
이 블로그글은 2019년 조재영(Kevin Jo), 김승수(SeungSu Kim)님의 딥러닝 홀로서기 세미나를 수강하고 작성한 글임을 밝힙니다.
💡 도움이 되셨다면 ♡와 팔로우 부탁드려요! 미리 감사합니다.
Assignment #2 Review
Goal
- Cifar-10 데이터셋을 사용하여 10 Classification 문제를 풀기
- 3개의 channel(RGB), 32 x 32 사이즈 (total 3072 차원)
- GPU 사용하기
- 다양한 regularization 기법 적용하기
질문/해결책
BatchNorm layer
__init__에서 BatchNorm layer를 한번만 정의해도 될까?
→ BatchNorm 마다 미니배치의 통계량(평균, 분산)이 다르기 때문에 hidden layr랑 1:1로 만들어 줘야한다.
코드 예시
class MLP(nn.Module):
def __init__(self, in_dim, out_dim, hid_dim, n_layer, act, dropout, use_bn, use_xavier):
... 생략 ...
self.linears = nn.ModuleList()
self.bns = nn.ModuleList()
for i in range(self.n_layer-1):
self.linears.append(nn.Linear(self.hid_dim, self.hid_dim))
if self.use_bn:
self.bns.append(nn.BatchNorm1d(self.hid_dim))
... 생략 ...- 코드와 같이 bachnorm의 경우에도 ModuleList()를 통해 리스트로 생성하여 append 해준다.
- 참고로 linear layer(fully connected layer)를 사용하기 때문에 BatchNorm1d를 적용한다.
💡 BatchNorm 동작 순서
- 평균 계산: 미니배치의 평균 μ 계산
- 분산 계산: 미니배치의 분산 σ2 계산
- 정규화: 입력을 평균 0, 분산 1로 정규화
- 스케일 및 시프트: 감마(γ)와 베타(β)로 스케일링과 시프팅 적용
- 출력: 조정된 결과를 다음 층으로 전달
Dropout
- Dropout이 input layer와 output layer 부분에 들어가도 될까?
→ Dropout의 경우 hidden layer에만 사용하여 오버피팅을 막게한다.
- input layer : 입력 층에 Dropout을 하게 되면 데이터 자체에 노이즈를 추가하는 효과, 즉, (중요한 정보가 손실 될 수 있음)
- Output layer : 출력 층에 Droput을 하게 되면 최종된 예측 결과에 Dropout을 적용하게 되므로 예측값 자체가 왜곡될 수 있음
코드 예시
class MLP(nn.Module):
def __init__(self, in_dim, out_dim, hid_dim, n_layer, act, dropout, use_bn, use_xavier):
... 생략 ...
self.dropout = nn.Dropout(self.dropout)
... 생략 ...- Dropout의 경우 BatchNorm과 달리 미니배치의 통계량을 사용하지 않고 설정된 비율대로 무작위로 노드를 비활성화하는 방법이기 때문에 여러번의 정의가 필요없다.
Xavier 초기화
- 어느 위치에서 초기화를 해주어야 할까?
→ 맨 처음 layer를 설정할때 __init__ 안에서 이루어져야 한다.
코드 예시
class MLP(nn.Module):
def __init__(self, in_dim, out_dim, hid_dim, n_layer, act, dropout, use_bn, use_xavier):
... 생략 ...
if self.use_xavier:
self.xavier_init()
def xavier_init(self):
for linear in self.linears:
nn.init.xavier_normal_(linear.weight)
linear.bias.data.fill_(0.01)nn.init.xavier_normal_(linear.weight): linear 계층의 가중치를 입력과 출력 노드 수에 맞춰 정규 분포로 초기화해 신호 크기를 안정적으로 유지한다.linear.bias.data.fill_(): linear 계층의 편향을 설정해 초기 학습 시 약간의 활성화를 유도한다.
Colab GPU 설정
- colab에서 GPU 설정을 하였으나 여전히 학습이 느린 이유는?
→ Batch Size를 너무 작게 설정하면 효과가 없다.
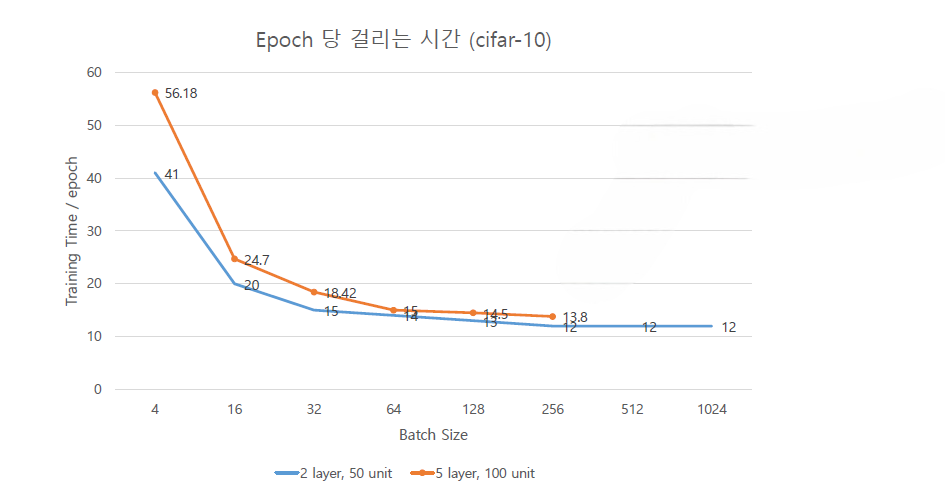
코드 예시
trainloader = torch.utils.data.DataLoader(partition['train'],
batch_size=128,
shuffle=True,
num_workers=2)- 128, 256, 512 등의 상대적으로 높은 값으로 설정한다.
💡 참고
- Batch Size : GPU의 연산 자원을 최대한 활용하는 데 초점
- num_workers : CPU를 이용해 데이터 준비 시간을 최적화
Activation, BatchNorm, Dropout 순서
- layer의 출력에 대해 어떤 순서로 적용해야할까?
→ MLP에서는 Linear -> Activation -> BatchNorm -> Dropout 순서로 적용하는게 좋다.
- Activation: 먼저 비선형 변환을 통해 레이어의 표현력을 강화한다.
- BatchNorm: 활성화된 출력을 정규화하여 학습 안정성을 높이고, 과적합을 방지한다.
- Dropout: 정규화된 값에 무작위로 뉴런을 비활성화해 과적합을 줄이고, 일반화 성능을 향상시킨다.
코드 예시
def forward(self, x):
x = self.act(self.fc1(x))
for i in range(len(self.linears)):
x = self.act(self.linears[i](x))
x = self.bns[i](x)
x = self.dropout(x)
x = self.fc2(x)
return x- x에 대한 linear에 출력에 대해 Activation, BatchNorm, Dropout 순서로 적용한다.
코드 개선
- 지난 Lec15.에서 Experiment로 모듈화하기를 다루었다.
- 여전히 개선사항이 필요해 보인다.
→ 작업에 맞게 Train, Validate, Test로 분리하여 함수를 정의하고 Experiment 함수에서 호출하여 사용하자
학습
def train(net, partition, optimizer, criterion, args):
trainloader = torch.utils.data.DataLoader(partition['train'],
batch_size=args.train_batch_size,
shuffle=True,
num_workers=2)
net.train()
correct = 0
total = 0
train_loss = 0.0
for i, data in enumerate(trainloader, 0):
optimizer.zero_grad()
# get the inputs
inputs, labels = data
inputs = inputs.view(-1, 3072)
inputs = inputs.cuda()
labels = labels.cuda()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
train_loss = train_loss / len(trainloader)
train_acc = 100 * correct / total
return net, train_loss, train_accnet,partition,optimizer,criterion,args를 인자로 받는다.-
partition의 경우 dataset을 담고 있는 딕셔너리이다.
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) trainset, valset = torch.utils.data.random_split(trainset, [40000, 10000]) testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) partition = {'train': trainset, 'val':valset, 'test':testset}
-
trainloader생성과 학습을 진행하고 loss와 accuracy를 평가한다.net,train_loss,train_acc를 반환한다.net은 학습된 모델을 뜻함
검증
def validate(net, partition, criterion, args):
valloader = torch.utils.data.DataLoader(partition['val'],
batch_size=args.test_batch_size,
shuffle=False,
num_workers=2)
net.eval()
correct = 0
total = 0
val_loss = 0
with torch.no_grad():
for data in valloader:
images, labels = data
images = images.view(-1, 3072)
images = images.cuda()
labels = labels.cuda()
outputs = net(images)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
val_loss = val_loss / len(valloader)
val_acc = 100 * correct / total
return val_loss, val_acc- Train과 달리 학습 과정에서 사용하는
optimizer는 인자로 받지 않는다. valloader생성하고 loss와 accuracy를 평가한다.val_loss,val_acc를 반환한다.
테스트
def test(net, partition, args):
testloader = torch.utils.data.DataLoader(partition['test'],
batch_size=args.test_batch_size,
shuffle=False,
num_workers=2)
net.eval()
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
images = images.view(-1, 3072)
images = images.cuda()
labels = labels.cuda()
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
test_acc = 100 * correct / total
return test_acc- Train과 Validate와 달리 loss를 계산하지 않으므로
criterion은 인자로 받지 않는다. testloader생성과 accuracy를 평가한다.test_acc를 반환한다.
Experiment
def experiment(partition, args):
net = MLP(args.in_dim, args.out_dim, args.hid_dim, args.n_layer, args.act, args.dropout, args.use_bn, args.use_xavier)
net.cuda()
criterion = nn.CrossEntropyLoss()
if args.optim == 'SGD':
optimizer = optim.RMSprop(net.parameters(), lr=args.lr, weight_decay=args.l2)
elif args.optim == 'RMSprop':
optimizer = optim.RMSprop(net.parameters(), lr=args.lr, weight_decay=args.l2)
elif args.optim == 'Adam':
optimizer = optim.Adam(net.parameters(), lr=args.lr, weight_decay=args.l2)
else:
raise ValueError('In-valid optimizer choice')
for epoch in range(args.epoch): # loop over the dataset multiple times
ts = time.time()
net, train_loss, train_acc = train(net, partition, optimizer, criterion, args)
val_loss, val_acc = validate(net, partition, criterion, args)
te = time.time()
print('Epoch {}, Acc(train/val): {:2.2f}/{:2.2f}, Loss(train/val) {:2.2f}/{:2.2f}. Took {:2.2f} sec'.format(epoch, train_acc, val_acc, train_loss, val_loss, te-ts))
test_acc = test(net, partition, args)
return train_loss, val_loss, train_acc, val_acc, test_acc- 학습, 검증, 테스트에 사용하는
net,criterion,optimizer를 정의한다. epoch을 반복하며 train(), validate()를 실행하고 최종 test()를 실행한다.
정리
- Dropout Layer는 Neural Net의 hidden layer 부분에 있어야 한다.
- 각 Linear Layer마다 BatchNorm Layer를 생성해야 한다.
- Batch Size는 약 128~512 정도로 늘려야 한다.
- Xavier 초기화는 init 메서드에서 수행해야 한다.
- MLP에서는 Linear -> Activation -> BatchNorm -> Dropout 순서를 따릅니다.

제 글이 유익하셨다면 ♡와 팔로우로 응원 부탁드립니다.