
본 블로그 글은 박동민·강영민 저자님의 으뜸파이썬 교재를 참고하여 만들어진 글임을 밝힙니다.
함수
- 반복적으로 사용되는 코드 - 덩어리 (block)
- 기능에 따라 미리 만들어진 블록은 필요할 때 호출
- 파이썬에 미리 만들어져 제공되는 내장함수
- 사용자가 정의 직접 만들어 사용하는 사용자 정의 함수
- def 키워드를 사용한다.
# 함수선언
def [함수이름] ([매개변수])
[코드 블록]
return [반환할 값]- 한번 만들어진 함수는 재사용이 가능하다.
- 프로그램 개발 의 시간과 비용을 절약할 수 있다.
매개변수 vs 인자
매개변수 (parameter)
- 함수나 메소드 헤더부에 정의된 변수로 함수가 호출될 때 실제값을 전달받는 변수이다.
인자 (argument)
- 함수나 메소드가 호출될 때 전달되는 실제 값을 말한다.
응용
두 수를 전달받아 사칙 연산 결과 print
def print_operations(a, b):
print(a + b) # 더하기
print(a - b) # 빼기
print(a * b) # 곱하기
print(a / b) # 나누기매개변수를 활용한 2차 방정식 근 구하기 (근의 공식)
def print_root(a, b, c):
r1 = (-b + (b ** 2 - 4 * a * c) ** 0.5) / (2 * a)
r2 = (-b - (b ** 2 - 4 * a * c) ** 0.5) / (2 * a)
print(f'해는 {r1} 또는 {r2}')return을 이용한 결과값 반환
- return 키워드를 이용하여 하나 이상의 값을 반환해 줄 수 있다.
- 이때 두 개 이상의 값을 반환하는 다중 반환문이 가능하다.
- 쉼표로 구분되는 튜플 형으로 반환된다.
응용
매개변수를 활용한 2차 방정식 근 구하기 (근의 공식 - 결과 반환)
def get_root(a, b, c):
r1 = (-b + (b ** 2 - 4 * a * c) ** 0.5) / (2 * a)
r2 = (-b - (b ** 2 - 4 * a * c) ** 0.5) / (2 * a)
return r1, r2전역 변수
- 전역 변수는 함수 외부에서 선언되며, 모든 함수에서 접근할 수 있다.
- 반면, 지역 변수는 함수 내부에서 선언되고, 해당 함수 내에서만 유효하다.
- 전역 변수는 수정 시
global키워드를 사용해야 함수 내부에서 변경 가능하다.- 다만 전역 변수를 사용하는 것은 코드의 길이가 길어 질 경우 전역변수는 에러의 주요 원인이된다.
디폴트 인자
- 함수 호출 시 인자를 제공하지 않을 경우 기본적으로 사용되는 값이다.
- 함수 정의 시 매개변수에 값을 할당하여 설정하며, 호출 시 해당 인자를 생략하면 디폴트 값이 자동으로 적용된다.
💡 중요
- 디폴트 매개변수는 전체 변수에 대해 모두 할당하거나 매개변수의 출현 순서상 뒤에 있는 변수부터 할당해야한다.
다음의 코드는 에러 발생
def div(a = 2, b): return a / b
응용
여러번 별을 출력하는 함수 (디폴트 값은 1)
def print_star(n = 1):
for _ in range(n):
print("******************")- 인자를 생략하는 경우 정상 수행됨
함수 인자 전달 방식
키워드 인자와 위치 인자
- 위치 인자 : 파이썬에서 기본 인자 전달 방식
- 키워드 인자 : 위치와 상관없이 키워드에 의해서 인자 값이 결정되는 방식
result1, result2 = get_root(c = -8, a = 1, b = 2)💡 중요
- 키워드 인자와 위치 인자를 섞어서 사용할 때에는 반드시 위치인자가 먼저 나타나야한다.
- 위치 인자를 사용할 경우 순서대로 매개변수에 할당된다.
다음의 코드는 에러 발생
result1, result2 = get_root(c = -8, a = 1, b) # 위치 인자는 키워드 인자보다 항상 먼저 result1, result2 = get_root(1, -8, b = 2) # 동일한 매개변수 b에 위치인자와 키워드 인자 동시 사용
가변 인자
- 인자의 수가 정해지지 않은 인자
- 매개변수를 앞에 사용
- 가변 인자를 사용하면 함수에 전달되는 인자를 튜플 형태로 묶어서 처리할 수 있다.
def print_numbers(*args):
for number in args:
print(number)
print_numbers(1, 2, 3)💡 중요
- 가변 인자는 위치 인자와 키워드 인자와 함께 혼합하여 사용할 수도 있다.
- 하지만 가변 인자는 항상 위치 인자보다 뒤에 있어야 하며, 키워드 인자보다 앞에 와야 한다.
def mix_params(a, b, *args, option=True): print(f"a: {a}, b: {b}") print(f"가변 인자: {args}") print(f"옵션: {option}") mix_params(1, 2, 3, 4, 5, option=False)
재귀 함수
- 함수 내부에서 자기 자신을 호출하는 함수
응용
피보나치 수
- 자연수에서 시작하여 다음과 같이 정의되는 수열
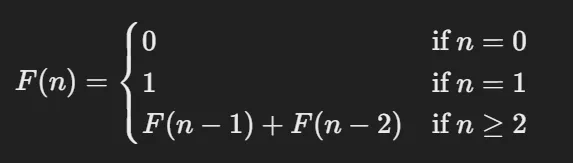
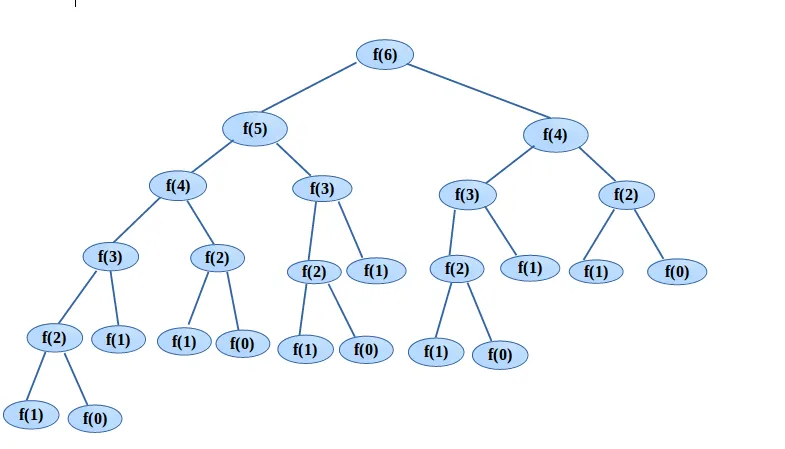
def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n-1) + fibonacci(n-2)입력함수와 출력함수
입력함수
- 사용자로부터 입력을 받기 위한 함수
- input() 함수 사용
- int(), float()와 함께 사용하여 다양한 타입으로 입력 받을 수 있음
- split() 함수와 함께 입력된 문자를 공백 단위로 나눠 받을 수 있음
- 구분자를 사용하면 공백 대신 구분자로 나눌 수 있음
a = int(input("정수를 입력하세요 : ")
b = float(input("실수를 입력하세요 : ")
c, d, e = input("공백으로 구분하여 3개의 단어를 입력하세요 : ").split()
f, g, h = input(",으로 구분하여 3개의 단어를 입력하세요 : ").split(',')문자열 메서드
| 함수 | 설명 | 예시 |
|---|---|---|
upper() | 문자열의 모든 문자를 대문자로 변환합니다. | s = "hello"s.upper()결과: 'HELLO' |
lower() | 문자열의 모든 문자를 소문자로 변환합니다. | s = "HELLO"s.lower()결과: 'hello' |
split() | 문자열을 공백이나 지정한 구분자를 기준으로 분할합니다. | s = "apple orange banana"s.split()결과: ['apple', 'orange', 'banana'] |
strip() | 문자열의 양쪽 끝에서 공백 또는 특정 문자를 제거합니다. | s = " hello "s.strip()결과: 'hello' |
replace() | 문자열에서 특정 부분을 다른 문자열로 대체합니다. | s = "hello world"s.replace("world", "Python")결과: 'hello Python' |
find() | 문자열 내에서 특정 문자열의 첫 번째 위치를 반환합니다. | s = "hello"s.find("e")결과: 1 |
join() | 리스트 등의 iterable을 특정 문자열로 연결합니다. | lst = ['a', 'b', 'c']"-".join(lst)결과: 'a-b-c' |
startswith() | 문자열이 특정 문자열로 시작하는지 확인합니다. | s = "hello"s.startswith("he")결과: True |
endswith() | 문자열이 특정 문자열로 끝나는지 확인합니다. | s = "hello"s.endswith("lo")결과: True |
count() | 문자열 내에서 특정 문자의 등장 횟수를 셉니다. | s = "banana"s.count("a")결과: 3 |
출력함수
f-string
name = "John"
age = 30
template = f"My name is {name} and I am {age} years old."
print(template) # 출력: My name is John and I am 30 years old.format() 함수
template = "My name is {} and I am {} years old."
result = template.format("John", 30)
print(result) # 출력: My name is John and I am 30 years old.- format의 경우 중괄호({ })에 숫자를 넣어 출력 순서 제어가 가능하다.
- 인덱스 중복도 가능함
% 연산자를 이용
template = "Hello, my name is %s."
result = template % "Alice"
print(result) # 출력: Hello, my name is Alice.고급 format()
정수 포매팅
- 정수를 출력할 때 특정 형식으로 표현하는 방법
- format() 함수나 f-string을 사용하여 다양한 방식으로 정수를 포매팅할 수 있
기본 정수 포매팅
# 정수를 그대로 출력
num = 123
print("정수: {}".format(num)) # 출력: 정수: 123자릿수를 맞춘 포매팅 (Zero Padding)
# 정수를 자릿수를 맞춰 출력 (앞을 0으로 채움)
num = 42
print("숫자: {:05}".format(num)) # 출력: 숫자: 00042천 단위 구분자 사용
# 정수에 천 단위 구분자 추가
num = 1234567
print("숫자: {:,}".format(num)) # 출력: 숫자: 1,234,567
진법 변환 포매팅
num = 255
print("2진수: {:b}".format(num)) # 출력: 2진수: 11111111
print("8진수: {:o}".format(num)) # 출력: 8진수: 377
print("16진수: {:x}".format(num)) # 출력: 16진수: ff
부호 포함 포매팅
# 양수와 음수를 구분하여 출력 (부호 표시)
num = 42
print("부호: {:+}".format(num)) # 출력: 부호: +42실수 포매팅
- 실수 포매팅은 실수를 소수점 자릿수를 지정하거나 지수 표기법으로 표현
기본 실수 포매팅
# 실수를 그대로 출력
num = 123.456
print("실수: {}".format(num)) # 출력: 실수: 123.456소수점 자릿수 지정
# 소수점 아래 2자리까지 출력
num = 3.141592
print("소수점 2자리: {:.2f}".format(num)) # 출력: 소수점 2자리: 3.14넓이와 자릿수 지정
# 전체 10자리로 맞추고 소수점 아래 3자리까지 출력
num = 3.141592
print("전체 10자리: {:10.3f}".format(num)) # 출력: 전체 10자리: 3.142지수 표기법
# 실수를 지수 표기법으로 출력
num = 0.000123
print("지수 표기법: {:.2e}".format(num)) # 출력: 지수 표기법: 1.23e-04천 단위 구분자와 소수점 자릿수 결합
# 실수에 천 단위 구분자와 소수점 자릿수 지정
num = 1234567.89123
print("포매팅: {:,.2f}".format(num)) # 출력: 포매팅: 1,234,567💡 정렬하기
- f-string과 format() 함수에서는 문자열을 가운데 정렬, 왼쪽 정렬, 오른쪽 정렬할 수 있다.
- 왼쪽 정렬:
<- 오른쪽 정렬:
>- 가운데 정렬:
^text = "Hello" print(f"{text:<10}") # 출력: 'Hello ' (총 10자리, 왼쪽 정렬) print(f"{text:>10}") # 출력: ' Hello' (총 10자리, 오른쪽 정렬) print(f"{text:^10}") # 출력: ' Hello ' (총 10자리, 가운데 정렬)
내장함수
- 파이썬 내장함수 목록
abs() | delattr() | hash() | memoryview() | set() |
|---|---|---|---|---|
all() | dict() | help() | min() | setattr() |
any() | dir() | hex() | next() | slice() |
ascii() | divmod() | id() | object() | sorted() |
bin() | enumerate() | input() | oct() | staticmethod() |
bool() | eval() | int() | open() | str() |
bytearray() | exec() | isinstance() | ord() | sum() |
bytes() | filter() | issubclass() | pow() | super() |
callable() | float() | iter() | print() | tuple() |
chr() | format() | len() | property() | type() |
classmethod() | frozenset() | list() | range() | vars() |
compile() | getattr() | locals() | repr() | zip() |
complex() | globals() | map() | reversed() | __import__() |
del() | hasattr() | max() | round() | len() |
사용 예시
type(): 객체의 데이터 타입을 확인한다.eval(): 문자열로 된 Python 표현식을 실행한다.id(): 객체의 고유 메모리 주소를 반환한다.abs(): 절대값을 반환한다.min(): 최소값을 반환한다.max(): 최대값을 반환한다.sorted(): 리스트나 튜플을 정렬하여 새로운 리스트로 반환한다.
# 1. type(): 데이터 타입을 확인
x = 10
print(type(x)) # 출력: <class 'int'>
# 2. eval(): 문자열을 파이썬 코드로 실행
expression = "3 + 5"
print(eval(expression)) # 출력: 8
# 3. id(): 객체의 고유 식별자를 반환
y = 20
print(id(y)) # 출력: (메모리 주소값, 값에 따라 다름)
# 4. abs(): 절대값을 반환
print(abs(-7)) # 출력: 7
# 5. min(): 리스트나 튜플의 최소값을 반환
numbers = [1, 2, 3, 4, 5]
print(min(numbers)) # 출력: 1
# 6. max(): 리스트나 튜플의 최대값을 반환
print(max(numbers)) # 출력: 5
# 7. sorted(): 리스트나 튜플을 정렬하여 반환
unsorted_numbers = [5, 1, 3, 4, 2]
print(sorted(unsorted_numbers)) # 출력: [1, 2, 3, 4, 5]💡 도움이 되셨다면 ♡와 팔로우 부탁드려요!

제 글이 유익하셨다면 ♡와 팔로우로 응원 부탁드립니다.