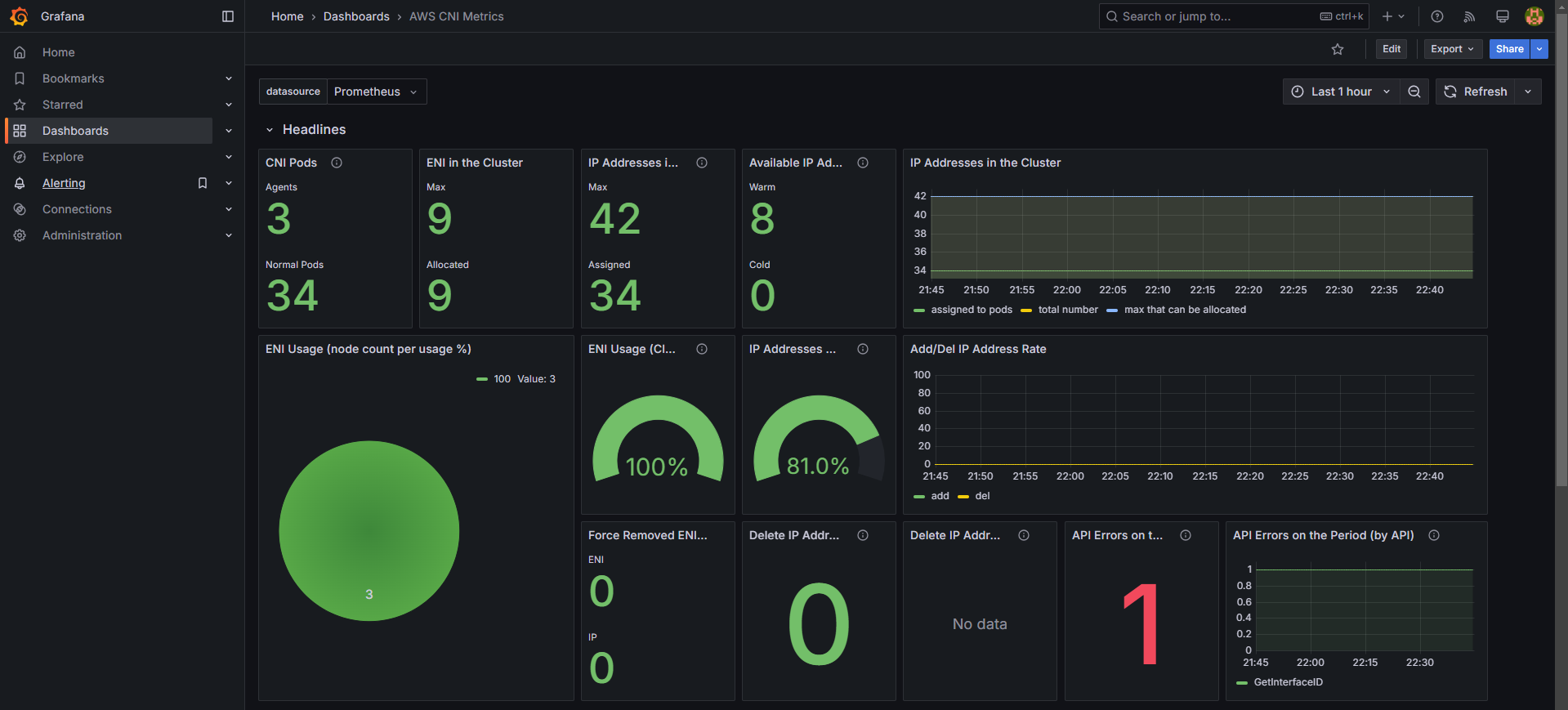
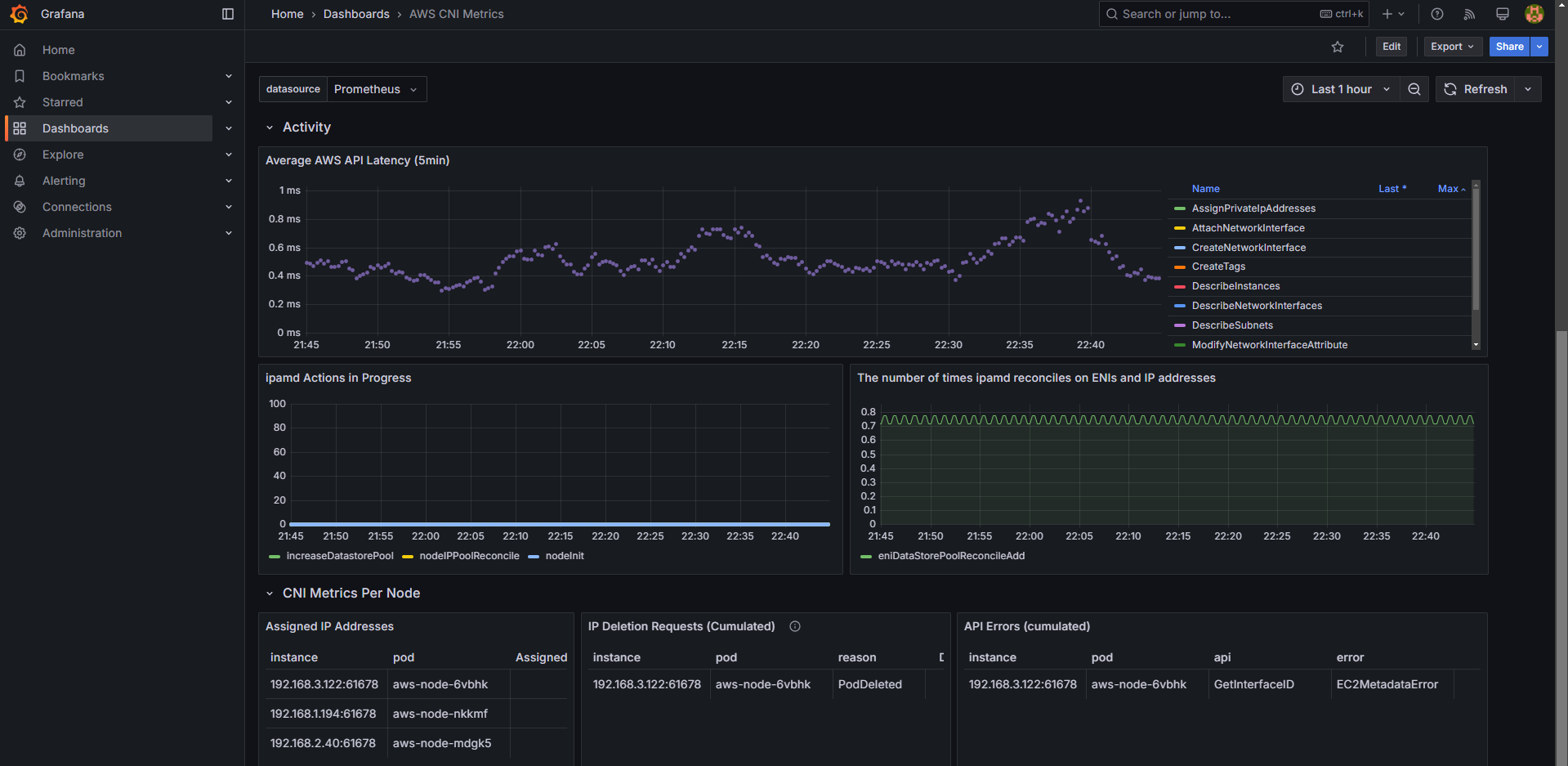
6. 애플리케이션 모니터링
NGINX 애플리케이션 모니터링을 위해 12708 대시보드를 추가할 수 있습니다.
# NGINX 모니터링 대시보드 추가
Dashboard → New → Import → 12708 입력 후 Load → 데이터 소스로 Prometheus 선택 후 Import 클릭NGINX 인스턴스를 확장하여 부하 테스트를 진행할 수도 있습니다.
# NGINX 인스턴스 확장
kubectl scale deployment nginx --replicas 9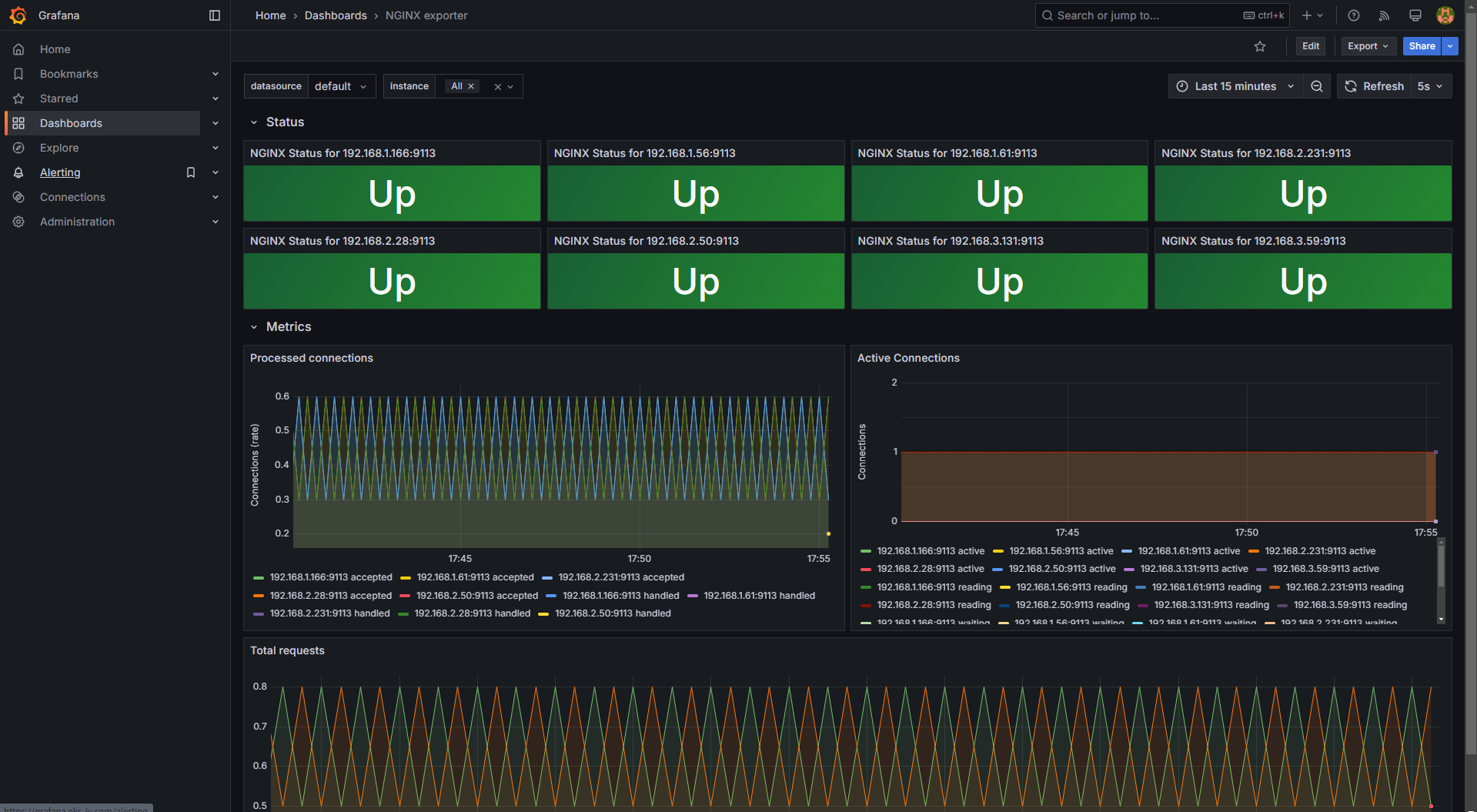
7. Grafana 패널(Panels) 구성 및 활용
7.1 패널(Panels) 개요
Grafana의 패널(Panels)은 데이터 시각화를 위한 핵심 요소로, 다양한 형태의 데이터를 시각적으로 표현할 수 있도록 지원합니다. 패널은 특정 쿼리의 결과를 다양한 차트, 테이블, 게이지 등의 형태로 표현하며, 각 패널은 개별적으로 구성 및 조정할 수 있습니다.
7.2 패널 유형
Grafana는 데이터 표현 방식에 따라 다양한 패널 유형을 제공합니다.
1. 그래프 및 차트(Charts & Graphs)
| 패널 유형 | 설명 |
|---|---|
| Time series | 시계열 데이터 시각화 (기본 그래프) |
| State timeline | 상태 변화를 시간에 따라 표시 |
| Status history | 주기적인 상태 변화를 시각적으로 표현 |
| Bar chart | 범주형 데이터를 바(bar) 형태로 표현 |
| Histogram | 값의 분포를 막대그래프로 표현 |
| Heatmap | 2차원 데이터를 색상 강도로 표현 |
| Pie chart | 비율과 비중을 원형 차트로 표현 |
| Candlestick | 주로 금융 데이터를 위한 가격 변동 시각화 |
| Gauge | 특정 값이 임계값에 도달했는지 확인 가능 |
2. 통계 및 숫자(Stats & Numbers)
| 패널 유형 | 설명 |
|---|---|
| Stat | 주요 지표를 강조하여 표시 |
| Bar gauge | 가로 또는 세로 막대 형태로 데이터 표시 |
3. 기타(Miscellaneous)
| 패널 유형 | 설명 |
|---|---|
| Table | 데이터를 표 형태로 표현 |
| Logs | 로그 데이터를 시각적으로 표현 |
| Node graph | 노드 간 관계를 시각화 |
| Traces | 트레이싱 데이터를 시각적으로 표현 |
| Flame graph | 프로파일링 데이터를 시각화 |
| Canvas | 정적 및 동적 레이아웃을 배치 가능 |
| Geomap | 지리 공간 데이터를 시각화 |
4. 위젯(Widgets)
| 패널 유형 | 설명 |
|---|---|
| Dashboard list | 사용 가능한 대시보드를 리스트로 표시 |
| Alert list | 활성화된 알림(Alerts) 목록을 표시 |
| Text | Markdown 및 HTML을 이용해 텍스트 표시 |
| News | RSS 피드를 표시 |
7.3 패널 실습: 대시보드 생성 및 패널 추가
7.3.1 대시보드 생성
- Dashboards → New → New dashboard 선택

- Add visualization 클릭
- 데이터 소스를 Prometheus로 설정

- 원하는 패널 유형을 선택하여 추가
7.3.2 패널 추가 실습
Grafana에서 주요 패널을 추가하고, PromQL을 활용한 쿼리를 입력하여 데이터를 시각화할 수 있습니다.
패널 1: Time series (노드별 5분간 CPU 사용 변화율)
- 설정 방법:
Time series선택- Title:
노드별 5분간 CPU 사용 변화율 - 쿼리 입력:
sum(rate(node_cpu_seconds_total[5m])) by (instance) - 옵션:
- 상단 Time settings:
Last 30 minutes,Last 3 hours... - 상단 Auto refresh:
5s...
- 상단 Time settings:
- 쿼리 시도
node_cpu_seconds_total
rate(node_cpu_seconds_total[5m])
sum(rate(node_cpu_seconds_total[5m]))
sum(rate(node_cpu_seconds_total[5m])) by (instance)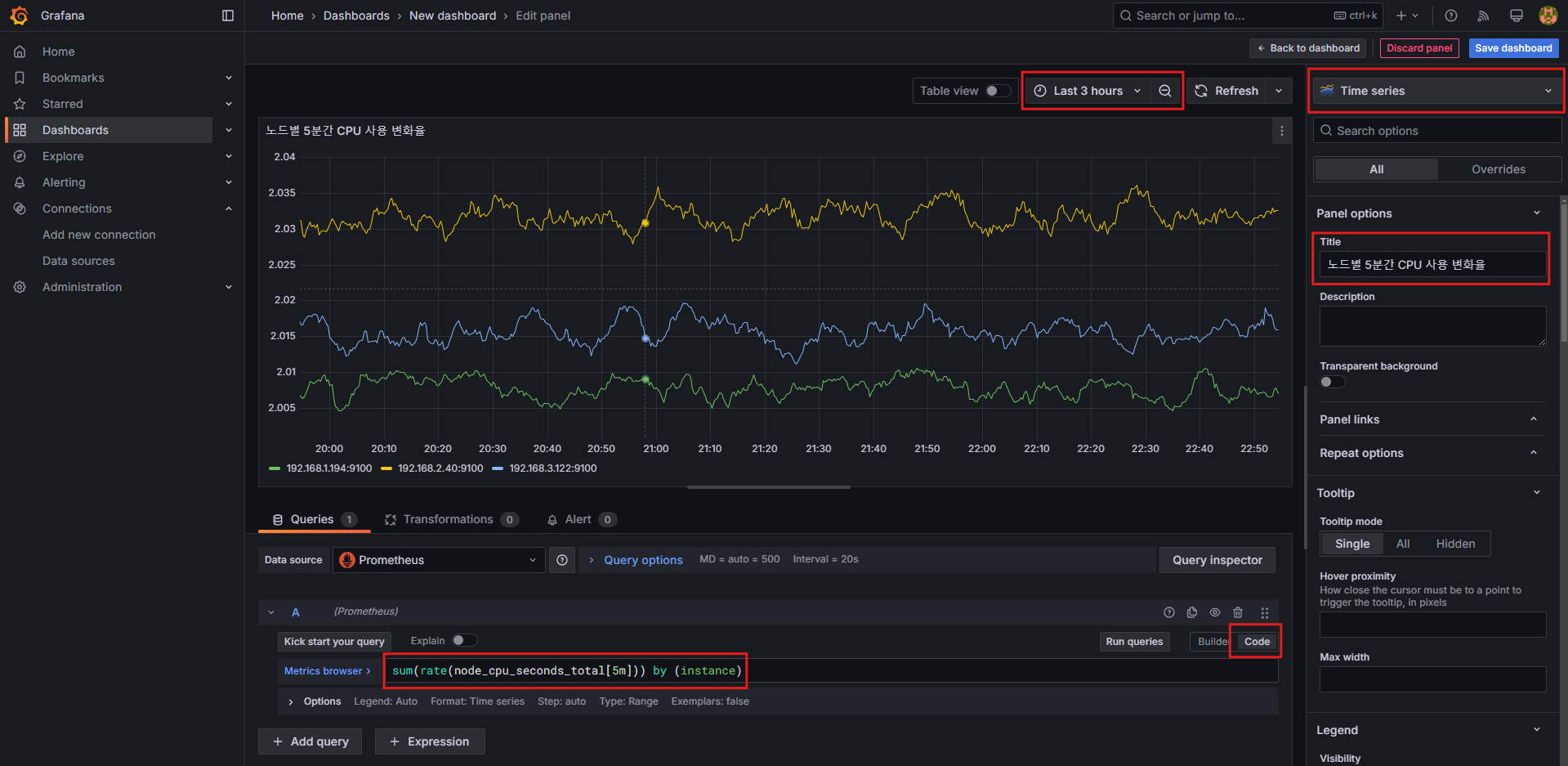
패널 2: Bar chart (네임스페이스 별 디플로이먼트 갯수)
- 설정 방법:
Bar chart선택- Title:
네임스페이스 별 디플로이먼트 갯수 - 쿼리 입력:
count(kube_deployment_status_replicas_available) by (namespace) - 쿼리 옵션:
- Legend:
Auto - Format:
Table,Time series - Type:
Instance
- Legend:
- 쿼리 시도
kube_deployment_status_replicas_available
count(kube_deployment_status_replicas_available) by (namespace)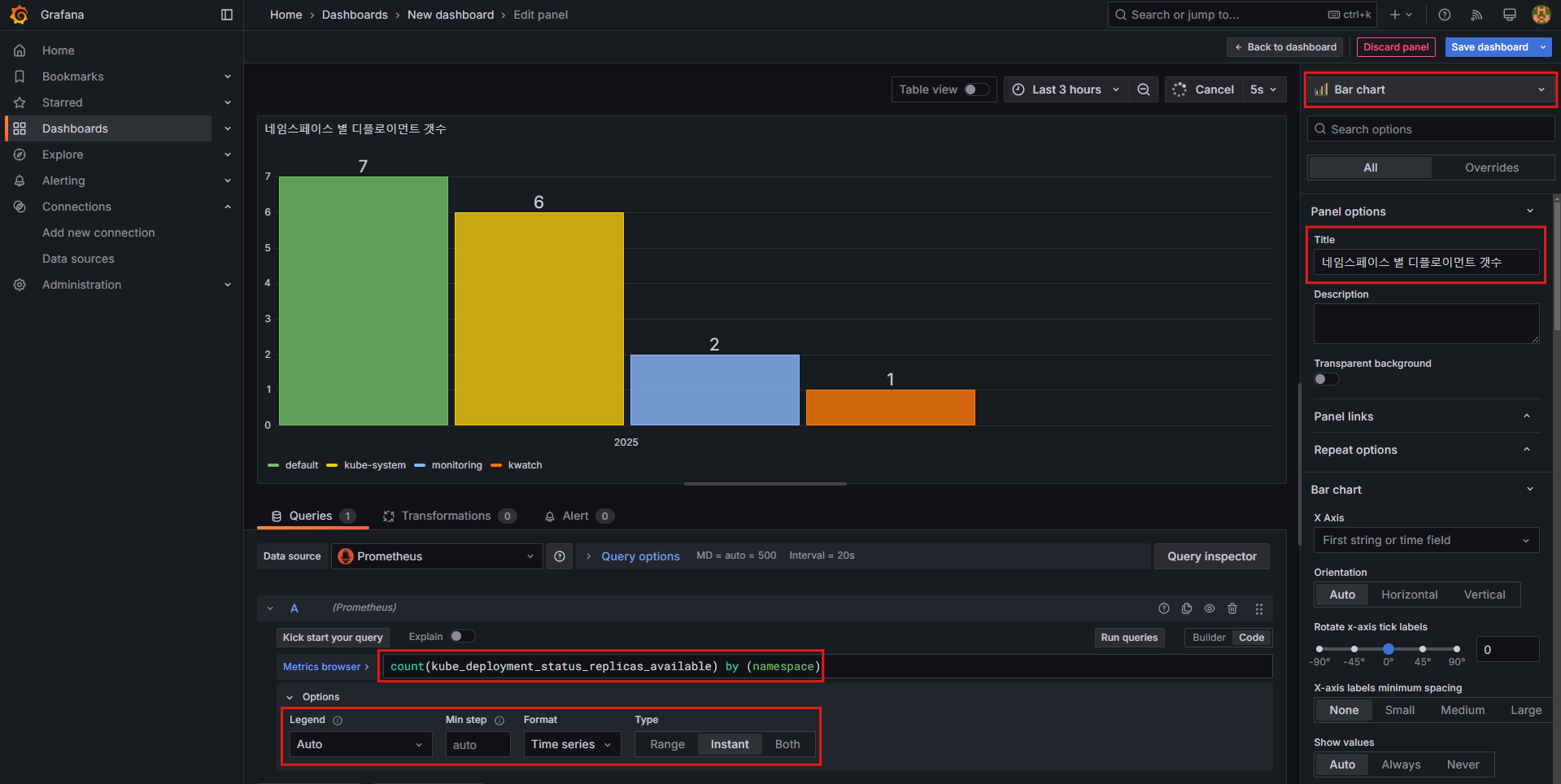
패널 3: Stat (nginx 파드 수)
- 설정 방법:
Stat선택- Title:
nginx 파드 수 - 쿼리 입력:
kube_deployment_spec_replicas{deployment="nginx"}
- 쿼리 시도
kube_deployment_spec_replicas
kube_deployment_spec_replicas{deployment="nginx"}- 확인 후 확장 테스트:
- NGINX 파드 수 증가:
kubectl scale deployment nginx --replicas 6
- NGINX 파드 수 증가:
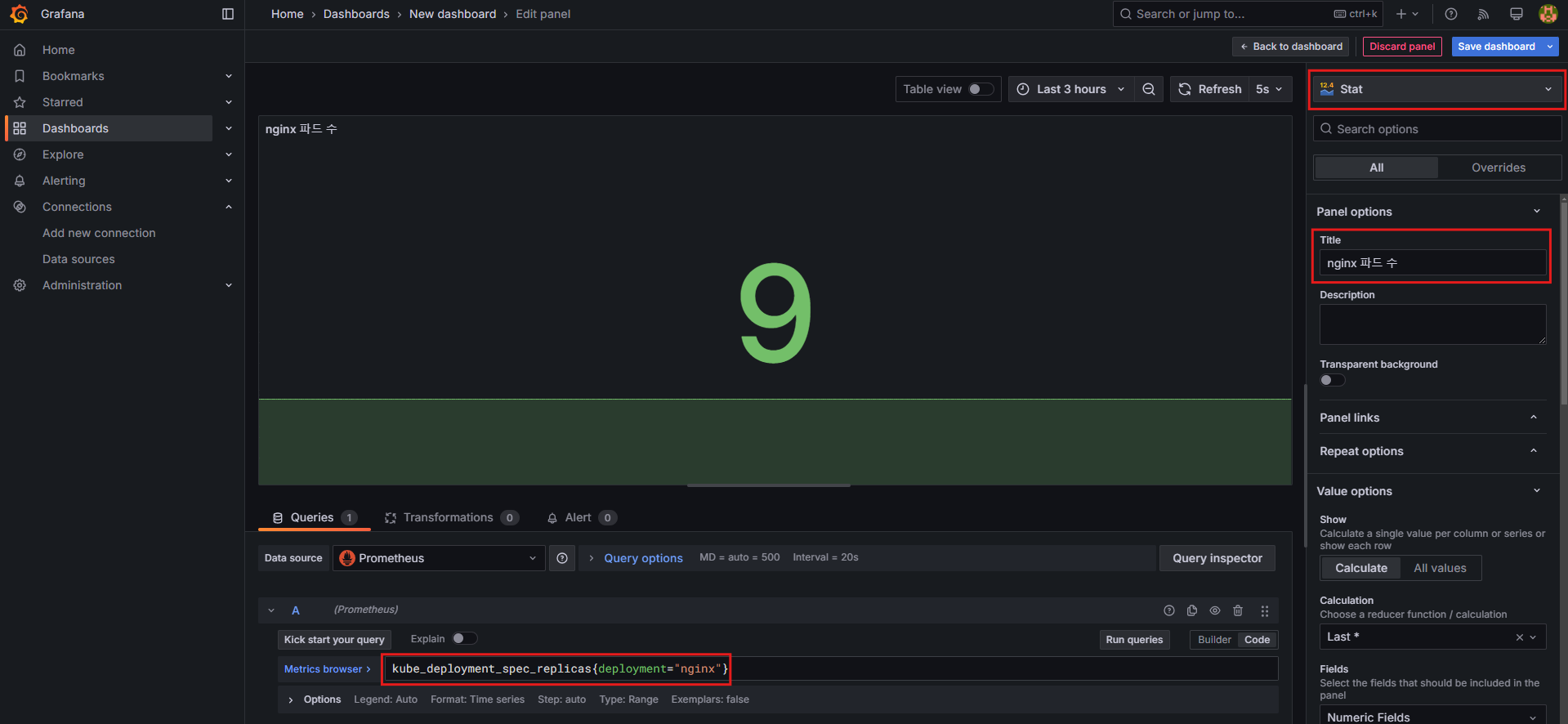
패널 4: Gauge (노드 별 1분간 CPU 사용률)
- 설정 방법:
Gauge선택- Title:
노드 별 1분간 CPU 사용률 - 쿼리 입력:
1 - (avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance))
- 쿼리 시도
node_cpu_seconds_total
node_cpu_seconds_total{mode="idle"}
node_cpu_seconds_total{mode="idle"}[1m]
rate(node_cpu_seconds_total{mode="idle"}[1m])
avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)
1 - (avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance))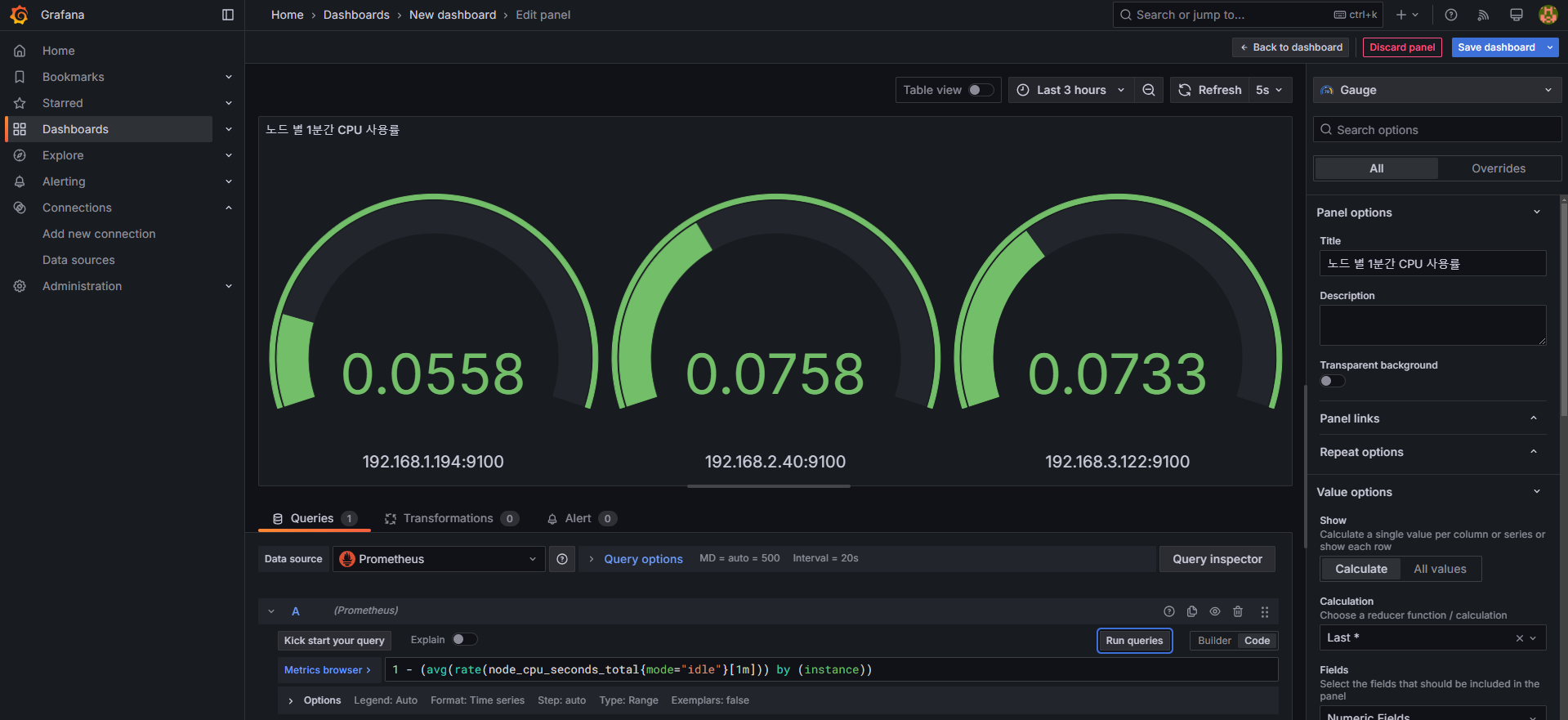
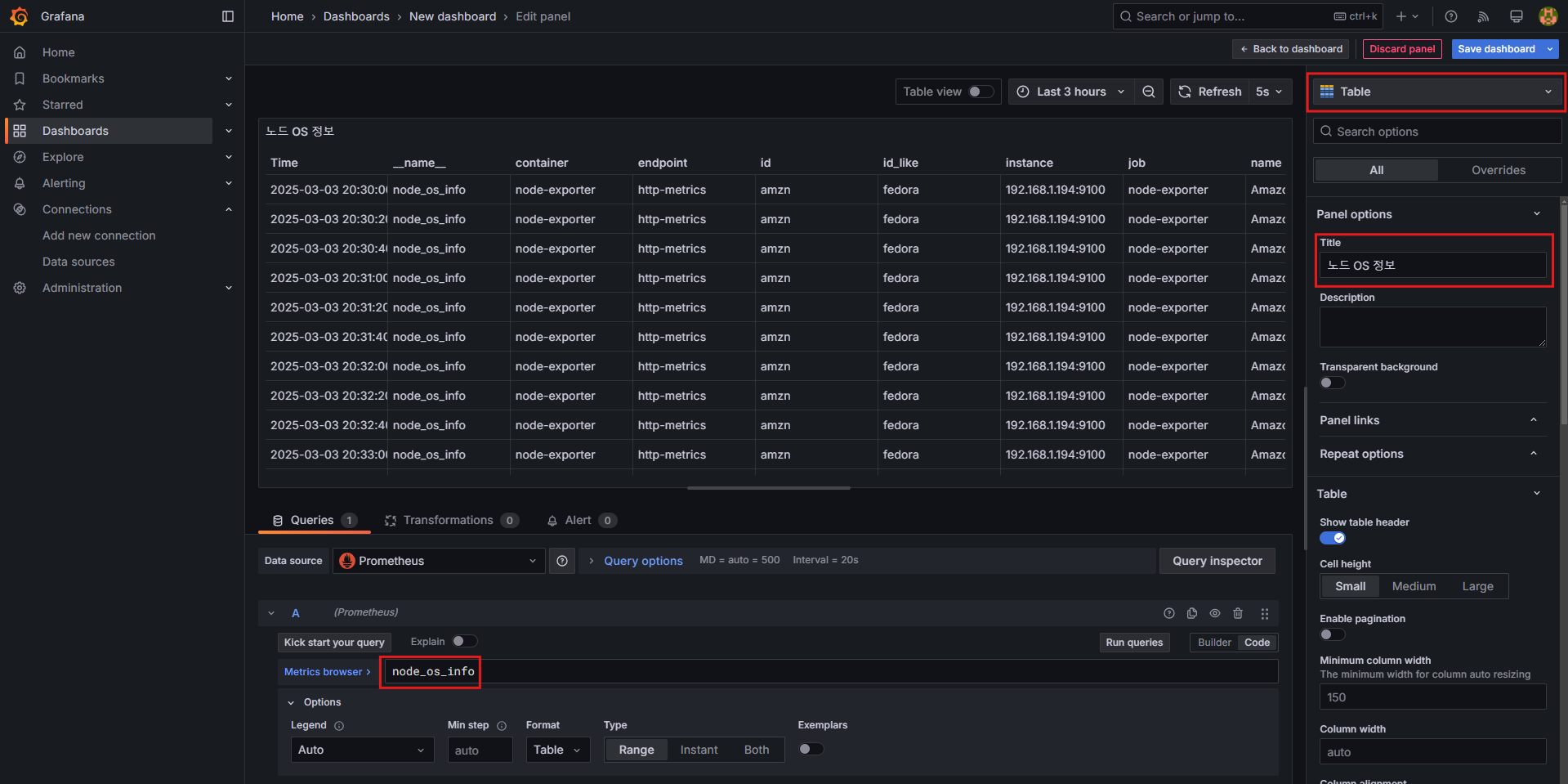
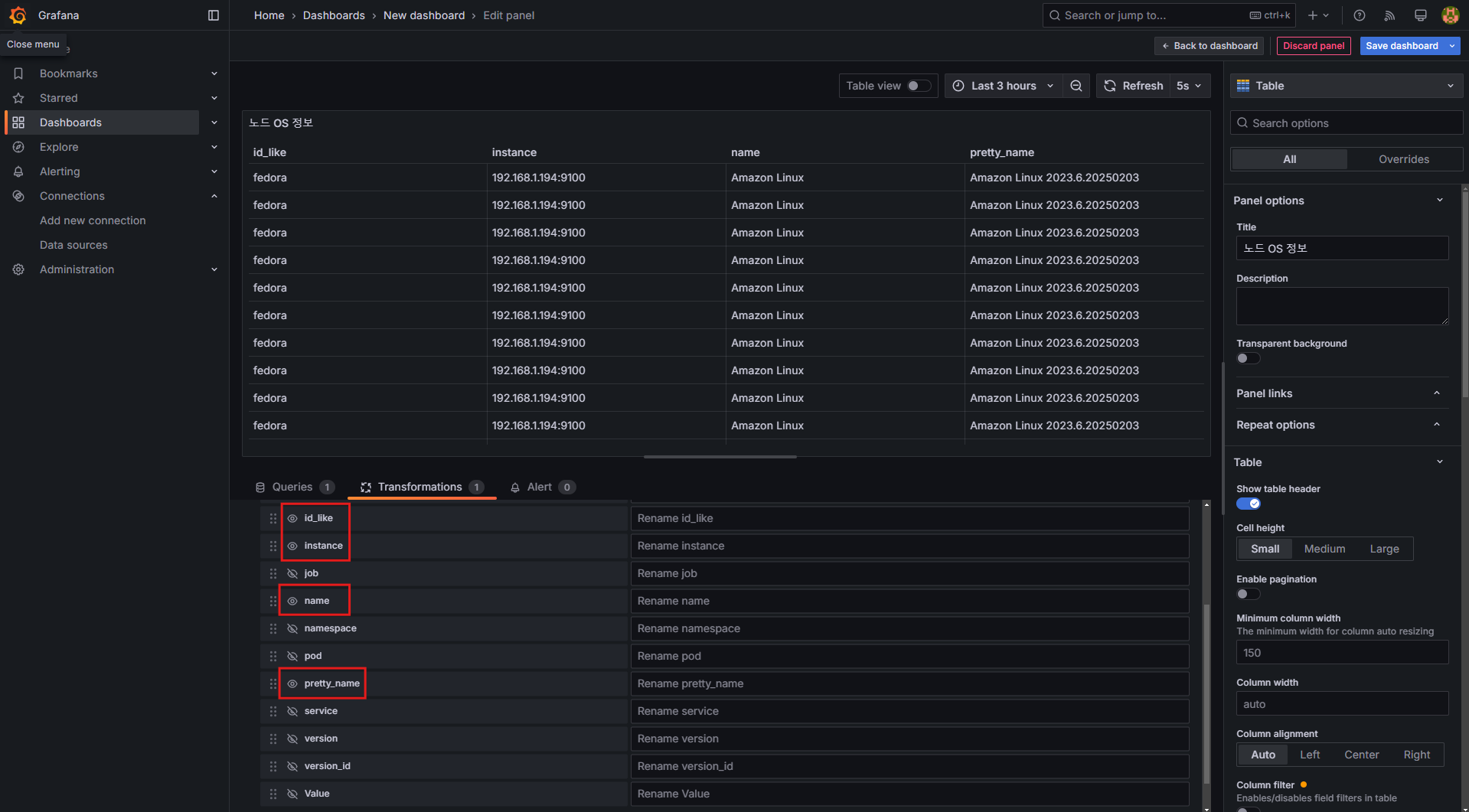
패널 5: Table (노드 OS 정보)
- 설정 방법:
Table선택- Title:
노드 OS 정보 - 쿼리 입력:
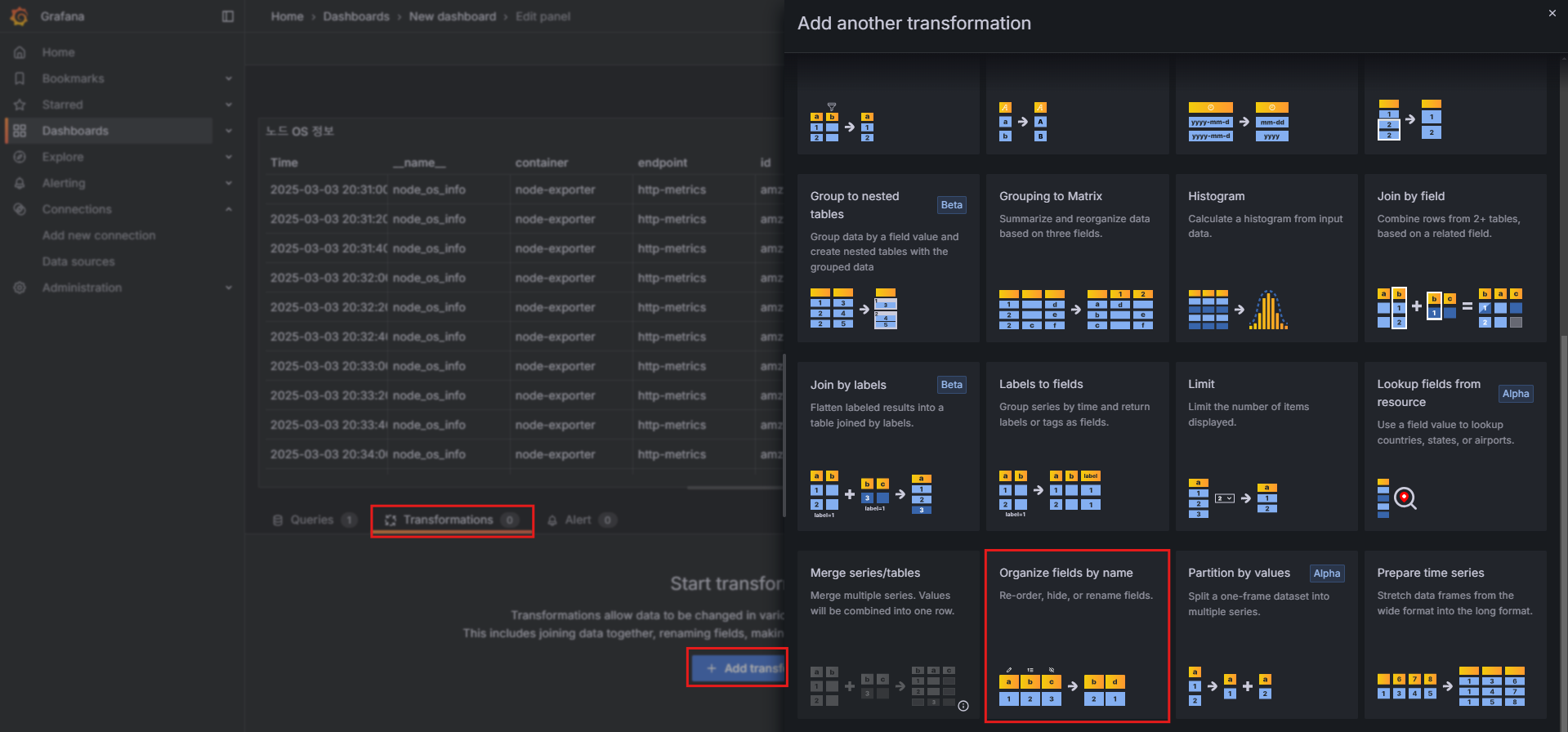
node_os_info - Transformations:
- 출력되는 값을 수정할 수 있습니다.
Organize fields by name:id_like,instance,name,pretty_name외 비활성화
7.3.3 패널 배치 및 저장
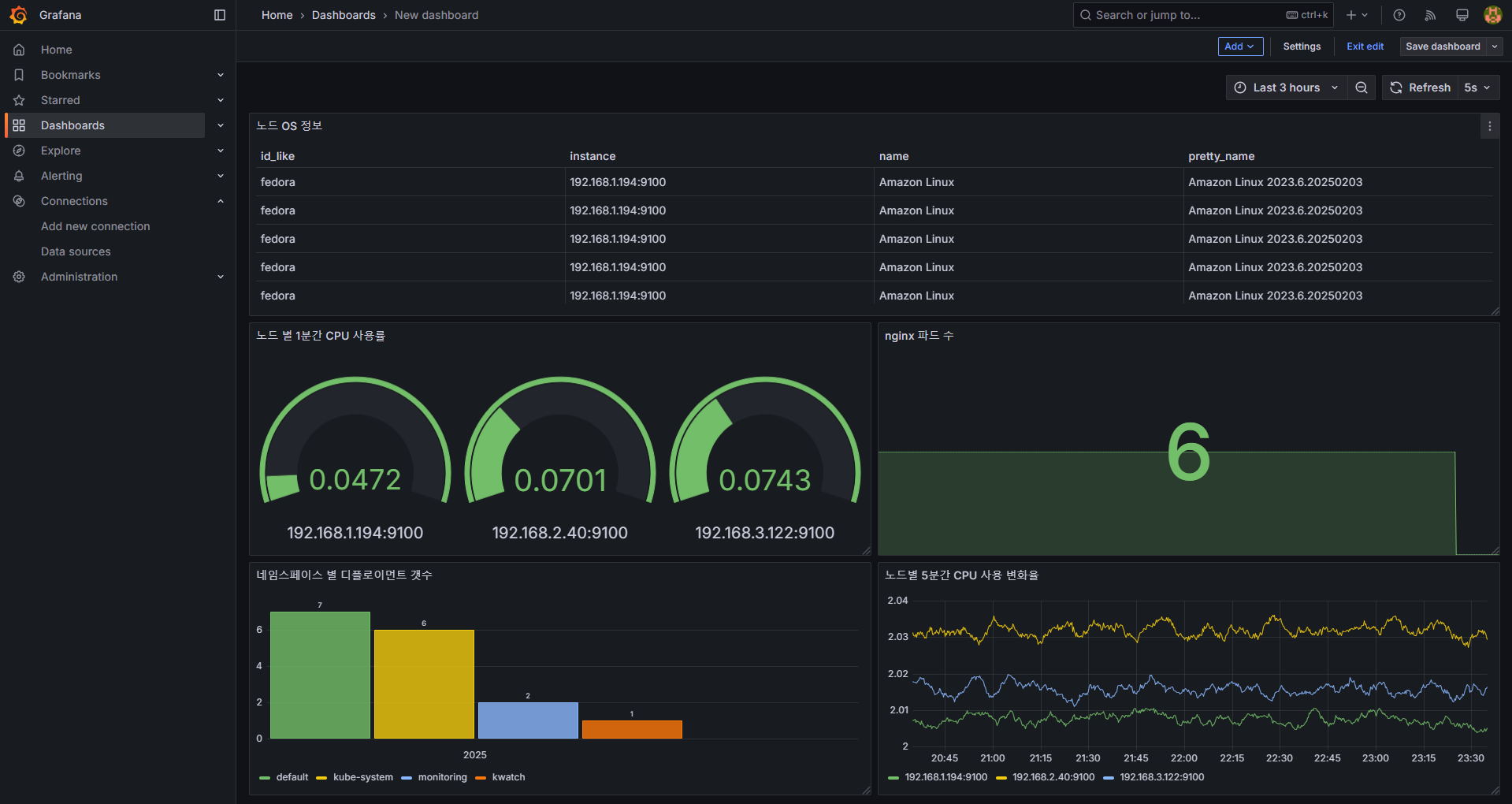
- 생성한 패널들을 원하는 위치로 배치 후 저장합니다.
- 대시보드 상단의 저장(Save) 버튼을 클릭하여 저장합니다.
8. Grafana Alerting (그라파나 알림) 구성 및 활용
8.1 Grafana Alerting 개요
Grafana의 Alerting(알림) 기능은 모니터링 대상에서 이상 징후가 감지되었을 때, 즉각적인 알림을 전송하는 기능입니다.
Grafana 9.4 및 9.5 버전에서 Alerting 기능이 대폭 강화되었으며, 특히 이미지 포함 알람 기능이 추가되었습니다.
🔗 Grafana 9.4 버전 릴리즈 노트: Grafana 9.4 Release
🔗 Grafana 9.5 버전 릴리즈 노트: Grafana 9.5 Release
🔗 Grafana Alerting 공식 문서: Grafana Alerting Docs
🔗 Grafana Alerting 실습 워크숍: Workshop
8.2 Grafana Alerting 설정 및 구성
8.2.1 Contact Points 설정 (알림 전송 대상 등록)
Alert 발생 시 알림을 받을 수 있도록 Slack, Email, Webhook 등의 Contact Point를 등록해야 합니다.
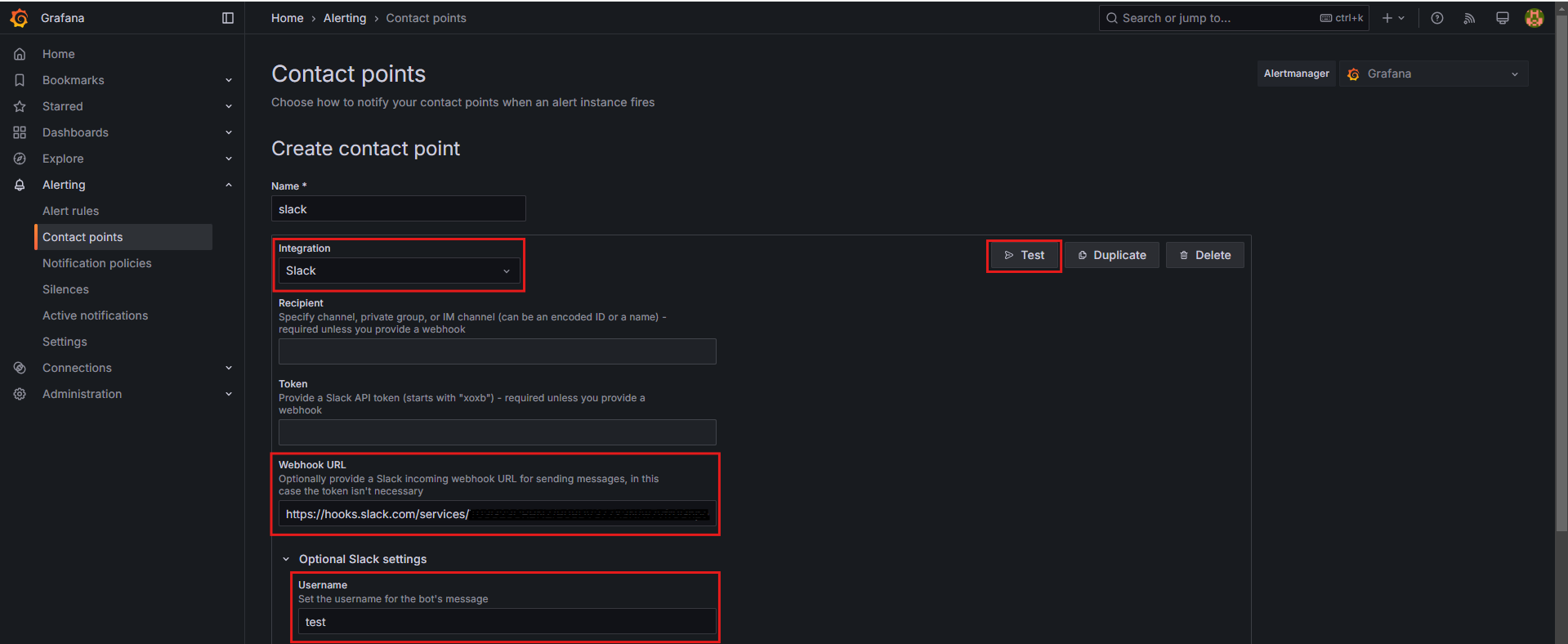
① Contact Point 추가
- Grafana → Alerting → Contact points → Create contact point 클릭

- Integration 선택:
Slack - Webhook URL 입력
- Optional Slack settings:
Username필드에 각자의 닉네임을 입력하여 메시지를 구분
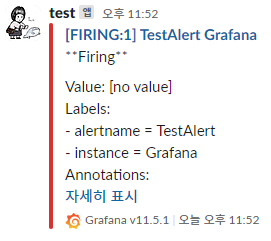
- 테스트 및 저장:
- 오른쪽 상단에서
Test버튼을 클릭하여 정상적으로 메시지가 발송되는지 확인한 후 저장합니다.
- 오른쪽 상단에서
8.2.2 Notification Policies 설정 (알림 정책 구성)
Alert 발생 시, 어떤 Contact Point로 알림을 보낼 것인지 설정하는 과정입니다.
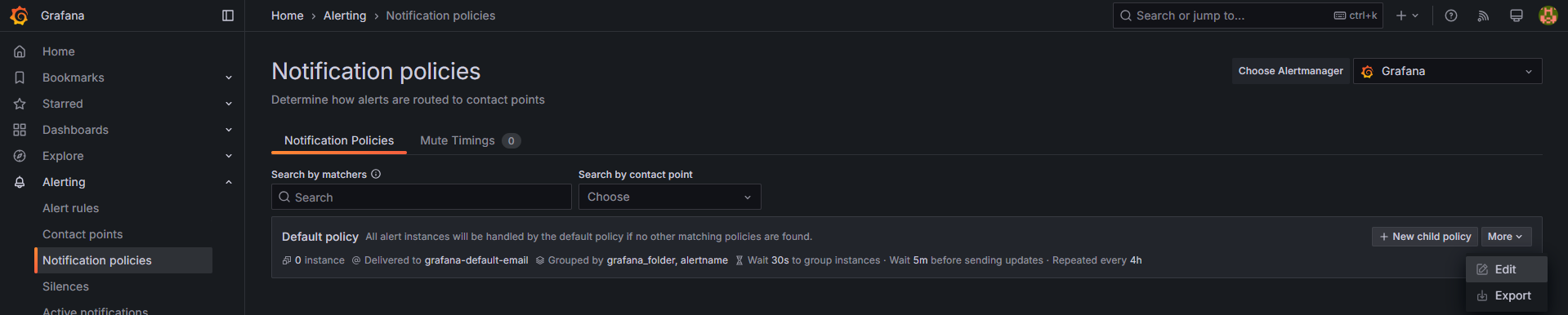
기본 정책 수정
-
Notification policies →
Default policyEdit 클릭
-
Default contact point를 "slack"으로 변경
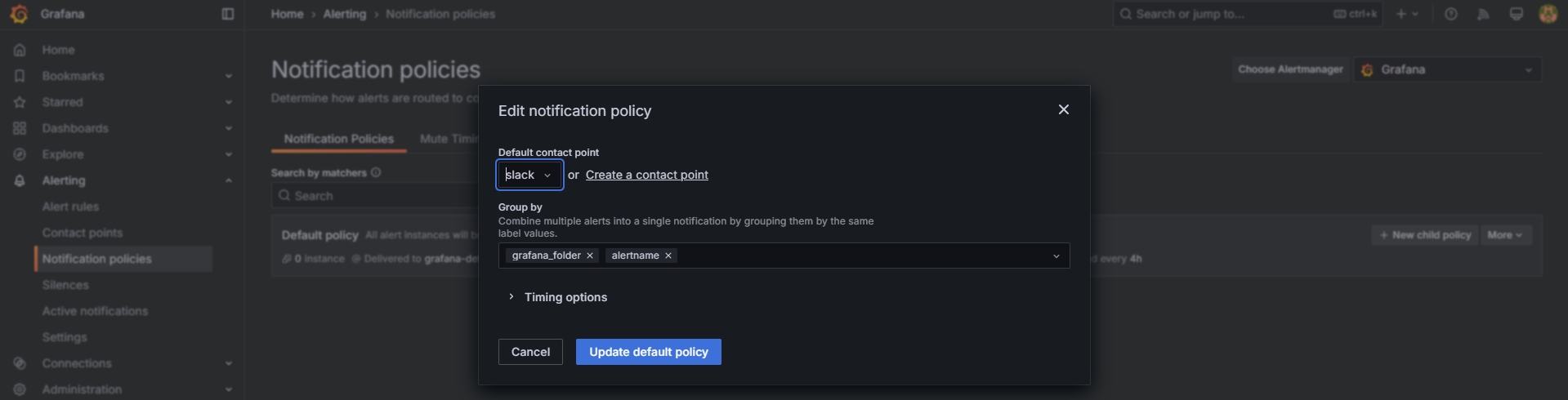
-
저장(Save) 클릭
이제 모든 Alerting 메시지가 Slack으로 전송됩니다.
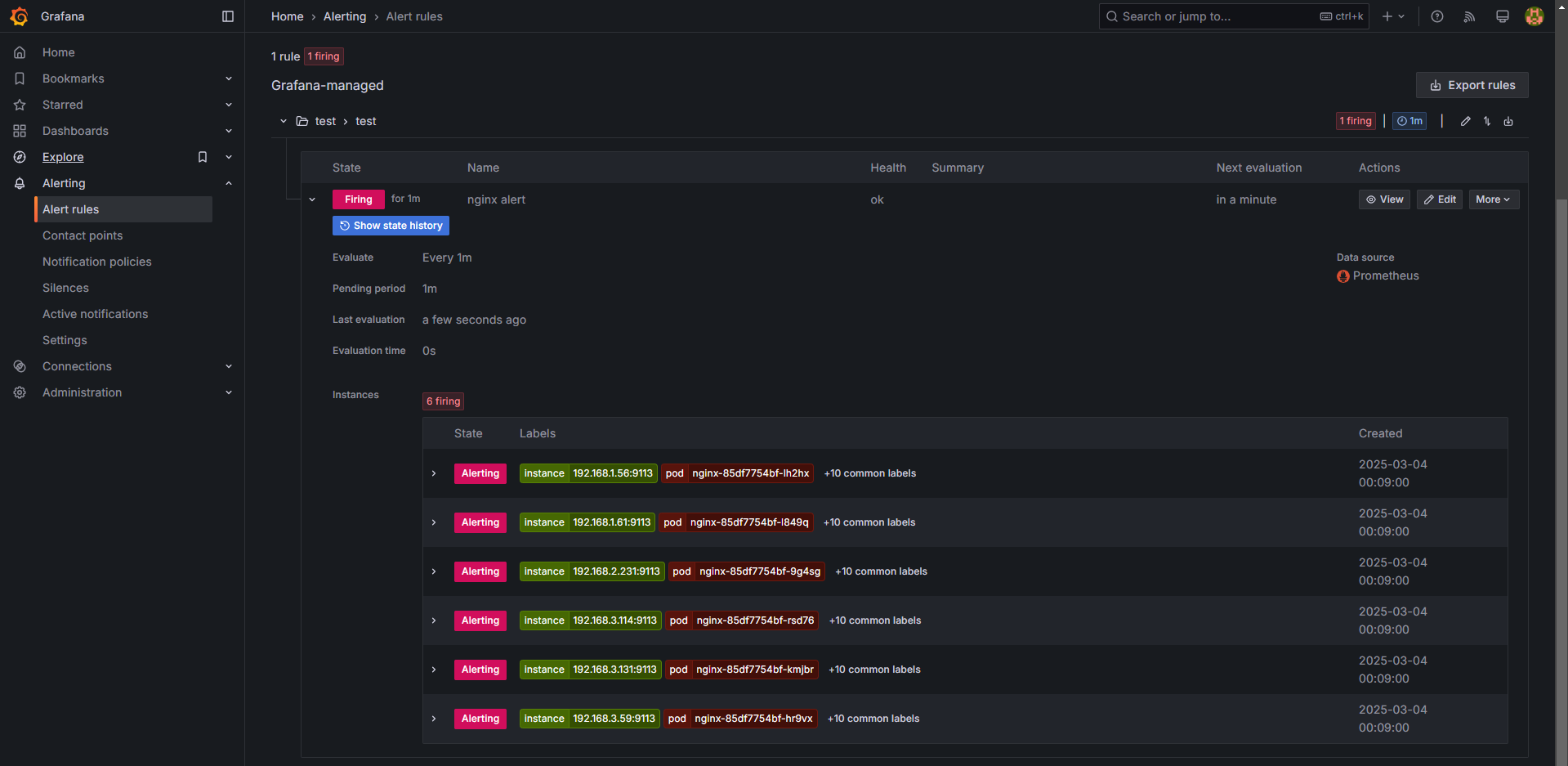
8.2.3 Alert Rule 생성 (알림 규칙 설정)
Alert Rule은 특정 조건이 충족될 경우 알림을 발생시키는 규칙입니다.
여기서는 nginx 웹 요청이 1분 동안 누적 60건 이상일 경우 알림을 설정하는 방법을 설명합니다.
① Alert Rule 생성
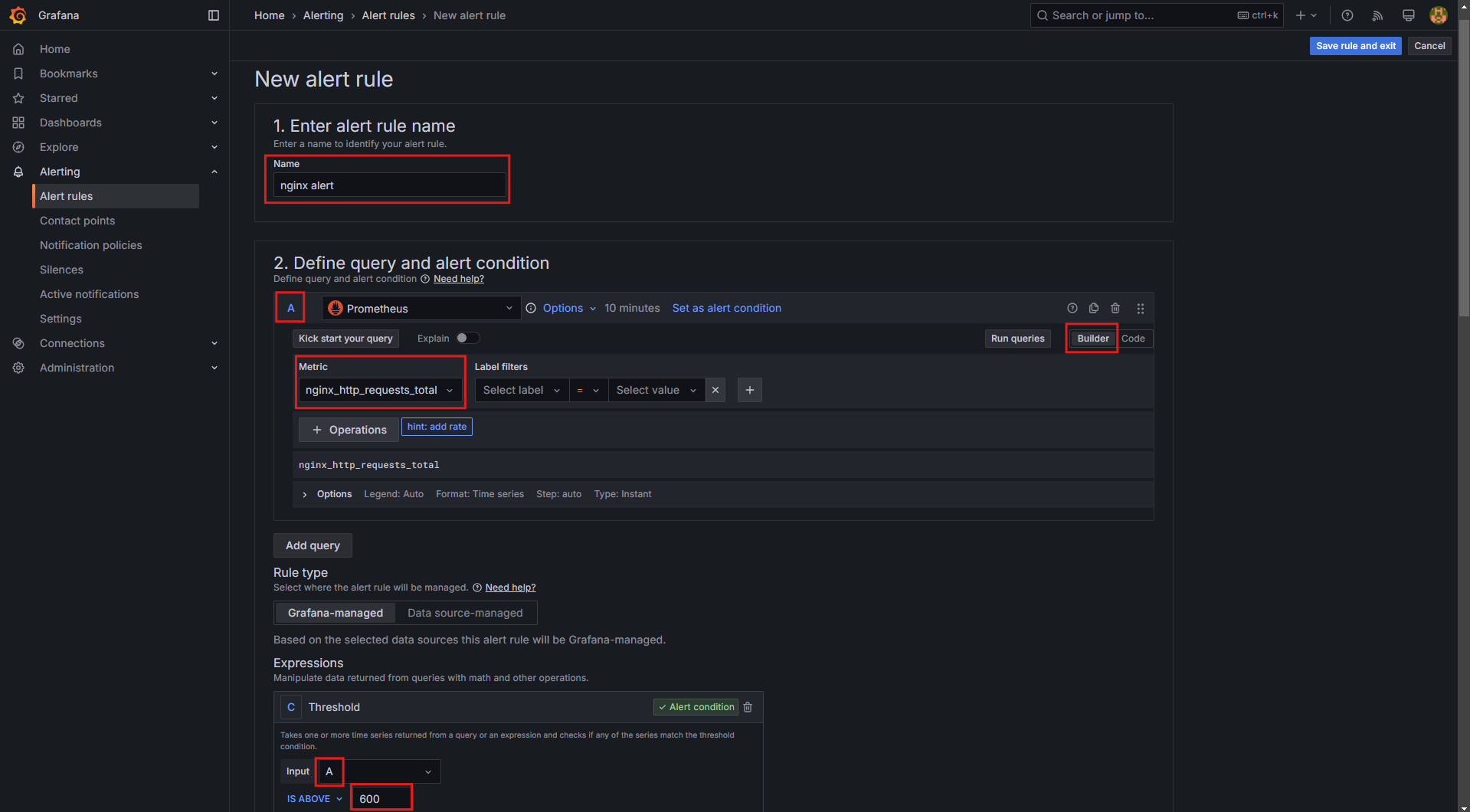
- Grafana → Alerting → Alert rules → New alert rule 클릭
- Name:
nginx alert - Expression(조건식) 설정:
nginx_http_requests_total메트릭을 사용하여 1분 동안 60건 이상의 요청이 발생하면 알람 발생- 예제 쿼리:
sum(increase(nginx_http_requests_total[1m])) > 60
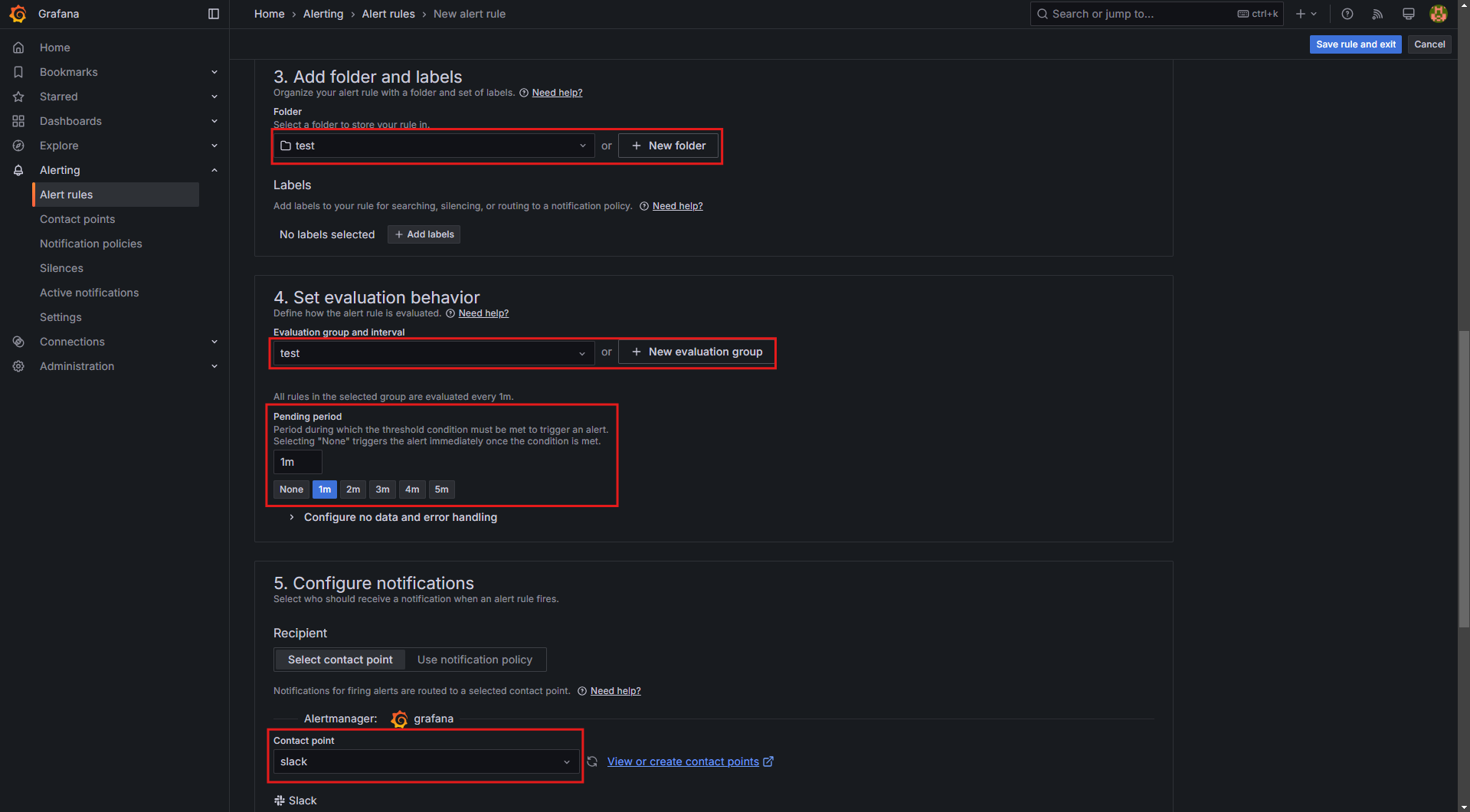
- 폴더(Folder) 및 평가 그룹(Evaluation group) 설정:
+Add new를 클릭하여 새로운 Folder 및 Evaluation group을 생성Pending period:1m(1분 동안 조건이 유지될 경우 Alert 발생)
- Notification 설정:
Configure notifications→Contact point를 Slack으로 선택
- 설정 완료 후 Save and Exit 클릭
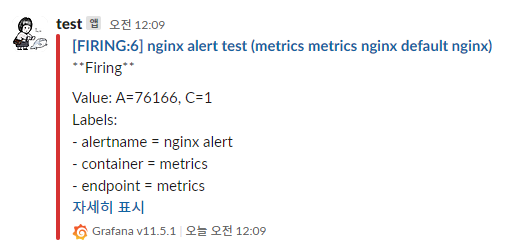
8.2.4 Alert 발생 테스트 (nginx 웹 요청 증가)
위에서 설정한 Alert Rule이 정상적으로 동작하는지 확인하기 위해, nginx에 반복적인 요청을 발생시킵니다.
nginx 웹 요청 반복 실행
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; done- 위 명령어를 실행하면 nginx 웹서버에 지속적으로 요청을 보냅니다.
- 일정 요청량이 초과되면 Grafana에서 Slack으로 알림이 전송됩니다.

9. Prometheus Alertmanager vs Grafana Alerting
Prometheus Alertmanager와 Grafana Alerting은 모두 알림을 관리하는 기능을 하지만, 사용 목적이 다릅니다.
4.1 Prometheus Alertmanager
- Prometheus에서 제공하는 기본 알림 관리 도구
Alertmanager는 Prometheus와 직접 통합되어, 특정 조건 충족 시 알람을 생성하고 다양한 경로로 전송 (Email, Slack, Webhook 등)- 장점:
- Prometheus의 메트릭 기반 경고 기능과 긴밀하게 통합됨
- Alert Grouping, Silence, Inhibition 등의 고급 기능 지원
- 단점:
- 설정이 복잡하며, UI가 직관적이지 않음
- Grafana와 직접적인 연동 기능이 제한적임
4.2 Grafana Alerting
- Grafana 8.0 이상에서 제공하는 자체 Alerting 시스템
- Prometheus, Loki, ElasticSearch 등 다양한 데이터 소스에서 직접 알림을 설정 가능
- 장점:
- UI가 직관적이며 설정이 용이
- 대시보드에서 직접 알람 설정 및 관리 가능
- Slack, Telegram, Email 등 다양한 Notification 채널 지원
- 이미지 포함 알람 전송 기능 제공
- 단점:
- Prometheus Alertmanager보다 고급 기능이 부족할 수 있음
4.3 선택 기준
| 기능 | Prometheus Alertmanager | Grafana Alerting |
|---|---|---|
| 설정 난이도 | 상대적으로 복잡 | UI 기반으로 쉬움 |
| 통합 가능 데이터 소스 | Prometheus 전용 | Prometheus, Loki, ElasticSearch 등 지원 |
| Notification 기능 | 기본 알림 전송 (Email, Slack 등) | 이미지 포함 알람 전송 가능 |
| Alert Grouping | 지원 | 제한적 |
| UI 및 관리 기능 | CLI 및 YAML 기반 | 직관적인 UI 제공 |
- Prometheus Alertmanager는 Prometheus 환경에서 메트릭 기반 알림을 설정할 때 적합
- Grafana Alerting은 보다 직관적이고 다양한 데이터 소스를 지원하는 경우 적합
