
도입
- 데이터 분석에서는 도메인이 중요하다.
- 데이터 분석 및 머신러닝의 전반적인 이해
- 데이터 분석 ≠ 머신러닝
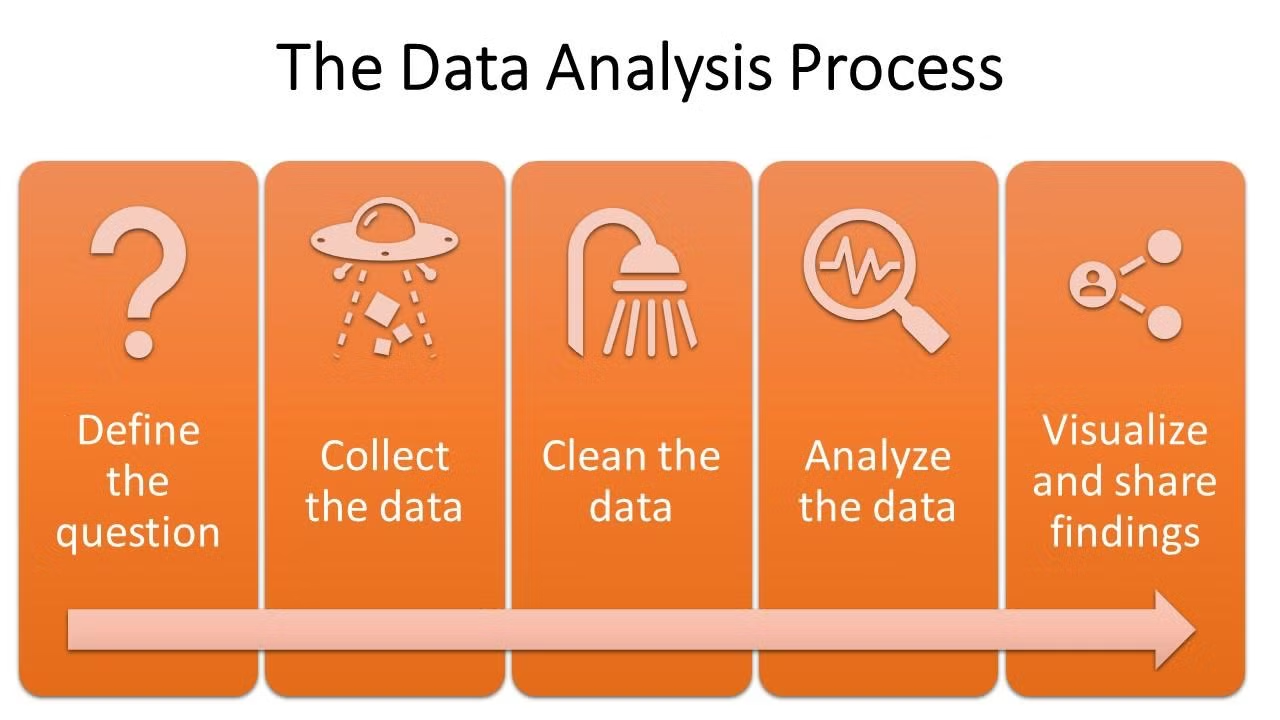
데이터 분석 프로세스
- 문제 정의 → 데이터 수집 → 데이터 전처리 → 데이터 분석 → 인사이트 추출
- 문제 정의가 매우 중요함
머신러닝 프로세스
- 비즈니스 이해 → 데이터 이해 → 데이터 전처리 → 모델링 → 평가 → 배포
- 모든 문제가 머신러닝으로 해결되는 것은 아님 (기초 통계료도 해결)
- 특화된 문제가 있음
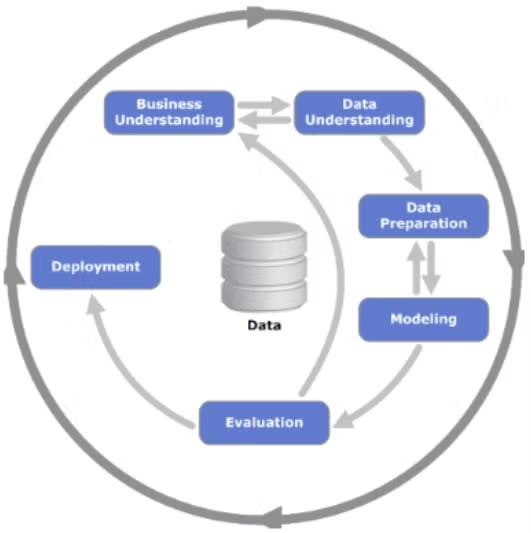
- ML1반에서는 모델링과 평가만 다루지만 전체적인 과정을 알고 있어야함
분석용 파이썬 라이브러리와 프레임워크
- 다양한 라이브러리와 프레임워크가 있어 모델을 사용할 수 있지만, 모델에 대한 이해가 매우 중요함

이미지 출처
Key Python Libraries for Data Analysis and Code examples
다양한 데이터 관련 직무

이미지 출처
필수 Skill
- 데이터 베이스/클라우드 서비스(Azure, AWS 등) 이해
- 데이터 추출 및 가공 (SQL)
- 데이터 분석 및 모델링 (R, Python)
- 데이터 시각화 및 대시보드 개발
수업
- 데이터 분할의 중요성 : 모델의 일반화 성능을 평가하기 위함
- 과적합 방지 : 모델이 학습에 지나치게 맞춰져 성능이 떨어지는 현상
- 일반화 성능 평가 : 학습에 사용되지 않는 데이터로 모델의 성능을 측정해야함. (훈련, 검증, 테스트 데이터셋으로 분할하여 사용)
- 데이터 분할 방법
- 훈련 데이터셋 : 모델이 학습하는 데 사용하는 데이터 (전체 데이터의 60%~80%)
- 검증 데이터셋 : 모델의 성능을 조정하고 하이퍼파라미터 튜닝을 수행 (전체 데이터의 10%~20%)
- 테스트 데이터셋 : 최종적으로 모델의 성능을 평가하는데 사용 (전체 데이터의 10%~20%)
- 데이터셋 분할 기법
- 홀드 아웃 방법 : 데이터를 훈련 세트와 테스트 데이터 셋으로 나눈다.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) - 교차 검증 : 데이터 셋을 여러개의 폴드로 나누어 훈련 및 검증을 여러 번 반복하는 방법
from sklearn.model_selection import cross_val_score scores = cross_val_score(model, X, y, cv=5) - 계층적 분할 : 데이터셋의 라벨의 분포를 유지하면서 데이터셋을 분할하는 방법 (분류 문제에서 비율이 불균형할 때 유용)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
- 홀드 아웃 방법 : 데이터를 훈련 세트와 테스트 데이터 셋으로 나눈다.
- 클래스 비율을 맞춰주는 것이 중요 : 데이터 불균형이 발생하면 성능에서 문제가 발생할 수 있다.
- tran_test split 하이퍼 파라미터
- arrays : 분할할 데이터
- test_size : 테스트 세트 크기 비율 또는 개수
- train_size : 훈련 세트 크기 비율 또는 개수
- random_state : 재현성을 위한 랜덤 시드
- shuffle : 데이터를 섞을지 여부
- stratify : 클래스 비율 유지 여부
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, ConfusionMatrixDisplay# 예시 데이터셋 만들기
X, y = make_classification(n_samples = 1000, n_features = 20, n_informative=10, n_redundant = 10, random_state=11)# 1. train, test 나누지 않았을 때 결과
model = DecisionTreeClassifier(random_state=111)
model.fit(X,y)
y_pred_no_split = model.predict(X)# 정확도 측정
acc_no_split = accuracy_score(y, y_pred_no_split)
acc_no_split # 과적합# 2. train, test 나누었을 떄 결과
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=111)model_split = DecisionTreeClassifier(random_state=111)
acc_train = accuracy_score(y_train, y_pred_train)
acc_test = accuracy_score(y_test, y_pred_test)
print(acc_train) #과적합
print(acc_test)
제 글이 유익하셨다면 ♡와 팔로우로 응원 부탁드립니다.