
이 블로그글은 2019년 조재영(Kevin Jo), 김승수(SeungSu Kim)님의 딥러닝 홀로서기 세미나를 수강하고 작성한 글임을 밝힙니다.
Advanced CNN Architectrues
ImageNet이란?
- 다양한 이미지 분류 및 물체 인식 과제에서의 성능을 비교할 수 있도록 설계된 대규모의 데이터셋이다.
- 1000개 이상의 카테고리에 속하는 약 1400만 개의 이미지를 포함하고 있다.
- ImageNet Large Scale Visual Recognition Challenge (ILSVRC)라는 대회에서 2017년까지 사용되었던 데이터로 학습용(training) 데이터와 테스트용(test) 데이터를 별도로 제공한다.
- 모델 성능을 비교할 수 있는 표준 벤치마크로, 다양한 모델들의 성능을 측정하고 비교하는 데 사용된다.
- Top-1 accuracy : 모델이 가장 높은 확률로 예측한 클래스가 실제 클래스와 일치하는 비율.
- Top-5 accuracy : 모델이 가장 높은 확률을 가진 5개의 클래스 중 하나를 예측한 비율.
ImageNet Large Scale Visual Recognition Challenge (ILSVRC)
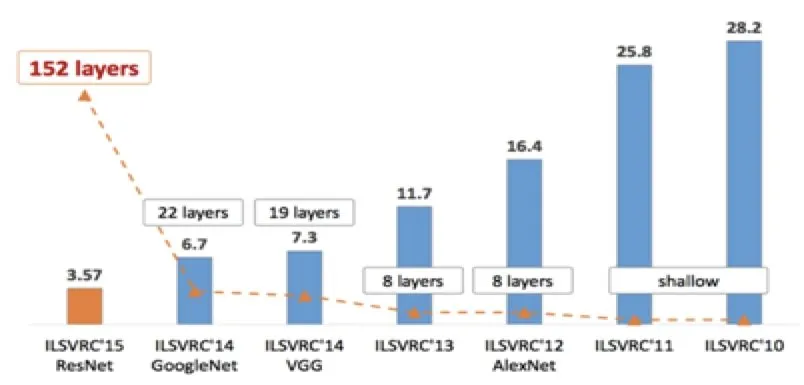
- Top-5 error rate를 주요 평가지표로 사용하였다.
- 2011년과 2012년에는 얕은(shallow) 신경망을 사용했으나, 2012년에 CNN을 적용한 AlexNet을 도입하면서 오류율이 약 10% 정도 감소했다.
- 이후 AlexNet에서 발전된 형태인 VGG, GoogleNet, 그리고 ResNet과 같은 심층 신경망들이 등장하면서, 성능은 급격히 개선되었고, 결국 3.57%의 Top-5 error rate에 도달했다
AlexNet
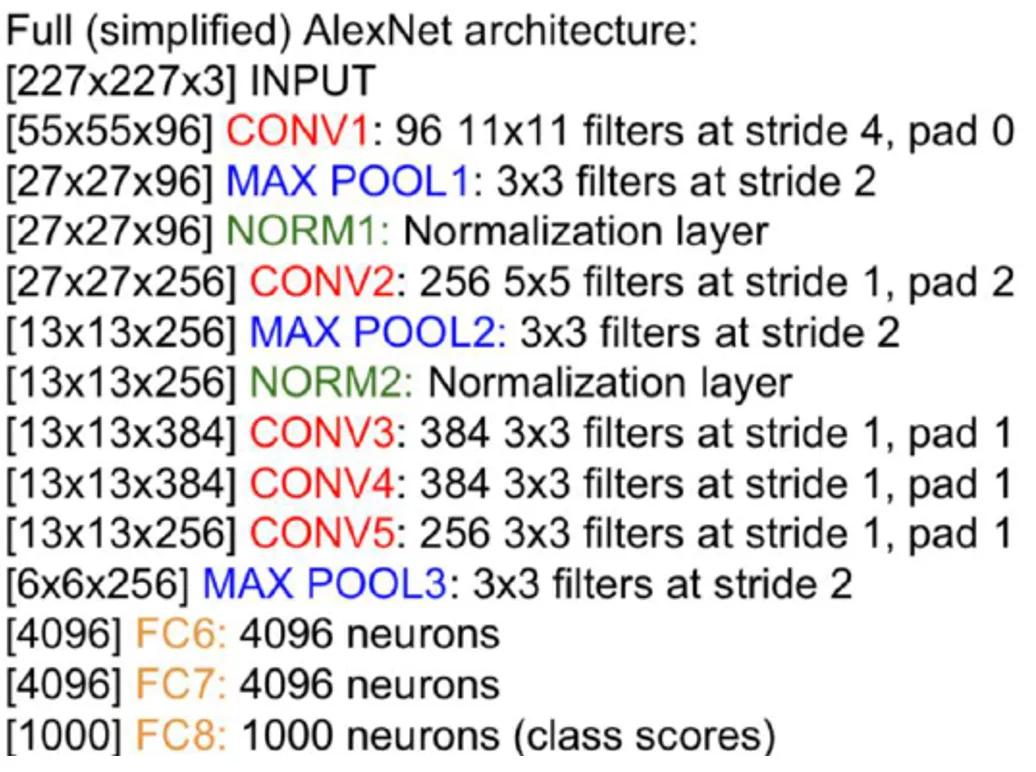
- 핵심 : CNN을 도입하자.
- 227 x 227 x 3 형태로 이미지를 입력받아 Conv layer와 Max Pooling layer를 거치고 최종적으로 FC layer를 거쳐 예측을 수행하였다. (참고로, 모델 그림의 224는 오기이며, 실제 입력 크기는 227 임)
- 2012년 당시 GPU 메모리가 3GB에 불과한 제한적인 환경에서 데이터 병렬 처리(data parallelism) 기법을 사용하여, 모델 파라미터를 여러 GPU에 분배하고 훈련 데이터를 병렬로 처리하여 메모리 부족 문제를 해결하였다.
VGG
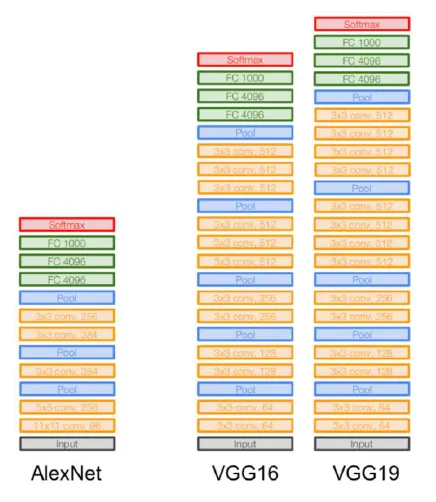
- 핵심 : 작은 필터를 가지고 네트워크를 더 깊게 쌓자
- Alex Net과 거의 동일한 구조를 가졌지만 네트워크를 깊게 필터를 줄이고 네트워크를 깊게 쌓았다.
- 기존 방식 (AlexNet): 큰 필터(예: 7x7)로 하나의 레이어를 쌓는 방식
- 개선된 방식: 작은 필터(예: 3x3)로 여러 개의 레이어를 쌓아 네트워크를 깊게 만들자.
- Alex Net과 거의 동일한 구조를 가졌지만 네트워크를 깊게 필터를 줄이고 네트워크를 깊게 쌓았다.
- 필터 크기와 수의 차이
- Receptive Field:
- 7x7 필터: 한 레이어에서 receptive field가 7x7임
- 3x3 필터 3개: 첫 번째 레이어에서 3x3 필터, 두 번째에서 5x5, 세 번째에서 7x7 필터를 사용
- 결과적으로, 두 방법 모두 동일한 receptive field(7x7)을 가질 수 있었다.
- 파라미터 수:
- 7x7 필터: 7x7 = 49개의 파라미터
- 3x3 필터 3개: 각 3x3 필터가 9개의 파라미터를 가지고, 세 개의 레이어에서 총 9 * 3 = 27개의 파라미터
- 작은 필터를 사용하면 파라미터 수가 절반으로 줄어들었다.
- Receptive Field:
- 효과
- 파라미터 수 절감: 동일한 receptive field를 유지하면서 파라미터 수가 적어짐.→ 모델 크기 축소로 overfitting
- 비선형성 증가: 여러 개의 작은 필터로 더 깊은 네트워크를 만들면 각 레이어마다 비선형성이 증가 → 더 복잡한 패턴을 학습할 수 있게 되어 학습 능력 향상
- 학습 속도 향상: 적은 파라미터와 깊은 네트워크 구조 덕분에 학습 속도도 빨라짐
- 한계
- 네트워크의 마지막 부분인 Classifier 부분에서 여전히 FC layer가 사용되고 있었기 때문에, 이 부분에서 파라미터 수가 급격하게 증가하였다.
GoogleNet
- 핵심 : 계산 효율성(computational efficiency)은 높이면서 네트워크를 더 깊게 쌓자
- Inception module을 도입하였고 FC layer를 CNN으로 대체하였다. (물론, 최종 분류를 위해 작은 FC Layer 사용)
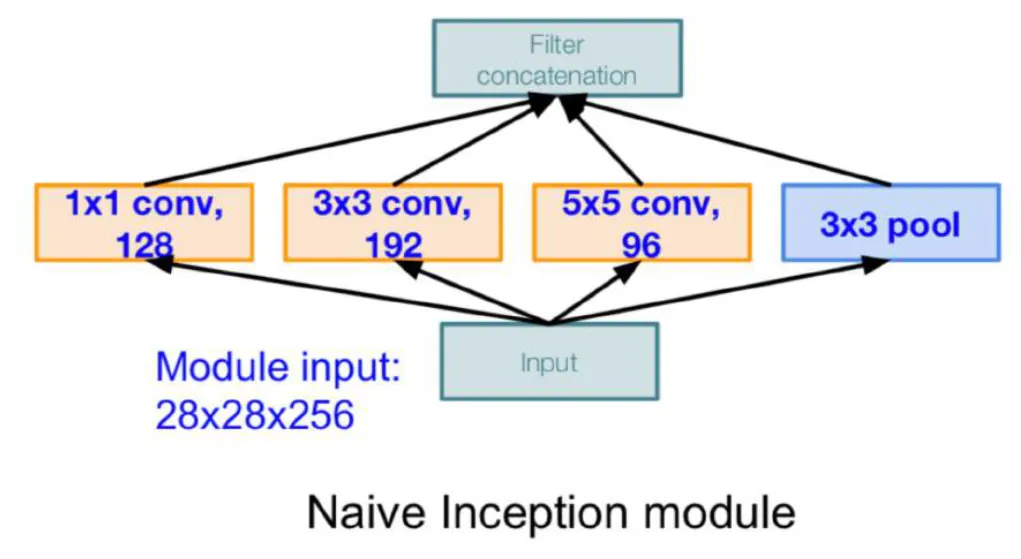
Native Inception Module
- 하나의 크기 필터만 사용하지 않고, 여러 크기의 필터를 동시에 적용하여 다양한 특성을 추출하였다.
- 패딩과 stride를 적절히 활용하여 출력 크기가 동일하도록 조정한 후, 모든 결과를 concatenate하였다.
- 입력: 28 x 28 x 256
- 1x1 conv: stride 1, 패딩 없음 → 28 x 28 x 128
- 3x3 conv: stride 1, 패딩 1 → 28 x 28 x 192
- 5x5 conv: stride 1, 패딩 2 → 28 x 28 x 96
- 3x3 pool: stride 1, 패딩 1 → 28 x 28 x 256
- 출력: 28 x 28 x (128 + 192 + 96 + 256) = 28 x 28 x 672
- 전과 달리, pooling 레이어는 크기를 줄이기 위한 용도가 아니라, 정보를 더욱 확장하고 다양한 특성을 학습하기 위해 사용되었다.
- 하지만 이렇게 되면, Output의 depth는 모델이 깊어짐에 따라 크게 증가하게 되고 이에 따라 파라미터 수가 증가하게 되어 근본적인 원인이였던 computational efficiency를 높이지 못하고 오히려 연산량이 많아진다. → 1x1 conv를 도입하여 해결
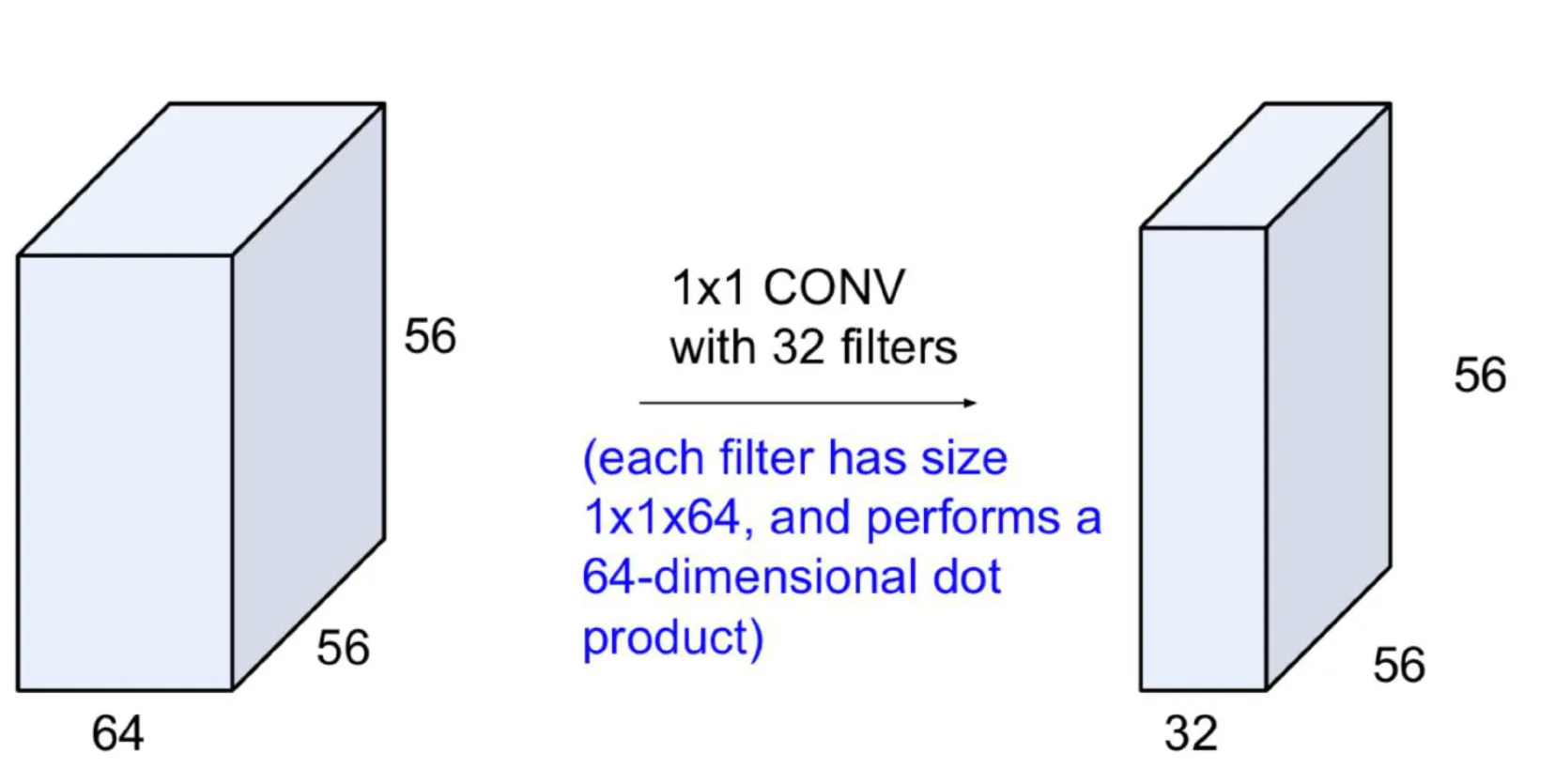
1x1 convolutions
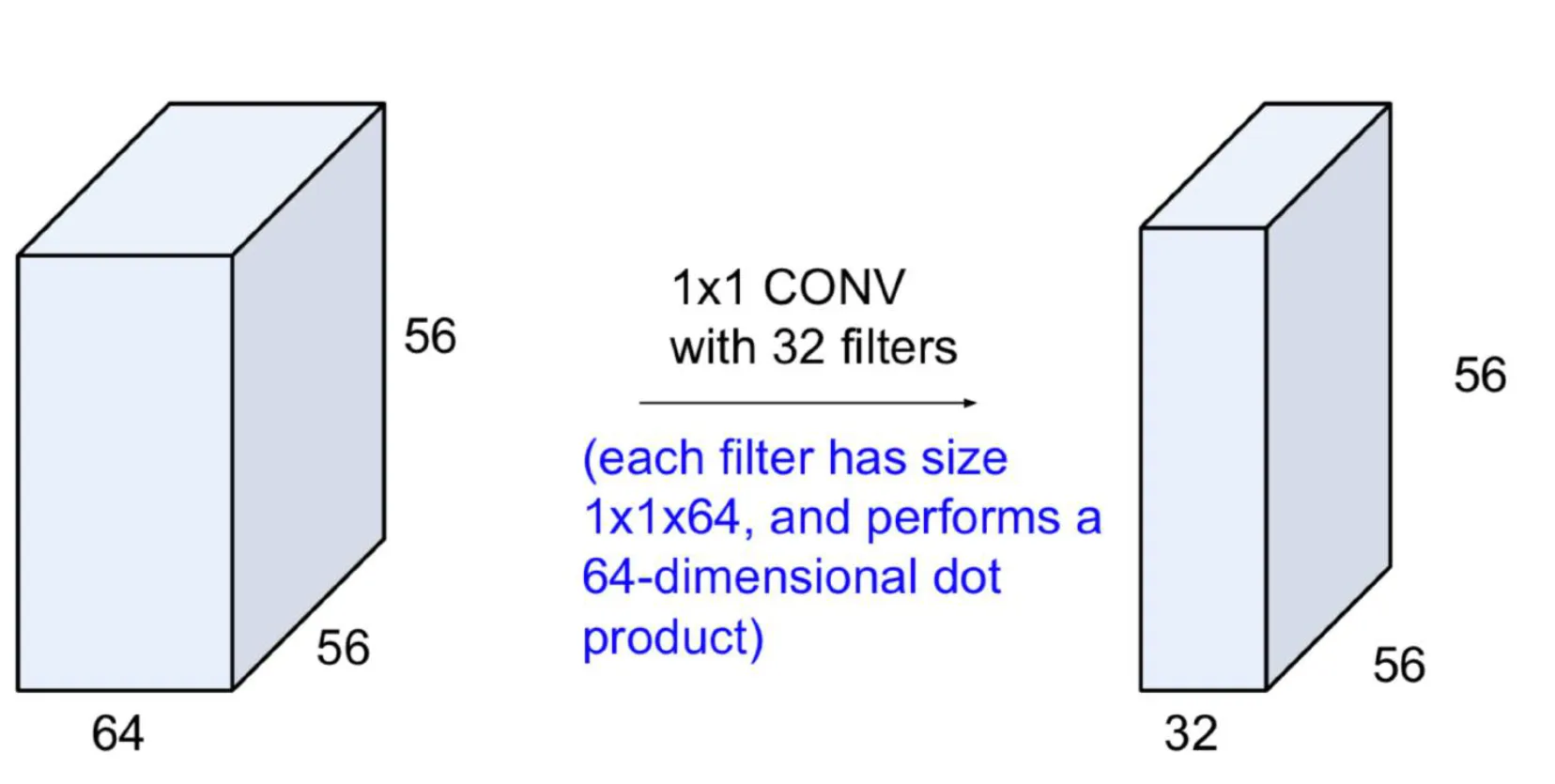
- 크기 (가로, 세로)는 그대로 두고, depth만 변환한다. 이는 특징 맵의 채널 수를 줄이거나 늘리는 효과를 가져온다.
- 특징
- 각 채널 간의 관계를 학습하면서, 다양한 채널들 사이의 정보를 압축할 수 있다. 이는 채널 간 연관성을 학습하고 특징 추출을 용이하게 한다.
- 모델 효율성을 높일 수 있다.
- Bottleneck이라고 불리는 Native Inception Module의 확장된 형태에 사용되었다.
BottleNeck
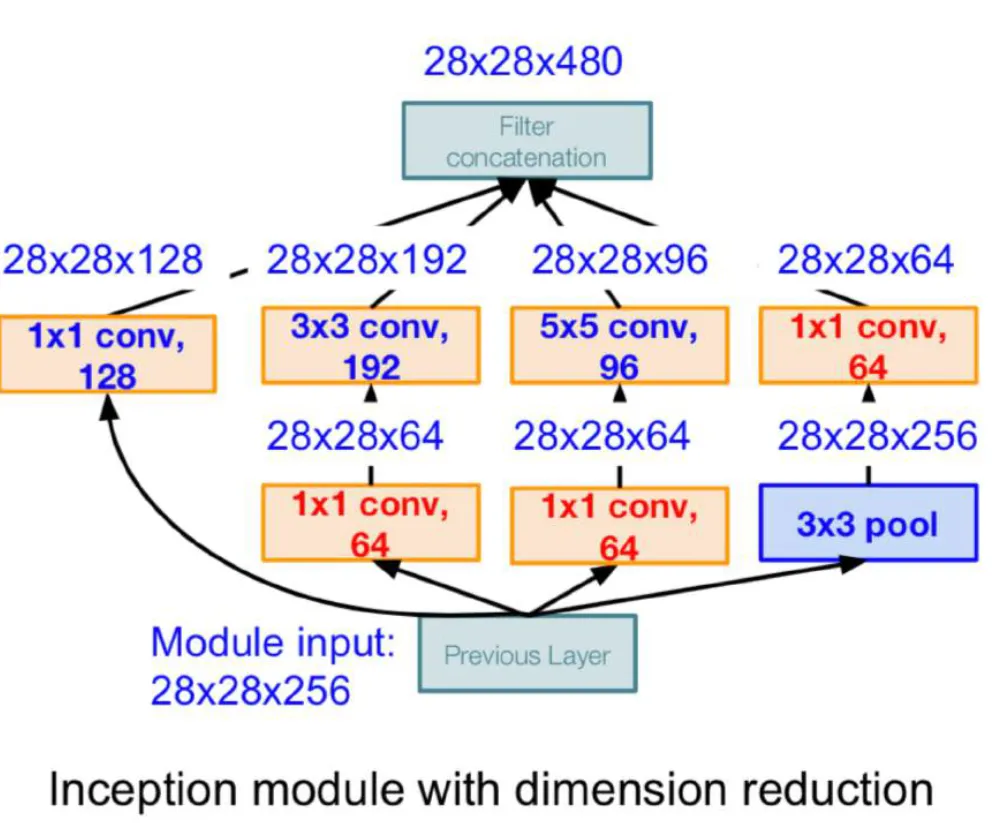
- 기존의 Native Inception Module에서 각 conv와 pooling layer를 통과하기 전후에 1x1 conv를 추가하였다.
- 정보의 양은 유지하며 depth를 줄여 연산량을 줄이는 효과를 가져왔다.
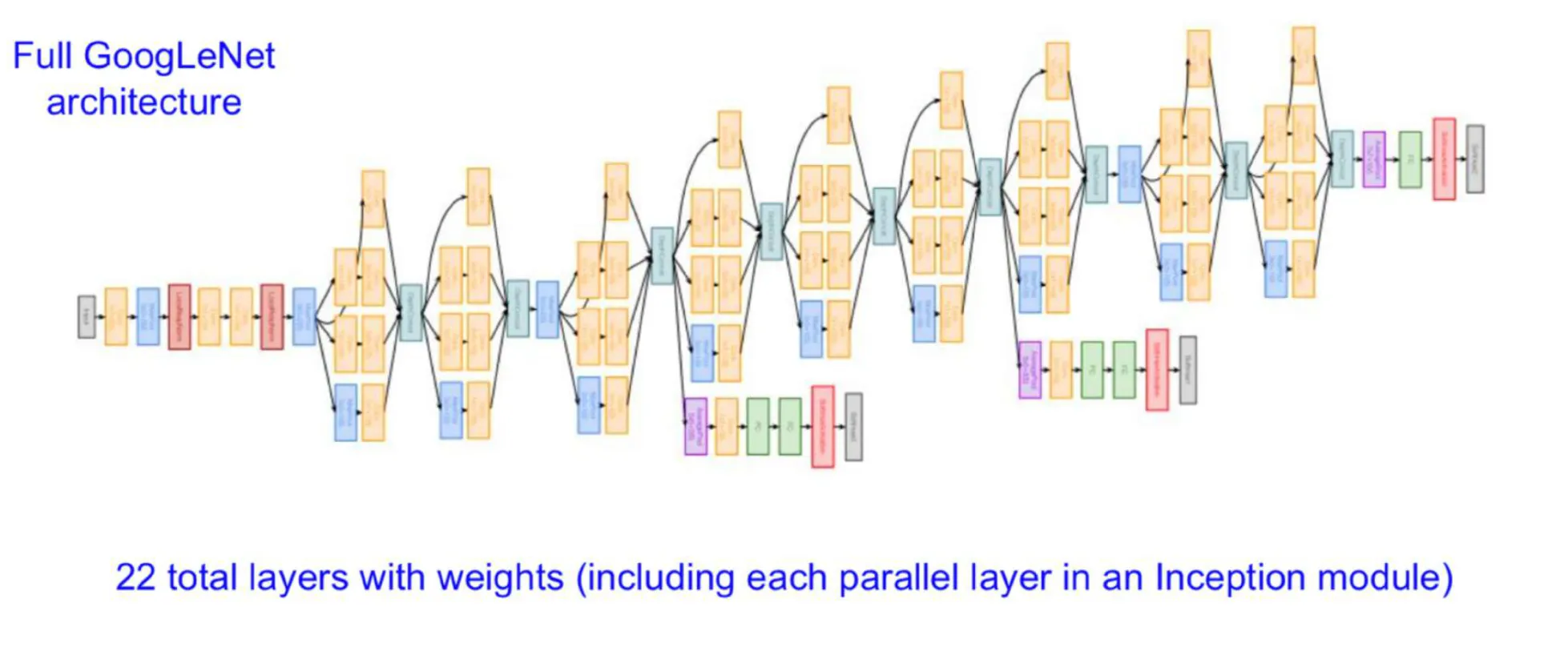
전체 구조
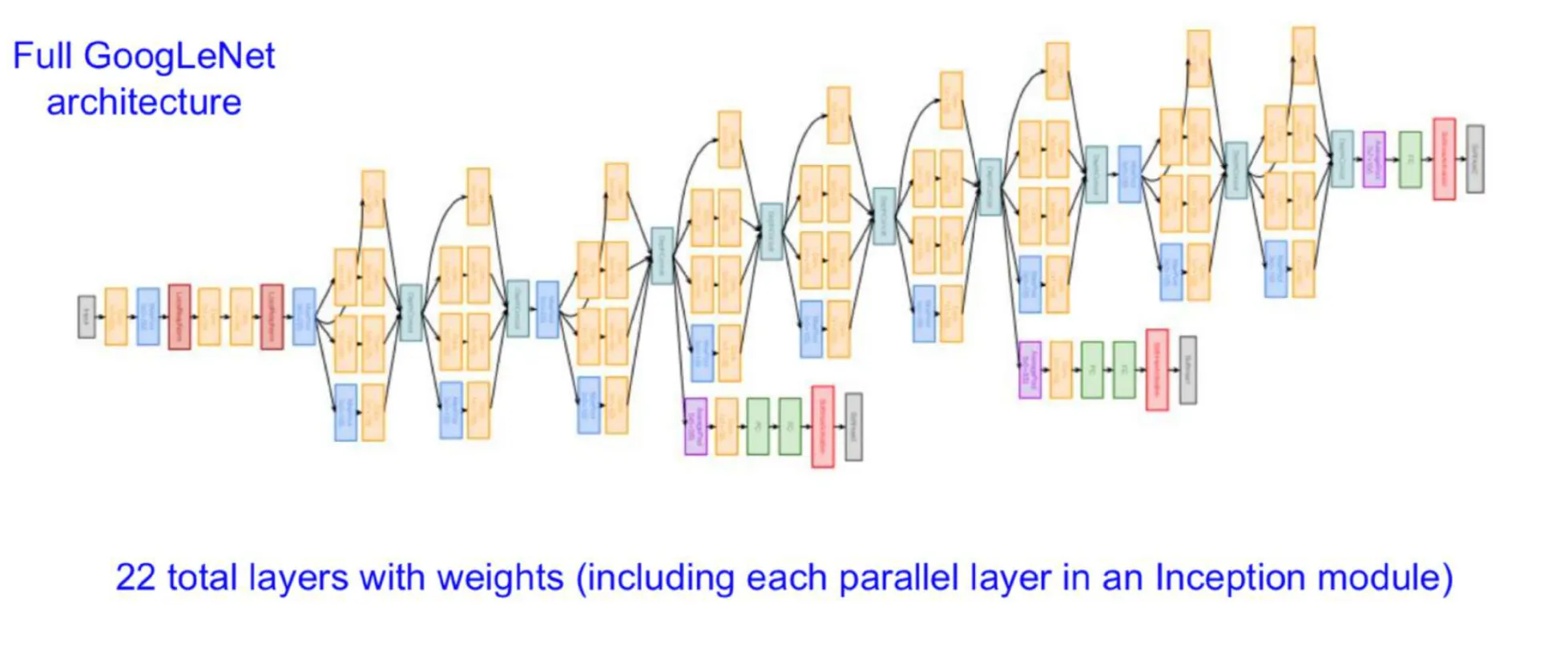
- 가중치를 갖는 22개의 layer를 가진다.
- 모델이 깊어지면서 Gradient Vanishing 문제가 발생했으며, 이는 마지막에 계산된 loss가 역전파를 통해 앞단까지 제대로 전달되지 않게 되는 문제였다. 이를 해결하기 위해 Auxiliary Classifiers를 도입하였다.
- Auxiliary Classifiers: 중간 layer에서 추가적인 classification을 수행하여 추가적인 loss를 계산하고, 이를 최종 loss와 합산하여 gradient가 Output에서 먼 layer까지 잘 전달되도록 하였다.
ResNet
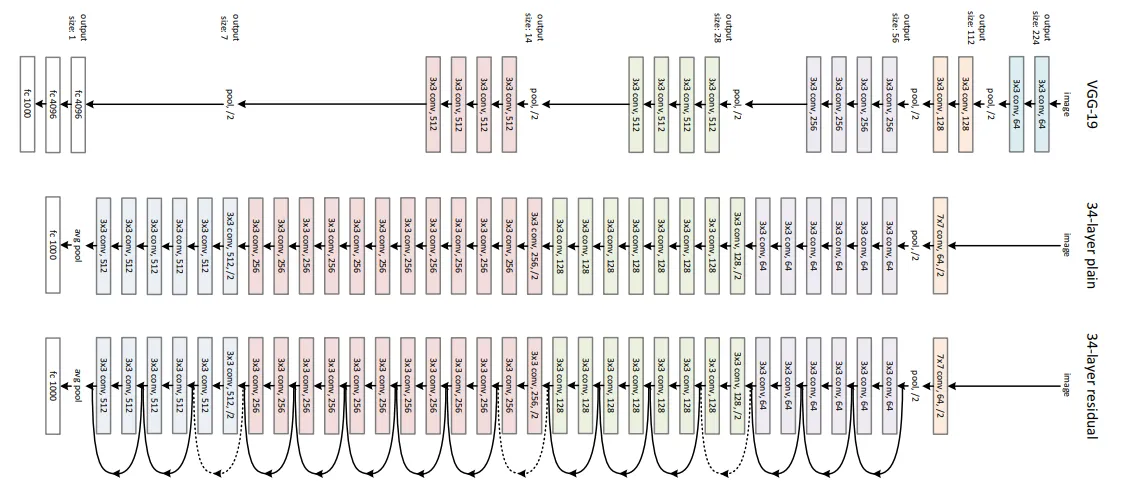
- 핵심 : residual connection을 써서 네트워크를 매우 깊게 쌓아보자
Deep CNN의 문제점
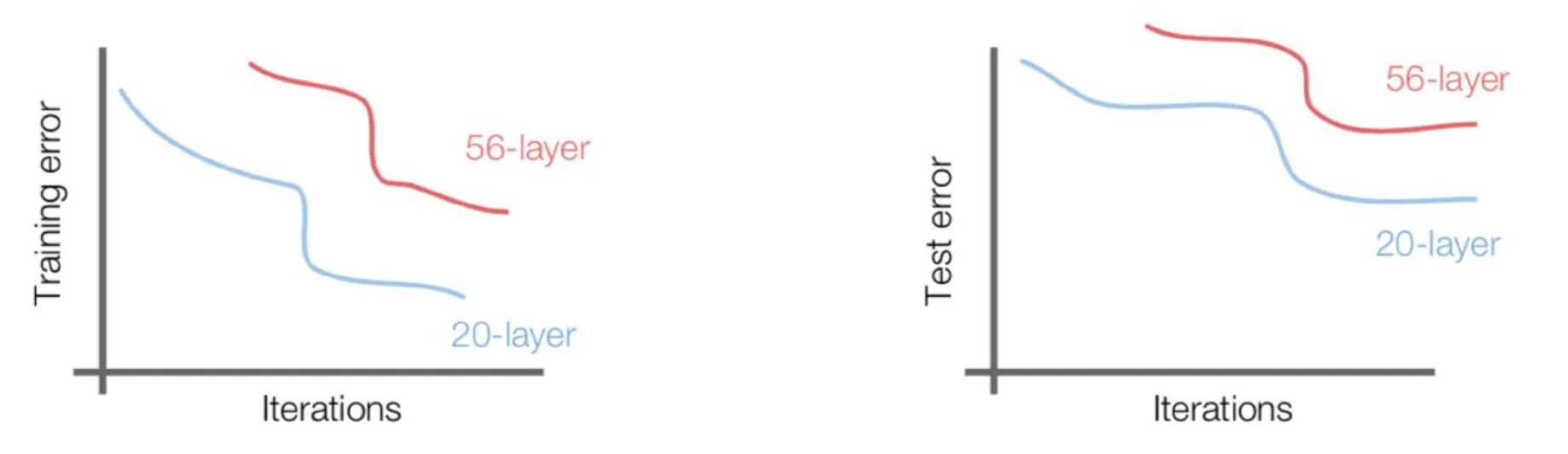
- 일반적인 직관: 모델의 레이어를 깊게 쌓으면 더 많은 정보를 학습할 수 있어, 더 좋은 성능을 낼 것이라고 예상할 수 있다.
- 실험 결과:
- 우측 그래프에서, 레이어가 적은(20-layer) 모델이 레이어가 많은(56-layer) 모델보다 test error가 작게 나왔다.
- 심지어 Training error도 레이어가 적은 모델이 더 낮았는데, 모델이 깊어질수록 데이터가 더 잘 학습될 것이라고 생각했으나 그 예측은 맞지 않았다.
- 결론: 모델이 깊어질수록 최적화가 어려워진다는 사실을 인식하게 되었다. → Residual Learning을 도입하여 해결
Residual Learning
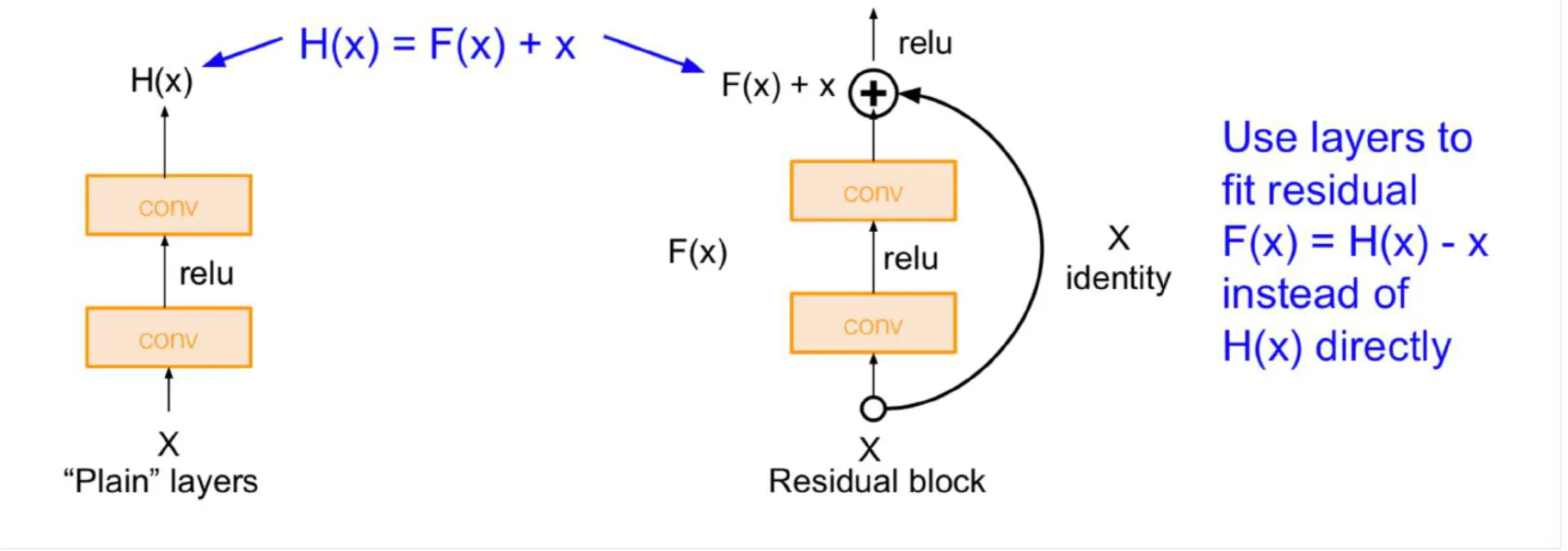
- Plain Layer: 이전 레이어가 배운 정보 x (입력)와, 더 배워야 할 정보 F(x)를 더한 값을 H(x)로 나타내며, 고차원 벡터 사이의 mapping을 학습한다.
- 깊어질수록 학습해야 할 정보가 많아져 최적화가 어려워지는 문제점을 가진다.
- Residual Block: 입력(이전 레이어에서 얻은 정보, 즉 이미 알고 있는 정보)을 출력에 더해줌으로써, 더 배워야 할 정보만을 학습하게 한다.
- 결과적으로 복잡한 mapping을 학습하는 것이 아니라, skip connection을 통해 이미 알고 있는 정보에서 더 배워야 할 정보만을 학습하도록 유도한다.
전체 구조

- 필터의 개수를 점차 늘리되, 필터 수를 2배씩 증가시킬 때마다 stride를 2로 설정하여, max pooling 대신 주기적으로 이전 output의 크기를 절반으로 줄였다.
- 모델의 맨 처음에는 7x7 convolution을 사용하였다.
- 최종 분류를 위해 하나의 FC Layer만 사용하여, 모델 파라미터 증가 문제를 해결하였다.
- 모델이 깊어짐에 따라 최적화가 어려운 문제를 해결하기 위해 Residual Learning을 도입하여, 각 레이어가 배워야 할 정보량을 줄여 최적화 문제를 해결하였다.
깊은 ResNet 모델에 BottleNeck 도입
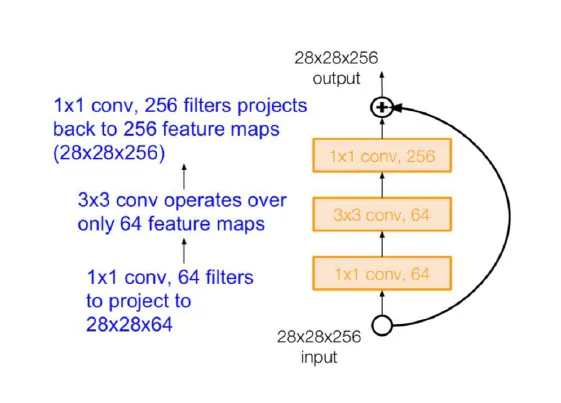
- ResNet은 레이어 수가 다른 모델들로 구성되어 있으며, 대표적으로 ResNet-18, ResNet-34, ResNet-50, ResNet-101, ResNet-152가 존재한다.
- 특히, ResNet-50 이상의 모델부터는 GoogleNet에서 사용된 Bottleneck 구조를 도입하여, depth를 줄여주고, 깊은 모델의 연산량 증가 문제를 해결하였다.
모델 성능 비교
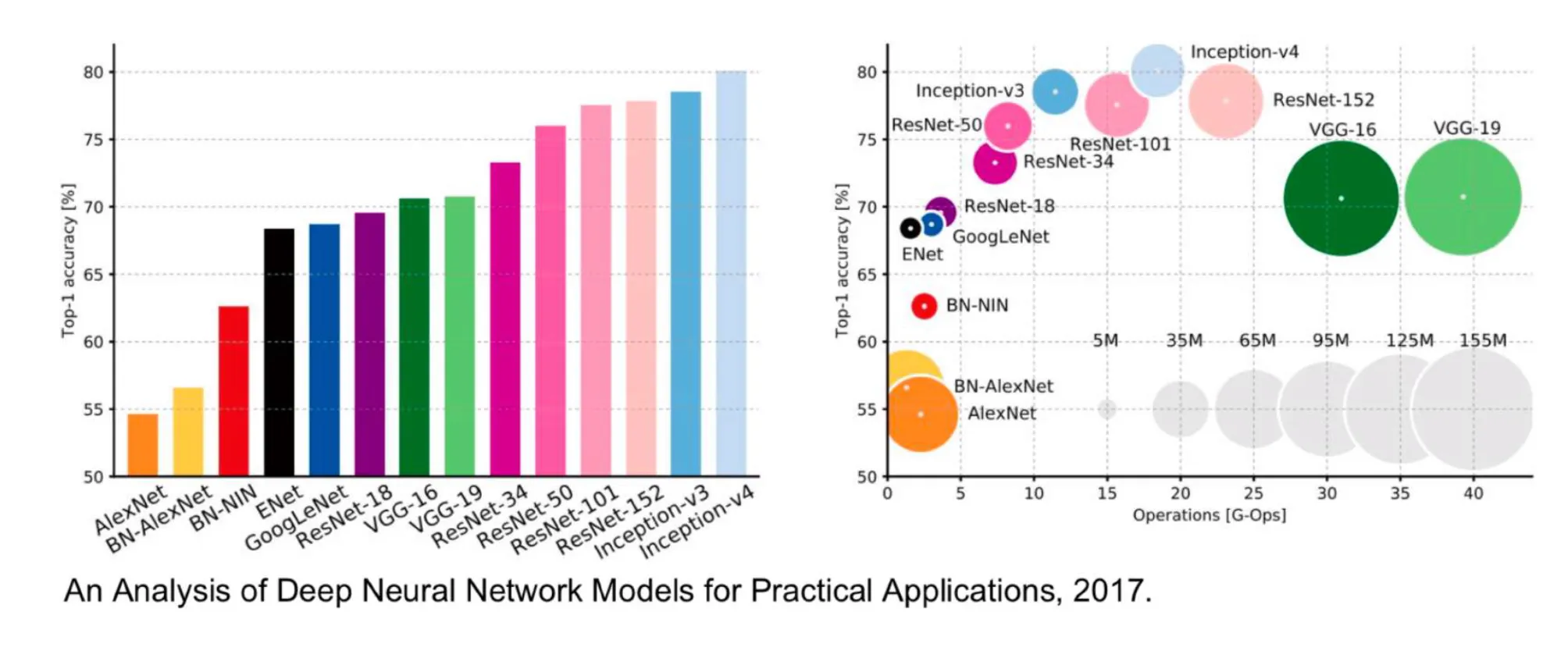
- 그래프는 Top-1 Accuracy, G-Ops (연산량), 그리고 메모리 사용량 지표를 통해 모델들간의 성능을 비교한다.
- 특히, ResNet과 Inception module을 결합한 Inception-v4는 VGG보다 적은 메모리와 연산량으로 더 높은 정확도를 기록했다.

제 글이 유익하셨다면 ♡와 팔로우로 응원 부탁드립니다.